
从零搭建电影数据爬虫:Python实战TMDB热门榜单抓取
前言
你是否曾经想分析电影数据却苦于没有数据源?是否想学习爬虫技术却不知从何下手?今天,我们将通过一个完整的实战案例,带你走进网络爬虫的世界。
爬虫
爬虫:也称为网络爬虫(网络机器人),是一种按照一定的预设规则,自动浏览并抓取网络数据的程序或脚本。
网络机器人入门
概述
网络机器人:也称为网络爬虫,是一种按照一定的预设规则,自动浏览并抓取网络数据的程序或脚本。
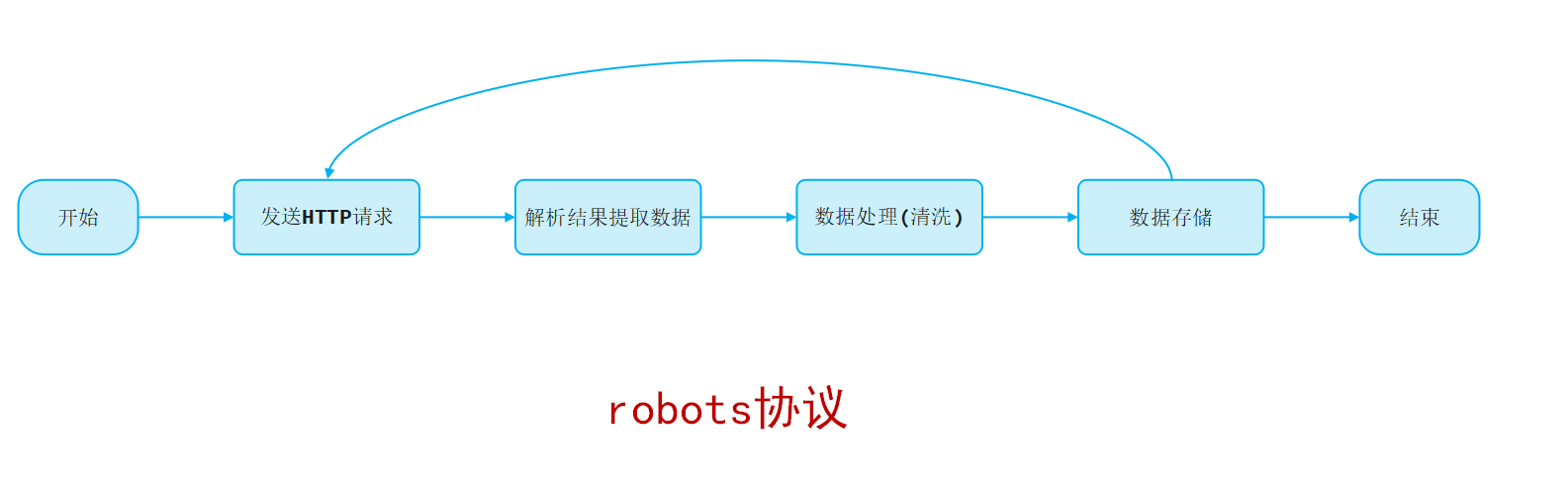
数据清洗:是指对采集到的原始数据进行处理、 修正、转换和标准化的过程,目的是让数据变得规范、准确 。
robots协议也称为爬虫协议、爬虫规则,是指网站根目录下存放的一份文本文件robots.txt,用于告诉爬虫哪些页面可以抓取,哪些页面不能抓取。(君子协议)
入门程序
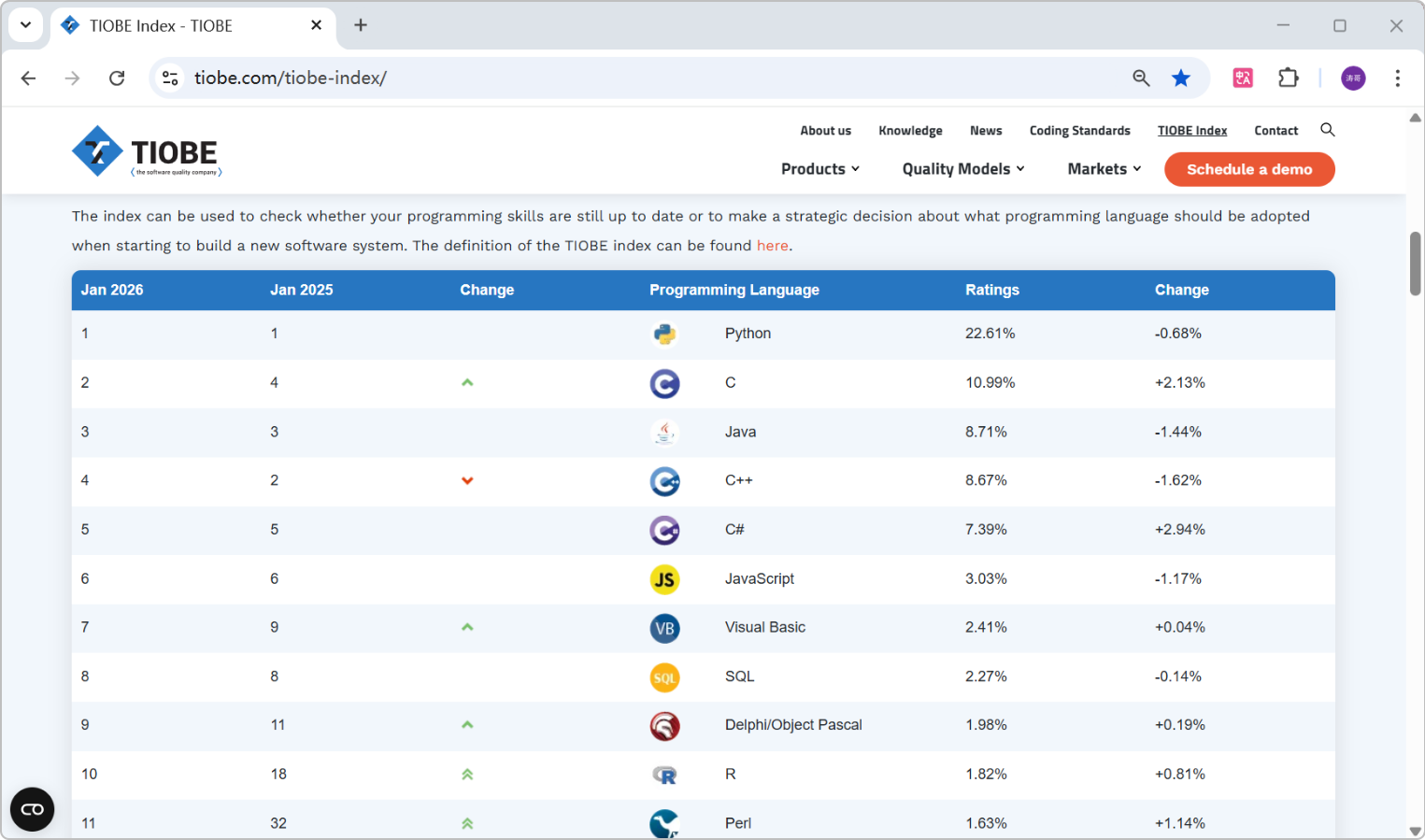
查看TIOBE网站的robots.txt文件,明确资源获取的规则
安装requests库,用于发送网络请求 (pip install requests)
编写python代码,访问TIOBE网站,获取数据
import requests
# 定义url
targetUrl = 'https://www.tiobe.com/tiobe-index/'
# 发送请求
response = requests.get(url=targetUrl)
# 输出数据到控制台
print(response.text)
网页解析
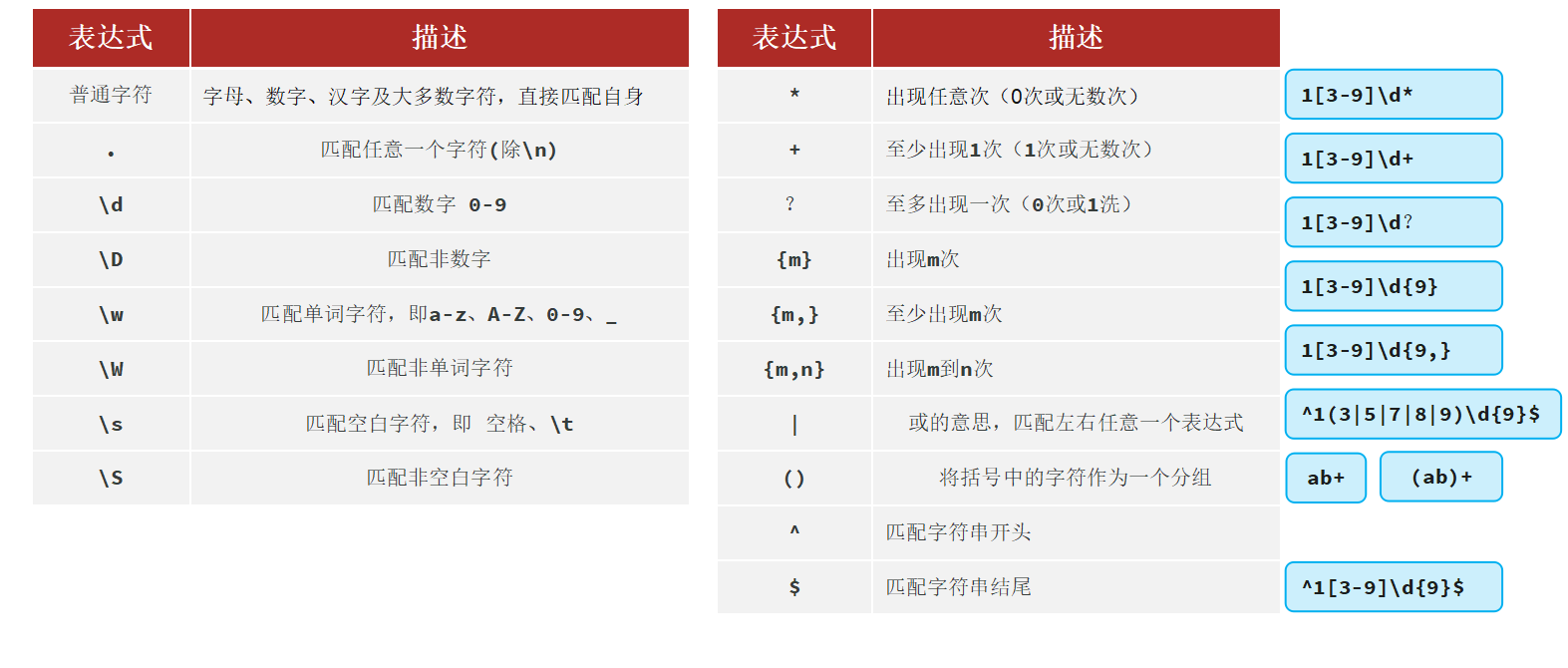
网页解析指的是从原始HTML文档中提取数据的过程,也是网络爬虫的关键步骤,从一堆标签文本中提取出需要的数据。
lxml:是一个高性能的HTML/XML文档的解析库,支持基于Xpath语法来解析和获取网页数据。
安装:
pip install lxml

Xpath:是一种用于在HTML/XML文档中导航或定位元素的查询语言,让你能够准确的定位文档中的特定元素、属性或文本 。
from lxml import html
# 读取html文件
with open("../resource/仙逆人物志.html",'r',encoding='utf-8') as file:
html_text = file.read()
# 解析html文本,将其转化为一个文档对象
document = html.fromstring(html_text)
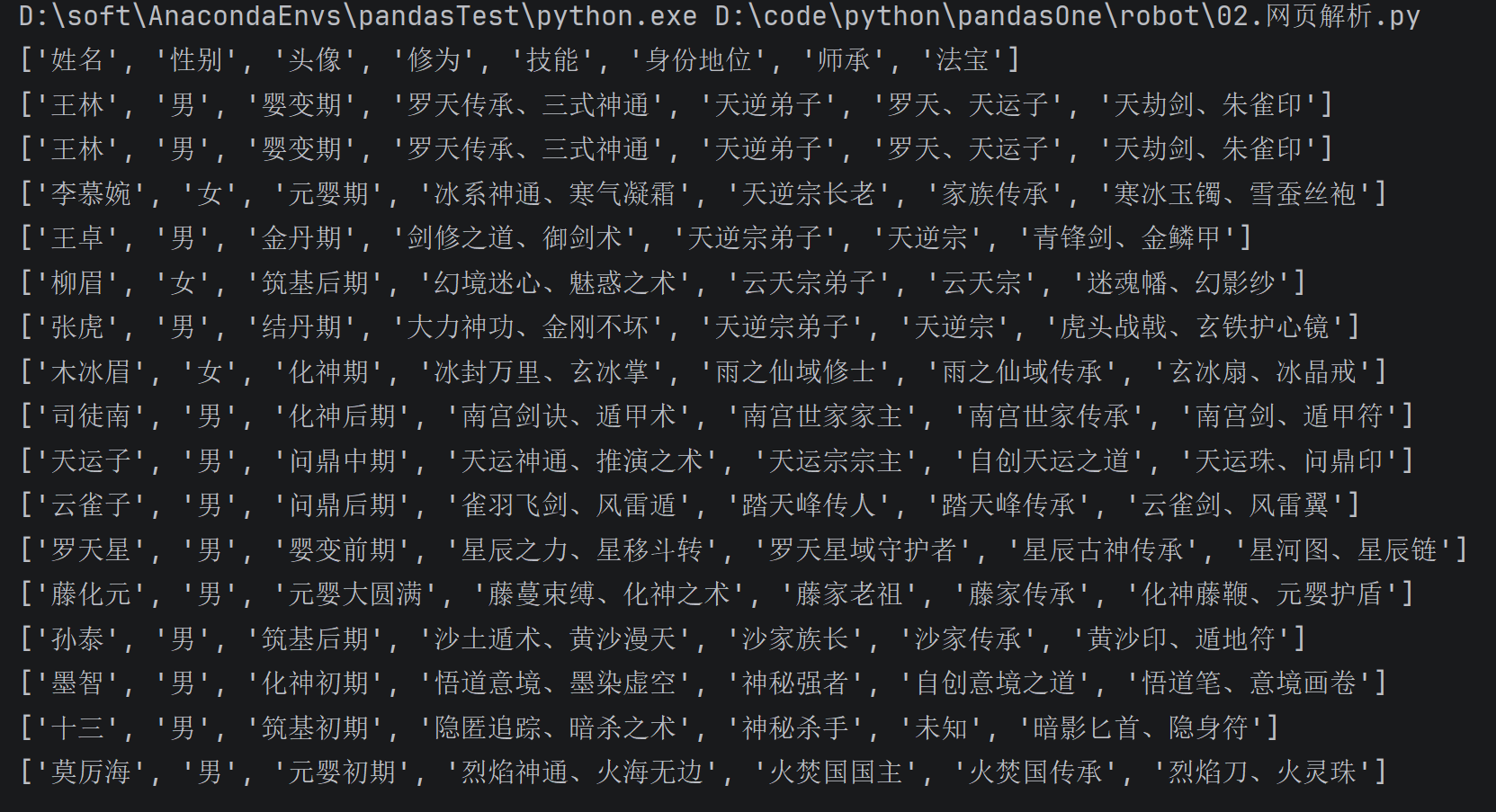
# 解析表头
th_list = document.xpath("//table/thead/tr/th/text()")
print(th_list)
# 解析表格中的数据
td_list = document.xpath("//table/tbody/tr[1]/td/text()")
print(td_list)
# 获取所有行数据
tr_list = document.xpath("//table/tbody/tr")
for tr in tr_list:
td_list = tr.xpath("./td/text()")
print(td_list)
Xpath语法
Xpath:一种在HTML/XML文档中导航或定位元素的查询语言,让你能够准确的定位文档中的特定元素、属性或文本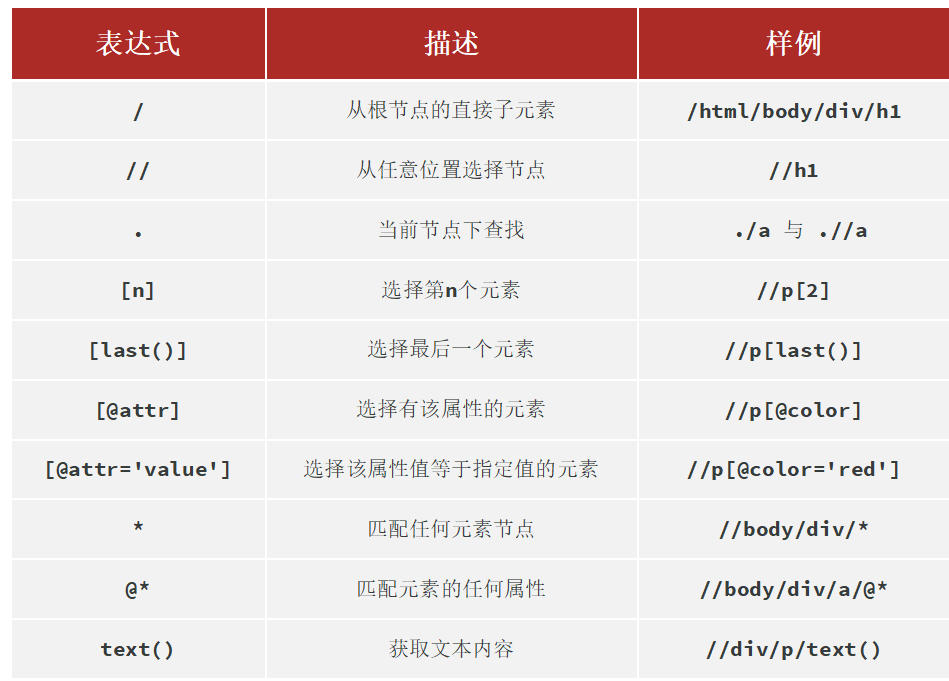
网络机器人案例
csv
CSV:(Comma-Separated Values,逗号分隔值),是一种简单、通用的文本文件格式,用于存储表格数据,可以直接使用Excel打开 。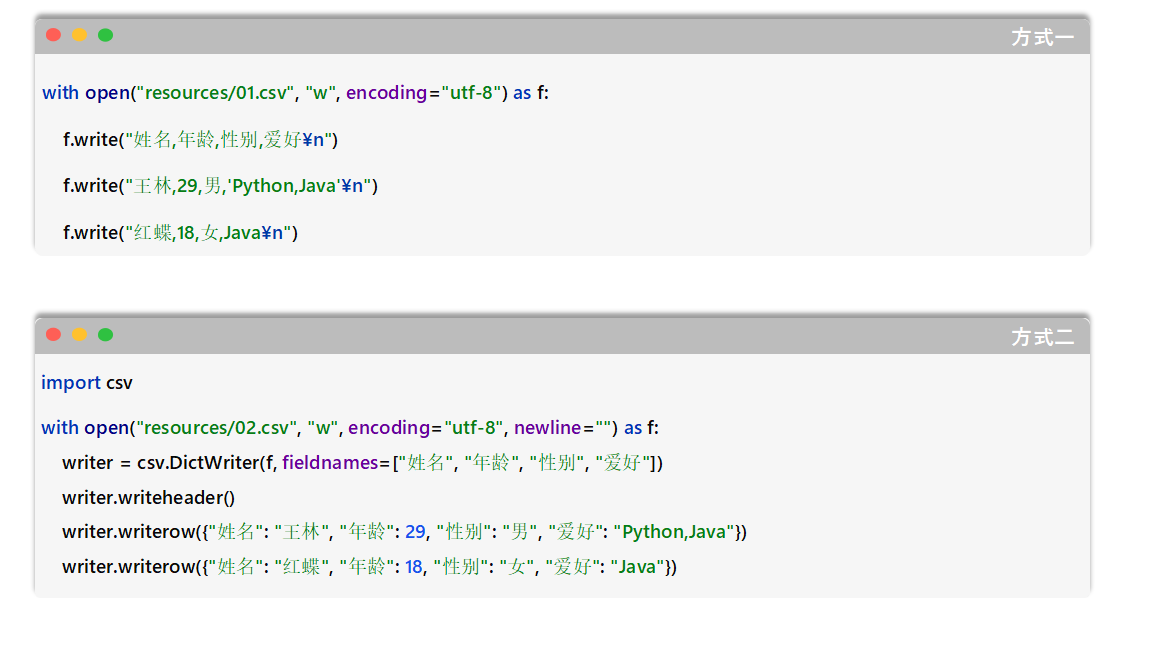
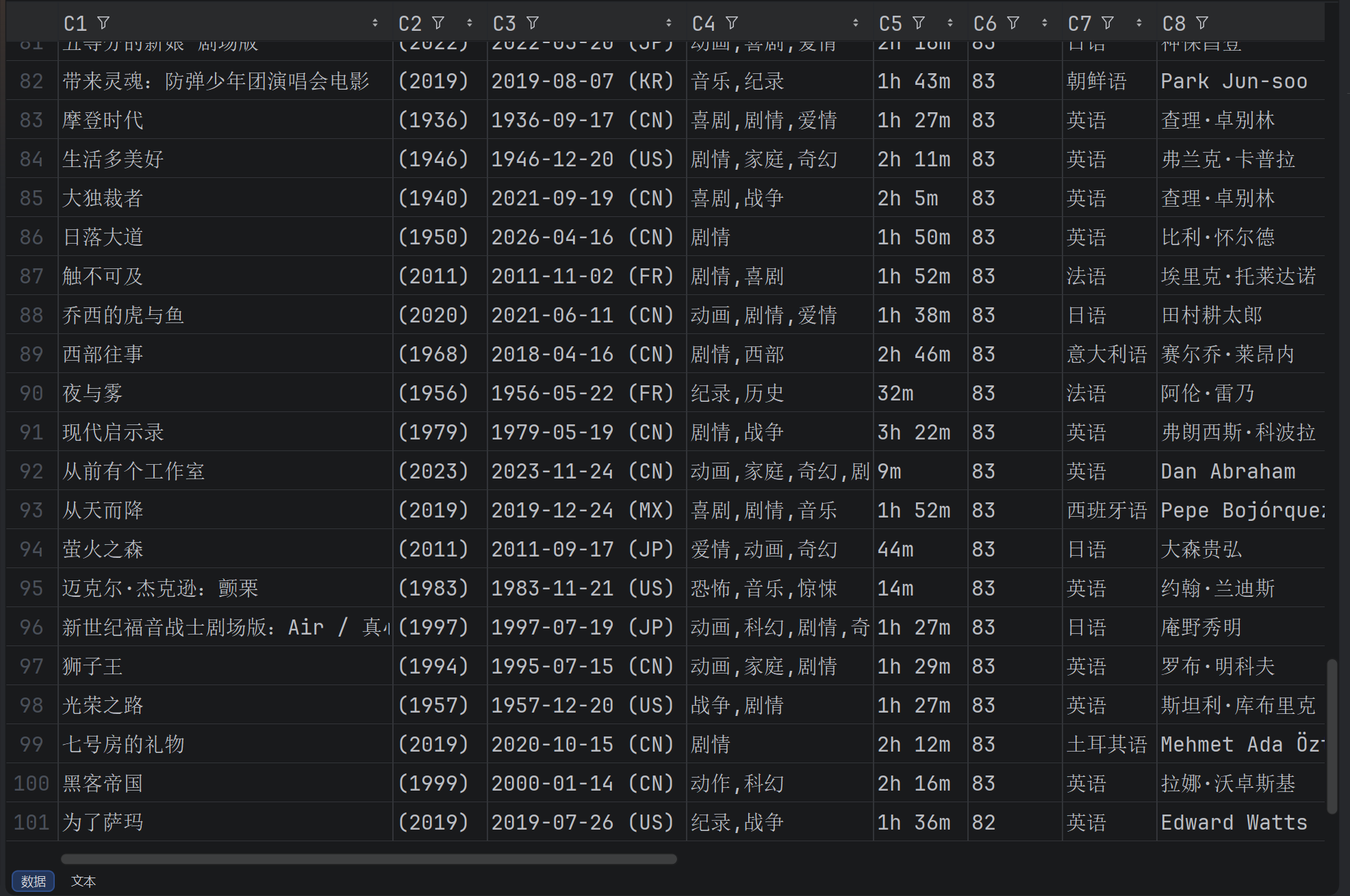
数据包括:电影名、年份、上映时间、类型、时长、评分、语言、导演、作者、主演、Slogan、简介
步骤:
- 明确网站(https://www.themoviedb.org)的robots.txt中的抓取规则
- 查看页面的结构,拆解具体的操作步骤,按步骤开发
- 获取高分电影列表数据
- 遍历电影列表,获取每一部电影的详情信息,并提取电影数据信息
- 将电影详情信息保存到csv文件
import requests
from lxml import html
#常量
TMDB_BASE_URL = 'https://www.themoviedb.org'
TMDB_TOP_URL = 'https://www.themoviedb.org/movie/top-rated'
def get_move_info(movie_info_url):
response = requests.get(movie_info_url,timeout=60)
document = html.fromstring(response.text)
pass
def save_movies(all_movies):
pass
def main():
# 1.发送请求 获取高分电影榜单数据
response = requests.get(TMDB_TOP_URL,timeout=60)
