
【OpenClaw】通过 Nanobot 源码学习架构---(6)Skills
0x00 概要
OpenClaw 应该有40万行代码,阅读理解起来难度过大,因此,本系列通过Nanobot来学习 OpenClaw 的特色。
Nanobot是由香港大学数据科学实验室(HKUDS)开源的超轻量级个人 AI 助手框架,定位为"Ultra-Lightweight OpenClaw"。非常适合学习Agent架构。
Skill(技能)是将特定领域的专业知识、工作流程和最佳实践打包成可复用的指令模块,嵌入到 AI 的上下文中,使 AI 在处理相关任务时能够自动激活并运用这些专业能力。
简单来说,Skill 就是一个教 AI 怎么干活的 "技能手册。通过将领域知识、标准流程与执行工具封装为可插拔的模块,Skill让智能体首次实现了专业能力的沉淀、共享与持续优化,从而真正从“自动化执行”迈向“专业化思考与行动”。
Skill 的本质,是把「隐性知识」变成「显性规程」。
注:本系列借鉴的文章过多,可能在参考文献中有遗漏的文章,如果有,还请大家指出。
0x01 原理
本部分很多内容参考于:AI Agent系列|深入解析Function Calling、MCP和Skills的本质差异与最佳实践
1.1 Function Calling
Function Calling的本质:LLM要实现工具调用,实际上最需要的内容只有:函数名、参数要求,以及一个description。然而,在Function Calling的框架下,用户面临几个问题:
- 如何融入到现有的系统中。
- 如何在尽可能的准确的前提下,能让用户能用文字(而非代码)指导模型按照特定的流程和规则执行任务?
- 所有知识都写入prompt,会造成上下文爆炸。
1.2 解决方案
上述问题的解决方案就是MCP和Skills。
MCP和Skills都是基于Function Calling的,它们只是在Function Calling这个基础能力之上的不同应用方式。
-
MCP:让AI“能做到”,执行工具,读写数据。
-
Skill:教AI“怎么做”,是给AI的操作手册(告诉模型一步一步 How to do),包括流程、标准、策略,脚本,代码,Skills 不是 “训练进模型”,而是写进 System Prompt,构建上下文时自动读进去,LLM 靠阅读理解就会用。
1.2.1 如何融入到现有的系统中?
MCP是一种用于规范大模型与外部能力交互方式的协议。如果说 Tools 解决的是“模型如何调用一个函数”,那么 MCP 解决的是“模型如何与一个长期存在、可复用的能力服务交互”。
MCP的核心是解决与既有系统的接驳问题,MCP的价值在于它提供了一套标准化的接驳协议,让不同的工具和数据源能够以统一的方式被LLM使用。本质上,MCP更偏重是一套接驳标准(只是在Function Calling的基础上,增加了一层JSON-RPC协议转换),而不是唯一的接驳方式。
或者说,MCP 更像是 API,Agent 只关心该 API 提交什么「参数」、得到什么「结果」。
1.2.2 如何指导模型按照特定的流程和规则执行任务?
Skills提供一个方式,让用户可以用文字定义指令、脚本和资源,形成可复用的任务流程。
Skills则实际上是一个sub-agent的包装:
- Skills只是在Function Calling之上的一个巧妙应用:把"加载文档"这个操作封装成一个函数,让模型在需要时自动去查找和加载固定的skills文档。
- Skills 让用户可以用文字来写流程,替代了过去在MCP调用的函数里用代码写的一套串接各种API的逻辑流程。这种方式可以增强流程的环境适应性——因为模型可以根据实际情况动态调整策略,处理不确定性,理解自然语言意图。Skills能支持更复杂的流程定义——通过SKILL.md文档告知LLM如何组合多个接口调用,所以长流程任务的成功率会更高。
1.2.3 如何解决上下文爆炸
可以使用双层加载范式。第一层: 系统提示中放技能名称 (低成本)。第二层: tool_result 中按需放完整内容。
System prompt (Layer 1 -- always present):
+--------------------------------------+
| You are a coding agent. |
| Skills available: |
| - git: Git workflow helpers | ~100 tokens/skill
| - test: Testing best practices |
