
降本增效新利器:企业如何通过GLM-5.2 API重构业务流程实现利润翻倍——2026年大模型企业落地全景指南
声明:本文作者认为,企业通过大模型API实现降本增效的核心,不在于"用最贵的模型",而在于"用对的模型做对的事"。GLM-5.2以744B总参数/40B激活的MoE架构,在长程编码和Agent任务上达到开源SOTA,而通过AIGC Bar这个API聚合平台,企业可以按需调用GLM-5.2、Kimi-K2.6、Qwen3.5等多模型构建智能体,实现"一次接入、多模型协作"的降本增效目标。但需清醒认识到:API调用主要面向开发者,普通用户使用对话服务直接访问各模型官网即可。
2026年,大语言模型已从"技术实验"全面进入"企业核心业务"阶段。从智能客服、代码助手到企业知识库和Agent系统,越来越多的应用开始承载真实生产流量。在这一背景下,如何选择合适的模型、如何控制API调用成本、如何构建可靠的智能体系统,成为企业技术团队面临的核心挑战。智谱AI于2026年6月发布的GLM-5.2,以744B总参数/40B激活的MoE架构和1M可用上下文窗口,在SWE-bench Pro等长程编码基准上达到开源SOTA,成为企业降本增效的新利器。本文将系统解析GLM-5.2的技术架构、企业应用场景、API调用方法以及多模型智能体构建策略,为企业大模型落地提供全景指南。
1 引言:企业AI降本增效的范式转换
理解GLM-5.2在企业降本增效中的价值,需要先把握2026年企业AI应用的宏观趋势和核心挑战。
1.1 从"技术实验"到"价值创造"的转换
2023年至2024年,企业AI应用主要处于"技术实验"阶段——各企业纷纷试点大模型项目,但多数停留在POC(概念验证)层面,难以产生可量化的业务价值。中欧国际工商学院方跃教授指出,企业把AI价值局限于降本增效、所有项目以短期省钱为目标,反而会放弃创新业务、市场拓展与模式重构,过度追逐短期效率最终锁死AI的长期增长潜力。
2025年至2026年,这一态势发生根本转变。LangChain发布的《State of Agent Engineering 2026》报告显示,企业不再问"是否要构建Agent",而是问"如何可靠、高效地部署Agent"。IBM咨询的调研进一步表明,数字化转型已从"IT项目和流程优化"演进为"企业核心竞争力构建",AI从"降本工具"升级为"价值引擎"。这一转换的核心标志是:企业开始将AI能力嵌入到核心业务流程中,而非仅用于边缘场景的效率提升。
1.2 企业AI降本增效的核心挑战
尽管AI降本增效的前景广阔,但企业在实际落地中面临多重挑战。第一是模型选择困难——市场上模型众多(GLM-5.2、GPT-5.5、Claude Opus 4.8、Kimi-K2.6等),性能和成本差异巨大,企业难以判断"哪个模型最适合我的场景"。第二是API调用成本不可控——大模型按token计费,高并发场景下成本可能指数增长,缺乏治理机制的企业很容易遭遇"账单爆炸"。第三是系统集成复杂——将AI能力嵌入到现有业务系统中,需要处理认证、路由、容错、监控等一系列工程问题。第四是效果评估困难——AI输出的质量难以用传统指标衡量,企业缺乏"AI投资回报率"的量化方法。
TrueFoundry 2026年的AI成本优化指南指出,AI支出在没有治理的情况下会螺旋式增长,企业需要从token级、计算级和Agent级三个层面建立成本控制体系。DigitalApplied的LLM API定价指数报告进一步强调,"在单一pipeline中智能混合不同层级的模型"是2026年最重要的成本优化杠杆——即简单任务用低成本模型,复杂任务用高性能模型,通过模型路由实现"性能-成本"的最优平衡。
1.3 GLM-5.2的企业价值定位
在这一背景下,GLM-5.2的企业价值定位逐渐清晰。InfoWorld的评测指出,GLM-5.2最明确的优势在于"将更强的编码能力与开源模型的成本优势相结合"——对于需要长程编码和Agent能力的企业场景,GLM-5.2提供了"闭源模型性能+开源模型成本"的折中方案。VentureBeat的报道进一步指出,GLM-5.2在多个长程编码基准上击败GPT-5.5,而成本仅为后者的1/6,这一性价比优势使其成为企业AI降本增效的理想选择。
GLM-5.2的企业价值不仅体现在成本上,更体现在能力上。其1M可用上下文窗口使企业能够处理超长文档(如法律合同、技术规范、代码库),其Agent能力使企业能够构建自主执行复杂任务的智能体,其开源特性使企业能够进行私有化部署以满足数据安全要求。这些能力共同构成了GLM-5.2在企业场景中的核心竞争力。
2 GLM-5.2技术架构深度解析
理解GLM-5.2如何赋能企业降本增效,需要深入其技术架构,把握其能力来源和性能边界。
2.1 MoE稀疏混合专家架构
GLM-5.2采用了MoE(Mixture of Experts)稀疏混合专家架构,总参数量744B,激活参数约40B。MoE架构的核心思想是引入稀疏激活机制——每个token只激活一小部分"专家"(即前馈网络模块),从而实现"参数量大但计算量可控"的目标。
MoE的路由机制可以形式化表示为:
MoE ( x ) = ∑ i = 1 N g i ( x ) ⋅ E i ( x ) , g ( x ) = TopK ( softmax ( W g ⋅ x ) ) \text{MoE}(x) = \sum_{i=1}^{N} g_i(x) \cdot E_i(x), \quad g(x) = \text{TopK}(\text{softmax}(W_g \cdot x)) MoE(x)=i=1∑Ngi(x)⋅Ei(x),g(x)=TopK(softmax(Wg⋅x))
其中 E i E_i Ei 为第 i i i 个专家网络, g i g_i gi 为门控函数分配给第 i i i 个专家的权重, W g W_g Wg 为门控权重矩阵,TopK操作只保留最大的 K K K 个权重。对于GLM-5.2, N N N 为专家总数, K K K 为每次激活的专家数,激活比约为 K / N ≈ 5.4 % K/N \approx 5.4\% K/N≈5.4%。
这一架构的企业意义在于:虽然模型总参数高达744B(提供了丰富的知识容量),但单次推理只激活40B参数(控制了计算成本)。从Roofline模型的视角,MoE架构使模型在相同的计算预算下,能够达到更低的损失——因为更大的总参数量提供了更丰富的知识表示,而稀疏激活确保了推理效率。
