
基于 MySQL + Python 的京东搜索行为分析增量导入优化实战
从三层数仓建模、LOAD DATA 批量入库、增量归档到 Power BI 看板,完整复盘一个可复用的数据分析模块。
一、项目背景与优化目标
这套项目的原始数据主要包含两类:一类是 1200 万级商品维表,另一类是搜索候选行为和历史行为明细。最初的痛点主要有三个:
- 图形化工具导入超大 TXT 文件速度慢
- 行为字段里存在大量下划线拼接的多值列,无法直接落库查询
- 增量导入后还要继续支持 BI 看板查看累计结果
因此这次优化的目标很明确:
- 第一次全量导入要快
- 后续增量导入不能覆盖历史行为数据
- 导入完成后要能直接重建漏斗分析、用户分层和类目转化三类看板
二、MySQL 表设计:DWD → DWS → ADS 三层架构
为了避免千万级大表在 BI 查询时直接 JOIN 和 GROUP BY,这里采用了 DWD 明细层、DWS 汇总层、ADS 分析层三层架构。核心思想是:把重计算前移到入库完成后执行,而不是把计算压力留给报表。
2.1 DWD 明细层
DWD 层保留最完整的行级事实,当前项目有 3 张核心表:
dim_product:商品维度表,保存商品名称、品牌、类目、店铺等属性fact_search_candidate:候选商品行为事实表,按sample_id + candidate_rank拆成一行一商品fact_history_behavior:历史行为事实表,按sample_id + history_rank拆成一行一行为
CREATE TABLE dim_product (
wid VARCHAR(50) NOT NULL PRIMARY KEY,
name VARCHAR(500),
brand_id VARCHAR(50),
brand_name VARCHAR(255),
cate_id_1 VARCHAR(50),
cate_name_1 VARCHAR(255),
cate_id_2 VARCHAR(50),
cate_name_2 VARCHAR(255),
cate_id_3 VARCHAR(50),
cate_name_3 VARCHAR(255),
cate_id_4 VARCHAR(50),
cate_name_4 VARCHAR(255),
shop_id VARCHAR(50)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE fact_search_candidate (
id INT AUTO_INCREMENT PRIMARY KEY,
sample_id INT NOT NULL,
query VARCHAR(2000),
candidate_rank INT,
wid VARCHAR(50) NOT NULL,
label TINYINT,
label_name VARCHAR(50)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE fact_history_behavior (
id INT AUTO_INCREMENT PRIMARY KEY,
sample_id INT NOT NULL,
history_rank INT,
history_query VARCHAR(2000),
wid VARCHAR(50) NOT NULL,
behavior_type VARCHAR(50),
behavior_name VARCHAR(50),
history_time VARCHAR(50)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;原始行为文件中的 candidate_wid_list、candidate_label_list、history_wid_list 等字段都是下划线拼接的多值列,因此在入库前必须先由 Python 拆成标准明细行。
