
Anthropic神话级模型解禁,发布Claude Fable 5!
刚刚,Anthropic 把那只传了好几个月的神话级 Claude放出来了。
名字也很有意思:Claude Fable 5。
Fable,寓言。
但它背后真正的影子,叫 Mythos,神话。
如果只看名字,它像是 Claude 家族新成员。但如果把背景、能力、安全机制和价格放在一起看,这次发布意义非凡!
性能上,毫无疑问的全方面大飞跃:
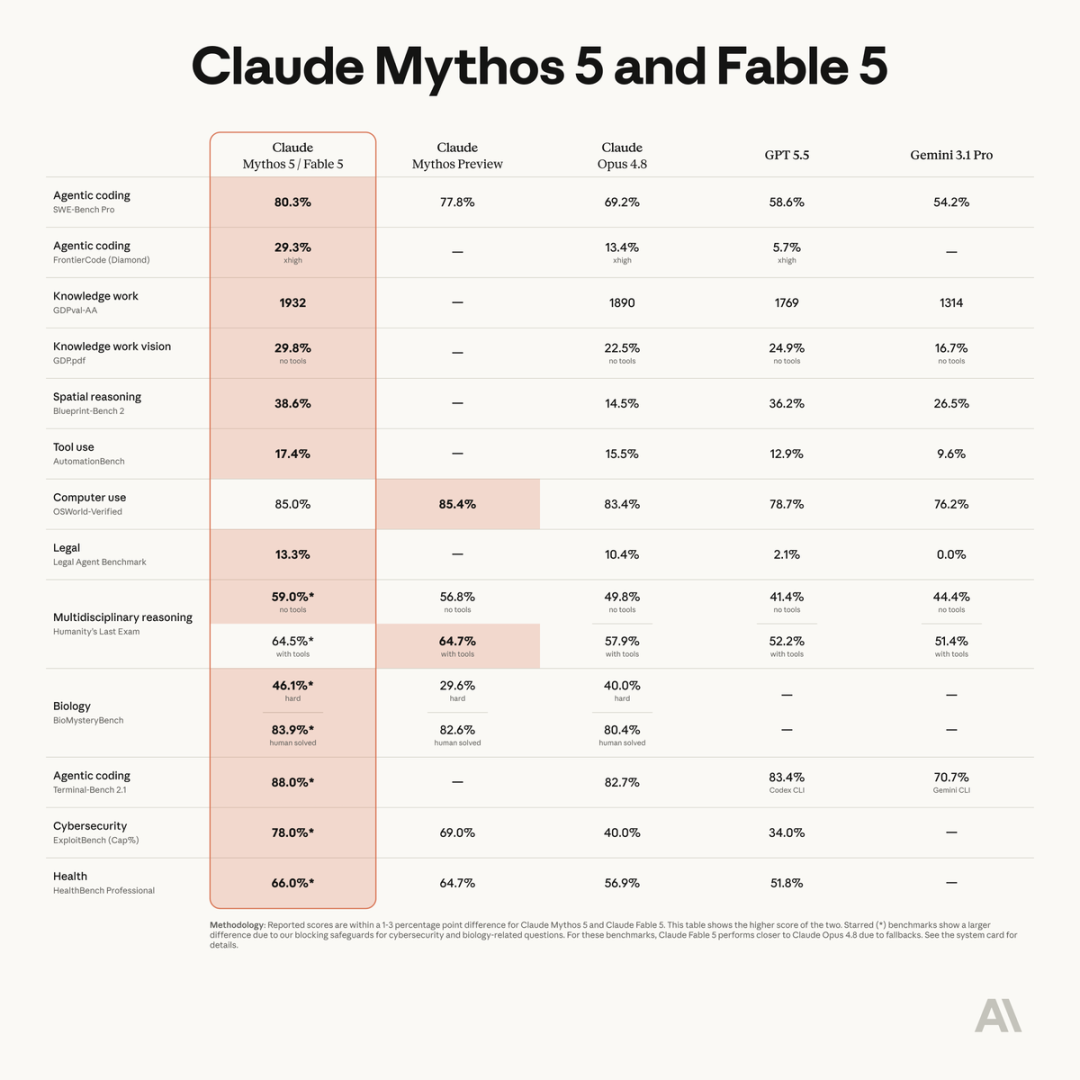
按照官方说法,它在软件工程、知识工作、视觉理解、科学研究等几乎所有测试领域都达到了最前沿水平。任务越长、越复杂,它相对之前 Claude 模型的优势越大。
不过,相比于Mythos 的完整版,Fable 只是一个「残缺」的公开版。
虽然底层能力接近,但 Fable 5 多了一套安全分类和模型路由机制。一旦请求涉及网络安全、生物化学风险、模型蒸馏等敏感方向,它就不会继续用 Fable 5 回答,而是自动切回 Claude Opus 4.8。
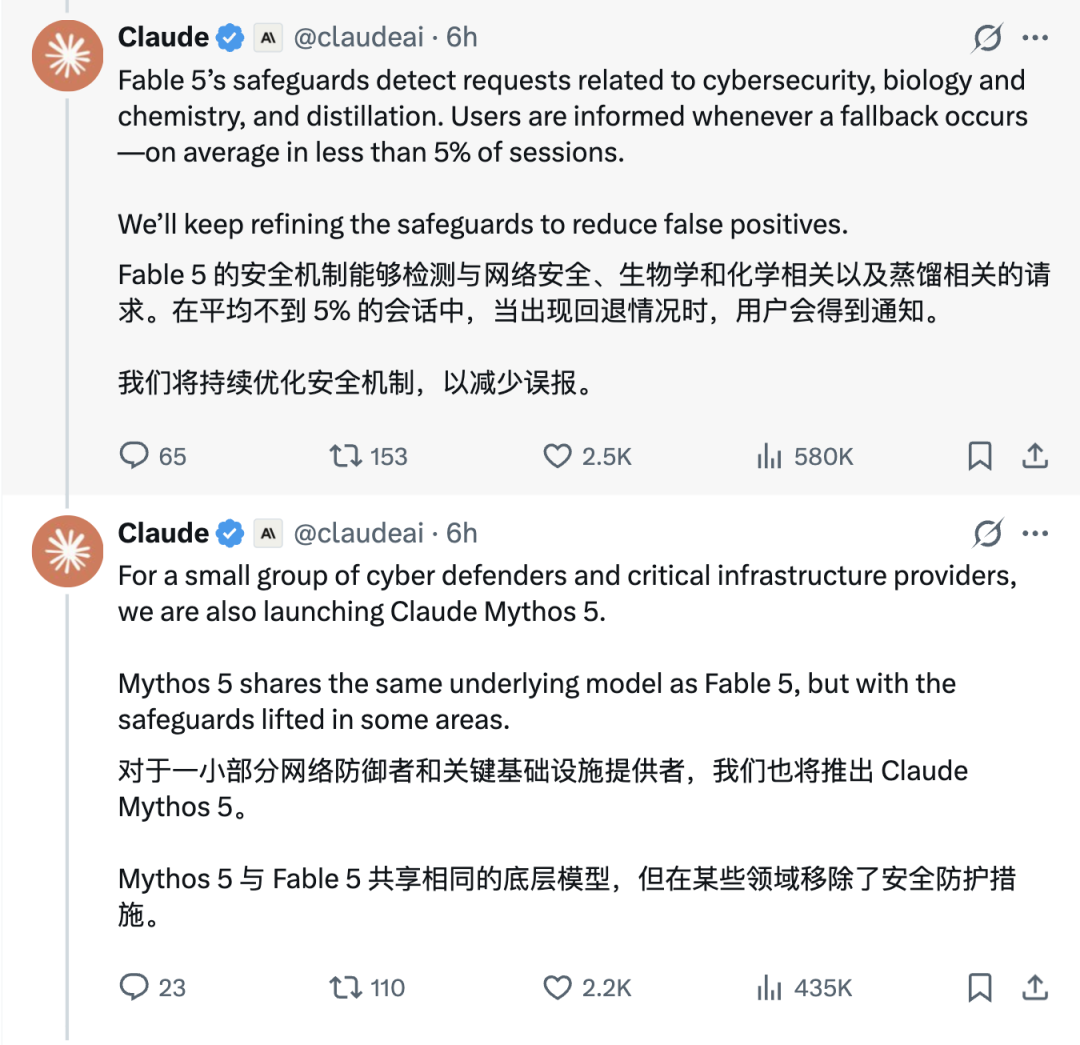
也就是说,普通用户这次确实摸到了 Mythos 级别的能力。
但只摸到了一部分。
大家等的是神话,Anthropic 最后交付的是一则被安全护栏包起来的寓言。
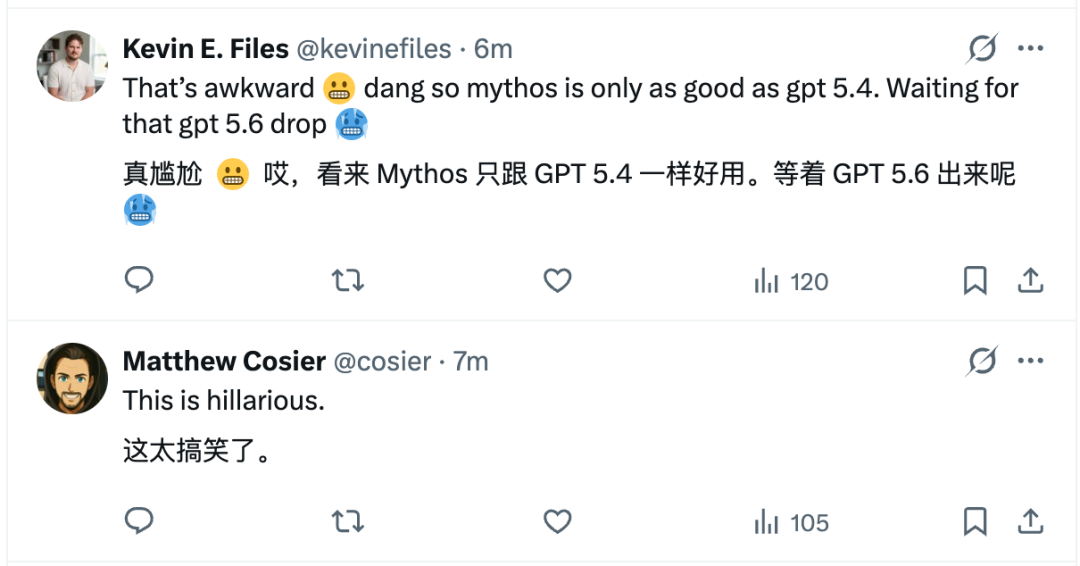
更有意思的是,Fable 这个名字刚出来,OpenAI 那边也有人下场玩梗了。
Codex 负责人Tibo 翻出自己 4 月的一条旧推,大意是:想象一下,如果我们把 GPT-5.4-Pro 命名成 Fable,会是什么画面。

