
数据结构|C++线性表 基础到进阶 完整核心代码实现
前置知识
指针
指针的定义: 数据类型 * 指针变量名
int a = 10;
//指针的定义
int *p;
//让指针记录变量a的地址,指针指向a的地址
p = &a;
指针的使用:解引用的方式:*指针变量
int a = 10;
int *p = &a;
//解引用访问指针指向的值
cout << *p << endl;
指针占用内存空间
32为操作系统下,占4个字节
64为操作系统下,占8个字节
可以使用sizeof(放变量)来访问占多少内存
空指针与野指针
空指针:用于给指针变量进行初始化,
int *p = NULL;,(用NULL表示空指针(内存编号为0的空间))不可以进行访问,原因:0~255的内存编号是系统占用的,不可以访问
野指针:指针变量指向非法的内存空间
空指针和野指针不是我们申请的空间,不可以访问
const修饰指针
常量指针:指针指向可以变,但是指向的值不能改变,
const int * p = &a;(const修饰指针)
指针常量:指针的指向不可以改,但是指向的值可以改,int * const p = &a;,辨析:const后面接着变量(修饰常量)
同时修饰指针和常量:指针指向和指针指向的值都不可以改,const * const p = &a;
记忆方法:根据const和*的位置,常量const指针*,如const int * p = &a;,指针*常量const,如:int * const p = &a;
指针和数组
作用:利用指针访问数组
样例:
#include<bits/stdc++.h>
using namespace std;
int main()
{
//定义一个数组
int arr[] = {0,2,3};
//用指针指向数组的首地址,方法一直接用数组名
int *p1 = arr;
//方法2取第一个数组元素的地址
int *p2 = &arr[0];
//通过解引用访问对应的元素
cout << arr[0] << endl;
cout << *p1 << endl;

指针与函数
作用:利用指针做函数的参数
样例:
#include<bits/stdc++.h>
using namespace std;
//地址传递两个数
void swap1(int *a, int *b)
{
int temp = *a;
*a = *b;
*b = temp;
}
//传入一个数组
void swap2(int arr[])//也可以用swap2(int *arr)
{
int temp = arr[0];
arr[0] = arr[1];
arr[1] = temp;
}
int main()
{
//定义一个数组
int arr[] = {0,2,3};
//用指针指向数组的首地址,方法一直接用数组名
int *p1 = arr;
//方法2取第一个数组元素的地址
int *p2 = &arr[0];
//通过解引用访问对应的元素
cout << arr[0] << endl;
//交换0和1
swap1(&arr[0],&arr[1]);
cout << *p1 << endl;
//交换1和0
swap2(arr);
cout << *p2 << endl;
}
结构体
结构体的定义
语法:
struct 结构体名{结构体数据类型}
创建方式:
struct 结构体名 变量名struct 结构体名 变量名 = {数据类型}struct 结构体名{数据类型}变量名;(注意后面的 ; 不要忘记写了)
样例:
#include <bits/stdc++.h>
using namespace std;
//定义结构体
struct bloger
{
string name;
int age;
int rating;
}up3;//第三种创建方式
int main()
{
struct bloger up1;//第一种创建方式
up1.name = "hawkpp", up1.age = 18, up1.rating = 200;
cout << up1.name << " " << up1.age << " " << up1.rating << endl;
bloger up2={"HawkPP",17,300};//第二种创建方式
cout << up2.name << " " << up2.age << " " << up2.rating << endl;
up3.name = "hawkPP", up3.age = 18, up3.rating = 1000;
cout << up3.name << " " << up3.age << " " << up3.rating << endl;
}
输出:
hawkpp 18 200
HawkPP 17 300
hawkPP 18 1000
结构体数组
语法:
struct 结构体名 数组名[元素个数] = {{数组的第一个元素},{第二个元素},........},访问类似数组
#include <bits/stdc++.h>
using namespace std;
//定义结构体
struct bloger
{
string name;
int age;
int rating;
};
int main()
{
struct bloger up[] = {{"hawkpp",18,200},{"HawkPP",17,300}};
for(int i = 0; i < 2; i++)
cout << up[i].name << " " << up[i].age << " " << up[i].rating << endl;
}
输出:
hawkpp 18 200
HawkPP 17 300
结构体指针
语法:使用操作符
->来访问结构体
样例:
#include <bits/stdc++.h>
using namespace std;
//定义结构体
struct bloger
{
string name;
int age;
int rating;
};
int main()
{
bloger up = {"hawkpp",18,200};
//创建指针指向结构体
bloger *p = &up;//记得取地址
//使用->操作符访问结构体元素
cout << p->name << " " << p->age << " " << p->rating << endl;
}
输出:
hawkpp 18 200
结构体嵌套
以样例解释:
#include <bits/stdc++.h>
using namespace std;
//定义结构体
struct bloger
{
string name;
int age;
int rating;
};
struct information_person
{
int id;
//嵌套结构体bloger
struct bloger up;//子结构体,子结构体必须在定义在调用之前
};
int main()
{
information_person person;
person.id = 1234;
//通过.操作符给内层结构体赋值
person.up = {"hawkpp",18,200};
cout << person.id << " " << person.up.name << " " << person.up.age << " " << person.up.rating << endl;
}
输出:
1234 hawkpp 18 200
线性表的定义和特点
什么是线性表(Linear List)?
线性表是具有相同特性的数据元素的一个有限序列
比如:有n个数据元素(结点)a1,a2,…an组成的有限序列,便是线性表
( a 1 , a 2 , … , a i − 1 , a i , a i + 1 , … , a n ) (a_1,\ a_2,\ \dots,\ a_{i-1},\ a_i,\ a_{i+1},\ \dots,\ a_n) (a1, a2, …, ai−1, ai, ai+1, …, an)
- a 1 a_1 a1:线性起点 / 起始结点,没有直接前趋
- a n a_n an:线性终点 / 终端结点,没有直接后继
- 中间的每一个元素,都有且仅有一个直接前驱、一个直接后继
- 下标含义:代表元素的序号,标记该元素在线性表里的位置
- 前驱后继关系
- a i − 1 a_{i-1} ai−1: a i a_i ai 的直接前驱
- a i + 1 a_{i+1} ai+1: a i a_i ai 的直接后继
- 表长 n n n: n n n 为数据元素的总个数
- 空表:当 n = 0 \boldsymbol{n=0} n=0 时,该线性表为空表
- 这里的数据元素 a i a_i ai 可以简单理解成一个变量名,其数据类型可以根据需求定义,比如说
int,char
顺序存储结构
什么是线性存储?
