
C++容器——vector的使用(上)
vector是基础数据结构中的顺序表结构。其实现方式为模板类型,这就让其应用范围更加广泛。可以在其内部存放任意内置类型,甚至可以存放自定义类型如string、vector、和自定义类型等。
一.vector的使用
1.1构造和拷贝构造
 vector的构造函数主要有三种:1.全缺省的默认构造(缺省参数为内存池,暂不做讲解);2.n个值的构造;3.迭代器区间构造;
vector的构造函数主要有三种:1.全缺省的默认构造(缺省参数为内存池,暂不做讲解);2.n个值的构造;3.迭代器区间构造;
//1.全缺省
vector<int> v1;
//2.n个参数构造
vector<int> v2(10, 1);
//3.迭代器区间构造
vector<int> v3(v2.begin(), v2.end());因为vector为模板类,在实现的过程中要显示指定其数据类型,此处以int为例。
v1为空白构造,v2用10个1进行构造,v3为迭代器区间进行构造
1.2遍历相关
因为vector为顺序表,所以和string一样,支持[ ]下标进行遍历。
//1.全缺省
vector<int> v1;
//2.n个参数构造
vector<int> v2(10, 1);
//3.迭代器区间构造
vector<int> v3(v2.begin(), v2.end());
//遍历相关
v1.push_back(1);
v1.push_back(2);
v1.push_back(3);
v1.push_back(4);
v1.push_back(5);
//[]下标遍历
for (size_t i = 0; i < v1.size(); i++)
{
cout << ++v1[i] << ' ';//同样可以修改
}
cout << endl;
//迭代器遍历
vector<int>::iterator it2 = v2.begin();
while (it2 != v2.end())
{
cout << ++(*it2) << ' ';//可以修改
it2++;
}
cout << endl;
//范围for
for (auto e : v3)
{
cout << e << ' ';
}
cout << endl;首先构造了3个对象分别为v1、v2、v3。

首先是方括号下标遍历,vector的成员函数同样重载了两个[ ]的重载,一种 是普通vector对象,可以返回并修改内部的值;另一种是针对const vector对象,返回的值不能被修改。
第二种是迭代器进行访问,在这里注意,迭代器要指定模板类,例如此处vector<int> iterator = v2.begin()。迭代器本质是类似于指针一样的东西,可以对其进行修改。注意如果是const对象,需要用const_iterator。
第三种是范围for,本质是将其转换为*it,但是一份拷贝,如果想改变内部,需要采用引用类型。
运行结果如下。[] 和迭代器均可以实现对类内私有成员变量值得改变和遍历。

1.3 查询大小和扩容相关函数
1.3.1 size和capacity
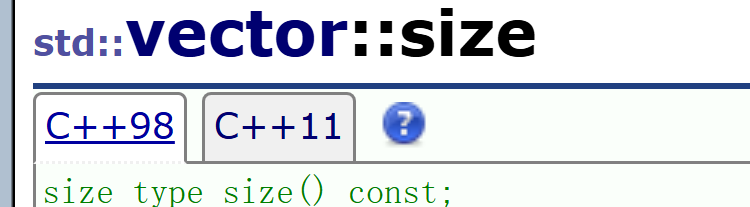

size返回当前vector对象存放数据的个数,capacity指示当前vector对象容量的大小。均实现为const成员函数,确保const对象也可调用。
1.3.2resize函数

