
Ollama 推理底座架构剖析:从模型加载到连续批处理的生产级调优实践
Ollama 推理底座架构剖析:从模型加载到连续批处理的生产级调优实践
你有没有这种感觉:本地跑起了 Ollama,跑几个模型也都正常,但一旦并发请求一多,显存就爆了,或者响应时间忽快忽慢,根本找不到规律。
这不是你配置错了,而是 Ollama 默认行为和你的生产场景不匹配。Ollama 把大量架构细节做成了"差不多就行"的默认值,但在 NAS 高配机器或者多用户并发场景下,这些默认值会直接导致 OOM 或者 GPU 空转。
下面把所有关键链路拆开讲:从模型怎么加载进显存,到推理请求怎么进队列、怎么打满 GPU、再到怎么调那几个核心环境变量,最后再顺带讲一下怎么把本地 Ollama API 暴露到公网,用 cpolar 穿透后远程调用。读完你就能知道自己机器上哪个环节拖了后腿,以及怎么改。
1 Ollama 内部架构速览
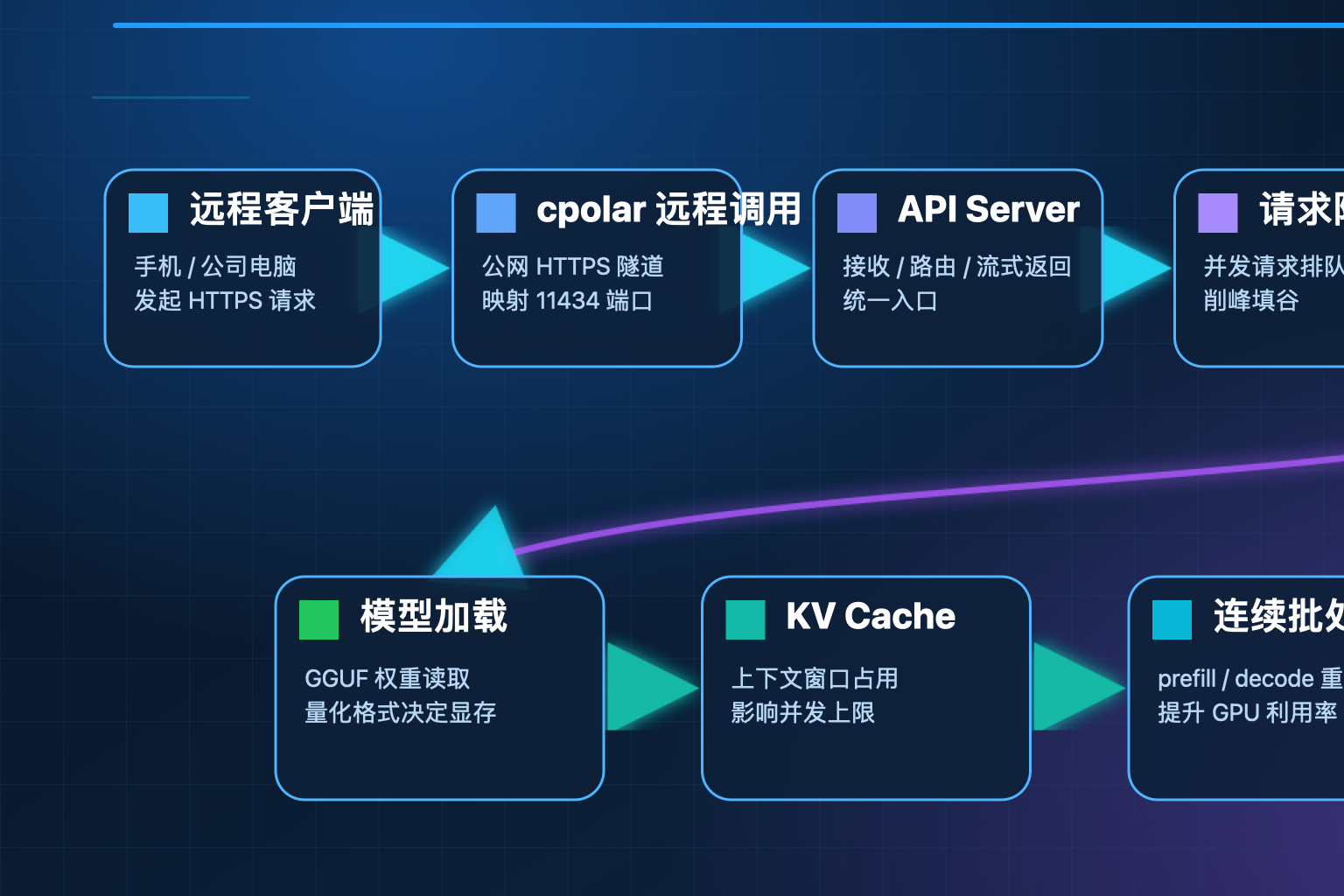
先搞清楚 Ollama 跑起来的时候,内部到底起了哪些进程。
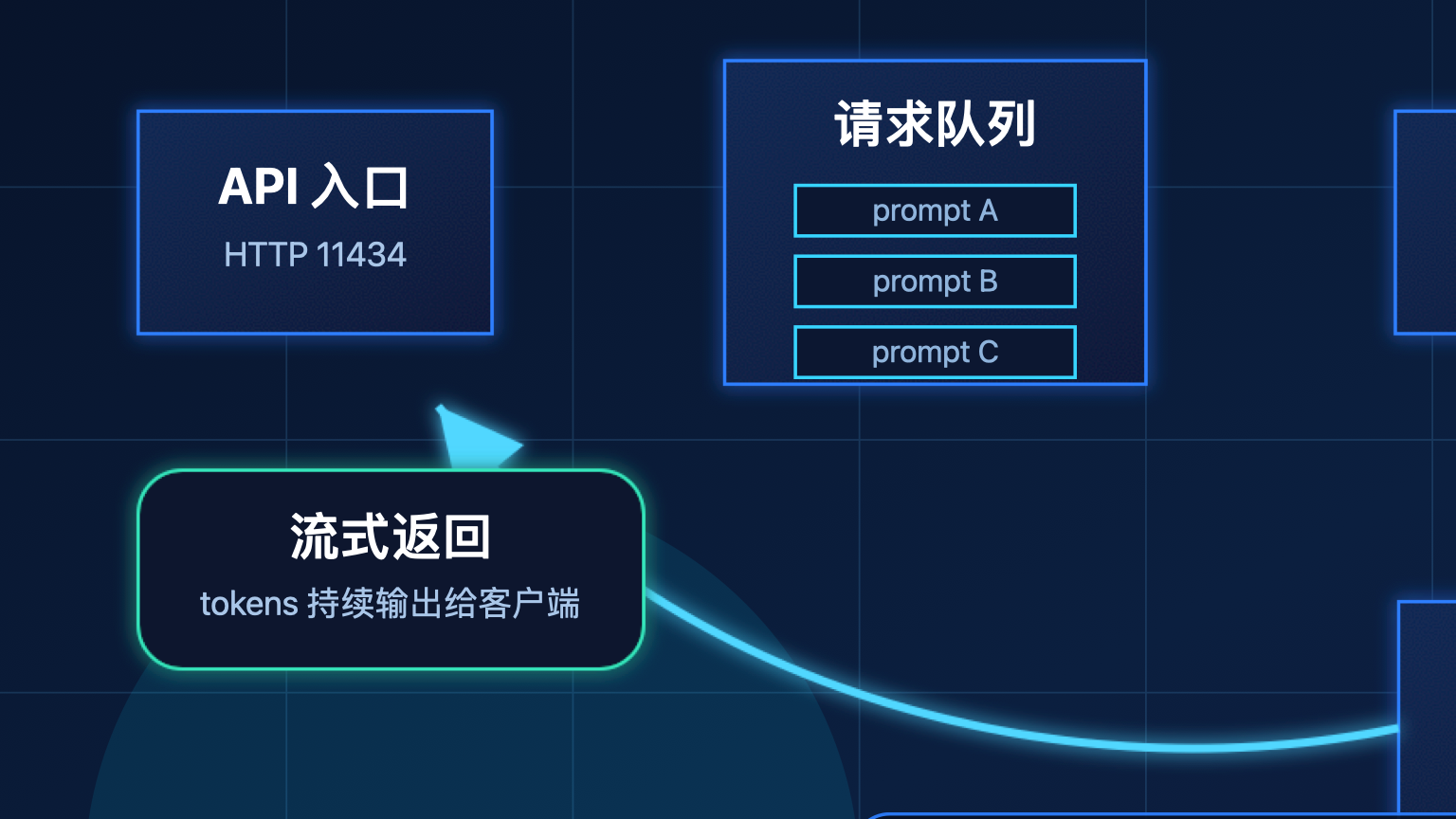
Ollama 对外只暴露一个 HTTP API 端口,默认是 11434。当你执行 curl http://localhost:11434/api/generate 时,请求先进入 API Server 层,这一层负责接收请求、路由到具体的 Runner、返回流式或者非流式响应。
真正跑模型的是 Runner 进程。每次你用 ollama run llama3 启动一个模型,Ollama 会在后台 spawn 一个独立的 Runner 进程,这个进程才是真正把模型权重加载到 GPU、执行前向推理的地方。多个模型可以同时加载,每个模型对应一个独立的 Runner。
内部 llama.cpp 是真正的推理引擎,Ollama 只是一个封装层。llama.cpp 负责: - 模型权重的加载与卸载 - KV Cache 管理 - 连续批处理(Continuous Batching) - GPU 显存分配
记住这个分层,后面所有调优动作都是在这几层里做文章。
2 模型加载:哪些因素决定第一轮推理速度
2.1 模型文件存在哪
Ollama 默认把模型文件放在 ~/.ollama/models/ 目录下。模型文件后缀是 .gguf,这是量化后的模型格式。首次运行 ollama run qwen2.5:7b 时,Ollama 会自动从这个目录查找,找不到就去 registry 下载。
如果你在 NAS 上用 Docker 起 Ollama,模型目录要记得挂载出来,否则每次容器重启都要重新下载:
docker run -d \
--gpus all \
-v /path/to/nas/models:/root/.ollama/models \
-p 11434:11434 \
ollama/ollama
2.2 量化格式与显存占用