把逻辑上相邻的数据元素存储在物理上相邻的存储单元中的存储结构,也称为顺序映像
图示: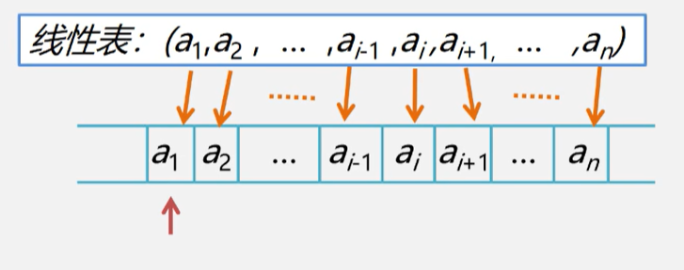
解释: a 1 a_1 a1 ~ a n a_n an依次存储在内存空间中,和原来的数据顺序一样,中间没有空出存储单元,因此每一个元素对应的下标(位置)都是已知的,可以直接通过下标访问对应的元素
线性表的第一个元素 a 1 a_1 a1 的存储结构,称为线性表的起始位置或基地址
顺序表(Sequence List)的特点
- 元素地址连续
- 元素依次存放
- 元素可以直接访问
- 数据类型相同
顺序表的基本操作
顺序表的定义
struct SqList
{
ELemType *elem;//ElemType表示数据类型,*elem表示动态数组
int length;//表示顺序表长或存储元素个数
};
SqList L;//定义顺序表的变量名为L
样例
#include <bits/stdc++.h>
using namespace std;
struct SqList
{
int *elem;//
int length;
};
int main()
{
SqList L;
//cin >> L.elem[0];不能直接像这样直接给元素赋值,因为目前elem没有指向任何空间,属于野指针,不可直接访问
// L.length++;必须初始化,不然length的初始值未知,会得到奇怪的答案
// 用new分配100个int的内存空间
L.elem = new int[100];
L.length = 0;//初始化length
cin >> L.elem[0];
L.length++;
cout << L.elem[0] << " " << L.length << endl;
// 用delete释放内存空间
delete[] L.elem;
// 置空,防止悬空野指针,避免程序崩了和非法访问
L.elem = nullptr;
}
new操作符:语法:new 数据类型名T[开辟的数量n],作用申请分配存放n个T类型的内存空间delete操作符:语法:
- 单个指针:
delete 指向开辟内存空间指针p- 数组指针:
delete[] 数组名
顺序表的销毁与清空
//销毁线性表
void DestroyList(SqList &L)
{
//L.elem是开辟内存的指针,如果不是空指针执行if语句
if(L.elem)
{
delete[] L.elem;//释放内存空间
L.elem = nullptr;//避免野指针
}
L.length = 0;//表长归0,变成空表
}
//清空线性表
void ClearList(SqList &L)
{
L.length = 0;//将线性表长度置为0
}
样例:
#include <bits/stdc++.h>
using namespace std;
struct SqList
{
int *elem;
int length;
};
//销毁线性表
void DestroyList(SqList &L)
{
//L.elem是开辟内存的指针,如果不是空指针执行if语句
if(L.elem)
{
delete[] L.elem;//释放内存空间
L.elem = nullptr;//避免野指针
}
L.length = 0;//表长归0,变成空表
}
//清空线性表
void ClearList(SqList &L)
{
L.length = 0;//将线性表长度置为0
}
int main()
{
SqList L;
//cin >> L.elem[0];不能直接像这样直接给元素赋值,因为目前elem没有指向任何空间,属于野指针,不可直接访问
// L.length++;必须初始化,不然length的初始值未知,会得到奇怪的答案
// 用new分配100个int的内存空间
L.elem = new int[100];
L.length = 0;//初始化length
cin >> L.elem[0];
L.length++;
cout << L.elem[0] << " " << L.length << endl;
//清空顺序表
ClearList(L);
//元素依然保留,只是表长变为0
cout << L.elem[0] << " " << L.length << endl;
//通过cpp引用的方式来调用销毁函数
DestroyList(L);
// cout << L.elem[0] << " " << L.length << endl;已经被销毁不能直接访问对应的元素
cout << L.length << endl;
引用:语法:
- 单个值:
数据类型 & B = A,- 作为函数形参:
函数返回值类型 函数名(数据类型 &m, 数据类型 &n....){}调用时:函数名(变量1,变量2...)
给一个变量A取别名B,用B来表示A,B的地址和数值和A相同,打个比喻:比如同一个人,有大名和小名,虽然叫法不同,但是都是同一个人
求表长和判断是否为空
//求表长,只读,安全高效,常量指针,放在数据被修改
int GetLength(const SqList &L)
{
return L.length;
}
//判断是否为空
int isEmpty(const SqList &L)
{
if(L.length == 0) return 1;//为空返回1
else return 0;
}
由于这里不需要对顺序表本身进行操作,所以直接使用值传递就行,不要使用引用传递
获取对应特定位置的值
//&e使用引用,修改传入的参数
int GetElem(SqList L, int i, ElemType &e)
{
//i表示第几个元素
if(i < 1||i > L.length) return 0;
//判断位数是否存在
e = L.elem[i-1];//第i个元素的下标为i-1
return 1;
}
样例:
#include <bits/stdc++.h>
using namespace std;
struct SqList
{
int *elem;
int length;
};
//获取特定位置的值
int GetElem(SqList L, int i, int &e)
{
if(i < 1||i > L.length) return 0;
//判断位数是否存在
e = L.elem[i-1];
return 1;
}
int main()
{
Sqlist L;
L.elem = new int[100];
L.length = 0;
cin >> L.elem[0];
L.length ++;
int first_num;
//输出第一个元素
if(GetElem(L,1,first_num))
cout << first_num << endl;
}
顺序表的查找
int LocateElem(SqList L, ElemType e)
{
//在顺序表中查找数据元素e,并返回对应的序号(第几个元素)
for(int i = 0; i < L.length; i++)
if(L.elem[i] == e) return i+1;//查找成功返回序号
//等价写法
/*
i == 0;
while(i < L.length)
{
if(L.elem[i] == e) return i + 1;
i++;
}*/
return 0;//查找失败返回0
}
顺序表的插入
算法思路:
- 判断插入位置 i 是否合法
- 判断顺序表的存储空间是否已满
- 将 n-1 到 i 的位置元素依次向后移动一个位置,空出第 i 个位置
- 将要插入的元素放在第 i 位
- 最后表长加一,插入成功
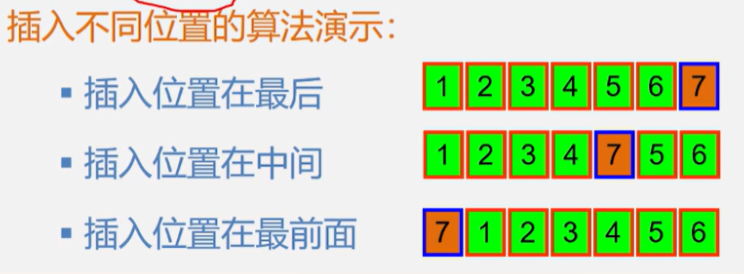
//Status 表示返回值类型,i表示对应的下标
Status ListInsert_Sq(SqList &L, int i, ElemType e)
{
//判断i是否合法
if(i < 0|| i > L.length) return 0;
//判断存储空间是否够用
if(L.length == MAXSIZE) return 0;
//插入位置及其后面的元素依次后移一个位置
for(int j = L.length - 1; j >= i; j--)
L.elem[j+1] = L.elem[j];
//将元素e插入对应位置
L.elem[i] = e;
//表长+1
L.length++;
return 1;
}
顺序表的删除
算法思路:
- 判断删除位置 i 是否合法(i 表示下标)
- 将i ~ n-1 的元素依次前移一个位置
- 表长减一
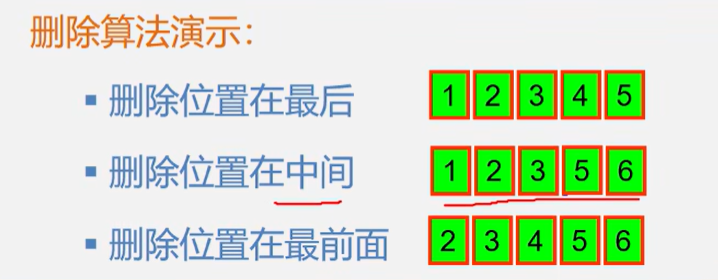
Status ListDelete_Sq(SqList &L,int i)
{
//判断是否合法
if(i < 0|| i > L.length) return 0;
//元素前移
for(int j = i; j < L.length - 1; j++)
L.elem[j] = L.elem[j+1];
//表长减一
L.length--;
return 1;
}
总结
-
优点:
- 存储密度大(结点本身所占存储量/结点结构所占存储量),可以简单理解为占用的空间利用率大,内存依次存取,没有空出太多的空间
- 可以随机访问表中任意元素
-
缺点:
- 在插入、删除某个元素的时候,需要移动大量元素
- 浪费存储空间
- 属于静态存储模式,数据元素的个数不能自由扩充,存储空间不灵活
链式存储结构
链式存储结构是什么?
