
【vllm】 DP并行代码解析
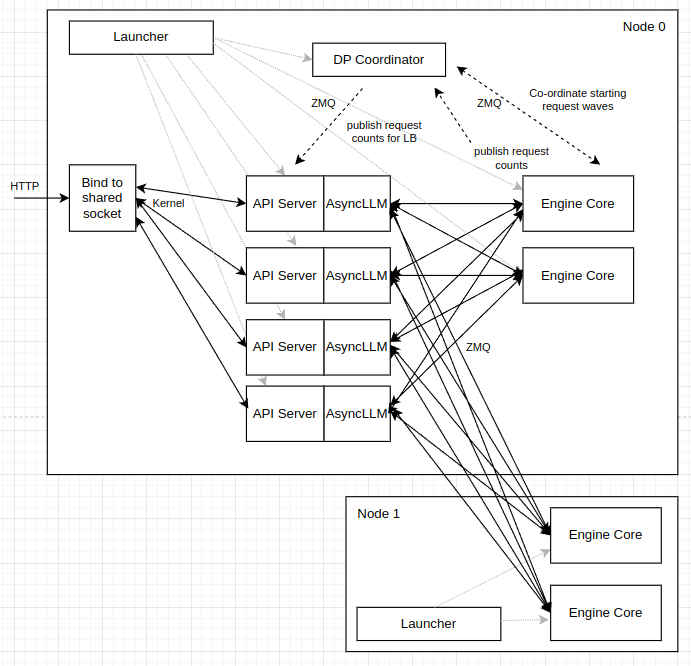
好的,我们来详细解析 get_engine_client_zmq_addr 这个函数的作用、它生成的地址是什么样子,以及它在 vLLM 架构中的用途。
1. get_engine_client_zmq_addr 函数是干嘛用的?
这个函数的核心作用是生成一个用于 ZMQ 通信的地址字符串。
在 vLLM 的分布式架构中,不同的进程(如 API Server、Engine Core、DP Coordinator)需要相互通信。ZMQ 是它们之间通信的“高速公路”。要在这条高速公路上通信,每个通信端点都需要一个唯一的“地址”,就像房子需要门牌号一样。
get_engine_client_zmq_addr 就是 vLLM 内部用来**动态地、规范地创建这些“门牌号”**的工具函数。它根据部署模式(是本地进程间通信还是跨网络通信)来决定生成哪种类型的地址。
2. 地址是什么样子的?
get_engine_client_zmq_addr 生成的地址主要有两种格式,这取决于 local_only 这个参数:
a) 本地进程间通信 (IPC - Inter-Process Communication)
- 当
local_only=True时:- 函数会调用
get_open_zmq_ipc_path()。 - 地址格式:
ipc:///tmp/vllm-some-random-uuid.sock - 解释:
ipc://: 这是 ZMQ 的传输协议前缀,表示使用 IPC。/tmp/vllm-some-random-uuid.sock: 这是一个文件系统路径。ZMQ 会在这个路径下创建一个Unix 域套接字 (Unix Domain Socket) 文件。
- 特点:
- 极高效率: IPC 通信不经过网络协议栈,而是直接通过内核的内存拷贝。对于在同一台物理机上的不同进程间通信,这是速度最快、延迟最低的方式。
- 仅限本机: 这种地址只能被同一台物理机上的进程访问。
- 函数会调用
b) 跨网络通信 (TCP)
- 当
local_only=False时:- 函数会调用
get_tcp_uri()。 - 地址格式:
tcp://<host>:<port> - 解释:
tcp://: 这是 ZMQ 的传输协议前缀,表示使用 TCP/IP 协议。<host>: 通常是主节点(Master Node)的 IP 地址,例如10.99.48.128。<port>: 一个动态分配的可用端口号。
- 特点:
- 跨机器通信: 允许部署在不同物理机上的进程进行通信。
- 有网络开销: 通信需要经过完整的 TCP/IP 协议栈,相比 IPC 会有更高的延迟和略低的吞吐量。
- 函数会调用
3. 它在 API Server 场景中具体干嘛用的?
