
Java文档搜索引擎-测试报告
一、项目概述
1、项目背景
本项目是一个轻量级Java文档搜索引擎,基于正倒排索引实现。我从Oracle官网收集了10228份Java官方文档,通过分词和索引构建,提供关键词搜索功能,并展示标题、描述、原文链接,方便开发者离线或快速查阅Java API文档。
2、需求分析
2.1功能需求
(1)支持单个关键词搜索,返回匹配的文档标题、描述、官方URL
(2)点击标题可跳转到https://docs.oracle.com/en/java/javase/21/docs/api对应页面
(3)结果按相关性倒序排列
2.2非功能需求
(1)1000篇文档以内,搜索响应时间<500ms
(2)界面简洁,搜索框和结果清晰展示
二、测试环境与范围
1、测试环境
| 配置项 | 详情 |
| 操作系统 | Windows 11 |
| JDK版本 | 17 |
| 浏览器 | Microsoft Edge148.0.3967.83 |
| 文档规模 | 10228份Oracle Java官方文档 |
| 开发工具 | IntelliJ IDEA2026.1 |
2、测试范围
2.1已测功能
(1)关键词搜索(中英文、数字、常见Java类名如ArrayList,含空格的关键词)
(2)搜索结果正确显示标题、描述、URL
(3)点击标题能否正确跳转到Oracle官网
(4)空关键词、特殊字符、无匹配结果等异常输入
2.2未测功能
(1)高并发场景
(2)分布式部署
(3)安全性(防SQL注入等)
三、设计测试用例与执行
测试用例设计方案:
(1)分层设计:按功能测试、界面测试、性能测试、兼容性测试四个方面拆分
(2)场景化描述:每个用例包含前置条件、操作步骤、预期结果三要素
(3)正反向结合:正常流程+异常场景双重验证
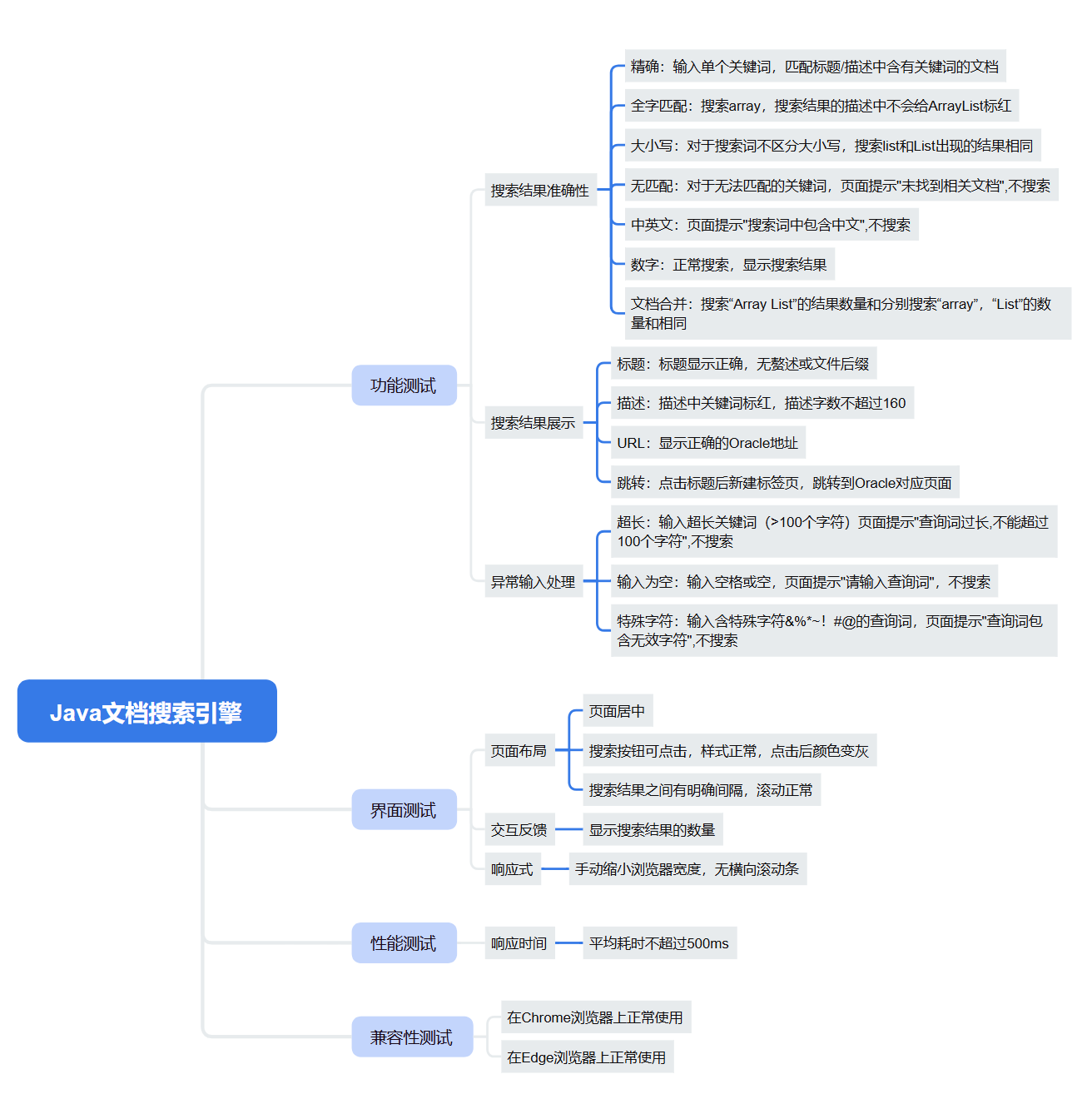
3.1、功能测试
测试用例全部通过
3.2、界面测试
测试用例全部通过

3.3、性能测试
测试用例全部通过

3.4、兼容性测试
测试用例全部通过

四、自动化测试
1、自动化技术架构
本项目的自动化测试采用 JUnit 5 框架,在 IntelliJ IDEA 中编写并执行。
测试范围:针对 DocSearcher 类的核心搜索方法 search(String query) 进行单元测试。
依赖管理:使用 Maven 管理 junit-jupiter 依赖,版本 5.9.3。
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter</artifactId>
<version>5.9.3</version>
<scope>test</scope>
</dependency>测试方式:通过 @BeforeEach 在每个测试前重新加载索引,确保测试隔离;使用 @Test 标记测试用例,利用 Assertions 类提供断言。
