- @qq_63013137
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
家里电脑可用跑哪个大模型?用硬件检测工具筛模型,再用 cpolar 远程体验私有 AI 家里电脑跑本地大模型,最容易踩的坑不是安装 Ollama,也不是下载模型,而是一上来就选了不可用自己机器的模型。 显存不够,模型加载失败;内存勉强够,回答速度慢到不想用;参数量看起来很大,实际体验却不如更小的新模型。与其凭感觉下载几十 GB 文件,不如先让硬件检测工具把机器能力摸清楚,再挑 1 到 2 个合适的
本文从 Ollama 安装、模型拉取、Open WebUI Docker 部署到局域网访问,完整演示本地大模型页面搭建流程,并补充临时公网访问方案。

从 CLAUDE.md、.cursorrules、AGENTS.md 到本地工具权限,梳理 AI 编程助手在仓库指令、敏感文件、命令执行和临时隧道中的安全边界,给出防御导向的检查清单。

本地运行 Claude Design 开源替代品生成产品原型页面,用 cpolar 把预览端口临时映射为 HTTPS 地址,发给产品经理、客户或异地同事实时评审;全程只暴露预览端口,不暴露项目目录、终端和 API Key。
Codex 日志异常怎么提前发现?本地 AI 工具观测面板 + cpolar 远程验收实战 Codex 这类本地 AI 编程工具一旦日志写入失控,最麻烦的地方不是“报错很红”,而是它常常躲在后台慢慢写盘。等磁盘告警、项目卡顿、SSD 写入量异常再回头查,已经晚了一拍。 这篇不聊泛泛的“AI 工具治理”,直接做一个能跑起来的小面板:本机扫描 Codex 相关日志,统计文件大小、更新时间、异常关键词命
HarmonyOS 7 之后怎么做真机调试?ArkTS 网络异常统一处理 + cpolar 远程给同事验收 我最近碰到一个很典型的鸿蒙开发场景:本地跑得很顺,一上真机就开始冒网络异常,调试窗口里一堆错误码,产品同事还在旁边催验收。这个时候最怕的不是报错本身,而是每个人看到的现象都不一样,最后排查方向越走越散。 这篇就按我自己整理过的一套方式来写:先把 HarmonyOS 7 之后的真机调试环境搭起

HarmonyOS 7 之后怎么做真机调试?ArkTS 网络异常统一处理 + cpolar 远程给同事验收 我最近碰到一个很典型的鸿蒙开发场景:本地跑得很顺,一上真机就开始冒网络异常,调试窗口里一堆错误码,产品同事还在旁边催验收。这个时候最怕的不是报错本身,而是每个人看到的现象都不一样,最后排查方向越走越散。 这篇就按我自己整理过的一套方式来写:先把 HarmonyOS 7 之后的真机调试环境搭起
围绕 HarmonyOS 7 之后的真机调试链路,整理 ArkTS 网络异常统一处理方式,并用 cpolar 把本地验收页临时共享给同事,降低远程联调和验收成本。

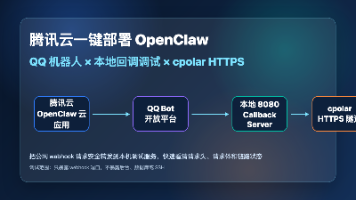
腾讯云一键部署 OpenClaw 打造 QQ 机器人:本地回调调试怎么用 cpolar 跑通? QQ 机器人最让人抓狂的地方,往往不是“机器人创建失败”,而是消息到底有没有打到自己的服务上。 腾讯云云应用已经把 OpenClaw 的部署流程压得很短,QQ 通道也能按向导接进去。但一到本地调试回调、看事件内容、排签名校验、让同事远程验收,localhost:8080 立刻变成一道墙:QQ 开放平台访
Ollama 推理底座架构剖析:从模型加载到连续批处理的生产级调优实践 你有没有这种感觉:本地跑起了 Ollama,跑几个模型也都正常,但一旦并发请求一多,显存就爆了,或者响应时间忽快忽慢,根本找不到规律。 这不是你配置错了,而是 Ollama 默认行为和你的生产场景不匹配。Ollama 把大量架构细节做成了"差不多就行"的默认值,但在 NAS 高配机器或者多用户并发场景下,这些默认值会直接导致