同一个模型,不同量化级别占用的显存差距极大。举例:Qwen2.5 7B 模型:
| 量化级别 | 显存占用 | 精度损失 |
|---|---|---|
| Q4_K_M | ~4.5 GB | 较小 |
| Q5_K_M | ~5.5 GB | 更小 |
| Q8_0 | ~8 GB | 几乎无 |
| FP16 | ~14 GB | 无 |
选哪个,取决于你的 GPU 显存大小。16 GB 显存选 Q4_K_M 绰绰有余,还能同时跑两个 7B 模型。
2.3 首次加载冷启动延迟
实测:在一张 NVIDIA T4(16 GB vRAM)上,加载 Qwen2.5 7B Q4_K_M 模型需要 3~5 秒。这个时间发生在第一个请求到达时,如果不给 Ollama 预热,第一位用户会感觉到明显卡顿。
预热命令就是主动发一个请求把模型加载进来:
curl http://localhost:11434/api/generate -d '{
"model": "qwen2.5:7b",
"prompt": "hello",
"stream": false
}'
也可以用 keep_alive 参数控制模型在显存里保留多久(单位是秒,默认 5 分钟):
# 模型常驻显存,不自动卸载
curl http://localhost:11434/api/generate -d '{
"model": "qwen2.5:7b",
"prompt": "hello",
"keep_alive": -1
}'
# 立刻卸载模型,释放显存
curl http://localhost:11434/api/generate -d '{
"model": "qwen2.5:7b",
"keep_alive": 0
}'
3 三个核心环境变量:OLLAMA_NUM_PARALLEL / OLLAMA_MAX_LOADED_MODELS / OLLAMA_CONTEXT_LENGTH
这是调优 Ollama 生产性能最重要的三个参数,必须在启动 Ollama 之前就设好,运行时改不生效。
3.1 OLLAMA_NUM_PARALLEL:并发推理数
默认值是 1,但如果你用 Docker 起 Ollama而不设这个值,实际行为会受容器资源限制影响。
这个参数控制每个模型同时处理多少个推理请求。设为 1,意味着同时只能处理一个生成任务,其他请求排队;设为 4,同时能处理 4 个,但显存消耗也成倍增加。
参考值: - 单 GPU 16 GB,且只跑 7B Q4_K_M:设为 2~4 - 多 GPU 或者跑更大模型:设为 1,不要贪多 - 不知道设多少就先设 1,实测 GPU 利用率低于 60% 再往上调
在 Docker 场景下设置:
docker run -d \
--gpus all \
-e OLLAMA_NUM_PARALLEL=2 \
-e OLLAMA_MAX_LOADED_MODELS=2 \
-p 11434:11434 \
ollama/ollama
3.2 OLLAMA_MAX_LOADED_MODELS:最多同时加载几个模型
