
AMD Hello-ROCm LoRA微调(二)
安装依赖
先执行pip uninstall torchvision
注意这边如果执行了之前环境配置操作,也要执行这一步操作,因为上一步操作中是这样安装的:
uv pip uninstall torchvision uv pip install vllm torchvision \ --no-cache \ --index-url https://mirrors.aliyun.com/pypi/simple/ \ --extra-index-url https://wheels.vllm.ai/rocm/ \ -U
而两次操作两个库不是从同一个源(一个阿里云一个腾讯云)安装的,而且 torchvision 的版本是预编译给另一个 PyTorch 构建的,否则按教程的操作运行Notebook示例文件时,会出现 torchvision::nms does not exist 和循环导入等错误。
官方教程给出的命令是下面这样:
uv pip install -U vllm modelscope transformers accelerate datasets trl peft scikit-learn pandas tqdm torchvision \
--no-cache \
-i https://mirrors.cloud.tencent.com/pypi/simple/ \
--extra-index-url https://wheels.vllm.ai/rocm/
|
字段 |
含义 |
|
! |
Jupyter Notebook 中执行系统命令的前缀(在终端中可直接去掉) |
|
uv |
一种用 Rust 编写的高性能 Python 包管理器,可替代 pip,安装速度更快 |
|
pip install |
uv 模拟的 pip 安装命令 |
|
-U (或 --upgrade) |
升级所有列出的包到最新可用版本(若已安装则升级,否则直接安装) |
