
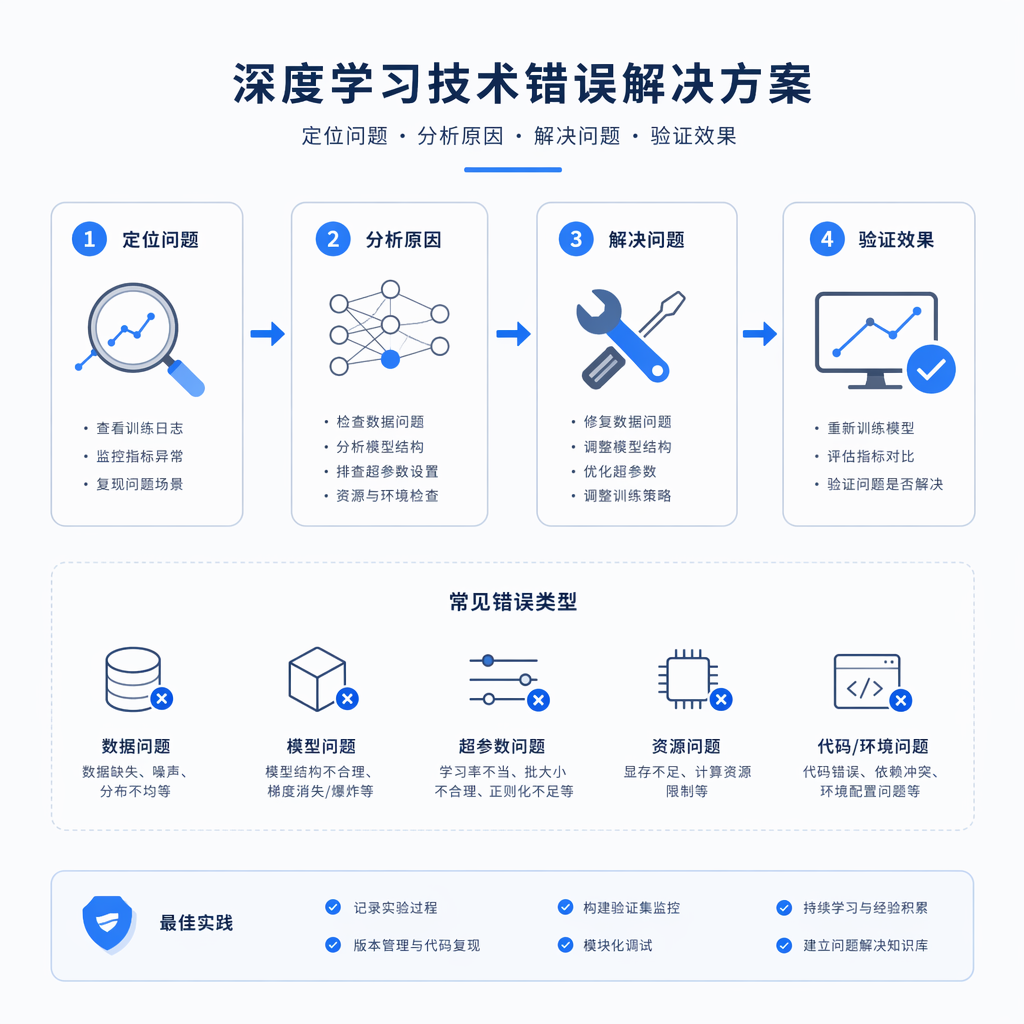
小白也能看懂的推理加速框架:vLLM、TGI与Continuous Batching
系列文章:AI大模型知识体系 | 第三周·第四篇
引言:HuggingFace 原生推理,为什么慢得让人抓狂?
上一篇我们聊了知识蒸馏——把大模型的"功力"压缩到小模型里,让推理更快更省。但如果你手头就是得用大模型呢?总不能每次都蒸馏一个小的出来吧?
这时候你可能会想:直接用 HuggingFace 的 pipeline 或者 generate() 跑不就行了?
