
【Python系列课程】NumPy数组计算(上):创建、索引与形状操作
·
📊 阅读时长:20分钟 | 关键词:NumPy、数组创建、数据类型、形状操作、索引切片
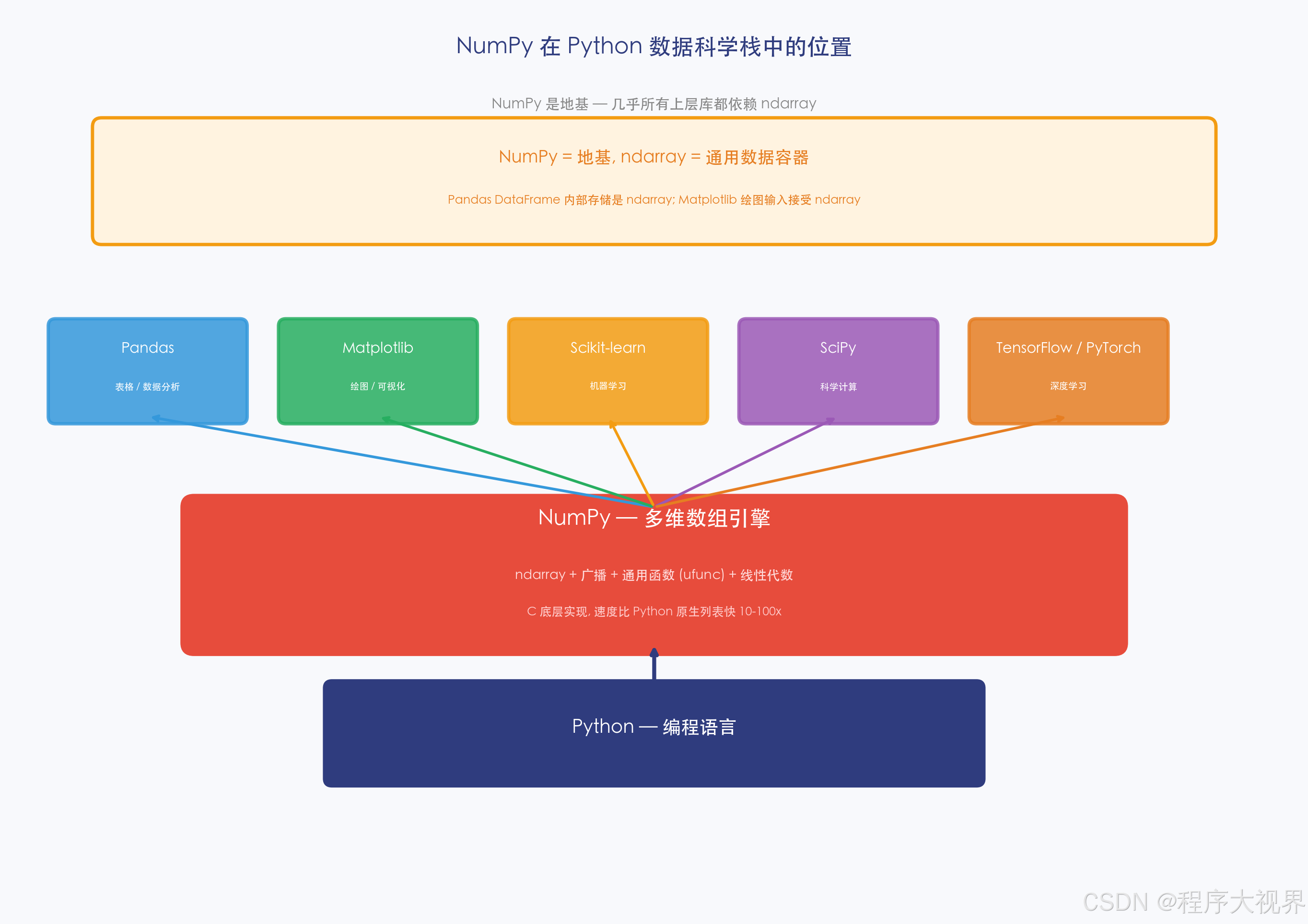
引言:为什么需要 NumPy?
Python 的列表已经很强大了——那为什么还需要 NumPy 的数组?