逻辑上相邻的数据元素在物理上不一定相邻,可以在存储单元上连续也可以不连续,甚至可以分散分布在内存的任意位置上,也称为非顺序映像 或 链式映像
链表的特点
-
结点(数据域+指针域)在存储器上的位置是任意的
-
访问时只能通过头指针进入链表,并通过每个结点的指针域依次向后顺序扫描其余结点(顺序存取法)
-
优点:
- 结点空间可以动态申请和释放,内存使用灵活
- 数据逻辑次序由结点指针维护,插入、删除元素时不需要移动大量数据
-
缺点:
- 存储密度小:每个结点需要额外开辟指针域占用存储空间;当数据域本身很小时,指针的额外开销占比会非常高
- 非随机存取结构:链表不支持下标直接访问,想要操作任意结点,都必须从头指针开始顺着链表依次遍历查找,算法时间复杂度更高
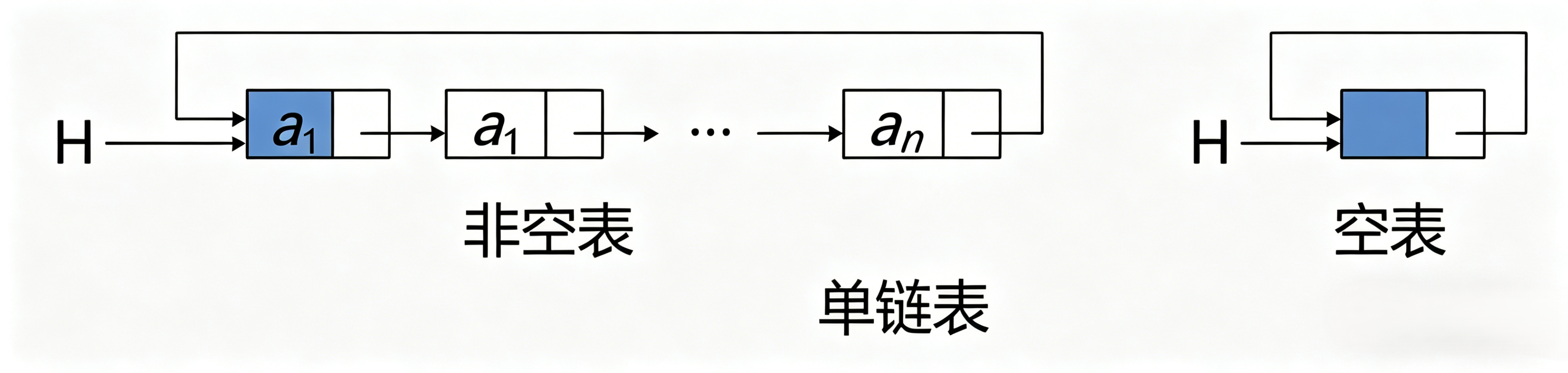
单链表
定义
每个结点只有 1 个指针域的链表,只指向下一个,只能从头往后走,不能回头,也称线性链表
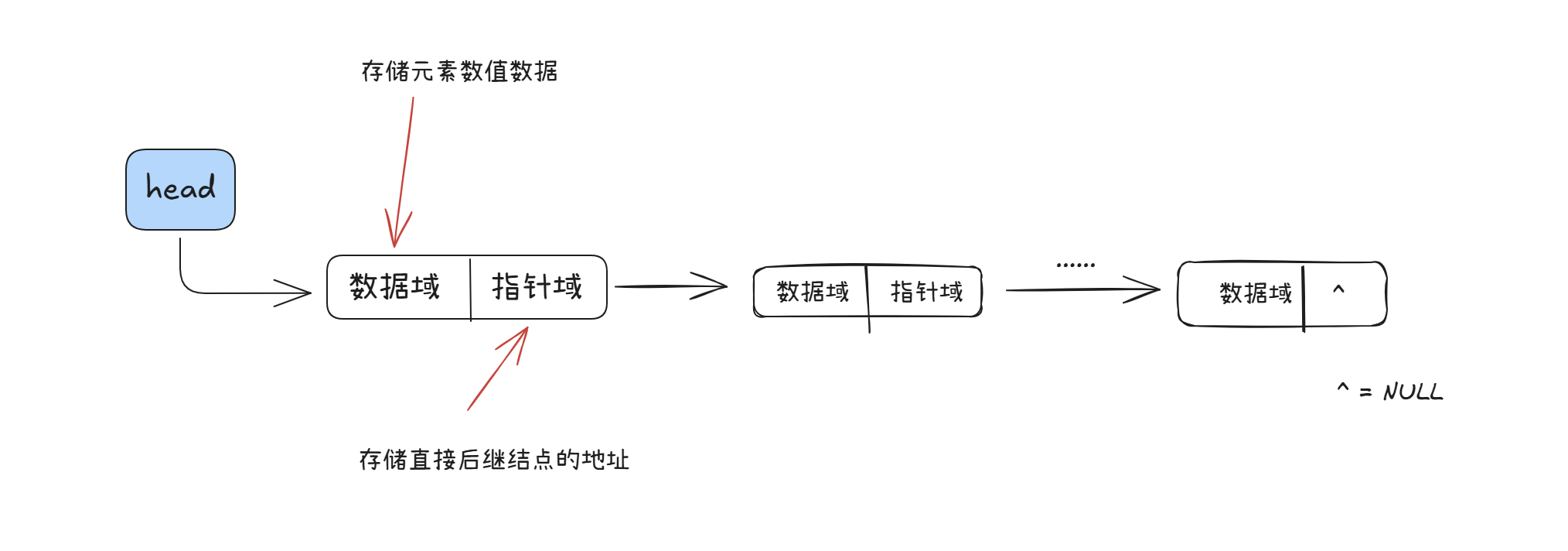
空表的表示:
- 无头结点时,头指针为空时表示空表
- 有头结点时,头节点的指针域为空时表示空表
图示中用 ^ 表示空指针
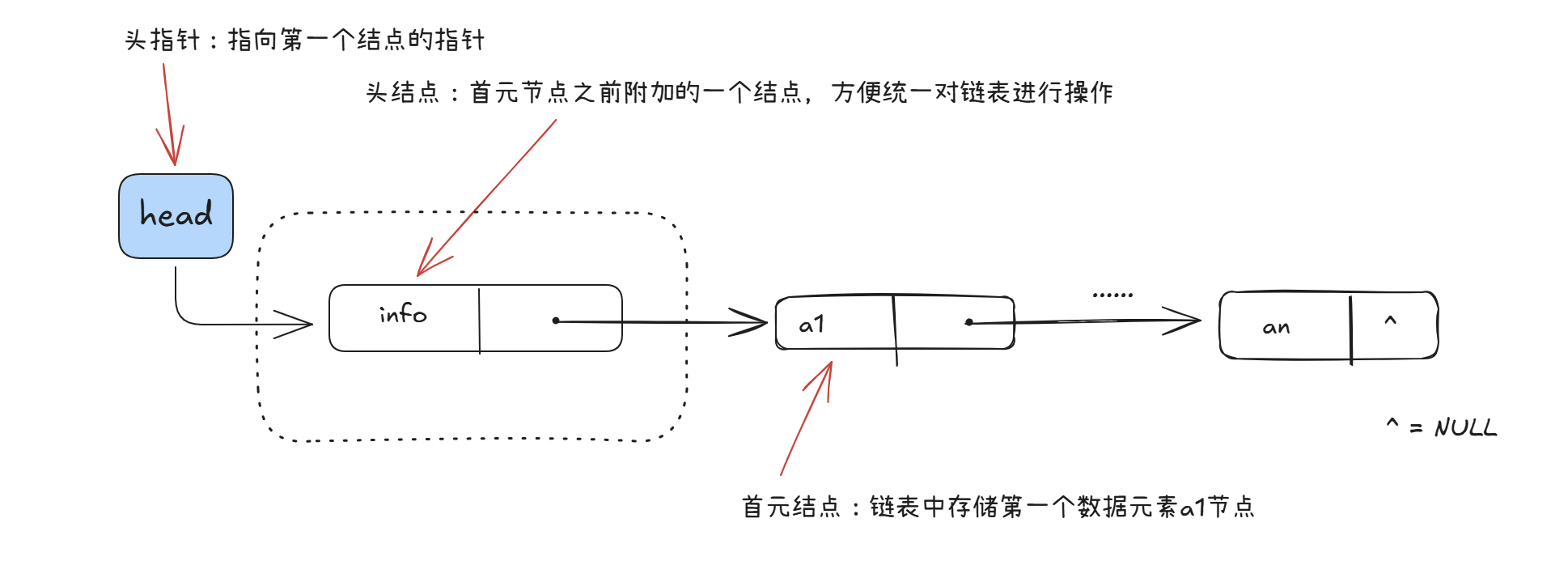
头结点的好处:
- 便于首元结点的处理
- 便于空表和非空表的统一处理
总之就是有了头结点不需要对链表进行特殊处理,方便对链表的一些列操作
头结点的数据域可以为空,也可以存放链表的长度等其他信息,但是该结点不计入链表的长度值
单链表的操作
单链表的定义
#include <bits/stdc++.h>
using namespace std;
//声明结点的类型和指向结点的指针类型
struct Lnode
{
ElemType data;//结点的数据域,ElemType可以为结构体及其它数据类型
Lnode *next;//结点的指针域
};
using LinkList = Lnode*;
// 给指针起别名:LinkList = Lnode*;
int main()
{
//链表头指针,代表整个链表
LinkList L;
//工作指针,用来遍历、操作链表
Lnode *p;
}
单链表的初始化
算法思路:
- 生成新结点作为头结点,用头指针L指向头结点
- 将头指针的指针域悬空
//Status用了判断是否成功初始化
Status InitList(LinkList &L)
{
L = new Lnode;//开辟内存空间存放结点
L ->next = NULL;//头结点的指针域悬空
return 1;
}
注意该初始化函数必须放在
using LinkList = Lnode*;之后
判断链表是否为空
int ListEmpty(LinkList L)
{
if(L->next)
return 0;//非空指针返回0
else
return 1;//为空指针返回1
}
单链表的销毁
思路:从头结点开始,依次释放所以结点
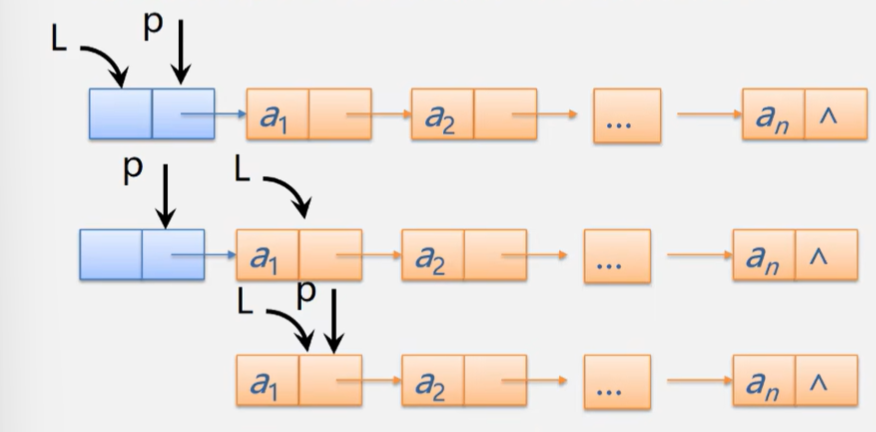
Status DestroyList_L(LinkList &L)
{
Lnode *p;//或者LinkList p;
while(L)//等价L != NULL执行语句,当L=NULL时结束循环
{
p = L;//p的作用释放前一结点的内存空间
L = L->next;
delete p;
}
return 1;
}
求单链表的表长