resize函数和string中的resize函数功能类似,为具体改变数组内容的长度。主要分三种情况:如果改变的长度小于原长度,直接缩小到目标长度,会移除一部分末尾的数据;2.如果大于原长度,且第二个参数指定了内容,则在末尾补充数据直到目标长度;3.如果大于原长度且目标参数缺省,则会补充数据类型的缺省值:如int会补充0,char会补充‘‘0’等.
vector<int> v1(5, 1);
for (auto& e : v1)
{
cout << e << ' ';
}
cout << endl;
v1.resize(2);
for (auto& e : v1)
{
cout << e << ' ';
}
cout << endl;
v1.resize(10, 2);
for (auto& e : v1)
{
cout << e << ' ';
}
cout << endl;
v1.resize(20);
for (auto& e : v1)
{
cout << e << ' ';
}
cout << endl; 首先创建了一个vector<int> 的对象v1,用5个1进行初始化。首先将其缩小到2,那么打印的数据应该只有2个1。之后将其数据扩张到10,用2来补充,那么应该有2个1和8个2。最后扩展到20,第二个参数缺省,那么应该会再补充10个0。运行结果如下: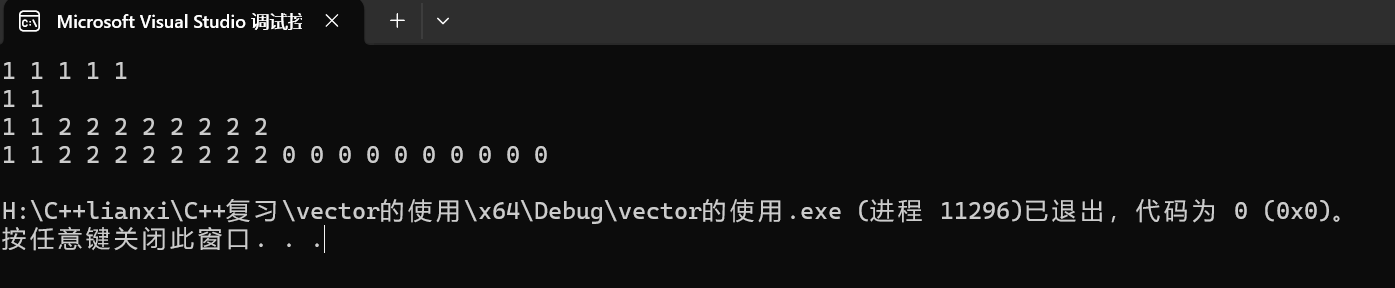
1.3.3 reserve函数
reserve函数,主要实现提前扩容的功能。与string中的reserve类似,同样只可以扩大空间,缩小空间不具有约束力,一般不会缩小空间。
下面这段代码展示了,vector中的扩容方式。
vector<int> v1;
size_t capacity = v1.capacity();
cout << "capacity:" << capacity << endl;
for (size_t i = 0; i < 100; i++)
{
v1.push_back(i);
if (capacity != v1.capacity())
{
capacity = v1.capacity();
cout << "capacity:" << capacity << endl;
}
//1.5倍扩容
}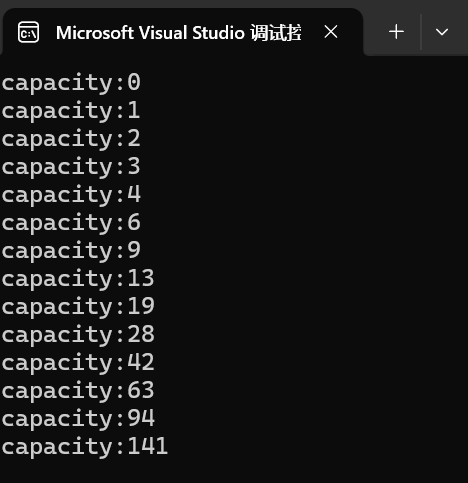
根据运行结果可以看出是较为标准的1.5倍扩容方式。
1.4 数据的增删函数
1.4.1 push_back和pop_back
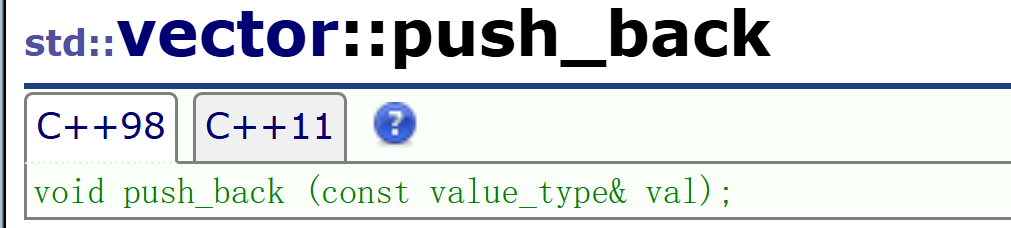