运行方式:在 IDEA 中直接运行测试类。
2、核心能力测试
使用 JUnit 5 编写了 6 个自动化测试用例,覆盖了正常搜索、空输入、超长关键词、特殊字符等场景。
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import searcher.DocSearcher;
import searcher.Result;
import java.util.List;
import static junit.framework.Assert.assertNotNull;
import static org.junit.jupiter.api.Assertions.assertEquals;
import static org.junit.jupiter.api.Assertions.assertTrue;
public class DocSearcherTest {
private DocSearcher docSearcher;
@BeforeEach
void setUp() {
docSearcher = new DocSearcher();
}
// 1. 正常搜索:有结果
@Test
void testSearchWithValidKeyword() {
List<Result> results = docSearcher.search("list");
assertNotNull(results);
assertTrue(results.size() > 0, "搜索 'list' 应该返回至少一条结果");
}
// 2. 搜索不存在的词:方法正常执行,不崩溃,且返回 List 对象
@Test
void testSearchWithNonExistentWord() {
List<Result> results = docSearcher.search("zzznotexist999");
assertNotNull(results);
}
// 3. 空字符串输入:返回空列表
@Test
void testSearchWithEmptyString() {
List<Result> results = docSearcher.search("");
assertNotNull(results);
assertEquals(0, results.size());
}
// 4. 只含空格的输入:返回空列表
@Test
void testSearchWithBlankSpaces() {
List<Result> results = docSearcher.search(" ");
assertNotNull(results);
assertEquals(0, results.size());
}
// 5. 超长关键词:确保不崩溃,返回空列表
@Test
void testSearchWithLongKeyword() {
