
【Java AI之路】 - 基于SpirngAI、百炼、Redis、MySQL的RAG及多路召回、COT
基础入门
RAG
什么是RAG
简单说,RAG(检索增强生成)是让 AI “先查资料再作答” 的技术,核心是解决大模型 “记不住新信息、容易说胡话” 的问题。
核心逻辑
-
先检索:AI 接到问题后,不直接凭 “记忆” 回答,而是先去指定的知识库(比如公司文档、最新新闻、专业资料)里找相关信息。
-
再生成:把找到的精准资料和自身知识结合,整理成自然语言回答,既保证准确性,又不脱离模型本身的语言能力。

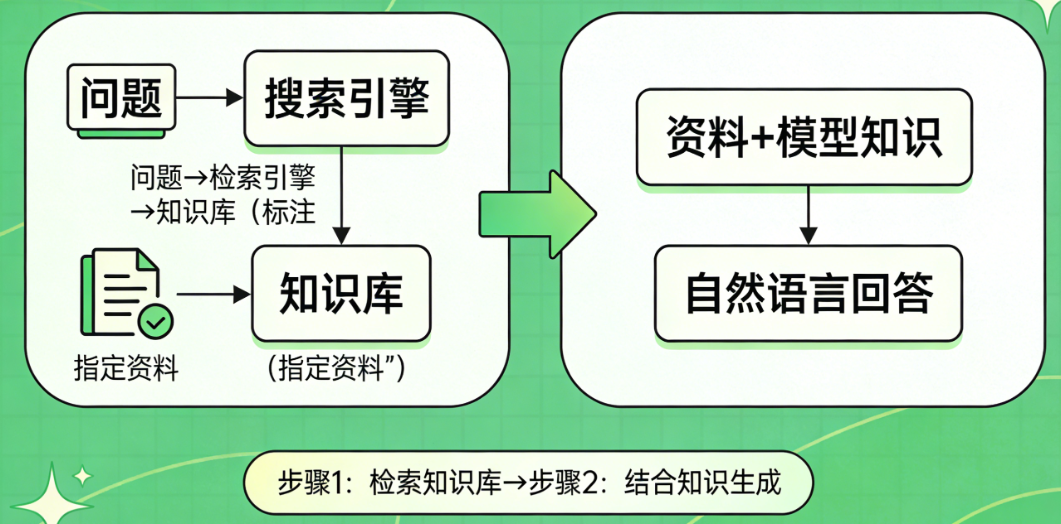
关键价值
-
解决 “知识过期”:大模型的训练数据有截止时间,RAG 能实时调取新信息(比如 2025 年的行业数据、刚发布的政策)。
-
降低 “幻觉率”:基于真实资料作答,减少 AI 编造不存在的事实、数据或逻辑。
-
支持 “专属知识”:可以接入企业内部文档、个人笔记等私域数据,让 AI 只围绕指定内容回答(比如公司产品手册、行业专属规范)。

举个实际例子
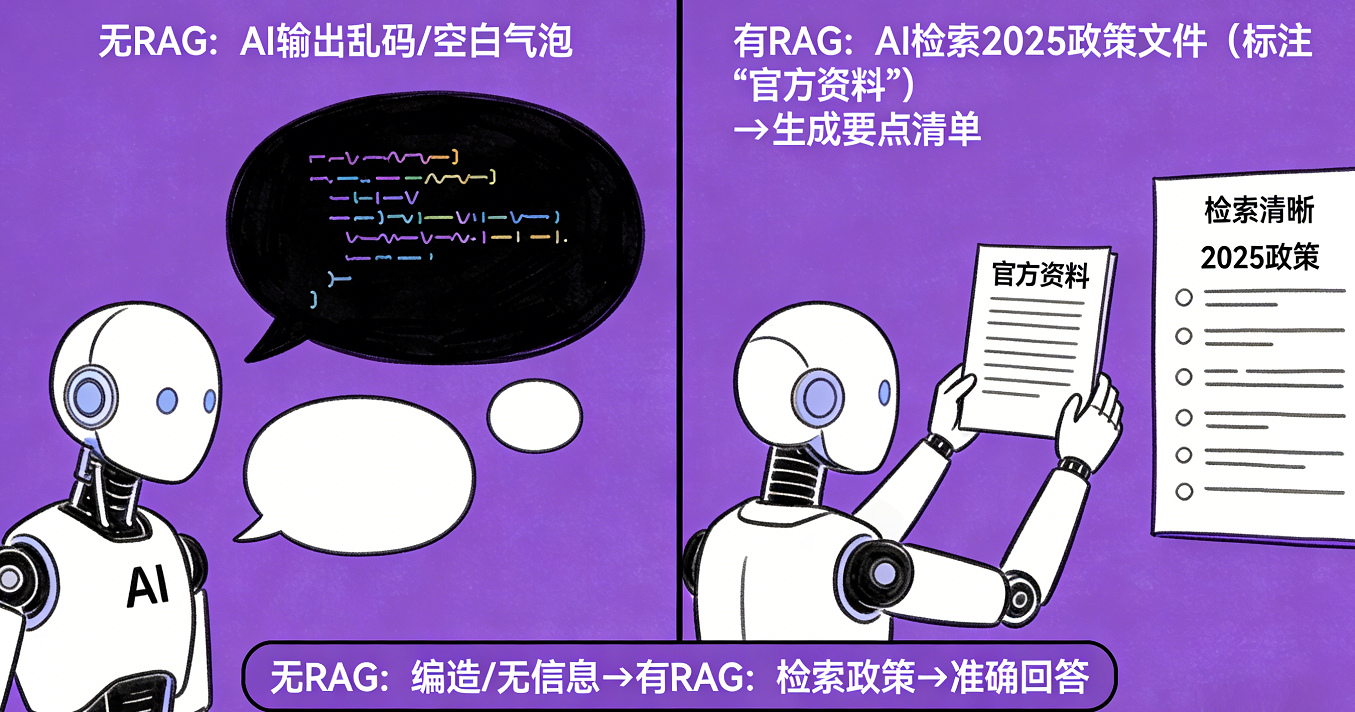
你问 AI “2025 年某行业的最新政策要求”,但 AI 的训练数据只到 2023 年:
- 没有 RAG:AI 可能会说 “没有相关信息”,或编造过时的政策。
- 有 RAG:AI 会先去检索 2025 年该行业的官方政策文件、权威解读,再基于这些真实资料,整理出清晰的政策要点和合规建议。
应用场景

以下是 RAG(检索增强生成)的 8 个典型应用场景,覆盖企业、生活、学习等核心领域:
- 企业内部知识库问答
- 核心用法:接入公司内部文档(员工手册、产品手册、流程规范、历史项目资料),员工提问时,AI 实时检索相关文档给出精准答案。
- 例子:新员工问 “报销流程和限额”,AI 直接调取最新报销规范,分步骤说明材料要求、审批节点;销售问 “某产品的技术参数”,快速检索产品手册给出对应信息。
- 智能客服(ToB/ToC)
- 核心用法:关联产品 FAQ、售后手册、用户反馈记录,客户咨询时,AI 检索匹配问题的解决方案,避免重复回复或答非所问。
- 例子:用户问 “家电保修范围”,AI 检索对应产品的保修政策,明确质保期限、免责条款;企业客户问 “API 接口调用限制”,调取技术文档给出具体参数和解决办法。
- 行业动态与政策解读
- 核心用法:接入行业权威网站、政府政策平台、最新研究报告,实时检索最新信息,帮助用户快速掌握动态。
- 例子:创业者问 “2025 年小微企业税收优惠政策”,AI 检索税务总局最新文件,整理优惠条件、申报流程;从业者问 “AI 行业最新监管要求”,汇总近期政策要点和合规建议。
- 学术科研与论文辅助
- 核心用法:对接学术数据库(知网、万方、SCI 论文库)、行业研究成果,科研人员提问时,检索相关文献、数据和研究结论。
- 例子:研究生问 “某算法的最新改进方向”,AI 检索近 3 年相关论文,总结主流改进思路和实验效果;医生问 “某疾病的最新治疗方案”,调取权威医学期刊的研究成果和临床指南。
- 个人私域知识管理
- 核心用法:接入个人笔记(Notion、备忘录)、阅读过的文章、收藏的资料,打造专属 “私人知识库”,快速检索记忆模糊的信息。
- 例子:你问 “之前收藏的 Excel 数据透视表教程”,AI 检索个人收藏文档,提取关键操作步骤;想回忆 “某本书的核心观点”,调取读书笔记给出提炼总结。
- 金融 /法律等专业领域咨询
- 核心用法:接入行业法规、案例库、市场数据,为专业咨询提供精准依据,避免主观判断。
- 例子:律师问 “某类合同纠纷的胜诉案例”,AI 检索相似司法案例,整理判决要点和法律依据;投资者问 “某股票的最新财务数据和行业对比”,调取财经平台数据给出客观分析。
- 产品说明书与使用指导
- 核心用法:关联产品电子版说明书、常见故障排查手册,用户遇到使用问题时,实时检索解决方案。
- 例子:用户问 “智能音箱怎么连接 WiFi”,AI 检索对应型号说明书,分步骤给出操作指引;程序员问 “某软件的函数用法”,调取开发文档给出语法示例和注意事项。
- 新闻资讯与热点汇总
- 核心用法:接入主流新闻平台、权威媒体账号,实时检索特定主题的最新资讯,自动汇总关键信息。
- 例子:你问 “近期某赛事的赛况和结果”,AI 检索最新报道,整理赛程、比分、核心亮点;关注 “某地区的天气预警”,调取气象部门实时信息,给出预警等级和应对建议。
步骤解析
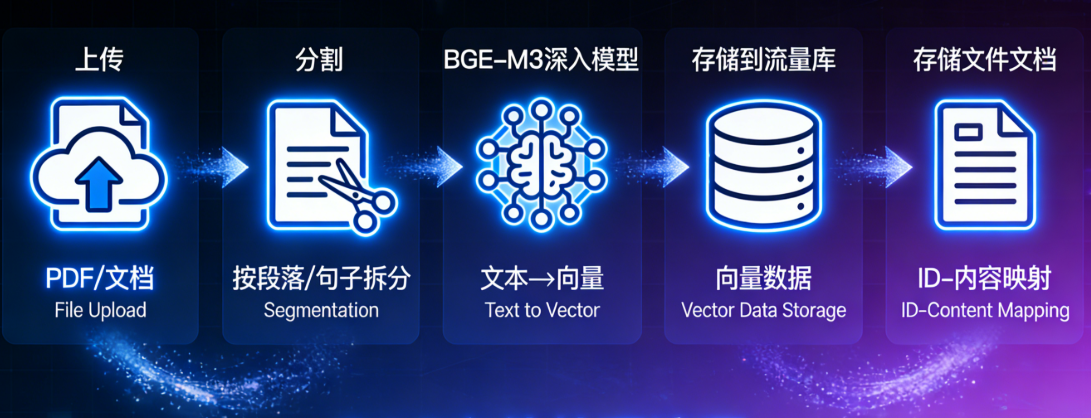
1. 文件上传
这是 RAG 文件处理的起始步骤,核心是接收、校验用户上传的文件,同时完成基础的预处理
- 文件接收:基于 Spring Boot 的
MultipartFile组件实现文件上传接口,支持的文件类型一般包括 TXT、PDF、DOCX、MD 等常见的文本类文档,也可以扩展支持 PPTX、XLSX(需要提取其中的文本内容) - 文件校验:
- 校验文件大小,避免过大文件占用资源
- 校验文件格式,拒绝非允许的文件类型
- 校验文件的完整性,避免损坏的文件
- 预处理:将文件的元信息(文件名、文件大小、上传时间、文件唯一标识)存储到关系型数据库(比如 MySQL)中,方便后续和向量数据做关联
2. 文档分割
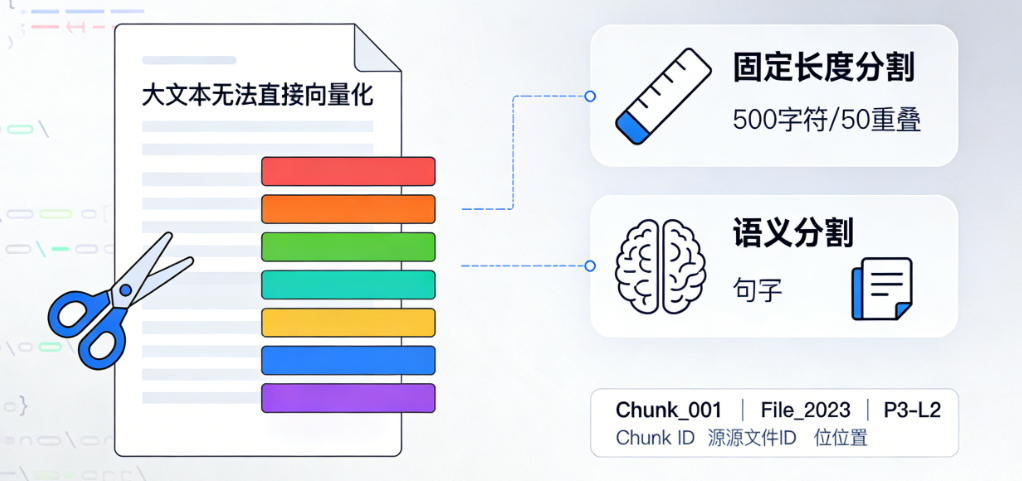
这一步是为了解决大文本无法直接进行向量化的问题(大模型的上下文窗口有限),同时提升后续检索的精准度
- 核心逻辑:将完整的文档,按照一定的规则切割为多个小的文本片段(Chunk)
- 常用分割策略:
- 按固定长度分割:比如每 500 个字符为一个 Chunk,同时设置一定的重叠长度(比如 50 个字符),避免切割到完整的语义单元
- 按语义分割:借助 Ollama 的本地大模型,或者 Spring AI 的语义分割工具,按照句子、段落的语义完成分割,这种方式可以避免切断完整的语义
- 处理细节:为每个分割后的 Chunk 生成唯一 ID,同时记录这个 Chunk 所属的源文件 ID、Chunk 在源文件中的位置信息,方便后续溯源
3. 向量化
将分割后的文本片段,转换为计算机可以理解的向量数据
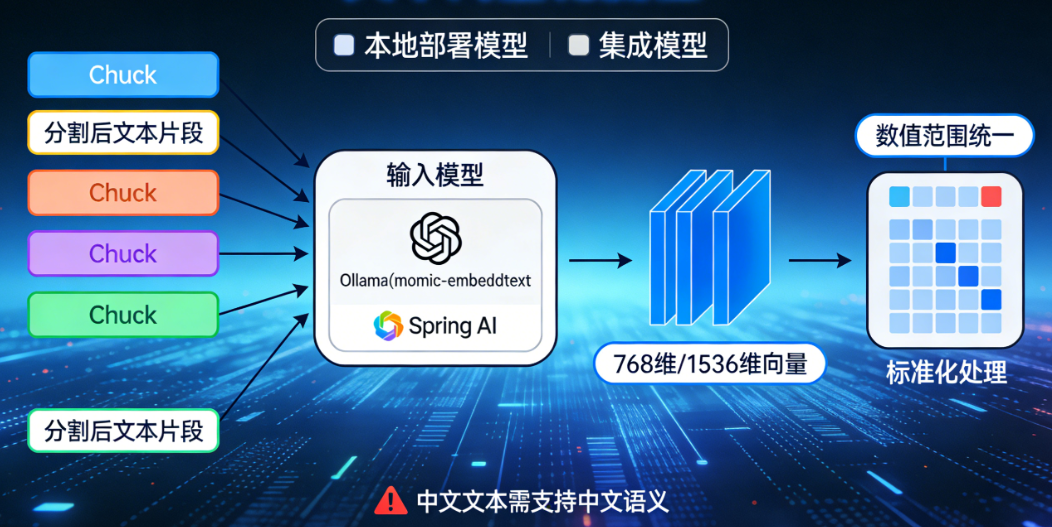
- 工具选择:可以选择 Ollama 部署的本地嵌入模型(比如
nomic-embed-text),或者 Spring AI 集成的嵌入模型 - 处理流程:
- 读取分割后的文本 Chunk
- 将文本传入嵌入模型,模型会将文本转换为固定维度的向量(比如 768 维、1536 维)
- 对生成的向量做标准化处理,保证向量的数值范围统一
- 注意事项:如果是中文文本,需要确保嵌入模型支持中文语义的理解,避免向量无法准确表达文本语义
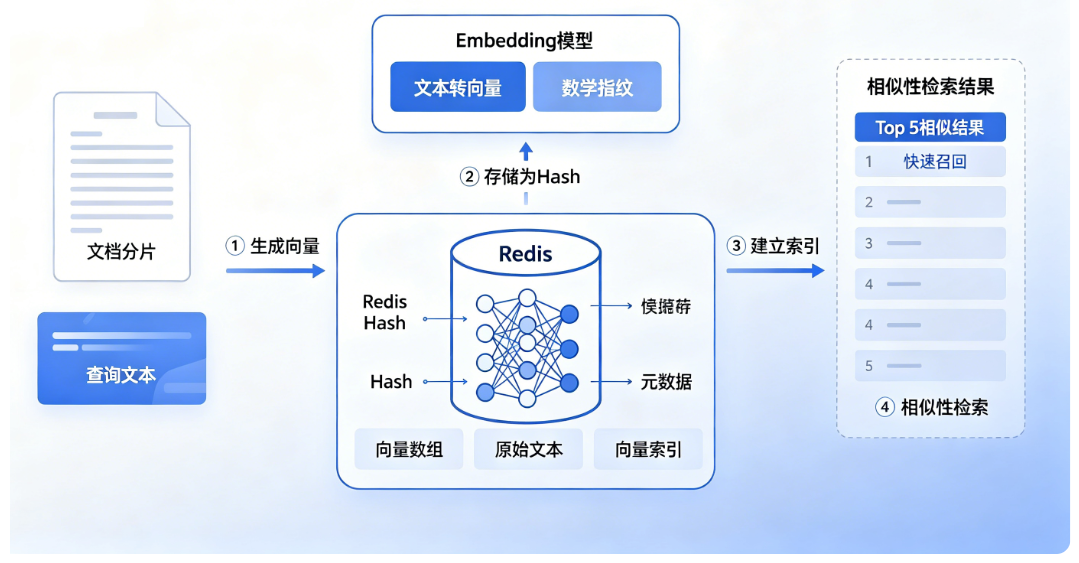
4. 向量库存储
将生成的向量数据存储到向量数据库中,用于后续的相似性检索。而 Redis 作为一个向量数据库,它的核心作用就是高效地存储这些由 Embedding 模型生成的向量,并针对它们进行快速的相似性搜索。
简单来说,你可以把 Redis 想象成一个为 AI 应用量身定制的智能搜索引擎。
Redis 作为向量数据库是如何工作的?