现在 Anthropic 真的把 Mythos-class 的公开版叫成了 Claude Fable 5,这条旧推瞬间有了回旋镖效果。
评论区也开始阴阳怪气:有人说“这太搞笑了”,有人吐槽“尴尬,Mythos 看起来也就 GPT-5.4 水平,等 GPT-5.6 吧”。。
调侃归调侃,对普通 Claude 用户来说,这次还是很香。
如果你不用它做高风险网络安全、生物化学、模型蒸馏这些事情,Fable 5 大概率就是目前最强的公开 Claude。
一个词总结叫—代际提升。

Karpathy 的推文里有个说法我很认同:可以交给 AI 的任务边界,又被往外推了一圈。
作为 Claude Mythos Preview 的后代模型。从目前公开信息看,Fable 5 的优势主要集中在几个方向:
软件工程、复杂知识工作、视觉理解、长上下文、多步骤任务和科学研究。
但 Fable 5 真正拉开差距的地方,而是当任务变长、变量变多、目标变模糊时,它还能继续推进。
◈编程断档领先
Fable 5 最亮眼的场景,仍然是编程。
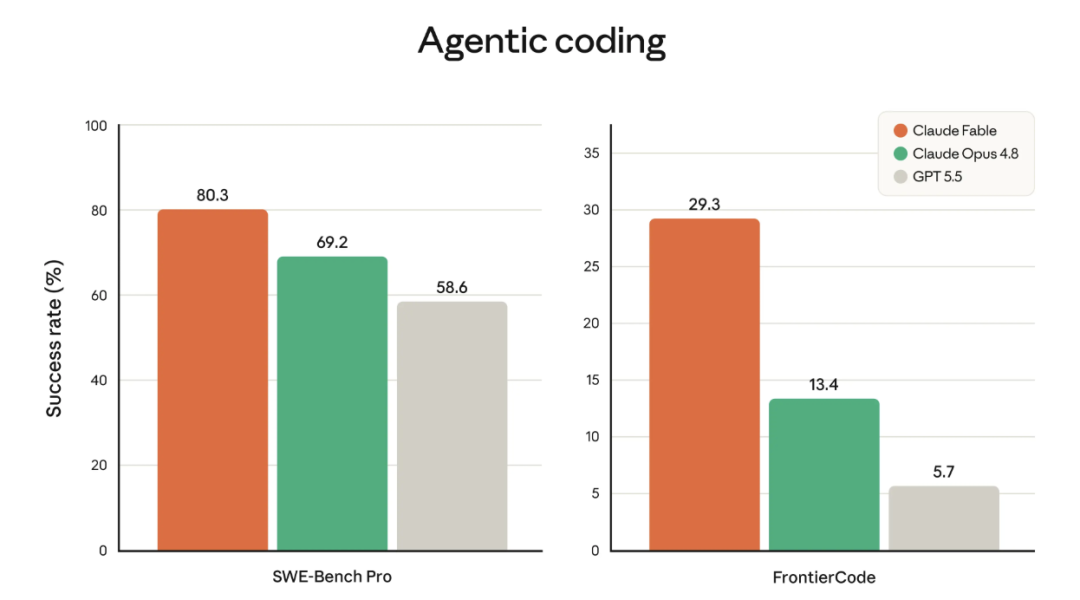
SWE-bench Pro 上 80.3%,Opus 4.8 是 69.2%,GPT-5.5 只有58.6%。
从Coding表中可以看到,真的完胜4.8和GPT。。
公开报道中提到,Stripe 曾用 Fable 5 在一个约 5000 万行 Ruby 代码库中完成全库迁移。这个工作如果由工程团队手动完成,通常可能需要数月,而 Fable 5 将其压缩到了极短时间内。
