
Java基础(3) | 集合框架:List、Set、Map 与队列全梳理
📚 本系列系统梳理了 Java 开发的详细知识点,从基础语法到工程实践层层递进,内容详实成体系,建议先收藏再慢慢阅读,方便日后随时回顾查阅。
前言
Java 的集合框架(Collections Framework)是日常开发中使用频率最高的 API,没有之一。这篇文章的目标是:快速回顾每种集合的用法,搞清楚它们之间的区别和选型依据。
1. 集合框架全景
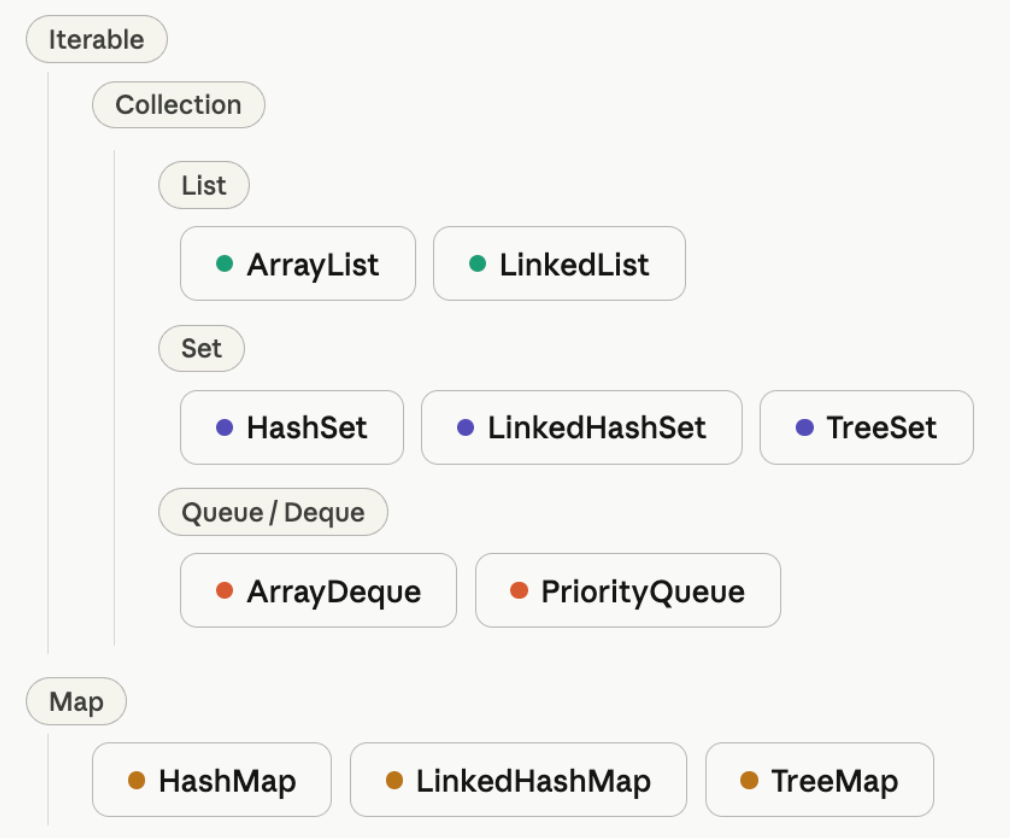
Java 集合的顶层接口分两条线:Collection(存储单个元素,下分 List、Set、Queue)和 Map(存储键值对,独立于 Collection 体系)。
Collection
├── List(有序,可重复)
│ ├── ArrayList
│ ├── LinkedList
│ └── Vector(遗留类,不推荐)
├── Set(无序,不可重复)
│ ├── HashSet
│ ├── LinkedHashSet
│ └── TreeSet
└── Queue(队列)
├── LinkedList
├── PriorityQueue
└── Deque
└── ArrayDeque
Map(键值对)
├── HashMap
├── LinkedHashMap
├── TreeMap
├── Hashtable(遗留类,不推荐)
└── ConcurrentHashMap
2. List:有序、可重复
2.1 ArrayList —— 最常用的列表
底层是动态数组,随机访问快,中间插入/删除慢。
List<String> list = new ArrayList<>();
// 增
list.add("a");
list.add("b");
list.add(1, "x"); // 在索引 1 插入,后面的元素后移
// 查
list.get(0); // "a"
list.indexOf("x"); // 1
list.contains("b"); // true
list.size(); // 3
// 改
list.set(0, "A"); // 将索引 0 的元素改为 "A"
// 删
list.remove(0); // 按索引删
list.remove("x"); // 按值删(只删第一个匹配的)
// 遍历
for (String s : list) {
System.out.println(s);
}
// 排序(均为原地排序)
list.sort(Comparator.naturalOrder()); // 升序
list.sort(Comparator.reverseOrder()); // 降序
Collections.sort(list); // 同 naturalOrder
list.sort((a, b) -> a.length() - b.length()); // 自定义比较
Collections.reverse(list); // 原地反转
// 构造(推荐写法,返回可变列表)
List<String> list2 = new ArrayList<>(Arrays.asList("a", "b", "c"));
// 注意:Arrays.asList("a","b","c") 单独使用返回固定长度列表,不能 add/remove
// List.of("a","b","c") 完全不可变,连 set 也不行
// 只有套上 new ArrayList<>() 才是完全可变的列表
// 拷贝
List<String> copy = new ArrayList<>(list); // 构造函数浅拷贝
2.2 LinkedList —— 链表实现
底层是双向链表,头尾操作快,随机访问慢(O(n) 需从头遍历)。同时实现了 List 和 Deque 接口,可当双端队列/栈使用,ArrayList 的方法全部可用。
LinkedList<String> list = new LinkedList<>();
// ArrayList 的方法全部可用
list.add("a");
list.get(0); // ⚠️ O(n),不推荐频繁使用
list.size();