2.2 动态稀疏注意力DSA
GLM-5.2的另一项核心技术是动态稀疏注意力(Dynamic Sparse Attention, DSA)。传统Transformer的注意力机制复杂度为 O ( n 2 ) O(n^2) O(n2),其中 n n n 为序列长度——对于1M token的上下文,这一复杂度在计算和内存上都是不可承受的。DSA通过动态生成稀疏注意力掩码,将有效注意力计算限制在关键区域,大幅降低了长上下文的计算开销。
DSA的核心思想可以形式化为:
Attn DSA ( Q , K , V ) = softmax ( Q K T d k ⊙ M dynamic ) V \text{Attn}_{\text{DSA}}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}} \odot M_{\text{dynamic}}\right)V AttnDSA(Q,K,V)=softmax(dkQKT⊙Mdynamic)V
其中 M dynamic M_{\text{dynamic}} Mdynamic 为动态生成的稀疏掩码矩阵, ⊙ \odot ⊙ 为逐元素乘法。掩码的生成基于查询与键的语义相关性——模型学习一个轻量级的掩码生成器,根据当前查询动态决定哪些键值对需要参与注意力计算。
DSA的企业价值在于:它使GLM-5.2的1M上下文窗口"真正可用"——不仅是理论上支持1M token,而是在1M token下仍保持稳定的性能和合理的推理速度。对于需要处理超长文档的企业场景(如代码库分析、法律合同审查、技术规范理解),这一能力至关重要。
2.3 性能基准与企业适用性
GLM-5.2在多项基准测试中表现优异。根据Hugging Face官方博客和SWE-bench排行榜的数据,GLM-5.2在SWE-bench Verified上取得81.0%,在SWE-bench Pro上取得62.1%,在AIME 2026上取得95.3%,均达到开源模型SOTA水平。与闭源前沿模型对比,GLM-5.2在SWE-bench Pro上仅落后Claude Opus 4.8约1%,但领先GPT-5.5约1%。
| 基准测试 | GLM-5.2 | GLM-5.1 | GPT-5.5 | Claude Opus 4.8 | 测试维度 |
|---|---|---|---|---|---|
| SWE-bench Verified | 81.0% | 62.0% | ~80% | ~82% | 编码修复 |
| SWE-bench Pro | 62.1% | 58.4% | ~61% | ~63% | 长程编码 |
| AIME 2026 | 95.3% | 95.3% | ~94% | ~96% | 数学推理 |
| GPQA-Diamond | 86.2% | 86.2% | ~85% | ~87% | 科学问答 |
| 上下文窗口 | 1M | 1M | ~1M | ~1M | 长文本处理 |
这些基准成绩的企业意义在于:GLM-5.2在编码、推理和长上下文处理上已达到或接近闭源前沿模型水平,而成本远低于后者。对于需要"前沿性能+可控成本"的企业场景,GLM-5.2提供了极具竞争力的选择。
3 企业降本增效的核心场景
GLM-5.2的企业降本增效价值需要通过具体场景落地。本节分析四个核心场景的技术原理和ROI模型。
3.1 智能编码与开发效率提升
编码是企业AI应用最成熟的场景之一。GLM-5.2在SWE-bench上的优异表现,使其成为企业开发团队的理想编码助手。SWE-bench评估的是模型在真实开源项目仓库中修复bug的能力——模型需要理解代码库结构、定位问题文件、生成修复代码并通过测试用例。这一能力直接对应企业开发中的"bug修复"和"功能实现"场景。
智能编码的降本增效逻辑可以用一个简单的ROI模型表示。设企业开发团队有 N N N 名工程师,平均年薪 S S S,每周编码时间 T T T 小时。引入GLM-5.2编码助手后,假设编码效率提升 η \eta η(根据GitHub Copilot的研究,AI辅助编码可提升效率30-50%),则年节省成本为:
Savings = N × S × T × η 40 \text{Savings} = N \times S \times \frac{T \times \eta}{40} Savings=N×S×40T×η
以50人开发团队、平均年薪40万、每周编码30小时、效率提升35%计算,年节省成本约 50 × 40 × 30 × 0.35 40 = 525 50 \times 40 \times \frac{30 \times 0.35}{40} = 525 50×40×4030×0.35=525 万元。而GLM-5.2 API的年调用成本(假设每工程师每天调用100次,每次平均2000 token,按AIGC Bar平台定价估算)约50-100万元,ROI高达5-10倍。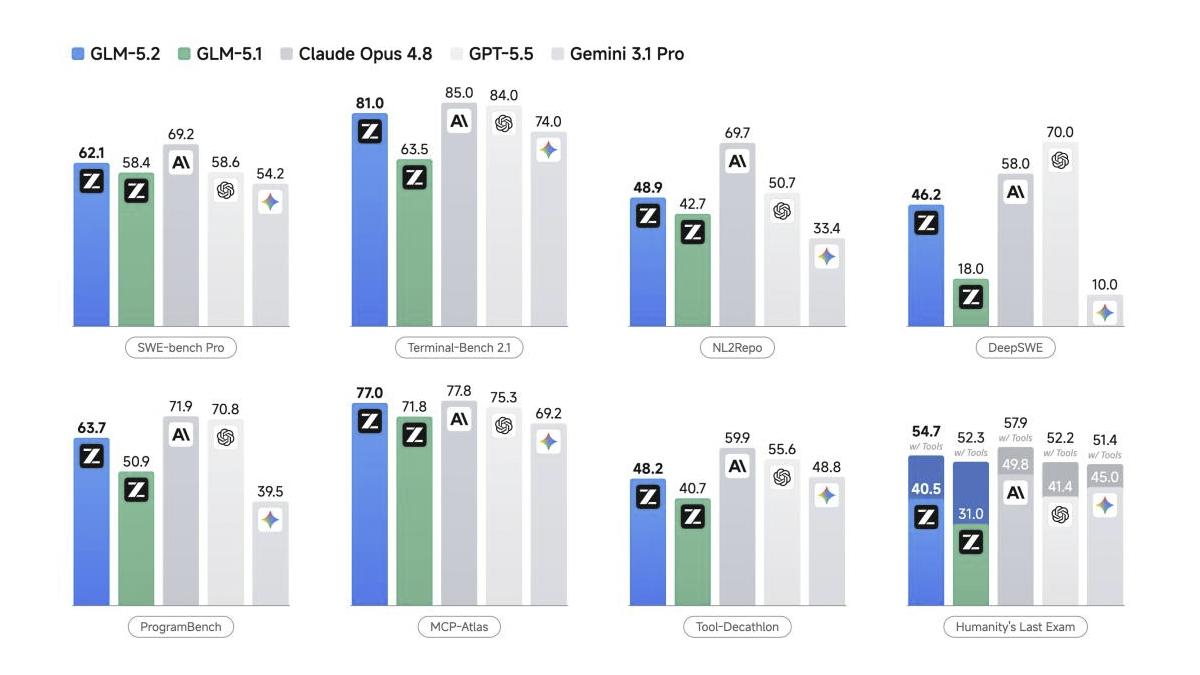
3.2 智能客服与知识库
智能客服是企业AI应用的另一核心场景。传统客服系统依赖关键词匹配和规则引擎,难以处理复杂的用户咨询。基于GLM-5.2的智能客服系统,结合RAG(检索增强生成)技术,能够理解用户意图、检索知识库、生成准确回答,大幅提升客服效率和用户满意度。
RAG的技术架构可以形式化描述。设企业知识库为 K = { d 1 , d 2 , . . . , d M } \mathcal{K} = \{d_1, d_2, ..., d_M\} K={d1,d2,...,dM},用户查询为 q q q,则RAG的生成过程为:
P ( y ∣ q ) = ∑ d ∈ TopK ( Retriever ( q , K ) ) P ( y ∣ q , d ) ⋅ P ( d ∣ q ) P(y | q) = \sum_{d \in \text{TopK}(\text{Retriever}(q, \mathcal{K}))} P(y | q, d) \cdot P(d | q) P(y∣q)=d∈TopK(Retriever(q,K))∑P(y∣q,d)⋅P(d∣q)
