
旧安卓手机部署openclaw
·
- 安卓版本6.0.1
- 8核 6+64G
2.下载termux工具(可以用笔记本提前下载好,传给手机)
- 安卓上最经典、最强大的Linux环境模拟器,社区资源极其丰富
- github下载地址,可以选择对应的安卓版本的安装包,universal.apk 是通用的包,推荐安装
https://github.com/termux/termux-app/releases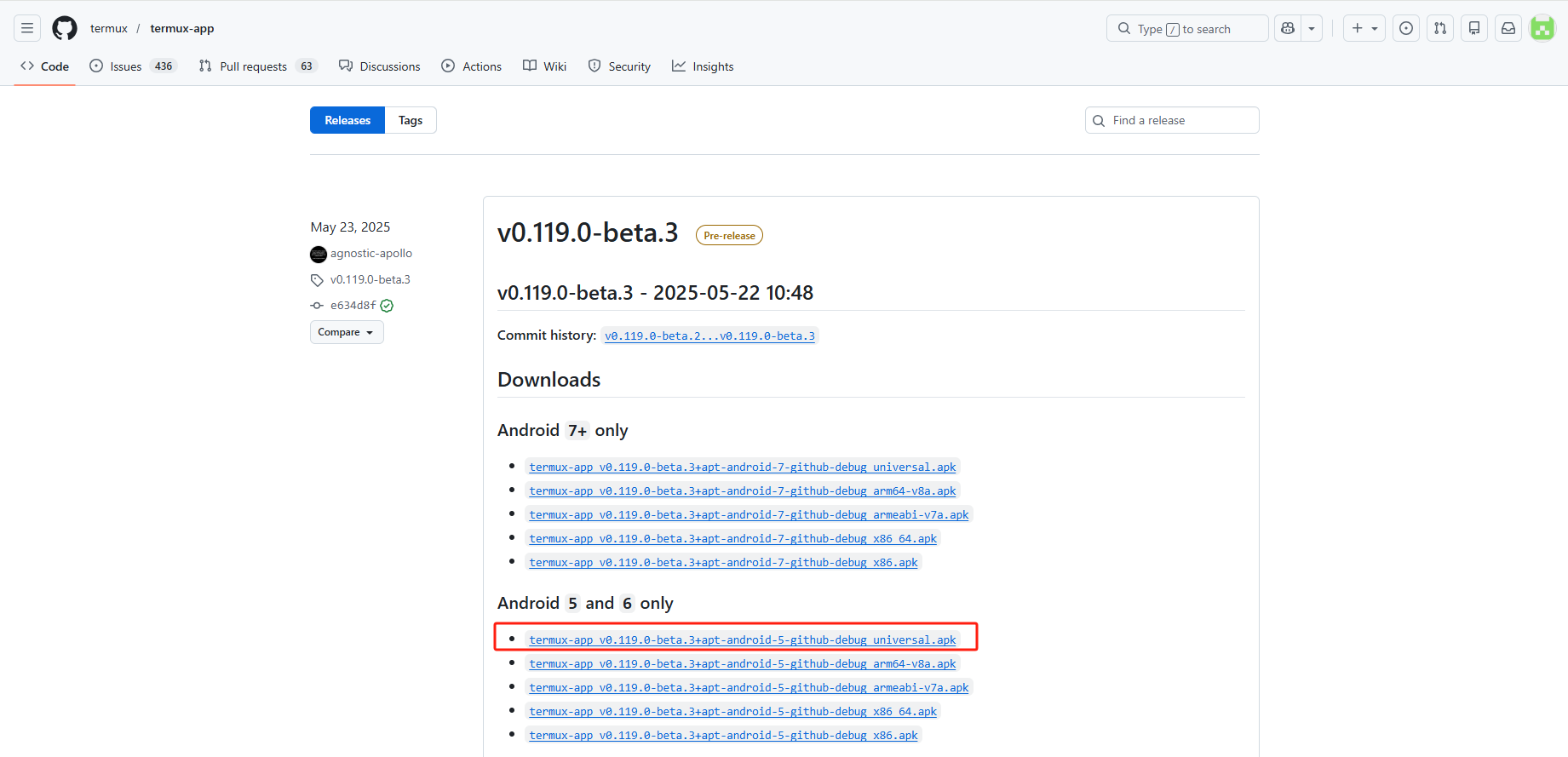
3.手机连接好wifi(重要!!!)
