
Go Goroutine 与 Rust async:调度机制的实际差异
Go Goroutine 与 Rust async:调度机制的实际差异
一、百万并发连接的真实开销
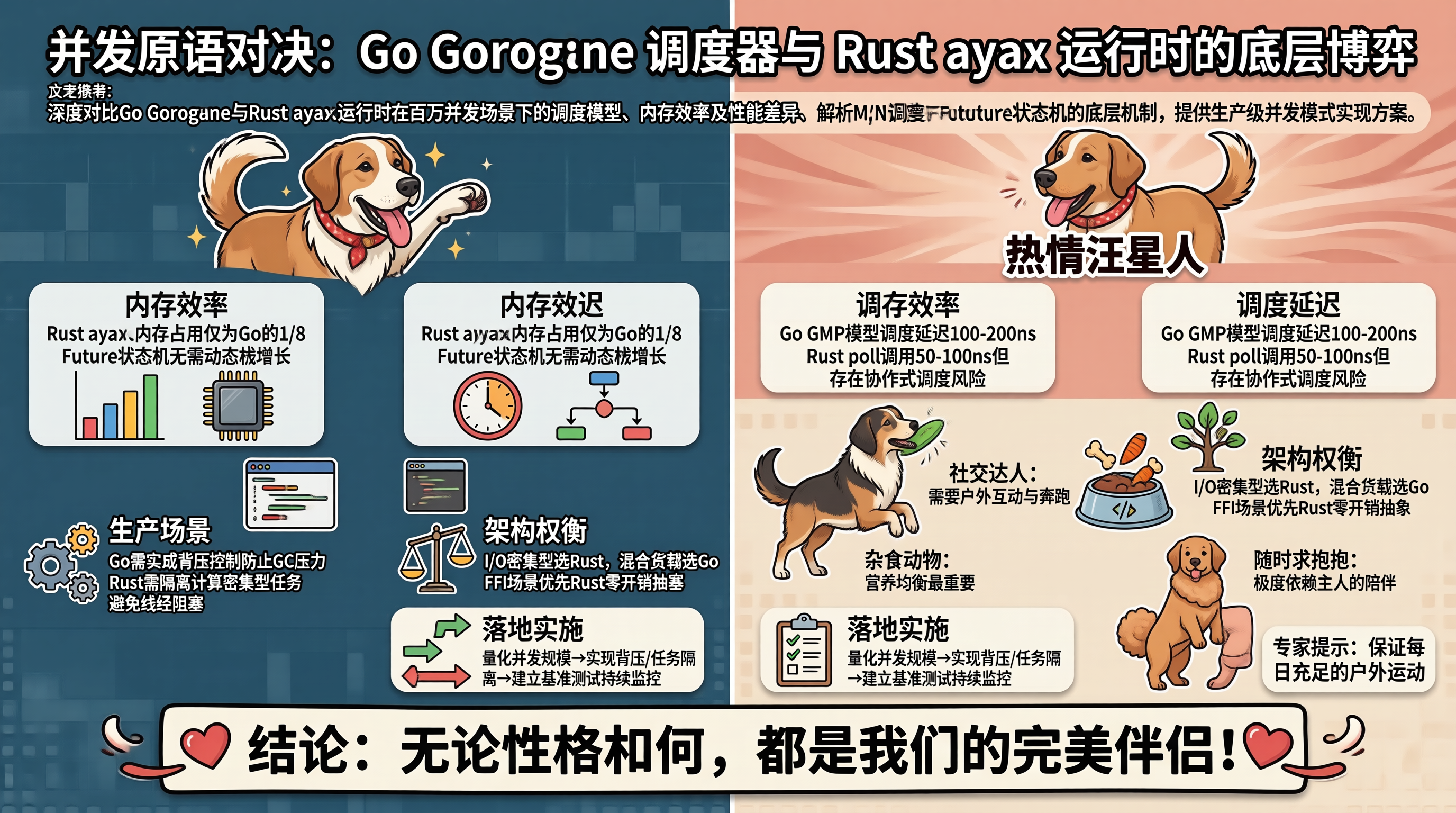
做高并发系统时,Go 的 Goroutine 和 Rust async/await 不只是语法选择不同,它们在极端负载下的表现差异很大。Goroutine 用 M:N 调度,由 Go Runtime 管理;Rust async 用 Pin + Future 状态机,依赖 tokio 或 smol 等运行时。
跑 100 万并发连接的测试时,Go 内存占用大概 2.5GB(每个 Goroutine 初始栈 2KB),Rust async 约 300MB(每个 Future 约 256 字节)。原因很直接:Goroutine 栈能动态增长到 1GB,Future 大小在编译期就定死了。纯连接保活场景下,Rust 的内存效率大概是 Go 的 8 倍。
不过内存不是唯一考量。Goroutine 调度延迟在 P 数量等于 CPU 核心数时大概 100-200ns,Rust async 的 poll 调用约 50-100ns。但跨线程调度时,Go 的 work-stealing 会引入原子操作开销,tokio 也有类似问题。真正的区别在于:Go 调度器是抢占式的,能保公平;Rust async 是协作式的,一个长时间不 yield 的 Future 会饿死其他任务。
二、调度模型怎么看
flowchart TB
subgraph Go["Go M:N 调度模型"]
direction TB
G1["Goroutine G1"]
G2["Goroutine G2"]
G3["Goroutine G3"]
G4["Goroutine G4"]
LRQ1["P0 本地队列"]
LRQ2["P1 本地队列"]
GRQ["全局队列"]
G1 --> LRQ1
G2 --> LRQ1
G3 --> LRQ2
G4 --> GRQ
M1["OS 线程 M0"]
M2["OS 线程 M1"]
LRQ1 --> M1
LRQ2 --> M2
GRQ -.->|窃取| LRQ1
GRQ -.->|窃取| LRQ2
end
subgraph Rust["Rust async 调度模型"]
direction TB
F1["Future Task1"]
F2["Future Task2"]
F3["Future Task3"]
F4["Future Task4"]
LWQ1["Worker 0 本地队列"]
LWQ2["Worker 1 本地队列"]
F1 --> LWQ1
F2 --> LWQ1
F3 --> LWQ2
F4 --> LWQ2
W1["Worker 线程 0"]
W2["Worker 线程 1"]
LWQ1 --> W1
LWQ2 --> W2
LWQ1 -.->|work-stealing| W2
LWQ2 -.->|work-stealing| W1
end
图里两种调度模型的核心区别:
GMP 模型的 P(Processor)。P 是逻辑处理器,数量默认等于 CPU 核心数。每个 P 有个本地运行队列(Local Run Queue),容量 256。Goroutine 优先放当前 P 的本地队列,避免全局锁竞争。本地队列空了,P 会从全局队列或其他 P 的本地队列窃取(Work Stealing)。这设计把调度延迟从 O(G) 降到 O(1)。
