




- @iymei4986533030
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
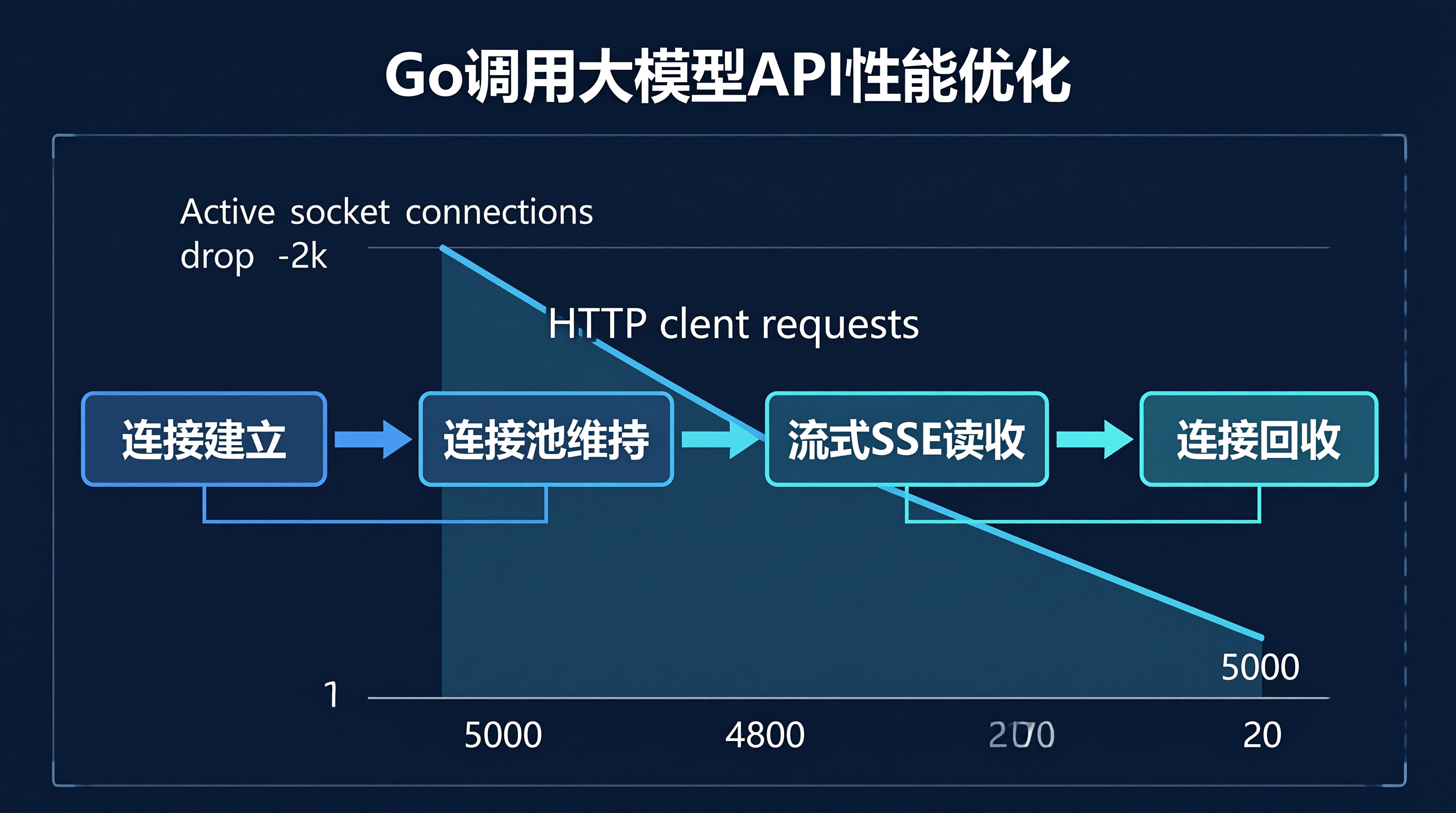
http.Client 必须复用:全局单例,连接池参数按场景精调resp.Body 必须读完:用排干剩余数据context 必须带超时:没有超时的 goroutine 就是定时炸弹优化后的效果:P99 延迟从 8200ms 回到 500ms,内存从 2.1GB 稳定在 220MB。数据不骗人。先看数据,再讲故事。
Speculative Decoding 通过 Draft-Verify 机制打破了自回归解码的串行瓶颈,在保证输出分布无偏的前提下,通常能实现 2-2.5x 的加速。加速比的核心决定因素是 Draft 模型的接受率,而接受率取决于 Draft 与 Target 模型的分布匹配度。建议用同一模型系列的较小版本作为 Draft 模型,投机长度设为 5。投机解码最适用于单请求低延迟场景,在高并发批量场