算法思路:从首元结点开始,依次计数所有结点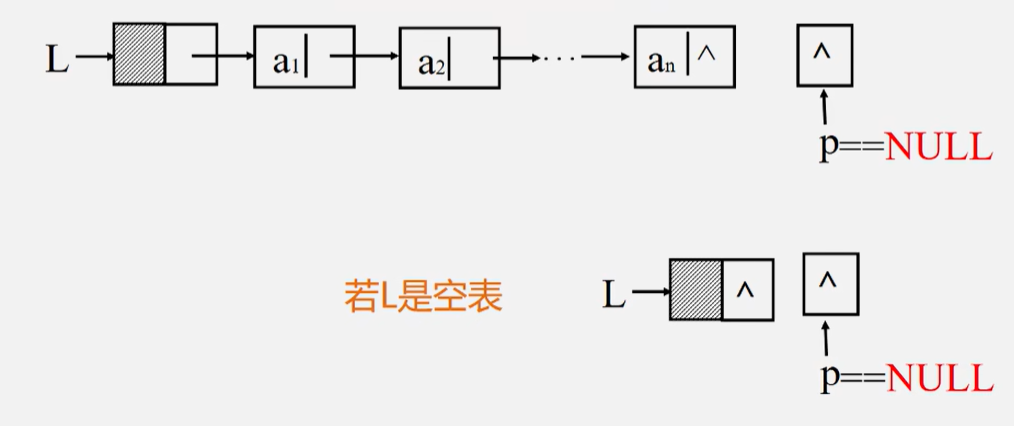
//返回数据元素个数
int ListLength_L(LinkList L)
{
LinkList p;
p = L->next;//指向第一个结点
int count = 0;//计数器,统计结点个数
while(p)
{
count++;
p = p->next;
}
return count;
}
取单链表中第i个元素
算法思路:从链表的头指针出发,顺着链域next逐个结点往下搜索,直至搜索到第i个结点为止(链表不是随机存取结构)
//获取获取链表L中某个元素,并通过引用的方式返回
Status GetElem_L(LinkList L, int i, ElemType &e)
{
LinkList p;
p = L->next;//初始化
int j = 1;
while(p&&j < i)
{
p = p->next;
++j;
}
if(!p||j > i) return 0;//第i个元素不存在
e = p->data;//获取第i个元素
return 1;
}
单链表的按值查找
算法思路:
- 从第一个结点开始,依次和要查找的值e比较
- 如果找到一个值与e相等的数据元素,则直接返回其在链表中的位置或地址
- 如果遍历整个链表都没有找到其值和e相等的元素,则返回0或
NULL
//ElemType为查找值的数据类型
//方法一:
Lnode *LocateElem_L(LinkList L, Elemtype e)
{
LinkList p = L->next;
while(p && p->data!=e)
p = p->next;
return p;//找到返回值为e的数据元素地址,查找失败返回NULL
}
//方法二:返回数据元素的位置序列从1开始,不是从0开始,查找失败返回0,查找成功返回其是第几个元素
int LocateElem_L(LinkList L, Elemtype e)
{
LinkList p;
p = L->next;
int j = 1;
while(p &&p->data != e)
{
p = p->next;
j++;
}
if(p) return j;
else return 0;
}
单链表的插入
算法思路:在第i个结点前插入值为e的新结点
- 首先找到第 a i − 1 a_{i-1} ai−1 的存储位置
p - 检测是否插入非法
- 生成一个数据域为e的新结点s
- 插入新结点:
- 新结点的指针域指向结点 a i a_i ai,
s->next = p->next; - 结点 a i − 1 a_{i-1} ai−1 的指针域指向新结点,
p->next = s;
- 新结点的指针域指向结点 a i a_i ai,
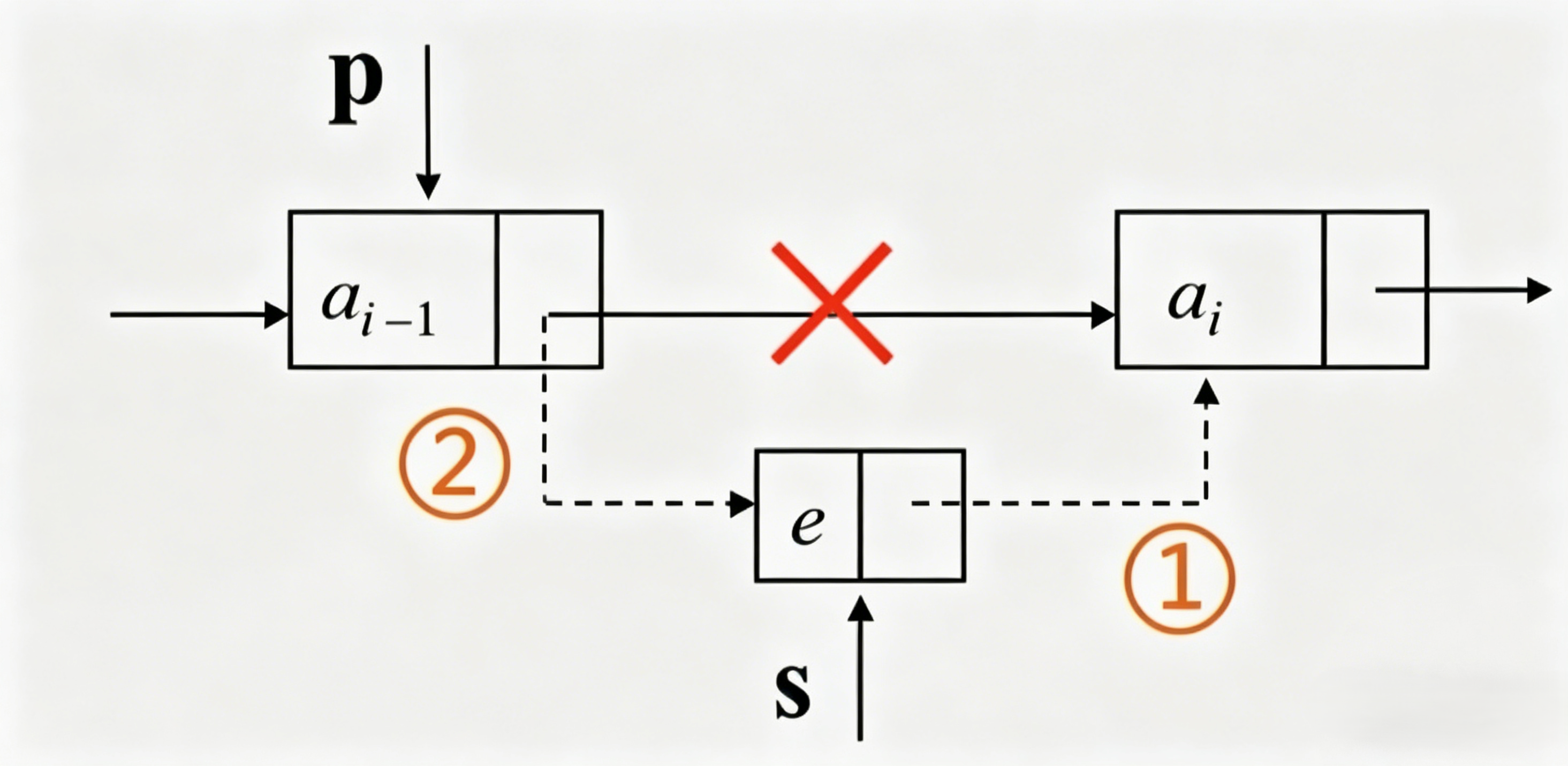
注意:1和2的顺序不能交换,因为如果交换1和2顺序的话,则先进行
p->next = s则 a i a_i ai 的地址被新结点地址覆盖,导致 a i a_i ai 地址丢失
Status ListInsert_L(LinkList &L, int i, ElemType e)
{
LinkList p;
p = L;
int j = 0;
//寻找第i-1个结点,p指向第i-1结点
while(p && j < i-1)
{
p = p->next;
++j;
}