如果你用 Python 列表做这个操作:
# 用列表计算:每个数的平方
lst = [1, 2, 3, 4, 5]
result = []
for x in lst:
result.append(x ** 2)
# 用 NumPy 计算:一行搞定
import numpy as np
arr = np.array([1, 2, 3, 4, 5])
result = arr ** 2
NumPy 的优势还不止于此:
| 对比维度 | Python 列表 | NumPy 数组 |
|---|---|---|
| 存储效率 | 每个元素是独立对象,内存开销大 | 连续内存块,数据类型统一,内存小 |
| 计算速度 | 逐元素 Python 循环,慢 | C 语言底层实现,向量化运算,快 10~100 倍 |
| 功能丰富度 | 基本的增删改查 | 线性代数、傅里叶变换、随机数等 |
一句话:只要你做数据分析、机器学习、科学计算,NumPy 是绕不过去的基础。
一、安装和导入
1.1 安装
pip install numpy
# 国内推荐用清华镜像
pip install numpy -i https://pypi.tuna.tsinghua.edu.cn/simple
1.2 导入惯例
import numpy as np # 业界标准写法,永远用 np 作为别名
二、创建数组:从零到一
2.1 np.array():最核心的创建方式
import numpy as np
# 从列表创建一维数组
arr1 = np.array([1, 2, 3, 4, 5])
print(arr1) # [1 2 3 4 5]
print(type(arr1)) # <class 'numpy.ndarray'>
# 从嵌套列表创建二维数组
arr2 = np.array([[1, 2, 3], [4, 5, 6]])
print(arr2)
# [[1 2 3]
# [4 5 6]]
# 指定数据类型
arr3 = np.array([1, 2, 3], dtype=np.float64)
print(arr3.dtype) # float64