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-hf", device_map="auto")
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-hf")
inputs = tokenizer("你好,请介绍一下你自己", return_tensors="pt").to("cuda")
outputs = model.generate(**inputs, max_new_tokens=200)
print(tokenizer.decode(outputs[0]))跑是能跑,但问题来了:
-
并发能力几乎为零:来 10 个用户同时请求,GPU 利用率可能还不到 30%
-
显存浪费严重:KV Cache 按最大长度预分配,短请求白白占着显存不干活
-
吞吐量感人:同样一张 A100,原生推理可能每秒只处理几个请求,而优化后的框架能处理几十个
打个比方:HuggingFace 原生推理就像一个人在 100 平米的办公室里,只用一张桌子办公,剩下的 99 平米全空着——资源浪费到令人心疼。
所以,我们需要专业的推理加速框架。今天就来聊聊三个核心话题:Continuous Batching、PagedAttention,以及基于它们构建的 vLLM 和 TGI。
一、Continuous Batching:餐厅上菜的智慧
1.1 先看 Static Batching 有多蠢
假设你开了一家餐厅,有 4 张桌子。最笨的上菜方式是什么?
等 4 桌客人都点完菜,一起做,一起上,最后一桌吃完了才能翻台。
这就是 Static Batching(静态批处理) 的逻辑:凑够一批请求,一起送进模型,等所有请求都生成完毕,再处理下一批。
Static Batching 时间线:
时间 ──────────────────────────────────────────────►
请求A: [生成50字] ████████░░░░░░░░░░░░ ← 做完了,干等...
请求B: [生成200字]████████████████████ ← 最慢的,决定整批结束时间
请求C: [生成30字] ██████░░░░░░░░░░░░░░ ← 更早做完,更早干等...
请求D: [生成150字]████████████████░░░░ ← 也在等...
GPU利用率: ████████░░░░░░░░░░░░░░░░░░ ← 大量时间在空转!问题很明显:短请求被长请求拖累,GPU 大量时间在"等人"。
1.2 Continuous Batching:吃完就走,来了就坐
聪明的餐厅怎么运营?吃完一桌立刻翻台,新客人来了随时入座。
Continuous Batching(连续批处理) 就是这个思路:每生成一个 Token 后,检查一下——谁生成完了就立刻送走,新来的请求立刻插进来,GPU 始终满载运转。
Continuous Batching 时间线:
时间 ──────────────────────────────────────────────►
请求A: [50字] ████████ → 完成!
请求B: [200字]████████████████████
请求C: [30字] ██████ → 完成!请求E立刻补上 ████████ → 完成!请求G ████
请求D: [150字]████████████████ → 完成!请求F立刻补上 ██████████
GPU利用率: ████████████████████████████ ← 几乎始终满载!1.3 代码对比:感受差异
用 HuggingFace 原生方式做批处理(Static Batching):
# Static Batching:等所有请求都生成完才返回
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-hf", device_map="auto")
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-hf")
prompts = ["写一首诗", "解释量子力学", "推荐三本书", "讲个笑话"]
inputs = tokenizer(prompts, return_tensors="pt", padding=True).to("cuda")
# 所有请求一起送进去,一起等最慢的那个
outputs = model.generate(**inputs, max_new_tokens=200)
# 短请求生成完了也得等长请求,GPU 白白空转而 Continuous Batching 的实现(vLLM 内部自动处理):
# Continuous Batching:vLLM 自动管理,请求完成即返回
from vllm import LLM, SamplingParams
llm = LLM(model="meta-llama/Llama-2-7b-hf")
sampling_params = SamplingParams(max_tokens=200)
prompts = ["写一首诗", "解释量子力学", "推荐三本书", "讲个笑话"]
outputs = llm.generate(prompts, sampling_params)
# 每个请求生成完就返回,新请求随时插入,GPU 始终满载1.4 性能提升有多大?
|
指标 |
Static Batching |
Continuous Batching |
|---|---|---|
|
GPU 利用率 |
30%~60% |
80%~95% |
|
吞吐量(tokens/s) |
基线 |
2~4 倍提升 |
|
请求延迟(P99) |
受最慢请求拖累 |
各请求独立返回 |
|
实现复杂度 |
简单 |
需要框架支持 |
Continuous Batching 是现代推理框架的标配功能,没有它,高并发服务根本无从谈起。
二、PagedAttention:vLLM 的杀手锏
2.1 KV Cache 的显存浪费问题
在第一周我们聊过 KV Cache——它就像"草稿纸",缓存已计算的 Key 和 Value,避免重复计算。但传统 KV Cache 有一个致命问题:显存浪费。
想象你住酒店:
-
传统方式:前台给你分配一个固定大小的房间,按你"可能住的最长时间"来分配。你说"我最多住 7 天",前台就给你留 7 天的房。结果你 2 天就走了,剩下 5 天的房间空着,别人也住不了。
-
PagedAttention 方式:前台按天给你分配房间,住一天给一天,走的那天立刻回收。房间利用率拉满。
传统 KV Cache 的问题一模一样:按最大序列长度预分配显存,短序列用不完的部分白白浪费。实测中,传统方式的显存浪费率高达 60%~80%!