当你的应用调用 vectorStore.add(documents) 时,背后发生了这几步:
- 生成向量:Spring AI 会调用你配置的 Embedding 模型(如阿里百炼的
text-embedding-v3),将文本内容(如文档分片)转换成一个浮点数数组,也就是向量。这个向量就像是该文本的“数学指纹”。 - 存储为 Hash:Redis 不会把向量当作文本存,而是将向量数组、原始文本和元数据(如来源、分片序号)打包,存储在一个 Redis Hash 数据结构中。这个 Hash 的 key 通常会带上你配置的前缀(如
rag:)。 - 建立索引:这一步最关键。只有当你开启了
initialize-schema: true,Spring AI 才会在 Redis 中创建一个向量索引。这个索引使用专门的算法(如 HNSW),为存储的向量建立一种可以快速查找“邻居”的目录。 - 相似性检索:当你调用
vectorStore.similaritySearch(query)时,系统会先将你的问题文本也生成一个查询向量,然后 Redis 会利用前面建立的索引,快速找到与之在“距离”上最接近的 K 个(如 Top 5)已存储的向量,并返回它们对应的原始文本。
5. 文档对应关系存储
建立源文件、文本 Chunk、向量数据之间的关联关系,保证检索结果可以溯源到源文件
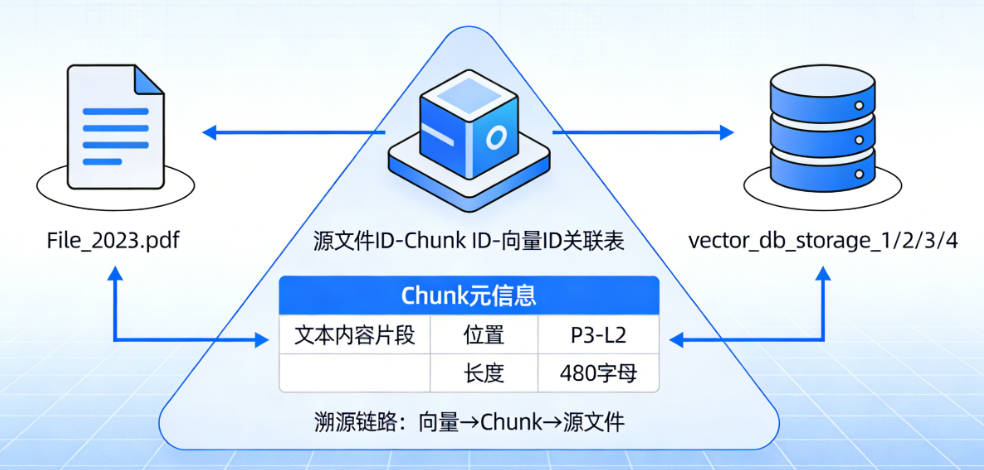
- 存储内容:
- 在关系型数据库中,维护源文件 ID、Chunk ID、向量 ID 的对应关系
- 同时存储 Chunk 的元信息:比如 Chunk 的文本内容、Chunk 在源文件中的位置、Chunk 的长度等
- 作用:当后续检索到相关的向量时,可以通过这个对应关系,找到对应的 Chunk 文本,以及这个 Chunk 所属的源文件,最终可以将源文件的完整内容返回给用户
向量化
在 RAG 技术(以及整个大模型应用领域)中,向量化(Vectorization) 本质是将非结构化的文本信息转换为计算机可理解、可计算的数值向量的过程,可以把它理解为给每一段文本生成一串 “数字身份证”,这串数字能精准表达文本的语义、情感、逻辑等核心特征。
一、为什么需要向量化?
计算机天生不理解 “文字”,只懂 “数字”。比如:
- 你看到 “猫” 和 “小猫”,能立刻判断它们语义高度相似;
- 但计算机直接处理文字时,只能看到两个不同的字符串,无法感知这种相似性。
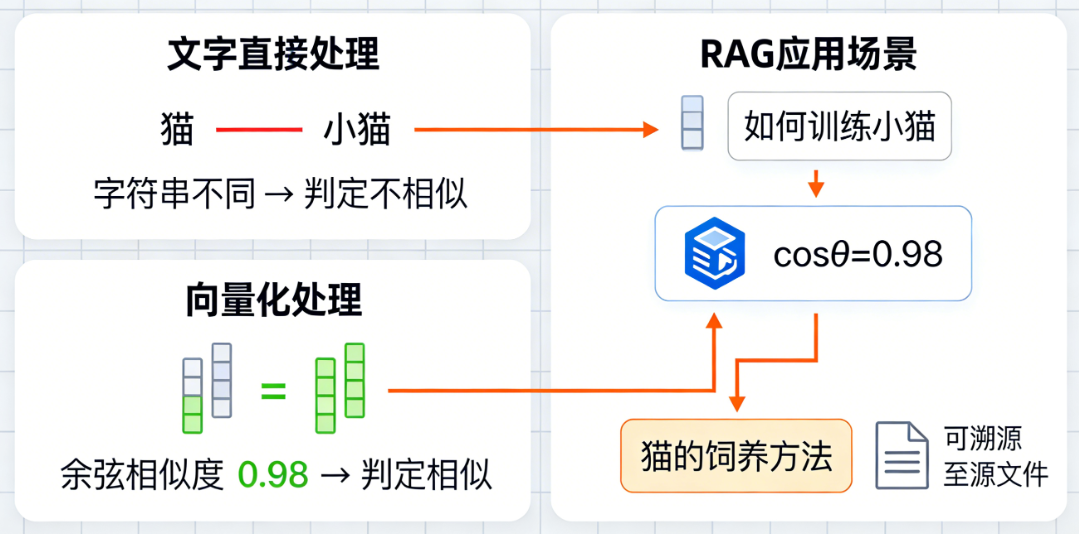
而向量化就是解决这个问题:把 “猫” 转换成 [0.12, 0.35, -0.21, ...](一串固定长度的数字),把 “小猫” 转换成 [0.11, 0.34, -0.22, ...]—— 这两个向量的数值高度接近,计算机就能通过计算向量间的距离(比如余弦相似度),判断出 “猫” 和 “小猫” 语义相似。
在 RAG 中,向量化的核心价值是:让后续的 “相似性检索” 成为可能(比如用户提问 “如何训练小猫”,能快速从向量库中找到 “猫的饲养方法” 相关的文本片段)。
二、向量化的核心逻辑
以你用到的 Ollama(嵌入模型)+ Spring AI 为例,向量化的过程可以拆解为 3 步:
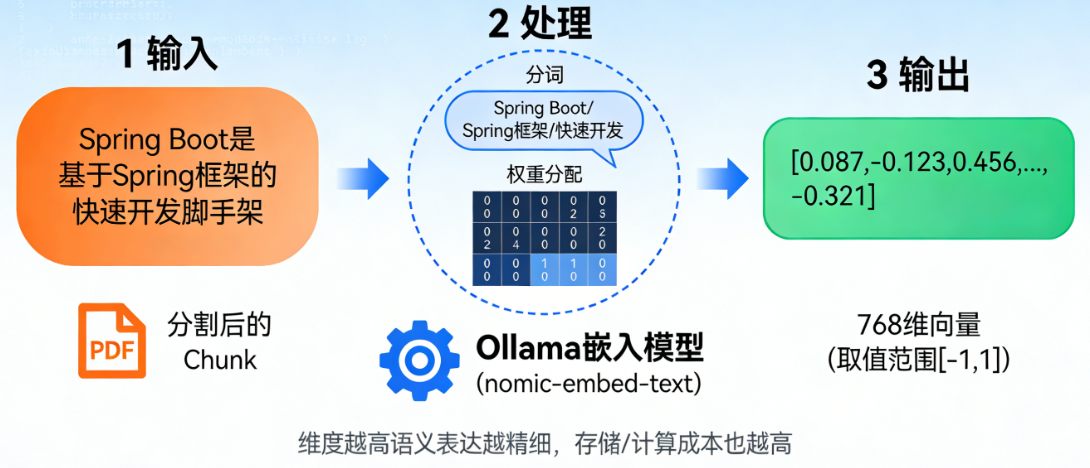
- 输入:分割后的文本片段(Chunk)
比如从 PDF 中分割出的一句话:“Spring Boot 是基于 Spring 框架的快速开发脚手架”。
- 处理:嵌入模型(Embedding Model)的计算
Ollama 可以部署专门的嵌入模型(比如 nomic-embed-text、bge-large),这类模型的核心作用就是 “语义转数字”:
- 模型会先对文本做分词(比如把上面的句子拆成 “Spring Boot”“Spring 框架”“快速开发” 等语义单元);
- 再通过预训练的语义规则,给每个语义单元分配数值权重,最终拼接成固定维度的向量(比如 768 维、1024 维 —— 维度越高,语义表达越精细,但存储 / 计算成本也越高)。
- 输出:固定长度的数值向量
比如最终生成的向量可能是:
[0.087, -0.123, 0.456, 0.098, ..., -0.321](共 768 个数字,每个数字的取值范围通常在 [-1, 1] 之间)。
三、向量化的关键特征
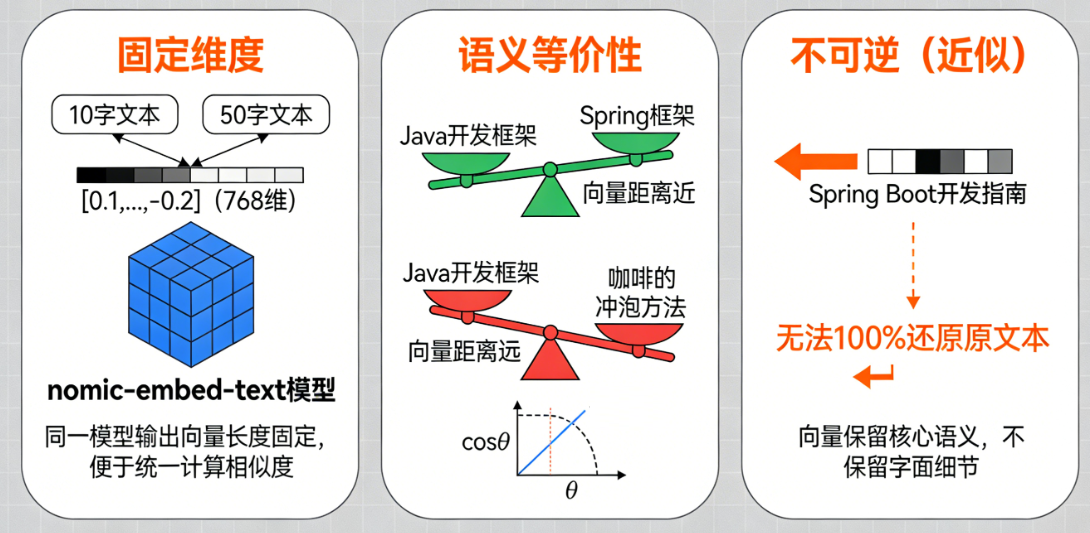
- 固定维度:同一模型生成的向量长度是固定的(比如
nomic-embed-text生成 768 维向量),不管输入文本是 10 个字还是 50 个字,输出向量的长度都一样 —— 这是为了后续能统一计算相似度。 - 语义等价性:语义相似的文本,向量数值高度相似;语义无关的文本,向量数值差异很大。比如:
- “Java 开发框架” 和 “Spring 框架” → 向量距离近;
- “Java 开发框架” 和 “咖啡的冲泡方法” → 向量距离远。
- 不可逆(近似):从文本能生成向量,但从向量无法 100% 还原出原文本(向量只保留核心语义,不保留字面细节)。
向量库
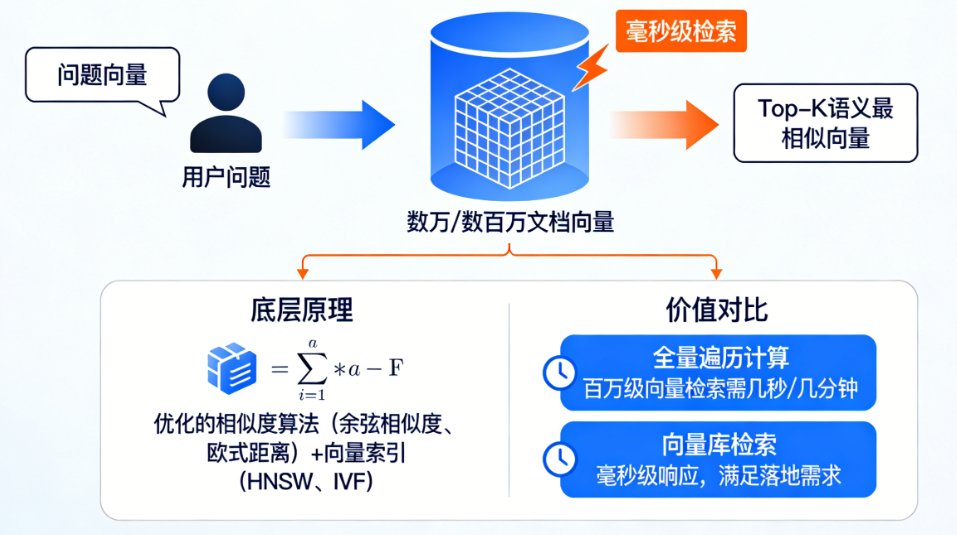
在 RAG(检索增强生成)和大模型应用体系中,向量库(Vector Database) 是专门用于存储、管理、检索「文本 / 数据的向量表示」的核心组件 ,可以把它理解为 “语义级别的数据库”,普通数据库(如 MySQL)按 “关键词 / 主键” 检索,而向量库按 “语义相似性” 检索,是实现 RAG 精准检索的核心基础设施。
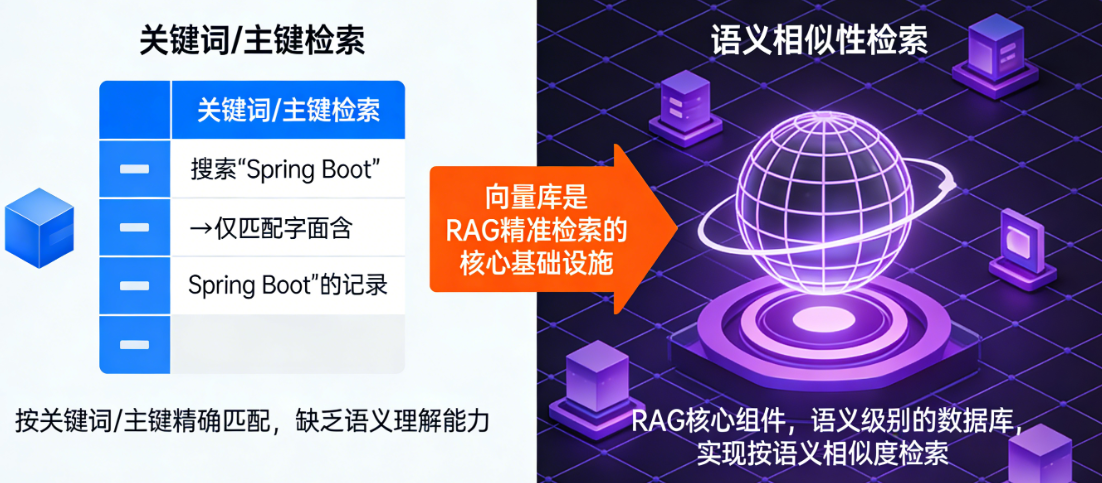
向量库的核心作用
存储海量向量 + 快速找到和 “目标向量” 语义最相似的向量,并关联回原始文本 / 数据,为 RAG 提供 “精准的本地知识库素材”。
拆解为 3 个具体作用:
向量存储:安全、结构化管理向量数据
-
通过生成的文档片段(Chunk)向量(比如 1024维浮点数数组),需要一个专门的地方存储 ,向量库会将向量与「Chunk ID、源文件 ID、Chunk 文本、上传时间」等元信息绑定存储,保证数据完整性。
-
对比:如果直接存在 MySQL 中,只能用
BLOB/TEXT存向量数组,无法高效计算相似度;而 Redis 这类向量库会对向量做结构化存储(dense_vector字段),适配向量的数值特性。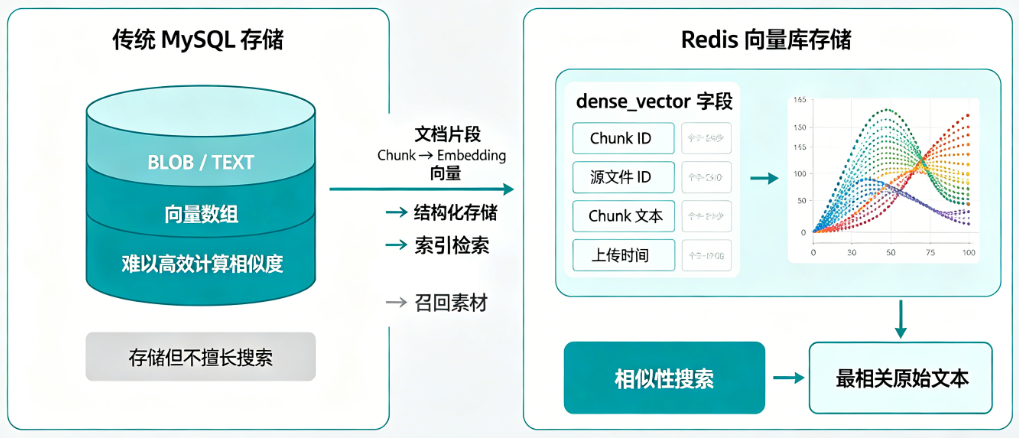
相似性检索:核心价值,实现 “语义匹配”
这是向量库最核心的作用 : 当用户提问生成 “问题向量” 后,向量库能在毫秒级内从数万 / 数百万个文档向量中,找到「语义最相似的 Top-K 个向量」:
-
底层原理:通过优化的相似度算法(如余弦相似度、欧式距离)+ 向量索引(如 HNSW、IVF),避免 “全量遍历计算”(否则百万级向量检索要几秒 / 几分钟,无法落地);
向量管理:支撑知识库的动态维护
实际落地中,你的本地知识库会不断更新(新增文件、删除过期文件、修改文档内容),向量库能支持:
- 新增:上传新文件后,分割→向量化→插入向量库;
- 删除:删除源文件时,批量删除关联的向量;
- 更新:修改文档后,重新分割向量化,替换旧向量;
- 过滤:检索时可结合元信息过滤(比如 “只检索 2025 年上传的 PDF 文档的向量”)。
向量库(Redis)解决哪些问题
| 场景 | 普通数据库(MySQL) | 向量库(Redis) |
|---|---|---|
| 检索逻辑 | 按“关键词 / 主键”精确匹配(比如查 “Spring Boot” 只能找到包含该字符串的内容) | 按“语义”模糊匹配“ |
| 向量存储 | 无专门字段,只能存为字符串 / 二进制,效率低 | 原生支持向量数据结构(通过 Redis Modules),适配向量数值特性 |
| 相似度计算 | 无内置算法,需手动写代码遍历计算,速度极慢 | 内置余弦相似度 / 欧氏距离等算法,结合向量索引(如 HNSW),毫秒级检索 |
| 海量数据检索 | 百万级向量全量计算,耗时分钟级 | 百万级向量检索,耗时毫秒级(索引优化,例如使用 HNSW 算法) |
举个例子:
- 用 MySQL 查 “如何用 Spring Boot 做向量检索”,只能找到包含 “Spring Boot”+“向量检索” 关键词的文本;
- 用 Redis 向量库查,能找到 “Spring Boot 整合 Redis 实现相似性查询” 这类语义相似但关键词不完全匹配的文本 —— 这正是 RAG 需要的 “精准检索”。
Redis 向量库的落地价值
- 保证回答的“本地性”:所有向量都存在本地 Redis(或 Redis Stack)中,检索过程不依赖外部服务,数据隐私可控。
- 提升回答的“精准度”:大模型不再凭空回答,而是基于向量库检索到的“语义最匹配”的本地素材作答,避免“胡说八道”。
- 支撑高并发/大数据量:如果你的知识库有上千份文档、数百万个 Chunk,Redis 基于内存的架构和向量索引优化能保证用户提问后 100~500ms 内返回检索结果,满足实际使用的响应要求。
- 溯源便捷:向量库存储了向量与源文件/Chunk 的关联关系(通过 Hash 或 JSON 结构),检索结果能直接关联到原始文档,方便用户核对答案来源。
常见向量库
向量库的核心价值在于高维向量的高效存储与快速相似性检索,不同产品在性能、功能、部署方式上各有侧重,以下是业界常用的几款向量库:
1. FAISS(Facebook AI Similarity Search)
- 核心定位:Facebook 开源的轻量级向量检索库,专注于单机高性能向量检索。
- 关键特性:支持稠密向量的 L2、内积等相似度计算,提供多种索引类型(Flat、IVF、HNSW 等),可通过量化(Scalar Quantization、Product Quantization)降低存储成本。
- 适用场景:小规模数据场景、离线向量检索任务,需结合其他工具实现分布式部署。
2. Pinecone
- 核心定位:云端托管式向量数据库,主打 “零运维” 的向量检索服务。
- 关键特性:完全托管,支持自动扩缩容,提供 REST API 接口,兼容多种向量生成模型,内置数据备份与高可用机制。
- 适用场景:快速上线的业务系统、不愿投入运维资源的中小团队,按使用量付费。
3. Weaviate
- 核心定位:开源的分布式向量数据库,支持混合检索(向量检索 + 结构化数据过滤)。
- 关键特性:基于 GraphQL 查询接口,支持动态模式定义,内置文本向量化功能(集成 Hugging Face 模型),支持容器化部署。
- 适用场景:需要结合结构化数据与非结构化数据检索的场景,如智能文档管理系统。
4. Qdrant
- 核心定位:轻量级开源向量数据库,主打 “简单易用” 与 “低资源占用”。
- 关键特性:支持稠密向量与稀疏向量检索,提供 REST API 和 gRPC 接口,支持动态索引更新,部署简单(单二进制文件或容器)。
- 适用场景:小规模部署、边缘计算场景、快速原型验证。
5. Milvus
- 核心定位:开源分布式向量数据库,专为大规模高维向量检索设计,兼顾性能、可靠性与扩展性。
- 关键特性:支持 PB 级向量存储、毫秒级检索响应,兼容多索引类型与相似度度量方式,提供完善的分布式架构与运维工具。
- 适用场景:大规模生产环境、高并发检索需求、多模态数据处理系统。
6.ElasticSearch
- 核心定位:开源分布式全文检索与分析引擎,支持向量存储 / 检索能力,兼顾文本检索与语义相似性检索,适配多场景数据处理需求。
- 关键特性:原生支持全文关键词检索 + 向量稠密向量(dense_vector)存储,内置余弦相似度 / 欧氏距离等度量方式,具备成熟的分布式分片 / 副本机制、动态扩缩容能力,可结合元数据过滤实现精准的混合检索(关键词 + 语义)。
- 适用场景:中小规模向量检索场景、文本 + 向量混合检索需求、已有 ES 生态的企业级生产环境、需轻量化部署的本地知识库系统。
7.Redis(向量数据库)
- 核心定位:开源内存数据结构存储,通过模块(RediSearch、RedisJSON)扩展为高性能向量数据库,兼顾低延迟检索与数据持久化。
- 关键特性:
- 纯内存架构:数据存储在内存中,读写性能极高(微秒级响应),适合低延迟场景。
- 向量索引支持:通过RediSearch模块支持HNSW(分层可导航小世界图)索引,实现十亿级向量毫秒级相似性检索。
- 多模态数据存储:原生支持Hash、JSON等多种数据结构,可同时存储向量、元数据和原始文本,无需额外映射。
- 易用性与生态:与Spring AI等框架深度集成,提供自动化的Schema初始化(
initialize-schema=true),简化开发流程。 - 持久化与高可用:支持RDB快照和AOF日志持久化,可通过Redis Sentinel或Cluster模式构建高可用集群。
- 适用场景:
- 中小规模生产环境:百万级向量规模,需毫秒级检索响应的RAG应用。
- 混合存储需求:同时需要向量检索与高速缓存的场景(如会话状态、频繁访问的元数据)。
- 低延迟敏感系统:对响应时间要求严格(如实时推荐、智能问答)。
- 轻量化本地部署:资源有限但需向量检索能力的边缘计算或开发测试环境。
环境搭建
导入依赖
<properties>
<java.version>17</java.version>
<spring-ai.version>1.1.7</spring-ai.version>
<spring-ai-alibaba.version>1.1.2.3</spring-ai-alibaba.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-openai</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-vector-store-redis</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-advisors-vector-store</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-rag</artifactId>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-spring-boot3-starter</artifactId>
<version>3.5.15</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.33</version>
</dependency>
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
</dependency>
</dependencies>
<!--引入各种bom包:指定了各种依赖的版本-->
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>${spring-ai.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
主配置文件
spring:
ai:
openai:
api-key: ${ALI_API_KEY}
base-url: https://dashscope.aliyuncs.com/compatible-mode
chat:
options:
model: qwen3.7-max
temperature: 0.7
max-tokens: 1024
embedding:
options:
model: text-embedding-v3
dimensions: 1024
vectorstore:
redis:
initialize-schema: true # 自动创建索引
index-name: knowledge-embedding-index # 索引名称
prefix: "rag:" # key前缀
data:
redis:
host: localhost
port: 6379
# password: # 如果有密码
timeout: 60000ms
jedis:
pool:
max-active: 8
max-idle: 8
min-idle: 0
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/mall_116?useUnicode=true&characterEncoding=utf8&serverTimezone=UTC
username: root
password: root1234
logging:
level:
com.woniuxy.spring: debug
rerank:
top-n: 5 # 最终返回数量
max-size: 30 # 参与重排的最大文档数
min-term-length: 2 # 最小词元长度
stop-words: "" # 可选停用词,逗号分隔(为空则不过滤)
rag:
# 文件上传
file-upload-dir: D:/knowledge-uploads/
max-file-size-mb: 100
allow-suffix: [".pdf", ".docx", ".doc", ".txt", ".md"]
# 切片与向量化
chunk-size: 300
chunk-overlap: 50
embed-batch-size: 10
# 向量检索
vector-top-k: 20
vector-similarity-threshold: 0.20
# Redis关键词检索
keyword-top-k: 10
redis-index-name: knowledge-embedding-index
# 语义缓存
cache-max-size: 500
cache-expire: 24h
cache-candidate-limit: 30
semantic-similarity-threshold: 0.85
# 本地重排
rerank-top-n: 5
rerank-max-size: 30
rerank-min-term-length: 2
rerank-stop-words: 你,我,他,的,了,是
enable-cot-record: true
cot-async-save: true
AI配置
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class ChatConfig {
@Bean
public ChatClient chatClient(ChatModel chatModel){
return ChatClient
.builder(chatModel)
.build();
}
}
文件上传
controller
package com.woniuxy.spring.controller;
import com.woniuxy.spring.service.VectorService;
import lombok.RequiredArgsConstructor;
import org.springframework.web.bind.annotation.*;
import org.springframework.web.multipart.MultipartFile;
@RestController
@RequestMapping("/ai")
@RequiredArgsConstructor
public class ChatController {
private final VectorService vectorService;
// 上传文件
@PostMapping("/upload")
public int uploadFile(MultipartFile file) throws Exception {
// 调用向量服务上传文件
return vectorService.uploadFile(file);
}
}
VectorService
import org.springframework.web.multipart.MultipartFile;
public interface VectorService{
int uploadFile(MultipartFile file) throws Exception;
}
实现类
package com.woniuxy.spring.service.impl;
import com.woniuxy.spring.service.VectorService;
import com.woniuxy.spring.util.DocumentSplitUtil;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.ai.document.Document;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Service;
import org.springframework.web.multipart.MultipartFile;
import java.io.File;
import java.util.List;
@Slf4j
@Service
@RequiredArgsConstructor
public class VectorServiceImpl implements VectorService {
@Value("${knowledge.file-upload-dir}")
private String fileUploadDir;
private final VectorStore vectorStore;
@Override
public int uploadFile(MultipartFile file) throws Exception {
// 1.保存文件到本地
String filePath = fileUploadDir + File.separator + file.getOriginalFilename();
file.transferTo(new File(filePath));
// 2.分割文件: 会自动给每一个document分配一个id,此id后面会作为redis中的key
List<Document> documents = DocumentSplitUtil.splitFileToDocuments(filePath, 300, 50);
// 3.每10个向量化并保存到redis:因为阿里的嵌入模型最多支持10个document
int batchSize = 10;
for (int i = 0; i < documents.size(); i += batchSize) {
int end = Math.min(i + batchSize, documents.size()); // 防止越界
vectorStore.add(documents.subList(i, end));
}
return documents.size();
}
}
DocumentSplitUtil工具类
import org.springframework.ai.document.Document;
import java.io.File;
import java.nio.charset.StandardCharsets;
import java.nio.file.Files;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* 文件文本分片工具:按字符长度分割,带重叠,输出SpringAI Document列表
*/
public class DocumentSplitUtil {
/**
* 读取文件并分割为 Document 集合
* @param filePath 文件路径
* @param maxChunkSize 单段最大字符长度
* @param overlapSize 重叠字符长度
* @return List<Document> 每一段文本封装成Document
* @throws Exception 文件读取/参数异常
*/
public static List<Document> splitFileToDocuments(String filePath, int maxChunkSize, int overlapSize) throws Exception {
// 参数校验
if (maxChunkSize <= 0) {
throw new IllegalArgumentException("分片最大长度必须 > 0");
}
if (overlapSize < 0 || overlapSize >= maxChunkSize) {
throw new IllegalArgumentException("重叠长度不能小于0且不能大于等于分片长度");
}
File file = new File(filePath);
if (!file.exists() || !file.isFile()) {
throw new IllegalArgumentException("文件不存在:" + filePath);
}
// 读取全文
String fullText = Files.readString(file.toPath(), StandardCharsets.UTF_8);
return splitTextToDocuments(fullText, filePath, maxChunkSize, overlapSize);
}
/**
* 纯文本字符串分片并转Document
* @param text 完整文本
* @param sourcePath 来源文件路径(存入元数据)
* @param maxChunkSize 单段最大长度
* @param overlapSize 重叠长度
* @return Document列表
*/
public static List<Document> splitTextToDocuments(String text, String sourcePath, int maxChunkSize, int overlapSize) {
List<Document> documentList = new ArrayList<>();
if (text == null || text.isBlank()) {
return documentList;
}
int textLen = text.length();
int start = 0;
int chunkIndex = 0;
while (start < textLen) {
int end = Math.min(start + maxChunkSize, textLen);
String chunkText = text.substring(start, end);
// 构造元数据:记录来源、分片序号、文本长度
Map<String, Object> meta = new HashMap<>();
meta.put("source", sourcePath);
meta.put("chunkIndex", chunkIndex);
meta.put("chunkLength", chunkText.length());
meta.put("startPos", start);
meta.put("endPos", end);
// 封装Document
Document doc = new Document(chunkText, meta);
documentList.add(doc);
// 滑动窗口:下一段起始 = 当前起点 + 块大小 - 重叠
start = start + maxChunkSize - overlapSize;
chunkIndex++;
}
return documentList;
}
}
存储文件信息
添加依赖