4.将下载好的termux.apk在手机上进行安装
略
5.在手机上安装后打开termux终端,执行初始化操作(都是在手机上的termux中操作)
5.1 安装openssh,方便通过ssh进行远程连接(下载比较慢,需要等会,如果中途出现网络错误,可以ctrl + c 打断,重新执行安装命令)
$ pkg install openssh -y5.2 设置密码
$ passwd #回车,输入密码回车设置完成5.3 启动sshd服务
$ sshd5.4 查看当前用户,我这边默认输出的用户u0_a116
$ whoami5.5 查看当前IP地址
$ ip a
5.6 修改默认的ssh端口,默认端口是8022(可选)
$ vi ~/../usr/etc/ssh/sshd_config
#最后添加并保存,根据自己需要设定端口
Port 22225.7 为了termux程序不被手机后台终止,可以设置后台锁定或者设置手机为常亮模式
6.通过电脑ssh远程连接,之后就可以在电脑上操作了
[root@localhost ~]# ssh -p 2222 u0_a116@172.16.1.1507.初始化命令操作
7.1 查看当前内核信息
$ uname -a
Linux localhost 3.10.84-perf-g1269e29-00269-g112a120 #1 SMP PREEMPT Thu Jun 4 16:40:13 CST 2020 aarch64 Android7.2 安装其他工具命令示范
# 安装curl命令
$ pkg install curl
# 安装nginx服务
$ pkg install nginx8.安装ubuntu系统
- 在termux的基础上安装ubuntu系统,可以更好的模拟真是操作系统
8.1 安装atilo工具
# 1. 添加 atilo 的官方仓库源
echo "deb [trusted=yes arch=all] https://yadominjinta.github.io/files/ termux extras" >> $PREFIX/etc/apt/sources.list.d/atilo.list
# 2. 更新包列表
apt update
# 3. 安装 atilo
apt install atilo
# 4. 查看 atilo 支持哪些 Linux 发行版
atilo images
# 5. 拉取 Ubuntu容器
atilo pull ubuntu
# 6. 进入 Ubuntu 容器
atilo run ubuntu- 具体的安装过程(下载ubuntu镜像,需要解决安卓手机**的问题)
安装ubuntu过程
8.2 ubuntu上的操作
8.2.1 查看ubuntu系统版本
root@localhost:~# cat /etc/os-release
NAME="Ubuntu"
VERSION="20.04.6 LTS (Focal Fossa)"
ID=ubuntu
ID_LIKE=debian
PRETTY_NAME="Ubuntu 20.04.6 LTS"
VERSION_ID="20.04"
HOME_URL="https://www.ubuntu.com/"
SUPPORT_URL="https://help.ubuntu.com/"
BUG_REPORT_URL="https://bugs.launchpad.net/ubuntu/"
PRIVACY_POLICY_URL="https://www.ubuntu.com/legal/terms-and-policies/privacy-policy"
VERSION_CODENAME=focal
UBUNTU_CODENAME=focal8.2.2 系统初始化
# 更新软件源
apt update && apt upgrade -y
# 安装基础工具
apt install -y net-tools iproute2 iputils-ping curl9.安装 Node.js 22 和 OpenClaw
- 本地大模型部署内容在下边,需要提前部署好本地大模型,方便后续openclaw连接
9.1 安装nodejs 22 版本(v22.22.1)
# 添加 NodeSource 官方源并安装 Node.js 22
curl -fsSL https://deb.nodesource.com/setup_22.x | bash -
apt install -y nodejs
# 验证 Node.js 版本(应为 v22.22.1)
node --version安装nodejs22过程
9.2 安装git
# 安装git,openclaw需要
apt install -y git安装git过程
9.3 安装openclaw
9.3.1 安装openclaw
# 全局安装 OpenClaw
npm install -g openclaw@latestroot@localhost:~# npm install -g openclaw@latest
npm warn deprecated node-domexception@1.0.0: Use your platform's native DOMException instead
added 539 packages in 6m
89 packages are looking for funding
run `npm fund` for details9.3.2 启动openclaw gateway
# 启动 OpenClaw gateway(默认端口 18789)
openclaw gateway- 提示缺少配置,需要咱们先执行“openclaw setup”进行初始化配置或者跳过配置都可以
root@localhost:~# openclaw gateway
🦞 OpenClaw 2026.3.13 (61d171a) — I'm not saying your workflow is chaotic... I'm just bringing a linter and a helmet.