//检测非法,大于i大于表长+1或小于1
if(!p || j > i -1) return 0;
//生成新结点s,将结点s的数据域置为e
LinkList s;
s = new Lnode;
s->data = e;
//将结点s插入L中
s->next = p->next;//先将新结点和第i个结点相连接
p->next = s;
return 1;
}
单链表的删除
算法思路:
- 找到 a i − 1 a_{i-1} ai−1 的存储位置
p,保存删除的 a i a_i ai 的值 - 检测删除位置的合理性
- 令
p->next指向 a i + 1 a_{i+1} ai+1 - 释放结点 a i a_i ai 的空间
//删除第i个数据元素
Status ListDelete_L(LinkList &L, int i, ElemType &e)
{
LinkList p = L;
int j = 0;
while(p->next&&j < i-1)
{
p = p->next;
++j;
}
//删除不合理的位置
if(!(p->next)||j > i - 1) return 0;
Lnode *q;//临时保持被删除的结点的地址,以便释放
q = p->next;
//改变删除节点的前驱结点的指针域
p->next = q->next;
//用e保存删除结点的数据域
e = q->data;
delete q;//释放删除结点空间
return 1;
}
单链表的建立
算法思路:
- 法1 :头插法
- 从一个空表开始,重复读入数据
- 生成新结点,将读入的数据存放到新结点的数据域中
- 从最后一个结点开始,依次将各结点插入到链表的前端
- 法2:尾插法
- 从一个空表
L开始,将新结点逐个插入到链表的尾部,尾指针r指向链表的尾结点 - 初始时,
r和L均指向头结点,每读入一个数据元素时,申请一个新结点,将新结点插入到尾结点,r指向新结点
- 从一个空表
//单链表的创建
//法1:头插法
void CreateList_H(LinkList &L, int n)//输入n个元素值
{
L = new Lnode;
L->next = NULL;//创建带有头结点的单链表
for(int i = n; i > 0; --i)
{
LinkList p;
p = new Lnode;//生成新结点
cin >> p->data;//输入元素值
p->next = L->next;//插入表头
}
}
//法2:尾插法
void CreateList_R(LinkList &L, int n)
{
L = new Lnode;
L->next = NULL;
LinkList r;
r = L;//开始时,尾结点指向头结点
for(int i = 0; i < n; ++i)
{
//生成新结点,输入元素值
LinkList p;
p = new Lnode;
cin >> p->data;
p->next = NULL;
r->next = p;//插入到表尾
r = p;//插入到尾结点
}
}
循环链表(Circular Linked List)
定义
首尾相连的链表,即表中最后一个结点的指针域指向头结点,整个链表形成一个环
优点:由表中任一结点就可以找到表中其他结点
注意:由于循环链表中没有NULL指针,因此进行遍历操作的时候,其终止条件:只能判断其是否为头指针
单循环链表:用尾指针表示单循环链表,原因头指针表示单循环链表的时候,查找元素不方便
循环链表的合并