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-spring-boot3-starter</artifactId>
<version>3.5.15</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.33</version>
</dependency>
建表sql
create table file_info(
id bigint primary key,
file_name varchar(256),
file_type varchar(32),
file_path varchar(256),
create_time datetime
);
create table file_document(
id bigint primary key,
file_info_id bigint,
document_id varchar(64)
);
实体类
@Data
@TableName("file_info")
public class FileInfo {
@TableId(type = IdType.ASSIGN_ID)
private Long id;
private String fileName;
private String fileType;
private String filePath;
private LocalDateTime createTime;
}
@Data
@TableName("file_document_re")
public class FileDocumentRe {
@TableId(type = IdType.ASSIGN_ID)
private Long id;
private Long fileInfoId;
private String documentId;
}
mapper
@Mapper
public interface FileInfoMapper extends BaseMapper<FileInfo> {
}
@Mapper
public interface FileDocumentReMapper extends BaseMapper<FileDocumentRe> {
}
service
public interface FileInfoService extends IService<FileInfo> {
public void saveFileInfo(String fileName,String filePath, List<Document> documents);
}
public interface FileDocumentReService extends IService<FileDocumentRe> {
}
实现类
import lombok.Data;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.ai.document.Document;
import org.springframework.scheduling.annotation.Async;
import org.springframework.stereotype.Service;
import java.time.LocalDateTime;
import java.util.List;
@Slf4j
@Data
@Service
@RequiredArgsConstructor
public class FileInfoServiceImpl extends ServiceImpl<FileInfoMapper, FileInfo> implements FileInfoService {
private final FileDocumentReService fileDocumentReService;
@Async("chatTaskExecutor")
@Override
public void saveFileInfo(String fileName, String filePath, List<Document> documents) {
log.info("文件 {} 开始保存文件信息到数据库,线程id:{}", fileName, Thread.currentThread().getId());
// 1.创建文件信息实体
FileInfo fileInfo = new FileInfo();
fileInfo.setFileName(fileName);
fileInfo.setFilePath(filePath);
fileInfo.setFileType(fileName.substring(fileName.lastIndexOf(".") + 1));
fileInfo.setCreateTime(LocalDateTime.now());
// 2.保存
save(fileInfo);
// 3.保存文件文档实体
fileDocumentReService.saveBatch(documents.stream().map(document -> {
FileDocumentRe fileDocument = new FileDocumentRe();
fileDocument.setFileInfoId(fileInfo.getId());
fileDocument.setDocumentId(document.getId());
return fileDocument;
}).toList());
}
}
@Service
public class FileDocumentReServiceImpl extends ServiceImpl<FileDocumentReMapper, FileDocumentRe> implements FileDocumentReService {
}
修改VectorServiceImpl,在uploadFile中新增将向量化信息存入数据库
package com.woniuxy.spring.service.impl;
import com.woniuxy.spring.service.FileInfoService;
import com.woniuxy.spring.service.VectorService;
import com.woniuxy.spring.util.DocumentSplitUtil;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.ai.chat.client.advisor.vectorstore.QuestionAnswerAdvisor;
import org.springframework.ai.document.Document;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Service;
import org.springframework.web.multipart.MultipartFile;
import java.io.File;
import java.util.List;
@Slf4j
@Service
@RequiredArgsConstructor
public class VectorServiceImpl implements VectorService {
@Value("${knowledge.file-upload-dir}")
private String fileUploadDir;
private final VectorStore vectorStore;
private final FileInfoService fileInfoService;
@Override
public int uploadFile(MultipartFile file) throws Exception {
// 1.保存文件到本地
String filePath = fileUploadDir + File.separator + file.getOriginalFilename();
file.transferTo(new File(filePath));
// 2.分割文件: 会自动给每一个document分配一个id,此id后面会作为redis中的key
List<Document> documents = DocumentSplitUtil.splitFileToDocuments(filePath, 300, 50);
// 3.每10个向量化并保存到redis:因为阿里的嵌入模型最多支持10个document
int batchSize = 10;
for (int i = 0; i < documents.size(); i += batchSize) {
int end = Math.min(i + batchSize, documents.size()); // 防止越界
vectorStore.add(documents.subList(i, end));
}
// 4.保存到数据库
fileInfoService.saveFileInfo(file.getOriginalFilename(), filePath, documents);
return documents.size();
}
@Override
public String chat(String message) {
return chatClient.prompt()
.advisors(QuestionAnswerAdvisor.builder(vectorStore).build())
.user(message)
.call()
.content();
}
}
知识库问答
基本流程
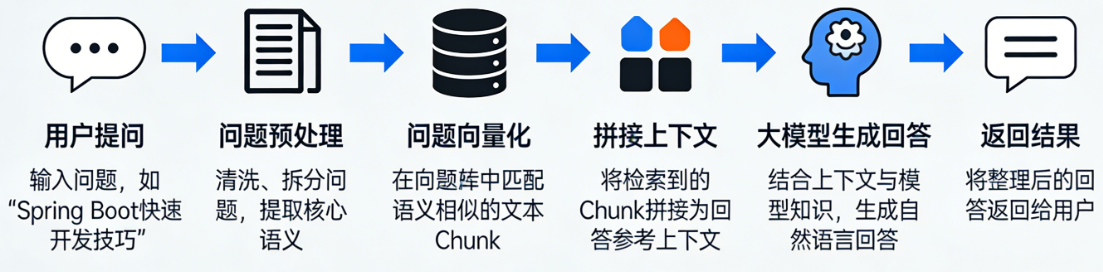
代码实现
controller
@GetMapping("/chat/{message}")
public String chat(@PathVariable("message")String message){
return vectorService.chat(message);
}
VectorService
String chat(String message);
实现类
private final ChatClient chatClient;
@Override
public String chat(String message) {
return chatClient.prompt()
.advisors(QuestionAnswerAdvisor.builder(vectorStore).build())
.user(message)
.call()
.content();
}
高阶优化
RAG存在的问题
检索粗糙:只抓相似文本,不理解文档全局逻辑,经常断章取义;
上下文窗口浪费:一次性塞一堆无关片段,挤占模型输入长度;
无法沉淀知识:每次提问都重复检索,知识不能结构化存储、复用;
幻觉问题难根治:检索片段碎片化,模型容易脑补不存在信息;
没有知识溯源链路:回答完不知道哪句话来自哪份文档、哪一段。
高召回率优化
召回率:所有和问题相关的文档 / 知识片段,有多少被成功检索出来。
- 传统 RAG 只靠单一向量检索,经常漏关键资料(召回率低);
- 高要求 RAG 必须多策略融合:混合检索(向量 + 关键词 + 全文检索)、多路召回、重排 Rerank、分层索引、实体检索;
- 业务意义:漏了关键资料,回答必然错误、片面,高召回是一切准确回答的基础。
提取常量
RagProperties是 RAG 项目全局统一配置绑定类,基于 Spring Boot 配置绑定注解实现 yml 配置自动注入。所有 RAG 全链路参数集中定义并预设默认值,按业务功能分模块管理向量检索、关键词检索、语义缓存、文档切片、文件上传、本地重排六大类阈值参数。业务组件通过依赖注入读取配置,消除代码硬编码,仅修改配置文件即可调整业务规则,实现配置与业务代码解耦,符合企业级项目标准化开发规范。
import lombok.Data;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.stereotype.Component;
import java.time.Duration;
import java.util.Collections;
import java.util.List;
@Data
@Component
@ConfigurationProperties(prefix = "rag")
public class RagProperties {
// 向量检索配置
private int vectorTopK = 20;
private double vectorSimilarityThreshold = 0.20;
// 关键词检索
private int keywordTopK = 10;
private String redisIndexName = "knowledge-embedding-index";
// 语义缓存配置
private int cacheMaxSize = 500;
private Duration cacheExpire = Duration.ofHours(24);
private int cacheCandidateLimit = 30;
private double semanticSimilarityThreshold = 0.85;
// 文档切片
private int chunkSize = 300;
private int chunkOverlap = 50;
private int embedBatchSize = 10;
// 文件上传
private String fileUploadDir;
private long maxFileSizeMb = 100;
private List<String> allowSuffix = Collections.emptyList();
// 重排配置
private int rerankTopN = 5;
private int rerankMaxSize = 30;
private int rerankMinTermLength = 2;
private String rerankStopWords;
}
优化VectorServiceImpl
VectorServiceImpl是 RAG 系统核心业务服务,封装两大核心功能:知识库文件批量入库、智能问答。
文件上传流程集成完整安全校验,防止路径穿越、恶意文件上传;自动完成文件存储、文本切片、分批次向量化存入 Redis 向量库,并记录文件元数据。所有分片大小、文件限制、批量数量均读取统一配置类RagProperties,无硬编码参数。
问答接口基于 Spring AI 标准 RAG 链路搭建,按「查询重写→多路混合召回→本地文档重排」顺序装配组件,整合向量语义检索与关键词检索,最后交由大模型生成知识库回答,组件分层解耦,便于扩展维护。
import com.woniuxy.spring.config.RagProperties;
import com.woniuxy.spring.processor.LocalRerankProcessor;
import com.woniuxy.spring.retriever.HybridDocumentRetriever;
import com.woniuxy.spring.service.FileInfoService;
import com.woniuxy.spring.service.VectorService;
import com.woniuxy.spring.util.DocumentSplitUtil;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.client.advisor.api.Advisor;
import org.springframework.ai.rag.advisor.RetrievalAugmentationAdvisor;
import org.springframework.ai.rag.preretrieval.query.transformation.RewriteQueryTransformer;
import org.springframework.ai.document.Document;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.stereotype.Service;
import org.springframework.util.StringUtils;
import org.springframework.web.multipart.MultipartFile;
import java.io.File;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.util.List;
/**
* RAG知识库文件上传、问答业务实现类
* 功能:1. 文件上传、切片、批量向量化存入Redis向量库、入库业务表记录
* 2. 封装完整RAG问答链路:查询重写→多路混合召回→本地规则重排→LLM生成回答
*/
@Slf4j
@Service
@RequiredArgsConstructor
public class VectorServiceImpl implements VectorService {
// SpringAI向量存储(RedisVectorStore),存储文档向量与原文
private final VectorStore vectorStore;
// 大模型对话客户端,用于查询重写、关键词提取、最终问答生成
private final ChatClient chatClient;
// 文件信息持久化服务,记录上传文件元数据
private final FileInfoService fileInfoService;
// 检索后本地规则重排处理器,对召回文档做相关性打分排序
private final LocalRerankProcessor rerankProcessor;
// 自定义多路混合召回器:向量相似度召回 + RedisSearch关键词全文召回
private final HybridDocumentRetriever hybridDocumentRetriever;
// RAG全局配置参数,统一读取yml配置
private final RagProperties ragProperties;
// 用户提问最大长度,超长截断节约LLM Token消耗
private static final int MAX_CHAT_MSG_LEN = 1000;
/**
* 上传知识库文件,完成全流程处理
* 流程:安全校验 → 本地磁盘存储 → 文本切片 → 批量向量化存入向量库 → 数据库留存文件记录
* @param file 前端上传文件
* @return 切片后的文档总块数
* @throws Exception 文件写入、切片、入库异常抛出
*/
@Override
public int uploadFile(MultipartFile file) throws Exception {
// ===================== 1. 文件安全校验,拦截非法请求 =====================
// 判断文件对象是否为空
if (file == null || file.isEmpty()) {
throw new IllegalArgumentException("上传文件不能为空");
}
String originalName = file.getOriginalFilename();
// 判断文件名称是否空白
if (!StringUtils.hasText(originalName)) {
throw new IllegalArgumentException("文件名称为空");
}
// 路径穿越防御:拼接完整路径并标准化,校验文件只能存放在配置的上传目录内
Path resolve = Paths.get(ragProperties.getFileUploadDir()).resolve(originalName).normalize();
Path basePath = Paths.get(ragProperties.getFileUploadDir()).normalize();
if (!resolve.startsWith(basePath)) {
throw new SecurityException("非法文件名,禁止路径穿越");
}
// 文件大小限制,防止超大文件占用磁盘/内存
long maxByte = ragProperties.getMaxFileSizeMb() * 1024 * 1024;
if (file.getSize() > maxByte) {
throw new IllegalArgumentException("文件超出最大限制:" + ragProperties.getMaxFileSizeMb() + "MB");
}
// 文件后缀白名单校验,只允许配置中指定的文档类型
String suffix = originalName.substring(originalName.lastIndexOf("."));
if (!ragProperties.getAllowSuffix().contains(suffix.toLowerCase())) {
throw new IllegalArgumentException("不支持的文件格式:" + suffix);
}
// ===================== 2. 文件落地到服务器本地磁盘 =====================
String filePath = resolve.toString();
file.transferTo(new File(filePath));
log.info("文件保存成功:{}", filePath);
// ===================== 3. 文件文本切片,生成Document文档块 =====================
List<Document> documents = DocumentSplitUtil.splitFileToDocuments(
filePath, ragProperties.getChunkSize(), ragProperties.getChunkOverlap()
);
log.info("文件切片完成,共{}块", documents.size());
// ===================== 4. 批量向量化写入Redis向量库 =====================
// 适配嵌入模型单次最大支持批量数量,分批次提交向量化
int batch = ragProperties.getEmbedBatchSize();
for (int i = 0; i < documents.size(); i += batch) {
int end = Math.min(i + batch, documents.size());
vectorStore.add(documents.subList(i, end));
}
// ===================== 5. 业务数据库保存文件元信息 =====================
fileInfoService.saveFileInfo(originalName, filePath, documents);
return documents.size();
}
/**
* RAG问答统一入口
* 完整链路:用户提问校验截断 → 查询重写 → 多路混合召回 → 本地重排 → LLM生成答案
* @param message 用户原始提问文本
* @return 大模型结合知识库文档生成的回答
*/
@Override
public String chat(String message) {
// 拦截空提问
if (!StringUtils.hasText(message)) {
return "请输入有效提问内容";
}
// 超长文本截断,减少LLM消耗token
String userMsg = message.length() > MAX_CHAT_MSG_LEN
? message.substring(0, MAX_CHAT_MSG_LEN)
: message;
// 构建RAG增强检索Advisor,装配全链路处理组件
Advisor retrievalAugmentationAdvisor = RetrievalAugmentationAdvisor.builder()
// 前置处理:LLM自动重写优化用户原始查询,提升召回效果
.queryTransformers(RewriteQueryTransformer.builder()
.chatClientBuilder(chatClient.mutate())
.build())
// 检索阶段:自定义混合召回器(向量+关键词双路召回)
.documentRetriever(hybridDocumentRetriever)
// 检索后处理:本地规则重排,过滤低相关文档
.documentPostProcessors(rerankProcessor)
.build();
// 执行对话,挂载RAG增强组件,传入用户问题并返回生成内容
return chatClient.prompt()
.advisors(retrievalAugmentationAdvisor)
.user(userMsg)
.call()
.content();
}
}
本地重排处理器
LocalRerankProcessor 实现 Spring AI 提供的DocumentPostProcessor后置重排接口,是多路检索完成后的文档排序组件,无需调用第三方重排大模型,依靠本地文本规则完成粗排,节省调用成本、降低响应延迟,适配私有化 RAG 场景。
-
配置与停用词管理
统一读取
RagProperties重排参数,内置基础中文停用词,同时支持 yml 自定义扩充;采用懒加载 + 同步锁只初始化一次停用词,避免多线程重复解析。 -
整体执行流程
接收召回后的文档列表 → 根据配置截断最大处理条数,控制 CPU 开销 → 解析用户提问,过滤停用词、数字、过短词汇提取有效关键词 → 遍历每一篇文档打分:向量语义分占 45% 权重、文本多维度规则分占 55% 权重,得到综合相关性分数 → 按分数降序截取配置指定 TopN 文档,把重排分数存入文档元数据供日志排查。
-
多层打分规则
规则分由 5 个维度加权计算:关键词覆盖率、关键词出现频次、关键词在文档的前置位置、关键词位置紧凑度、文档长度惩罚,综合判断文本字面匹配程度;同时复用向量检索自带的语义相似度,兼顾语义与字面双重相关性。
-
容错设计
文档过少、无有效关键词、计算异常等场景均做降级处理,直接返回原始前 N 条文档,不会中断整条 RAG 问答链路。
import com.woniuxy.spring.config.RagProperties;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.ai.document.Document;
import org.springframework.ai.rag.Query;
import org.springframework.ai.rag.postretrieval.document.DocumentPostProcessor;
import org.springframework.stereotype.Service;
import org.springframework.util.StringUtils;
import java.util.*;
import java.util.stream.Collectors;