+--------------------------------------+
When model calls load_skill("git"):
+--------------------------------------+
| tool_result (Layer 2 -- on demand): |
| <skill name="git"> |
| Full git workflow instructions... | ~2000 tokens
| Step 1: ... |
| </skill> |
+--------------------------------------+
1.3 Skills:大模型的经验库
Skill = 可复用的工作方法,就是把专家经验固化下来,让每次执行都按最佳实践来,即把人类经验性的任务,变成 AI 可复用的模块。
Skills是项目保持精简的扩展机制。不是把所有可能的功能都塞进核心代码库,而是把新能力定义为 SKILL.md 文件——用 Markdown 写的指令文档,教智能体如何使用特定工具或执行特定工作流。
Skill 的本质是 Prompt + Tools。
- Prompt: 告诉 LLM “我是谁”、“我能做什么”、“什么时候用我”。
- Tools: 具体的函数实现(通常是 CLI 命令或 API 调用)。
tool 是能力,skill 是方法:
- Tools 是能力的低层接口(API),tool 更像“手和脚”,是 agent 真正可以直接调用的操作能力,tool 解决的是“能不能做”。
- Skills 是任务的高级模板(SOP + Tools),skill 更像“作战手册”或者“标准流程”。所以,skill 解决的是:应该怎么做,按什么步骤做,什么时候用这套流程最合适。
| 特性 | Function Calling | Skills |
|---|---|---|
| 定位 | 原子能力 | 任务模块 |
| 构成 | 仅包含函数定义(JSON Schema) | 包含 Prompt + 代码 + 流程定义 |
| 关注点 | 我可以调用这个 API | 我知道如何完成这项工作 |
| 上下文 | 无状态,通常一次性调用 | 有状态,通过 Prompt 引导多步推理 |
| 复用性 | 代码级复用 | 业务逻辑级复用 |
1.3.1 Skill的核心原理
Skill的核心在于“模块化封装”与“渐进式披露”。它的出现本质上是工程化手段的伟大创新,其核心目标是更高效地释放和驾驭大模型已有的潜力。它并非因为大模型突然变得“更聪明”,而是它将完成特定专业任务所需的所有要素(知识、流程、工具)打包成一个独立模块,助力大模型从漫无边际的“流淌”,转向目标明确、步骤清晰的“专业执行”。
Skill的关键创新在于:
- 运行机制:智能体在初始时仅预载轻量的技能索引目录。当识别到具体任务需求后,才动态加载相应技能的详细指令与资源。这种“按需加载”模式,实现了对上下文窗口的极致利用。
- 累积能力:Skill 把复杂任务沉淀成可调用、可复用、可组合的“技能模块,Agent 的落地,正在从单次问答,转向可复用能力的积累。
- 攻克专业化匮乏:它将隐性的领域专家知识(如财务分析SOP、代码审查清单)显性化、结构化,成为模型可理解和执行的具体指令,让通用大模型获得了深度专业能力。它不是在给 AI 增加新的「能力」(AI 本身已经很强),而是在给 AI 增加领域知识和操作规程——告诉它:在这个特定场景下,应该怎么做,用什么工具,遵守什么约束。
- 化解上下文爆炸:相比传统上将全部知识塞进提示词或固化在冗长workflow中的方式,Skill的“按需加载”机制在复杂任务中可降低40%-60%的上下文消耗。
1.3.2 Skills 与架构选型
我们思考下:当 Single Agent 遇到知识瓶颈时,除了拆分成 Multi-Agent,还有没有更轻量的路径?
Skill 机制给出的答案是——回归 Single Agent 架构本体,但赋予其极强的动态扩展能力。这种模式让单个 Agent 具备了"局部专业化"的能力:它在宏观上保持统一的记忆和状态,微观上却能像调用工具一样灵活掌握成千上万种垂直领域的专业知识。
因此,架构选择的原则可以明确为:
能用 Single Agent 解决的,绝不上复杂架构。 遇到知识瓶颈,优先引入 Agent Skills 机制,通过动态渐进式加载 Skills 来扩展能力边界。
为什么 Skills 能保持上下文一致性?