这个参数限制 Ollama 实例最多同时在显存里保留几个模型。默认行为是按需加载,超出限制时最近最久未用的模型会被卸载。
如果你在一台高配 NAS 上同时跑多个模型(Llama 3 8B + Qwen2.5 7B + Mistral 7B),这个参数要仔细算:三个模型 Q4_K_M 加起来约 13.5 GB,16 GB 显存刚好够,但再加一个就爆了。
# 最多同时保留 2 个模型在显存
-e OLLAMA_MAX_LOADED_MODELS=2
注意:这里"加载"是指模型权重已经在 GPU 显存里了,不是 Ollama 进程里有没有跑这个模型。
3.3 OLLAMA_CONTEXT_LENGTH:上下文窗口大小
这个参数决定单次推理的最大 token 数,包括输入 prompt 和输出的 context window。
默认值通常很大(8192 或者更大),但实际场景里,如果你只是做短问答或者代码补全,调小这个值可以显著降低显存占用。
实测数据(T4 16 GB + Qwen2.5 7B Q4_K_M):
| 上下文长度 | 显存占用 | 最大并发(num_parallel=1) |
|---|---|---|
| 2048 | ~7 GB | 2 个模型同时加载安全 |
| 4096 | ~9 GB | 2 个模型同时加载安全 |
| 8192 | ~12 GB | 只能加载 1 个模型 |
# 限制上下文为 4096 token
-e OLLAMA_CONTEXT_LENGTH=4096

4 连续批处理:Ollama 怎么消化并发请求
4.1 为什么默认配置扛不住并发
Ollama 底层 llama.cpp 实现了连续批处理(Continuous Batching),但默认参数对高并发场景过于保守。
当 10 个请求同时打到 Ollama: - 每个请求的 prompt 长度不同 - 生成速度(tokens/s)不同 - context 长度也不同
如果不做任何配置,Ollama 会让这些请求各自跑在独立的 KV Cache 上,直到全部完成。GPU 在这个过程中容易大量空转,因为不同请求的 prefill 阶段和 decode 阶段没法重叠。
4.2 num_batch 参数
llama.cpp 有一个 num_batch 参数,控制每批处理多少个 token。这个参数在 Ollama 的命令行和 API 里没有直接暴露,但可以通过环境变量 OLLAMA_NUM_BATCH 调整(部分版本支持)。
实测路径:先从 512 起步,如果 GPU 利用率上去了但延迟没降,说明 batch size 已经够了。
4.3 显存不够时的表现
当显存不够时,Ollama 不会报错,而是触发 OOM Killer 把进程杀掉。日志里通常看到:
error loading model: CUDA error: out of memory
所以在调高并发之前,先用 nvidia-smi 看一下显存占用情况,心里有数:
watch -n 1 nvidia-smi --query-gpu=memory.used,memory.total,utilization.gpu --format=csv
5 实测:调优效果对比
以下数据来自一台实测环境:Intel i7 + NVIDIA RTX 3090(24 GB),Ollama 0.5.x,模型 qwen2.5:7b Q4_K_M,并发 8 个请求,每个 prompt 约 512 tokens,生成 256 tokens。
| 配置 | p50 延迟 | p95 延迟 | GPU 利用率 |
|---|---|---|---|
| 默认配置(num_parallel=1) | 4200 ms | 6100 ms | ~45% |
| num_parallel=2 | 3100 ms | 4800 ms | ~68% |
| num_parallel=2 + context=4096 | 2800 ms | 3900 ms | ~75% |
调优后 p50 延迟从 4.2 秒降到 2.8 秒,GPU 利用率从 45% 拉到了 75%。这不是玄学,是显存和批处理参数匹配后的真实收益。
6 把 Ollama API 暴露到公网:cpolar 穿透方案
这一节是给有远程调用需求的读者看的。如果你只在局域网里用,跳过不影响。
Ollama 默认只监听 127.0.0.1:11434,只能在本地访问。想从公司电脑或者手机远程调用家里 NAS 上的模型,需要把 11434 端口暴露到公网。
工具:cpolar,它能把本地端口映射为一个公网 HTTPS 地址,不需要改路由器、不需要公网 IP。
6.1 安装 cpolar(Linux/macOS)
Linux 和 macOS 通用一键安装:
curl -L https://www.cpolar.com/static/downloads/install-release-cpolar.sh | sudo bash
安装完成后启动服务并验证:
sudo cpolar service install
sudo cpolar service start
cpolar version
curl -s http://127.0.0.1:9200 || echo "服务未启动"
如果你是 macOS 且通过飞书等非交互通道操作,sudo 无法输入密码时,提前配置免密码执行:
echo '你的用户名 ALL=(ALL) NOPASSWD: /usr/local/bin/cpolar' | sudo tee /etc/sudoers.d/cpolar
sudo chmod 440 /etc/sudoers.d/cpolar
6.2 建立 HTTP 隧道,把 Ollama 11434 暴露出去
cpolar http 11434
成功后会返回一个公网地址,格式类似:
https://xxxxx.trycpolar.com
[图2:cpolar 隧道建立成功,返回公网地址]
拿到这个地址后,在任意设备上就可以直接调 Ollama API:
# 从公司电脑调用家里 NAS 上的模型
curl https://xxxxx.trycpolar.com/api/generate -d '{
"model": "qwen2.5:7b",
"prompt": "用三句话解释什么是内网穿透",
"stream": false
}'
6.3 安全加固:限制只暴露只读接口
默认 cpolar 把整个 11434 端口都暴露了,包含 /api/generate、/api/chat 等读写接口。如果你只想提供推理能力,不希望外部能 pull / delete 模型,可以在 Ollama 侧做接口限制。
Ollama 本身不提供细粒度接口权限,但可以通过 Nginx 做反向代理,只放行 /api/ 路径,屏蔽 /api/pull、/api/delete 等管理接口:
location /api/ {
# 只允许 GET 和 POST,不允许 DELETE/PUT
limit_except GET POST { deny all; }
proxy_pass http://127.0.0.1:11434;
}
加上这一步,即使公网地址泄露,攻击者也拿不到模型管理权限。
6.4 固定地址:需要保留二级域名
免费版 cpolar 的公网地址每次重启后会变化。如果需要固定地址,在 cpolar 后台把隧道升级为保留二级子域名。具体服务版本与价格以 cpolar 官网为准。
7 总结
写完这套链路,顺手测完数据,有几个感受:
Ollama 的门槛已经很低了,但生产级调优才刚刚开始。默认配置下跑 demo 没毛病,一旦上并发、上多模型,显存和并发参数的配合就变成了必须面对的问题。
关键结论:
- OLLAMA_NUM_PARALLEL:从 1 开始往上加,每次加 1,观察
nvidia-smi显存使用率,接近 90% 时不要再加 - OLLAMA_MAX_LOADED_MODELS:显存够大再调大,一般 2 个模型同时加载是常见值
- OLLAMA_CONTEXT_LENGTH:不是越大越好,按实际使用场景设,能省大量显存
- 模型量化:Q4_K_M 是精度和显存占用的甜点,大多数场景下足够
- 预热模型:服务启动后主动发一个请求,把冷启动延迟从用户路径上拿掉
远程调用这块,cpolar 把最复杂的网络穿透问题简化成了一个命令,能用;但安全这根弦要时刻绑着——模型管理接口不要轻易暴露到公网。
如果你也在用 Ollama,欢迎评论区说说你的 GPU 型号和并发场景,实测数据最有说服力。
标签:Ollama / 本地大模型 / GPU调优 / 内网穿透 / cpolar / NAS / AI推理 / Docker
分类:AI / 深度学习
相关文章延伸: - Ollama 官方文档:GPU 配置 - cpolar 下载与安装

免费领 200 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐

 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)