/**
* RAG检索后本地粗排处理器
* 实现Spring AI标准后置处理器接口,对多路召回后的文档做相关性打分排序
* 打分逻辑:向量语义相似度(最高权重) + 字面关键词多维度规则加权
* 优势:无需调用第三方重排模型,低延迟、无额外接口费用,适合私有化知识库
*/
@Slf4j
@Service
@RequiredArgsConstructor
public class LocalRerankProcessor implements DocumentPostProcessor {
// RAG全局配置类,读取重排相关参数
private final RagProperties ragProperties;
// 停用词集合(懒加载单例)
private Set<String> stopWords;
// 停用词初始化同步锁,防止多线程并发重复加载
private final Object stopWordsLock = new Object();
// 内置基础中文通用停用词,无自定义配置时默认使用
private static final Set<String> DEFAULT_CN_STOP_WORDS = new HashSet<>(Arrays.asList(
"的", "了", "是", "我", "有", "和", "就", "不", "人", "都", "一", "他", "这", "为", "之",
"也", "很", "到", "说", "要", "去", "你", "会", "着", "没有", "看", "好", "自己", "什么"
));
// Document元数据key:向量原始相似度分数
private static final String METADATA_SCORE = "score";
// Document元数据key:重排综合得分
private static final String METADATA_RERANK_SCORE = "rerank_score";
/**
* 懒加载获取停用词集合
* 先加载内置默认停用词,再追加yml配置自定义停用词
* @return 合并后的停用词集合
*/
private Set<String> getStopWords() {
if (stopWords == null) {
synchronized (stopWordsLock) {
if (stopWords == null) {
// 初始化内置停用词
stopWords = new HashSet<>(DEFAULT_CN_STOP_WORDS);
// 读取yml自定义停用词追加
String cfg = ragProperties.getRerankStopWords();
if (StringUtils.hasText(cfg)) {
Set<String> custom = parseStopWords(cfg);
stopWords.addAll(custom);
}
}
}
}
return stopWords;
}
/**
* 解析配置字符串为停用词集合
* 支持分隔符:逗号、空格、竖线
* @param config yml配置的停用词字符串
* @return 去重停用词集合
*/
private Set<String> parseStopWords(String config) {
return Arrays.stream(config.split("[,\\s|]+"))
.filter(StringUtils::hasText)
.map(String::trim)
.collect(Collectors.toSet());
}
/**
* Spring AI标准后置处理入口方法
* 对召回的文档列表执行截断、特征提取、打分、排序、截断TopN
* @param query 用户原始检索查询
* @param documents 多路召回得到的原始文档列表
* @return 重排后TopN高相关文档
*/
@Override
public List<Document> process(Query query, List<Document> documents) {
// 无召回文档直接返回空
if (documents == null || documents.isEmpty()) return Collections.emptyList();
// 从配置读取重排参数:最终返回条数、单次最大处理文档上限
int topN = ragProperties.getRerankTopN();
int maxRerank = ragProperties.getRerankMaxSize();
// 第一步:截断原始文档,控制单次重排计算量,避免CPU消耗过高
List<Document> toRerank = truncateDocuments(documents, maxRerank);
// 文档数量小于等于目标条数,无需重排直接返回
if (toRerank.size() <= topN) {
log.debug("文档数量{} <= topN{},跳过重排", toRerank.size(), topN);
return toRerank;
}
long start = System.currentTimeMillis();
try {
// 提取查询文本关键词特征(过滤停用词、纯数字、短词)
QueryFeatures features = extractQueryFeatures(query.text());
// 无有效关键词,规则打分失效,降级返回原始前N条
if (features.validTerms.isEmpty()) {
log.warn("查询无有效关键词,降级返回前{}条", topN);
return toRerank.stream().limit(topN).collect(Collectors.toList());
}
// 遍历所有待重排文档,计算综合分数
List<ScoredDocument> scoredList = new ArrayList<>();
for (Document doc : toRerank) {
// 1. 获取多路召回携带的向量语义相似度分数
double vecScore = getVectorScore(doc);
// 2. 计算纯文本规则匹配得分
double ruleScore = calculateRuleScore(features, doc);
// 综合加权:向量语义权重最高0.45,字面规则合计0.55
double finalScore = vecScore * 0.45 + ruleScore * 0.55;
scoredList.add(new ScoredDocument(doc, finalScore));
}
// 按综合分数倒序排序,截取topN,并将重排分数写入文档元数据
List<Document> result = scoredList.stream()
.sorted((a, b) -> Double.compare(b.score, a.score))
.limit(topN)
.map(sd -> {
Map<String, Object> meta = new HashMap<>(sd.doc.getMetadata());
meta.put(METADATA_RERANK_SCORE, sd.score);
return sd.doc.mutate().metadata(meta).build();
})
.collect(Collectors.toList());
long cost = System.currentTimeMillis() - start;
log.info("本地重排完成,耗时{}ms,输入{}条,输出{}条,最高分{:.4f}",
cost, toRerank.size(), result.size(),
result.get(0).getMetadata().get(METADATA_RERANK_SCORE));
return result;
} catch (Exception e) {
// 重排逻辑异常兜底降级,不中断RAG流程
log.error("重排异常,降级原始前{}条", topN, e);
return toRerank.stream().limit(topN).collect(Collectors.toList());
}
}
/**
* 截断文档列表,限制单次重排最大处理数量,控制性能开销
* @param docs 原始召回文档
* @param max 最大处理条数上限
* @return 截断后文档列表
*/
private List<Document> truncateDocuments(List<Document> docs, int max) {
if (docs.size() <= max) return docs;
log.debug("待重排文档{}超过上限{},截断", docs.size(), max);
return docs.stream().limit(max).collect(Collectors.toList());
}
/**
* 提取查询文本特征:分割词汇、过滤停用词、过滤纯数字、过滤过短词汇
* @param text 用户查询文本
* @return 封装后的查询特征对象(有效关键词总数、全部分割词汇)
*/
private QueryFeatures extractQueryFeatures(String text) {
if (!StringUtils.hasText(text)) return new QueryFeatures(Collections.emptyList(), 0);
// 最小词汇长度,读取配置
int minLen = ragProperties.getRerankMinTermLength();
// 按非文字/数字字符分割中英文混合文本
String[] parts = text.split("[^\\p{L}\\p{N}]+");
List<String> all = Arrays.stream(parts)
.filter(s -> s != null && s.length() >= minLen)
.collect(Collectors.toList());
Set<String> stop = getStopWords();
// 过滤停用词、纯数字、去重得到有效关键词
List<String> valid = all.stream()
.filter(t -> !stop.contains(t))
.filter(t -> !isNum(t))
.distinct()
.collect(Collectors.toList());
// 过滤后有效词过少,降级使用全部分割词汇
if (valid.size() < 2 && all.size() >= 2) {
valid = all.stream().distinct().collect(Collectors.toList());
}
return new QueryFeatures(valid, all.size());
}
/**
* 读取文档中存储的向量相似度分数
* 无分数时默认赋值0.1低分
* @param doc 召回文档
* @return 向量相似度数值
*/
private double getVectorScore(Document doc) {
Object obj = doc.getMetadata().get(METADATA_SCORE);
if (obj instanceof Number) {
return ((Number) obj).doubleValue();
}
return 0.1;
}
/**
* 多维度规则加权计算字面匹配得分
* 维度:覆盖率、词频、出现位置、关键词紧凑度、文档长度惩罚
* @param ft 查询关键词特征
* @param doc 待打分文档
* @return 0~1区间规则匹配分数
*/
private double calculateRuleScore(QueryFeatures ft, Document doc) {
String text = doc.getText();
// 无文本直接0分
if (!StringUtils.hasText(text)) return 0;
List<String> terms = ft.validTerms;
String lowerText = text.toLowerCase();
int textLen = lowerText.length();
// 各维度加权求和
double cover = calcCover(terms, lowerText) * 0.35; // 关键词覆盖率权重最高
double freq = calcFreq(terms, lowerText, textLen) * 0.25; // 词频权重
double pos = calcPos(terms, lowerText, textLen) * 0.20; // 前置位置权重
double compact = calcCompact(terms, lowerText) * 0.10; // 关键词聚集紧凑度
double lenPen = calcLenPen(textLen) * 0.10; // 过长/过短文档惩罚
// 限制分数0~1
return Math.min(1, Math.max(0, cover + freq + pos + compact + lenPen));
}
/**
* 计算关键词覆盖率:匹配到的关键词 / 总有效关键词
*/
private double calcCover(List<String> terms, String text) {
long hit = terms.stream().filter(t -> text.contains(t.toLowerCase())).count();
return (double) hit / terms.size();
}
/**
* 归一化词频得分:关键词在文档中出现密度
*/
private double calcFreq(List<String> terms, String text, int len) {
int total = 0;
for (String t : terms) {
String lt = t.toLowerCase();
int idx = 0;
// 循环统计该关键词所有出现次数
while ((idx = text.indexOf(lt, idx)) != -1) {
total++;
idx += lt.length();
}
}
double density = (double) total / len;
// 密度放大至0~1区间
return Math.min(density * 50, 1);
}
/**
* 位置得分:关键词越靠近文档开头分数越高
*/
private double calcPos(List<String> terms, String text, int len) {
double sumPos = 0;
int hitCnt = 0;
for (String t : terms) {
int idx = text.indexOf(t.toLowerCase());
if (idx >= 0) {
// 越靠前数值越大
sumPos += 1.0 - ((double) idx / len);
hitCnt++;
}
}
return hitCnt > 0 ? sumPos / hitCnt : 0;
}
/**
* 紧凑度得分:关键词出现位置越集中分数越高,分散则低分
*/
private double calcCompact(List<String> terms, String text) {
List<Integer> posList = new ArrayList<>();
for (String t : terms) {
int idx = text.indexOf(t.toLowerCase());
if (idx >= 0) posList.add(idx);
}
// 少于2个关键词无法计算紧凑度,给中等分
if (posList.size() < 2) return 0.5;
// 计算位置标准差,标准差越小越集中
double avg = posList.stream().mapToDouble(Integer::doubleValue).average().orElse(0);
double var = posList.stream().mapToDouble(p -> Math.pow(p - avg, 2)).average().orElse(0);
double std = Math.sqrt(var);
// 标准差500以内视为高度集中
return Math.min(1, Math.max(0, 1 - std / 500));
}
/**
* 文档长度惩罚分:过短、过长文档降低分数,500字左右文本最优
*/
private double calcLenPen(int len) {
if (len < 10) return 0.3;
if (len < 100) return 0.8;
if (len < 500) return 1.0;
if (len < 1500) return 0.9;
if (len < 3000) return 0.7;
return 0.5;
}
/**
* 判断字符串是否为纯数字
*/
private boolean isNum(String s) {
return s.matches("^\\d+$");
}
/**
* 查询特征内部封装类
* validTerms:过滤停用词后的有效关键词
* totalTerms:原始分割出的全部词汇数量
*/
private static class QueryFeatures {
List<String> validTerms;
int totalTerms;
QueryFeatures(List<String> valid, int total) {
validTerms = valid;
totalTerms = total;
}
}
/**
* 带综合分数的文档包装类
* 用于排序临时存储文档与打分结果
*/
private static class ScoredDocument {
Document doc;
double score;
ScoredDocument(Document d, double s) {
doc = d;
score = s;
}
}
}
多路召回
HybridDocumentRetriever 实现 Spring AI 标准DocumentRetriever检索接口,是整套 RAG 的多路混合召回组件,同时提供向量语义检索和RedisSearch 关键词全文检索两条检索链路,互补弥补单一检索的召回缺陷。
双路召回逻辑
-
向量召回:借助 Embedding 做语义匹配,能匹配含义相近、文字不同的文档,自带相似度分数;
-
关键词召回:调用 LLM 提取查询关键词,使用 Redis 全文检索做字面匹配,捕获向量漏召回的精准文本。
两路文档按文档 ID 去重,同时标记文档来源(向量 / 关键词 / 双路命中),优先以向量相似度分数排序并截断固定条数,传递给下游重排器。
Caffeine 语义缓存优化
内置本地缓存减少 LLM 与 Embedding 重复调用:缓存每条查询的向量与关键词;新查询与缓存条目做余弦相似度匹配,达到阈值直接复用历史关键词,不用重复调用大模型。缓存配置、容量、过期时间全部读取RagProperties,并维护访问队列控制遍历开销,附带缓存命中率统计、手动清空缓存接口。
工程容错与安全设计
- Redis 检索关键词自动转义特殊字符,避免检索语法报错;
- 向量检索、关键词提取、Redis 解析全链路捕获异常,单路失败不会中断整体召回流程;
- 使用
@PostConstruct在 Bean 初始化完毕后构建缓存,所有组件通过构造注入,符合 Spring 开发规范; - 统一管理常量、工具方法,代码分层清晰,支持监控缓存指标、知识库更新后清理缓存等运维需求。
import com.fasterxml.jackson.core.type.TypeReference;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.github.benmanes.caffeine.cache.Cache;
import com.github.benmanes.caffeine.cache.Caffeine;
import com.github.benmanes.caffeine.cache.RemovalCause;
import com.woniuxy.spring.config.RagProperties;
import jakarta.annotation.PostConstruct;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.document.Document;
import org.springframework.ai.embedding.EmbeddingModel;
import org.springframework.ai.rag.Query;
import org.springframework.ai.rag.retrieval.search.DocumentRetriever;
import org.springframework.ai.vectorstore.SearchRequest;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.stereotype.Component;
import redis.clients.jedis.JedisPooled;
import redis.clients.jedis.commands.ProtocolCommand;
import java.nio.charset.StandardCharsets;
import java.util.*;
import java.util.concurrent.ConcurrentLinkedDeque;
import java.util.concurrent.atomic.AtomicLong;
import java.util.stream.Collectors;
/**
* 自定义多路混合召回器,实现Spring AI标准DocumentRetriever接口
* 召回链路:
* 1. 向量相似度召回:基于Embedding语义匹配,捕获同义、近似语义内容
* 2. RedisSearch关键词全文召回:基于LLM提取关键词字面匹配,弥补向量漏召回
* 缓存机制:Caffeine本地缓存查询向量+关键词,通过余弦相似度做语义模糊命中,减少LLM与Embedding调用
* 合并逻辑:两路文档去重,携带各自匹配分数,按语义分数降序截断固定条数,标记来源类型(vector/keyword/hybrid)
*/
@Slf4j
@Component
@RequiredArgsConstructor // Lombok自动生成全参构造,Spring自动注入所有final依赖
public class HybridDocumentRetriever implements DocumentRetriever {
// SpringAI Redis向量存储,用于语义向量检索
private final VectorStore vectorStore;
// Redis客户端,执行RedisSearch全文检索命令FT.SEARCH
private final JedisPooled jedisPooled;
// LLM对话客户端,用于提取查询核心关键词
private final ChatClient chatClient;
// JSON序列化工具,解析LLM返回关键词数组、Redis元数据
private final ObjectMapper objectMapper;
// 嵌入模型,生成用户查询向量用于语义缓存匹配
private final EmbeddingModel embeddingModel;
// RAG统一配置类,读取yml中所有召回、缓存阈值参数
private final RagProperties ragProperties;
// 文档元数据固定Key常量
private static final String METADATA_RECALL_FROM = "recall_from";
private static final String METADATA_SCORE = "score";
// 召回来源标记
private static final String RECALL_VECTOR = "vector";
private static final String RECALL_KEYWORD = "keyword";
private static final String RECALL_HYBRID = "hybrid";
// RedisSearch返回字段名常量
private static final String FIELD_CONTENT = "content";
private static final String FIELD_SOURCE = "source";
private static final String FIELD_META = "metadata";
// LLM关键词提取最大文本长度,截断节约Token
private static final int MAX_QUERY_LEN = 500;
// 两路召回合并后最大文档条数,控制送入重排的数据量
private static final int MERGE_LIMIT = 50;
// ==================== Caffeine本地语义缓存 ====================
// Key: 用户原始查询文本 Value: 查询向量+提取关键词+时间戳
private Cache<String, CachedEntry> cache;
// 访问顺序队列,仅保留最近CANDIDATE_LIMIT条用于相似度对比,降低遍历开销
private final ConcurrentLinkedDeque<String> accessOrder = new ConcurrentLinkedDeque<>();
// 语义模糊匹配命中计数
private final AtomicLong semanticHits = new AtomicLong(0);
// 语义缓存未命中计数(需要调用LLM+Embedding)
private final AtomicLong semanticMisses = new AtomicLong(0);
/**
* Bean依赖注入完成后初始化Caffeine缓存
* 配置:最大容量、写入24小时过期、统计命中率、过期/淘汰打印日志
*/
@PostConstruct
public void initCache() {
this.cache = Caffeine.newBuilder()
.maximumSize(ragProperties.getCacheMaxSize())
.expireAfterWrite(ragProperties.getCacheExpire())
.recordStats()
.removalListener((key, value, cause) -> {
if (cause == RemovalCause.EXPIRED) {
log.debug("语义缓存条目过期移除: {}", key);
} else if (cause == RemovalCause.SIZE) {