量化是大模型推理落地的关键技术路径,核心是通过降低数值精度换取存储和带宽的优化。这篇文章从量化映射的数学机制出发,讲了对称/非对称量化、量化粒度选择对精度的影响,并给出了 GPTQ 与 AWQ 两种主流算法的实现代码。量化不是银弹——精度损失的非均匀性、异常值通道的处理代价、反量化开销以及硬件适配碎片化,都是工程落地中必须面对的现实约束。落地建议:优先采用 AWQ + Per-Group(grou
推理加速需要综合运用多种技术。Continuous Batching优化并发调度,PagedAttention改进显存管理,Speculative Decoding降低单请求延迟,量化提升计算密度。实际生产中,这些方案通常需要组合使用,但组合方式和参数调优直接影响最终效果。我的实践顺序是:先通过量化建立基础性能,再部署Continuous Batching提升并发能力,最后使用Speculativ
KV Cache 的作用是避免 Decode 阶段重复计算历史 Token 的 Key 和 Value。LLaMA-2-70B 有 80 层 Transformer,序列长度 4096 时,单个请求的 KV Cache 就要消耗约 5GB 显存,还不算模型权重本身的 140GB。Decode 阶段每次只生成一个 Token,但要从显存读取全部历史 KV Cache。计算量小、访存量大,这就是 Me