其中 Retriever \text{Retriever} Retriever 为检索器(通常基于向量相似度), TopK \text{TopK} TopK 为取最相关的 K K K 个文档, P ( y ∣ q , d ) P(y | q, d) P(y∣q,d) 为GLM-5.2基于查询和检索文档生成回答的概率。这一架构使客服系统能够基于企业自有知识生成准确回答,避免了纯LLM的"幻觉"问题。
智能客服的降本增效体现在两个方面:一是减少人工客服需求——AI可处理60-80%的常见咨询,人工客服只需处理复杂案例;二是提升响应速度和一致性——AI可7×24小时秒级响应,且回答质量一致。以一个日均10000次咨询的客服中心为例,引入GLM-5.2智能客服后,可减少50%的人工客服需求,年节省成本约200-500万元。
3.3 文档处理与合同审查
企业的文档处理需求庞大——合同审查、报告生成、文档摘要等任务消耗大量人力。GLM-5.2的1M上下文窗口使其能够处理超长文档(如百页合同、技术规范),在文档处理场景中具有独特优势。
以合同审查为例,传统人工审查一份百页合同需要4-8小时,而GLM-5.2可在数分钟内完成审查,识别风险条款、缺失条款和异常条款。审查的准确率取决于Prompt工程和知识库质量——通过将企业合同标准和历史案例构建为知识库,GLM-5.2能够提供比通用模型更精准的审查结果。
文档处理的降本增效逻辑类似编码场景。设企业法务团队每月审查 N N N 份合同,每份人工审查成本 C C C,引入GLM-5.2后审查效率提升 η \eta η,则月节省成本为 N × C × η N \times C \times \eta N×C×η。对于合同量大的企业(如房地产、金融),这一节省可达数百万元/年。
3.4 数据分析与决策支持
GLM-5.2的推理能力使其能够辅助数据分析和决策支持。通过Code Interpreter功能,GLM-5.2可以编写Python代码处理数据、生成图表、执行统计分析,将"自然语言提问"转化为"数据驱动答案"。
数据分析的降本增效体现在:分析师无需编写复杂SQL或Python代码,只需用自然语言描述需求,GLM-5.2即可生成分析代码并执行。这一能力使非技术人员也能进行数据分析,扩大了数据驱动决策的覆盖面。同时,GLM-5.2可以快速处理多维度数据,发现人工难以察觉的模式和趋势,提升决策质量。
4 AIGC Bar API聚合平台与模型调用
企业调用GLM-5.2等模型,最便捷的方式是通过API聚合平台。本节详细介绍AIGC Bar平台的使用方法。
4.1 AIGC Bar平台概览
AIGC Bar是一个API聚合平台,提供对多种大模型的统一接入服务。平台的核心价值在于"一次接入、多模型调用"——开发者只需注册一个账号、获取一个API密钥,即可调用GLM-5.2、Kimi-K2.6、Qwen3.5、Gemma-4、DeepSeek-V4-Flash等多种模型,无需分别对接各模型供应商。
AIGC Bar平台的模型按分组管理。OpenSource-MultiModal分组包含GLM-5.2、Kimi-K2.6、Qwen3.5等开源多模态模型,API调用需要付费,按token计费。free分组包含DeepSeek-V4-Flash等模型,完全免费,适合开发者进行原型开发和功能测试。这一分组机制使开发者能够根据需求灵活选择模型,在成本和能力之间取得平衡。
4.2 注册与API密钥获取
使用AIGC Bar平台的第一步是注册账号。开发者通过注册链接AIGC Bar完成注册后,在控制台获取API密钥。API密钥是调用模型的凭证,需妥善保管,避免泄露。
注册流程简单快捷:访问注册链接 → 填写邮箱和密码 → 验证邮箱 → 登录控制台 → 获取API密钥。整个流程无需企业认证,个人开发者也可快速上手。获取API密钥后,开发者即可通过OpenAI兼容的API接口调用各种模型。
4.3 API调用示例
AIGC Bar平台提供OpenAI兼容的API接口,开发者可以使用标准的OpenAI SDK进行调用。以下是Python调用GLM-5.2的示例代码:
import openai
# 初始化客户端
client = openai.OpenAI(
api_key="你的AIGC-Bar-API-Key", # 在 https://api.aigc.bar/register?aff=UP4F 注册后获取
base_url="https://api.aigc.bar/v1"
)
# 调用GLM-5.2 (OpenSource-MultiModal分组,付费)
response = client.chat.completions.create(
model="glm-5.2",
messages=[
{"role": "system", "content": "你是一个专业的企业助手"},
{"role": "user", "content": "帮我分析这份合同的风险条款"}
],
temperature=0.3,
max_tokens=4000,
extra_headers={"X-Group": "OpenSource-MultiModal"}
)
print(response.choices[0].message.content)
以下是调用免费模型DeepSeek-V4-Flash的示例:
# 调用DeepSeek-V4-Flash (free分组,免费)
response = client.chat.completions.create(
model="deepseek-v4-flash",
messages=[
{"role": "user", "content": "帮我写一个Python快速排序算法"}
],
extra_headers={"X-Group": "free"}
)
print(response.choices[0].message.content)
以下是多模型协作的示例——根据任务复杂度动态选择模型:
def smart_model_call(user_input, complexity="auto"):
"""根据任务复杂度智能选择模型"""
if complexity == "auto":