2.2 DWS 汇总层
DWS 层把高频分析维度提前聚合,当前主要用了 4 张表:
dim_product_category:从商品维表中提取轻量类目字段tmp_candidate_wid_summary:商品级曝光、点击、加购、购买汇总ads_current_sample_summary:样本级当前候选行为汇总tmp_history_sample_summary:样本级历史行为汇总
TRUNCATE TABLE tmp_candidate_wid_summary;
INSERT INTO tmp_candidate_wid_summary (wid, exposure_count, click_count, cart_count, purchase_count)
SELECT wid,
COUNT(*) AS exposure_count,
SUM(CASE WHEN label IN (1,2,3) THEN 1 ELSE 0 END) AS click_count,
SUM(CASE WHEN label IN (2,3) THEN 1 ELSE 0 END) AS cart_count,
SUM(CASE WHEN label = 3 THEN 1 ELSE 0 END) AS purchase_count
FROM fact_search_candidate
GROUP BY wid;2.3 ADS 分析层
ADS 层直接服务 BI,这里最终落了 4 张表:
ads_candidate_label_summary:候选标签分布ads_search_funnel:曝光 → 点击 → 加购 → 购买漏斗ads_category_conversion:一级类目转化表现ads_user_segment:用户价值分层
INSERT INTO ads_search_funnel (step_name, step_count, step_rate)
SELECT '曝光', SUM(total_candidates), 1.0000 FROM ads_current_sample_summary
UNION ALL
SELECT '点击', SUM(click_count), ROUND(SUM(click_count)/SUM(total_candidates),4) FROM ads_current_sample_summary
UNION ALL
SELECT '加购', SUM(cart_count), ROUND(SUM(cart_count)/SUM(total_candidates),4) FROM ads_current_sample_summary
UNION ALL
SELECT '购买', SUM(purchase_count), ROUND(SUM(purchase_count)/SUM(total_candidates),4) FROM ads_current_sample_summary;三、自动化增量 ETL 管道实现
当前主程序已经统一收敛到 run_incremental_v2.py,整体流程是:
incoming/ 目录扫描
→ detect_file_type() 判断 product / behavior
→ clean_product_to_csv() 或 clean_behavior_to_csv()
→ LOAD DATA LOCAL INFILE 写入明细表
→ 01_build_indexes.sql
→ 02_rebuild_summary.sql
→ 03_rebuild_ads.sql
→ 归档到 processed/3.1 这版脚本的几个关键点
相比最初版本,这一版脚本主要做了 4 个关键改进:
- 支持无表头的增量行为文件识别,不再因为首列不是