log.debug("语义缓存容量LRU淘汰: {}", key);
}
})
.build();
}
/**
* 缓存存储实体:一条查询对应的向量、关键词、写入时间戳
*/
private static class CachedEntry {
// 查询文本向量
final float[] embedding;
// LLM提取的核心关键词列表
final List<String> keywords;
// 缓存写入时间,用于双重过期校验
final long timestamp;
CachedEntry(float[] embedding, List<String> keywords) {
this.embedding = embedding;
this.keywords = keywords;
this.timestamp = System.currentTimeMillis();
}
/**
* 双重过期校验:对比当前时间与配置过期时长
* @param expireMs 配置缓存过期毫秒数
* @return true=已过期,需要删除
*/
boolean isExpired(long expireMs) {
return System.currentTimeMillis() - timestamp > expireMs;
}
}
/**
* Redis命令枚举,预编译字节数组避免重复字符串转码
*/
private enum RedisCommand implements ProtocolCommand {
FT_SEARCH,
FT_CREATE,
FT_INFO;
private final byte[] rawBytes;
RedisCommand() {
this.rawBytes = this.name().replace('_', '.').getBytes(StandardCharsets.UTF_8);
}
@Override
public byte[] getRaw() {
return rawBytes;
}
}
/**
* Spring AI标准检索入口方法
* @param query 用户查询封装对象
* @return 两路召回合并、去重、按分数排序截断后的文档列表
*/
@Override
public List<Document> retrieve(Query query) {
String rawText = query.text();
String queryText = rawText.strip();
// 拦截空查询,避免无效Embedding与Redis调用
if (queryText.isBlank()) {
log.warn("检索输入查询文本为空,直接返回空文档集合");
return Collections.emptyList();
}
log.debug("开始执行多路混合召回,用户查询文本:{}", queryText);
// 1. 向量语义召回
List<Document> vectorDocs = vectorRetrieve(queryText);
log.debug("向量语义检索召回文档数量:{} 条", vectorDocs.size());
// 2. Redis关键词全文召回
List<Document> keywordDocs = keywordRetrieve(queryText);
log.debug("关键词全文检索召回文档数量:{} 条", keywordDocs.size());
// 3. 两路结果合并、去重、按语义分数排序、截断上限
List<Document> merged = mergeAndDeduplicate(vectorDocs, keywordDocs);
log.debug("两路文档合并去重截断后最终数量:{} 条", merged.size());
return merged;
}
/**
* 执行向量相似度检索
* @param queryText 用户查询文本
* @return 语义匹配文档列表,自带相似度分数存入metadata score
*/
private List<Document> vectorRetrieve(String queryText) {
try {
SearchRequest searchRequest = SearchRequest.builder()
.query(queryText)
.topK(ragProperties.getVectorTopK())
.similarityThreshold(ragProperties.getVectorSimilarityThreshold())
.build();
return vectorStore.similaritySearch(searchRequest);
} catch (Exception e) {
log.error("向量语义检索执行异常", e);
return Collections.emptyList();
}
}
/**
* 关键词检索主逻辑:优先走语义缓存,未命中则调用LLM提取关键词再查询RedisSearch
* @param queryText 用户原始查询
* @return 全文匹配文档列表
*/
private List<Document> keywordRetrieve(String queryText) {
try {
// 尝试从语义缓存获取关键词
List<String> keys = getCachedKeywords(queryText);
if (keys != null) {
log.debug("语义缓存命中,复用历史关键词:{} → {}", queryText, keys);
} else {
// 缓存无匹配,调用LLM提取关键词并存入缓存
keys = extractKeywords(queryText);
putCachedKeywords(queryText, keys);
log.debug("缓存未命中,LLM提取关键词结果: {}", keys);
}
List<Document> allDocuments = new ArrayList<>();
// 遍历每个关键词执行Redis全文检索
for (String key : keys) {
log.debug("执行关键词检索,关键词:{}", key);
String safeKey = escapeQuery(key);
// 组装FT.SEARCH参数:索引名、模糊匹配、分页、返回指定字段
Object result = jedisPooled.sendCommand(RedisCommand.FT_SEARCH,
ragProperties.getRedisIndexName(),
"@content:*" + safeKey + "*",
"LIMIT", "0", String.valueOf(ragProperties.getKeywordTopK()),
"RETURN", "3", FIELD_CONTENT, FIELD_META, FIELD_SOURCE
);
// 校验返回数据格式
if (!(result instanceof List)) {
log.warn("Redis FT.SEARCH返回数据非List类型,跳过当前关键词,类型:{}", result == null ? "null" : result.getClass().getName());
continue;
}
@SuppressWarnings("unchecked")
List<Object> results = (List<Object>) result;
List<Document> docs = parseSearchResults(results);
log.debug("关键词'{}'检索得到{}条文档", key, docs.size());
allDocuments.addAll(docs);
}
// 关键词检索结果去重后返回
return deduplicateDocuments(allDocuments);
} catch (Exception e) {
log.error("关键词全文检索整体执行异常", e);
return Collections.emptyList();
}
}
/**
* 语义缓存匹配逻辑:遍历最近访问的缓存条目,计算余弦相似度,达到阈值则复用关键词
* @param queryText 当前用户查询
* @return 命中则返回缓存关键词,未命中返回null
*/
private List<String> getCachedKeywords(String queryText) {
// 缓存为空直接返回未命中
if (cache.estimatedSize() == 0) {
return null;
}
try {
// 生成当前查询向量用于相似度对比
float[] currentEmbedding = embeddingModel.embed(queryText);
// 仅取最近访问的N条缓存对比,减少计算量
List<String> candidates = new ArrayList<>(accessOrder);
int limit = ragProperties.getCacheCandidateLimit();
int compareCount = Math.min(candidates.size(), limit);
String bestMatch = null;
double bestSim = 0.0;
long expireMs = ragProperties.getCacheExpire().toMillis();
int compared = 0;
for (int i = 0; i < compareCount; i++) {
String q = candidates.get(i);
CachedEntry entry = cache.getIfPresent(q);
// 缓存条目已被淘汰,从访问队列清理
if (entry == null) {
accessOrder.remove(q);
continue;
}
// 缓存条目过期,主动清理
if (entry.isExpired(expireMs)) {
cache.invalidate(q);
accessOrder.remove(q);
continue;
}
compared++;
// 计算两条查询向量余弦相似度
double sim = calculateCosineSimilarity(currentEmbedding, entry.embedding);
if (sim > bestSim) {
bestSim = sim;
bestMatch = q;
}
}
log.debug("缓存相似度对比完成,总缓存{}条,实际对比{}条", cache.estimatedSize(), compared);
double threshold = ragProperties.getSemanticSimilarityThreshold();
// 相似度达到阈值,命中语义缓存
if (bestMatch != null && bestSim >= threshold) {
semanticHits.incrementAndGet();
log.debug("语义模糊匹配成功 {} ≈ {} 相似度:{:.4f}", queryText, bestMatch, bestSim);
CachedEntry entry = cache.getIfPresent(bestMatch);
return entry != null ? entry.keywords : null;
}
// 无匹配,计数未命中
semanticMisses.incrementAndGet();
return null;
} catch (Exception e) {
log.warn("语义缓存相似度匹配异常,降级走未命中逻辑", e);
return null;
}
}
/**
* 将新查询向量+关键词存入Caffeine缓存,维护访问顺序队列(仅保留最近CANDIDATE_LIMIT条)
* @param queryText 用户原始查询
* @param keywords LLM提取的关键词列表
*/
private void putCachedKeywords(String queryText, List<String> keywords) {
try {
float[] embedding = embeddingModel.embed(queryText);
CachedEntry entry = new CachedEntry(embedding, keywords);
cache.put(queryText, entry);
// 更新访问队列,当前查询置顶
accessOrder.remove(queryText);
accessOrder.addFirst(queryText);
// 队列截断,永久只保留最近对比条数,消除remove O(n)性能损耗
int limit = ragProperties.getCacheCandidateLimit();
while (accessOrder.size() > limit) {
accessOrder.pollLast();
}
// 打印缓存统计信息
var stats = cache.stats();
double hitRate = getSemanticHitRate();
log.info("语义缓存写入完成,当前缓存容量{}/{},语义匹配命中率{:.1f}%,Caffeine原生命中率{:.1f}%",
cache.estimatedSize(), ragProperties.getCacheMaxSize(), hitRate, stats.hitRate() * 100);
} catch (Exception e) {
log.warn("写入语义缓存失败", e);
}
}
/**
* 计算自定义语义缓存匹配总命中率
*/
private double getSemanticHitRate() {
long total = semanticHits.get() + semanticMisses.get();
return total == 0 ? 0 : (double) semanticHits.get() / total * 100;
}
/**
* 计算两个浮点向量的余弦相似度,取值区间 [-1,1]
* @param vec1 向量1
* @param vec2 向量2
* @return 相似度数值,向量为空返回0
*/
private double calculateCosineSimilarity(float[] vec1, float[] vec2) {
if (vec1 == null || vec2 == null || vec1.length == 0 || vec2.length == 0) return 0;
double dot = 0, n1 = 0, n2 = 0;
int len = Math.min(vec1.length, vec2.length);
for (int i = 0; i < len; i++) {
float v1 = vec1[i], v2 = vec2[i];
dot += v1 * v2;
n1 += v1 * v1;
n2 += v2 * v2;
}
// 零向量避免除零
if (n1 == 0 || n2 == 0) return 0;
return dot / (Math.sqrt(n1) * Math.sqrt(n2));
}
/**
* 调用LLM提取查询核心关键词,截断超长文本并清洗模型返回JSON
* @param queryText 用户查询文本
* @return 关键词字符串列表
*/
private List<String> extractKeywords(String queryText) {
// 超长文本截断,减少LLM输入token消耗
String shortQuery = queryText.length() > MAX_QUERY_LEN
? queryText.substring(0, MAX_QUERY_LEN)
: queryText;
// 固定Prompt,约束模型仅输出纯净JSON数组
String prompt = """
你是拆词助手,提取用户核心关键词,仅返回标准JSON字符串数组,无任何多余文字、注释、代码块。
样例输出:["关键词1","关键词2"]
用户文本:%s
""".formatted(shortQuery);
try {
String raw = chatClient.prompt(prompt).call().content();
// 清洗Markdown代码块、换行、空格
raw = raw.replaceAll("```(json)?", "").trim().replaceAll("\\s+", "");
return objectMapper.readValue(raw, new TypeReference<List<String>>() {});
} catch (Exception e) {
log.error("调用LLM提取关键词失败", e);
return Collections.emptyList();
}
}
/**
* 根据Document ID对文档列表去重
*/
private List<Document> deduplicateDocuments(List<Document> documents) {
Map<String, Document> map = new LinkedHashMap<>();
for (Document doc : documents) {
map.putIfAbsent(doc.getId(), doc);
}
return new ArrayList<>(map.values());
}
/**
* Redis返回字节/对象统一转字符串工具方法
*/
private String safeToString(Object obj) {
if (obj == null) return null;
if (obj instanceof byte[]) return new String((byte[]) obj, StandardCharsets.UTF_8);
return obj.toString();
}
/**
* 解析Redis FT.SEARCH返回的嵌套数组,组装Document对象并填充元数据
*/
@SuppressWarnings("unchecked")
private List<Document> parseSearchResults(List<Object> results) {
List<Document> docs = new ArrayList<>();
if (results == null || results.size() < 2) return docs;
try {
int idx = 1;
while (idx < results.size()) {
String docId = safeToString(results.get(idx++));
if (docId == null || idx >= results.size()) break;
Object fieldObj = results.get(idx++);
if (!(fieldObj instanceof List)) continue;
List<Object> fields = (List<Object>) fieldObj;
String content = null, source = null;
Map<String, Object> meta = new HashMap<>();
meta.put(METADATA_RECALL_FROM, RECALL_KEYWORD);
// 遍历返回字段,赋值内容、来源、自定义元数据
for (int i = 0; i < fields.size() - 1; i += 2) {
String fName = safeToString(fields.get(i));
String fVal = safeToString(fields.get(i + 1));
if (FIELD_CONTENT.equals(fName)) content = fVal;
else if (FIELD_SOURCE.equals(fName)) {
source = fVal;
meta.put(FIELD_SOURCE, source);
} else if (FIELD_META.equals(fName)) {
try {
Map<String, Object> inner = objectMapper.readValue(fVal, new TypeReference<Map<String, Object>>() {});
meta.putAll(inner);
} catch (Exception ex) {
meta.put(fName, fVal);
}
} else {
meta.put(fName, fVal);
}
}
// 仅保留存在正文内容的文档
if (content != null && !content.isBlank()) {
docs.add(new Document(docId, content, meta));
}
}
} catch (Exception e) {
log.error("解析RedisSearch返回结果异常", e);
}
return docs;
}
/**
* 合并向量召回、关键词召回两路文档:
* 1. 按文档ID去重,同时标记hybrid(两路同时命中)
* 2. 向量文档携带原始语义分数,关键词默认0.1低分
* 3. 按分数降序排序,截断最大合并条数MERGE_LIMIT
* 4. 回填recall_from与score元数据供下游重排使用
*/
private List<Document> mergeAndDeduplicate(List<Document> vectorDocs, List<Document> keywordDocs) {
Map<String, DocumentWrapper> map = new LinkedHashMap<>();
// 存入向量召回文档,携带原始相似度分数
for (Document d : vectorDocs) {
double score = d.getMetadata().containsKey(METADATA_SCORE)
? ((Number) d.getMetadata().get(METADATA_SCORE)).doubleValue()
: 0.5;
DocumentWrapper w = new DocumentWrapper(d, score, RECALL_VECTOR);
map.put(d.getId(), w);
}
// 存入关键词召回文档,重复ID标记为混合来源
for (Document d : keywordDocs) {
if (map.containsKey(d.getId())) {
DocumentWrapper exist = map.get(d.getId());
exist.recallType = RECALL_HYBRID;
} else {
map.put(d.getId(), new DocumentWrapper(d, 0.1, RECALL_KEYWORD));
}
}
// 按匹配分数从高到低排序,截断上限,填充元数据后返回
return map.values().stream()
.sorted((a, b) -> Double.compare(b.score, a.score))
.limit(MERGE_LIMIT)
.map(w -> {
Map<String, Object> meta = new HashMap<>(w.doc.getMetadata());
meta.put(METADATA_RECALL_FROM, w.recallType);
meta.put(METADATA_SCORE, w.score);
return w.doc.mutate().metadata(meta).build();
})
.collect(Collectors.toList());
}
/**
* 文档临时包装类:存储原始文档、匹配分数、召回来源,用于合并阶段排序
*/
private static class DocumentWrapper {
Document doc;
double score;
String recallType;
DocumentWrapper(Document d, double s, String t) {
doc = d; score = s; recallType = t;
}
}
/**
* RedisSearch特殊字符转义,防止模糊查询语法报错
*/
private String escapeQuery(String query) {
if (query == null) return "";
return query.replaceAll("([!\"(){}\\[\\\\]^~*?:/\\-])", "\\\\$1");
}
/**
* 对外暴露手动清空全部语义缓存接口
* 适用场景:知识库全量更新后,清除旧查询缓存
*/
public void clearCache() {
cache.invalidateAll();
accessOrder.clear();
semanticHits.set(0);
semanticMisses.set(0);
log.info("已清空全部本地语义缓存");
}
/**
* 对外获取缓存监控统计指标,可对接监控接口/打印日志
* @return 缓存各项指标Map
*/
public Map<String, Object> getCacheStats() {
var stats = cache.stats();
Map<String, Object> res = new LinkedHashMap<>();
res.put("size", cache.estimatedSize());
res.put("caffeineHitRate", stats.hitRate() * 100);
res.put("evictionCount", stats.evictionCount());
res.put("semanticHitRate", getSemanticHitRate());
res.put("semanticHits", semanticHits.get());
res.put("semanticMisses", semanticMisses.get());
return res;
}
}
索引查询
FT.SEARCH knowledge-embedding-index "@content:*奥特曼*" LIMIT 0 10 RETURN 3 content metadata source
| 内容 | 说明 |
|---|---|
FT.SEARCH |
Redis 搜索命令 |
knowledge-embedding-index |
索引名称 |
@content:*奥特曼* |
在 content 字段中模糊匹配 |
LIMIT |
分页关键字 |
0 |
起始偏移量 |
10 |
返回数量 |
RETURN |
返回字段关键字 |
3 |
返回字段数量 |
content |
第1个字段 |
metadata |
第2个字段 |
source |
第3个字段 |
这3步组成了一个完整的 RAG(检索增强生成)流水线,每一步都有特定的目的,协同工作来提升最终回答的质量。我用一个模拟场景来解释它们的作用。
场景设定
假设你的知识库里有 10,000 份关于《西游记》的文档,用户提出了一个问题:
“孙悟空的金箍棒是从哪里来的?”