在 run_multi_api_server 的流程中,这个函数被 get_engine_zmq_addresses 调用,用来创建多对 ZMQ 地址,这些地址构成了 API Server 和 Engine Core 之间的通信“桥梁”。
我们来看一下 EngineZmqAddresses 这个数据结构:
@dataclass
class EngineZmqAddresses:
# ZMQ input socket addresses for each front-end client (requests)
inputs: list[str]
# ZMQ output socket addresses for each front-end client (responses)
outputs: list[str]
# ...
在启动流程中,会发生以下事情:
-
生成地址对:
get_engine_zmq_addresses会循环num_api_servers次。- 在每次循环中,它会调用两次
get_engine_client_zmq_addr,生成一对地址:一个用于inputs,一个用于outputs。 inputs地址: 这是Engine Core接收请求的地址。API Server会把推理请求发送到这个地址。outputs地址: 这是Engine Core发送结果的地址。API Server会从这个地址读取推理结果。
-
绑定和连接:
-
API Server(作为客户端):- 它会创建一个
ROUTER类型的 ZMQ 套接字,并绑定 (bind) 到inputs地址列表中的一个。这是它向Engine Core发送请求的“出口”。 - 它会创建一个
PULL类型的 ZMQ 套接字,并连接 (connect) 到outputs地址列表中的一个。这是它接收Engine Core结果的“入口”。
- 它会创建一个
-
Engine Core(作为服务端):- 它会创建一个
DEALER类型的 ZMQ 套接字,并连接 (connect) 到对应的inputs地址。这是它接收请求的“入口”。 - 它会创建一个
PUSH类型的 ZMQ 套接字,并绑定 (bind) 到对应的outputs地址。这是它发送结果的“出口”。
- 它会创建一个
-
为什么需要 inputs 和 outputs 两条独立的通道?
这是 ZMQ 的一种常见设计模式,用于实现全双工、异步的通信:
- 请求通道 (
inputs):API Server可以随时向Engine Core发送请求,而不用等待上一个请求的回复。 - 结果通道 (
outputs):Engine Core可以在处理完任何一个请求后,立即将结果推送到结果通道,而不用关心请求的顺序。
这种分离的设计使得整个系统的吞吐量和并发能力大大提高。
总结:
get_engine_client_zmq_addr 是 vLLM 分布式架构的“地址簿生成器”。在 API Server 场景中,它负责创建成对的、唯一的 ZMQ 地址(可能是高效的 ipc:// 或可跨网络的 tcp://),这些地址定义了 API Server 和 Engine Core 之间发送请求和接收结果的双向通信管道,是整个系统协同工作的基础。
好的,我们通过一个具体的、简化的例子来说明 get_engine_client_zmq_addr 如何工作,以及生成的地址如何被 API Server 和 Engine Core 使用。
假设我们有这样一个场景:
- 部署模式: 内部负载均衡,跨两个节点。
- Node 0 (主节点, IP: 10.0.0.1):
- 启动 2 个
API Server(--api-server-count=2)。 - 启动 1 个
Engine Core。
- 启动 2 个
- Node 1 (计算节点, IP: 10.0.0.2):
- 启动 1 个
Engine Core(无头模式)。
- 启动 1 个
第 1 步:在主节点 (Node 0) 上生成 ZMQ 地址
当 vllm serve 命令在 Node 0 上执行时,get_engine_zmq_addresses 函数会被调用,参数 num_api_servers=2。
这个函数内部会循环两次,每次都调用 get_engine_client_zmq_addr 来生成一对 input 和 output 地址。
因为这是跨节点部署 (local_only 会是 False),所以会生成 TCP 地址。
第一次循环 (为 API Server 0 生成地址):
get_engine_client_zmq_addr()-> 返回"tcp://10.0.0.1:54321"(假设端口是 54321) -> 存入inputs[0]get_engine_client_zmq_addr()-> 返回"tcp://10.0.0.1:54322"(假设端口是 54322) -> 存入outputs[0]
第二次循环 (为 API Server 1 生成地址):
get_engine_client_zmq_addr()-> 返回"tcp://10.0.0.1:54323"-> 存入inputs[1]get_engine_client_zmq_addr()-> 返回"tcp://10.0.0.1:54324"-> 存入outputs[1]
最终,addresses 对象看起来像这样:
addresses = EngineZmqAddresses(
inputs=["tcp://10.0.0.1:54321", "tcp://10.0.0.1:54323"],
outputs=["tcp://10.0.0.1:54322", "tcp://10.0.0.1:54324"],
# ... 其他地址 ...
)
第 2 步:启动进程并分配地址
接下来,run_multi_api_server 会启动所有相关进程,并把这些地址分配给它们。
启动 API Server 进程
APIServerProcessManager 会启动两个 API Server 子进程。
-
API Server 0 (进程):
- 它会收到分配给它的地址对:
input_address:"tcp://10.0.0.1:54321"output_address:"tcp://10.0.0.1:54322"
- 它的 ZMQ 设置:
- 创建一个
ROUTER套接字,绑定 (bind) 到"tcp://10.0.0.1:54321"。现在它可以从这个地址发送请求。 - 创建一个
PULL套接字,连接 (connect) 到"tcp://10.0.0.1:54322"。现在它可以从这个地址拉取结果。
- 创建一个
- 它会收到分配给它的地址对:
-
API Server 1 (进程):
- 它会收到分配给它的地址对:
input_address:"tcp://10.0.0.1:54323"output_address:"tcp://10.0.0.1:54324"
- 它的 ZMQ 设置:
- 创建一个
ROUTER套接字,绑定 (bind) 到"tcp://10.0.0.1:54323"。 - 创建一个
PULL套接字,连接 (connect) 到"tcp://10.0.0.1:54324"。
- 创建一个
- 它会收到分配给它的地址对:
启动 Engine Core 进程
launch_core_engines 会启动两个 Engine Core 进程,一个在 Node 0,一个在 Node 1。这两个 Engine Core 在启动时都会通过握手从主进程(前端)那里获得所有 API Server 的地址。
- Engine Core 0 (在 Node 0) 和 Engine Core 1 (在 Node 1):
- 它们都会收到完整的地址列表:
inputs:["tcp://10.0.0.1:54321", "tcp://10.0.0.1:54323"]outputs:["tcp://10.0.0.1:54322", "tcp://10.0.0.1:54324"]
- 它们的 ZMQ 设置:
- 创建一个
DEALER套接字,它会连接 (connect) 到所有的input地址,即"tcp://10.0.0.1:54321"和"tcp://10.0.0.1:54323"。这样,它就能接收来自任何一个 API Server 的请求。 - 创建一个
PUSH套接字,它会绑定 (bind) 到一个output地址。这里的设计比较微妙,通常Engine Core会绑定到它自己负责处理的那个API Server对应的output地址,或者有一个更集中的结果收集机制。为简化起见,我们假设它会把结果推送到一个共享的队列,而这个队列的入口是其中一个output地址。
- 创建一个
- 它们都会收到完整的地址列表:
第 3 步:一次完整的请求-响应流程
现在,让我们看看一个请求是如何流动的:
- 一个外部 HTTP 请求到达 Node 0 的共享端口,内核将它交给了 API Server 0。
API Server 0经过内部负载均衡决策,决定将这个请求发送给 Engine Core 1 (在 Node 1 上)。API Server 0通过它绑定在"tcp://10.0.0.1:54321"上的ROUTER套接字,将请求数据发送出去。Engine Core 1的DEALER套接字(它连接了所有 input 地址)收到了这个请求。Engine Core 1完成模型推理,得到结果。Engine Core 1需要将结果发回给 API Server 0。它通过PUSH套接字将结果发送到与API Server 0对应的output地址,即"tcp://10.0.0.1:54322"。API Server 0的PULL套接字(它连接到了"tcp://10.0.0.1:54322")收到了这个结果。API Server 0将结果格式化后,通过 HTTP 响应返回给原始的客户端。
可视化这个例子:
+-------------------------------- Node 0 (10.0.0.1) ---------------------------------+
| |
| +--------------+ bind: tcp://...:54321 (ROUTER) +-------------------+ |
| | API Server 0 |<------------------------------------------>| Engine Core 0 | |
| +--------------+ connect: tcp://...:54322 (PULL) | (also connects to | |
| | all API Servers) | |
| +--------------+ bind: tcp://...:54323 (ROUTER) +-------------------+ |
| | API Server 1 |<------------------------------------------> | |
| +--------------+ connect: tcp://...:54324 (PULL) | |
| ^ | |
| | +---------------------------------------------------------------------+
| | |
+-------|----------------------------------------------------------------------------+
| ZMQ Communication
v
+-------------------------------- Node 1 (10.0.0.2) ---------------------------------+
| |
| +-------------------+ |
| | Engine Core 1 | |
| | (connects to all | |
| | API Servers) | |
| +-------------------+ |
| |
+------------------------------------------------------------------------------------+
这个例子清晰地展示了 get_engine_client_zmq_addr 生成的地址如何成为连接不同节点上、不同进程之间的“血管”,使得数据(请求和响应)可以在这个分布式系统中顺畅地流动。
get_engine_client_zmq_addr 地址格式和用途
get_engine_client_zmq_addr 是 vLLM 中用于生成 ZMQ 通信地址的函数,它根据部署场景决定使用 IPC(本地进程间通信)还是 TCP(网络通信)地址格式。 1
地址格式
函数返回两种类型的地址:
-
IPC 地址(本地通信):
ipc:///tmp/vllm_rpc/{uuid}例如:
ipc:///tmp/vllm_rpc/12345678-1234-1234-1234-123456789abc -
TCP 地址(网络通信):
tcp://{host}:{port}例如:
tcp://192.168.1.100:5555
主要用途
1. API Server 与 Engine Core 通信
在 launch_core_engines 函数中,为每个 API Server 创建输入输出地址: 2