我们从 Prompt 工程的角度拆解其机制:
| 层级 | 特征 | 作用 |
|---|---|---|
| System Prompt | 恒定不变 | 核心系统指令(人设身份、基础要求)保持稳定,确保模型认知的统一性 |
| User Prompt | 动态注入 | Skills 内容以"用户输入"或"工具返回结果"的形式渐进式披露 |
这对模型而言意味着什么?就像是用户在对话过程中不断提供新的参考资料(Reference Material),而不是强行改变它的"人设"。打个比方:Multi-Agent 是让模型"精神分裂"成多个人格轮流登场;而 Skills 是让同一个专家在需要时查阅不同的专业手册——人格不变,知识动态扩展。
Agent Skills 架构的三重收益
1. 低成本的知识注入
真正实现了将海量领域知识"说明书化"——模型按需阅读,无需全量预加载。这比 Multi-Agent 更轻量,也比 RAG 更精准(RAG 是检索后被动接收,Skills 是主动调用并明确用途)。
2. 全局上下文一致性
由于始终由同一个主 Agent 执行(类似 Multi-Agent 里的 Orchestrator,但没有路由层),它完整知晓:
- 已执行的步骤
- 已读取的 Agent Skills
- 当前的任务状态
这彻底消除了 Multi-Agent 中的信息割裂和重复劳动问题——没有路由错误的风险,也没有子 Agent 间的上下文盲区。
3. 规避 Context 爆炸
通过"读一点、做一点、再读一点"的流式处理,有效控制了瞬时上下文长度。相比 Multi-Agent 每个子节点都要维护独立 System Prompt 的冗余,Skills 只在需要时加载,用完即释放。
本质洞察
Skill 用文件系统的结构化能力替代了复杂的网络通信协议,用渐进式的信息披露替代了暴力的全量注入。这不是简单的"功能替代",而是架构哲学的转变:从"用复杂度换能力"走向"用编排精度换效率"。
1.3.3 Skill的结构
Skill 不是“一个统一目录里的插件列表”,而是一套分层发现、按 workspace 和共享范围组织起来的工作流系统。Skill 通常包含三层结构(三级加载机制):
- 元数据(始终加载):
- 技能的描述、功能与接口定义。
- 这些信息永远被加载在上下文,约 100 词。
- AI 用这个判断是否触发 Skill。
- 指令(触发时加载):
- 结构化的专业操作步骤与判断逻辑。
- Skill 被触发后才加载,建议 < 500 行。
- 资源(按需加载):
- 执行所需的数据、模板或工具链接。
- AI 判断需要时才加载,无大小限制,因为脚本可以直接执行。比如,
references/负责放详细说明,scripts/负责放真正复用的脚本。
所以 skill 不是“只有一个 markdown 文件”,而是一组围绕某种任务组织起来的资源,或者说,能力即文件(Capability as Files)。复用 + 资源需求 = Skill。
下面展示了一个典型的Skill的目录结构,通过 元数据 → 指令 → 代码与资源 这三层结构(Skills 本质上只是一种文件结构约定),一个 skill 不仅能被 Claude 正确识别和触发,还能真正完成从“理解需求”到“执行任务”的完整闭环。
some-repository/
├── AGENTS.md # Permanent repository guidelines (recommended)
└── .agents/
└── skills/
├── rot13-encryption/ # AgentSkills standard (progressive disclosure)
│ ├── SKILL.md
│ ├── scripts/
│ │ └── rot13.sh
│ └── references/
│ └── README.md
├── another-agentskill/ # AgentSkills standard (progressive disclosure)
│ ├── SKILL.md
│ └── scripts/
│ └── placeholder.sh