关键:NumPy 数组中的所有元素必须是同一种数据类型。这是它比列表快的重要原因之一。
2.2 常用创建函数速查表
| 函数 | 功能 | 示例 |
|---|---|---|
np.array() |
从现有数据创建 | np.array([1,2,3]) |
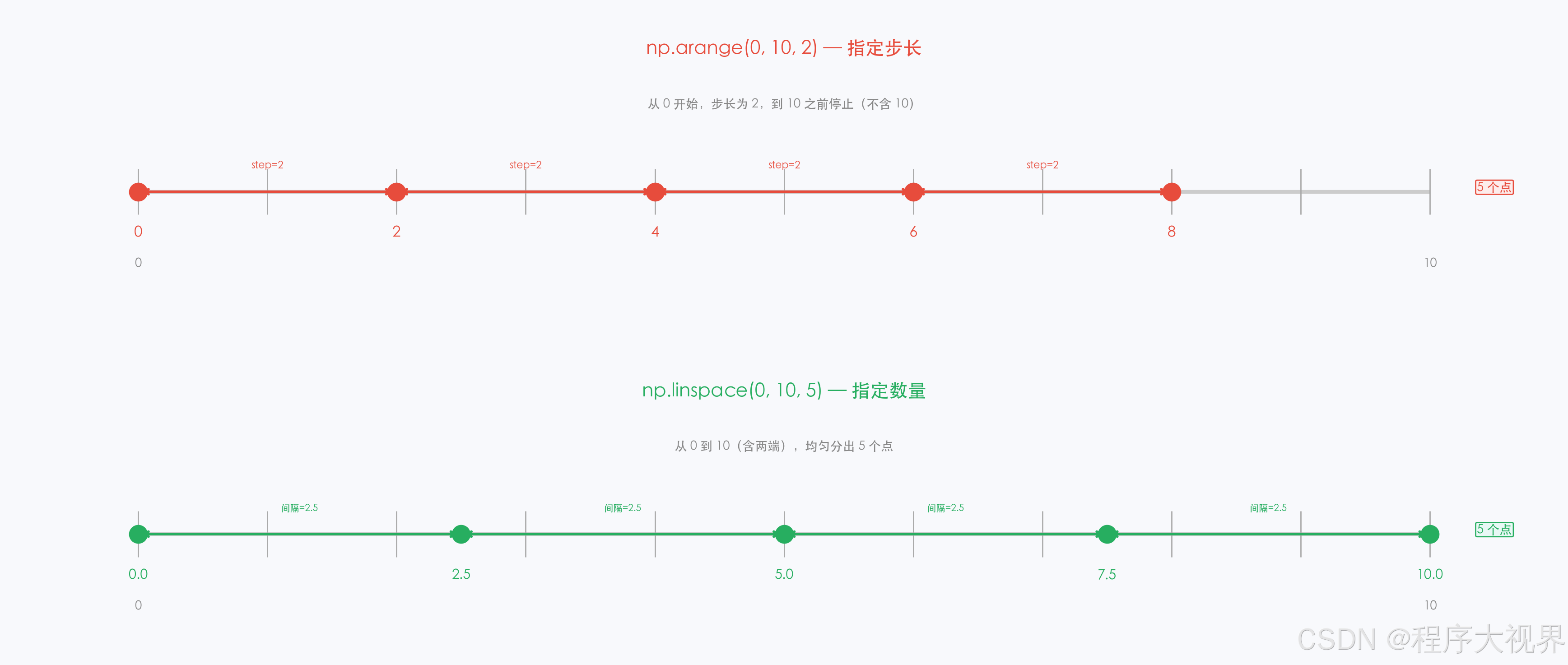
np.arange(start, stop, step) |
类似 range,返回数组 | np.arange(0, 10, 2) → [0 2 4 6 8] |
np.linspace(start, stop, num) |
等间隔取 num 个点 | np.linspace(0, 1, 5) → [0. 0.25 0.5 0.75 1. ] |
np.zeros(shape) |
全 0 数组 | np.zeros((2,3)) → 2行3列全0 |
np.ones(shape) |
全 1 数组 | np.ones((2,3)) → 2行3列全1 |
np.eye(N) |
N×N 单位矩阵 | np.eye(3) → 3×3单位矩阵 |
np.random.rand(shape) |
0~1 均匀分布随机数 | np.random.rand(2,3) |
np.random.randn(shape) |
标准正态分布随机数 | np.random.randn(2,3) |
import numpy as np
# arange:指定步长
print(np.arange(0, 10, 2)) # [0 2 4 6 8]
# linspace:指定点数(端点默认包含)
print(np.linspace(0, 1, 5)) # [0. 0.25 0.5 0.75 1. ]
# 重塑形状
arr = np.arange(12)
print(arr.reshape((3, 4)))
# [[ 0 1 2 3]
# [ 4 5 6 7]
# [ 8 9 10 11]]
三、数组属性:读懂一个数组
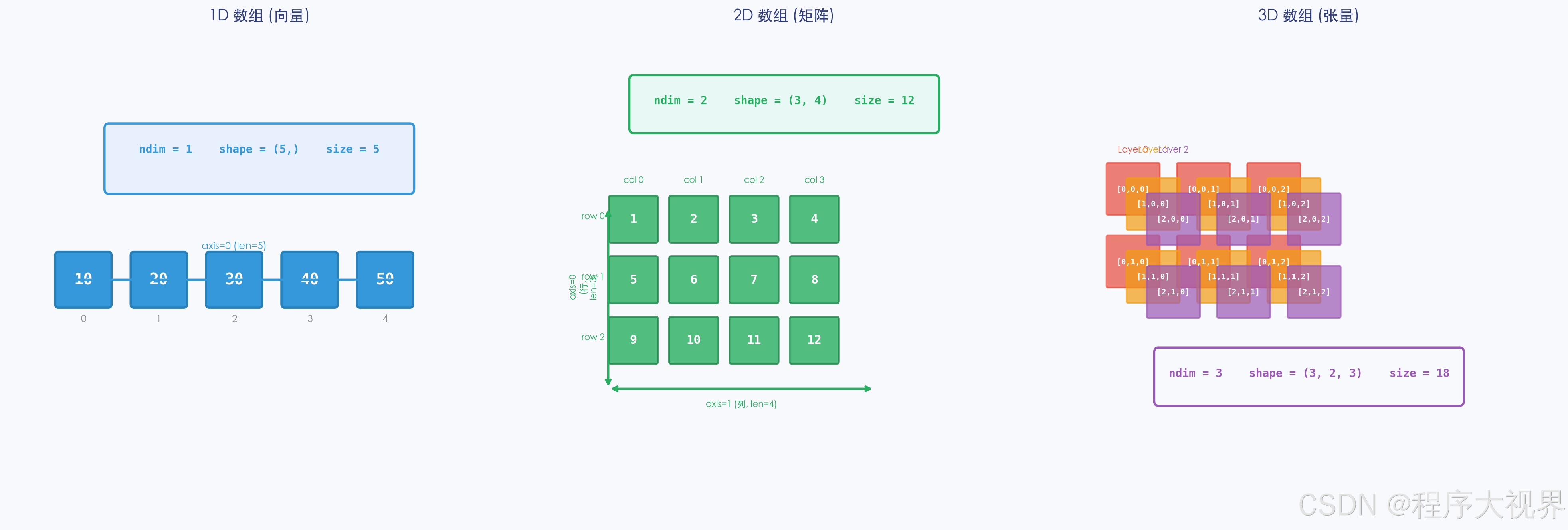