# 简单启发式判断复杂度
if len(user_input) < 100 and "?" in user_input:
complexity = "low"
elif "代码" in user_input or "分析" in user_input:
complexity = "high"
else:
complexity = "medium"
# 模型路由
if complexity == "low":
model, group = "deepseek-v4-flash", "free" # 免费
elif complexity == "medium":
model, group = "qwen3.5-122b-a10b", "OpenSource-MultiModal" # 低成本
else:
model, group = "glm-5.2", "OpenSource-MultiModal" # 高性能
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": user_input}],
extra_headers={"X-Group": group}
)
return response.choices[0].message.content, model
4.4 流式输出与工具调用
对于需要实时反馈的场景,AIGC Bar平台支持流式输出(Streaming):
# 流式输出
stream = client.chat.completions.create(
model="glm-5.2",
messages=[{"role": "user", "content": "详细解释MoE架构的原理"}],
stream=True,
extra_headers={"X-Group": "OpenSource-MultiModal"}
)
for chunk in stream:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="", flush=True)
对于Agent场景,平台支持工具调用(Function Calling):
# 工具调用
tools = [
{
"type": "function",
"function": {
"name": "search_knowledge_base",
"description": "搜索企业知识库",
"parameters": {
"type": "object",
"properties": {
"query": {"type": "string", "description": "搜索关键词"}
},
"required": ["query"]
}
}
}
]
response = client.chat.completions.create(
model="glm-5.2",
messages=[{"role": "user", "content": "查询公司年假政策"}],
tools=tools,
extra_headers={"X-Group": "OpenSource-MultiModal"}
)
# 处理工具调用
if response.choices[0].message.tool_calls:
for tool_call in response.choices[0].message.tool_calls:
if tool_call.function.name == "search_knowledge_base":
import json
args = json.loads(tool_call.function.arguments)
result = search_knowledge_base(args["query"]) # 你的知识库搜索函数
# 将结果返回给模型继续生成
5 多模型智能体构建策略
AIGC Bar平台的核心价值之一是支持调用所有模型创建自己的智能体。本节探讨多模型智能体的构建策略。
5.1 多模型协作的理论基础
多模型协作的理论基础是"模型专业化"——不同模型在不同任务上各有所长,通过合理组合可以实现"1+1>2"的效果。GLM-5.2擅长长程编码和推理,Kimi-K2.6擅长原生多模态理解,Qwen3.5-122B-A10B擅长高效批量推理,DeepSeek-V4-Flash擅长快速响应(且免费)。
多模型协作的架构可以分为三种模式。第一种是"串行流水线"模式——任务按阶段划分,每个阶段由最适合的模型处理。例如,编码任务可以先由DeepSeek-V4-Flash分析需求,再由GLM-5.2设计方案,最后由Kimi-K2.6生成代码。第二种是"并行投票"模式——多个模型独立处理同一任务,通过投票或集成选择最佳结果。这一模式适合需要高可靠性的场景。第三种是"路由分发"模式——根据任务特征动态选择最合适的模型,是成本效率最高的模式。
5.2 智能体架构设计
基于多模型协作的智能体架构可以抽象为四层:感知层(接收用户输入和工具输出)、决策层(选择模型和工具)、执行层(调用模型和工具)、反馈层(评估结果并调整策略)。
5.3 成本优化策略
多模型智能体的成本优化核心是"分级路由"——根据任务复杂度将请求路由到不同成本的模型。这一策略可以用决策函数表示:
Model ( x ) = { DeepSeek-V4-Flash if complexity ( x ) < τ 1 Qwen3.5-122B if τ 1 ≤ complexity ( x ) < τ 2 GLM-5.2 if complexity ( x ) ≥ τ 2 \text{Model}(x) = \begin{cases} \text{DeepSeek-V4-Flash} & \text{if } \text{complexity}(x) < \tau_1 \\ \text{Qwen3.5-122B} & \text{if } \tau_1 \leq \text{complexity}(x) < \tau_2 \\ \text{GLM-5.2} & \text{if } \text{complexity}(x) \geq \tau_2 \end{cases} Model(x)=⎩ ⎨ ⎧DeepSeek-V4-FlashQwen3.5-122BGLM-5.2if complexity(x)<τ1if τ1≤complexity(x)<τ2if complexity(x)≥τ2