2.2 PagedAttention:像操作系统管理虚拟内存一样管理 KV Cache
PagedAttention 的灵感来自操作系统的虚拟内存分页机制。
操作系统不会给每个进程分配一整块连续的物理内存,而是把内存切成固定大小的页(Page),按需分配、按需回收。进程看到的是连续的虚拟地址,实际物理内存可以是不连续的。
PagedAttention 做了同样的事:
传统 KV Cache(连续预分配):
┌──────────────────────────────────────────────────┐
│ 请求A: [已用██][已用██][已用██][ 空 ][ 空 ][ 空 ] │ ← 浪费50%
│ 请求B: [已用██][ 空 ][ 空 ][ 空 ][ 空 ][ 空 ] │ ← 浪费83%
│ 请求C: [已用██][已用██][已用██][已用██][已用██][ 空 ] │ ← 浪费17%
└──────────────────────────────────────────────────┘
→ 无法共享空闲块,总浪费率约 60%~80%
PagedAttention(分页管理):
┌────┬────┬────┬────┬────┬────┬────┬────┐
│ A1 │ A2 │ A3 │ B1 │ C1 │ C2 │ C3 │ C4 │ ← 物理块(Block)
└────┴────┴────┴────┴────┴────┴────┴────┘
↑ ↑ ↑ ↑
请求A的页表 请求B 请求C的页表 需要时再分配
虚拟 → 物理映射(Page Table):
请求A: [Block 0] → [Block 1] → [Block 2] → (需要时再分配)
请求B: [Block 3] → (需要时再分配)
请求C: [Block 4] → [Block 5] → [Block 6] → [Block 7] → (需要时再分配)2.3 PagedAttention 的三大好处
-
显存利用率接近 100%:不再预分配整块空间,用多少占多少,几乎没有浪费
-
支持更大的批处理:同样的显存,能同时服务更多请求
-
支持 Prefix Caching(前缀缓存):多个请求共享相同前缀时(比如相同的 System Prompt),前缀的 KV Cache 只存一份,其他请求通过页表指向它即可
Prefix Caching 示例:
System Prompt: "你是一个有用的AI助手..."(共享前缀)
请求A: [共享前缀 Block] → [A 的专属 Block 1] → [A 的专属 Block 2]
请求B: [共享前缀 Block] → [B 的专属 Block 1]
请求C: [共享前缀 Block] → [C 的专属 Block 1] → [C 的专属 Block 2]
→ System Prompt 的 KV Cache 只算一份,省下大量显存!三、vLLM 详解:推理框架界的"卷王"
3.1 vLLM 是什么?