query被误跳过 - 行为数据会读取当前最大
sample_id,保证增量导入时历史数据不丢 - 商品维表按“全量快照”处理,先灌入临时表,再原子切换到
dim_product - 统一清洗回车符和特殊字符,避免
label_name、history_time出现脏数据
3.2 文件类型识别
def detect_file_type(fp: Path) -> str:
sep = detect_separator(fp)
with open(fp, "r", encoding="utf-8-sig", errors="replace") as f:
first_line = f.readline().strip()
parts = [part.strip() for part in first_line.split(sep)]
first_cell = parts[0].lower() if parts else ""
if first_cell == "query":
return "behavior"
if first_cell == "wid":
return "product"
if len(parts) == len(USER_BEHAVIOR_COLUMNS):
return "behavior"
return "unknown"这一步很重要,因为后续我们测试 5 万伪造行为增量时,用的就是无表头 CSV。如果没有这个兜底逻辑,脚本会直接把文件判成 unknown 然后跳过。
3.3 增量行为数据如何避免覆盖历史数据
行为数据导入前,会先查当前事实表中的最大 sample_id:
cur.execute("SELECT COALESCE(MAX(sample_id), 0) FROM fact_search_candidate")
max_sample_id = cur.fetchone()[0]这样第二天的新行为数据就会从第一天的最大 sample_id 继续往后编号,因此行为事实表是追加而不是覆盖。
3.4 批量入库为什么快
真正让导入速度提升的关键,不是 Python 循环插入,而是先把清洗结果写成 TSV,再用 LOAD DATA LOCAL INFILE 一次性批量写入:
def load_csv_to_table(csv_path: Path, table: str, columns: str, replace: bool = False):
cur.execute("SET autocommit = 0")
cur.execute("SET foreign_key_checks = 0")
cur.execute("SET unique_checks = 0")
cur.execute(
f"LOAD DATA LOCAL INFILE '{escaped_path}' "
f"INTO TABLE {table} "
f"CHARACTER SET utf8mb4 "
f"FIELDS TERMINATED BY '\\t' "
f"LINES TERMINATED BY '\\n' "
f"({columns})"
)
conn.commit()这种方式比逐行 INSERT 快得多,尤其适合千万级明细入库。
四、性能优化点总结
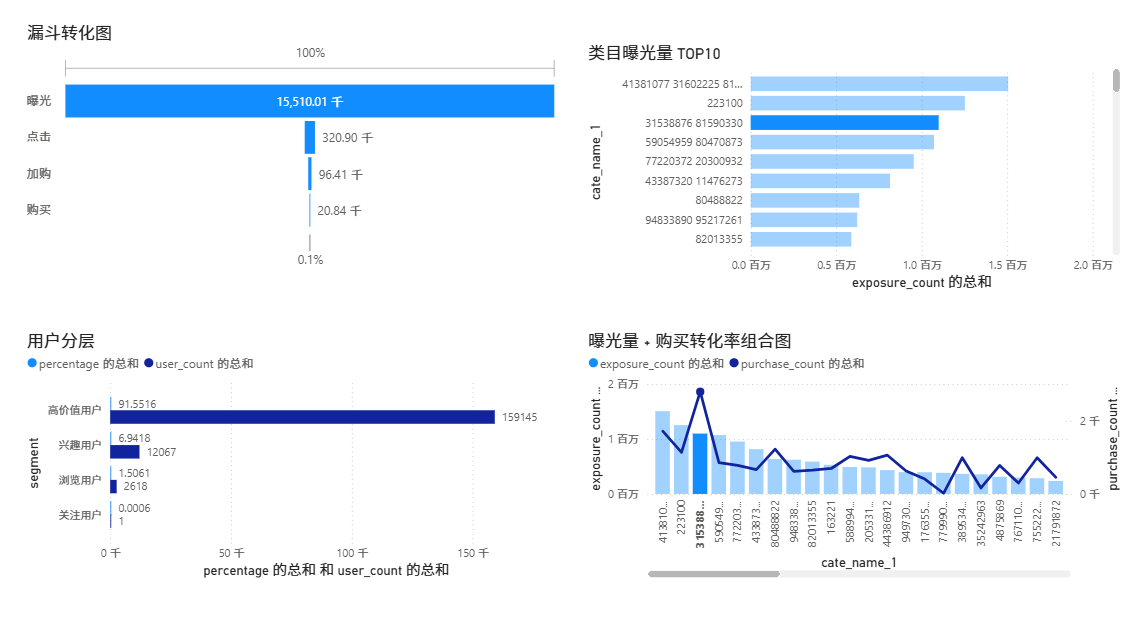
原始数据
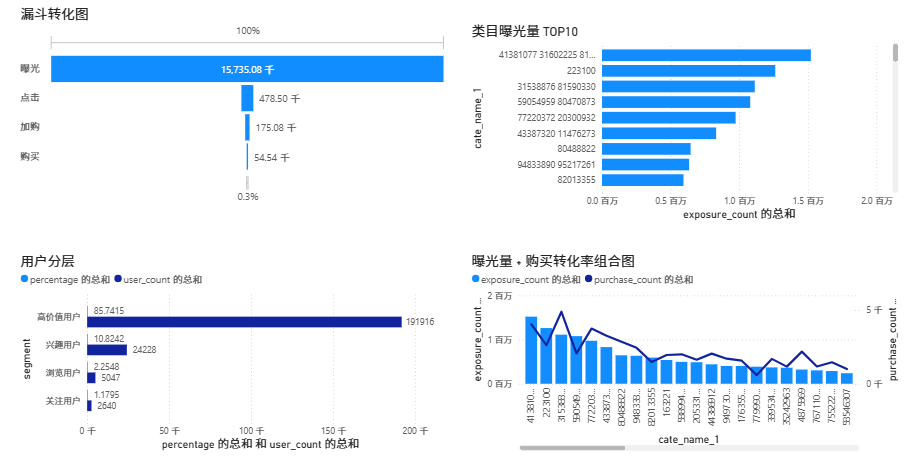
导入新数据后#只测试导入了5万的行为数据
这套方案能跑起来,主要靠下面几个优化点:
- 行为事实表导入前先删二级索引,导完再统一建索引,比边导入边维护索引快很多
- 商品表采用全量快照 + 临时表切换,既保留速度,也避免直接
TRUNCATE后失败导致空表 - 行为清洗按 chunk 分块读取,避免一次性把超大明细展开到内存里