└── legacy_trigger_this.md # Legacy/OpenHands format (keyword-triggered)
1.3.4 Skill vs Workflow vs Prompt
与Workflow相比,Skill代表了一种根本性的能力升级。其核心区别在于:
- Workflow是预先编排好的、线性的、固定路径的执行流程图,确保复杂任务能“稳定地做对”;
- Skill是模块化的、可组合的、按需调用的专业化能力包,旨在让智能体能够“专业地做对”。Skill以前者难以实现的知识封装与灵活调度,开启了智能体专业化与规模化应用的新阶段。Skill所代表的“能力模块化”与“知识工程化”方向,无疑是构建下一代专业化、高可靠智能体的关键路径。
Skill 与 Prompt 对比如下:
| 维度 | Prompt | Skill |
|---|---|---|
| 触发 | 手动粘贴 | 自动匹配 |
| 能力 | 仅文本 | 文档+脚本+模板 |
| 复用 | 低 | 高 |
| 上下文 | 每次完整加载 | 渐进式加载 |
1.3.5 场景
Skill 适合解决的三类问题:
- AI 没有的领域知识
- 重复性工作流
- 需要确定性执行的操作(与直接提示词相比,SKill强在可复用性和一致性)
不适合用 Skill 的情况
- 一次性任务:你只用这个工作流一次,写 Skill 的时间比直接做还长
- 高度个性化:每次需求都完全不同,没有可以固化的模式
- AI 已经很擅长:通用编码、写作、翻译等,AI 本身就有很强的默认行为,加了 Skill 反而可能画蛇添足
未来很多软件的核心资产可能是:一组高质量、可调用、可审计、可复用的 Agent Skills。Agent 的竞争,未来很可能会从“谁的模型分数更高”,逐渐转向:谁更擅长把能力沉淀成技能,谁更擅长把技能组织成工作流,谁更擅长让这些流程在真实业务里稳定运行。
0x02 SkillsLoader
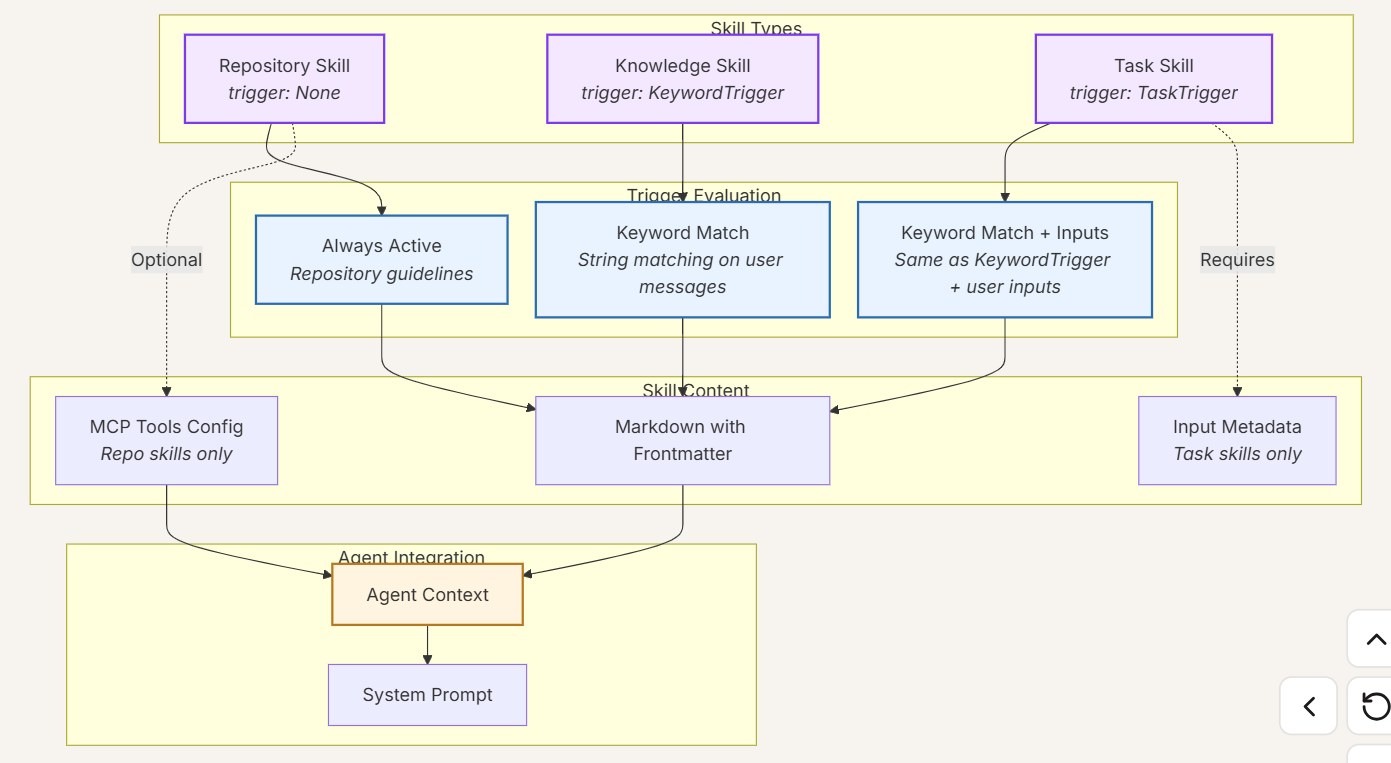
SkillsLoader 是 Nanobot 框架中负责智能体技能(Skills)管理的核心组件,核心职责是加载、管理、校验智能体的技能文件(以 SKILL.md 为载体),为智能体提供可用技能的检索、加载、校验能力,是 Agent 具备工具使用 / 任务执行能力的基础支撑模块。
- SkillsLoader:扫描插件
- ContextBuilder:把插件文档塞进上下文
- LLM:照着插件文档做任务
2.1 业界范式
我们引用 openhands 的文档来看看Skills管理系统的范式。
The Skill system has four primary responsibilities:
- Context Injection - Add specialized prompts to agent context based on triggers
- Trigger Evaluation - Determine when skills should activate (always, keyword, task)
- MCP Integration - Load MCP tools associated with repository skills
- Third-Party Support - Parse
.cursorrules,agents.md, and other skill formats
其架构图如下:
2.2 通用工作流程
我们来看看 Skill 的通用工作流程。
LLM 使用 Skills 的方式 = 阅读文档 + 调用工具。即,人负责说清目标和约束,Skill 封装实现标准(代码/流程),Agent 负责理解意图并调度执行。LLM不需要理解具体有哪些工具以及工具的用法是什么,只需要在需要使用某个工具时查看工具说明书,再把工具拿出来用。
Agent 的行为是Progressive Disclosure,渐进式批露:
- 初始化,这样只看 Skill 的 name 和 description, 扫一眼这个工具能干啥
- Agent 看技能摘要,确定 skill 和任务相匹配