05:48:49 Missing config. Run `openclaw setup` or set gateway.mode=local (or pass --allow-unconfigured).9.3.3 运行 openclaw setup 生成配置文件
- 方法一:直接生成配置文件,后续配置
root@localhost:~# openclaw setup
🦞 OpenClaw 2026.3.13 (61d171a) — I'm like tmux: confusing at first, then suddenly you can't live without me.
Wrote ~/.openclaw/openclaw.json
Workspace OK: ~/.openclaw/workspace
Sessions OK: ~/.openclaw/agents/main/sessions- 方法二:通过交互式窗口,生成配置文件
openclaw交互配置过程
9.3.4 openclaw配置连接本地大模型
- 获取openclaw连接本地大模型的id,可以看到id为:Qwen3.5-4B,在部署大模型的时候可以指定模型名称- --served-model-name - "Qwen3.5-4B",使用下列命令可以看到id
root@localhost lipengcheng]# curl http://172.16.4.28:8000/v1/models
{"object":"list","data":[{"id":"Qwen3.5-4B","object":"model","created":1774180466,"owned_by":"vllm","root":"/model","parent":null,"max_model_len":32768,"permission":[{"id":"modelperm-ab46652e69e81417","object":"model_permission","created":1774180466,"allow_create_engine":false,"allow_sampling":true,"allow_logprobs":true,"allow_search_indices":false,"allow_view":true,"allow_fine_tuning":false,"organization":"*","group":null,"is_blocking":false}]}]}- 配置文件:~/.openclaw/openclaw.json
- 可根据自己的实际情况修改,我这里只修改或者添加了基础信息,比如本地大模型的 baseUrl,apiKey,id,name,contextWindow,maxTokens等
"models": {
"mode": "merge", // 【模板】合并模式,固定写法,保持 "merge"
"providers": {
"vllm": { // 【模板】提供商名称 "vllm",固定写法(可自定义但通常不变)
// 以下为【本地需修改】字段 =================================
"baseUrl": "http://172.16.4.28:8000/v1", // ⚠️ 本地修改:你的 vLLM 服务地址(IP:端口/v1)
"apiKey": "local_vllm_key", // ⚠️ 本地修改:自定义 API Key(vLLM 默认不校验,可任意填)
// ========================================================
"api": "openai-completions", // 【模板】API 类型,固定 "openai-completions"
"models": [
{
// 以下为【本地需修改】字段 =================================
"id": "Qwen3.5-4B", // ⚠️ 本地修改:模型唯一标识,必须与 defaults.model.primary 值一致
"name": "Qwen3.5-4B", // ⚠️ 本地修改:模型显示名称(可随意,不影响匹配)
"contextWindow": 32768, // ⚠️ 本地修改:模型上下文长度,必须与 vLLM 的 --max-model-len 相同
"maxTokens": 8192 // ⚠️ 本地修改:单次最大输出 token 数(≤ contextWindow - 输入长度)
// ========================================================
// 以下为【模板】字段,固定不变 =============================
"reasoning": false, // 【模板】本地模型不支持推理链,固定 false
"input": ["text"], // 【模板】输入类型固定 ["text"]
"cost": { // 【模板】本地模型成本为 0
"input": 0,
"output": 0,
"cacheRead": 0,
"cacheWrite": 0
}
// ========================================================
}
]
}
}