如果一个模型能在这种场景里稳定工作,哪怕只能承担其中一部分,也意味着软件开发的成本结构会继续被重写。
◈视觉:AI 开始真正“看懂屏幕”
另一个很有信号意义的能力,是视觉。
之前很多模型也能看图,但那种“看图”更多是识别图里有什么,或者回答图表上的问题。
而 Fable 5 可以把视觉信息当作行动依据。

在专注于视觉文件推理的基准测试GDPpdf上,Fable 5和Mythos 5在不借助外部工具的条件下拿到了29.8%的成绩,Opus 4.8得分为22.5%,GPT-5.5得分为24.9%,Gemini 3.1 Pro得分为16.7%。
Anthropic官方也猜大家看一堆数据很枯燥,于是放出了Fable 5打游戏的Demo,更具直接视觉效果。
此前的Claude模型如果想玩RPG游戏《宝可梦·火红版》,必须在外部为其配置一套极其复杂的“脚手架”(包括地图导航援助、内存游戏状态读取等)。
现在,Fable 5实现了纯粹的“原生视觉盲打”。
仅凭一张张原始的游戏屏幕截图,在没有任何地图外挂的前提下,它完全自主推演、策略规划,硬生生打通关了整部游戏。
真实世界里的软件,本来就是屏幕。
这也是为什么视觉能力和 Agent 能力会绑在一起。
未来很多 AI 助手,不会只是等你把资料复制粘贴给它,而是直接看你看到的界面,理解你正在做什么,然后继续往下干。
◈上下文与记忆:不会失忆,才配长期干活
这次升级的另一个重点,是长上下文和记忆。
官方说法:Fable 5 能在百万级 Token 的长期任务里保持专注,还会主动用自己记的笔记改进后续输出。
测试场景又是游戏——《杀戮尖塔》。接入持久化文件记忆后,Fable 5 的表现提升幅度是 Opus 4.8 的三倍,打到最终章节的频率同样翻了三倍。