|
待安装的包列表 |
一系列用于大模型推理、微调和数据处理的库:vllm(LLM 推理引擎)、modelscope(阿里模型库)、transformers/datasets/accelerate/trl/peft(Hugging Face 模型、数据、分布式、强化学习微调、参数高效微调)、scikit-learn(机器学习)、pandas(数据分析)、tqdm(进度条)、torchvision(PyTorch 视觉工具) |
|
--no-cache |
强制不使用本地缓存,从远程重新下载所有包以确保获取最新文件(下载会变慢) |
|
-i https://mirrors.cloud.tencent.com/pypi/simple/ |
指定主软件包索引源为腾讯云 PyPI 镜像,用于在国内加速下载大部分 Python 包 |
|
--extra-index-url https://wheels.vllm.ai/rocm/ |
额外添加一个索引源,专门提供 vLLM 针对 AMD ROCm 平台编译的 wheel 包,确保在 AMD GPU 上能正确安装和使用 vLLM |
前期准备
要微调模型要先准备好模型、数据集。


配置训练环境
接着要配置训练环境,通常包括:
GPU资源
这里是单卡环境。
数据集划分
1.比例划分:Train :Test(8:2);Train:Eval:Test(6:2:2)
2.设置集合样本数量如TRAIN_LIMIT、EVAL_LIMIT等参数,比如取Top 1000
精度
- 模型权重的存储数据类型MODEL_DTYPE。
|
类型 |
bit |
数值范围 |
特点 |
典型用途 |
|
FP32 |
32 |
±10^38 |
最高精度,训练基准 |
全精度训练与推理 |
|
FP16 |
16 |
±65504 |
显存减半,数值范围窄,可能溢出 |
混合精度训练(需梯度缩放) |
|
BF16 |
16 |
±10^38(同FP32) |