第1步:检索前 - 查询重写 (Query Rewriting)
这一步在真正去搜索之前,先由大模型对用户的原始问题进行加工,生成一个“更利于检索”的新问题。
- 要解决的问题:用户的提问通常很口语化、简略或包含模糊指代(比如“它”),直接拿原话去搜索,效果往往不好。
- 它的作用:大模型会理解你的意图,把问题改写成更清晰、更完整的表述。
- 示例:
- 用户原始问题:“它从哪里来的?”
- 重写后的查询:“孙悟空所使用的金箍棒的来源和获取过程是怎样的?”
- 预期效果:用这个重写后的、词汇更丰富的句子去搜索,向量检索能找到更多语义相关的文档片段。
第2步:检索 - 向量检索 (Vector Retrieval)
这一步是用处理好的问题,去向量数据库(如 Redis)里“粗召回”一批可能相关的文档片段。
- 要解决的问题:知识库太大,必须快速筛选出一小批最有可能包含答案的候选文档,作为后续步骤的“素材”。
- 它的作用:这是一种“海选”机制,目标是保证召回率,即宁可多召回一些,也不能漏掉真正相关的。它会根据语义相似度,从海量数据中捞出 Top K(比如 Top 10)个文档片段。
- 示例:
- 它可能会召回这样的片段:
文档A:“…龙王给了孙悟空一根定海神针…”文档B:“…金箍棒原是太上老君炼制的神铁…”文档C:“…孙悟空在东海龙宫获得了兵器…”文档D:“…唐僧师徒继续西行…”(这个就不太相关,但因为是粗召回,也可能被包含进来)
- 它可能会召回这样的片段:
- 预期效果:迅速缩小范围,但结果可能很粗糙,混杂了一些低相关度的文档。
第3步:检索后 - 重排 (Rerank)
这一步是“精筛选”,对第2步召回的候选文档进行重新打分和排序。
- 要解决的问题:向量检索的“粗召回”虽然广,但结果排序可能不准,一些真正重要的文档排名可能靠后。
- 它的作用:它会用一个更精细、更强大的模型(比如交叉编码器),逐一分析“用户问题 + 文档内容”这对组合,计算它们之间的深度相关性,然后按相关性从高到低重新排序。这个模型通常比向量检索的模型更准确,但计算成本也更高,所以只对少量候选文档(比如 Top 10)进行操作。
- 示例:
- 重排前(可能按向量距离排序):
文档A(向量距离最近)文档B文档C文档D(不相关)
- 重排后(按深度相关性排序):
文档B(直接说出了金箍棒的来源!)文档A(提到了获得过程)文档C文档D(被重排模型识别为不相关,并丢弃)
- 重排前(可能按向量距离排序):
- 预期效果:通过精细化的排序,把最有可能包含正确答案的文档排在最前面,提供给大模型。
| 步骤 | 名称 | 核心目标 | 使用的模型/技术 | 处理的文档量 | 关键产出 |
|---|---|---|---|---|---|
| 1 | 查询重写 | 优化输入 | 大语言模型 (LLM) | 1个(原问题) | 一个更清晰、更完整的查询语句 |
| 2 | 向量检索 | 保证召回率 | 向量模型 (Embedding Model) | 全部(海量) | 一批(如Top 10)语义相关的候选文档 |
| 3 | 重排 | 提升精确率 | 重排模型 (Rerank Model) | 少量(候选文档) | 按相关性精排序的最终文档列表 |
思维链(CoT)过程留存
思维链 CoT:让大模型分步推理,把思考过程输出出来,而不是直接给最终答案。
旧 RAG 只输出最终回答,看不到模型怎么思考;
现在要求:必须完整留存推理步骤,例如:
问题:XX 业务的赔付规则是什么?
步骤 1:先检索赔付相关文档 3 份;
步骤 2:提取文档中赔付门槛、时间限制;
步骤 3:对比不同场景区分个人 / 企业赔付;
步骤 4:整合信息输出最终规则。
留存思维链的价值:便于定位错误、人工审计、优化提示词、排查幻觉来源。
CoT(思维链)指大模型回答问题中间产生的分步推理、检索依据、打分、召回记录,需要全链路持久化存储,核心存储载体分两种:
- 数据库持久化(永久留存,历史会话可回溯):存会话 ID、用户问题、LLM 推理步骤、召回文档、重排分数、最终答案、耗时;
- Redis 临时缓存(会话上下文短期留存):同一次问答多轮对话复用 CoT 中间过程。
完整链路留存包含 5 类数据:
- 用户原始提问、截断后的标准查询;
- CoT 中间步骤:查询重写文本、LLM 提取关键词、语义缓存命中状态、余弦相似度;
- 多路召回数据:向量召回文档、关键词召回文档、文档来源标记、原始相似度分数;
- 本地重排中间数据:关键词特征、5 维度规则分、综合重排分数、TopN 筛选结果;
- LLM 完整推理过程、最终回答、各阶段耗时指标。
建表sql
CREATE TABLE `rag_cot_record` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键',
`session_id` varchar(128) NOT NULL COMMENT '会话ID,多轮对话绑定',
`user_query` text NOT NULL COMMENT '用户原始提问',
`rewrite_query` text DEFAULT NULL COMMENT 'LLM重写后的查询语句',
`cache_hit` tinyint(1) DEFAULT 0 COMMENT '语义缓存是否命中 0否1是',
`semantic_similarity` decimal(6,4) DEFAULT NULL COMMENT '缓存匹配余弦相似度',
`extract_keywords` varchar(1024) DEFAULT NULL COMMENT 'LLM提取关键词,逗号分隔',
`vector_docs_json` longtext DEFAULT NULL COMMENT '向量召回文档JSON',
`keyword_docs_json` longtext DEFAULT NULL COMMENT '关键词召回文档JSON',
`rerank_docs_json` longtext DEFAULT NULL COMMENT '重排后TopN文档JSON',
`cot_think` longtext DEFAULT NULL COMMENT 'LLM完整CoT推理思考过程',
`final_answer` longtext NOT NULL COMMENT '返回用户最终答案',
`retrieve_cost_ms` bigint DEFAULT 0 COMMENT '多路召回耗时',
`rerank_cost_ms` bigint DEFAULT 0 COMMENT '本地重排耗时',
`llm_cost_ms` bigint DEFAULT 0 COMMENT '大模型推理耗时',
`create_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '记录创建时间',
PRIMARY KEY (`id`),
KEY `idx_session_id` (`session_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='RAG思维链CoT完整记录表';
RagProperties 新增 CoT 配置
// ===================== CoT思维链留存配置 =====================
/** 是否开启思维链数据库留存 */
private boolean enableCotRecord = true;
/** 是否异步入库CoT记录,true不阻塞问答接口 */
private boolean cotAsyncSave = true;
CoT 中间数据包装类
召回链路 CoT 封装 RetrieveCoTResult
package com.woniuxy.spring.model.cot;
import org.springframework.ai.document.Document;
import lombok.Data;
import java.util.List;
@Data
public class RetrieveCoTResult {
// 缓存信息
private Boolean cacheHit;
private Double matchSimilarity;
private List<String> keywords;
// 两路召回文档
private List<Document> vectorDocs;
private List<Document> keywordDocs;
private List<Document> mergedDocs;
// 耗时
private Long costMs;
}
重排链路 CoT 封装 RerankCoTResult
package com.woniuxy.spring.model.cot;
import org.springframework.ai.document.Document;
import lombok.Data;
import java.util.List;
@Data
public class RerankCoTResult {
// 关键词特征
private List<String> validTerms;
// 文档数据
private List<Document> rawDocs;
private List<Document> topNDocs;
// 耗时
private Long costMs;
}
数据库实体 RagCoTRecord
package com.woniuxy.spring.entity;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
import java.time.LocalDateTime;
import java.math.BigDecimal;
@Data
@TableName("rag_cot_record")
public class RagCoTRecord {
@TableId(type = IdType.AUTO)
private Long id;
private String sessionId;
private String userQuery;
private String rewriteQuery;
private Boolean cacheHit;
private BigDecimal semanticSimilarity;
private String extractKeywords;
private String vectorDocsJson;
private String keywordDocsJson;
private String rerankDocsJson;
private String cotThink;
private String finalAnswer;
private Long retrieveCostMs;
private Long rerankCostMs;
private Long llmCostMs;
private LocalDateTime createTime;
}
Mapper + 持久化 Service
RagCoTRecordMapper
package com.woniuxy.spring.mapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.woniuxy.spring.entity.RagCoTRecord;
import org.apache.ibatis.annotations.Mapper;
@Mapper
public interface RagCoTRecordMapper extends BaseMapper<RagCoTRecord> {
}
CoT 持久化服务 CotRecordService
package com.woniuxy.spring.service;
import com.baomidou.mybatisplus.extension.service.IService;
import com.woniuxy.spring.cot.RerankCoTResult;
import com.woniuxy.spring.cot.RetrieveCoTResult;
import com.woniuxy.spring.entity.RagCoTRecord;
public interface CotRecordService extends IService<RagCoTRecord> {
void saveCoTRecord(String sessionId,
String userQuery,
String rewriteQuery,
RetrieveCoTResult retrieveCoT,
RerankCoTResult rerankCoT,
String cotThink,
String finalAnswer,
Long llmCost);
void asyncSaveCoTRecord(String sessionId,
String userQuery,
String rewriteQuery,
RetrieveCoTResult retrieveCoT,
RerankCoTResult rerankCoT,
String cotThink,
String finalAnswer,
Long llmCost);
}
实现类
package com.woniuxy.spring.service.impl;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.woniuxy.spring.cot.RerankCoTResult;
import com.woniuxy.spring.cot.RetrieveCoTResult;
import com.woniuxy.spring.entity.RagCoTRecord;
import com.woniuxy.spring.mapper.RagCoTRecordMapper;
import com.woniuxy.spring.service.CotRecordService;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.scheduling.annotation.Async;
import org.springframework.stereotype.Service;
import org.springframework.util.CollectionUtils;
import java.math.BigDecimal;
import java.util.Collections;
import java.util.List;
import java.util.stream.Collectors;
@Slf4j
@Service
@RequiredArgsConstructor
public class CotRecordServiceImpl extends ServiceImpl<RagCoTRecordMapper, RagCoTRecord> implements CotRecordService {
private final ObjectMapper objectMapper;
/**
* 同步保存CoT记录
*/
@Override
public void saveCoTRecord(String sessionId,
String userQuery,
String rewriteQuery,
RetrieveCoTResult retrieveCoT,
RerankCoTResult rerankCoT,
String cotThink,
String finalAnswer,
Long llmCost) {
try {
RagCoTRecord record = buildRecord(sessionId, userQuery, rewriteQuery, retrieveCoT, rerankCoT, cotThink, finalAnswer, llmCost);
baseMapper.insert(record);
log.info("思维链记录入库成功,sessionId:{}", sessionId);
} catch (Exception e) {
log.error("CoT记录入库异常", e);
}
}
/**
* 异步保存,不阻塞主问答流程
*/
@Async
@Override
public void asyncSaveCoTRecord(String sessionId,
String userQuery,
String rewriteQuery,
RetrieveCoTResult retrieveCoT,
RerankCoTResult rerankCoT,
String cotThink,
String finalAnswer,
Long llmCost) {
saveCoTRecord(sessionId, userQuery, rewriteQuery, retrieveCoT, rerankCoT, cotThink, finalAnswer, llmCost);
}
/**
* 组装数据库实体(增加全量空值保护)
*/
private RagCoTRecord buildRecord(String sessionId,
String userQuery,
String rewriteQuery,
RetrieveCoTResult retrieveCoT,
RerankCoTResult rerankCoT,
String cotThink,
String finalAnswer,
Long llmCost) throws Exception {
RagCoTRecord record = new RagCoTRecord();
record.setSessionId(sessionId);
record.setUserQuery(userQuery);
record.setRewriteQuery(rewriteQuery);
record.setCotThink(cotThink);
record.setFinalAnswer(finalAnswer);
record.setLlmCostMs(llmCost == null ? 0 : llmCost);
// ========== 召回CoT空值防护 ==========
if (retrieveCoT != null) {
record.setRetrieveCostMs(retrieveCoT.getCostMs() == null ? 0 : retrieveCoT.getCostMs());
record.setCacheHit(retrieveCoT.getCacheHit() == null ? false : retrieveCoT.getCacheHit());
// 相似度
if (retrieveCoT.getMatchSimilarity() != null) {
record.setSemanticSimilarity(new BigDecimal(retrieveCoT.getMatchSimilarity()).setScale(4, BigDecimal.ROUND_HALF_UP));
}
// 关键词
List<String> kwList = retrieveCoT.getKeywords();
String kwStr = "";
if (!CollectionUtils.isEmpty(kwList)) {
kwStr = kwList.stream().collect(Collectors.joining(","));
}
record.setExtractKeywords(kwStr);
// 向量文档
List<?> vectorDocs = retrieveCoT.getVectorDocs();
record.setVectorDocsJson(objectMapper.writeValueAsString(vectorDocs == null ? Collections.emptyList() : vectorDocs));
// 关键词文档
List<?> keywordDocs = retrieveCoT.getKeywordDocs();
record.setKeywordDocsJson(objectMapper.writeValueAsString(keywordDocs == null ? Collections.emptyList() : keywordDocs));
} else {
// retrieveCoT为null时填充默认空数据
record.setRetrieveCostMs(0L);
record.setCacheHit(false);
record.setExtractKeywords("");
record.setSemanticSimilarity(null);
record.setVectorDocsJson("[]");
record.setKeywordDocsJson("[]");
}
// ========== 重排CoT空值防护 ==========
if (rerankCoT != null) {
record.setRerankCostMs(rerankCoT.getCostMs() == null ? 0 : rerankCoT.getCostMs());
List<?> topDocs = rerankCoT.getTopNDocs();
record.setRerankDocsJson(objectMapper.writeValueAsString(topDocs == null ? Collections.emptyList() : topDocs));
} else {
record.setRerankCostMs(0L);
record.setRerankDocsJson("[]");
}
return record;
}
}
启动类开启异步
@SpringBootApplication
@EnableAsync // 开启@Async异步入库
public class SpringAi20262Application {
public static void main(String[] args) {
SpringApplication.run(SpringAi20262Application.class, args);
}
}
改造 HybridDocumentRetriever
只修改返回值与新增中间变量存储缓存相似度,其余原有逻辑不动
package com.woniuxy.spring.retriever;
import com.fasterxml.jackson.core.type.TypeReference;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.github.benmanes.caffeine.cache.Cache;
import com.github.benmanes.caffeine.cache.Caffeine;
import com.github.benmanes.caffeine.cache.RemovalCause;
import com.woniuxy.spring.config.RagProperties;
import com.woniuxy.spring.cot.RetrieveCoTResult;
import com.woniuxy.spring.util.ThreadLocalUtil;
import jakarta.annotation.PostConstruct;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.document.Document;
import org.springframework.ai.embedding.EmbeddingModel;
import org.springframework.ai.rag.Query;
import org.springframework.ai.rag.retrieval.search.DocumentRetriever;
import org.springframework.ai.vectorstore.SearchRequest;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.stereotype.Component;
import redis.clients.jedis.JedisPooled;
import redis.clients.jedis.commands.ProtocolCommand;
import java.nio.charset.StandardCharsets;
import java.util.*;
import java.util.concurrent.ConcurrentLinkedDeque;
import java.util.concurrent.atomic.AtomicLong;
import java.util.stream.Collectors;
/**
* 自定义多路混合召回器,实现Spring AI标准DocumentRetriever接口
* 召回链路:
* 1. 向量相似度召回:基于Embedding语义匹配,捕获同义、近似语义内容
* 2. RedisSearch关键词全文召回:基于LLM提取关键词字面匹配,弥补向量漏召回
* 缓存机制:Caffeine本地缓存查询向量+关键词,通过余弦相似度做语义模糊命中,减少LLM与Embedding调用
* 合并逻辑:两路文档去重,携带各自匹配分数,按语义分数降序截断固定条数,标记来源类型(vector/keyword/hybrid)
*/
@Slf4j
@Component
@RequiredArgsConstructor // Lombok自动生成全参构造,Spring自动注入所有final依赖
public class HybridDocumentRetriever implements DocumentRetriever {
// SpringAI Redis向量存储,用于语义向量检索
private final VectorStore vectorStore;
// Redis客户端,执行RedisSearch全文检索命令FT.SEARCH
private final JedisPooled jedisPooled;
// LLM对话客户端,用于提取查询核心关键词
private final ChatClient chatClient;
// JSON序列化工具,解析LLM返回关键词数组、Redis元数据
private final ObjectMapper objectMapper;
// 嵌入模型,生成用户查询向量用于语义缓存匹配
private final EmbeddingModel embeddingModel;
// RAG统一配置类,读取yml中所有召回、缓存阈值参数
private final RagProperties ragProperties;
// 文档元数据固定Key常量
private static final String METADATA_RECALL_FROM = "recall_from";
private static final String METADATA_SCORE = "score";
// 召回来源标记
private static final String RECALL_VECTOR = "vector";
private static final String RECALL_KEYWORD = "keyword";
private static final String RECALL_HYBRID = "hybrid";
// RedisSearch返回字段名常量
private static final String FIELD_CONTENT = "content";
private static final String FIELD_SOURCE = "source";
private static final String FIELD_META = "metadata";
// LLM关键词提取最大文本长度,截断节约Token
private static final int MAX_QUERY_LEN = 500;
// 两路召回合并后最大文档条数,控制送入重排的数据量
private static final int MERGE_LIMIT = 50;
// ==================== Caffeine本地语义缓存 ====================
// Key: 用户原始查询文本 Value: 查询向量+提取关键词+时间戳
private Cache<String, CachedEntry> cache;
// 访问顺序队列,仅保留最近CANDIDATE_LIMIT条用于相似度对比,降低遍历开销
private final ConcurrentLinkedDeque<String> accessOrder = new ConcurrentLinkedDeque<>();
// 语义模糊匹配命中计数
private final AtomicLong semanticHits = new AtomicLong(0);
// 语义缓存未命中计数(需要调用LLM+Embedding)
private final AtomicLong semanticMisses = new AtomicLong(0);
/**
* Bean依赖注入完成后初始化Caffeine缓存
* 配置:最大容量、写入24小时过期、统计命中率、过期/淘汰打印日志
*/
@PostConstruct
public void initCache() {
this.cache = Caffeine.newBuilder()
.maximumSize(ragProperties.getCacheMaxSize())
.expireAfterWrite(ragProperties.getCacheExpire())
.recordStats()
.removalListener((key, value, cause) -> {
if (cause == RemovalCause.EXPIRED) {
log.debug("语义缓存条目过期移除: {}", key);
} else if (cause == RemovalCause.SIZE) {
log.debug("语义缓存容量LRU淘汰: {}", key);
}
})
.build();
}
/**
* 缓存存储实体:一条查询对应的向量、关键词、写入时间戳
*/
private static class CachedEntry {
// 查询文本向量
final float[] embedding;
// LLM提取的核心关键词列表
final List<String> keywords;
// 缓存写入时间,用于双重过期校验
final long timestamp;
CachedEntry(float[] embedding, List<String> keywords) {
this.embedding = embedding;
this.keywords = keywords;
this.timestamp = System.currentTimeMillis();
}
/**
* 双重过期校验:对比当前时间与配置过期时长
* @param expireMs 配置缓存过期毫秒数
* @return true=已过期,需要删除
*/
boolean isExpired(long expireMs) {
return System.currentTimeMillis() - timestamp > expireMs;
}
}
/**
* Redis命令枚举,预编译字节数组避免重复字符串转码
*/
private enum RedisCommand implements ProtocolCommand {
FT_SEARCH,
FT_CREATE,
FT_INFO;
private final byte[] rawBytes;
RedisCommand() {
this.rawBytes = this.name().replace('_', '.').getBytes(StandardCharsets.UTF_8);