addresses = EngineZmqAddresses(
inputs=[
get_engine_client_zmq_addr(client_local_only, host)
for _ in range(num_api_servers)
],
outputs=[
get_engine_client_zmq_addr(client_local_only, host)
for _ in range(num_api_servers)
],
)
2. DP Coordinator 地址设置
Coordinator 使用该函数创建发布订阅地址: 3
front_publish_address = get_engine_client_zmq_addr(
local_only=local_only, host=host
)
back_publish_address = get_engine_client_zmq_addr(local_only_eng, host)
地址选择逻辑
函数根据 local_only 参数决定地址类型: 4
local_only=True:使用 IPC 地址(进程在同一节点)local_only=False:使用 TCP 地址(跨节点通信)
实际应用示例
在测试代码中可以看到具体的地址格式: 5
EngineZmqAddresses(
inputs=["tcp://127.0.0.1:5555"],
outputs=["tcp://127.0.0.1:5556"],
coordinator_input=None,
coordinator_output=None,
)
Notes
get_engine_client_zmq_addr 是 vLLM 分布式架构中的关键地址生成函数,它抽象了底层通信细节,使系统能够灵活地在单节点(IPC)和多节点(TCP)部署之间切换,而无需修改上层业务逻辑。
Wiki pages you might want to explore:
Citations
File: vllm/v1/utils.py (L143-156)
def get_engine_client_zmq_addr(local_only: bool, host: str, port: int = 0) -> str:
"""Assign a new ZMQ socket address.
If local_only is True, participants are colocated and so a unique IPC
address will be returned.
Otherwise, the provided host and port will be used to construct a TCP
address (port == 0 means assign an available port)."""
return (
get_open_zmq_ipc_path()
if local_only
else (get_tcp_uri(host, port or get_open_port()))
)
File: vllm/v1/engine/utils.py (L810-820)
# Set up input and output addresses.
addresses = EngineZmqAddresses(
inputs=[
get_engine_client_zmq_addr(client_local_only, host)
for _ in range(num_api_servers)
],
outputs=[
get_engine_client_zmq_addr(client_local_only, host)
for _ in range(num_api_servers)
],
)
File: vllm/v1/engine/coordinator.py (L69-75)
front_publish_address = get_engine_client_zmq_addr(
local_only=local_only, host=host
)
local_only_eng = dp_size == parallel_config.data_parallel_size_local
back_publish_address = get_engine_client_zmq_addr(local_only_eng, host)
back_output_address = get_engine_client_zmq_addr(local_only_eng, host)
File: tests/v1/engine/test_engine_core_client.py (L1125-1130)
return EngineZmqAddresses(
inputs=["tcp://127.0.0.1:5555"],
outputs=["tcp://127.0.0.1:5556"],
coordinator_input=None,
coordinator_output=None,
)
跨节点部署中的地址管理
在您描述的跨节点部署场景中,get_engine_client_zmq_addr 负责生成 TCP 地址用于节点间通信。
地址生成逻辑
get_engine_client_zmq_addr 函数根据 local_only 参数决定地址类型: 1
def get_engine_client_zmq_addr(local_only: bool, host: str, port: int = 0) -> str:
return (
get_open_zmq_ipc_path()
if local_only
else (get_tcp_uri(host, port or get_open_port()))
)
在跨节点场景中:
- Node 0 (主节点):
local_only=False,host="10.0.0.1"→ 生成tcp://10.0.0.1:随机端口 - Node 1 (计算节点):
local_only=False,host="10.0.0.1"→ 生成tcp://10.0.0.1:随机端口
地址分发机制
对端节点通过 handshake 机制接收地址:
-
初始化阶段:主节点创建 handshake socket 监听指定端口 2
-
Engine Core 连接:Node 1 的 Engine Core 通过
run_headless连接到主节点 3 -
Handshake 过程:Engine Core 发送 HELLO 消息,接收包含所有 ZMQ 地址的初始化消息 4
具体流程
地址配置示例
在您的场景中,地址配置如下: 5
addresses = EngineZmqAddresses(
inputs=[
"tcp://10.0.0.1:5555", # API Server 0 输入
"tcp://10.0.0.1:5556", # API Server 1 输入
],
outputs=[
"tcp://10.0.0.1:5557", # API Server 0 输出
"tcp://10.0.0.1:5558", # API Server 1 输出
],
coordinator_input="tcp://10.0.0.1:5559",
coordinator_output="tcp://10.0.0.1:5560",
)
Notes
跨节点部署的关键是所有节点都连接到主节点的 IP 地址,通过 handshake 机制统一分发通信地址。这确保了即使 Engine Core 在不同节点,也能正确建立 ZMQ 通信连接。 6
Wiki pages you might want to explore:
Citations
File: vllm/v1/utils.py (L143-156)
def get_engine_client_zmq_addr(local_only: bool, host: str, port: int = 0) -> str:
"""Assign a new ZMQ socket address.