#2.解析数据,获得电影列表
document = html.fromstring(response.text)
movie_list = document.xpath('//*[@class="media-list-results contents"]/div')
all_movies = []
for movie in movie_list:
movie_urls = movie.xpath('.//a[@data-media-type="movie"]/@href')
if movie_urls:
#每个电影详情url地址
movie_info_url = TMDB_BASE_URL + movie_urls[0]
# 发送请求,获取电影详情数据
move_info = get_move_info(movie_info_url)
#4.保存数据
save_movies(all_movies)
pass
if __name__ == '__main__':
main()
主流程(main函数):
-
向TMDB高分电影榜单页面(/movie/top-rated)发送GET请求
-
使用lxml解析HTML,通过XPath定位电影列表容器(class="media-list-results contents"下的所有div)
-
遍历每个电影条目,提取详情页链接(@data-media-type="movie"的a标签的href属性)
-
拼接完整URL后调用get_move_info函数获取该电影的详细信息
-
将获取到的电影信息收集到all_movies列表
-
最后调用save_movies函数保存所有数据
辅助函数:
-
get_move_info(movie_info_url):接收电影详情页URL,发送请求并解析页面,提取所需信息(当前为占位实现)
-
save_movies(all_movies):将爬取到的所有电影数据持久化存储(当前为占位实现)
获取电影详情信息
def get_move_info(movie_info_url):
# 发送请求
response = requests.get(movie_info_url,timeout=60)
# 解析数据
document = html.fromstring(response.text)
# 电影名称
movie_names = document.xpath('//*[@id="original_header"]/div[2]/section/div[1]/h2/a/text()')
movie_years = document.xpath('//*[@id="original_header"]/div[2]/section/div[1]/h2/span/text()')
movie_date = document.xpath('//*[@id="original_header"]/div[2]/section/div[1]/div/span[2]/text()')
movie_tags = document.xpath('//*[@id="original_header"]/div[2]/section/div[1]/div/span[3]/a/text()')
movie_cost_time = document.xpath('//*[@id="original_header"]/div[2]/section/div[1]/div/span[4]/text()')
movie_scores = document.xpath('//*[@id="consensus_pill"]/div/div[1]/div/div/@data-percent')
movie_languages = document.xpath('//*[@id="media_v4"]/div/div/div[2]/div/section/div[1]/div/section[1]/p[3]/text()')
movie_directors = document.xpath('//*[@id="original_header"]/div[2]/section/div[3]/ol/li[1]/p[1]/a/text()')
movie_authors = document.xpath('//*[@id="original_header"]/div[2]/section/div[3]/ol/li[2]/p[1]/a/text()')
movie_solgans = document.xpath('//*[@id="original_header"]/div[2]/section/div[3]/h3[1]/text()')
movie_descriptions = document.xpath('//*[@id="original_header"]/div[2]/section/div[3]/div/p/text()')
#返回电影详情
movie_info = {
'电影名': movie_names[0].strip() if movie_names else '',
'年份': movie_years[0].strip() if movie_years else '',
'上映日期': movie_date[0].strip() if movie_date else '',
