
python文件的数据处理
代码分析:
if not line.strip(): # 跳过空行
continue
这行代码的意思是:如果一行全是空白(空行或者只有空格/制表符),就跳过这一行,不处理。
1. line.strip()
strip() 方法会去掉字符串开头和结尾的空白字符(空格、换行\n、制表符\t等)。
python
line = " hello " line.strip() # 结果是 "hello" line = " \n\t " line.strip() # 结果是 ""(空字符串) line = "\n" line.strip() # 结果是 ""(空字符串)
2. if not line.strip():
not 表示取反。当 line.strip() 的结果是空字符串时,条件为 True。
python
# 空字符串在布尔值中是 False
bool("") # 结果是 False
# not False = True,所以会执行 continue
3. continue
continue 的意思是:跳过本次循环的剩余代码,直接进入下一次循环。
line.strip() 的结果是空字符串时,又因为空字符串在布尔值中是 False,所以才要取反。
逻辑推导:
-
line.strip()结果是空字符串"" -
空字符串在布尔值中是
False -
not False=True
# 写法1:显式判断是否为空字符串
if line.strip() == "":
continue
# 写法2:判断字符串长度是否为0
if len(line.strip()) == 0:
continue
但 if not line.strip(): 是 Python 中更简洁、更Pythonic的写法。
·································································································································
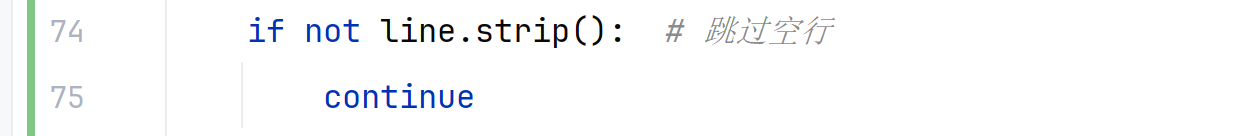
bill.txt 文件内容是这样的:
text
name, date, money, type, remarks 周杰轮, 2022-01-01, 100000, 消费, 正式 周杰轮, 2022-01-02, 300000, 收入, 正式
每一列是用逗号 , 分隔的,所以需要按逗号来分割,才能取出每一列的数据。
line = "周杰轮, 2022-01-01, 100000, 消费, 正式" # 这里为字符串
parts = line.split(',') # 按逗号分割 # 转换为列表了
# 结果:['周杰轮', ' 2022-01-01', ' 100000', ' 消费', ' 正式']
# 索引0 索引1 索引2 索引3 索引4

1. len(parts) >= 5
parts 是按逗号分割后得到的列表。这个判断确保这一行至少有5列数据。
python
# 正常的一行:有5列
"周杰轮, 2022-01-01, 100000, 消费, 正式".split(',')
# 得到 ['周杰轮', ' 2022-01-01', ' 100000', ' 消费', ' 正式']
# len(parts) = 5 ✅
# 如果某行格式错误,只有3列
"周杰轮, 2022-01-01, 100000".split(',')
# 得到 ['周杰轮', ' 2022-01-01', ' 100000']
# len(parts) = 3 ❌ 不会执行后面的判断
为什么需要这个判断?
-
防止索引越界错误(
parts[4]要求列表至少有5个元素) -
如果文件格式有问题,这行会被保留(不会因为判断失败而报错)
2. parts[4].strip() == '测试'
| 部分 | 含义 |
|---|---|
parts[4] |
取第5列(索引从0开始:0姓名,1日期,2金额,3类型,4备注) |
.strip() |
去掉字符串首尾的空格 |
== '测试' |
判断是否等于"测试" |
python
# 例子 parts = ['周杰轮', ' 2022-01-01', ' 100000', ' 消费', ' 正式'] parts[4] # ' 正式' parts[4].strip() # '正式' '正式' == '测试' # False # 如果是测试数据 parts = ['林俊节', ' 2022-01-02', ' 100000', ' 消费', ' 测试'] parts[4] # ' 测试' parts[4].strip() # '测试' '测试' == '测试' # True
总结:
| 先按行分割,再按列分割 | ✅ 正确 | - |
| 按行分割是为了拿出每组数据 | ✅ 正确 | - |
| 按列分割是为了找出要的东西 | ✅ 正确 | - |
| 行列分割看文本格式 | ✅ 正确 | - |
| 操作后变列表,用索引访问 | ✅ 正确 | - |
| 字符串也能用索引访问 | ✅ 正确 | - |
| 行是按空格分割 | ❌ 错误 | 行是按换行符 \n 分割 |
| 数值太大不好才转列表 | ❌ 错误 | 转列表是为了取完整的一列,不是数值大小问题 |
对于文本取出得数据是否是完成的一列,这里要区别字符串与列表的一些使用索引情况的区别。
按行分割后(还没按列分割)
python
lines = [
"周杰轮, 2022-01-01, 100000, 消费, 正式", # 这是一个字符串
]
# 直接用索引
lines[0][0] # 结果是 '周' ← 只拿到第一个字符
lines[0][1] # 结果是 '杰' ← 只拿到第二个字符
lines[0][4] # 结果是 '轮' ← 还是只拿到一个字符
问题:我们想要的是"备注列"(正式/测试),而不是某个字符!