}- agent需要添加 agents.defaults.model.primary的值,需要增加前缀vllm,因为的大模型是从vllm中获取的 ,如果使用openai部署的,需改改为openai,后边的是大模型的id,需要和model模块中的id保持一致
"agents": {
// ========== 模板部分 ==========
"defaults": { // 【模板】所有 agent 的默认配置
// ----- 本地需修改 -----
"model": {
"primary": "vllm/Qwen3.5-4B" // ⚠️ 本地修改:指定使用的模型完整标识(必须与 models 中的 provider/id 匹配)
},
// ----- 模板部分(一般不动) -----
"workspace": "/root/.openclaw/workspace", // 【模板】agent 工作目录(存放对话历史、缓存等)
"compaction": { // 【模板】上下文压缩策略
"mode": "safeguard" // 【模板】安全模式:当上下文即将超限时自动压缩
}
}
}9.3.5 配置局域网访问openclaw(默认只能127访问)
- ~/.openclaw/openclaw.json 中的"gateway模块中的 mode": "local", 此值必须为local,否则openclaw gateway会阻断启动
# 将网关绑定的网络接口设置为“lan”(通常意味着监听局域网 IP,而非仅 localhost),
# 使得局域网内其他设备可以访问 OpenClaw 的 Web 界面或 API。
openclaw config set gateway.bind lan
# 允许在非 HTTPS 环境下使用控制台 UI 的身份验证。
# 默认情况下,OpenClaw 可能要求 HTTPS 才能进行登录,启用此选项可以允许不安全的 HTTP 连接,
# 方便在局域网内测试,但生产环境不建议开启。
openclaw config set gateway.controlUi.allowInsecureAuth true
# 允许使用请求头中的 Host 或 Origin 作为回退来验证跨域访问。
# 当代理或反向代理导致正常的安全检查失败时,开启此选项可以绕过部分限制,
# 使局域网内的前端能正常访问网关 API。
openclaw config set gateway.controlUi.dangerouslyAllowHostHeaderOriginFallback true
# 完全禁用设备配对认证机制。
# 通常 OpenClaw 要求新设备进行授权确认,关闭此选项后任何能访问网关的设备都可以直接使用,
# 方便在受信任的局域网环境中快速接入,但会降低安全性。
openclaw config set gateway.controlUi.dangerouslyDisableDeviceAuth true9.3.6 连接openclaw的web ui
- 需要从~/.openclaw/openclaw.json配置文件中auth模块中获取token,然后登录webui的时候需要填写
http://openclaw ip:18789/
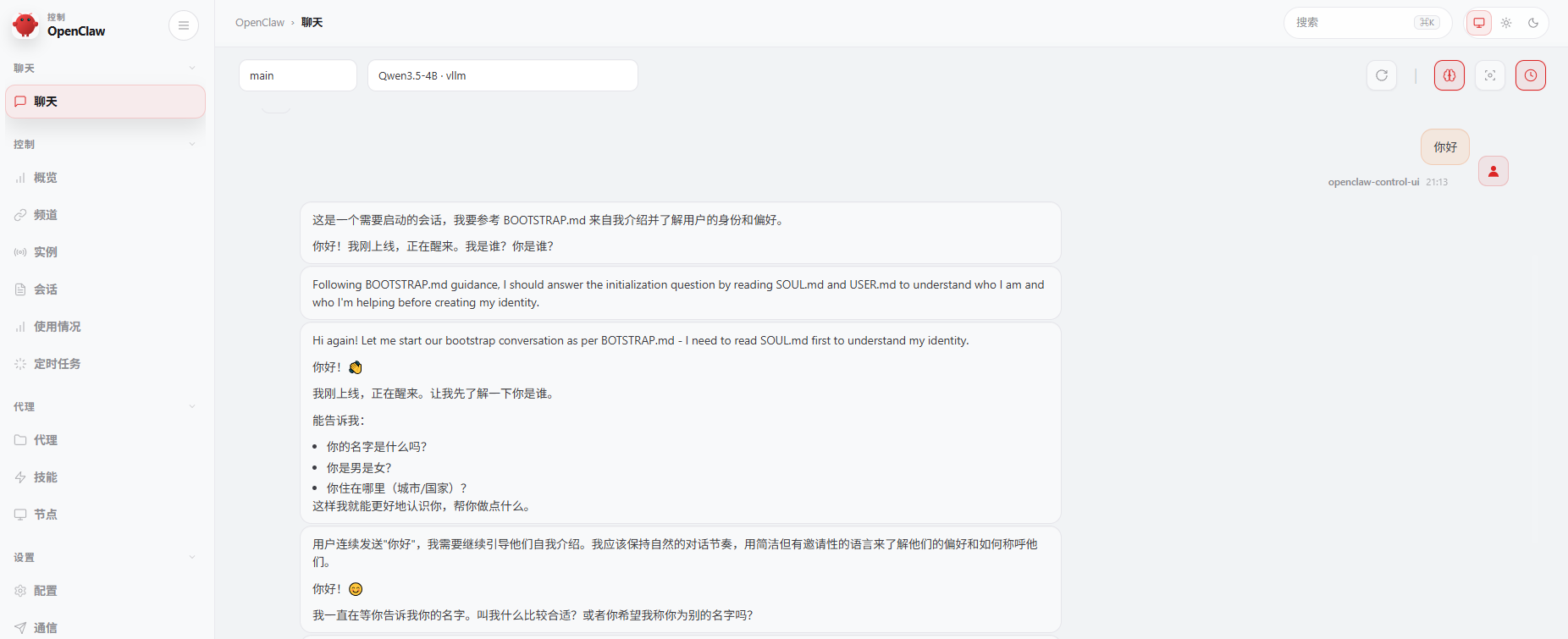
9.3.7 在openclaw web ui中发送你好测试
10.本地服务器大模型部署(centos或者ubuntu操作系统)
- 我这是使用的centos7.9的操作系统
10.1 docker安装
https://www.cnblogs.com/Leonardo-li/p/1824628810.2 下载vLLM(20.7G)
# latest版本对应v0.17.1
docker pull vllm/vllm-openai:latest10.3 使用modescope下载千问模型
- 查看modescope支持的模型
https://www.modelscope.cn/models- 我的是NVIDIA T4,16G显存,所以选择了Qwen3.5-4B模型,实际选择模型需要根据自己的算力情况(最开始测试的Qwen3.5-9B, 运行不起来)
- Qwen3.5-4B占用了11.7G的显存
# 下载modescope ,使用 modelscope(推荐国内网络)
pip3 install modelscope -i https://pypi.tuna.tsinghua.edu.cn/simple
# 使用 ModelScope 下载 Qwen3.5-4B
python3 -c "from modelscope.hub.snapshot_download import snapshot_download; snapshot_download('Qwen/Qwen3.5-4B', cache_dir='/data/lipengcheng/models')"10.4 编写使用vllm启动qwen3.5-4B模型的docker-compose.yaml文件
version: '3.8'
services:
vllm:
image: vllm/vllm-openai:latest
container_name: vllm_qwen
restart: unless-stopped
privileged: true
ports:
- "8000:8000"
volumes:
- /data/lipengcheng/models/Qwen/Qwen3.5-4B:/model
- /etc/localtime:/etc/localtime:ro
environment:
- CUDA_VISIBLE_DEVICES=1
- OPENBLAS_NUM_THREADS=1
- OMP_NUM_THREADS=1
- VLLM_DISABLE_TRACING=1
- VLLM_USE_V1=0
- OTEL_SDK_DISABLED=true
- OTEL_PYTHON_DISABLED_INSTRUMENTATIONS=all
ulimits:
nproc: 65535
nofile: 65535
shm_size: 10g
command:
- /model
- --tensor-parallel-size
- "1"
- --dtype
- float16
- --gpu-memory-utilization
- "0.9" #使用90%的模型能力
- --max-model-len
- "32768" #模型上下文长度,必须大于16000,因为openclaw要求大于16000
- --served-model-name
- "Qwen3.5-4B" # 添加这一行,指定 API 返回的模型 id
- --max-num-seqs
- "1"
- --trust-remote-code
- --enable-auto-tool-choice
- --tool-call-parser
- "hermes" # 解析器名称,根据模型可选 hermes / mistral / llama3_json / qwen
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]- 启动容器,加载模型(启动时间较慢,我这边启动了40多分钟,也是根据你的服务器性能,资源决定)
docker-compose up -dvllm加载模型启动输出日志
- 访问大模型进行测试(已经可以正常问了,但由于我是用的是qwen3.5-4B基础模型,所以返回的数据中有些注释之类的,先忽略,主要是为了oepnclaw接入本地大模型测试,后期在调整大模型)
[root@localhost lipengcheng]# curl http://localhost:8000/v1/chat/completions -H "Content-Type: application/json" -d '{
"model": "/model",
"messages": [{"role": "user", "content": "你好"}],
"max_tokens": 100
}'
{"id":"chatcmpl-bd5b7c3d595dd29e","object":"chat.completion","created":1774074680,"model":"/model","choices":[{"index":0,"message":{"role":"assistant","content":"Thinking Process:\n\n1. **Analyze the Input:**\n * Input: \"你好\" (Nǐ hǎo)\n * Language: Chinese\n * Meaning: \"Hello\"\n * Intent: Greeting, initiating conversation.\n\n2. **Determine the appropriate response:**\n * Tone: Friendly, polite, helpful.\n * Content: Return the greeting, offer assistance.\n * Language","refusal":null,"annotations":null,"audio":null,"function_call":null,"tool_calls":[],"reasoning":null},"logprobs":null,"finish_reason":"length","stop_reason":null,"token_ids":null}],"service_tier":null,"system_fingerprint":null,"usage":{"prompt_tokens":11,"total_tokens":111,"completion_tokens":100,"prompt_tokens_details":null},"prompt_logprobs":null,"prompt_token_ids":null,"kv_transfer_params":null}11.遇到的问题
11.1 使用清华源执行更新时,报错如下:
# 1.修改pkg为清华源
$ vi $PREFIX/etc/apt/sources.list
##替换为清华源
deb https://mirrors.tuna.tsinghua.edu.cn/termux/apt/termux-main stable main
# 2. 更新源命令
$ pkg update
# 3. 关键报错信息
CANNOT LINK EXECUTABLE: library "libssl.so.1.1" not found
E: Method https has died unexpectedly!