'类型': ','.join(movie_tags) if movie_tags else '',
'时长': movie_cost_time[0].strip() if movie_cost_time else '',
'评分': movie_scores[0].strip() if movie_scores else '',
'语言': movie_languages[0].strip() if movie_languages else '',
'导演': ','.join(movie_directors) if movie_directors else '',
'作者': ','.join(movie_authors) if movie_authors else '',
'宣传语': movie_solgans[0].strip() if movie_solgans else '',
'简介': movie_descriptions[0].strip() if movie_descriptions else ''
}
print(movie_info)
return movie_info
向传入的电影详情URL发送HTTP请求,获取页面HTML
使用XPath从HTML中精准提取11个维度的电影数据:
- 基本信息:电影名、年份、上映日期、类型、时长
- 评分与语言:评分百分比、语言
- 人员信息:导演、编剧(作者)
- 宣传内容:宣传语、剧情简介
对每个字段进行安全处理:取第一个匹配结果(或拼接多个结果),去除空白字符,若未找到则返回空字符串
将提取的数据组装成字典结构返回
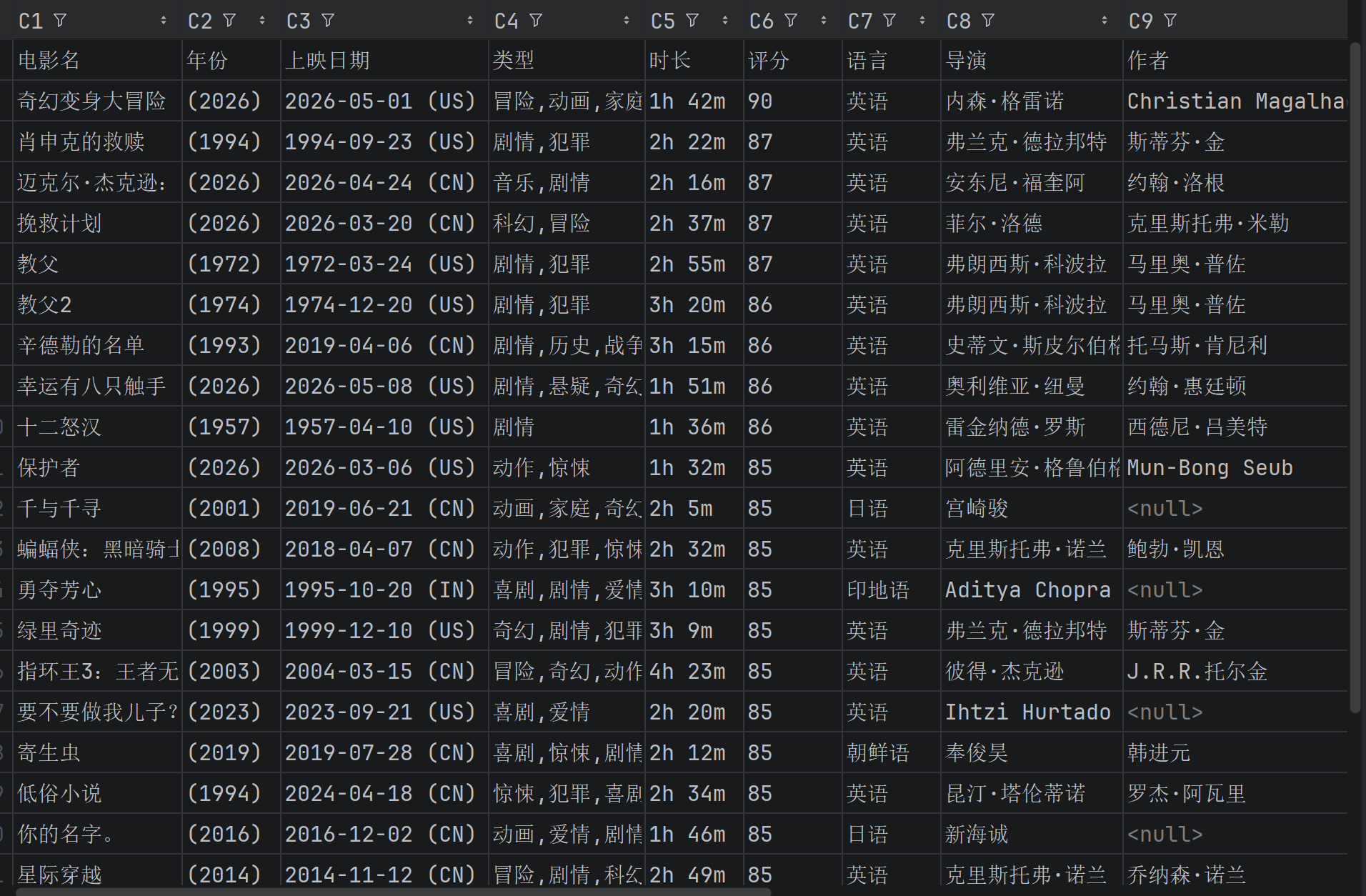
{'电影名': '迈克尔·杰克逊:巨星之路', '年份': '(2026)', '上映日期': '2026-04-24 (CN)', '类型': '音乐,剧情', '时长': '2h 16m', '评分': '87', '语言': '英语', '导演': '安东尼·福奎阿', '作者': '约翰·洛根', '宣传语': 'Discover the making of a king.', '简介': '本片将通过一段从未展现过的深度视角,真实记录传奇巨星迈克尔·杰克逊的复杂人生。影片不仅再现了他最具标志性的艺术表演瞬间,更深入挖掘了他的内心世界——从天才神童的成长阵痛到全球偶像背后的争议与坚韧,全面呈现这位伟大艺术家的辉煌与坎坷。'}
{'电影名': '挽救计划', '年份': '(2026)', '上映日期': '2026-03-20 (CN)', '类型': '科幻,冒险', '时长': '2h 37m', '评分': '87', '语言': '英语', '导演': '菲尔·洛德', '作者': '克里斯托弗·米勒', '宣传语': '信念是暗夜唯一的光', '简介': '太阳正在被“吃”掉,绝望吞噬地球。一名“平凡”的中学教师背负全人类的希望,踏上“太空不归路”。末路孤旅中,他意外遇到一位外星萌友,一个同样身陷绝境的外星工程师,这对“宇宙搭子”成了两个文明最后的救命稻草。他们能否在资源紧缺的情况下攻克重重科学谜 题,寻回唯一的希望火种?'}
{'电影名': '教父', '年份': '(1972)', '上映日期': '1972-03-24 (US)', '类型': '剧情,犯罪', '时长': '2h 55m', '评分': '87', '语言': '英语', '导演': '弗朗西斯·科波拉', '作者': '马里奥·普佐', '宣传语': '一份你无法拒绝的邀约。', '简介': '40年代的美国,“教父”维托·唐·柯里昂是黑手党柯里昂家族的首领,带领家族从事非法的勾当,但同时他也是许多弱小平民的保护神,深得人们爱戴。因为拒绝了毒枭索洛索的毒品交易要求,柯里昂家族和纽约其他几个黑手党家族的矛盾激化、圣诞前夕,索洛索劫持了“教父”的参谋汤姆,并派人暗杀“教父”;因为内奸的出卖,“教父”的大儿子逊尼被仇家杀害;小儿子麦克也被卷了进来,失去爱妻。黑手党家族之间的矛盾越来越白热化。年老的“教父”面对丧子之痛怎样统领全局?黑手党之间的仇杀如何落幕?谁是家族的内奸?谁又能够成为新一代的“教父”?血雨腥风和温情脉脉,在这部里程碑式的黑帮史诗巨片里真实上演。'}
{'电影名': '幸运有八只触手', '年份': '(2026)', '上映日期': '2026-05-08 (US)', '类型': '剧情,悬疑,奇幻', '时长': '1h 54m', '评分': '86', '语言': '英语', '导演': '奥利维亚·纽曼', '作者': '约翰·惠廷顿', '宣传语': 'Brighter together.', '简介': '在这部感人的剧情片中,一名寡妇在小镇的水族馆上夜班时,与一只聪明的章鱼以及一个迷茫的年轻小伙子建立了深厚羁绊。改编自畅销书。'}
{'电影名': '教父2', '年份': '(1974)', '上映日期': '1974-12-20 (US)', '类型': '剧情,犯罪', '时长': '3h 20m', '评分': '86', '语言': '英语', '导演': '弗朗西斯·科波拉', '作者': '马里奥·普佐', '宣传语': '柯里昂帝国的兴衰史。', '简介': '作为《教父》的续篇,影片延续了科莱昂家族两代权力交替的史诗。科波拉在第二部分中讲述了两条故事线:由罗伯特·德尼罗以非凡演技演绎的年轻教父维托的根源与崛起,以及迈克尔(阿尔·帕西诺饰)作为新任教父的上位之路。'}