list.contains("a");
list.remove(0);
// 头尾操作(O(1))
list.addFirst("x"); // 头插
list.addLast("z"); // 尾插
list.getFirst(); // 取头,空时抛异常
list.getLast(); // 取尾,空时抛异常
list.removeFirst(); // 删头,空时抛异常
list.removeLast(); // 删尾,空时抛异常
list.peekFirst(); // 取头但不删,空时返回 null
list.peekLast(); // 取尾但不删,空时返回 null
list.pollFirst(); // 取头并删除,空时返回 null
list.pollLast(); // 取尾并删除,空时返回 null
// 当队列用(FIFO)
list.offer("a"); // 尾部入队
list.peek(); // 查看队首,空时返回 null
list.poll(); // 取出队首并移除,空时返回 null
2.3 ArrayList vs LinkedList
| 操作 | ArrayList | LinkedList |
|---|---|---|
随机访问 get(i) |
O(1) | O(n) |
尾部添加 add(e) |
O(1) 均摊 | O(1) |
| 中间插入/删除 | O(n)(需要移动元素) | O(n)(需要先遍历定位) |
| 头部插入 | O(n) | O(1) |
| 内存 | 紧凑,缓存友好 | 每个节点额外存两个指针 |
结论:95% 的场景用 ArrayList。 LinkedList 只在频繁头部插入/删除且不需要随机访问时才考虑,实际项目中很少遇到。
3. Set:不可重复
3.1 HashSet —— 最常用的集合
底层是 HashMap(值都是同一个虚拟对象),无序,增删查都是 O(1)。
Set<String> set = new HashSet<>();
boolean ok = set.add("a"); // 添加成功返回 true,重复返回 false
set.add("b");
set.add("a"); // 重复元素,添加失败,set 仍为 {a, b}
set.size(); // 2
set.contains("a"); // true
set.remove("a");
// 遍历(顺序不确定)
for (String s : set) {
System.out.println(s);
}
// 集合运算
Set<String> a = new HashSet<>(Arrays.asList("a", "b", "c"));
Set<String> b = new HashSet<>(Arrays.asList("b", "c", "d"));
a.retainAll(b); // 交集,a 变为 {b, c}(原地)
a.addAll(b); // 并集,a 变为 {a, b, c, d}(原地)
a.removeAll(b); // 差集,a 变为 {a}(原地)
// 类型转换
Set<String> set = new HashSet<>(list); // List 去重
List<String> list = new ArrayList<>(set); // Set 转 List
// TreeSet:有序(自然排序),增删查 O(log n)
Set<String> tree = new TreeSet<>(); // 遍历时字母序输出
// LinkedHashSet:保持插入顺序,增删查 O(1)
Set<String> linked = new LinkedHashSet<>(); // 遍历时按插入顺序输出
关于
Set<String> set = new HashSet<>()的写法:
<String>是泛型,指定集合中元素的类型,编译器会做类型检查,避免运行时类型错误<>是菱形运算符,让编译器自动推断右边的泛型类型,无需重复写- 引用类型写
Set(接口)而非HashSet(实现类)是面向接口编程:以后想换成TreeSet或LinkedHashSet只改右边一处,其余代码不用动
3.2 LinkedHashSet —— 保留插入顺序