push_back用来在数组的末尾插入一个值,而pop_back用来去除一个值
//数据插入相关
vector<int> v1;
for (size_t i = 0; i < 10; i++)
{
v1.push_back(i);//尾插
}
v1.pop_back();//尾删
for (auto e : v1)
{
cout << e << ' ';
}
cout << endl;首先插入了0-9的整形,之后弹出了末尾的元素9,打印结果应该为0-8;
![]()
1.4.2 insert和erase
由于vector是顺序表,底层本质是一个数组,所以没有直接提供头插和头删的相关函数。如果想做到这一点,就需要用到insert和erase函数。

insert函数的基础用法为,传递一个迭代器位置,并插入一个值;
//insert需要提供需要插入数据位置的迭代器
v1.insert(v1.begin(), 10);
v1.insert(v1.begin()+2, 11);
//调用算法库的find函数,需要提供要搜索的迭代器区间和目标数值
//返回一个迭代器位置
v1.insert(find(v1.begin(),v1.end(), 5), 15);上面这段代码展示了insert的用法。传递v1,begin()迭代器的位置,表示在第一个数据的位置插入10。第二行代码表示在第二个数据的位置插入11。
最后一行代码,调用了算法库中的find函数。该函数的主要用法是,传递一个迭代器区间,并传递要查找的值,如果能找到,就返回该值对应的迭代器位置,否则返回迭代器右边界。那么该行代码的含义就是查找v1对象中是否有5这个数据,如果有,就在这个位置插入一个15。