{'电影名': '辛德勒的名单', '年份': '(1993)', '上映日期': '2019-04-06 (CN)', '类型': '剧情,历史,战争', '时长': '3h 15m', '评分': '86', '语言': '英语', '导演': '史蒂文·斯皮尔伯格', '作者': '托马斯·肯尼利', '宣传语': '谁拯救了一条生命,谁就拯救了整个世界。', '简介': '1939年,波兰在纳粹德国的统治下,党卫军对犹太人进行了隔离统治。德国商人奥斯卡·辛德勒(连姆·尼森 Liam Neeson 饰)来到德军统治下的克拉科夫,开设了一间搪瓷厂,生产军需用品。凭着出众的社交能力和大量的金钱,辛德勒和德军建立了良好的关系,他的工厂雇用犹太人工作,大发战争财。'}
{'电影名': '十二怒汉', '年份': '(1957)', '上映日期': '1957-04-10 (US)', '类型': '剧情', '时长': '1h 36m', '评分': '86', '语言': '英语', '导演': '雷金纳德·罗斯', '作者': '西德尼·吕美特', '宣传语': '命悬其手,死视其意', '简介': '西德尼·吕美特执导的本片堪称电影史上最颠覆的法庭剧。这部改编自雷金纳德·罗斯电视剧的经典之作,以密室内群像戏的精炼笔法,透视美国司法体系的肌理,张力十足。亨利·方达饰演的异议者,在由白人男性组成的陪审团中孤身抗辩——其余成员皆急于裁定被控弑父的波多黎各少年有罪。故事在一个闷热的午后、一间汗流浃背的房间里层层推进,最终凝聚成一部史诗规模的思辨传奇。吕美特这部震撼人心的导演处女作,精准捕捉了1950年代美国社会变革的前夜,成就了影史不朽的首作丰碑。'}
{'电影名': '保护者', '年份': '(2026)', '上映日期': '2026-03-06 (US)', '类型': '动作,惊悚', '时长': '1h 32m', '评分': '85', '语言': '英语', '导演': '阿德里安·格鲁伯格', '作者': 'Mun-Bong Seub', '宣传语': 'Mother. Savior. Killer...', '简介': '退役军人尼基与女儿克洛伊平静生活,却在废弃工厂醒来后发现女儿遭绑架,她必须重返黑暗世界,对抗人贩子、警察与军方,在72小时黄金救援期内救回女儿。'}
{'电影名': '千与千寻', '年份': '(2001)', '上映日期': '2019-06-21 (CN)', '类型': '动画,家庭,奇幻', '时长': '2h 5m', '评分': '85', '语言': '日语', '导演': '宫崎骏', '作者': '', '宣传语': '隧道的另一头,是不可思议的小镇。', '简介': '小女孩千寻被困在一个陌生的精灵世界。当她的父母发生神秘变化后,她必须鼓起自己从未发现的勇气,才能解救自己,并将家人带回外面的世界。'}
{'电影名': '蝙蝠侠:黑暗骑士', '年份': '(2008)', '上映日期': '2018-04-07 (CN)', '类型': '动作,犯罪,惊悚', '时长': '2h 32m', '评分': '85', '语言': '英语', '导演': '克里斯托弗·诺兰', '作者': '鲍勃·凯恩', '宣传语': '黎明前的夜是最黑暗的!', '简介': '蝙蝠侠在打击犯罪的战争中加大了赌注。在吉姆·戈登警长与地方检察官哈维·丹特的协助下,蝙蝠侠决心清除肆虐哥谭街头的残余犯罪组织。这一联手行动卓有成效,但他们很快发现自己沦为了一场混沌统治的猎物——这场混乱由一位新兴犯罪大师所掀动,惶恐的哥谭市民称他为“小丑”。[华纳兄弟影业]'}
{'电影名': '勇夺芳心', '年份': '(1995)', '上映日期': '1995-10-20 (IN)', '类型': '喜剧,剧情,爱情', '时长': '3h 10m', '评分': '85', '语言': '印地语', '导演': 'Aditya Chopra', '作者': '', '宣传语': 'Come… fall In love, all over again…', '简介': '乔德利和妻子结婚多年,一直十分恩爱。两人共同养育了两个女儿希姆莱和图吉,两个姑娘都出落得亭亭玉立。一晃眼,希姆莱就到了该嫁人的年纪了,尽管乔德利一家人已经在伦敦生活了二十多年了,但乔德利骨子里依旧是一个传统的印度人。乔德利将希姆莱许配给了朋友的儿子库杰,这让希姆莱感到十分不满。一次偶然中,希姆莱邂逅了名为拉杰的印度男子,尽管拉杰为人轻浮,油腔滑调,但希姆莱还是同他坠入了情网。得知此事的乔德利举家迁回了印度,拉杰亦紧跟其后,他要如何才能获得乔德利的认可呢?'}