继承 HashSet,额外维护了一条双向链表记录插入顺序,遍历时按插入顺序输出。
Set<String> set = new LinkedHashSet<>();
set.add("c");
set.add("a");
set.add("c"); // 重复,忽略,顺序仍是 c, a
set.add("b");
// 遍历顺序:c, a, b(和插入顺序一致)
3.3 TreeSet —— 自动排序
底层是红黑树,元素始终有序,增删查都是 O(log n)。
Set<Integer> set = new TreeSet<>();
set.add(3);
set.add(1);
set.add(2);
// 遍历顺序:1, 2, 3(自然排序)
// 自定义排序
Set<String> set2 = new TreeSet<>((a, b) -> b.compareTo(a)); // 降序
// TreeSet 独有的范围操作
TreeSet<Integer> set = new TreeSet<>(Arrays.asList(1, 3, 5, 7, 9));
set.first(); // 1,最小值
set.last(); // 9,最大值
set.floor(6); // 5,≤6 的最大值
set.ceiling(6); // 7,≥6 的最小值
set.lower(5); // 3,<5 的最大值
set.higher(5); // 7,>5 的最小值
set.headSet(5); // [1, 3],小于 5 的子集
set.tailSet(5); // [5, 7, 9],大于等于 5 的子集
set.subSet(3, 7); // [3, 5],[3, 7) 的子集
3.4 三种 Set 对比
| 特性 | HashSet | LinkedHashSet | TreeSet |
|---|---|---|---|
| 底层结构 | 哈希表 | 哈希表 + 链表 | 红黑树 |
| 顺序 | 无序 | 插入顺序 | 自然/自定义排序 |
| 时间复杂度 | O(1) | O(1) | O(log n) |
| null 值 | 允许一个 | 允许一个 | 不允许(无法比较) |
4. Map:键值对
4.1 HashMap —— 最常用的映射
底层是数组 + 链表 + 红黑树(链表长度 > 8 时转红黑树),无序,增删查 O(1)。
Map<String, Integer> map = new HashMap<>();
// 增 / 改
map.put("Alice", 90);
map.put("Bob", 85);
map.put("Alice", 95); // key 重复,覆盖旧值
// 查
map.get("Alice"); // 95
map.get("nobody"); // null
map.getOrDefault("nobody", 0); // 0(key 不存在时返回默认值)
map.containsKey("Bob"); // true
map.containsValue(85); // true
map.size(); // 2
// 删
map.remove("Bob");
// 遍历
for (Map.Entry<String, Integer> entry : map.entrySet()) {
System.out.println(entry.getKey() + " = " + entry.getValue());
}
// lambda 写法(Java 8+)forEach
map.forEach((k, v) -> System.out.println(k + " = " + v));
// 只遍历 key 或 value,两者都是视图,不是拷贝——修改原 map 会影响它们,直接在上面 remove 也会影响原 map。
for (String key : map.keySet()) { ... } // Set<String>
for (Integer val : map.values()) { ... } // Collection<Integer>
4.2 几个实用方法(Java 8+)
// putIfAbsent:key 不存在时才插入