StringBuilder longWord = new StringBuilder();
for (int i = 0; i < 300; i++) {
longWord.append("a");
}
List<Result> results = docSearcher.search(longWord.toString());
assertNotNull(results);
assertEquals(0, results.size());
}
// 6. 特殊字符:不会导致异常,返回空列表
@Test
void testSearchWithSpecialCharacters() {
List<Result> results = docSearcher.search("#@$%^&*");
assertNotNull(results);
}
}
五、测试结果分析
1、自动化测试结果
所有用例均通过,验证了搜索核心逻辑的稳定性。
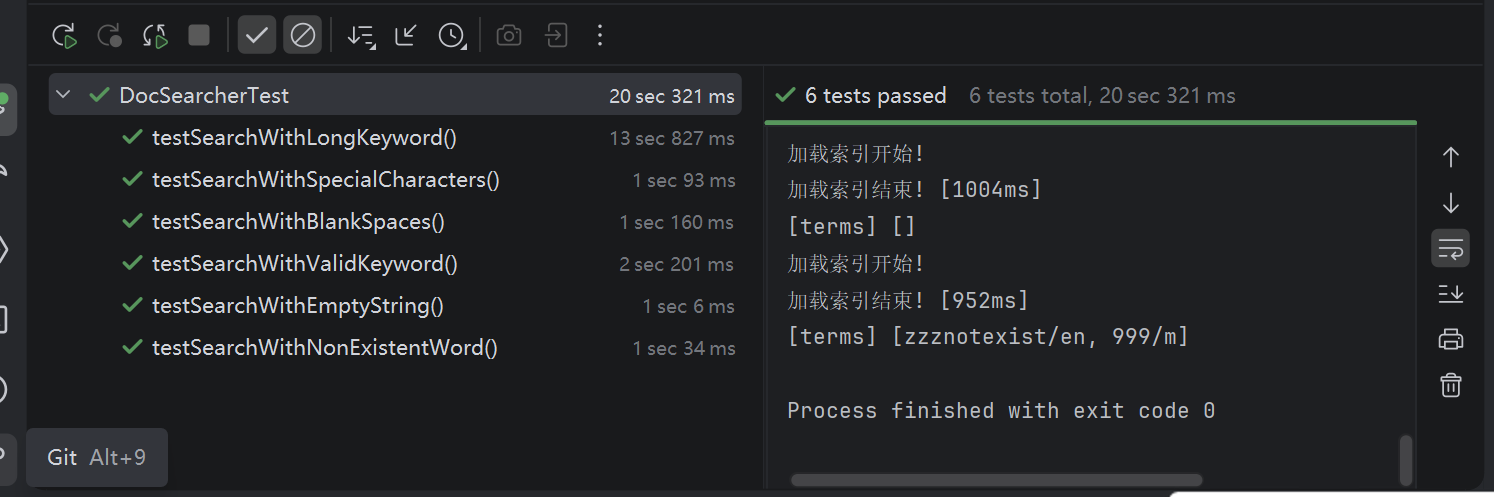
2、测试过程中发现并修复的问题
测试过程中发现部分异常输入(中文、特殊字符、空值、超长关键词)处理不够完善,已通过增加参数校验、长度限制和友好提示等方式修复。修复后全部测试用例通过。
(1)特殊/空白输入导致404错误
问题描述:输入为空、空格或特殊字符(如 #@$%)时,后端返回 404,未做友好提示。
原因分析:接口未对参数进行有效性校验。
修复措施:在搜索接口入口增加参数校验,无效输入返回空结果和提示信息。
(2)超长关键词未提示
问题描述:输入连续 300 个字符时,程序仍正常搜索,未提示“关键词过长”。
修复措施:增加长度判断,超过 100 字符时返回空结果并给出提示。
六、测试结论与后续优化
1、测试结论
本次测试共执行 20 条手工测试用例 和 6 条自动化测试用例,覆盖功能、界面、性能、兼容性四大模块。测试结果如下:
功能测试:11条用例全部通过,搜索准确性、结果展示、异常处理均符合预期。
界面测试:5条用例全部通过,布局合理、交互反馈正常、响应式良好。
性能测试:在 10228 份文档下,平均响应时间 < 1500ms,满足预期。
兼容性测试:Chrome 和 Edge 浏览器下功能正常,布局无错乱。
总体评估:项目核心功能完整,异常处理完善,性能达标,已达到小型文档搜索引擎的交付标准。
2、后续优化
虽然当前版本已满足基本需求,但后续可继续完善以下方向:
中文搜索支持:当前分词器已支持中文,但文档集为英文,后续可切换中文文档集以充分利用该能力。
自动化测试增强:补充 API 层的 MockMvc 集成测试和前端 Selenium 回归测试。
部署上线:将项目部署到云服务器,提供公网访问链接,并补充网络延迟等环境下的性能测试。
更多推荐
 12
12 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)