{'电影名': '绿里奇迹', '年份': '(1999)', '上映日期': '1999-12-10 (US)', '类型': '奇幻,剧情,犯罪', '时长': '3h 9m', '评分': '85', '语言': '英语', '导演': '弗兰克·德拉邦特', '作者': '斯蒂芬·金', '宣传语': '保罗·埃奇康姆从不相信奇迹。直到他遇见奇迹的那一天。', '简介': '1935年。美国南部惨淡肃杀的冷山监狱。这里有片一英里长的绿地,人们叫它“绿里”。不过,它的居民皆为死囚,在绿地的另一头,便是行刑用的电椅。保罗·艾治科姆(汤姆·汉 克斯饰)是这里的狱监,对于走过“绿里”、继而在电椅上惨叫毙命的死囚行刑程序,他俨然已无动于衷。除了保罗及其爱妻简外,“绿里”上还有凶残的副狱监豪威尔,有施虐倾向 的狱吏佩西,良心未泯的看守海尔和他身患绝症的妻子美琳达,喜用宠物鼠逗狱吏和诸“难友”取乐的德拉克,连环杀人狂威廉,负疚深重的犯人彼特等一干形形色色的人们。他们之 间充满了敌意和不屑。但神秘的约翰·考夫利的到来改变了一切。考夫利因谋杀两名幼女被 判死罪,他相貌恐怖,体形硕大,却出奇地平和、敏感而缄默,天真时甚至像个孩子,同时, 他似乎还具有一种不可名状的神秘力量,令人不由自主地对其产生信任感,这不禁让艾治科姆对其罪行是否属实深怀疑问。 真情无法取代程式,考夫利终要走过“绿里”。在这个貌似粗鲁的男人即将赴死的刹那,“绿里”上的人们以不同以往的形式实现了各自生命的重要跨越。'}
{'电影名': '指环王3:王者无敌', '年份': '(2003)', '上映日期': '2004-03-15 (CN)', '类型': '冒险,奇幻,动作', '时长': '4h 23m', '评分': '85', '语言': '英语', '导演': '彼得·杰克逊', '作者': 'J.R.R.托尔金', '宣传语': '敌人的邪眼在移动!', '简介': '索伦大军为剿灭人类种族,已对刚铎都城米那斯提力斯展开围攻。这座昔日的伟大王国由一位日渐衰弱的摄政王守护,此刻比任何时候都更需要它的王者归来。但阿拉贡能否回应血脉的召唤,成为命定之君?中土世界的命运,正系于他宽阔的双肩。'}
{'电影名': '要不要做我儿子?', '年份': '(2023)', '上映日期': '2023-09-21 (US)', '类型': '喜剧,爱情', '时长': '2h 20m', '评分': '85', '语言': '英语', '导演': 'Ihtzi Hurtado', '作者': '', '宣传语': '简介', '简介': '四十岁的卢发现相伴十五年的伴侣出轨,生活瞬间崩塌。她在重建自我的过程中,与一位年轻放浪的男子产生了出乎意料的关系。'}
{'电影名': '寄生虫', '年份': '(2019)', '上映日期': '2019-07-28 (CN)', '类型': '喜剧,惊悚,剧情', '时长': '2h 12m', '评分': '85', '语言': '朝鲜语', '导演': '奉俊昊', '作者': '韩进元', '宣传语': '表现得好像这个地方是你的似的。', '简介': '这部定义时代精神的惊世之作,将全球范围内对阶级不平等的审视浓缩为一场流行电影的反叛风暴。奉俊昊导演以这部打破类型桎梏的黑色喜剧惊悚片,奠定了其世界顶尖电影作者的地位。故事聚焦首尔的两个家庭——一户在低洼社区潮湿半地下室里挣扎求生的底层家庭,另一户则居住于可俯瞰城市的现代建筑奇观中尽享奢华。当两家人的命运因危险关系交织在一起时,资本主义的黑暗裂隙以惊人之势被彻底撕裂。影片凭借导演精心构建的戏剧场景、出色的群像演绎与震撼的视觉设计,成为一部技艺卓绝的典范之作。从戛纳到奥斯卡,横扫几乎所有国际至高奖项,更以首部非英语片问鼎最佳影片的历史性突破,宣告韩国新电影已成为不可忽视的世界力量。'}
{'电影名': '低俗小说', '年份': '(1994)', '上映日期': '2024-04-18 (CN)', '类型': '惊悚,犯罪,喜剧', '时长': '2h 34m', '评分': '85', '语言': '英语', '导演': '昆汀·塔伦蒂诺', '作者': '罗杰·阿瓦里', '宣传语': '仅仅因为你是一个角色并不意味着你有角色。', '简介': '由序幕、尾声及三个独立又环环相扣的故事构成。早餐店两名劫匪打劫时,偶遇黑道打手朱尔斯与文森特;文森特奉命陪伴老大马沙的妻子,深陷诱惑困境;拳击手布奇因祖传金表,和马沙结下恩怨。'}
{'电影名': '你的名字。', '年份': '(2016)', '上映日期': '2016-12-02 (CN)', '类型': '动画,爱情,剧情', '时长': '1h 46m', '评分': '85', '语言': '日语', '导演': '新海诚', '作者': '', '宣传语': '我正在寻觅未曾相识的你。', '简介': '彗星降临之夜,两个生命的轨迹就此改变。高中生三叶与泷本是素不相识的陌生人,过着各自的生活。然而某夜,他们突然互换了身体——三叶在泷的身体中醒来,泷则进入了她的人生。这种奇异的现象持续随机发生,两人不得不互相迁就,调整生活节奏。出人意料的是,他们渐渐磨合出默契,通过留言、讯息,更重要的是,通过留在彼此生命中的印记建立起联结。当璀璨的彗星点亮夜空时,他们终于醒悟:渴望从这份羁绊中获得更多——一个真正见面的机会,一次真正了解彼此的相遇。他们牵起命运的丝线,试图寻找通向对方的路。然而阻隔他们的,不仅仅是距离。这份牵绊,是否足以对抗时间残酷的捉弄?抑或他们的相遇,终究只是对星辰许下的愿望?[FUNimation]'}