紧接着push_back和pop_back代码的部分,运行结果如上。在第一个位置插入了一个10,之后在第二个位置插入11。并找到了5的位置,在这个位置插入15,可看到5在15之后。
1.4.3 erase函数
 erase函数为删除一个迭代器位置的数据,或者删除一段迭代器区间的位置。
erase函数为删除一个迭代器位置的数据,或者删除一段迭代器区间的位置。
v1.erase(v1.begin());
v1.erase(v1.begin()+1);
v1.erase(find(v1.begin(), v1.end(), 15));紧接上面代码,这段代码的三行分别表示:删除第一个数据,之后删除第二个数据,并在这组数据中找到15这个元素并删除。
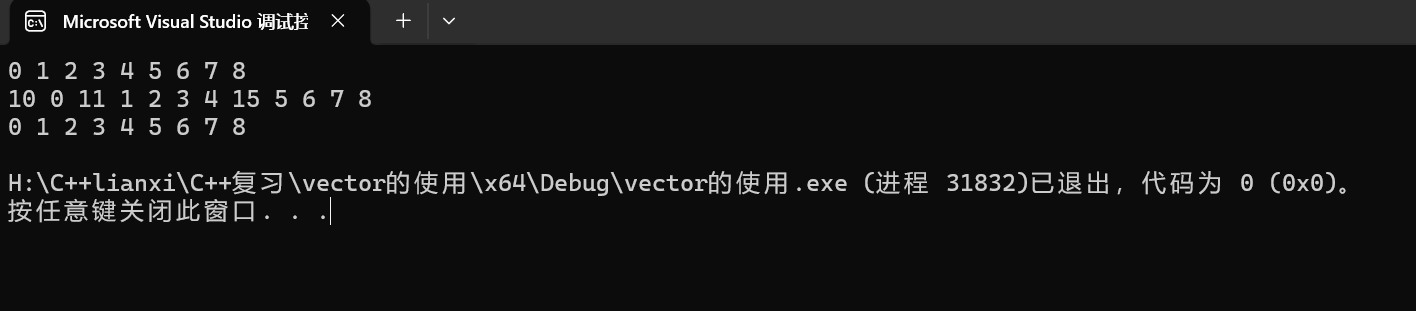
可看出,删除第一个元素10,之后第二个元素为11。删除11之后又利用find函数找到了15并删除。
1.5 vector和string的区别(简述)
//vector是模板,其参数可以放置任何类型;
vector<string> v1;
//char类型的vector不能代替string。少了'\0'和很多的函数设计。
vector<char> v2;由于vector是模板,其内部当然可以放char类型的数据,那么放了char类型的数据之后,看似和string类很相似,但却有着极大的不同。首先string类会在数据的最后放一个'\0',而vector不会,这就导致,string可以较容易的和C语言的相关函数进行连接。其次string中有许多读取、插入一个字符串的接口函数,而vector并没有。所以vector并不能代替string。
1.6 initializer_list构造
initializer_list,是一种C++的新标准,引入该对象进行构造,可以更便利的使用vector;
如果要利用该对象,需要引入一个头文件:
#include<initializer_list>
//vector同样支持initializer_list构造
auto l1 = {10,20,30};//initializer_list构造
vector<int> v1(l1);//直接传递一个initializer_list对象
vector<int> v2({ 1,2,3,4,5 });//隐式类型转换构造
vector<int> v3 = { 1,2,3,4,5,6 };//隐式类型转换后拷贝构造如创建了一个initializer_list对象l1,直接用该对象进行vector的构造。同样支持initializer_list进行构造的话,就可以向v2和v3一样利用隐式类型转换进行构造。
但要注意,v2和v3虽然都能构造,但其内部调用的函数并不相同。v2是利用传递的数据构造了一个initializer_list对象,然后利用该对象对v2进行构造。v3利用传递的数据构造了一个initializer_list对象之后,构造了一份临时的vector对象,并将该对象拷贝构造给了v3。要注意这两种写法的区别。
1.7 结构化绑定语法
struct A
{
A(int a1 = 0,int a2 = 0)
:_a1(a1)
,_a2(a2)
{
cout << "A(int a1 = 0,int a2 = 0)" << endl;
}
A(const A& a)
:_a1(a._a1)
,_a2(a._a2)
{
cout << "A(const A& a)" << endl;
}
int _a1 = 0;
int _a2 = 0;
};这里创建了一个结构体A,内部存在两个成员变量_a1和_a2。
A a1(100, 100);
auto [x, y] = a1;
cout << x << ":" << y << endl;首先创建了一个A类型的对象a1,并用100,100进行构造。
因为知道结构体A中存在两个对象,所以利用auto [a,b]来自动识别A类型对象a1的值,可以将a1内部的两个100分别赋值给a和b。

可看出这样可以正确识别到。
这样就可以利用到vector<A>类型对象的遍历中。
vector<A> v1;
A a(2, 2);
v1.push_back(a);
v1.push_back(A(3, 3));
v1.push_back({ 4,4 });
for (auto& e : v1)
{
cout << e._a1 << ":" << e._a2 << endl;
}
for (auto& [x, y] : v1)
{
cout << x << ":" << y << endl;
}首先建立了一个存放A类型对象的vector对象v1,之后建立了一个A类型的对象a,并用2,2进行构造。之后利用了三种push_back方式:1.直接尾插a对象;2.尾插匿名对象;3.隐式类型转换。
之后用范围for进行输出。第一种是常规的,e对象取到的内容是A类型的对象。所以要输出的话,需要利用‘ . ’操作符访问。
如果利用上面的结构化绑定语法,则可以直接输出x,y,就是对象内部的两个元素。

这些就是vector的主要使用方法, 下一篇博客将会带来vector的底层基本实现。
更多推荐
 3
3 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)