
ollama.service服务配置说明
vim /etc/systemd/system/ollama.service
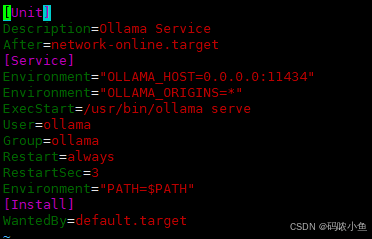
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
Environment="OLLAMA_HOST=0.0.0.0:11434
解释:监听地址和端口 0.0.0.0是对IP没有限制
Environment="PATH=/usr/local/bin:/usr/bin:/bin:/usr/local/games:/usr/games"
解释:定义可执行文件的搜索路径
Environment="OLLAMA_SCHED_SPREAD=true"
解释:调用分散模式多显卡的情况处理多并发的情况下可以减少时间
Environment="OLLAMA_NUM_PARALLEL=15"
解释:最大线程数,同时允许的最大处理并非数
Environment="OLLAMA_MAX_LOADED_MODELS=1"
解释:最大模型数,同时可以加载最多几个模型(我三张显卡的情况 llama3 70B,和一个27B并行建议1-2)
Environment="OLLAMA_MODELS=/mnt/rayse/files/ollama/models"
解释:模型存储路径
Environment="OLLAMA_KEEP_ALIVE=1h"
解释:模型加载后保留的时间,超过1小时,就卸载了,就要从新加载模型。
ExecStart=/usr/bin/ollama serve
解释:启动服务的指令
User=ollama
解释:指定运行服务的用户,服务将以 ollama 用户的身份运行
Group=ollama
解释:指定运行服务的用户组,服务将属于 ollama 用户组。
Restart=always
解释:配置服务异常停止后的自动重启
RestartSec=3
解释:设置服务停止后重新启动的时间间隔
Environment="CUDA_VISIBLE_DEVICES=0,1
解释:在多张显卡的情况下只用显卡0和显卡1进行运行服务。
[Install]
WantedBy=default.target

免费领 200 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐

 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)