}
@Override
public byte[] getRaw() {
return rawBytes;
}
}
/**
* Spring AI标准检索入口方法
* @param query 用户查询封装对象
* @return 两路召回合并、去重、按分数排序截断后的文档列表
*/
@Override
public List<Document> retrieve(Query query) {
RetrieveCoTResult cotResult = new RetrieveCoTResult();
String rawText = query.text();
String queryText = rawText.strip();
long start = System.currentTimeMillis();
List<Document> vectorDocs = Collections.emptyList();
List<Document> keywordDocs = Collections.emptyList();
List<String> keywords = null;
Boolean cacheHit = false;
Double simScore = null;
if (!queryText.isBlank()) {
// 向量召回
vectorDocs = vectorRetrieve(queryText);
// 关键词检索,同时填充缓存、关键词、相似度到cotResult
keywordDocs = keywordRetrieve(queryText, cotResult);
cacheHit = cotResult.getCacheHit();
keywords = cotResult.getKeywords();
simScore = cotResult.getMatchSimilarity();
}
// 合并文档
List<Document> mergedDocs = mergeAndDeduplicate(vectorDocs, keywordDocs);
long costMs = System.currentTimeMillis() - start;
// 填充完整CoT数据
cotResult.setVectorDocs(vectorDocs);
cotResult.setKeywordDocs(keywordDocs);
cotResult.setMergedDocs(mergedDocs);
cotResult.setCacheHit(cacheHit);
cotResult.setKeywords(keywords);
cotResult.setMatchSimilarity(simScore);
cotResult.setCostMs(costMs);
// 存入线程本地,上层业务可读取
ThreadLocalUtil.setRetrieveCoT(cotResult);
// 接口标准返回合并后的文档列表
return mergedDocs;
}
/**
* 执行向量相似度检索
* @param queryText 用户查询文本
* @return 语义匹配文档列表,自带相似度分数存入metadata score
*/
private List<Document> vectorRetrieve(String queryText) {
try {
SearchRequest searchRequest = SearchRequest.builder()
.query(queryText)
.topK(ragProperties.getVectorTopK())
.similarityThreshold(ragProperties.getVectorSimilarityThreshold())
.build();
return vectorStore.similaritySearch(searchRequest);
} catch (Exception e) {
log.error("向量语义检索执行异常", e);
return Collections.emptyList();
}
}
/**
* 关键词检索主逻辑:优先走语义缓存,未命中则调用LLM提取关键词再查询RedisSearch
* @param queryText 用户原始查询
* @return 全文匹配文档列表
*/
// 内部方法不变,将缓存信息写入cotResult
private List<Document> keywordRetrieve(String queryText, RetrieveCoTResult cotResult) {
try {
List<String> keys = getCachedKeywords(queryText, cotResult);
if (keys != null) {
cotResult.setCacheHit(true);
cotResult.setKeywords(keys);
} else {
cotResult.setCacheHit(false);
keys = extractKeywords(queryText);
putCachedKeywords(queryText, keys);
cotResult.setKeywords(keys);
}
// 原有Redis FT.SEARCH逻辑完全不变
List<Document> allDocuments = new ArrayList<>();
for (String key : keys) {
String safeKey = escapeQuery(key);
Object result = jedisPooled.sendCommand(RedisCommand.FT_SEARCH,
ragProperties.getRedisIndexName(),
"@content:*" + safeKey + "*",
"LIMIT", "0", String.valueOf(ragProperties.getKeywordTopK()),
"RETURN", "3", FIELD_CONTENT, FIELD_META, FIELD_SOURCE
);
if (!(result instanceof List)) continue;
@SuppressWarnings("unchecked")
List<Object> results = (List<Object>) result;
List<Document> docs = parseSearchResults(results);
allDocuments.addAll(docs);
}
return deduplicateDocuments(allDocuments);
} catch (Exception e) {
log.error("关键词检索异常", e);
return Collections.emptyList();
}
}
/**
* 语义缓存匹配逻辑:遍历最近访问的缓存条目,计算余弦相似度,达到阈值则复用关键词
* @param queryText 当前用户查询
* @return 命中则返回缓存关键词,未命中返回null
*/
// 修改getCachedKeywords,将匹配相似度存入cotResult
private List<String> getCachedKeywords(String queryText, RetrieveCoTResult cotResult) {
if (cache.estimatedSize() == 0) return null;
try {
float[] currentEmbedding = embeddingModel.embed(queryText);
List<String> candidates = new ArrayList<>(accessOrder);
int limit = ragProperties.getCacheCandidateLimit();
int compareCount = Math.min(candidates.size(), limit);
String bestMatch = null;
double bestSim = 0.0;
long expireMs = ragProperties.getCacheExpire().toMillis();
int compared = 0;
for (int i = 0; i < compareCount; i++) {
String q = candidates.get(i);
CachedEntry entry = cache.getIfPresent(q);
if (entry == null || entry.isExpired(expireMs)) {
accessOrder.remove(q);
if (entry != null) cache.invalidate(q);
continue;
}
compared++;
double sim = calculateCosineSimilarity(currentEmbedding, entry.embedding);
if (sim > bestSim) {
bestSim = sim;
bestMatch = q;
}
}
double threshold = ragProperties.getSemanticSimilarityThreshold();
if (bestMatch != null && bestSim >= threshold) {
semanticHits.incrementAndGet();
cotResult.setMatchSimilarity(bestSim);
CachedEntry entry = cache.getIfPresent(bestMatch);
return entry != null ? entry.keywords : null;
}
semanticMisses.incrementAndGet();
return null;
} catch (Exception e) {
log.warn("缓存匹配异常", e);
return null;
}
}
/**
* 将新查询向量+关键词存入Caffeine缓存,维护访问顺序队列(仅保留最近CANDIDATE_LIMIT条)
* @param queryText 用户原始查询
* @param keywords LLM提取的关键词列表
*/
private void putCachedKeywords(String queryText, List<String> keywords) {
try {
float[] embedding = embeddingModel.embed(queryText);
CachedEntry entry = new CachedEntry(embedding, keywords);
cache.put(queryText, entry);
// 更新访问队列,当前查询置顶
accessOrder.remove(queryText);
accessOrder.addFirst(queryText);
// 队列截断,永久只保留最近对比条数,消除remove O(n)性能损耗
int limit = ragProperties.getCacheCandidateLimit();
while (accessOrder.size() > limit) {
accessOrder.pollLast();
}
// 打印缓存统计信息
var stats = cache.stats();
double hitRate = getSemanticHitRate();
log.info("语义缓存写入完成,当前缓存容量{}/{},语义匹配命中率{:.1f}%,Caffeine原生命中率{:.1f}%",
cache.estimatedSize(), ragProperties.getCacheMaxSize(), hitRate, stats.hitRate() * 100);
} catch (Exception e) {
log.warn("写入语义缓存失败", e);
}
}
/**
* 计算自定义语义缓存匹配总命中率
*/
private double getSemanticHitRate() {
long total = semanticHits.get() + semanticMisses.get();
return total == 0 ? 0 : (double) semanticHits.get() / total * 100;
}
/**
* 计算两个浮点向量的余弦相似度,取值区间 [-1,1]
* @param vec1 向量1
* @param vec2 向量2
* @return 相似度数值,向量为空返回0
*/
private double calculateCosineSimilarity(float[] vec1, float[] vec2) {
if (vec1 == null || vec2 == null || vec1.length == 0 || vec2.length == 0) return 0;
double dot = 0, n1 = 0, n2 = 0;
int len = Math.min(vec1.length, vec2.length);
for (int i = 0; i < len; i++) {
float v1 = vec1[i], v2 = vec2[i];
dot += v1 * v2;
n1 += v1 * v1;
n2 += v2 * v2;
}
// 零向量避免除零
if (n1 == 0 || n2 == 0) return 0;
return dot / (Math.sqrt(n1) * Math.sqrt(n2));
}
/**
* 调用LLM提取查询核心关键词,截断超长文本并清洗模型返回JSON
* @param queryText 用户查询文本
* @return 关键词字符串列表
*/
private List<String> extractKeywords(String queryText) {
// 超长文本截断,减少LLM输入token消耗
String shortQuery = queryText.length() > MAX_QUERY_LEN
? queryText.substring(0, MAX_QUERY_LEN)
: queryText;
// 固定Prompt,约束模型仅输出纯净JSON数组
String prompt = """
你是拆词助手,提取用户核心关键词,仅返回标准JSON字符串数组,无任何多余文字、注释、代码块。
样例输出:["关键词1","关键词2"]
用户文本:%s
""".formatted(shortQuery);
try {
String raw = chatClient.prompt(prompt).call().content();
// 清洗Markdown代码块、换行、空格
raw = raw.replaceAll("```(json)?", "").trim().replaceAll("\\s+", "");
return objectMapper.readValue(raw, new TypeReference<List<String>>() {});
} catch (Exception e) {
log.error("调用LLM提取关键词失败", e);
return Collections.emptyList();
}
}
/**
* 根据Document ID对文档列表去重
*/
private List<Document> deduplicateDocuments(List<Document> documents) {
Map<String, Document> map = new LinkedHashMap<>();
for (Document doc : documents) {
map.putIfAbsent(doc.getId(), doc);
}
return new ArrayList<>(map.values());
}
/**
* Redis返回字节/对象统一转字符串工具方法
*/
private String safeToString(Object obj) {
if (obj == null) return null;
if (obj instanceof byte[]) return new String((byte[]) obj, StandardCharsets.UTF_8);
return obj.toString();
}
/**
* 解析Redis FT.SEARCH返回的嵌套数组,组装Document对象并填充元数据
*/
@SuppressWarnings("unchecked")
private List<Document> parseSearchResults(List<Object> results) {
List<Document> docs = new ArrayList<>();
if (results == null || results.size() < 2) return docs;
try {
int idx = 1;
while (idx < results.size()) {
String docId = safeToString(results.get(idx++));
if (docId == null || idx >= results.size()) break;
Object fieldObj = results.get(idx++);
if (!(fieldObj instanceof List)) continue;
List<Object> fields = (List<Object>) fieldObj;
String content = null, source = null;
Map<String, Object> meta = new HashMap<>();
meta.put(METADATA_RECALL_FROM, RECALL_KEYWORD);
// 遍历返回字段,赋值内容、来源、自定义元数据
for (int i = 0; i < fields.size() - 1; i += 2) {
String fName = safeToString(fields.get(i));
String fVal = safeToString(fields.get(i + 1));
if (FIELD_CONTENT.equals(fName)) content = fVal;
else if (FIELD_SOURCE.equals(fName)) {
source = fVal;
meta.put(FIELD_SOURCE, source);
} else if (FIELD_META.equals(fName)) {
try {
Map<String, Object> inner = objectMapper.readValue(fVal, new TypeReference<Map<String, Object>>() {});
meta.putAll(inner);
} catch (Exception ex) {
meta.put(fName, fVal);
}
} else {
meta.put(fName, fVal);
}
}
// 仅保留存在正文内容的文档
if (content != null && !content.isBlank()) {
docs.add(new Document(docId, content, meta));
}
}
} catch (Exception e) {
log.error("解析RedisSearch返回结果异常", e);
}
return docs;
}
/**
* 合并向量召回、关键词召回两路文档:
* 1. 按文档ID去重,同时标记hybrid(两路同时命中)
* 2. 向量文档携带原始语义分数,关键词默认0.1低分
* 3. 按分数降序排序,截断最大合并条数MERGE_LIMIT
* 4. 回填recall_from与score元数据供下游重排使用
*/
private List<Document> mergeAndDeduplicate(List<Document> vectorDocs, List<Document> keywordDocs) {
Map<String, DocumentWrapper> map = new LinkedHashMap<>();
// 存入向量召回文档,携带原始相似度分数
for (Document d : vectorDocs) {
double score = d.getMetadata().containsKey(METADATA_SCORE)
? ((Number) d.getMetadata().get(METADATA_SCORE)).doubleValue()
: 0.5;
DocumentWrapper w = new DocumentWrapper(d, score, RECALL_VECTOR);
map.put(d.getId(), w);
}
// 存入关键词召回文档,重复ID标记为混合来源
for (Document d : keywordDocs) {
if (map.containsKey(d.getId())) {
DocumentWrapper exist = map.get(d.getId());
exist.recallType = RECALL_HYBRID;
} else {
map.put(d.getId(), new DocumentWrapper(d, 0.1, RECALL_KEYWORD));
}
}
// 按匹配分数从高到低排序,截断上限,填充元数据后返回
return map.values().stream()
.sorted((a, b) -> Double.compare(b.score, a.score))
.limit(MERGE_LIMIT)
.map(w -> {
Map<String, Object> meta = new HashMap<>(w.doc.getMetadata());
meta.put(METADATA_RECALL_FROM, w.recallType);
meta.put(METADATA_SCORE, w.score);
return w.doc.mutate().metadata(meta).build();
})
.collect(Collectors.toList());
}
/**
* 文档临时包装类:存储原始文档、匹配分数、召回来源,用于合并阶段排序
*/
private static class DocumentWrapper {
Document doc;
double score;
String recallType;
DocumentWrapper(Document d, double s, String t) {
doc = d; score = s; recallType = t;
}
}
/**
* RedisSearch特殊字符转义,防止模糊查询语法报错
*/
private String escapeQuery(String query) {
if (query == null) return "";
return query.replaceAll("([!\"(){}\\[\\\\]^~*?:/\\-])", "\\\\$1");
}
/**
* 对外暴露手动清空全部语义缓存接口
* 适用场景:知识库全量更新后,清除旧查询缓存
*/
public void clearCache() {
cache.invalidateAll();
accessOrder.clear();
semanticHits.set(0);
semanticMisses.set(0);
log.info("已清空全部本地语义缓存");
}
/**
* 对外获取缓存监控统计指标,可对接监控接口/打印日志
* @return 缓存各项指标Map
*/
public Map<String, Object> getCacheStats() {
var stats = cache.stats();
Map<String, Object> res = new LinkedHashMap<>();
res.put("size", cache.estimatedSize());
res.put("caffeineHitRate", stats.hitRate() * 100);
res.put("evictionCount", stats.evictionCount());
res.put("semanticHitRate", getSemanticHitRate());
res.put("semanticHits", semanticHits.get());
res.put("semanticMisses", semanticMisses.get());
return res;
}
}
改造 LocalRerankProcessor
返回 RerankCoTResult
package com.woniuxy.spring.processor;
import com.woniuxy.spring.config.RagProperties;
import com.woniuxy.spring.cot.RerankCoTResult;
import com.woniuxy.spring.util.ThreadLocalUtil;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.ai.document.Document;
import org.springframework.ai.rag.Query;
import org.springframework.ai.rag.postretrieval.document.DocumentPostProcessor;
import org.springframework.stereotype.Service;
import org.springframework.util.StringUtils;
import java.util.*;
import java.util.stream.Collectors;
@Slf4j
@Service
@RequiredArgsConstructor
public class LocalRerankProcessor implements DocumentPostProcessor {
private final RagProperties ragProperties;
private Set<String> stopWords;
private final Object stopWordsLock = new Object();
// 内置通用中文停用词
private static final Set<String> DEFAULT_CN_STOP_WORDS = new HashSet<>(Arrays.asList(
"的", "了", "是", "我", "有", "和", "就", "不", "人", "都", "一", "他", "这", "为", "之",
"也", "很", "到", "说", "要", "去", "你", "会", "着", "没有", "看", "好", "自己", "什么"
));
private static final String METADATA_SCORE = "score";
private static final String METADATA_RERANK_SCORE = "rerank_score";
private Set<String> getStopWords() {
if (stopWords == null) {
synchronized (stopWordsLock) {
if (stopWords == null) {
stopWords = new HashSet<>(DEFAULT_CN_STOP_WORDS);
String cfg = ragProperties.getRerankStopWords();
if (StringUtils.hasText(cfg)) {
Set<String> custom = parseStopWords(cfg);
stopWords.addAll(custom);
}
}
}
}
return stopWords;
}
private Set<String> parseStopWords(String config) {
return Arrays.stream(config.split("[,\\s|]+"))
.filter(StringUtils::hasText)
.map(String::trim)
.collect(Collectors.toSet());
}
// Spring AI标准接口,返回值不变
@Override
public List<Document> process(Query query, List<Document> documents) {
RerankCoTResult cotResult = buildRerankCoT(query, documents);
ThreadLocalUtil.setRerankCoT(cotResult);
return cotResult.getTopNDocs();
}
// 新增私有方法,封装全部重排打分中间数据
private RerankCoTResult buildRerankCoT(Query query, List<Document> documents) {
RerankCoTResult cotResult = new RerankCoTResult();
long start = System.currentTimeMillis();
List<Document> rawList = new ArrayList<>(documents);
cotResult.setRawDocs(rawList);
if (documents == null || documents.isEmpty()) {
cotResult.setTopNDocs(Collections.emptyList());
cotResult.setCostMs(System.currentTimeMillis() - start);
return cotResult;
}
int topN = ragProperties.getRerankTopN();
int maxRerank = ragProperties.getRerankMaxSize();
List<Document> toRerank = truncateDocuments(documents, maxRerank);
if (toRerank.size() <= topN) {
cotResult.setTopNDocs(toRerank);
cotResult.setCostMs(System.currentTimeMillis() - start);
return cotResult;
}
try {
QueryFeatures features = extractQueryFeatures(query.text());
cotResult.setValidTerms(features.validTerms);
List<ScoredDocument> scoredList = new ArrayList<>();
for (Document doc : toRerank) {
double vecScore = getVectorScore(doc);
double ruleScore = calculateRuleScore(features, doc);
double finalScore = vecScore * 0.45 + ruleScore * 0.55;
scoredList.add(new ScoredDocument(doc, finalScore));
}
List<Document> result = scoredList.stream()