按列分割后
python
parts = lines[0].split(',') # 按逗号分割
# parts = ['周杰轮', ' 2022-01-01', ' 100000', ' 消费', ' 正式']
parts[0] # '周杰轮' ← 完整的姓名
parts[1] # ' 2022-01-01' ← 完整的日期
parts[4] # ' 正式' ← 完整的备注!
核心原因总结
| 操作 | 结果类型 | 索引访问的结果 |
|---|---|---|
| 只按行分割 | 字符串 | 只能拿到单个字符 |
| 行分割 + 列分割 | 列表 | 能拿到整列数据 |
python
# 只按行分割
行[0][4] → '轮' (第0行的第4个字符)
# 按行列分割
行[0].split(',')[4] → ' 正式' (第0行的第4列)
直观比喻
想象一个 Excel 表格:
text
| A | B | C | D | E | |---------|-------------|-------|-------|------| | 周杰轮 | 2022-01-01 | 100000| 消费 | 正式 |
-
只按行分割:相当于把整行当作文本
"周杰轮,2022-01-01,100000,消费,正式",用索引只能找到第几个字 -
再按列分割:相当于告诉程序"按逗号分开",就能拿到每个单元格的内容
结论
必须按列分割的原因:
因为我们要判断的是"备注列"的完整内容('正式'或'测试'),而不是这一行的第几个字符。
只有先按列分割成列表,才能通过索引(如 [4])拿到一整列的数据。
所以说虽然字符串已经按照行的方式分割后成为了一个列表,但是里边的元素还是按照字符串排放,用索引也只能取出单个字符,如果想要取出一组数据,就得再次分割为列表,之后取出的数据就是完成得数据。
其他常用"字符串→列表"的方法
| 需求 | 方法 | 示例 |
|---|---|---|
| 按行分割 | split('\n') |
"a\nb\nc".split('\n') → ['a','b','c'] |
| 按逗号分割 | split(',') |
"a,b,c".split(',') → ['a','b','c'] |
| 按空格分割 | split() |
"a b c".split() → ['a','b','c'] |
| 每个字符成列表 | list() |
list("abc") → ['a','b','c'] |
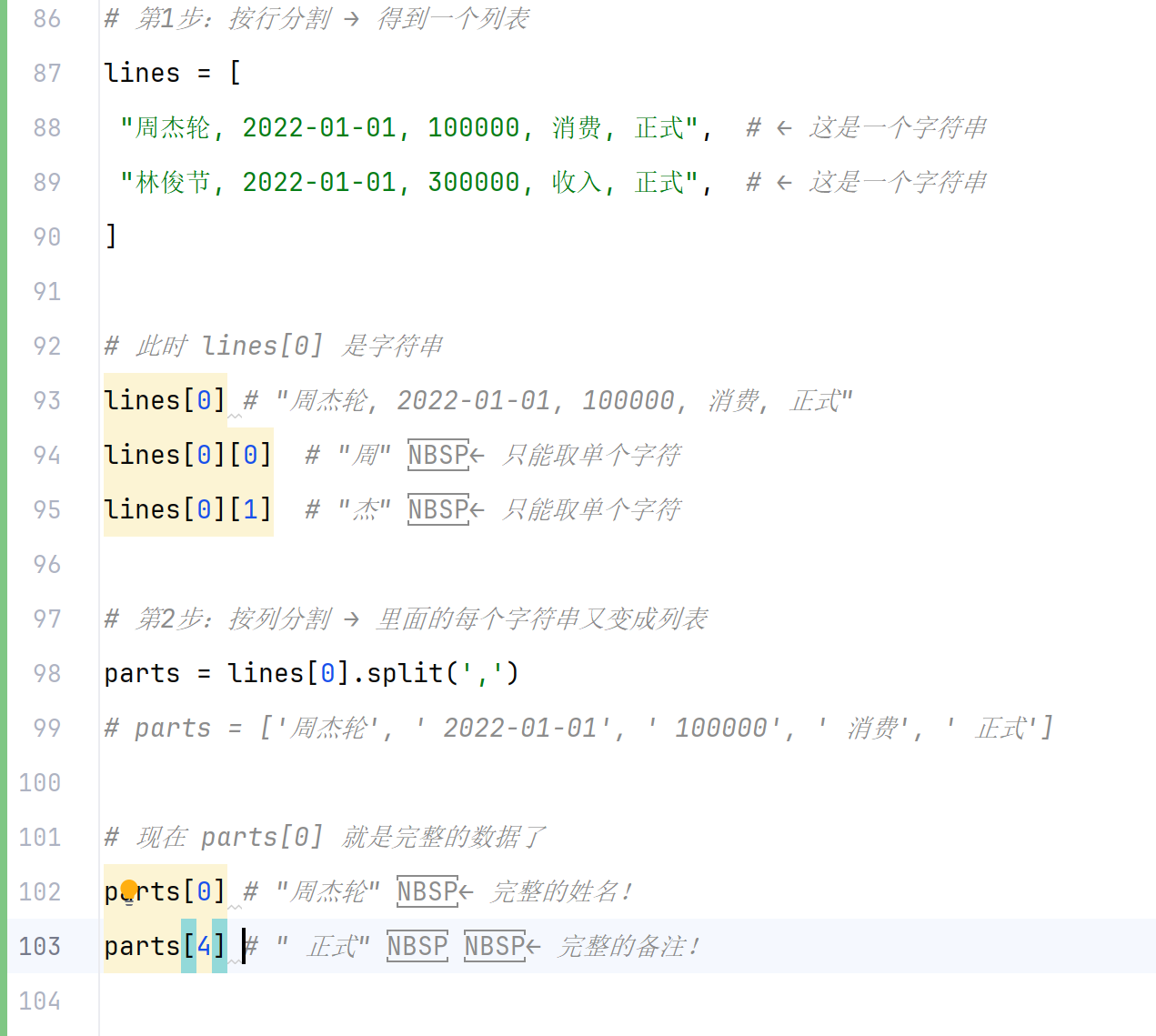
# 第1步:按行分割 → 得到一个列表
lines = [
"周杰轮, 2022-01-01, 100000, 消费, 正式", # ← 这是一个字符串