import numpy as np
arr = np.array([[1, 2, 3], [4, 5, 6]])
print(arr.ndim) # 2 → 维度(轴的数量)
print(arr.shape) # (2, 3) → 形状(每个轴的长度)
print(arr.size) # 6 → 总元素个数
print(arr.dtype) # int64 → 数据类型
print(arr.itemsize) # 8 → 每个元素的字节数
| 属性 | 含义 | 示例(shape=(2,3,4)) |
|---|---|---|
ndim |
维度数(秩) | 3 |
shape |
各维度大小 | (2, 3, 4) |
size |
元素总数 | 2×3×4 = 24 |
dtype |
元素数据类型 | int64 / float32 等 |
四、数据类型(dtype):省内存 = 省时间
NumPy 支持比 Python 更细粒度的数据类型,合理选择可以大幅减少内存占用。
| 类型 | 含义 | 字节数 | 适用场景 |
|---|---|---|---|
np.int8 |
8位有符号整数 | 1 | 图像像素(0~255) |
np.int32 |
32位有符号整数 | 4 | 默认整数(一般够用) |
np.int64 |
64位有符号整数 | 8 | 大数计算 |
np.float32 |
32位单精度浮点 | 4 | 深度学习(省显存) |
np.float64 |
64位双精度浮点 | 8 | 默认浮点(精度高) |
np.bool_ |
布尔值 | 1 | 掩码、条件索引 |
np.str_ |
字符串 | 变长 | 不推荐(用 Pandas) |
import numpy as np
# 默认 dtype(根据系统自动选)
arr1 = np.array([1, 2, 3])
print(arr1.dtype) # int64(64位系统)
# 指定 dtype(显式控制)
arr2 = np.array([1, 2, 3], dtype=np.float32)
print(arr2.dtype) # float32