显存减半,动态范围大,几乎无需梯度缩放 |
混合精度训练 |
|
INT8 |
8 |
-128 ~ 127 |
再减半显存,需量化校准,略损精度 |
推理加速、边缘部署 |
|
INT4 |
4 |
-8 ~ 7 |
极致压缩,精度损失较大,需仔细量化 |
极低资源推理(如 llama.cpp Q4) |
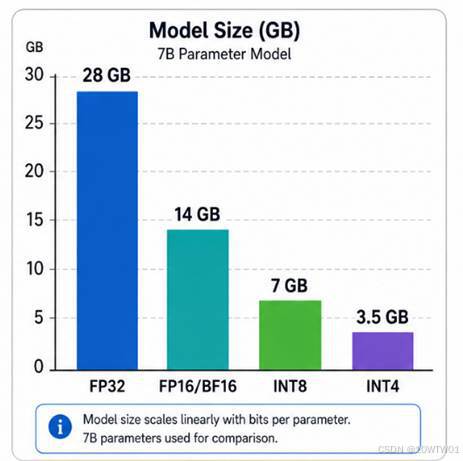
2.训练参数精度:常见的有FP16、BF16、FP32,一般也受显卡影响。
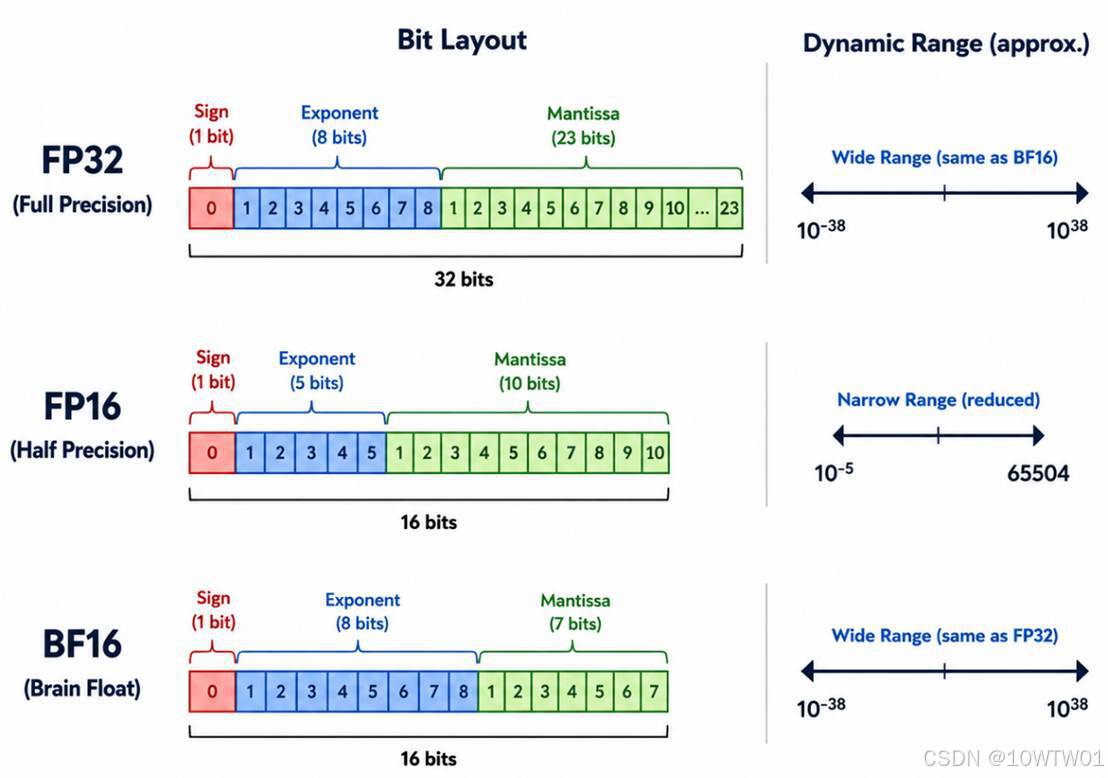
- FP32精度最高,但训练需要显存也多。
- BF16牺牲了小数位的精度,但既能节省显存、加快训练,又能保持较大数值范围。
- FP16 的数值范围较小,训练时容易出现梯度溢出,通常需要配合梯度缩放
随机种子
因为计算机生成的是伪随机数,其生成函数可以看作:下一个数 = f(当前状态, 种子),相当于给定种子调用random()拿到的数一定相同,让数据 shuffle、LoRA 初始化和训练过程尽量可复现(因为复现性还受计算差异如硬件一致性、确定性算法等影响)。
def setup_seed(seed: int = 42):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
set_seed(seed)
if torch.cuda.is_available():
torch.cuda.manual_seed_all(seed)
setup_seed(SEED)
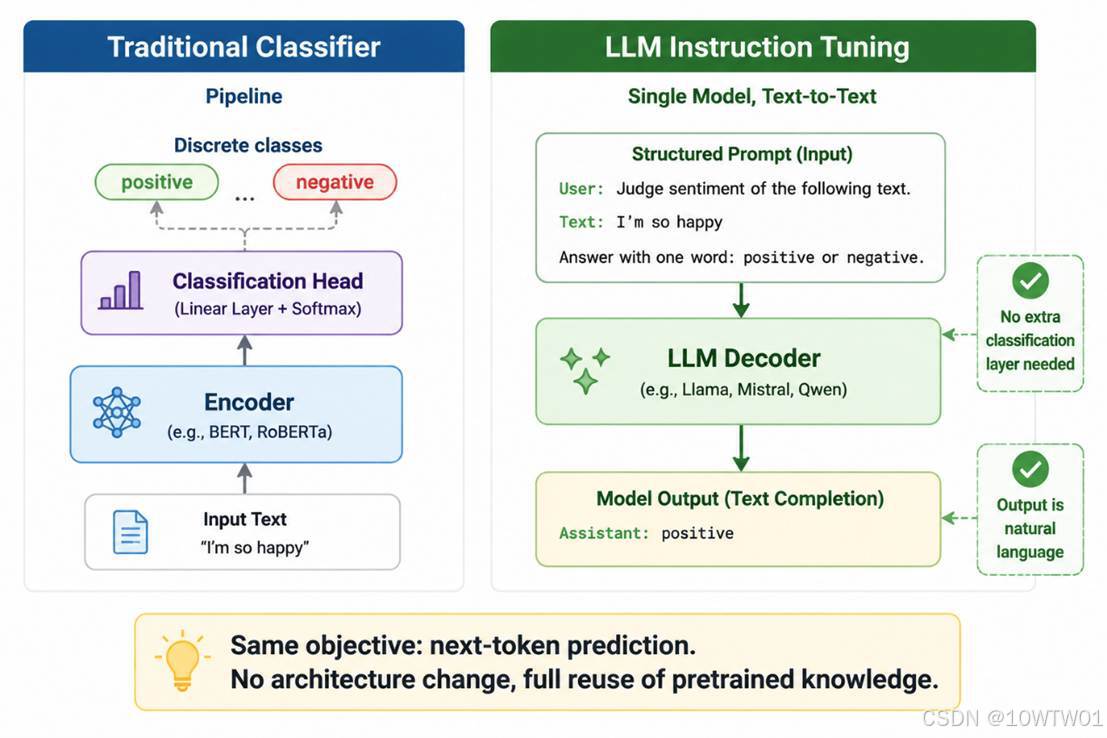
指令微调(复用原有架构以及knowledge)
因为我们想要想要微调后的模型实现情绪分类任务(classification task),但对于LLM来说本质上仍然是生成任务(generation task)而不仅仅是特征到标签的映射,所以要把分类任务重新包装成生成任务,即变成一个prompt-completion 格式数据:
- prompt:system + user
- completion:assistant 只输出对应的情绪标签
def to_prompt_completion(example):
text = example["text"]
label = label_names[example["label"]]
user_content = f"Classify the emotion of this text:\n\n{text}"
return {
"prompt": [
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": user_content},
],
"completion": [
{"role": "assistant", "content": label},
],
}
sft_dataset = dataset.map(
to_prompt_completion,
remove_columns=dataset["train"].column_names,
)
batch_size
每次训练传多少个数据进去batch。
比如有 1000 条对话训练数据,设定 batch_size = 8:
模型一次拿 8 条数据,算它们的平均损失;
反向传播时,基于这 8 条数据产生的平均梯度来更新一次权重;
跑完整个数据集需要 1000 / 8 = 125 次参数更新,这 125 步称为 1 个 epoch。
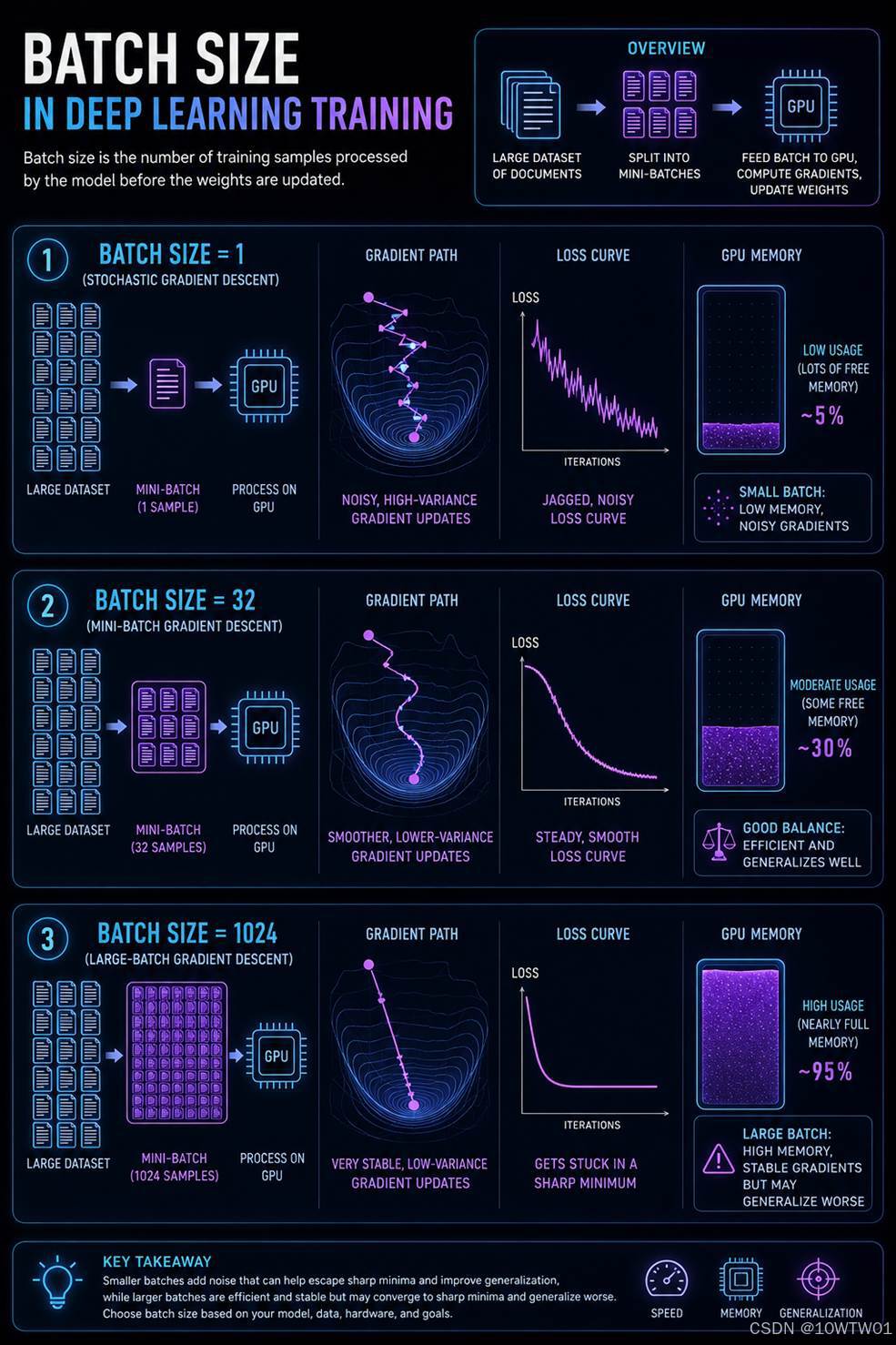
而模型训练时的显存占用可以拆成三块:
- 模型参数本身(权重 + 优化器状态):模型结构不变就固定下来了。
- 中间激活值:在多层神经网络中,每一层的梯度都依赖于该层的输入激活值。所以前向传播时产生的临时数据,必须存到反向传播用。其体积 ≈ 单条样本激活值 × batch size。