- DWS 预计算把高频
JOIN / GROUP BY从 BI 查询时前移到入库完成后执行 - 所有已处理文件统一归档到
processed,支持重复运行和增量追加
五、踩坑与修复记录
这次优化过程中,踩坑不少,下面是几个最典型的问题。
5.1 表头误导入
问题:CSV 首次写入带表头,LOAD DATA 又没跳过头行,导致 sample_id=0 的脏数据进库。
修复:行为和商品 TSV 一律写无表头。
5.2 Windows 回车符污染字段
问题:Windows 默认换行符会把 \r 残留到最后一列,最后出现 无行为\r、0\r 这种值。
修复:
- 写 TSV 时统一
lineterminator="\n" - 在清洗函数中统一移除
\r和\n
5.3 旧版标签展开跨行串位
问题:旧版行为标签展开逻辑会把不同样本的 candidate_label_list 扁平拼在一起,造成标签错位。
修复:按单行对齐拆分 candidate_wid_list 和 candidate_label_list,不再做跨块扁平映射。
5.4 无表头增量文件被跳过
问题:无表头行为文件的首列不是 query,会被判定成 unknown。
修复:增加“7 列即行为文件”的兜底判断逻辑。
5.5 伪造增量数据无法关联商品维表
问题:早期生成的 5 万伪造行为数据里,wid 是 P000001 这种虚构编码,导致类目分析全部失真。
修复:从真实商品文件中抽样 wid,再生成测试行为数据。
六、实测结果
6.1 首次全量导入
首次全量导入实测结果如下:
- 商品维表
12141247行,商品清洗 + 导入约 14 分钟 - 候选行为表
15510012行,历史行为表26667260行,行为清洗 + 导入约 14 分钟 - 建索引
3 分 09 秒 - 汇总
4 分 54 秒 - ADS
2 分 34 秒 - 全链路首次导入总耗时
38 分 56 秒
6.2 5 万行为增量导入
后续又测试了一次 5 万行为增量文件,结果如下:
- 新增候选明细
225070行 - 新增历史明细
249582行 - 增量导入总耗时
12 分 51 秒 - 原始历史行为数据不会清空,而是在
sample_id=173831之后继续追加
这说明当前行为增量逻辑已经满足“第二天数据追加、第一天数据保留”的要求。
七、代码结构
data/test/
run_incremental_v2.py # 主流程:扫描、清洗、导入、重建汇总、归档
clean_behavior.py # 行为字段拆分与清洗逻辑
gen_5w.py # 真实 wid 抽样的增量测试数据生成器
config.py # MySQL 连接配置
sql/
00_rebuild_all_tables.sql
01_build_indexes.sql
02_rebuild_summary.sql
03_rebuild_ads.sql链接:https://pan.quark.cn/s/03c47705aecd?pwd=r4Rj
如果后续还要继续扩展留存分析、用户分层或者更多 BI 看板,建议继续沿用“明细层追加、汇总层重建、分析层直连”的思路,把复杂计算尽量放到导入完成后统一执行。
八、总结
这次优化的核心不是单纯“把导入跑通”,而是把它做成一个可以重复跑、可以增量追加、可以直接对接 BI 的数据分析模块。
最终这套方案解决了三个关键问题:
- 首次全量导入速度慢
- 后续增量导入不能保留历史
- BI 查询直接打明细表性能差
通过 Python 清洗 + LOAD DATA 批量入库 + 三层数仓建模 + 增量归档,这套链路已经具备了较强的复用价值。后续无论是继续扩展留存分析,还是接入更多 BI 看板,都可以在这套基础上继续演进。
更多推荐
 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)