{'电影名': '星际穿越', '年份': '(2014)', '上映日期': '2014-11-12 (CN)', '类型': '冒险,剧情,科幻', '时长': '2h 49m', '评分': '85', '语言': '英语', '导演': '克里斯托弗·诺兰', '作者': '乔纳森·诺兰', '宣传语': '人类的下一步将迈向非凡!', '简介': '近未来的地球黄沙遍野,小麦、秋葵等基础农作物相继因枯萎病灭绝,人类不再像从前那样仰望星空,放纵想象力和灵感的迸发,而是每日在沙尘暴的肆虐下倒数着所剩不多的光景。在家务农的前NASA宇航员库珀接连在女儿墨菲的书房发现奇怪的重力场现象,随即得知在某个未知区域内前NASA成员仍秘密进行一个拯救人类的计划。多年以前土星附近出现神秘虫洞,NASA借机将数名宇航员派遣到遥远的星系寻找适合居住的星球。在布兰德教授的劝说下,库珀忍痛告别了女儿,和其他三名专家教授女儿艾米莉亚·布兰德、罗米利、多伊尔搭乘宇宙飞船前往目前已知的最有希望的三颗星球考察。他们穿越遥远的星系银河,感受了一小时七年光阴的沧海桑田,窥见了未知星球和黑洞的壮伟与神秘。在浩瀚宇宙的绝望而孤独角落,总有一份超越了时空的笃定情怀将他们紧紧相连……'}
保存电影详情
def save_movies(all_movies):
# 使用csv.DictWriter正确写入CSV文件
with open(MOVE_LIST_FILE, 'w', encoding='utf-8-sig', newline='') as f:
fieldnames = ['电影名', '年份', '上映日期', '类型', '时长', '评分', '语言', '导演', '作者', '宣传语', '简介']
writer = csv.DictWriter(f, fieldnames=fieldnames)
# 写入表头
writer.writeheader()
# 写入数据行
for movie in all_movies:
writer.writerow(movie)
获取分页数据
def main():
all_movies = []
for page_num in range(1,6):
# 1.发送请求 获取高分电影榜单数据
if page_num == 1:
response = requests.get(TMDB_TOP_URL_1, timeout=60)
else:
# POST请求参数
payload = {
'air_date.gte': '',
'air_date.lte': '',
'certification': '',
'certification_country': 'CN',
'debug': '',
'first_air_date.gte': '',
'first_air_date.lte': '',
'include_adult': 'false',
'include_softcore': 'false',
'latest_ceremony.gte': '',
'latest_ceremony.lte': '',
'page': str(page_num),
'primary_release_date.gte': '',
'primary_release_date.lte': '',
'region': '',
'release_date.gte': '',
'release_date.lte': '2026-12-29',
'show_me': 'everything',
'sort_by': 'vote_average.desc',
'vote_average.gte': '0',
'vote_average.lte': '10',
'vote_count.gte': '300',
'watch_region': 'CN',
'with_genres': '',
'with_keywords': '',
'with_networks': '',
'with_origin_country': '',
'with_original_language': '',
'with_watch_monetization_types': '',
'with_watch_providers': '',
'with_release_type': '',
'with_runtime.gte': '0',
'with_runtime.lte': '400'
}
response = requests.post(TMDB_TOP_URL_2, data=payload, timeout=60)
# 2.解析数据,获得电影列表
document = html.fromstring(response.text)
movie_list = document.xpath('//*[@class="media-list-results contents"]/div')
for movie in movie_list:
movie_urls = movie.xpath('.//a[@data-media-type="movie"]/@href')
if movie_urls:
# 每个电影详情url地址
movie_info_url = TMDB_BASE_URL + movie_urls[0]
# 发送请求,获取电影详情数据
move_info = get_move_info(movie_info_url)
