
Python 中文姓名生成器
·
前言:
最近在写一个小工具,需要批量生成测试用户的姓名。本来想直接在网上找现成的库,完全定制自己的名字库。于是就有了这篇文章。我会先从**标准库实现**讲起(不装任何第三方包),再介绍如何用专业的`mingzi`库生成更“真实”的姓名。两种方案各有优劣,你可以根据实际需求选择。
目录
一、核心思路:姓名是怎么生成的?
无论用哪种编程语言,姓名生成器的核心逻辑都大同小异:
-
准备姓名字库:建立姓氏列表和名字列表(或单字列表)
-
随机组合:从姓氏列表中随机选一个姓,从名字列表中随机选一个名,拼接起来
-
控制生成规则:可配置字数、性别、文化背景等参数
二、Python实现:简洁高效
Python凭借其简洁的语法和丰富的库支持,是实现姓名生成器最便捷的语言之一。
2.1基础原理实现
1. 准备两个列表:**姓氏库**(百家姓)和**名字库**(常用汉字)。 2. 随机选一个姓,随机决定名字字数(1~3个字),从名字库中抽取组合。 3. 过滤掉“张张”这种姓氏与单字名完全相同的组合。 4. 支持批量生成,可选是否去重。
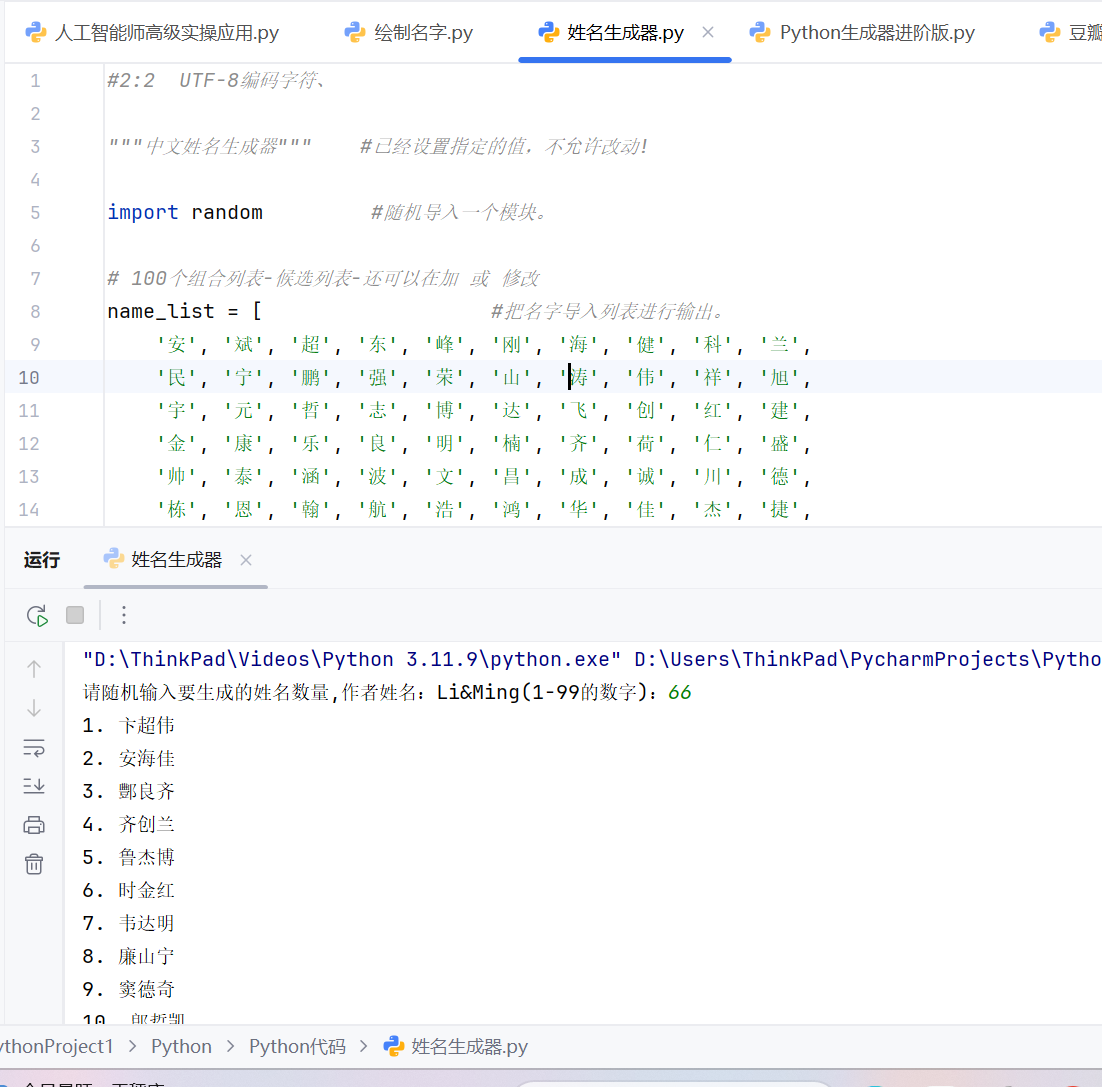
2.2代码如下
# -*- coding: utf-8 -*-
"""中文姓名生成器"""
import random
# 名字库(单字)
name_pool = [
'安', '斌', '超', '东', '峰', '刚', '海', '健', '科', '兰',
'民', '宁', '鹏', '强', '荣', '山', '涛', '伟', '祥', '旭',
'宇', '元', '哲', '志', '博', '达', '飞', '创', '红', '建',
'金', '康', '乐', '良', '明', '楠', '齐', '荷', '仁', '盛',
'帅', '泰', '涵', '波', '文', '昌', '成', '诚', '川', '德',
'栋', '恩', '翰', '航', '浩', '鸿', '华', '佳', '杰', '捷',
'俊', '凯', '立', '亮', '良', '龙', '林', '霖', '梅', '鸣',
'明', '鹏', '奇', '琦', '强', '荣', '胜', '帅', '泽', '中',
'仲', '卓', '子', '自', '宗', '祖', '尊', '宙', '诸', '珂', # 补上逗号
'夏', '简', '老', '忠', '齐', '孙', '张', '宇', '琳', '何'
]
# 百家姓(单姓)
surname_pool = [
'赵', '钱', '孙', '李', '周', '吴', '郑', '王', '冯', '陈',
'褚', '卫', '蒋', '沈', '韩', '杨', '朱', '秦', '尤', '许',
'何', '吕', '施', '张', '孔', '曹', '严', '华', '金', '魏',
'陶', '姜', '戚', '谢', '邹', '喻', '柏', '水', '窦', '章',
'云', '苏', '潘', '葛', '奚', '范', '彭', '郎', '鲁', '韦',
'昌', '马', '苗', '凤', '花', '方', '俞', '任', '袁', '柳',
'酆', '鲍', '史', '唐', '费', '廉', '岑', '薛', '雷', '贺',
'倪', '汤', '滕', '殷', '罗', '毕', '郝', '邬', '安', '常',
'乐', '于', '时', '傅', '皮', '卞', '齐', '康', '伍', '余',
'元', '卜', '顾', '孟', '平', '黄', '和', '穆', '杨', '李'
]
def generate_names(count, min_len=1, max_len=3, unique=False):
"""
生成指定数量的随机中文姓名。
:param count: 生成数量
:param min_len: 名字部分最少字数(默认1)
:param max_len: 名字部分最多字数(默认3)
:param unique: 是否要求生成的姓名不重复(默认False)
:return: 姓名列表
"""