神经网络的训练本质是求梯度(参数对损失的影响),用的是链式法则。
举例类比:函数 y = f(g(x)),要算 dy/dx,需要:
dy/dx = f'(g(x)) * g'(x)
其中 g(x) 就是中间激活值,g'(x) 计算时需要用到 x 的值。
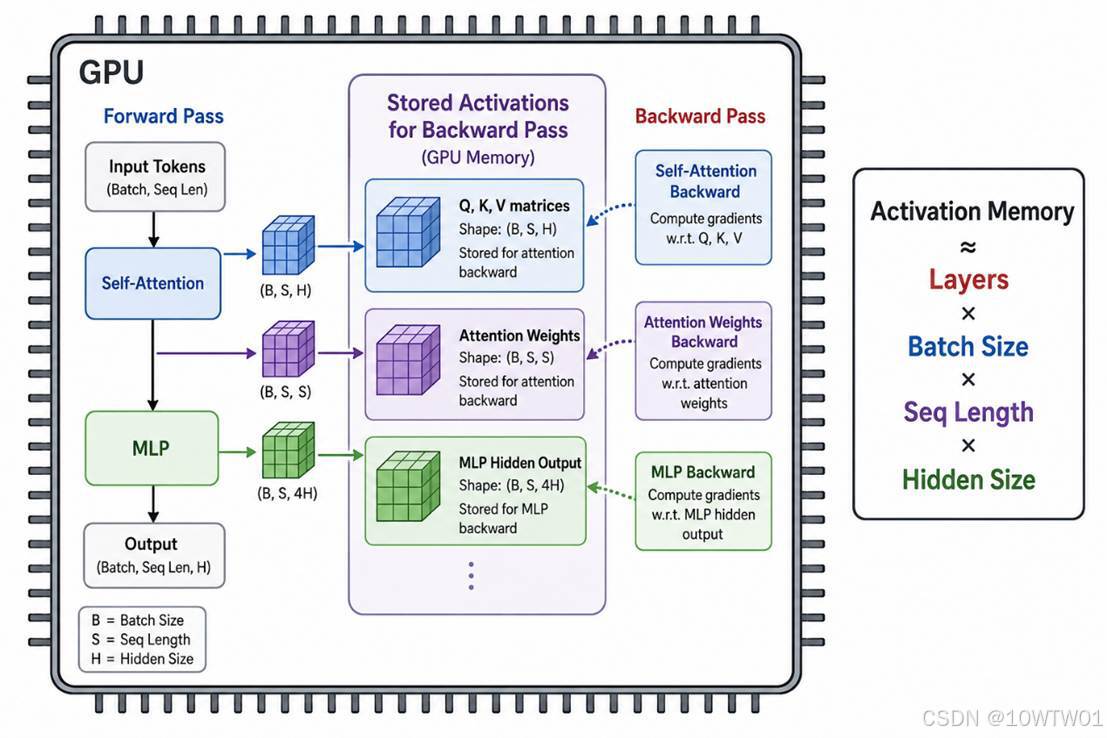
- 数据本身:输入的 token 张量等,也跟 batch size 成正比。
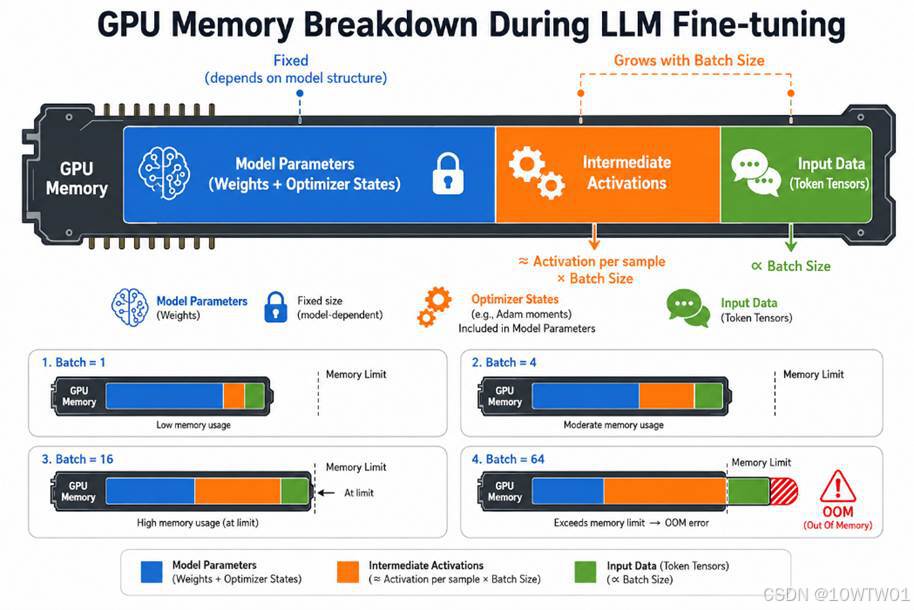
所以遇到GPU OOM可以考虑减小batch_size或降低前文所提的精度等。
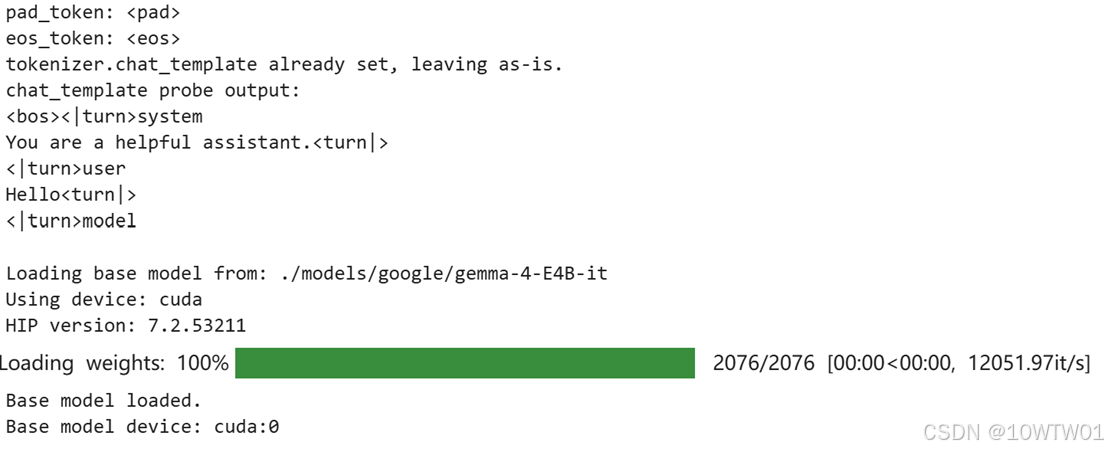
加载 tokenizer 和基础模型
Tokenizer(分词器)
组成:词汇表 + 特殊标记 + 格式化模板,把自然语言转成模型需要的数字序列。其实推理的时候也是需要的,不过模型会内置
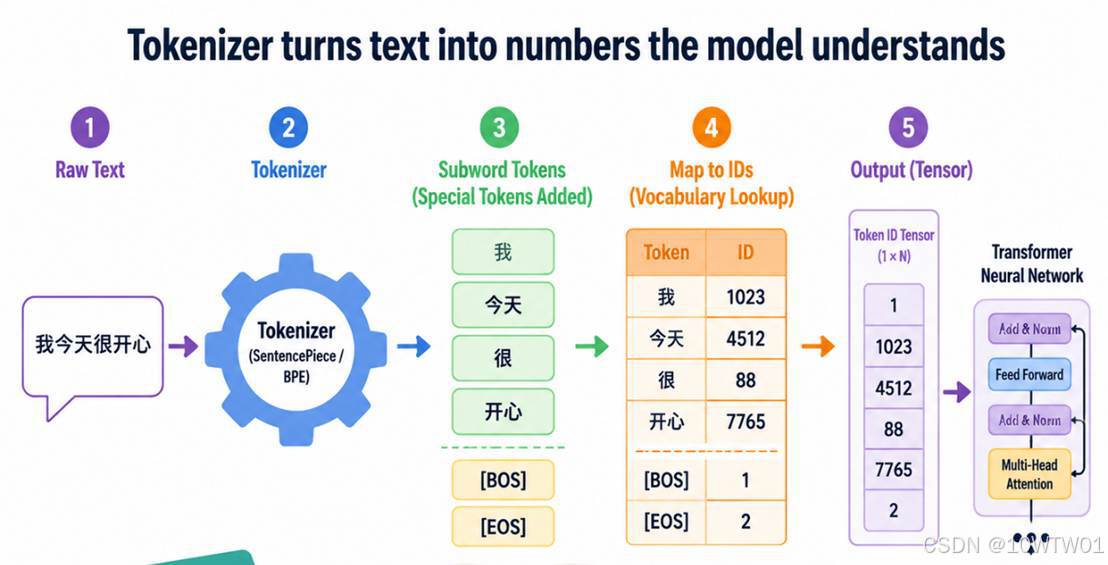
- tokenizer.json(词汇表与分词规则)
- tokenizer_config.json(特殊标记、chat_template 等)
- special_tokens_map.json
加载模型
由于本实验是在单卡上跑的,所以训练加载模型时要配置如下参数:
1.不用 device_map="auto":device_map="auto" 是 Hugging Face transformers 为多卡、CPU offload 设计的自动分配器。单卡场景下如果用了,有时会把部分层放到 CPU,或者引入额外的通信开销,反而增加显存占用甚至变慢。
不加这一项,模型就只会加载到单张 GPU 上(或先加载到 CPU,后续由 Trainer 统一移动到 GPU),简单可控。
2.不用 bitsandbytes 4bit
4bit 量化(load_in_4bit=True)能把模型权重大幅压缩,显存省很多,但会带来两个问题:
精度损失:微调时可能影响最终性能。
与某些 Trainer 特性不兼容:比如梯度检查点、优化器状态等有时会出小问题。
3 加载后交给 SFTTrainer 管理设备:不需要自己手动调用 .cuda() 或 .to(device)。把模型直接传给 SFTTrainer,它会在内部自动把模型移动到训练所用的设备(比如 cuda:0),并且管理好数据、优化器、模型之间的设备一致性。避免手动管理设备时常见的错误(比如模型和数据不在同一设备)。不过通常还是要.cuda().to(device)自己配置。
4 开启 gradient_checkpointing=True 来节省显存(计算时间换显存空间)
正常情况下,前向传播每一层产生的中间激活值(隐藏状态、注意力矩阵等)都要保存在显存里,等着反向传播时用。开启梯度检查点后,只保留少量层的激活值作为“检查点”,其余层的前向结果直接丢弃。等到反向传播需要时,再从最近的检查点重新计算出来。显存占用显著下降,代价是大约 20~30% 的额外计算量。
推理辅助函数
微调前后都用同一套推理函数做评估,方便对比模型效果。extract_label() 用于从模型生成文本里提取对应的label(数据集的情绪标签集合,固定映射)。如果提取不到,会被记为 INVALID(相当于模型没有输出对应的情绪标签)。
def extract_label(raw_text: str) -> str:
raw_text = raw_text.strip().lower()
match = LABEL_PATTERN.search(raw_text)
if match:
return match.group(1)
tokens = raw_text.split()
if not tokens:
return "INVALID"
return tokens[0].strip(".,!?:;\"'()[]{}")