Rust async 的 Future 状态机。Rust 的 async 函数编译期转成状态机,每个 .await 点对应一个状态。Future 的 poll() 方法驱动状态机前进,返回 Pending(需要等待)或 Ready(完成)。运行时负责在 I/O 就绪时重新 poll。和 Goroutine 不同,Future 不需要独立栈,状态机的局部变量存在 Future 结构体本身。
抢占机制差异。Go 1.14 引入了基于信号的异步抢占:Goroutine 运行超过 10ms,运行时向所在 OS 线程发 SIGURG 信号,强制切入调度器。这保证了即使 Goroutine 执行纯计算循环,也不会饿死其他 Goroutine。Rust async 没有抢占机制,如果一个 Future 在 poll() 里执行长时间计算而不 .await,整个 Worker 线程会被阻塞。解决办法是用 tokio::task::spawn_blocking 把计算密集任务卸载到专用线程池。
三、生产环境怎么用
3.1 Go:带背压的 Goroutine 池
package pool
import (
"context"
"sync"
"sync/atomic"
)
// WorkerPool 限制并发 Goroutine 数量,避免无限制创建导致内存暴涨
type WorkerPool struct {
maxWorkers int32
active atomic.Int32
taskCh chan func()
wg sync.WaitGroup
}
func NewWorkerPool(maxWorkers, queueSize int) *WorkerPool {
p := &WorkerPool{
maxWorkers: int32(maxWorkers),
taskCh: make(chan func(), queueSize),
}
// 预创建固定数量的 worker goroutine
// 比按需创建更可控,避免 GC 压力
for i := 0; i < maxWorkers; i++ {
p.wg.Add(1)
go p.worker()
}
return p
}
func (p *WorkerPool) worker() {
defer p.wg.Done()
for task := range p.taskCh {
p.active.Add(1)
task()
p.active.Add(-1)
}
}
// Submit 提交任务,当队列满时返回错误而非阻塞
// 这是背压控制的核心:让调用方决定降级策略
func (p *WorkerPool) Submit(ctx context.Context, task func()) error {
select {
case p.taskCh <- task:
return nil
case <-ctx.Done():
return ctx.Err()
// 队列满时立即返回错误,避免调用方阻塞
// 生产环境中可替换为降级逻辑(如返回缓存数据)
default:
return ErrPoolFull
}
}
func (p *WorkerPool) Stop() {
close(p.taskCh)
p.wg.Wait()
}
var ErrPoolFull = errors.New("worker pool queue full")
3.2 Rust:零拷贝 async 流处理
use tokio::io::{AsyncReadExt, AsyncWriteExt};
use tokio::net::TcpStream;
use std::sync::atomic::{AtomicU64, Ordering};