If local_only is True, participants are colocated and so a unique IPC
address will be returned.
Otherwise, the provided host and port will be used to construct a TCP
address (port == 0 means assign an available port)."""
return (
get_open_zmq_ipc_path()
if local_only
else (get_tcp_uri(host, port or get_open_port()))
)
File: vllm/v1/engine/utils.py (L810-820)
# Set up input and output addresses.
addresses = EngineZmqAddresses(
inputs=[
get_engine_client_zmq_addr(client_local_only, host)
for _ in range(num_api_servers)
],
outputs=[
get_engine_client_zmq_addr(client_local_only, host)
for _ in range(num_api_servers)
],
)
File: vllm/v1/engine/utils.py (L888-890)
handshake_address = get_engine_client_zmq_addr(
handshake_local_only, host, parallel_config.data_parallel_rpc_port
)
File: vllm/entrypoints/cli/serve.py (L187-189)
host = parallel_config.data_parallel_master_ip
port = parallel_config.data_parallel_rpc_port
handshake_address = get_tcp_uri(host, port)
File: vllm/v1/engine/core.py (L922-930)
handshake_socket.send(
msgspec.msgpack.encode(
{
"status": "HELLO",
"local": local_client,
"headless": headless,
}
)
)
File: docs/serving/data_parallel_deployment.md (L37-47)
This will run DP=4 with DP ranks 0 and 1 on the head node and ranks 2 and 3 on the second node:
```bash
# Node 0 (with ip address 10.99.48.128)
vllm serve $MODEL --data-parallel-size 4 --data-parallel-size-local 2 \
--data-parallel-address 10.99.48.128 --data-parallel-rpc-port 13345
# Node 1
vllm serve $MODEL --headless --data-parallel-size 4 --data-parallel-size-local 2 \
--data-parallel-start-rank 2 \
--data-parallel-address 10.99.48.128 --data-parallel-rpc-port 13345
根据您的主节点配置,另一个节点需要使用 `--headless` 模式启动。以下是完整的配置方案:
## 节点配置
### 主节点 (Node 0: 192.168.1.100)
```bash
python -m vllm.entrypoints.openai.api_server \
--model llama-2-7b \
--api-server-count 2 \
--data-parallel-size 2 \
--data-parallel-size-local 1 \
--data-parallel-address 192.168.1.100 \
--data-parallel-rpc-port 29550
计算节点 (Node 1: 192.168.1.101)
python -m vllm.entrypoints.openai.api_server \
--model llama-2-7b \
--headless \
--data-parallel-size 2 \
--data-parallel-size-local 1 \
--data-parallel-start-rank 1 \
--data-parallel-address 192.168.1.100 \
--data-parallel-rpc-port 29550
关键参数说明
--data-parallel-size 2: 总共2个数据并行副本--data-parallel-size-local 1: 每个节点运行1个副本--data-parallel-start-rank 1: 第二个节点的起始rank为1--headless: 计算节点不启动API服务器 1--data-parallel-address: 主节点IP地址--data-parallel-rpc-port: 节点间通信端口(默认29550)
通信流程
- 主节点创建 DP Coordinator 和 Engine Core
- 计算节点通过 handshake 连接到主节点 2
- 主节点分发 ZMQ 通信地址给计算节点 3
- 建立跨节点的 ZMQ 连接进行负载均衡
Notes
确保两个节点网络互通,防火墙允许指定端口的通信。主节点的 API 服务器会通过内部负载均衡将请求分发到两个节点的 Engine Core。 4
Wiki pages you might want to explore:
Citations
File: docs/serving/data_parallel_deployment.md (L37-47)
This will run DP=4 with DP ranks 0 and 1 on the head node and ranks 2 and 3 on the second node:
```bash
# Node 0 (with ip address 10.99.48.128)
vllm serve $MODEL --data-parallel-size 4 --data-parallel-size-local 2 \
--data-parallel-address 10.99.48.128 --data-parallel-rpc-port 13345
# Node 1
vllm serve $MODEL --headless --data-parallel-size 4 --data-parallel-size-local 2 \