# 4. 解决方法
# 4.1 可以试着把源https修改为http
deb http://mirrors.tuna.tsinghua.edu.cn/termux/apt/termux-main stable main
# 4.2 执行更新
pkg update
# 4.3 安装修复https工具
pkg install openssl1.1-tool -y
# 4.4 将清华源http修改为https
deb https://mirrors.tuna.tsinghua.edu.cn/termux/apt/termux-main stable main11.2 由于安卓6.0的限制,termux底层只能按照nodejs 12的版本,安装不了高版本
11.3 openclaw报错
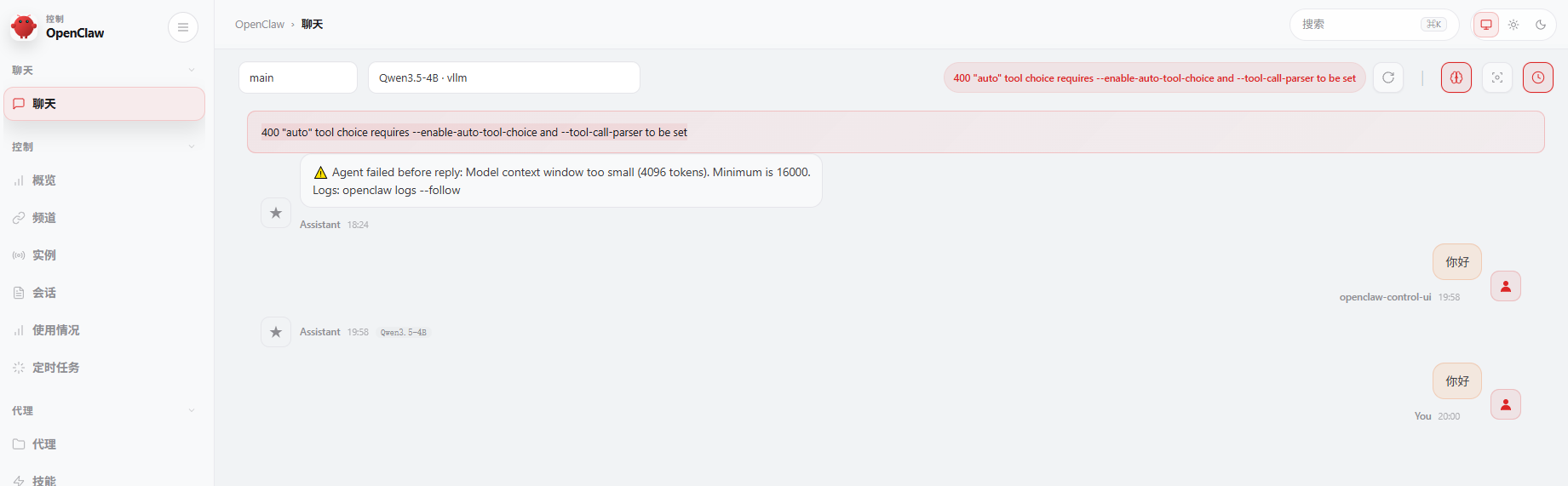
- 这个错误是因为 vLLM 后端在响应 OpenClaw 的工具调用请求时,缺少必要的启动参数。错误信息 400 "auto" tool choice requires --enable-auto-tool-choice and --tool-call-parser to be set 表示 vLLM 需要启用工具调用功能,但你当前的启动命令中未包含相关配置。
- 原因
OpenClaw 的 Agent 可能尝试使用工具(如联网搜索、计算器等),并在请求中设置了 tool_choice: "auto"。 vLLM 默认不支持工具调用(function calling),需要显式添加 --enable-auto-tool-choice 和 --tool-call-parser 参数 - 在启动vllm时,在command最后添加3行:
command:
- /model
- --tensor-parallel-size
- "1"
- --dtype
- float16
- --gpu-memory-utilization
- "0.9"
- --max-model-len
- "32768"
- --served-model-name
- "Qwen3.5-4B"
- --max-num-seqs
- "1"
- --trust-remote-code
# 添加如下3行
- --enable-auto-tool-choice
- --tool-call-parser
- "hermes"
免费领 150 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐
 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)