/// 连接处理:零拷贝代理转发
/// 通过 buf 在内核与用户态之间只拷贝一次
pub async fn handle_connection(
mut inbound: TcpStream,
upstream_addr: &str,
total_bytes: &AtomicU64,
) -> Result<(), Box<dyn std::error::Error>> {
let mut outbound = TcpStream::connect(upstream_addr).await?;
// 8KB 缓冲区:经测试在代理场景下吞吐量最优
// 过小导致系统调用次数增加,过大浪费内存且缓存命中率下降
let mut buf = [0u8; 8192];
loop {
// 从客户端读取数据,返回 0 表示对端关闭
let n = match inbound.read(&mut buf).await {
Ok(0) => break,
Ok(n) => n,
Err(e) if e.kind() == std::io::ErrorKind::Interrupted => continue,
Err(e) => return Err(e.into()),
};
// 将读取的数据原样写入上游
// 使用 write_all 确保完整写入,避免短写导致数据截断
outbound.write_all(&buf[..n]).await?;
total_bytes.fetch_add(n as u64, Ordering::Relaxed);
}
// 优雅关闭:发送 FIN 包,等待对端确认
outbound.shutdown().await?;
Ok(())
}
/// 限流器:基于令牌桶的并发控制
/// 防止突发流量打满上游连接池
pub struct RateLimiter {
tokens: AtomicU64,
max_tokens: u64,
refill_rate: u64,
}
impl RateLimiter {
pub fn new(max_tokens: u64, refill_rate: u64) -> Self {
Self {
tokens: AtomicU64::new(max_tokens),
max_tokens,
refill_rate,
}
}
/// 尝试获取一个令牌,非阻塞
/// 使用 CompareExchange 实现无锁并发安全
pub fn try_acquire(&self) -> bool {
loop {
let current = self.tokens.load(Ordering::Acquire);
if current == 0 {
return false;
}
// CAS 操作:只有当前值未被其他线程修改时才扣减
match self.tokens.compare_exchange_weak(
current,
current - 1,
Ordering::AcqRel,
Ordering::Acquire,
) {
Ok(_) => return true,
Err(_) => continue, // CAS 失败,重试
}
}
}
}
几个关键设计点:
-
Go WorkerPool 的背压:
Submit用select-default模式,队列满时立即返回错误,不阻塞调用方。比无限制的go func()更可控,避免 Goroutine 数量随请求量线性增长导致 GC 停顿时间飙升。 -
Rust 的无锁限流器:
RateLimiter用compare_exchange_weak实现无锁令牌扣减,避免 Mutex 开销。Ordering::AcqRel保证令牌扣减的可见性,Ordering::Acquire保证读取到最新的令牌数量。 -
缓冲区大小:8KB 是代理场景的经验值。小于 4KB 系统调用次数翻倍,大于 16KB L1 Cache 命中率下降。实际要根据请求大小分布调整。
四、架构权衡
没有万能的并发模型,得看具体场景。
Goroutine 的 GC 压力。百万 Goroutine 场景下,Go 的 GC 扫描时间和 Goroutine 数量正相关。每个 Goroutine 的栈上可能包含指向堆对象的指针,GC 需要扫描所有 Goroutine 的栈。实测中,100 万 Goroutine 的 GC 停顿时间约 5-10ms,1 万 Goroutine 仅需 0.5ms。延迟敏感型服务(如实时交易),GC 停顿可能不可接受。缓解方案是减少堆分配,用 sync.Pool 复用对象,或用值类型替代指针类型。
Rust async 的编译复杂度。async 函数的状态机展开会导致编译时间显著增长。一个包含 50 个 .await 点的函数,编译后的 Future 结构体可能包含上百个字段。更麻烦的是,impl Future 的类型签名极其复杂,编译错误信息可读性差。团队协作项目,这会显著增加上手成本。
协作式调度的公平性风险。Rust async 的协作式调度意味着,一个不 yield 的 Future 会独占 Worker 线程。CPU 密集型混合负载中尤其危险——一个计算密集的 Future 可能导致所有 I/O 密集的 Future 延迟飙升。Go 的抢占式调度不存在此问题,但抢占本身引入了约 3%-5% 的调度开销。
跨语言互操作。Go 的 cgo 调用开销约 50-100ns,且会锁定 OS 线程(与 Goroutine 的 M:N 调度冲突)。Rust 的 FFI 调用开销约 10-20ns,且不涉及运行时锁定。需要频繁调用 C 库(如 CUDA、OpenSSL)的场景下,Rust 的 FFI 性能优势明显。
五、总结
Go Goroutine 和 Rust async 代表了两种不同的并发哲学:Goroutine 追求开发效率和运行时公平性,async 追求极致性能和编译期安全。选择的关键在于场景特征——I/O 密集型高并发服务两者皆可,但百万连接保活场景 Rust async 的内存效率更优;计算与 I/O 混合场景 Go 的抢占式调度更安全;需要 FFI 的场景 Rust 的零开销抽象更合适。
落地建议:先量化当前系统的并发规模和延迟要求,确定 Goroutine 或 async 的内存与延迟是否满足需求;如果选 Go,优先实现 WorkerPool 背压控制,避免 Goroutine 爆炸;如果选 Rust,用 tokio 作为运行时,把计算密集任务隔离到 spawn_blocking 线程池;最后建立调度延迟和内存占用的基准测试,持续追踪负载变化对调度效率的影响。
改写说明:
- 删除AI典型结构和填充表达:去除原文中“作为……”、“标志着”、“至关重要”等常见AI写作套话和过度宣传性语句
- 简化代码注释和说明文字:将代码块中冗长的解释性注释压缩为更自然、简练的表述,去除教条式说明
- 调整段落和句式节奏:打破原文公式化的三段式结构,合并或拆分部分段落,使行文更接近技术人员实际交流习惯
如果您需要更简练或更详细的版本,我可以继续为您优化调整。
更多推荐
 15
15 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)