算法思路:
- 以一个循环链表( A A A)的头结点作为合并后链表的头结点
- 将另外一个循环链表( B B B)的首元结点与A的表尾连接
- 释放链表B的头结点
- 链表B的尾指针指向A的头结点
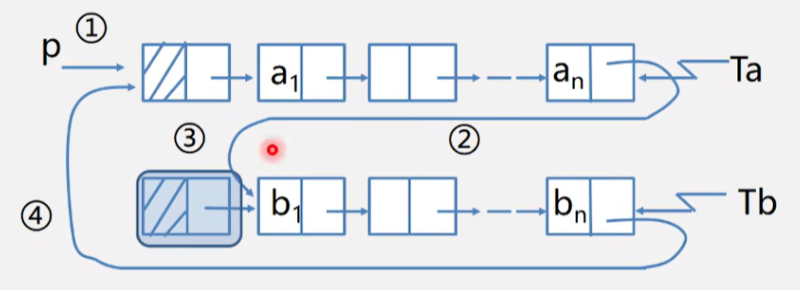
注意: T a T_a Ta 和 T b T_b Tb 都是单循环链表的尾指针
LinkList Connect(LinkList Ta, LinkList Tb)
{
p = Ta-next;//用p存放头结点指针域
Ta->next = Tb->next->next;//Tb的首元结点和Ta的尾结点连接
delete Tb->next;//释放Tb的头指针
Tb->next = p;//Tb的尾指针指向新链表的头指针,形成新的链表
return Tb;//返回Tb,因为其为新链表的尾指针
}
双链表(Doubly Linked List)
定义
结点有两个指针域的链表
包含前继指针prior、数据域和后继指针next
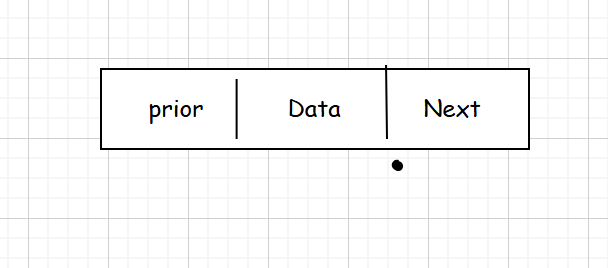
struct DulNode
{
Elemtype data;
struct DulNode *prior, *next;
node() : data(0), pre(nullptr), next(nullptr) {}
node(int val) : data(val), pre(nullptr), next(nullptr) {}
};
using DuLinkList = DulNode*;

双向循环链表
算法思路:
- 让头结点的前驱指针指向链表的最后一个结点
- 让最后一个结点的后继指针指向头结点
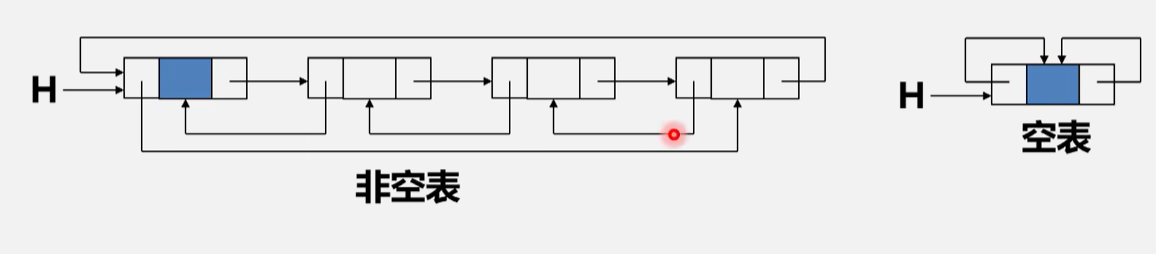
双向链表的插入
算法思路:将新结点s插入到结点p之前
- 新结点s的前驱指针指向a
- p结点的前驱指针的后继指针指向结点s
- 新结点s的后继结点指向p
- 结点p的前驱指针指向s
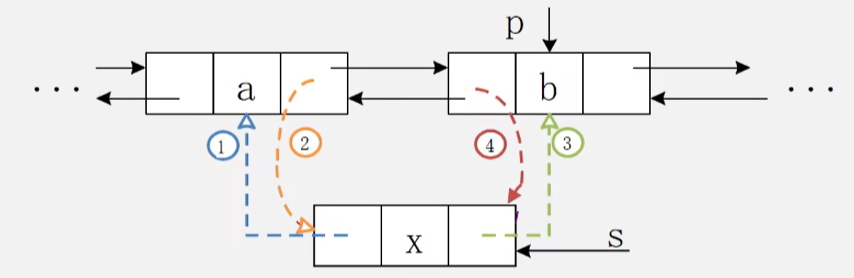
//在有头结点的双向循环链表中的第i个位置之前插入元素e
Status ListInsert_DuL(DuLinkList &L, int i, ElemType e)
{
DuLinkList p,s;//定义两个节点
//检验查找位置是否正确
if(!(p = GetElemP_Dul(L,i))) return 0;
//给新结点赋值
s = new DulNode;
s->data = e;
//下面依次对应上面的4步骤
s->prior = p->prior;
p->prior->next = s;
s->next = p;
p->prior = s;
return 1;
}
双向链表的删除
算法思路:
- 结点p的前驱结点的后继指针指向p的后继结点
- p的后继结点的前驱指针指向p的前驱结点
- 1和2可以交换顺序
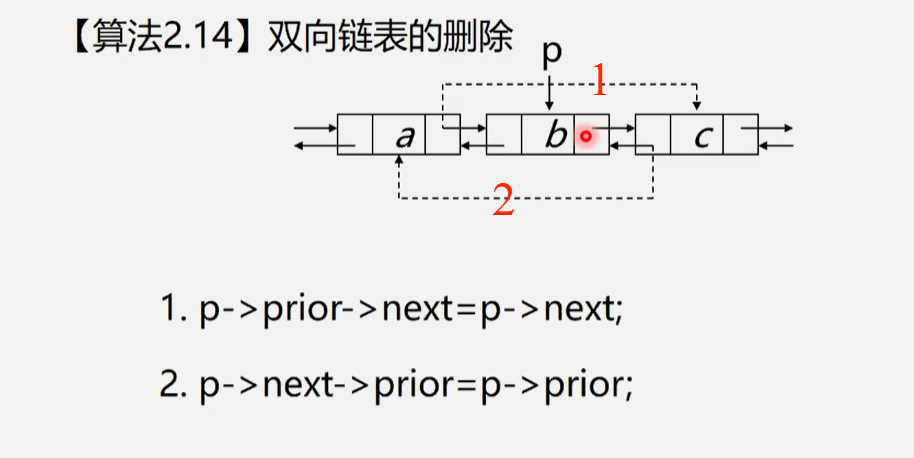
Status ListDelete_Dul(DuLink &L, int i, ElemType &e)
{
if(!(p = GetElemP_Dul(L,i))) return 0;
e = p->data;
p->prior->next = p->next;
p->next->prior = p->prior;
delete p;