.sorted((a, b) -> Double.compare(b.score, a.score))
.limit(topN)
.map(sd -> {
Map<String, Object> meta = new HashMap<>(sd.doc.getMetadata());
meta.put(METADATA_RERANK_SCORE, sd.score);
return sd.doc.mutate().metadata(meta).build();
}).collect(Collectors.toList());
long cost = System.currentTimeMillis() - start;
cotResult.setTopNDocs(result);
cotResult.setCostMs(cost);
return cotResult;
} catch (Exception e) {
log.error("重排异常", e);
List<Document> fallback = toRerank.stream().limit(topN).collect(Collectors.toList());
cotResult.setTopNDocs(fallback);
cotResult.setCostMs(System.currentTimeMillis() - start);
return cotResult;
}
}
private List<Document> truncateDocuments(List<Document> docs, int max) {
if (docs.size() <= max) return docs;
log.debug("待重排文档{}超过上限{},截断", docs.size(), max);
return docs.stream().limit(max).collect(Collectors.toList());
}
private QueryFeatures extractQueryFeatures(String text) {
if (!StringUtils.hasText(text)) return new QueryFeatures(Collections.emptyList(), 0);
int minLen = ragProperties.getRerankMinTermLength();
String[] parts = text.split("[^\\p{L}\\p{N}]+");
List<String> all = Arrays.stream(parts)
.filter(s -> s != null && s.length() >= minLen)
.collect(Collectors.toList());
Set<String> stop = getStopWords();
List<String> valid = all.stream()
.filter(t -> !stop.contains(t))
.filter(t -> !isNum(t))
.distinct()
.collect(Collectors.toList());
if (valid.size() < 2 && all.size() >= 2) {
valid = all.stream().distinct().collect(Collectors.toList());
}
return new QueryFeatures(valid, all.size());
}
private double getVectorScore(Document doc) {
Object obj = doc.getMetadata().get(METADATA_SCORE);
if (obj instanceof Number) {
return ((Number) obj).doubleValue();
}
return 0.1;
}
private double calculateRuleScore(QueryFeatures ft, Document doc) {
String text = doc.getText();
if (!StringUtils.hasText(text)) return 0;
List<String> terms = ft.validTerms;
String lowerText = text.toLowerCase();
int textLen = lowerText.length();
double cover = calcCover(terms, lowerText) * 0.35;
double freq = calcFreq(terms, lowerText, textLen) * 0.25;
double pos = calcPos(terms, lowerText, textLen) * 0.20;
double compact = calcCompact(terms, lowerText) * 0.10;
double lenPen = calcLenPen(textLen) * 0.10;
return Math.min(1, Math.max(0, cover + freq + pos + compact + lenPen));
}
private double calcCover(List<String> terms, String text) {
long hit = terms.stream().filter(t -> text.contains(t.toLowerCase())).count();
return (double) hit / terms.size();
}
private double calcFreq(List<String> terms, String text, int len) {
int total = 0;
for (String t : terms) {
String lt = t.toLowerCase();
int idx = 0;
while ((idx = text.indexOf(lt, idx)) != -1) {
total++;
idx += lt.length();
}
}
double density = (double) total / len;
return Math.min(density * 50, 1);
}
private double calcPos(List<String> terms, String text, int len) {
double sumPos = 0;
int hitCnt = 0;
for (String t : terms) {
int idx = text.indexOf(t.toLowerCase());
if (idx >= 0) {
sumPos += 1.0 - ((double) idx / len);
hitCnt++;
}
}
return hitCnt > 0 ? sumPos / hitCnt : 0;
}
private double calcCompact(List<String> terms, String text) {
List<Integer> posList = new ArrayList<>();
for (String t : terms) {
int idx = text.indexOf(t.toLowerCase());
if (idx >= 0) posList.add(idx);
}
if (posList.size() < 2) return 0.5;
double avg = posList.stream().mapToDouble(Integer::doubleValue).average().orElse(0);
double var = posList.stream().mapToDouble(p -> Math.pow(p - avg, 2)).average().orElse(0);
double std = Math.sqrt(var);
return Math.min(1, Math.max(0, 1 - std / 500));
}
private double calcLenPen(int len) {
if (len < 10) return 0.3;
if (len < 100) return 0.8;
if (len < 500) return 1.0;
if (len < 1500) return 0.9;
if (len < 3000) return 0.7;
return 0.5;
}
private boolean isNum(String s) {
return s.matches("^\\d+$");
}
private static class QueryFeatures {
List<String> validTerms;
int totalTerms;
QueryFeatures(List<String> valid, int total) {
validTerms = valid;
totalTerms = total;
}
}
private static class ScoredDocument {
Document doc;
double score;
ScoredDocument(Document d, double s) {
doc = d;
score = s;
}
}
}
核心业务层
VectorServiceImpl 整合全链路并持久化 CoT
package com.woniuxy.spring.service.impl;
import com.woniuxy.spring.config.RagProperties;
import com.woniuxy.spring.cot.RerankCoTResult;
import com.woniuxy.spring.cot.RetrieveCoTResult;
import com.woniuxy.spring.processor.LocalRerankProcessor;
import com.woniuxy.spring.retriever.HybridDocumentRetriever;
import com.woniuxy.spring.service.CotRecordService;
import com.woniuxy.spring.service.FileInfoService;
import com.woniuxy.spring.service.VectorService;
import com.woniuxy.spring.util.DocumentSplitUtil;
import com.woniuxy.spring.util.ThreadLocalUtil;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.client.advisor.api.Advisor;
import org.springframework.ai.rag.advisor.RetrievalAugmentationAdvisor;
import org.springframework.ai.rag.preretrieval.query.transformation.RewriteQueryTransformer;
import org.springframework.ai.document.Document;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.stereotype.Service;
import org.springframework.util.StringUtils;
import org.springframework.web.multipart.MultipartFile;
import java.io.File;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.util.*;
import java.util.concurrent.atomic.AtomicReference;
import java.util.stream.Collectors;
/**
* RAG知识库文件上传、问答业务实现类
* 功能:1. 文件上传、切片、批量向量化存入Redis向量库、入库业务表记录
* 2. 封装完整RAG问答链路:查询重写→多路混合召回→本地规则重排→LLM生成回答
*/
@Slf4j
@Service
@RequiredArgsConstructor
public class VectorServiceImpl implements VectorService {
// SpringAI向量存储(RedisVectorStore),存储文档向量与原文
private final VectorStore vectorStore;
// 大模型对话客户端,用于查询重写、关键词提取、最终问答生成
private final ChatClient chatClient;
// 文件信息持久化服务,记录上传文件元数据
private final FileInfoService fileInfoService;
// 检索后本地规则重排处理器,对召回文档做相关性打分排序
private final LocalRerankProcessor rerankProcessor;
// 自定义多路混合召回器:向量相似度召回 + RedisSearch关键词全文召回
private final HybridDocumentRetriever hybridDocumentRetriever;
// RAG全局配置参数,统一读取yml配置
private final RagProperties ragProperties;
// 用户提问最大长度,超长截断节约LLM Token消耗
private static final int MAX_CHAT_MSG_LEN = 1000;
// 新增CoT存储
private final CotRecordService cotRecordService;
/**
* 上传知识库文件,完成全流程处理
* 流程:安全校验 → 本地磁盘存储 → 文本切片 → 批量向量化存入向量库 → 数据库留存文件记录
* @param file 前端上传文件
* @return 切片后的文档总块数
* @throws Exception 文件写入、切片、入库异常抛出
*/
@Override
public int uploadFile(MultipartFile file) throws Exception {
// ===================== 1. 文件安全校验,拦截非法请求 =====================
// 判断文件对象是否为空
if (file == null || file.isEmpty()) {
throw new IllegalArgumentException("上传文件不能为空");
}
String originalName = file.getOriginalFilename();
// 判断文件名称是否空白
if (!StringUtils.hasText(originalName)) {
throw new IllegalArgumentException("文件名称为空");
}
// 路径穿越防御:拼接完整路径并标准化,校验文件只能存放在配置的上传目录内
Path resolve = Paths.get(ragProperties.getFileUploadDir()).resolve(originalName).normalize();
Path basePath = Paths.get(ragProperties.getFileUploadDir()).normalize();
if (!resolve.startsWith(basePath)) {
throw new SecurityException("非法文件名,禁止路径穿越");
}
// 文件大小限制,防止超大文件占用磁盘/内存
long maxByte = ragProperties.getMaxFileSizeMb() * 1024 * 1024;
if (file.getSize() > maxByte) {
throw new IllegalArgumentException("文件超出最大限制:" + ragProperties.getMaxFileSizeMb() + "MB");
}
// 文件后缀白名单校验,只允许配置中指定的文档类型
String suffix = originalName.substring(originalName.lastIndexOf("."));
if (!ragProperties.getAllowSuffix().contains(suffix.toLowerCase())) {
throw new IllegalArgumentException("不支持的文件格式:" + suffix);
}
// ===================== 2. 文件落地到服务器本地磁盘 =====================
String filePath = resolve.toString();
file.transferTo(new File(filePath));
log.info("文件保存成功:{}", filePath);
// ===================== 3. 文件文本切片,生成Document文档块 =====================
List<Document> documents = DocumentSplitUtil.splitFileToDocuments(
filePath, ragProperties.getChunkSize(), ragProperties.getChunkOverlap()
);
log.info("文件切片完成,共{}块", documents.size());
// ===================== 4. 批量向量化写入Redis向量库 =====================
// 适配嵌入模型单次最大支持批量数量,分批次提交向量化
int batch = ragProperties.getEmbedBatchSize();
for (int i = 0; i < documents.size(); i += batch) {
int end = Math.min(i + batch, documents.size());
vectorStore.add(documents.subList(i, end));
}
// ===================== 5. 业务数据库保存文件元信息 =====================
fileInfoService.saveFileInfo(originalName, filePath, documents);
return documents.size();
}
/**
* RAG问答统一入口
* 完整链路:用户提问校验截断 → 查询重写 → 多路混合召回 → 本地重排 → LLM生成答案
* @param message 用户原始提问文本
* @return 大模型结合知识库文档生成的回答
*/
/**
* RAG问答统一入口,完整留存CoT思维链至数据库
* @param message 用户原始提问
* @param sessionId 会话标识,前端传入;为空自动生成UUID
* @return LLM结合知识库生成的最终回答
*/
@Override
public String chat(String message, String sessionId) {
// 1. 入参基础校验
if (!StringUtils.hasText(message)) {
return "请输入有效提问内容";
}
if (!StringUtils.hasText(sessionId)) {
sessionId = UUID.randomUUID().toString();
}
String originalUserMsg = message;
String userMsg = message.length() > MAX_CHAT_MSG_LEN
? message.substring(0, MAX_CHAT_MSG_LEN)
: message;
AtomicReference<String> rewriteQueryText = new AtomicReference<>();
// 2. 构建RAG Advisor
Advisor retrievalAugmentationAdvisor = buildRetrievalAdvisor(rewriteQueryText);
// 3. CoT专用Prompt
String cotPromptTemplate = buildCotPrompt(userMsg);
// 4. 调用LLM(带异常处理)
String fullLlmResp;
long llmStart = System.currentTimeMillis();
try {
fullLlmResp = chatClient.prompt()
.advisors(retrievalAugmentationAdvisor)
.user(cotPromptTemplate)
.call()
.content();
} catch (Exception e) {
log.error("LLM调用失败", e);
return "抱歉,服务暂时不可用,请稍后重试";
}
long llmCostMs = System.currentTimeMillis() - llmStart;
// 5. 拆分思考与答案
String cotThinkContent = "";
String finalAnswer = fullLlmResp;
if (fullLlmResp.contains("【思考过程】") && fullLlmResp.contains("【最终回答】")) {
String[] splitArr = fullLlmResp.split("【最终回答】");
cotThinkContent = splitArr[0].replace("【思考过程】", "").trim();
if (splitArr.length > 1) {
finalAnswer = splitArr[1].trim();
}
}
// 深拷贝数据,避免异步线程引用问题
RetrieveCoTResult retrieveCoT = ThreadLocalUtil.getRetrieveCoT();
RerankCoTResult rerankCoT = ThreadLocalUtil.getRerankCoT();
// 深拷贝数据
RetrieveCoTResult retrieveCoTCopy = deepCopyRetrieveCoT(retrieveCoT);
RerankCoTResult rerankCoTCopy = deepCopyRerankCoT(rerankCoT);
// 立刻清空ThreadLocal
ThreadLocalUtil.clear();
// 6. 持久化:使用深拷贝后的数据
if (ragProperties.isEnableCotRecord()) {
try {
if (ragProperties.isCotAsyncSave()) {
cotRecordService.asyncSaveCoTRecord(
sessionId,
originalUserMsg,
rewriteQueryText.get(),
retrieveCoTCopy, // 使用深拷贝数据
rerankCoTCopy, // 使用深拷贝数据
cotThinkContent,
finalAnswer,
llmCostMs
);
} else {
cotRecordService.saveCoTRecord(
sessionId,
originalUserMsg,
rewriteQueryText.get(),
retrieveCoTCopy,
rerankCoTCopy,
cotThinkContent,
finalAnswer,
llmCostMs
);
}
} catch (Exception e) {
log.error("CoT记录保存失败", e);
}
}
return finalAnswer;
}
/**
* 构建RAG Advisor
*/
private Advisor buildRetrievalAdvisor(AtomicReference<String> rewriteQueryText) {
return RetrievalAugmentationAdvisor.builder()
.queryTransformers(RewriteQueryTransformer.builder()
.chatClientBuilder(chatClient.mutate())
.build())
.documentRetriever(query -> {
rewriteQueryText.set(query.text());
return hybridDocumentRetriever.retrieve(query);
})
.documentPostProcessors(rerankProcessor)
.build();
}
/**
* 构建CoT Prompt
*/
private String buildCotPrompt(String userMsg) {
return String.format("""
你是企业知识库专业问答助手,回答用户问题时必须完整输出推理思维链,严格分为两段固定格式,禁止多余解释、markdown、符号:
【思考过程】:分步拆解用户问题,逐条结合参考文档分析匹配依据,说明文档相关性判断逻辑
【最终回答】:整理简洁、通顺、准确的答案给用户
参考知识库文档上下文:{context}
用户问题:%s
""", userMsg);
}
/**
* 深拷贝 RetrieveCoTResult(只拷贝必要的数据)
*/
private RetrieveCoTResult deepCopyRetrieveCoT(RetrieveCoTResult source) {
if (source == null) {
return null;
}
RetrieveCoTResult copy = new RetrieveCoTResult();
copy.setCacheHit(source.getCacheHit());
copy.setMatchSimilarity(source.getMatchSimilarity());
copy.setKeywords(source.getKeywords() != null ? new ArrayList<>(source.getKeywords()) : null);
copy.setCostMs(source.getCostMs());
// 只拷贝文档ID和文本内容,不拷贝完整Document对象(避免大对象序列化)
copy.setVectorDocs(copyDocuments(source.getVectorDocs()));
copy.setKeywordDocs(copyDocuments(source.getKeywordDocs()));
copy.setMergedDocs(copyDocuments(source.getMergedDocs()));
return copy;
}
/**
* 深拷贝 RerankCoTResult
*/
private RerankCoTResult deepCopyRerankCoT(RerankCoTResult source) {
if (source == null) {
return null;
}
RerankCoTResult copy = new RerankCoTResult();
copy.setValidTerms(source.getValidTerms() != null ? new ArrayList<>(source.getValidTerms()) : null);
copy.setCostMs(source.getCostMs());
copy.setRawDocs(copyDocuments(source.getRawDocs()));
copy.setTopNDocs(copyDocuments(source.getTopNDocs()));
return copy;
}
/**
* 拷贝文档列表(只拷贝必要字段)
*/
private List<Document> copyDocuments(List<Document> docs) {
if (docs == null || docs.isEmpty()) {
return Collections.emptyList();
}
return docs.stream()
.map(doc -> {
// 创建新的Document,只拷贝ID、内容和关键元数据
Map<String, Object> meta = new HashMap<>();
if (doc.getMetadata() != null) {
// 只拷贝必要的元数据字段
copyMetadata(meta, doc.getMetadata(), "recall_from", "score", "rerank_score", "source");
}
return new Document(doc.getId(), doc.getText(), meta);
})
.collect(Collectors.toList());
}
/**
* 选择性拷贝元数据
*/
private void copyMetadata(Map<String, Object> target, Map<String, Object> source, String... keys) {
for (String key : keys) {
if (source.containsKey(key)) {
target.put(key, source.get(key));
}
}
}
}
简易 ThreadLocal 工具
传递中间 CoT 数据
package com.woniuxy.spring.util;
import com.woniuxy.spring.model.cot.RetrieveCoTResult;
import com.woniuxy.spring.model.cot.RerankCoTResult;
public class ThreadLocalUtil {
private static final ThreadLocal<RetrieveCoTResult> RETRIEVE_COT = new ThreadLocal<>();
private static final ThreadLocal<RerankCoTResult> RERANK_COT = new ThreadLocal<>();
public static void setRetrieveCoT(RetrieveCoTResult data) {
RETRIEVE_COT.set(data);
}
public static RetrieveCoTResult getRetrieveCoT() {
return RETRIEVE_COT.get();
}
public static void setRerankCoT(RerankCoTResult data) {
RERANK_COT.set(data);
}
public static RerankCoTResult getRerankCoT() {
return RERANK_COT.get();
}
public static void clear() {
RETRIEVE_COT.remove();
RERANK_COT.remove();
}
}
application.yml 配置示例
rag:
# 原有所有向量、缓存、切片、文件、重排配置省略
enable-cot-record: true
cot-async-save: true
更多推荐
 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)