all_movies.append(move_info)
#4.保存数据
save_movies(all_movies)
循环遍历的方式获取前5页的电影数据(页码从1到5),每页包含一定数量的电影条目
在POST请求的payload中,‘page’: str(page_num)是核心分页参数:
- 第1页时page=1(但用GET方式)
- 第2页时page=2
- 以此类推,直到第5页
完整代码
import requests
from lxml import html
import csv
#常量
TMDB_BASE_URL = 'https://www.themoviedb.org'
TMDB_TOP_URL_1 = 'https://www.themoviedb.org/movie/top-rated'
TMDB_TOP_URL_2 = 'https://www.themoviedb.org/discover/movie/items'
MOVE_LIST_FILE = '../data/move_list.csv'
def get_move_info(movie_info_url):
# 发送请求
response = requests.get(movie_info_url,timeout=60)
# 解析数据
document = html.fromstring(response.text)
# 电影名称
movie_names = document.xpath('//*[@id="original_header"]/div[2]/section/div[1]/h2/a/text()')
movie_years = document.xpath('//*[@id="original_header"]/div[2]/section/div[1]/h2/span/text()')
movie_date = document.xpath('//*[@id="original_header"]/div[2]/section/div[1]/div/span[@class="release"]/text()')
movie_tags = document.xpath('//*[@id="original_header"]/div[2]/section/div[1]/div/span[@class="genres"]/a/text()')
movie_cost_time = document.xpath('//*[@id="original_header"]/div[2]/section/div[1]/div/span[@class="runtime"]/text()')
movie_scores = document.xpath('//*[@id="consensus_pill"]/div/div[1]/div/div/@data-percent')
movie_languages = document.xpath('//*[@id="media_v4"]/div/div/div[2]/div/section/div[1]/div/section[1]/p[3]/text()')
movie_directors = document.xpath('//*[@id="original_header"]/div[2]/section/div[3]/ol/li[1]/p[1]/a/text()')
movie_authors = document.xpath('//*[@id="original_header"]/div[2]/section/div[3]/ol/li[2]/p[1]/a/text()')
movie_solgans = document.xpath('//*[@id="original_header"]/div[2]/section/div[3]/h3[1]/text()')
movie_descriptions = document.xpath('//*[@id="original_header"]/div[2]/section/div[3]/div/p/text()')
#返回电影详情
movie_info = {
'电影名': movie_names[0].strip() if movie_names else '',
'年份': movie_years[0].strip() if movie_years else '',
'上映日期': movie_date[0].strip() if movie_date else '',
'类型': ','.join(movie_tags) if movie_tags else '',
'时长': movie_cost_time[0].strip() if movie_cost_time else '',
'评分': movie_scores[0].strip() if movie_scores else '',
'语言': movie_languages[0].strip() if movie_languages else '',
'导演': ','.join(movie_directors) if movie_directors else '',