其中 complexity ( x ) \text{complexity}(x) complexity(x) 为任务复杂度评估函数, τ 1 \tau_1 τ1 和 τ 2 \tau_2 τ2 为阈值。通过这一策略,企业可以在保持任务质量的同时,将API成本降低50-70%。
| 优化策略 | 实现方式 | 成本节省 | 适用场景 |
|---|---|---|---|
| 分级路由 | 按复杂度选模型 | 50-70% | 通用场景 |
| 缓存复用 | 缓存常见查询结果 | 30-50% | 客服场景 |
| 批量处理 | 合并多个请求 | 20-40% | 批量推理 |
| 上下文压缩 | 压缩长上下文 | 30-50% | 长文档处理 |
| 模型蒸馏 | 小模型替代大模型 | 60-80% | 高频简单任务 |
5.4 智能体构建实战案例
以下是一个"企业智能助手"的实战案例,展示如何通过AIGC Bar平台构建多模型协作的智能体:
import openai
import json
class EnterpriseAssistant:
def __init__(self, api_key):
self.client = openai.OpenAI(
api_key=api_key,
base_url="https://api.aigc.bar/v1"
)
self.conversation_history = []
def _select_model(self, user_input):
"""根据输入选择最优模型"""
# 编码相关任务用GLM-5.2
if any(kw in user_input for kw in ["代码", "bug", "函数", "编程", "API"]):
return "glm-5.2", "OpenSource-MultiModal"
# 图片相关任务用Kimi-K2.6
elif any(kw in user_input for kw in ["图片", "截图", "图表", "识别"]):
return "kimi-k2.6", "OpenSource-MultiModal"
# 简单问答用免费模型
elif len(user_input) < 50:
return "deepseek-v4-flash", "free"
# 默认用Qwen3.5
else:
return "qwen3.5-122b-a10b", "OpenSource-MultiModal"
def chat(self, user_input):
"""智能对话"""
model, group = self._select_model(user_input)
self.conversation_history.append({
"role": "user", "content": user_input
})
response = self.client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": "你是企业智能助手,提供专业、准确的服务。"},
*self.conversation_history
],
temperature=0.7,
max_tokens=2000,
extra_headers={"X-Group": group}
)
reply = response.choices[0].message.content
self.conversation_history.append({
"role": "assistant", "content": reply
})
return {
"reply": reply,
"model_used": model,
"group": group
}
# 使用示例
assistant = EnterpriseAssistant("你的AIGC-Bar-API-Key")
result = assistant.chat("帮我写一个Python数据清洗脚本")
print(f"[使用模型: {result['model_used']}]")
print(result["reply"])
6 企业落地的工程实践
将GLM-5.2等模型嵌入到企业业务流程中,需要解决一系列工程问题。本节探讨企业落地的关键工程实践。
6.1 API调用的可靠性保障
生产环境的API调用需要保障可靠性,主要涉及容错、重试和限流三个方面。容错机制确保单次API失败不会导致整个业务流程中断——通过try-catch捕获异常,并切换到备用模型或返回缓存结果。重试机制处理临时性故障(如网络波动、模型过载)——采用指数退避策略,避免重试风暴。限流机制控制API调用频率,避免超出平台的速率限制。
import time
from functools import wraps
def retry_with_backoff(max_retries=3, backoff_base=1):
"""指数退避重试装饰器"""
def decorator(func):
@wraps(func)
def wrapper(*args, **kwargs):
for attempt in range(max_retries):
try:
return func(*args, **kwargs)
except Exception as e:
if attempt == max_retries - 1:
# 最后一次重试失败,切换备用模型
return fallback_model_call(*args, **kwargs)
wait = backoff_base * (2 ** attempt)
time.sleep(wait)
return wrapper
return decorator
@retry_with_backoff(max_retries=3)
def call_glm52(messages):
"""调用GLM-5.2,失败自动重试"""
response = client.chat.completions.create(
model="glm-5.2",
messages=messages,