map.putIfAbsent("Carol", 88);
// computeIfAbsent:key 不存在时用函数计算值并插入,常用于初始化嵌套结构
Map<String, List<String>> groups = new HashMap<>();
groups.computeIfAbsent("team1", k -> new ArrayList<>()).add("Alice");
// 等价于:
if (!groups.containsKey("team1")) {
groups.put("team1", new ArrayList<>());
}
groups.get("team1").add("Alice");
groups.computeIfAbsent("team1", k -> new ArrayList<>()).add("Bob");
// {"team1": ["Alice", "Bob"]}
// merge:合并值
map.merge("Alice", 5, Integer::sum); // Alice 的值 += 5
// 等价于:
if (!map.containsKey("Alice")) {
map.put("Alice", 5); // 不存在:直接插入
} else {
map.put("Alice", map.get("Alice") + 5); // 存在:用函数合并
}
// getOrDefault + 计数器模式
Map<Character, Integer> freq = new HashMap<>();
for (char c : "hello".toCharArray()) {
freq.merge(c, 1, Integer::sum);
}
// {h=1, e=1, l=2, o=1}
4.3 LinkedHashMap —— 保留插入顺序
和 LinkedHashSet 同理,底层在 HashMap 基础上额外维护一条双向链表,遍历时按插入顺序输出。还可以通过开启访问顺序模式实现 LRU 缓存:
// 构造参数:初始容量=16,负载因子=0.75(元素数超过 容量×0.75 时扩容),accessOrder=true(按访问顺序排列)
// accessOrder=false(默认):按插入顺序;accessOrder=true:每次 get 后该元素移到末尾
Map<String, Integer> lru = new LinkedHashMap<>(16, 0.75f, true) {
@Override
protected boolean removeEldestEntry(Map.Entry<String, Integer> eldest) {
return size() > 100; // 每次 put 后自动调用,返回 true 则淘汰头部(最久未访问的)
}
};
两个机制组合即构成完整的 LRU Cache:
accessOrder=true:最近访问的元素移到链表末尾,链表头部始终是最久未访问的removeEldestEntry:容量超限时自动淘汰头部元素
LeetCode 146(LRU Cache)用此写法可直接实现,无需手动维护双向链表。
4.4 TreeMap —— 按 key 排序
底层红黑树,key 始终有序,增删查 O(log n)。
Map<String, Integer> map = new TreeMap<>();
map.put("banana", 2);
map.put("apple", 5);
map.put("cherry", 1);
// 遍历顺序:apple, banana, cherry(按 key 字典序)
// 独有的范围操作
TreeMap<Integer, String> tm = new TreeMap<>();
tm.put(1, "a"); tm.put(3, "c"); tm.put(5, "e"); tm.put(7, "g");
tm.firstKey(); // 1
tm.lastKey(); // 7
tm.floorKey(4); // 3(<= 4 的最大 key)
tm.ceilingKey(4); // 5(>= 4 的最小 key)
tm.subMap(2, 6); // {3=c, 5=e}(左闭右开)