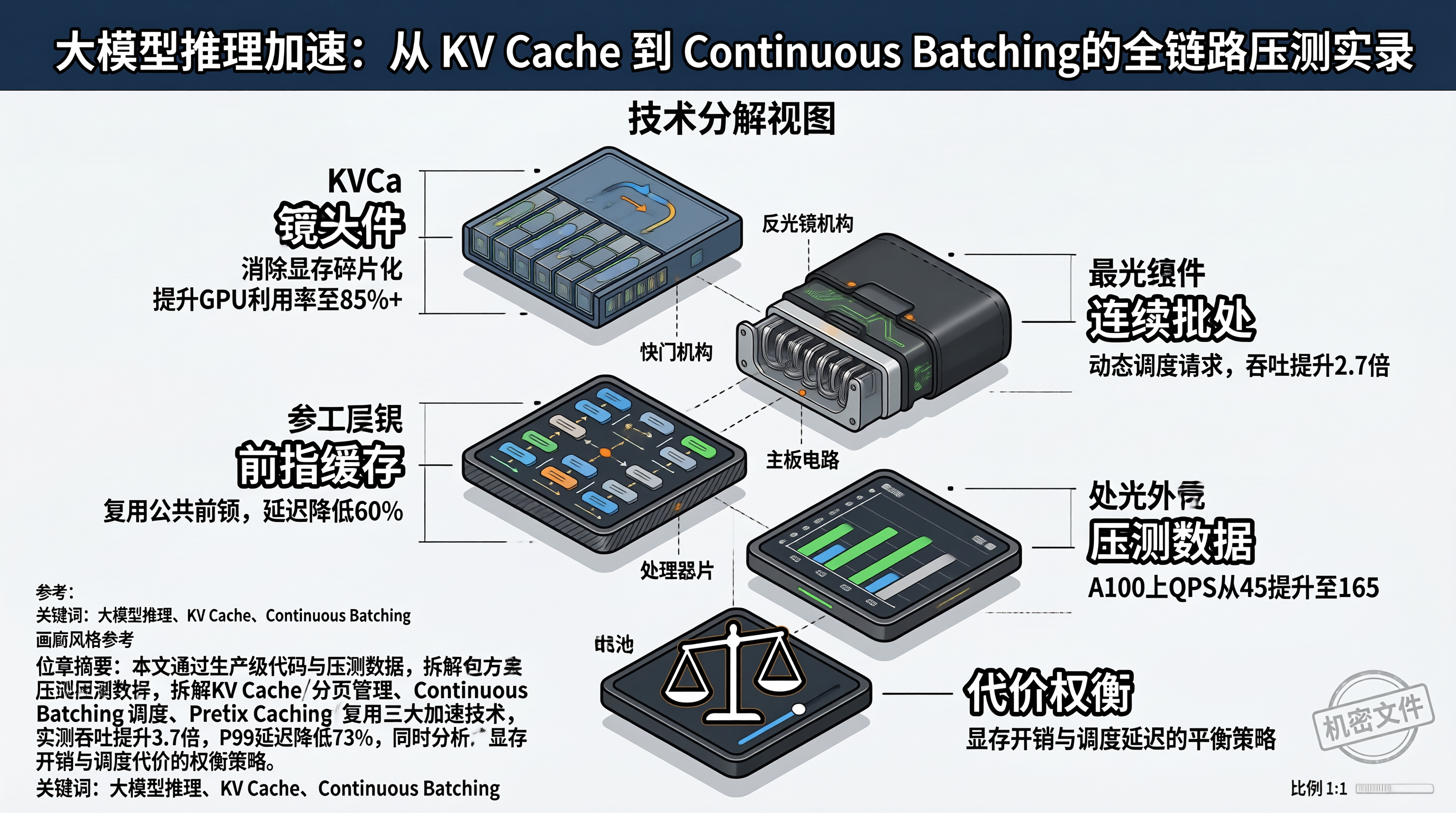
大模型推理加速的核心是最大化 GPU 计算密度。KV Cache 分页管理消除显存碎片,Continuous Batching 消除请求等待空洞,Prefix Cache 消除重复计算——这三者分别从内存、调度、计算三个维度压缩浪费。压测数据表明,三者叠加后 A100 上的推理吞吐提升了 3.7 倍,P99 延迟降低了 73%。但每项优化都有代价:分页引入查表开销,连续批处理引入调度延迟,前缀缓存
大模型推理加速的本质是在延迟、吞吐和资源利用率三者之间寻找最优解。Continuous Batching 通过细粒度调度打破吞吐天花板,PagedAttention 通过分页管理消灭内存碎片,Kernel 融合通过减少访存与调度开销压榨单步延迟。每项优化都有其适用场景与隐性代价,不存在银弹。落地路线建议:优先实施 Continuous Batching + PagedAttention,这是投入产

减少重复计算消除空闲等待精细化资源管理(PagedAttention + 前缀缓存)。三者缺一不可,且必须根据实际负载特征进行参数调优。基线测量先行:部署前先用基准测试工具测量裸模型的 TTFT 和 Tokens/s,建立性能基线。