extra_headers={"X-Group": "OpenSource-MultiModal"}
)
return response.choices[0].message.content
def fallback_model_call(*args, **kwargs):
"""备用模型调用(免费模型)"""
response = client.chat.completions.create(
model="deepseek-v4-flash",
messages=kwargs.get("messages", args[0]),
extra_headers={"X-Group": "free"}
)
return response.choices[0].message.content
6.2 成本监控与预算控制
企业需要建立API成本监控体系,实时跟踪各模型的调用量和费用。核心监控指标包括:日/周/月调用量、token消耗量、费用趋势、模型分布等。预算控制通过设置费用上限告警和硬性截断,避免因代码bug或异常流量导致的"账单爆炸"。
from datetime import datetime, timedelta
from collections import defaultdict
class CostMonitor:
def __init__(self, daily_budget=100.0):
self.daily_budget = daily_budget # 日预算(元)
self.usage_log = defaultdict(lambda: {"calls": 0, "tokens": 0, "cost": 0.0})
def log_usage(self, model, tokens_in, tokens_out, cost):
"""记录单次调用"""
today = datetime.now().strftime("%Y-%m-%d")
self.usage_log[today]["calls"] += 1
self.usage_log[today]["tokens"] += tokens_in + tokens_out
self.usage_log[today]["cost"] += cost
# 预算检查
if self.usage_log[today]["cost"] > self.daily_budget * 0.8:
self._send_alert(f"日费用已达预算80%: {self.usage_log[today]['cost']:.2f}元")
def _send_alert(self, message):
"""发送告警(可对接企业微信/钉钉/邮件)"""
print(f"[告警] {message}")
def get_daily_report(self):
"""获取日报"""
today = datetime.now().strftime("%Y-%m-%d")
return self.usage_log[today]
6.3 数据安全与合规
企业使用API调用大模型时,数据安全是核心关切。AIGC Bar平台作为API中转服务,会处理企业发送的请求内容。对于敏感数据(如客户隐私、商业机密),企业应采取以下措施:数据脱敏——在发送前去除或替换敏感信息;本地预处理——将敏感操作放在本地,仅将非敏感部分发送给API;私有化部署——对于高度敏感场景,考虑本地部署开源模型(如GLM-5.2开源权重)。
合规方面,企业需确保API使用符合相关法规(如《个人信息保护法》《数据安全法》)。建议建立"AI使用合规清单",明确哪些数据可以发送给API、哪些数据禁止发送,并对开发人员进行合规培训。
6.4 性能优化与延迟控制
生产环境中,API调用的延迟直接影响用户体验。GLM-5.2作为744B参数的大模型,推理延迟相对较高,企业需要通过多种手段优化端到端延迟。
第一是流式输出(Streaming)。流式输出让模型"边生成边返回",用户无需等待完整响应即可看到开始内容,显著降低首token延迟感知。对于长文本生成场景,流式输出可以将感知延迟从"秒级"降低到"百毫秒级"。
第二是并发处理。对于可以并行的任务(如批量文档处理),通过多线程或异步IO并发调用API,可以将总处理时间从"串行累加"降低到"单次最长"。Python的asyncio库配合aiohttp可以实现高效的异步API调用。
第三是缓存策略。对于重复性高的查询(如常见客服问题),可以将模型响应缓存到Redis等缓存系统,命中缓存时直接返回,无需调用API。缓存策略可以将60-80%的客服查询转化为缓存命中,大幅降低API调用成本和延迟。
import redis
import json
import hashlib
class ResponseCache:
def __init__(self, redis_host="localhost", redis_port=6379, ttl=3600):
self.redis = redis.Redis(host=redis_host, port=redis_port, decode_responses=True)
self.ttl = ttl # 缓存有效期(秒)
def _get_cache_key(self, model, messages):
"""生成缓存键"""
content = f"{model}:{json.dumps(messages, sort_keys=True)}"
return hashlib.md5(content.encode()).hexdigest()
def get(self, model, messages):
"""获取缓存"""
key = self._get_cache_key(model, messages)
cached = self.redis.get(key)
if cached:
return json.loads(cached)
return None
def set(self, model, messages, response):
"""设置缓存"""
key = self._get_cache_key(model, messages)