tm.headMap(4); // {1=a, 3=c},key < 4 的部分
tm.tailMap(4); // {5=e, 7=g},key >= 4 的部分
// 按 key 降序
Map<String, Integer> map = new TreeMap<>(Comparator.reverseOrder());
// 按 key 长度排序
Map<String, Integer> map = new TreeMap<>(Comparator.comparingInt(String::length));
4.5 三种 Map 对比
| 特性 | HashMap | LinkedHashMap | TreeMap |
|---|---|---|---|
| 底层结构 | 哈希表 | 哈希表 + 链表 | 红黑树 |
| 顺序 | 无序 | 插入/访问顺序 | key 排序 |
| 时间复杂度 | O(1) | O(1) | O(log n) |
| null key | 允许一个 | 允许一个 | 不允许 |
5. Queue 与 Deque
5.1 Queue —— 队列(FIFO)
Queue 是先进先出(FIFO)的线性结构,Java 中 Queue 是接口,常用实现有 LinkedList 和 ArrayDeque。
每个操作都有两个版本,区别在于失败时的行为:
| 操作 | 失败时抛异常 | 失败时返回特殊值 |
|---|---|---|
| 入队 | add(e) |
offer(e) → false |
| 出队 | remove() |
poll() → null |
| 查看队首 | element() |
peek() → null |
实际开发始终推荐用 offer / poll / peek,更安全。
// LinkedList 可用,但推荐 ArrayDeque(底层循环数组,无链表指针开销,性能更好)
Queue<String> queue = new ArrayDeque<>();
queue.offer("a"); // 入队,返回 false 表示失败(一般不会满)
queue.offer("b");
queue.offer("c");
queue.peek(); // "a"(查看队首,不移除,空时返回 null)
queue.poll(); // "a"(取出队首并移除,空时返回 null)
queue.size(); // 2
queue.isEmpty(); // false
除非需要存
null元素,否则优先用ArrayDeque而非LinkedList。
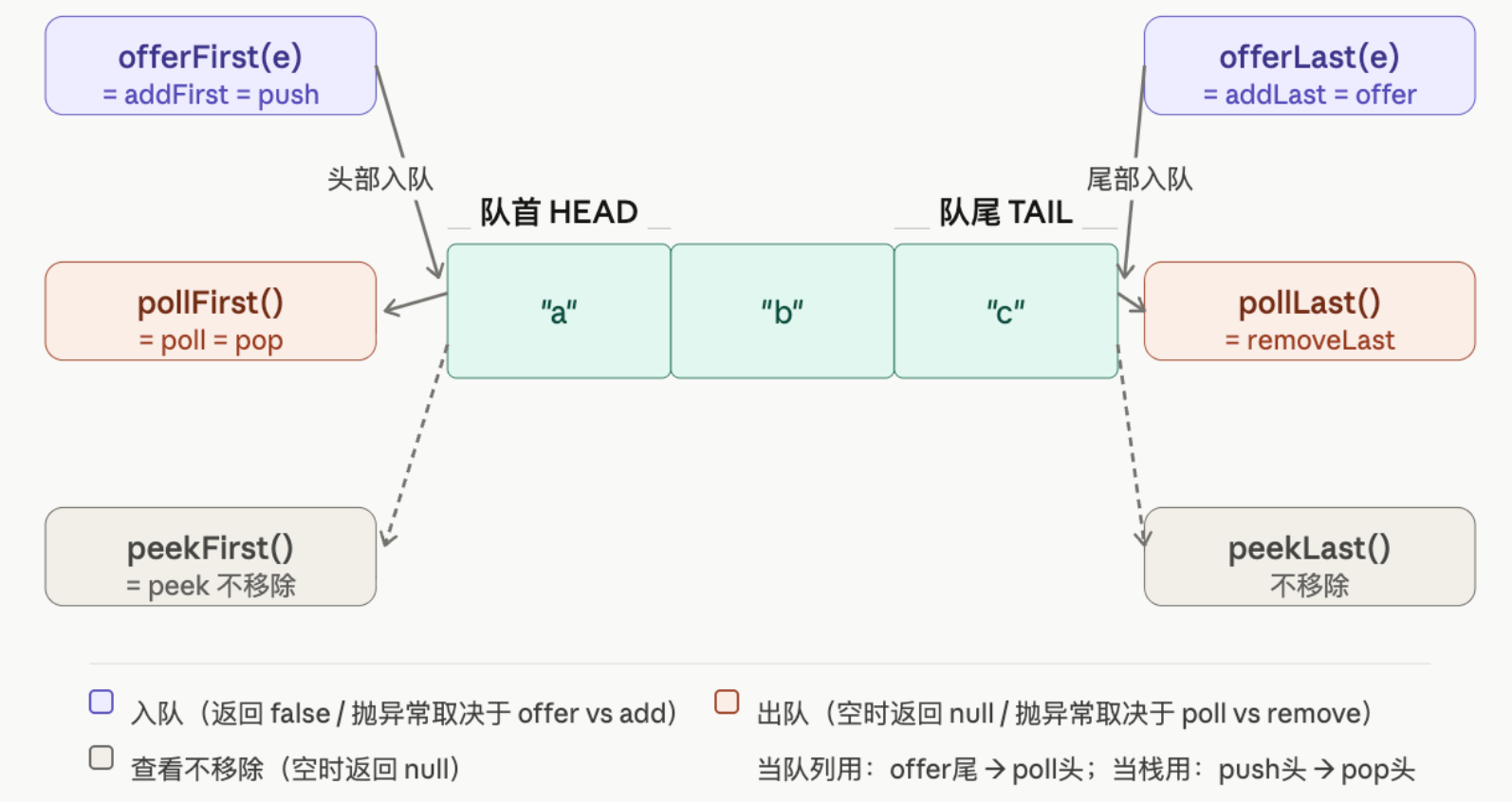
5.2 Deque —— 双端队列
ArrayDeque 是首选实现,比 LinkedList 更快(连续内存,无节点开销)。可以同时当栈和队列用。
Deque<String> deque = new ArrayDeque<>();
// 当队列用(FIFO):从尾入,从头出
deque.offer("a"); // = offerLast
deque.poll(); // = pollFirst
deque.peek(); // = peekFirst
// 当栈用(LIFO):从头入,从头出
deque.push("a"); // = addFirst
deque.pop(); // = removeFirst
deque.peek(); // = peekFirst(栈和队列的 peek 碰巧一样)
不要用
Stack类。它是Vector的子类,带同步锁,性能差,且继承了Vector的随机访问方法(破坏了栈的语义)。用ArrayDeque替代。
方法命名看似繁多,实际只有三类操作(入队、出队、查看),每类在队首和队尾各有一个,记住下面两套常用别名即可:
- 当队列用(FIFO):
offer=offerLast,poll=pollFirst,peek=peekFirst - 当栈用(LIFO):
push=addFirst,pop=removeFirst,peek=peekFirst
offerFirst / offerLast 等完整形式只在需要同时操作两端时才用得上(如滑动窗口单调队列)。