# 类型转换
arr3 = arr1.astype(np.float64)
print(arr3.dtype) # float64
省内存小技巧:
import numpy as np
# 图像像素值 0~255,用 int8 就够了!
pixels = np.array([255, 128, 0, 64], dtype=np.uint8)
print(pixels.nbytes) # 4 字节(如果用 int64 要 32 字节)
# 深度学习推理时用 float32,比 float64 省一半显存
weights = np.random.rand(1000, 1000).astype(np.float32)
五、形状操作:给数组"整形"
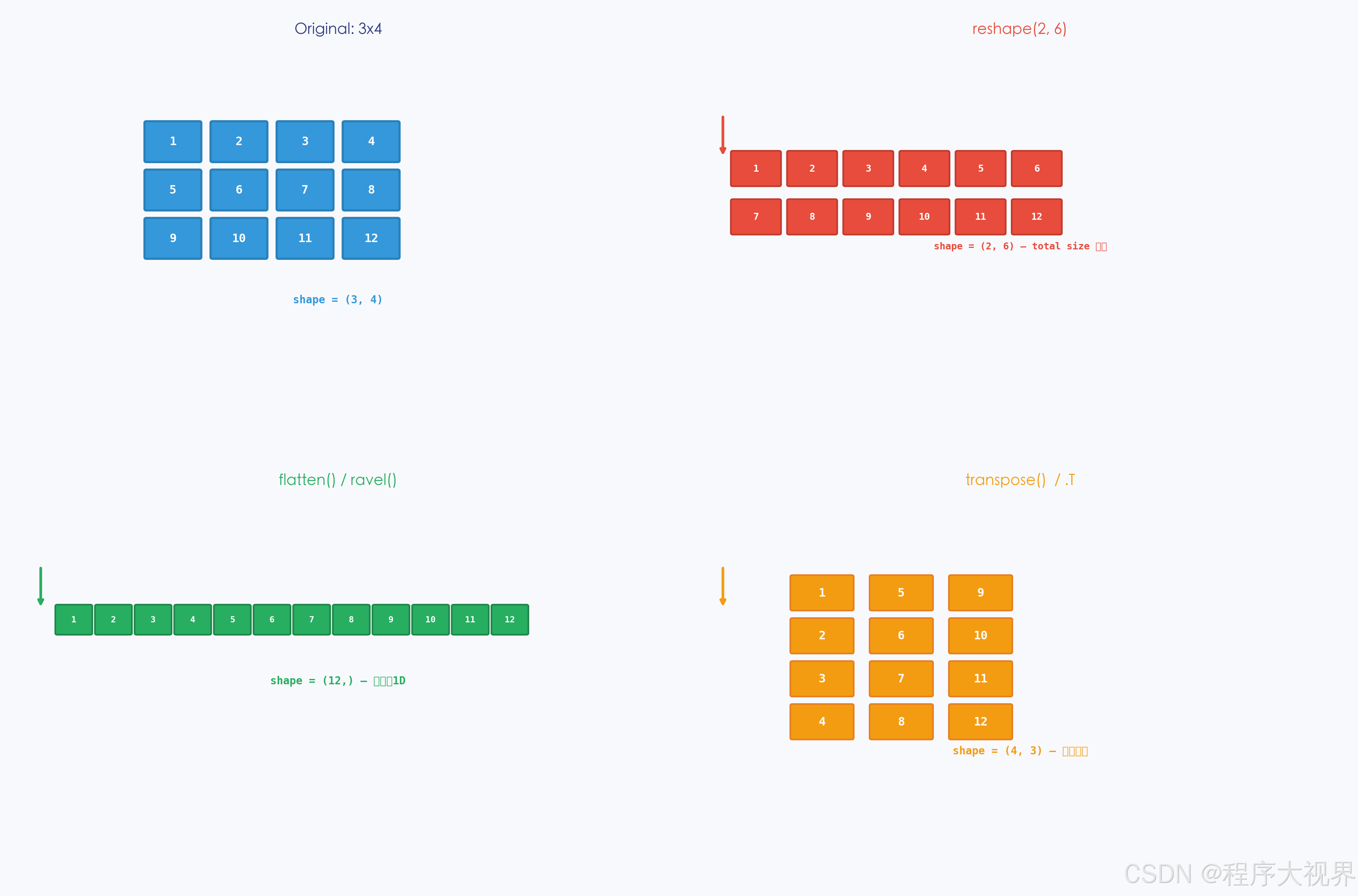
5.1 reshape():改变形状,不改变数据
import numpy as np
arr = np.arange(12)
print(arr.reshape((3, 4)))
# [[ 0 1 2 3]
# [ 4 5 6 7]
# [ 8 9 10 11]]
# -1 让 NumPy 自动推断该维度大小
print(arr.reshape((3, -1))) # 等同于 (3, 4),因为 12/3=4
print(arr.reshape((-1, 2))) # 等同于 (6, 2),因为 12/2=6
重要:reshape 不改变原数组,而是返回一个新的视图(如果可能的话)。
5.2 flatten() vs ravel():扁平化
import numpy as np
arr = np.array([[1, 2], [3, 4]])
# flatten():返回副本(修改不影响原数组)
flat1 = arr.flatten()
flat1[0] = 999
print(arr[0, 0]) # 1(原数组未改变)
# ravel():返回视图(修改会影响原数组)
flat2 = arr.ravel()
flat2[0] = 999
print(arr[0, 0]) # 999(原数组被改变了!)