vLLM 是 UC Berkeley 团队开发的高性能大模型推理引擎,2023 年开源后迅速成为社区最流行的推理框架。它的核心卖点就一个字:快。
vLLM 的架构可以简化为:
┌─────────────────────────────────┐
│ vLLM Engine │
│ │
请求 ──► ┌───────┴───────┐ ┌──────────────┐ │
│ Scheduler │──►│ Model Runner │ │
│ (调度器) │ │ (模型执行器) │ │
└───────┬───────┘ └──────┬───────┘ │
│ │ │
┌───────▼───────┐ ┌──────▼───────┐ │
│ Block Manager │ │ GPU Workers │ │
│ (显存块管理器) │ │ (GPU 执行) │ │
└───────────────┘ └──────────────┘ │
│ │
┌───────▼───────┐ │
│ KV Cache │ │
│ Pool (显存池) │ │
└───────────────┘ │
└─────────────────────────────────┘3.2 vLLM 核心特性
|
特性 |
说明 |
|---|---|
|
PagedAttention |
分页管理 KV Cache,显存利用率接近 100% |
|
Continuous Batching |
请求完成即释放,新请求即时插入 |
|
Prefix Caching |
共享前缀的 KV Cache 只存一份 |
|
Speculative Decoding |
支持投机解码加速(v0.4+) |
|
多卡并行 |
支持张量并行(Tensor Parallelism)和流水线并行 |
|
量化支持 |
支持 GPTQ、AWQ、FP8 等多种量化格式 |
|
OpenAI 兼容 API |
自带服务器,接口与 OpenAI API 完全兼容 |
3.3 用 vLLM 跑推理:简单到离谱
离线批量推理:
from vllm import LLM, SamplingParams
# 初始化模型
llm = LLM(
model="Qwen/Qwen2.5-7B-Instruct",
tensor_parallel_size=1, # GPU 数量
gpu_memory_utilization=0.9, # 显存利用率(默认 0.9)
max_model_len=4096, # 最大上下文长度
)
# 设置采样参数
sampling_params = SamplingParams(
temperature=0.7,
top_p=0.9,
max_tokens=512,
)
# 批量推理
prompts = [
"请用一句话解释什么是机器学习",
"写一首关于春天的五言绝句",
"Python中list和tuple的区别是什么",
]
outputs = llm.generate(prompts, sampling_params)
for output in outputs:
print(f"Prompt: {output.prompt}")
print(f"Response: {output.outputs[0].text}")
print("---")启动 OpenAI 兼容的 API 服务:
# 一行命令启动服务
python -m vllm.entrypoints.openai.api_server \
--model Qwen/Qwen2.5-7B-Instruct \
--host 0.0.0.0 \
--port 8000 \
--tensor-parallel-size 1 \
--gpu-memory-utilization 0.9然后用任何 OpenAI SDK 都能调用:
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:8000/v1",
api_key="not-needed", # vLLM 不需要真实 key
)
response = client.chat.completions.create(
model="Qwen/Qwen2.5-7B-Instruct",
messages=[
{"role": "user", "content": "用Python写一个快速排序"}
],
temperature=0.7,
max_tokens=512,
)
print(response.choices[0].message.content)3.4 vLLM 的性能表现
根据 vLLM 论文数据,与 HuggingFace 原生推理相比:
|
场景 |
HuggingFace |
vLLM |
提升 |
|---|---|---|---|
|
LLaMA-13B 吞吐量 |
2.4 tokens/s |
11.2 tokens/s |
4.7x |
|
显存利用率 |
~40% |
~95% |
2.4x |
|
并发请求数(同显存) |
~10 |
~40 |
4x |
四、TGI:HuggingFace 官方的推理引擎
4.1 TGI 是什么?
TGI(Text Generation Inference) 是 HuggingFace 官方推出的推理服务框架。如果说 vLLM 是"学术界的卷王",那 TGI 就是"官方出品、必属精品"。
TGI 的核心优势在于与 HuggingFace 生态的深度整合——模型仓库、Tokenizer、量化格式,全部无缝衔接。
4.2 TGI 核心特性
|
特性 |
说明 |
|---|---|
|
Continuous Batching |
与 vLLM 类似的动态批处理 |
|
Flash Attention |
内置 Flash Attention 2 加速 |
|
量化支持 |
支持 bitsandbytes、GPTQ、AWQ、EETQ |
|
水印机制 |
支持 Watermarking,可检测生成内容是否来自你的模型 |
|
Token 流式输出 |
Server-Sent Events(SSE)流式返回 |
|
多卡张量并行 |
基于 safetensors 的快速加载 |
|
HuggingFace 生态 |
直接从 Hub 拉模型,零配置 |
4.3 用 TGI 启动服务
# 用 Docker 一键启动(推荐方式)
docker run --gpus all -p 8080:80 \
-v $PWD/data:/data \
ghcr.io/huggingface/text-generation-inference:latest \
--model-id Qwen/Qwen2.5-7B-Instruct \
--num-shard 1 \
--max-input-length 2048 \
--max-total-tokens 4096调用方式:
import requests
response = requests.post(
"http://localhost:8080/generate",
json={
"inputs": "请解释什么是深度学习",
"parameters": {
"max_new_tokens": 200,
"temperature": 0.7,
"top_p": 0.9,
}
}
)
print(response.json()["generated_text"])4.4 vLLM vs TGI:怎么选?