return 1;
}
线性表的比较
单链表、循环链表和双向链表的比较
| 链表类型 | 查找表头结点(首元结点) | 查找表尾结点 | 查找结点 *P 的前驱结点 |
|---|---|---|---|
| 带头结点的单链表 L | L->next 时间复杂度O(1) |
从L->next依次向后遍历 时间复杂度O(n) |
通过p->next无法找到其前驱 |
| 带头结点仅设头指针L的循环单链表 | L->next 时间复杂度O(1) |
从L->next依次向后遍历 时间复杂度O(n) |
通过p->next可以找到其前驱 时间复杂度O(n) |
| 带头结点仅设尾指针R的循环单链表 | R->next 时间复杂度O(1) |
R 时间复杂度O(1) |
通过p->next可以找到其前驱 时间复杂度O(n) |
| 带头结点的双向循环链表L | L->next 时间复杂度O(1) |
L->prior 时间复杂度O(1) |
p->prior 时间复杂度O(1) |
顺序表和链表的比较
| 大类 | 比较项目 | 顺序表 | 链表 |
|---|---|---|---|
| 空间 | 存储空间 | 预先分配,会导致空间闲置或溢出现象 | 动态分配,不会出现存储空间闲置或溢出现象 |
| 存储密度 | 不用为表示结点间的逻辑关系而增加额外的存储开销,存储密度等于1 | 需要借助指针来体现元素间的逻辑关系,存储密度小于1 | |
| 时间 | 存取元素 | 随机存取,按位置访问元素的时间复杂度为O(1) | 顺序存取,按位置访问元素时间复杂度为O(n) |
| 插入、删除 | 平均移动约表中一半元素,时间复杂度为O(n) | 不需移动元素,确定插入、删除位置后,时间复杂度为O(1) | |
| 适用场景 | 适用情况 | ① 表长变化不大,且能事先确定变化的范围 ② 很少进行插入或删除操作,经常按元素位置序号访问数据元素 |
① 长度变化较大 ② 频繁进行插入或删除操作 |
线性表的合并
算法思路:
- 依次取出Lb中的每个元素
- 在La中查找该元素
- 如果找不到插入a的后面
void union(List &La, List Lb)
{
La_len = ListLength(La)
Lb_len = ListLength(Lb)
for(int i = 1; i <= Lb_len; i++)
{
GetELem(Lb,i,e);
if(!LocateElem(La,e))
ListInsert(&La,++La_len,e);
}
}
用顺序表实现
算法思路:
- 取两个指针(头指针和尾指针)分别指向顺序表a和b的第一个元素和最后一个元素
- 循环:依次比较头指针所指向的值,如果pa所指向的值小,插入新表c中,指针pa后移一位
- 如果pb所指向的值小,插入新表c中,指针pb后移一位
- 直到一顺序表遍历结束,跳出循环
- 单独执行有剩余元素的顺序表(头指针没有和尾指针重合的顺序表),将其剩余元素插入到新表c中
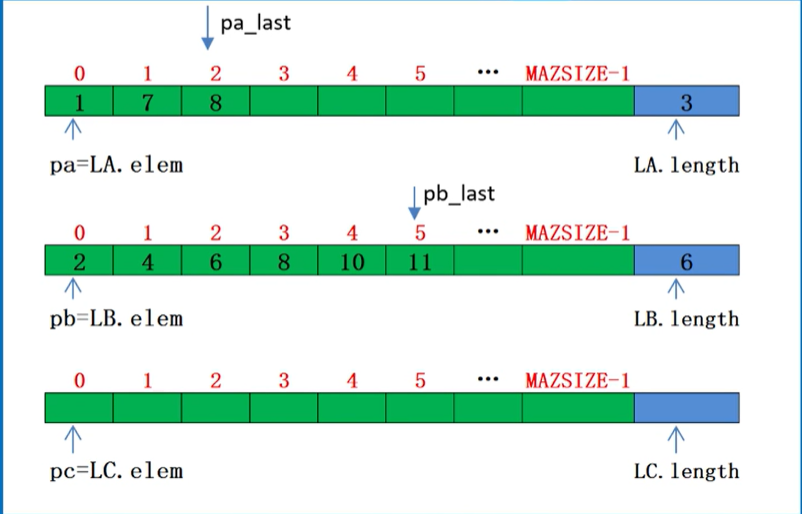
void MergeList_Sq(SqList La, SqList Lb, SqList &c)
{
pa = La.elem;//指针pa指向顺序表a的第一个元素
pb = Lb.elem;//指针pb指向顺序表b的第一个元素
Lc.length = La.length + Lb.length;//将新表的长度初始为两个表长之和