'作者': ','.join(movie_authors) if movie_authors else '',
'宣传语': movie_solgans[0].strip() if movie_solgans else '',
'简介': movie_descriptions[0].strip() if movie_descriptions else ''
}
print(movie_info)
return movie_info
def save_movies(all_movies):
# 使用csv.DictWriter正确写入CSV文件
with open(MOVE_LIST_FILE, 'w', encoding='utf-8-sig', newline='') as f:
fieldnames = ['电影名', '年份', '上映日期', '类型', '时长', '评分', '语言', '导演', '作者', '宣传语', '简介']
writer = csv.DictWriter(f, fieldnames=fieldnames)
# 写入表头
writer.writeheader()
# 写入数据行
for movie in all_movies:
writer.writerow(movie)
def main():
all_movies = []
for page_num in range(1,6):
# 1.发送请求 获取高分电影榜单数据
if page_num == 1:
response = requests.get(TMDB_TOP_URL_1, timeout=60)
else:
# POST请求参数
payload = {
'air_date.gte': '',
'air_date.lte': '',
'certification': '',
'certification_country': 'CN',
'debug': '',
'first_air_date.gte': '',
'first_air_date.lte': '',
'include_adult': 'false',
'include_softcore': 'false',
'latest_ceremony.gte': '',
'latest_ceremony.lte': '',
'page': str(page_num),
'primary_release_date.gte': '',
'primary_release_date.lte': '',
'region': '',
'release_date.gte': '',
'release_date.lte': '2026-12-29',
'show_me': 'everything',
'sort_by': 'vote_average.desc',
'vote_average.gte': '0',
'vote_average.lte': '10',
'vote_count.gte': '300',
'watch_region': 'CN',
'with_genres': '',
'with_keywords': '',
'with_networks': '',
'with_origin_country': '',
'with_original_language': '',
'with_watch_monetization_types': '',
'with_watch_providers': '',
'with_release_type': '',
'with_runtime.gte': '0',
'with_runtime.lte': '400'
}
response = requests.post(TMDB_TOP_URL_2, data=payload, timeout=60)
# 2.解析数据,获得电影列表
document = html.fromstring(response.text)
movie_list = document.xpath('//*[@class="media-list-results contents"]/div')
for movie in movie_list:
movie_urls = movie.xpath('.//a[@data-media-type="movie"]/@href')
if movie_urls:
# 每个电影详情url地址
movie_info_url = TMDB_BASE_URL + movie_urls[0]
# 发送请求,获取电影详情数据
move_info = get_move_info(movie_info_url)
all_movies.append(move_info)
#4.保存数据
save_movies(all_movies)
if __name__ == '__main__':
main()
总结
你可以基于本案例继续探索:
-
爬取电影详情页的更多字段(演员、剧情简介、预告片等)
-
增加动态页数判断(获取总页数后自动遍历)
-
使用代理IP池应对更严格的网站
-
将数据存入数据库(MySQL、MongoDB等)
-
结合数据分析库(pandas)进行可视化分析
更多推荐
 13
13 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)