| 方法 | 返回类型 | 修改是否影响原数组 | 速度 |
|---|---|---|---|
flatten() |
副本 | ❌ 不影响 | 稍慢(需要复制) |
ravel() |
视图(尽量) | ✅ 可能影响 | 更快(尽量不复制) |
5.3 转置:.T 或 transpose()
import numpy as np
arr = np.array([[1, 2, 3], [4, 5, 6]])
print(arr.T)
# [[1 4]
# [2 5]
# [3 6]]
# 高维数组的 transpose(指定轴的顺序)
arr3d = np.arange(24).reshape((2, 3, 4))
print(arr3d.transpose((2, 0, 1)).shape) # (4, 2, 3)
六、索引和切片:比列表更强大
6.1 一维数组的索引切片(和列表几乎一样)
import numpy as np
arr = np.arange(10) # [0 1 2 3 4 5 6 7 8 9]
print(arr[0]) # 0
print(arr[-1]) # 9
print(arr[2:5]) # [2 3 4]
print(arr[:5]) # [0 1 2 3 4]
print(arr[::2]) # [0 2 4 6 8]
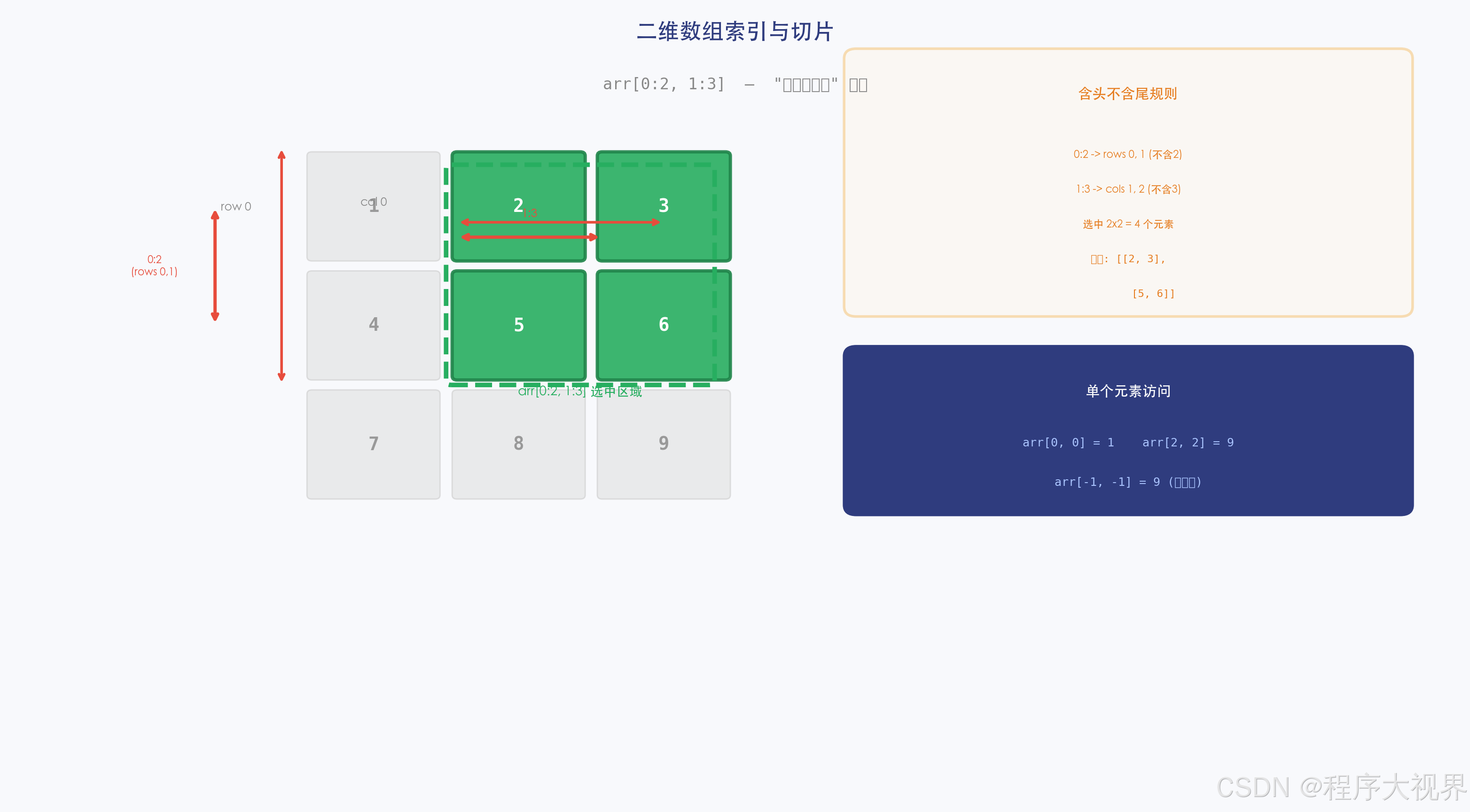
6.2 二维数组的索引切片(核心重点!)
import numpy as np
arr = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
# 形状:(3, 3)
# 行索引:0,1,2
# 列索引:0,1,2
# 方式一:用逗号分隔(推荐!)
print(arr[0, 1]) # 2 → 第0行第1列
print(arr[1, :]) # [4 5 6] → 第1行所有列
print(arr[:, 2]) # [3 6 9] → 所有行第2列
# 方式二:用多个 [](不推荐,冗长)
print(arr[0][1]) # 2
# 同时切行和切列
print(arr[0:2, 1:3])
# [[2 3]
# [5 6]]
6.3 布尔索引(超级实用!)
import numpy as np
arr = np.array([3, 7, 2, 9, 5])
# 条件过滤:选出所有 > 5 的元素
mask = arr > 5
print(mask) # [False True False True False]
print(arr[mask]) # [7 9]
# 一行搞定
print(arr[arr > 5]) # [7 9]
print(arr[(arr > 3) & (arr < 8)]) # [7 5] → 注意要用 & 不是 and!