|
维度 |
vLLM |
TGI |
|---|---|---|
|
开发方 |
UC Berkeley |
HuggingFace |
|
核心创新 |
PagedAttention |
Flash Attention + 生态整合 |
|
显存管理 |
更优(PagedAttention) |
较好(传统方式优化) |
|
吞吐量 |
更高(同等条件下) |
略低 |
|
部署方式 |
pip install / Docker |
Docker(推荐) |
|
模型兼容 |
主流模型广泛支持 |
HuggingFace 模型无缝支持 |
|
API 风格 |
OpenAI 兼容 |
自有 API + OpenAI 兼容 |
|
社区活跃度 |
非常高 |
高 |
|
适合场景 |
追求极致吞吐的在线服务 |
HuggingFace 生态用户、快速部署 |
简单建议:追求性能选 vLLM,追求省心选 TGI。两者都是成熟方案,差距没有想象中大。
五、其他推理框架速览
5.1 TensorRT-LLM(NVIDIA)
NVIDIA 出品的推理框架,在 NVIDIA GPU 上能榨干每一滴性能。
-
核心优势:深度 CUDA 优化、Kernel Fusion(算子融合)、FP8 量化、In-flight Batching
-
缺点:部署复杂,需要编译模型引擎(build 过程可能要几十分钟),对非 NVIDIA 硬件不友好
-
适合场景:大规模生产环境,追求极致吞吐,有专业运维团队
# TensorRT-LLM 模型编译(简化示例)
python convert_llama.py --model-dir meta-llama/Llama-2-7b-hf \
--output-dir ./llama_trt \
--dtype float16
trtllm-build --model-dir ./llama_trt \
--output-dir ./llama_engine \
--gemm_plugin float165.2 LMDeploy(InternLM 团队)
上海 AI Lab(InternLM 团队)出品的推理框架,对国产 GPU 和消费级显卡友好。
-
核心优势:Turbomind 引擎、W4A16 量化、支持 KV Cache 量化、多模态推理
-
缺点:社区规模不如 vLLM,模型支持范围略窄
-
适合场景:国产 GPU 环境、消费级显卡部署、InternLM 系列模型
from lmdeploy import pipeline, TurbomindEngineConfig
# 使用 4bit 量化部署
pipe = pipeline("internlm/internlm2_5-7b-chat-w4a16",
backend_config=TurbomindEngineConfig(model_format="awq"))
response = pipe("你好,请介绍一下你自己")
print(response.text)六、推理框架全面对比
|
特性 |
vLLM |
TGI |
TensorRT-LLM |
LMDeploy |
|---|---|---|---|---|
|
开发方 |
UC Berkeley |
HuggingFace |
NVIDIA |
上海 AI Lab |
|
核心加速 |
PagedAttention |
Flash Attention |
Kernel Fusion |
Turbomind |
|
Continuous Batching |
✅ |
✅ |
✅(In-flight) |
✅ |
|
Prefix Caching |
✅ |
✅ |
✅ |
✅ |
|
投机解码 |
✅ |
✅ |
✅ |
✅ |
|
量化格式 |
GPTQ/AWQ/FP8 |
GPTQ/AWQ/bitsandbytes |
INT4/INT8/FP8/SmoothQuant |
W4A16/AWQ/KV量化 |
|
多卡并行 |
✅ TP/PP |
✅ TP |
✅ TP/PP |
✅ TP |
|
多模态 |
✅(v0.5+) |
✅ |
✅ |
✅ |
|
部署难度 |
⭐⭐ |
⭐⭐ |
⭐⭐⭐⭐ |
⭐⭐⭐ |
|
吞吐性能 |
⭐⭐⭐⭐⭐ |
⭐⭐⭐⭐ |
⭐⭐⭐⭐⭐ |
⭐⭐⭐⭐ |
|
生态兼容 |
广泛 |
HuggingFace 无缝 |
NVIDIA 专属 |
InternLM 优先 |
|
推荐场景 |
通用在线服务 |
HF 生态快速部署 |
大规模生产 |
国产GPU/消费级 |
七、实操:用 vLLM 部署一个模型服务
下面我们用 vLLM 从零部署一个完整的模型 API 服务,包含安装、启动、测试全流程。
7.1 安装 vLLM
# 创建虚拟环境
conda create -n vllm python=3.10 -y
conda activate vllm
# 安装 vLLM(CUDA 12.1+)
pip install vllm7.2 启动 API 服务
python -m vllm.entrypoints.openai.api_server \
--model Qwen/Qwen2.5-7B-Instruct \
--served-model-name my-qwen \
--host 0.0.0.0 \
--port 8000 \
--tensor-parallel-size 1 \
--gpu-memory-utilization 0.9 \
--max-model-len 4096 \
--enable-prefix-caching关键参数说明:
|
参数 |