--data-parallel-start-rank 2 \
--data-parallel-address 10.99.48.128 --data-parallel-rpc-port 13345
**File:** vllm/v1/engine/utils.py (L810-820)
```python
# Set up input and output addresses.
addresses = EngineZmqAddresses(
inputs=[
get_engine_client_zmq_addr(client_local_only, host)
for _ in range(num_api_servers)
],
outputs=[
get_engine_client_zmq_addr(client_local_only, host)
for _ in range(num_api_servers)
],
)
File: vllm/v1/engine/utils.py (L888-890)
handshake_address = get_engine_client_zmq_addr(
handshake_local_only, host, parallel_config.data_parallel_rpc_port
)
excellent question. This gets to the heart of how vLLM orchestrates a distributed system. The --headless mode is the key to creating a “worker-only” node, and the synchronization relies on a clear “master-worker” pattern established through command-line arguments and ZMQ communication.
下面我将分步详细解释多机环境下的启动和同步过程,并用一个具体的例子来说明。
核心思想:总指挥部与前线作战单元
您可以将 vLLM 的多机部署想象成一个军事行动:
- 主节点 (Head Node):这是**“总指挥部”**。它负责对外接收命令(HTTP 请求)、制定作战计划(负载均衡)、并与所有作战单元保持通信。它自己也可以部署一些作战单元。
- 计算节点 (Worker Node / Headless Node):这些是**“前线纯作战单元”**。它们不直接对外,只专注于执行总指挥部下发的任务(模型推理)。
--headless参数就是告诉这个节点:“你是一个纯作战单元,不要管指挥和通讯的事,专心打仗就行。”
同步的关键在于:所有“作战单元”在启动时都必须知道“总指挥部”的地址,并主动去报到。
多机启动和同步的详细步骤
我们以上一节文档中的例子来具体说明:
- 总配置:
DP=4(总共 4 个 Engine Core) - 主节点 (Node 0, IP: 10.0.0.1): 运行 2 个 Engine Core (rank 0, 1) 和 API 服务器。
- 计算节点 (Node 1): 运行 2 个 Engine Core (rank 2, 3),模式为
--headless。
第 1 步:用户操作 - 启动命令
主节点 (Node 0) 上的命令:
vllm serve $MODEL --data-parallel-size 4 --data-parallel-size-local 2 \
--data-parallel-address 10.0.0.1 --data-parallel-rpc-port 13345
--data-parallel-size 4: “整个集群总共有 4 个作战单元。”--data-parallel-size-local 2: “我这个节点负责部署 2 个单元(rank 0 和 1)。”--data-parallel-address 10.0.0.1: 【最关键的参数】 “我就是总指挥部,我的公开地址是10.0.0.1。”--data-parallel-rpc-port 13345: “所有单元请通过13345端口来联系我进行报到和握手。”
计算节点 (Node 1) 上的命令:
vllm serve $MODEL --headless --data-parallel-size 4 --data-parallel-size-local 2 \
--data-parallel-start-rank 2 \
--data-parallel-address 10.0.0.1 --data-parallel-rpc-port 13345
--headless: “我是一个纯作战单元,不启动 API 服务器和协调器。”--data-parallel-size 4: “我知道整个集群总共有 4 个作战单元。”--data-parallel-size-local 2: “我这个节点负责部署 2 个单元。”--data-parallel-start-rank 2: “我负责的是从 rank 2 开始的单元(即 rank 2 和 3)。”--data-parallel-address 10.0.0.1和--data-parallel-rpc-port 13345: 【最关键的参数】 “我知道总指挥部的地址是10.0.0.1:13345,我等下会去那里报到。”
小结: 命令行参数提供了初始的“集结点”信息。所有节点都知道集群的总规模,并且计算节点被明确告知了主节点的地址。
第 2 步:启动和连接
-
主节点 (Node 0) 的行为:
- 启动自己的
Engine Core进程 (rank 0, 1)。 - 启动
API Server进程和DP Coordinator进程。 - 最重要的是,它会创建一个 ZMQ
ROUTER套接字,并绑定 (bind) 到10.0.0.1:13345。这个套接字就是**“握手套接字”**。 - 主节点的
wait_for_engine_startup函数现在开始等待所有 4 个Engine Core(包括它不认识的远程 rank 2, 3)前来报到。
- 启动自己的
-
计算节点 (Node 1) 的行为:
- 因为它处于
--headless模式,它只启动自己的Engine Core进程 (rank 2, 3)。 - 每个启动的
Engine Core进程(rank 2 和 3)都会读取命令行参数,得知主节点的地址是10.0.0.1:13345。 - 它们各自创建一个 ZMQ