# 复杂条件(用括号!)
condition = (arr > 3) | (arr == 2) # 大于3 或者等于2
print(arr[condition]) # [3 7 2 9 5]
⚠️ 超级大坑:布尔索引中必须用位运算符(& | ~),不能用逻辑运算符(and or not)!
# ❌ 错误写法(会报错或结果不对)
# print(arr[arr > 3 and arr < 8]) # ValueError!
# ✅ 正确写法
print(arr[(arr > 3) & (arr < 8)]) # [7 5]
6.4 花式索引(用整数数组来索引)
import numpy as np
arr = np.array([10, 20, 30, 40, 50])
# 用整数列表/数组来取元素
print(arr[[0, 2, 4]]) # [10 30 50]
print(arr[np.array([1, 3, 0]]) # [20 40 10]
# 二维花式索引
arr2d = np.array([[1, 2], [3, 4], [5, 6]])
print(arr2d[[0, 2], [0, 1]]) # [1 6] → 取 (0,0) 和 (2,1)
七、动手练习
练习 1:用 NumPy 计算均方误差(MSE)
均方误差是机器学习中最常用的损失函数,公式为:
MSE=1n∑i=1n(ypred−ytrue)2\text{MSE} = \frac{1}{n}\sum_{i=1}^{n}(y_{pred} - y_{true})^2MSE=n1i=1∑n(ypred−ytrue)2
请不要用循环,用 NumPy 向量化运算一行写出:
import numpy as np
y_true = np.array([3.0, 2.5, 4.0, 5.0])
y_pred = np.array([2.8, 2.7, 3.9, 5.2])
# 在这里写你的代码(提示:用 np.mean() 和 ** 运算符)
mse = None # 替换成你的代码
print(f"MSE = {mse:.4f}") # 期望输出:MSE = 0.0475
练习 2:图片像素值归一化
import numpy as np
# 模拟一张 2×2 的灰度图片,像素值范围 0~255
img = np.array([[120, 200], [80, 255]], dtype=np.uint8)
# 请将像素值归一化到 0~1 范围(公式:pixel / 255.0)
# 注意:必须先转换成 float,否则整数除法会截断!
img_normalized = None # 替换成你的代码
print(img_normalized)
print(img_normalized.dtype) # 应该是 float64 或 float32
练习 3:布尔索引实战——找出所有不及格的分数
import numpy as np
scores = np.array([85, 92, 58, 73, 45, 99, 61])
# 1. 找出所有不及格(< 60)的分数
failing = None # 替换
print(f"不及格分数:{failing}")
# 2. 把这些不及格的分数改成 60(补考及格线)
# 在这里写代码(提示:用布尔索引作为左值)
print(f"补考后:{scores}")
小结
今天这篇文章,我们搞定了 NumPy 的基础核心:
| 知识点 | 一句话总结 |
|---|---|
| 为什么用 NumPy | 快(C 底层)、省内存(统一 dtype)、功能强 |
| 创建数组 | array() 从现有数据;arange()/linspace() 快速生成序列 |
| 数组属性 | ndim(维度数)、shape(形状)、dtype(数据类型) |
| 数据类型 | 合理选 dtype 能省大量内存;用 astype() 转换 |
| 形状操作 | reshape() 整形;flatten()/ravel() 扁平化;.T 转置 |
| 索引切片 | 逗号分隔多维索引 arr[i, j];布尔索引超实用 |
| 大坑预警 | 布尔索引中用 & ` |
下一篇文章,我们将深入 NumPy 的向量化运算、广播机制、聚合函数——这些是 NumPy 真正强大的地方,也是 Pandas 的底层基础。
本文是「Python从入门到数据分析」系列的第 16 篇,共 24 篇。关注我,不错过后续更新。
更多推荐
 10
10 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)