Lc.elem = new ElemType[Lc.length];//为合并后的新表分配内存空间
pc = Lc.elem;
pa_last = La.elem + La.length - 1;//指针pa_last指向表a的最后一个元素
pb_last = Lb.elem + Lb.length - 1;//指针pb_last指向表b的最后一个元素
while(pa <= pa_last&&pb <= pb_last)//两表都为非空
{
if(*pa <= *pb)
*pc++ = *pa++;
else
*pc++ = *pb++;
}
while(pa <= pa_last)//a表有剩余执行
*pc++ = *pa++;
while(pb <= pb_last)//b表有剩余执行
*pc++ = *pb++;
}
用链表实现
算法思路:
- 先设置指针
pa、pb、pc,和设置新链表C - 将指针
pc指向其中一链表A的头结点 - 依次遍历链表A和链表B,并比较头指针所指向的值
- 如果链表A的头指针
pa所指向的值<=pb所指向的值,将指针pa所指向的结点尾插在pc所指向的结点后,并将指针pa后移 - 如果指针
pa所指向的值>pb所指向的值,将指针pb所指向的结点尾插在pc所指向的结点后
- 如果链表A的头指针
- 判断是否有剩余链表A和B中是否元素没有遍历,如果有直接将指针
pc指向对应链表的工作指针pa/pb,并释放头结点Lb
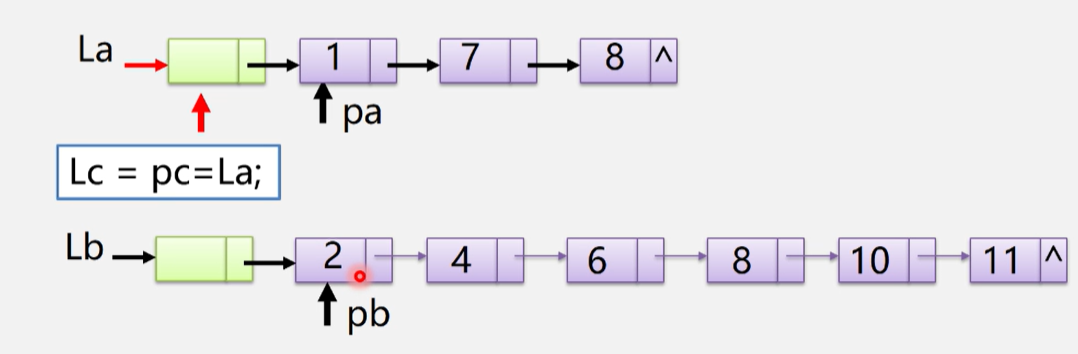
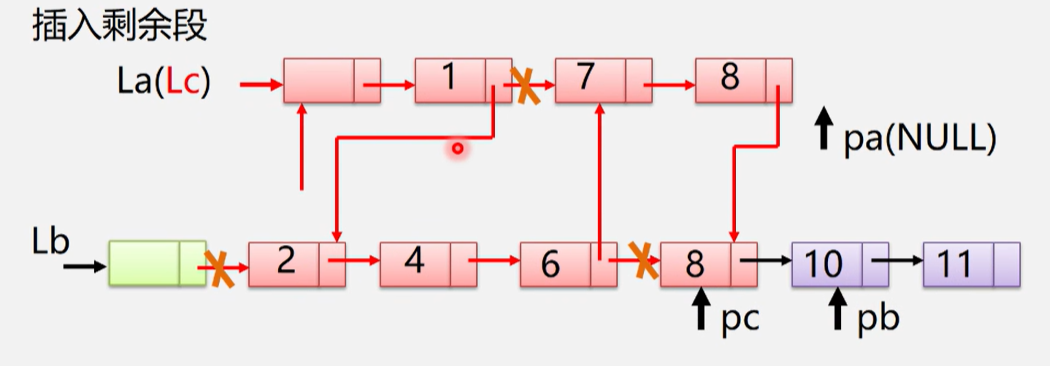
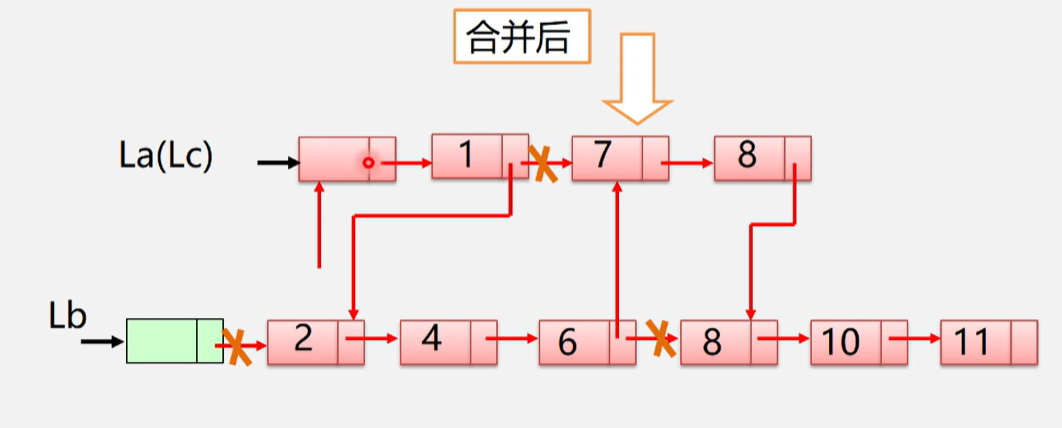
void MergeList_L(LinkList &La, LinkList &b, LinkList &Lc)
{
//声明工作指针pa\pb\pc
LinkList pa, pb, pc;
//将工作指针指向原来的链表的首元结点
pa = La->next;
pb = Lb->next;
//复用La的头结点作为Lc的头结点
pc = Lc = La;
//合并链表,并比较指针所指向的数据域大小,拼接在pc的后面
while(pa&&pb)
{
if(pa->data <= pb->data)
{
pc->next = pa;
//把pa结点接在新链表尾部
pc = pa;
//pc后移
pa = pa->next;
//pa后移
}
else
{
pc->next = pb;//pb结点接到新链表的尾部
pc = pb;//pc后移
pb = pb->next;//pb后移
}
}
//将剩余没有遍历完的链表接在新链表c的后面
pc->next = pa? pa:pb;
//释放Lb的头结点
delete Lb;
}
补充
pc->next = pa ? pa:pb的意思:pa是条件如果pa指向的不是空指针就直接把A链表剩余部分拼接在链表C的后面,反之,如果pa指向为空指针,就直接把B链表剩余的部分拼接在链表C的后面
线性表练习题单整理
文末说明
参考资料
本文学习与编写过程中参考了以下教程:
版权声明
- 本文作者:HawkPP
- 发布平台:CSDN
- 转载请注明出处,本文仅供学习交流使用
联系与反馈
如有疏漏或错误,欢迎各位大佬指正,我会及时修改完善!
感谢你的阅读与交流!
更多推荐
 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)