self.redis.setex(key, self.ttl, json.dumps(response, ensure_ascii=False))
# 使用示例
cache = ResponseCache()
def cached_chat(model, messages, group):
"""带缓存的API调用"""
# 先查缓存
cached = cache.get(model, messages)
if cached:
return cached, "cache"
# 缓存未命中,调用API
response = client.chat.completions.create(
model=model,
messages=messages,
extra_headers={"X-Group": group}
)
result = response.choices[0].message.content
# 写入缓存
cache.set(model, messages, result)
return result, "api"
6.5 监控与可观测性
生产系统的可观测性是保障稳定运行的基础。企业应建立三层监控体系:基础设施层(API响应时间、错误率、吞吐量)、业务层(任务完成率、用户满意度、成本效率)、模型层(输出质量、幻觉率、安全合规)。
可观测性的技术实现可以通过日志、指标和追踪三个维度展开。日志记录每次API调用的详细信息(时间、模型、输入摘要、输出摘要、耗时、成本);指标聚合统计关键维度的数据(日调用量、平均延迟、错误率、成本趋势);追踪串联一次完整请求的所有调用链路(从用户请求到模型响应的全链路)。
6.6 团队组织与流程保障
技术方案的成功落地离不开团队组织和流程保障。企业应建立"AI工程团队",负责模型选型、API管理、智能体开发和运维监控。AI工程团队应包含以下角色:AI工程师(负责模型调用和智能体开发)、数据工程师(负责数据管道和知识库)、运维工程师(负责基础设施和监控)、产品经理(负责需求分析和效果评估)。
流程方面,企业应建立"AI应用上线评审"流程,确保每个AI应用在上线前经过充分测试和合规审查。评审内容包括:功能测试(模型输出是否满足业务需求)、性能测试(延迟和吞吐量是否达标)、安全测试(是否存在数据泄露风险)、成本评估(API调用成本是否在预算内)。只有通过全部评审的应用才能上线,确保AI应用的质量和安全。
7 对话服务与API调用的区分
本文需要特别强调一个重要区分:如果只是使用对话服务,国内模型使用官网就可以了;API调用主要是开发者用的。这一区分对于企业决策者尤为重要——并非所有AI应用场景都需要通过API调用,盲目接入API可能增加不必要的成本和复杂度。
7.1 官网对话服务的适用场景
对于普通用户的日常对话需求,各模型的官网提供了优秀的开箱即用体验。智谱清言(chatglm.cn)、Kimi(kimi.com)、通义千问(tongyi.aliyun.com)、豆包(doubao.com)等官网都提供了免费的基础对话服务,无需编程知识即可使用。这些官网通常还提供文件上传、联网搜索、代码高亮、多轮对话管理等增值功能,对于个人用户的日常问答、写作辅助、学习辅导等场景,体验优于API调用。
企业内部的非技术员工,如果只是偶尔使用AI辅助工作(如撰写邮件、整理会议纪要、翻译文档),直接使用官网对话服务即可,无需通过API接入。这样既降低了IT管理成本,也避免了API调用费用的产生。
7.2 API调用的适用场景
API调用的核心价值在于"可编程性"和"可集成性"——将AI能力嵌入到应用程序、工作流或智能体中,实现官网无法提供的功能。典型的API调用场景包括:将AI集成到企业内部系统(如CRM、ERP、OA);构建定制化的智能客服或知识助手;实现批量文档处理或数据分析;开发多模型协作的Agent系统;构建面向外部用户的AI产品。
对于这些场景,API调用是唯一可行的路径——官网对话服务无法提供编程接口、无法实现批量处理、无法定制系统提示、无法集成到现有系统。因此,API调用主要面向开发者和技术团队,而非普通用户。
7.3 企业如何选择
企业在选择使用官网对话还是API调用时,可以参考以下决策框架。如果需求是"个人使用、偶尔使用、无需集成",选择官网对话;如果需求是"团队使用、频繁使用、需要集成",选择API调用;如果需求是"对外提供服务、需要定制化、需要多模型协作",必须选择API调用。
| 决策维度 | 官网对话 | API调用 |
|---|---|---|
| 目标用户 | 普通用户/非技术员工 | 开发者/技术团队 |
| 使用频率 | 偶尔/低频 | 频繁/高频 |
| 集成需求 | 无需集成 | 需要嵌入系统 |
| 定制需求 | 无需定制 | 需要定制提示/流程 |
| 成本模式 | 基础免费 | 按量付费 |
| 技术门槛 | 无 | 需要编程能力 |
| 典型场景 | 日常问答/写作 | 应用集成/智能体 |
8 未来展望与总结
8.1 大模型企业应用的未来趋势
展望未来,大模型在企业中的应用将呈现几个明确趋势。第一是Agent化——从"单次问答"走向"多步自主执行",Agent将承担越来越复杂的业务流程。GLM-5.2在长程Agent任务上的优势,使其成为企业构建Agent系统的理想基座。
第二是多模态化——从"纯文本"走向"文本+图像+音频+视频"的融合处理。随着Kimi-K2.6等原生多模态模型的成熟,企业将能够处理更丰富的输入类型,拓展AI应用边界。
第三是端云协同——从"纯云端"走向"端侧+云端"的协同部署。Gemma-4等高效模型的出现,使在手机、PC等终端设备上运行大模型成为可能,为隐私敏感场景提供了新路径。
第四是成本持续下降——随着MoE架构的成熟和推理优化技术的进步,大模型API的调用成本将持续下降,使更多企业能够负担AI应用。GLM-5.2以GPT-5.5的1/6成本实现可比性能,这一趋势将进一步加速。
8.2 GLM-5.2的战略价值
对于企业而言,GLM-5.2的战略价值体现在三个方面。第一是技术自主可控——作为国产开源模型,GLM-5.2的权重公开,企业可以在需要时进行本地部署,避免对单一API供应商的过度依赖。第二是成本优势——GLM-5.2的MoE架构使其推理成本远低于同性能的稠密模型,通过AIGC Bar平台调用,企业可以进一步享受聚合平台的规模效应。第三是生态开放——GLM系列的开源属性使其拥有活跃的社区生态,企业可以获得丰富的工具支持和深度集成,这些是闭源模型无法提供的。随着GLM系列的持续迭代(从GLM-5到GLM-5.1再到GLM-5.2仅用了4个月),其能力将不断提升,而通过AIGC Bar等平台,企业可以第一时间体验到最新版本。