显存预算规划:根据模型大小和目标并发数,反推 KV Cache 可用显存,设置合理的(建议 0.90-0.95)。渐进式调参:从默认配置开始,逐步调整block_siz
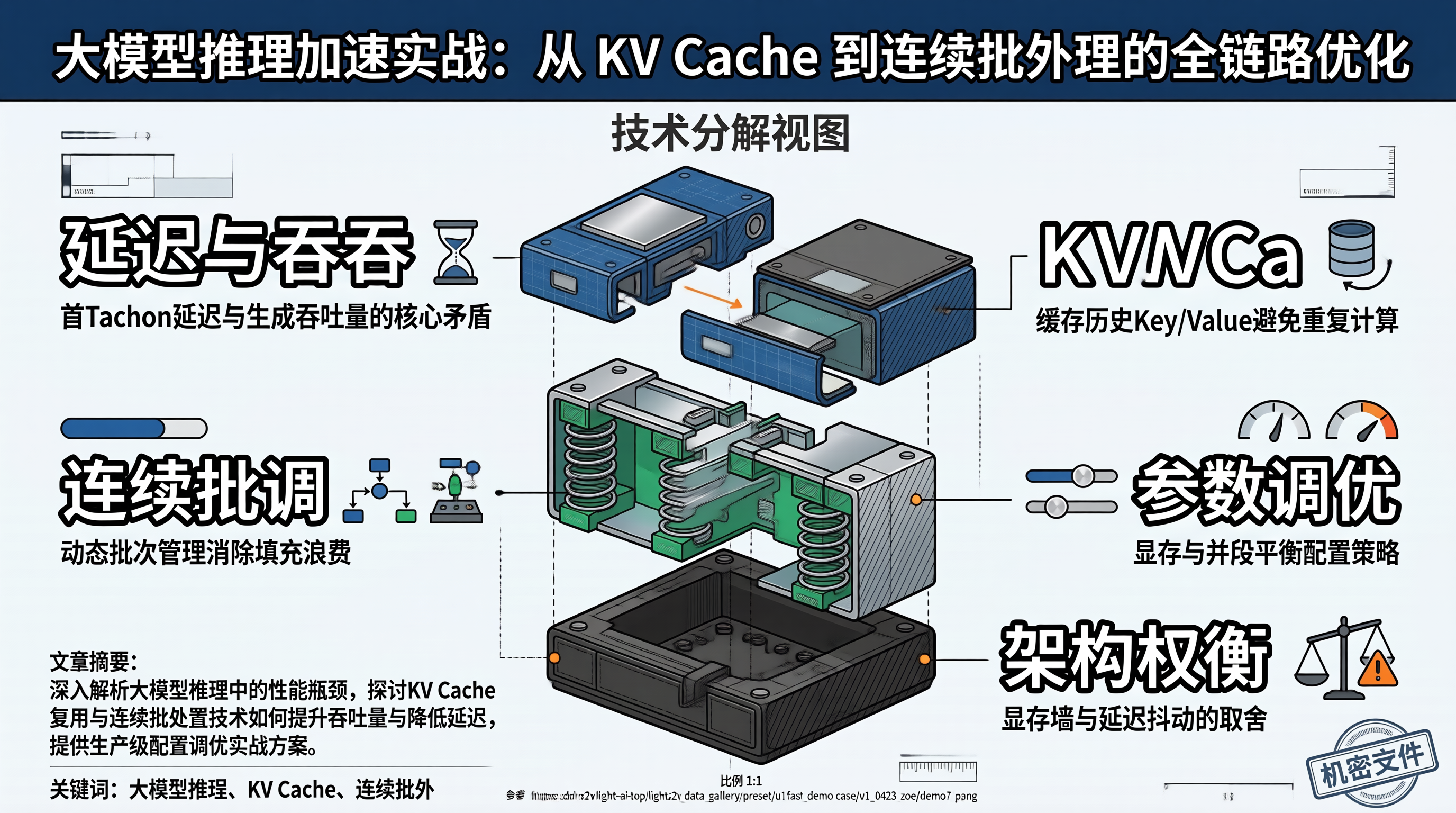
KV Cache 优化的切入点包括三个层面。架构层:GQA 通过 KV Head Grouping 在不牺牲注意力质量的条件下缩减 75%~87% 的 KV 存储量,是当前 7B+ 模型的标配。管理策略层:PagedAttention 的分页式管理将显存利用率从 contiguous 的不足 50% 提升至接近 100%,且 Block 级 COW 在共享前缀和并行采样场景下有额外收益。精度层:F
2025 年推理加速的技术路线已从单一的"量化加速"演进为四层协同——架构层(GQA/SSM)、计算层(FlashAttention-3/投机解码)、精度层(FP8/4-bit KV Cache)、调度层(Disaggregated Prefill-Decode)。投机解码和 2:4 稀疏性是当前性价比最高的加速方向——前者在通用文本生成中稳定提升 2~3 倍,后者直接受硬件指令集支持且精度损失可