顺着这条线,Anthropic 还反复强调了一个词:Token 效率。
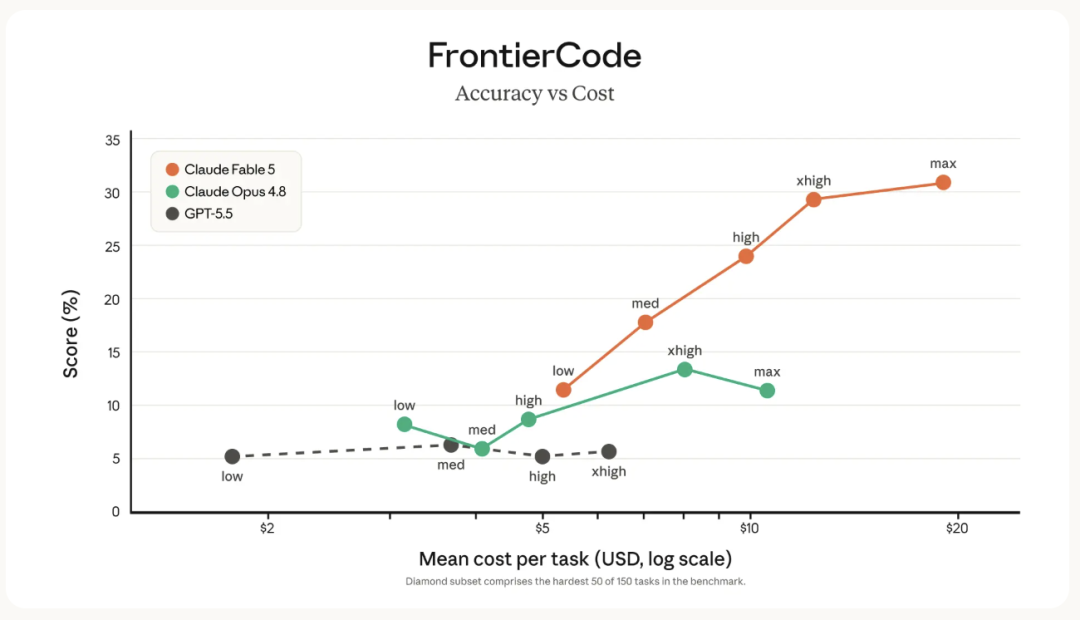
逻辑不复杂:越能长时间自主工作的模型,越烧 Token。一个模型如果一边很强、一边很"费话",账单很快会让企业肉疼。前面物理科研那个 case——只用 1/3 的推理 Token,36 小时追平对手四天的产出——讲的就是这件事。
说白了,强不强是技术问题,用不用得起是商业问题。Fable 5 把这两个问题一起答了。
◈前沿科研:藏着掖着的 Mythos,终于在这里现身
科研板块要分两层看:台前的 Fable 5,和幕后的 Mythos 5。
台前的部分:物理研究机构和初创公司 VibeCAD 测试显示,Fable 5 只用 1/3 的推理 Token,36 小时内产出的物理研究成果,逼近 GPT-5.5 四天的工作量。
而幕后那个一直没露面的满血版 Mythos 5,这次终于放了点战绩出来。
在生物医药领域,Mythos 5 已经能在零人类协助的情况下,独立跑完一个生物学家的完整工作流:自己选蛋白质结合位点,自己调度生物信息学工具,跑挂了自己 Debug。
它设计的 14 个蛋白质靶向复合物里,9 个已经进入实验室的真实药物研发管线。
盲测环节更直接:与 Opus 系列对比,科学家在 80% 的情况下更倾向 Mythos 给出的分子生物学假设。其中一个假设——关于大肠杆菌蛋白的一种新解毒机制——后来被另一家独立实验室的研究证实了。AI 提的科学假设,被人类实验室验证为真,这在以前是科幻小说的桥段。