DEALER套接字,并连接 (connect) 到tcp://10.0.0.1:13345。 - 它们现在正在跨越网络,主动尝试与主节点建立联系。
- 因为它处于
第 3 步:握手和同步 (The Handshake)
这个过程与我们之前讨论的 wait_for_engine_startup 完全一致,但现在它发生在网络上。
-
远程报到 (HELLO):
- 计算节点上的
Engine Core2 和 3 成功连接到主节点的握手套接字后,立即发送 “HELLO” 消息。消息中包含了它们的身份标识(rank 2 或 3)。 - 通信:
Node 1 Engine Core (DEALER)->Node 0 Handshake Socket (ROUTER)
- 计算节点上的
-
总指挥部回应 (Reply with Config):
- 主节点上的
wait_for_engine_startup函数收到了来自 rank 2 和 3 的 “HELLO” 消息。它知道这些是远程的Engine Core。 - 它将包含
DP Coordinator地址的配置信息,通过 ZMQ 发回给 rank 2 和 3。 - 通信:
Node 0 Handshake Socket (ROUTER)->Node 1 Engine Core (DEALER)
- 主节点上的
-
远程就绪 (READY):
- 计算节点上的
Engine Core收到配置后,连接到DP Coordinator,并完成自己的模型加载等初始化工作。 - 初始化完成后,它们再次通过与主节点的 ZMQ 连接,发送 “READY” 消息。
- 通信:
Node 1 Engine Core (DEALER)->Node 0 Handshake Socket (ROUTER)
- 计算节点上的
-
本地同步: 与此同时,主节点上的
Engine Core0 和 1 也在与自己的wait_for_engine_startup函数进行同样的握手流程(通常通过更快的本地 IPC 通信)。
第 4 步:集群准备就绪
- 主节点上的
wait_for_engine_startup函数的等待循环,在收到了所有 4 个Engine Core(2 个本地,2 个远程)的 “HELLO” 和 “READY” 消息后,终于结束。 DP Coordinator也收到了来自所有 4 个Engine Core的订阅。- 至此,整个集群完成同步,所有
Engine Core都与DP Coordinator和API Server建立了通信管道。 - 当一个 HTTP 请求到达主节点的
API Server时,API Server会根据DP Coordinator提供的包含所有 4 个Engine Core的负载信息,来决定将请求发送到哪个Engine Core——这个Engine Core完全可能位于远程的计算节点上。
总结: headless 模式下的多机同步,本质上是一个集中式的协调过程。通过在启动时提供主节点的“集结点”地址,所有分散的计算节点都能主动向中心报到,并由中心统一分发配置、完成同步,最终形成一个统一的、可协同工作的计算集群。
根据您的主节点配置,另一个节点需要使用 --headless 模式启动。以下是完整的配置方案:
节点配置
主节点 (Node 0: 192.168.1.100)
python -m vllm.entrypoints.openai.api_server \
--model llama-2-7b \
--api-server-count 2 \
--data-parallel-size 2 \
--data-parallel-size-local 1 \
--data-parallel-address 192.168.1.100 \
--data-parallel-rpc-port 29550
计算节点 (Node 1: 192.168.1.101)
python -m vllm.entrypoints.openai.api_server \
--model llama-2-7b \
--headless \
--data-parallel-size 2 \
--data-parallel-size-local 1 \
--data-parallel-start-rank 1 \
--data-parallel-address 192.168.1.100 \
--data-parallel-rpc-port 29550
关键参数说明
--data-parallel-size 2: 总共2个数据并行副本--data-parallel-size-local 1: 每个节点运行1个副本--data-parallel-start-rank 1: 第二个节点的起始rank为1--headless: 计算节点不启动API服务器 1--data-parallel-address: 主节点IP地址--data-parallel-rpc-port: 节点间通信端口(默认29550)
通信流程
- 主节点创建 DP Coordinator 和 Engine Core
- 计算节点通过 handshake 连接到主节点 2
- 主节点分发 ZMQ 通信地址给计算节点 3
- 建立跨节点的 ZMQ 连接进行负载均衡
Notes
确保两个节点网络互通,防火墙允许指定端口的通信。主节点的 API 服务器会通过内部负载均衡将请求分发到两个节点的 Engine Core。 4
Wiki pages you might want to explore:
Citations
File: docs/serving/data_parallel_deployment.md (L37-47)
This will run DP=4 with DP ranks 0 and 1 on the head node and ranks 2 and 3 on the second node:
```bash
# Node 0 (with ip address 10.99.48.128)
vllm serve $MODEL --data-parallel-size 4 --data-parallel-size-local 2 \
--data-parallel-address 10.99.48.128 --data-parallel-rpc-port 13345
# Node 1
vllm serve $MODEL --headless --data-parallel-size 4 --data-parallel-size-local 2 \