- 发现需要用 → 调用
read_file读SKILL.md - 按文档里的步骤执行
具体工作流程是这样的:
- 初始化阶段:用户用文字定义指令、脚本和资源,打包成Skills(包含SKILL.md和可选的脚本、参考资料等)。LLM 在启动时会读取所有Skills的元数据(名称和描述),这些元数据被加载到模型的上下文中(系统提示词),Agent 在每次对话开始时就"知道"自己拥有哪些 Skill,但不知道具体内容。用于后续的意图匹配和技能触发判断。
- 发现阶段:当用户发起请求时,LLM 会根据请求内容,对比已加载的Skills元数据,判断是否需要使用某个Skill。这个判断过程本质上就是LLM根据上下文做决策,跟Function Calling中判断是否需要调用工具是一样的。需要注意两个要点:
- Agent 只在觉得自己搞不定时才找 Skill。简单的一步操作(比如"读一下这个文件"),即使 Description 完美匹配也可能不触发,因为 Agent 判断自己直接就能完成。
- Agent 天生偏向欠触发(under-triggering)。Description 要写得主动一点,把边界往外推。
- 加载阶段(Function Calling):如果 LLM 判断需要某个Skill(当用户的请求与某个 Skill 的 description 匹配),它会通过Function Calling机制调用一个专门的加载工具(类似
load_skill(skill_name)),将对应的SKILL.md文档内容读取并加载到当前上下文中。这一步完全依赖Function Calling的能力。 - 执行阶段(继续使用Function Calling):SKILL.md的内容(包含指令、流程、示例等)被加入到上下文后,LLM 按照文档中定义的指令执行任务。如果SKILL.md中定义了需要执行脚本(比如
scripts/rotate_pdf.py),LLM 还是会通过Function Calling调用执行脚本的函数。如果需要加载参考资料,同样是通过Function Calling调用读取文件的函数。
可以看到,整个Skills的运行过程,从加载文档、执行脚本到读取资源,每一步都离不开Function Calling。Skills并没有创造新的能力,它只是把Function Calling这个基础能力组织成了一个更易用的形式:让用户可以用文字定义流程,让LLM 自动发现和加载相关知识。 这也意味着 Skill 的激活本身会消耗 1-2 步工具调用。所以 description 写得准不准,直接影响 Token 消耗和响应速度,误触发意味着浪费,漏触发意味着能力缺失。
用户消息
↓
Agent 判断是否需调用某 Skill(基于请求内容匹配已加载的 skill_name 与 description)
↓
若需要,则通过 Function Calling 调用 load_skill(skill_name)
↓
将对应 SKILL.md 的内容注入当前上下文,作为执行指令依据(SOP)
↓
Agent 依照 SKILL.md 中定义的流程执行任务
↓
在执行过程中,按需通过 Function Calling:
• 调用 bash 执行附带脚本
• 调用 read_file 读取所需资源文件
↓
整合执行结果
2.3 Nanobot Skill 管理系统核心特色
Nanobot Skill 管理系统的核心特色如下:
- 双源优先级加载:支持「工作区技能(workspace)」和「内置技能(builtin)」双来源,工作区技能优先级更高(避免内置技能被覆盖);
- 需求校验机制:自动校验技能依赖(CLI 工具、环境变量),可过滤掉依赖不满足的不可用技能;
- 结构化技能管理:提供技能列表查询、单技能加载、技能摘要构建(XML 格式)、常驻技能筛选等能力,适配 Agent 上下文加载、渐进式技能使用的需求;
2.4 总体流程
SkillsLoader 相关的总体流程如下。
用户输入:“每小时检查一次Github星数”更多推荐
 8
8 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)