最夸张的一条留在最后:基因组学研究中,Mythos 5 自主工作了一周多,整合 138 个物种的单细胞数据,然后自己设计、自己训练了一个定制的微型机器学习模型。这个由 AI 亲手训练出来、体积小 100 倍的小模型,表现直接击败了前不久刚发表在《Science》上的最新成果。
AI 不只在做科研,AI 开始造工具做科研了。
不过注意一个细节:以上 Mythos 5 的所有战绩,你都只能"听说"。
它至今只对 Project Glasswing 合作伙伴和特定生物学研究人员开放。最好的故事,发生在你进不去的房间里。
◈价格:强是真的强,贵也是真的贵
当然,说到这里必须泼一点冷水—Fable 5 不便宜。
公开价格是每百万输入 token 10 美元,每百万输出 token 50 美元。
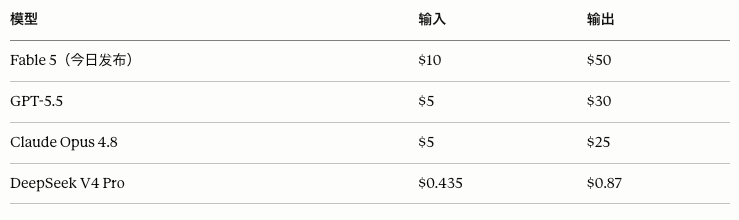
这价格是Opus标准版的两倍,不到Mythos Preview的一半,GPT-5.5 Pro的六分之一。
Ps:为了庆祝Fable5的发布,最近Claude重置了5小时和速率限制。
Mythos 是神话,Fable 是寓言。神话留在了只有巨头能进的房间里,寓言被包上护栏,交给了我们。
先在受控环境里验证,再把成熟的部分开放,这套节奏在前沿 AI 行业里,算是走出了一条新路子。
模型在分层,用户在分级,能力在分发。AI 行业花了三年时间回答“AI 能不能做”,而 Fable 5 发布这天,问题悄悄换了——
不是 AI 能不能做,是你被允许用它做什么。
这是更安全的必经之路,还是会带来新的不平衡?这个问题,留给时间。
更多推荐
 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)