5.3 PriorityQueue —— 优先队列(堆)
底层是最小堆,每次 poll() 取出的是当前最小元素。
// 默认最小堆
PriorityQueue<Integer> minHeap = new PriorityQueue<>();
minHeap.offer(3);
minHeap.offer(1);
minHeap.offer(2);
minHeap.poll(); // 1
minHeap.poll(); // 2
// 最大堆
PriorityQueue<Integer> maxHeap = new PriorityQueue<>(Comparator.reverseOrder());
// 自定义排序
PriorityQueue<int[]> pq = new PriorityQueue<>((a, b) -> a[0] - b[0]);
6. 工具类:Collections 与 Arrays
// Collections 工具方法
Collections.sort(list);
Collections.reverse(list);
Collections.shuffle(list); // 随机打乱
Collections.max(list);
Collections.min(list);
Collections.frequency(list, "a"); // 统计出现次数
Collections.unmodifiableList(list); // 返回不可修改的视图
// 快速创建不可变集合(Java 9+)
List<String> list = List.of("a", "b", "c");
Set<Integer> set = Set.of(1, 2, 3);
Map<String, Integer> map = Map.of("a", 1, "b", 2);
// 这些集合不可 add/put/remove,否则抛 UnsupportedOperationException
// 可变副本
List<String> mutable = new ArrayList<>(List.of("a", "b", "c"));
7. 选型速查
| 需求 | 推荐 |
|---|---|
| 有序列表,随机访问 | ArrayList |
| 频繁头尾操作 | ArrayDeque |
| 去重,不关心顺序 | HashSet |
| 去重,保留插入顺序 | LinkedHashSet |
| 去重,需要排序 | TreeSet |
| 键值映射,不关心顺序 | HashMap |
| 键值映射,保留插入顺序 | LinkedHashMap |
| 键值映射,按 key 排序 | TreeMap |
| FIFO 队列 | ArrayDeque |
| 栈(LIFO) | ArrayDeque(不要用 Stack) |
| 优先级队列 / 堆 | PriorityQueue |
| 线程安全的 Map | ConcurrentHashMap(不要用 Hashtable) |
8. 小结
| 主题 | 关键要点 |
|---|---|
| 两条主线 | Collection(单元素)和 Map(键值对)是两个独立体系 |
| List | ArrayList 是默认选择,LinkedList 很少用 |
| Set | 三兄弟:无序 HashSet、有序 LinkedHashSet、排序 TreeSet |
| Map | HashMap 日常首选,Java 8 的 computeIfAbsent / merge 非常实用 |
| Queue | ArrayDeque 同时替代队列和栈,PriorityQueue 是堆 |
| 不可变集合 | Java 9+ 的 List.of() / Set.of() / Map.of() |
| 遗留类 | Vector、Stack、Hashtable 都不要用 |
下一篇预告:面向对象——类、对象、封装、继承、多态、接口
🎯 如果这篇文章对你有帮助,别忘了点赞、收藏、关注三连!关注我,让你在 Java 学习的道路上不迷路,持续为你带来成体系的 Java 干货~
更多推荐
 13
13 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)