"林俊节, 2022-01-01, 300000, 收入, 正式", # ← 这是一个字符串
]
# 此时 lines[0] 是字符串
lines[0] # "周杰轮, 2022-01-01, 100000, 消费, 正式"
lines[0][0] # "周" ← 只能取单个字符
lines[0][1] # "杰" ← 只能取单个字符
# 第2步:按列分割 → 里面的每个字符串又变成列表
parts = lines[0].split(',')
# parts = ['周杰轮', ' 2022-01-01', ' 100000', ' 消费', ' 正式']
# 现在 parts[0] 就是完整的数据了
parts[0] # "周杰轮" ← 完整的姓名!
parts[4] # " 正式" ← 完整的备注!
一句话总结
行分割得到的是"字符串列表",列分割才能让每个字符串变成"数据列表",这样才能用索引取出完整的一列数据。
---------------------------------------------------------------------------------------------------------------------------------
对于读的操作分析:
| 方法 | 第一次调用 | 第二次调用 | 第二次调用的返回值 |
|---|---|---|---|
read() |
返回文件内容(字符串) | 返回 ""(空字符串) |
|
readlines() |
返回文件内容(列表) | 返回 [](空列表) |
|
readline() |
返回第一行(字符串) |
返回 |
如果需要多次使用文件内容,先赋值给变量:
python
f = open("bill.txt", 'r', encoding='utf-8')
content = f.read() # 存到变量
f.close()
# 之后可以无数次使用 content
print(content)
print(content) # 正常输出
print(content) # 正常输出
或者使用 with 语句(推荐):
python
with open("bill.txt", 'r', encoding='utf-8') as f:
content = f.read()
# 文件自动关闭,content 可以随便用
print(content)
print(content)
只要在赋值之前无输出,都不会改变,指针指向还是从头开始。只有"读取操作"会移动指针,赋值操作本身不会移动指针。
更多推荐


 9
9 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)