说明 |
|---|---|
|
|
HuggingFace 模型 ID 或本地路径 |
|
|
API 中使用的模型名称 |
|
|
使用的 GPU 数量 |
|
|
GPU 显存利用率(0~1,建议 0.85~0.95) |
|
|
最大上下文长度 |
|
|
开启前缀缓存(推荐) |
7.3 测试服务
from openai import OpenAI
import time
client = OpenAI(
base_url="http://localhost:8000/v1",
api_key="not-needed",
)
# 测试单轮对话
start = time.time()
response = client.chat.completions.create(
model="my-qwen",
messages=[
{"role": "system", "content": "你是一个有帮助的AI助手。"},
{"role": "user", "content": "用Python实现二分查找"}
],
temperature=0.7,
max_tokens=512,
)
elapsed = time.time() - start
print(f"回复内容:\n{response.choices[0].message.content}")
print(f"\n耗时: {elapsed:.2f}s")
print(f"Token数: {response.usage.completion_tokens}")
print(f"速度: {response.usage.completion_tokens / elapsed:.1f} tokens/s")7.4 并发压测
import asyncio
from openai import AsyncOpenAI
async def send_request(client, prompt, request_id):
start = time.time()
response = await client.chat.completions.create(
model="my-qwen",
messages=[{"role": "user", "content": prompt}],
max_tokens=100,
)
elapsed = time.time() - start
tokens = response.usage.completion_tokens
print(f"请求#{request_id}: {tokens} tokens, {elapsed:.2f}s, {tokens/elapsed:.1f} tokens/s")
async def main():
client = AsyncOpenAI(base_url="http://localhost:8000/v1", api_key="not-needed")
prompts = [f"请用一句话解释什么是{topic}" for topic in
["机器学习", "深度学习", "自然语言处理", "计算机视觉", "强化学习",
"迁移学习", "生成对抗网络", "注意力机制", "词嵌入", "批归一化"]]
start = time.time()
tasks = [send_request(client, p, i) for i, p in enumerate(prompts)]
await asyncio.gather(*tasks)
total_time = time.time() - start
print(f"\n总耗时: {total_time:.2f}s")
print(f"总请求数: {len(prompts)}")
print(f"平均每请求: {total_time/len(prompts):.2f}s")
asyncio.run(main())跑一下这个压测,你会真切感受到 Continuous Batching 的威力——10 个并发请求几乎和 1 个请求一样快!
八、总结
今天我们从"餐厅上菜"聊到"虚拟内存管理",把推理加速框架的核心技术拆了个遍:
-
Continuous Batching:像餐厅翻台一样,做完就走、来了就坐,GPU 始终满载,吞吐量提升 2~4 倍
-
PagedAttention:像操作系统管理内存一样管理 KV Cache,显存利用率从 40% 飙到 95%,同样显存能服务 4 倍的请求
-
vLLM:PagedAttention 的发明者,推理框架界的性能卷王,OpenAI 兼容 API 开箱即用
-
TGI:HuggingFace 官方出品,生态整合无敌,Docker 一键部署
-
TensorRT-LLM:NVIDIA 亲儿子,性能天花板,但部署门槛也最高
-
LMDeploy:国产之光,对消费级显卡和国产 GPU 友好
选型一句话:通用场景选 vLLM,HF 生态选 TGI,极致性能选 TensorRT-LLM,国产 GPU 选 LMDeploy。
这些框架的共同目标只有一个:让大模型推理又快又省,让一张 GPU 顶过去好几张。
下篇预告
框架选好了,接下来就是真刀真枪地部署。下一篇我们将进入本地部署实战——从环境搭建到模型下载,从单卡部署到多卡并行,手把手带你把一个大模型跑起来。不再只是看代码,而是自己动手跑起来!

免费领 150 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐
 10
10 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)