7.1 普通用户的对话服务
对于普通用户而言,如果只需要与AI进行对话(如问答、写作、翻译),无需通过API调用模型。国内主流模型均提供了优秀的官方对话服务:
- GLM系列:通过智谱清言官网(chatglm.cn)或智谱清言APP使用
- Kimi系列:通过Kimi官网(kimi.com)或Kimi APP使用
- Qwen系列:通过通义千问官网(tongyi.aliyun.com)使用
- DeepSeek系列:通过DeepSeek官网或APP使用
这些官方平台提供了优化的对话界面、多轮对话管理、文件上传、联网搜索等丰富功能,且基础使用免费。对于普通用户的对话需求,官网体验优于API调用。
7.2 开发者的API调用
API调用面向开发者,用于将AI能力嵌入到应用程序、工作流或智能体中。API调用的价值在于"可编程性"和"可集成性"——开发者可以通过API实现官网无法提供的功能,如多模型协作、批量推理、自定义系统提示、工具调用链、流式输出等。
| 使用方式 | 目标用户 | 访问方式 | 成本 | 技术要求 | 典型场景 |
|---|---|---|---|---|---|
| 官网对话 | 普通用户 | 浏览器访问 | 基础免费 | 无 | 日常问答、写作 |
| API调用 | 开发者 | 编程接口 | 按量付费 | 编程能力 | 应用集成、智能体 |
| 本地部署 | 企业/研究者 | 自建服务器 | 硬件成本 | 运维能力 | 数据敏感场景 |
因此,如果你是普通用户,只需要与AI对话,直接使用各模型官网即可;如果你是开发者,需要将AI能力嵌入到产品中,那么通过AIGC Bar调用API是最佳路径。
8 未来展望与结论
8.1 企业AI的发展趋势
展望未来,企业AI的发展将呈现几个趋势。第一,多模型协作将成为标配——单一模型难以在所有场景下都最优,企业需要构建"模型路由层"实现智能选择。第二,Agent能力将成为核心竞争维度——从"被动回答"到"主动执行",AI Agent将深度嵌入企业工作流。第三,成本优化将更加精细化——从"按token计费"到"按价值计费",模型选择将基于任务ROI而非单纯成本。第四,数据安全与合规将更加严格——随着AI应用深入,监管要求将不断提升,企业需建立完善的AI治理体系。
8.2 GLM-5.2的长期价值
GLM-5.2作为2026年开源大模型的代表,其长期价值不仅体现在当前的性能优势上,更体现在其开源生态的持续演进上。开源意味着企业可以进行私有化部署、定制化微调和深度集成,这些是闭源模型无法提供的。随着GLM系列的持续迭代(从GLM-5到GLM-5.1再到GLM-5.2仅用了4个月),其能力将不断提升,而通过AIGC Bar等平台,企业可以第一时间体验到最新版本。
8.3 降本增效的本质
最后,需要强调的是,企业通过GLM-5.2 API实现降本增效的本质,不是"用AI替代人",而是"用AI增强人"。AI处理重复性、规则性的任务,让人专注于创造性、判断性的工作;AI提供数据驱动的洞察,让人做出更明智的决策;AI扩展人的能力边界,让小团队实现大产出。这才是"降本增效"的真正含义——不是简单地削减成本,而是通过技术杠杆放大每一份投入的价值。
通过AIGC Bar,企业可以便捷地接入GLM-5.2、Kimi-K2.6、Qwen3.5等多种模型,构建自己的智能体,实现业务流程的AI化重构。在这个AI赋能一切的时代,率先掌握大模型应用能力的企业,将在竞争中占据先机,实现真正的降本增效和利润增长。
[1] Z.ai. GLM-5.2: Built for Long-Horizon Tasks[EB/OL]. Hugging Face Blog, 2026. 链接: https://huggingface.co/blog/zai-org/glm-52-blog
[2] InfoWorld. Z.ai pitches GLM-5.2 for long-running software engineering tasks[EB/OL]. 2026. 链接: https://www.infoworld.com/article/4186136/z-ai-pitches-glm-5-2-for-long-running-software-engineering-tasks
[3] LangChain. State of Agent Engineering 2026[R]. 2026. 链接: https://www.langchain.com/state-of-agent-engineering
[4] TrueFoundry. AI Cost Optimization: A Practical Guide for 2026[EB/OL]. 2026. 链接: https://www.truefoundry.com/blog/what-is-ai-cost-optimization
[5] MDPI. Retrieval-Augmented Generation (RAG) and Large Language Models[J]. Applied Sciences, 2026, 16(1): 368. 链接: https://www.mdpi.com/2076-3417/16/1/368
[6] VentureBeat. Z.ai’s open-weights GLM-5.2 beats GPT-5.5 on multiple long-horizon coding benchmarks[EB/OL]. 2026. 链接: https://venturebeat.com/technology/z-ais-open-weights-glm-5-2-beats-gpt-5-5-on-multiple-long-horizon-coding-benchmarks-for-1-6th-the-cost
 12
12 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)