names = []
attempts = 0
max_attempts = count * 100 # 防止死循环
while len(names) < count and attempts < max_attempts:
attempts += 1
surname = random.choice(surname_pool)
# 随机决定名字长度(1~3个字)
name_len = random.randint(min_len, max_len)
# 从名字库中随机抽取 name_len 个不同字组成名字
chosen = random.sample(name_pool, name_len)
given_name = ''.join(chosen)
# 如果名字长度为1且与姓氏相同,则重试(避免“张张”这类怪异组合)
if name_len == 1 and given_name == surname:
continue
full_name = surname + given_name
# 如果要求唯一性,检查是否已存在
if unique and full_name in names:
continue
names.append(full_name)
if len(names) < count:
print(f"警告:仅生成了 {len(names)} 个唯一姓名,请扩充名字库或放宽条件。")
return names
if __name__ == '__main__':
# 获取用户输入
try:
num = int(input("请输入要生成的姓名数量,作者姓名:LiMing&(1~99):"))
except ValueError:
print("请输入有效的整数!")
exit(1)
if num <= 0:
print("数量必须大于0!")
exit(1)
if num > 99:
print("单次生成数量不能超过99!")
exit(1)
# 生成姓名(这里默认不强制唯一,若需唯一可传参 unique=True)
name_list = generate_names(num, unique=False)
# 输出
for idx, name in enumerate(name_list, start=1):
print(f"{idx}. {name}")运行效果:
随机输入对应的1-99的数字即可跟姓氏列表的名字相组合。
2.3安装的库
进阶方案需安装:`pip install mingzi faker` pip install mingzi三、进阶方案:使用专业的 mingzi 库
如果你的需求是生成更贴近真实人口的姓名(姓氏分布符合统计、支持复姓、控制性别比例),那么强烈推荐使用mingzi库。
3.1 什么是 mingzi?
mingzi是一个专门为中文姓名设计的Python库,它内置了大量真实姓氏和名字,且姓氏分布比例参考了人口统计数据,生成结果更贴近现实。同时,它天然支持区分男/女姓名。
3.2 安装
pip install mingzi3.3 基本用法
from mingzi import mingzi
# 生成5个姓名,包含性别信息
result = mingzi(volume=5)
print(result)
# 输出示例:[['王雪', '女'], ['李宇', '男'], ['张静', '女'], ['刘洋', '男'], ['陈浩', '男']]
# 只生成姓名,不显示性别
names = mingzi(volume=5, show_gender=False)
print(names) # ['王雪', '李宇', '张静', '刘洋', '陈浩']
# 控制女性比例(70%为女性)
names = mingzi(volume=10, female_rate=0.7)3.4 如何集成到你的项目?
如果你喜欢mingzi的真实感,但想保留自己的主程序交互逻辑,只需替换生成函数:
from mingzi import mingzi
def generate_names_with_mingzi(count):
return mingzi(volume=count, show_gender=False)更多推荐
 11
11 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)