--data-parallel-start-rank 2 \
--data-parallel-address 10.99.48.128 --data-parallel-rpc-port 13345
**File:** vllm/v1/engine/utils.py (L810-820)
```python
# Set up input and output addresses.
addresses = EngineZmqAddresses(
inputs=[
get_engine_client_zmq_addr(client_local_only, host)
for _ in range(num_api_servers)
],
outputs=[
get_engine_client_zmq_addr(client_local_only, host)
for _ in range(num_api_servers)
],
)
File: vllm/v1/engine/utils.py (L888-890)
handshake_address = get_engine_client_zmq_addr(
handshake_local_only, host, parallel_config.data_parallel_rpc_port
)
data-parallel-rpc-port 详解
data-parallel-rpc-port 是 vLLM 数据并行部署中用于节点间 RPC 通信的端口号,默认值为 29550。 1
完整代码流程
1. 配置定义
在 ParallelConfig 类中定义默认值:
data_parallel_rpc_port: int = 29550
"""Port for data parallel messaging."""
```[1](#12-0)
### 2. CLI 参数解析
在 `EngineArgs.add_cli_args()` 中注册命令行参数:
```python
parallel_group.add_argument(
"--data-parallel-rpc-port",
"-dpp",
type=int,
help="Port for data parallel RPC communication.",
)
```[2](#12-1)
### 3. 配置创建
在 `create_engine_config()` 中处理端口配置:
```python
data_parallel_rpc_port = (
self.data_parallel_rpc_port
if (self.data_parallel_rpc_port is not None)
else ParallelConfig.data_parallel_rpc_port
)
```[3](#12-2)
### 4. ZMQ 地址创建
在 `launch_core_engines()` 中使用端口创建握手地址:
```python
handshake_address = get_engine_client_zmq_addr(
handshake_local_only, host, parallel_config.data_parallel_rpc_port
)
```[4](#12-3)
### 5. 节点间通信
在 `run_headless()` 中建立连接:
```python
host = parallel_config.data_parallel_master_ip
port = parallel_config.data_parallel_rpc_port
handshake_address = get_tcp_uri(host, port)
```[5](#12-4)
## 使用示例
在多节点部署中,所有节点必须使用相同的 RPC 端口:
```bash
# Node 0
vllm serve $MODEL --data-parallel-address 192.168.1.100 --data-parallel-rpc-port 13345
# Node 1
vllm serve $MODEL --headless --data-parallel-address 192.168.1.100 --data-parallel-rpc-port 13345
```[6](#12-5)
## Notes
该端口是数据并行集群的关键通信通道,用于:
- 节点发现和握手
- ZMQ socket 地址分配
- DP Coordinator 与 Engine Core 间的通信
确保防火墙允许该端口的通信,否则节点无法建立连接。 [7](#12-6)
Wiki pages you might want to explore:
- [Configuration and Initialization (vllm-project/vllm)](/wiki/vllm-project/vllm#2)
### Citations
**File:** vllm/config/parallel.py (L115-116)
```python
data_parallel_rpc_port: int = 29550
"""Port for data parallel messaging."""
File: vllm/engine/arg_utils.py (L852-857)
parallel_group.add_argument(
"--data-parallel-rpc-port",
"-dpp",
type=int,
help="Port for data parallel RPC communication.",
)
File: vllm/engine/arg_utils.py (L1632-1636)
data_parallel_rpc_port = (
self.data_parallel_rpc_port
if (self.data_parallel_rpc_port is not None)
else ParallelConfig.data_parallel_rpc_port
)
File: vllm/entrypoints/cli/serve.py (L187-189)
host = parallel_config.data_parallel_master_ip
port = parallel_config.data_parallel_rpc_port
handshake_address = get_tcp_uri(host, port)
File: docs/serving/data_parallel_deployment.md (L37-47)
This will run DP=4 with DP ranks 0 and 1 on the head node and ranks 2 and 3 on the second node:
```bash
# Node 0 (with ip address 10.99.48.128)
vllm serve $MODEL --data-parallel-size 4 --data-parallel-size-local 2 \
--data-parallel-address 10.99.48.128 --data-parallel-rpc-port 13345
# Node 1
vllm serve $MODEL --headless --data-parallel-size 4 --data-parallel-size-local 2 \
--data-parallel-start-rank 2 \
--data-parallel-address 10.99.48.128 --data-parallel-rpc-port 13345
**File:** docs/usage/security.md (L24-28)
```markdown
#### 3. **Data Parallel Configuration:**
- `data_parallel_master_ip`: IP of the data parallel master (default: 127.0.0.1)
- `data_parallel_master_port`: Port of the data parallel master (default: 29500)

免费领 200 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐

 29
29 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)