def generate_label(model, tokenizer, user_text: str, system_prompt: str = SYSTEM_PROMPT, max_new_tokens: int = 4) -> str:
user_content = f"Classify the emotion of this text:\n\n{user_text}"
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_content},
]
device = next(model.parameters()).device
inputs = tokenizer.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt",
)
inputs = {k: v.to(device) for k, v in inputs.items()}
input_len = inputs["input_ids"].shape[-1]
model.eval()
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=max_new_tokens,
do_sample=False,
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id,
)
raw_pred = tokenizer.decode(outputs[0][input_len:], skip_special_tokens=True).strip()
return extract_label(raw_pred)
评估函数
评估指标包括:
|
指标 |
含义 |
|
accuracy |
预测正确的样本占总样本的比例,说明整体有多准(但类别不均衡时会被带偏) |
|
macro_f1 |
对每个类别分别计算 F1,然后取平均(不加权),说明小类(样本少的情绪)是否也被照顾到了 |
|
invalid_predictions |
模型没有输出合法标签的样本数,说明模型是否遵循了指令,输出格式是否稳定利用推理函数来计算得出。 |
|
classification_report |
包含每个类别的 precision、recall、f1-score,说明每一个具体情绪的判断质量 |
|
confusion_matrix |
以热力图或矩阵展示真实 vs 预测的分布,说明最容易混淆的情绪对(如“愤怒” vs “悲伤”) |
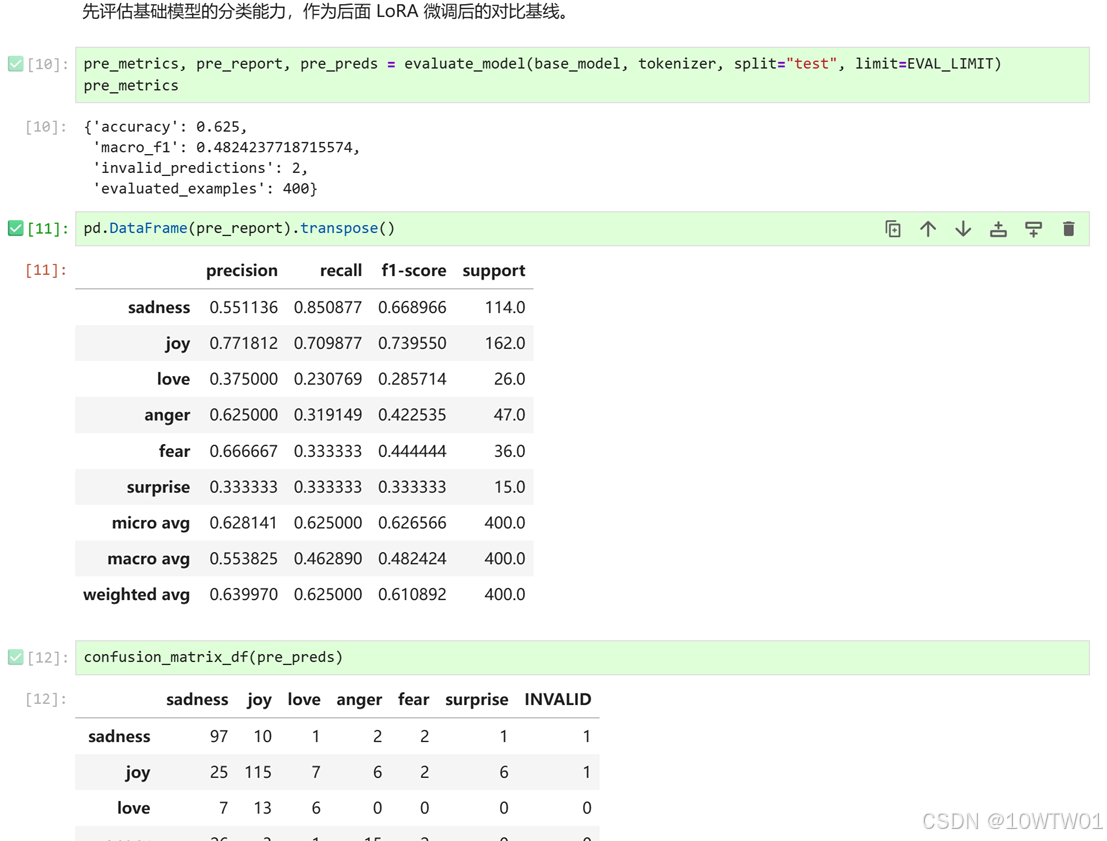
微调前评估
配置 LoRA
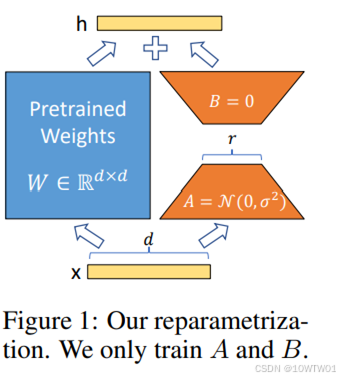
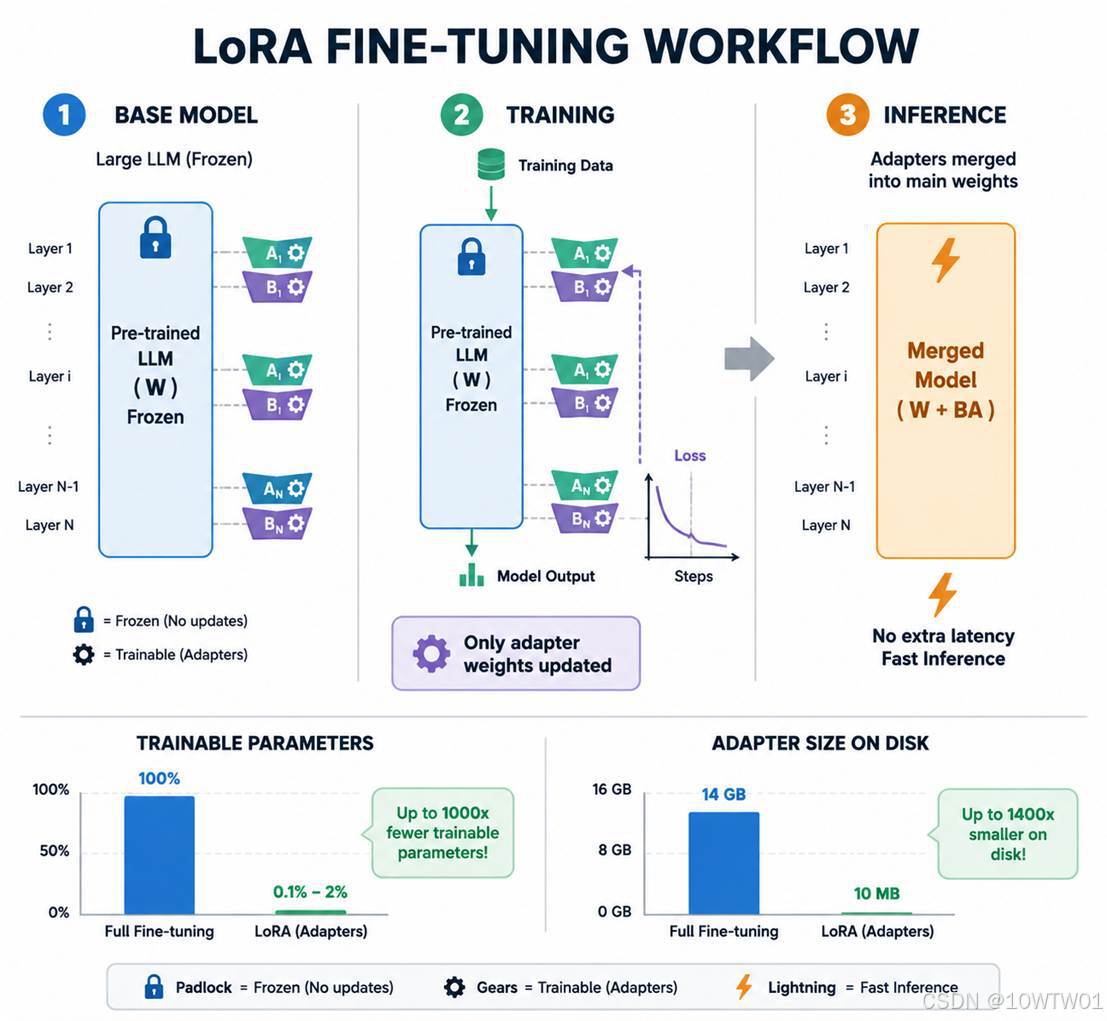
LoRA(Low-Rank Adaptation)是目前大语言模型微调最主流的方法。它不修改原始模型权重,而是在特定层旁路插入小的、可训练的秩分解矩阵,只更新这些小矩阵。可以形象的类比为:
- 全量微调:把原书每一页都擦掉重写,成本极高,而且一旦写坏书就废了。
- LoRA:在每一页上贴一张极薄的便利贴,只写要补充或修改的内容。原书正文完全不动,但阅读时会把便利贴的内容和原文叠加,最终效果相当于一本新书。
数学上,原有权重矩阵 W 保持不变,LoRA 添加两个小矩阵 A 和 B,使得:
新权重=W+A×B
其中A和B都是低秩矩阵(参数量远小于 W)。训练时只更新 A 和 B,原模型W冻结。
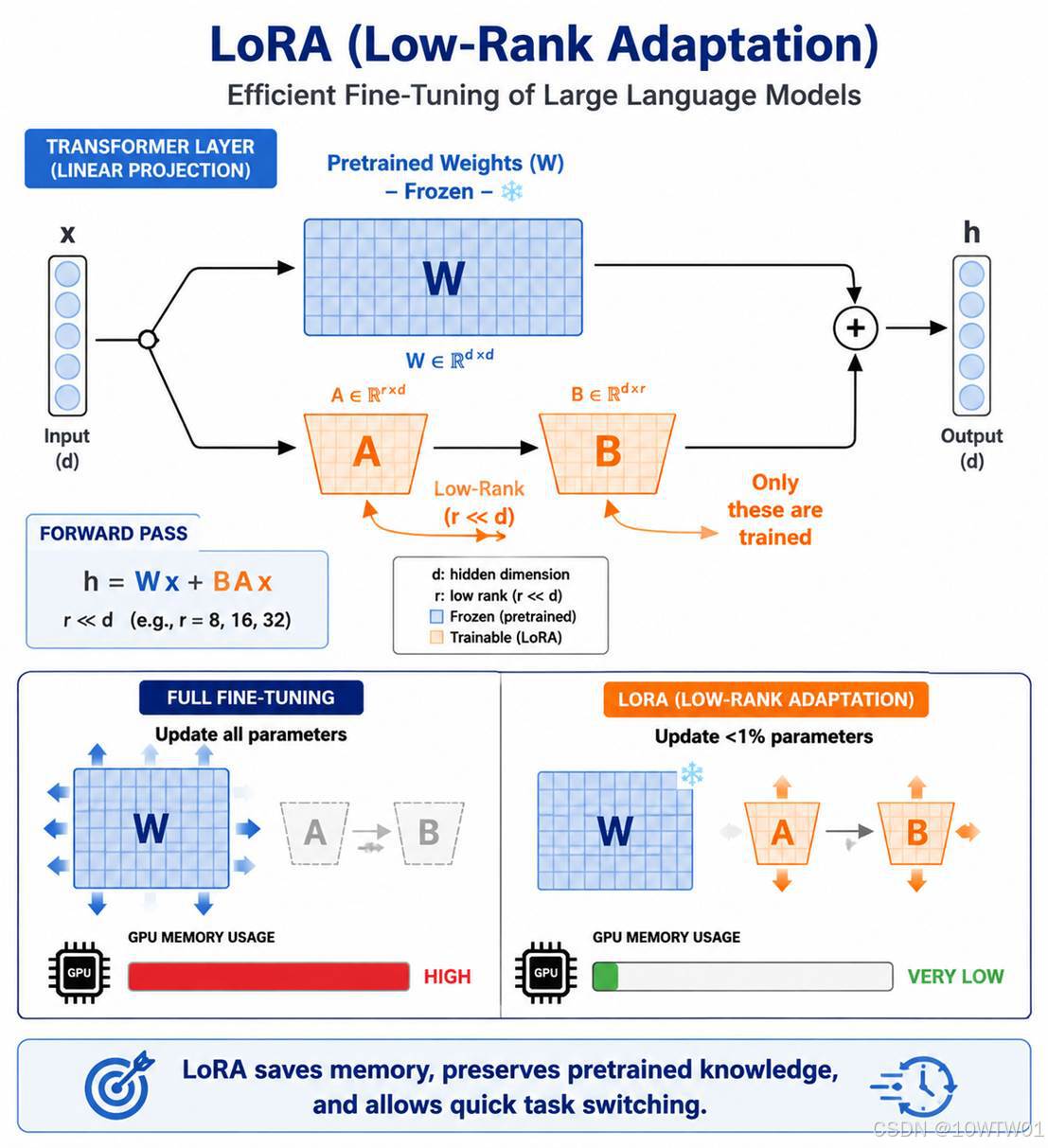
教程中使用target_modules="all-linear",表示尽量给模型中的线性层加 LoRA,可以改成指定模块名控制显存和训练速度,也会影响训练效果。
定义训练参数
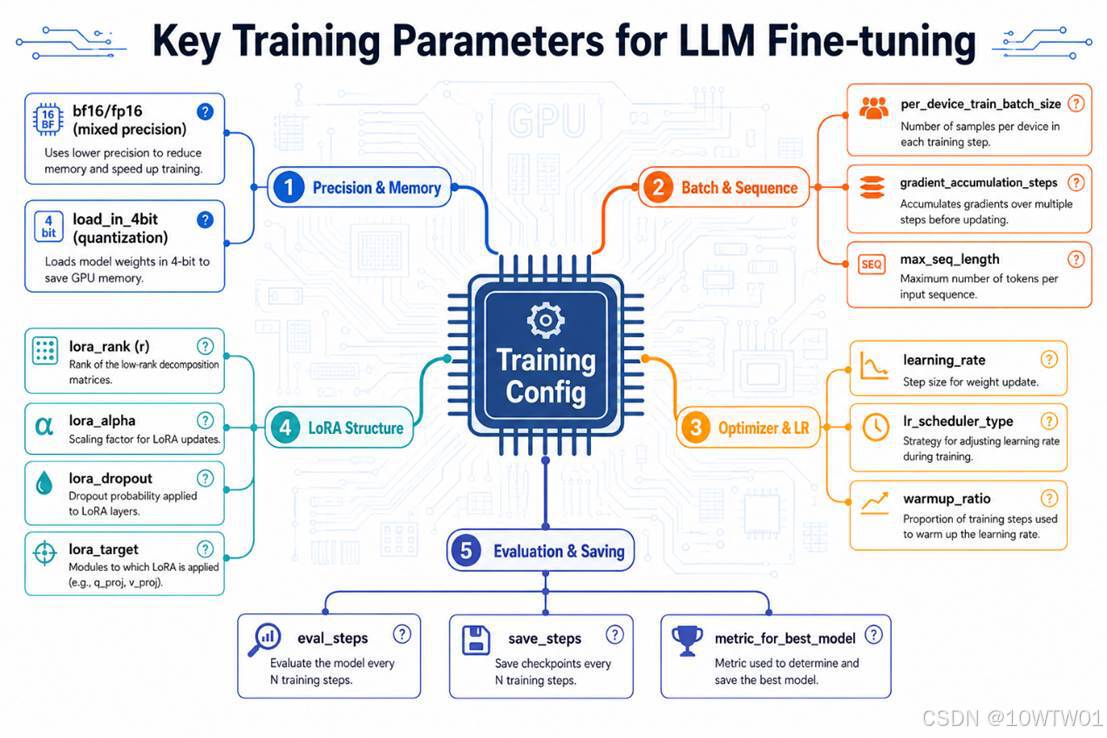
|
类别 |
参数 |
作用 |
典型值 / 说明 |
|
精度与显存 |
MODEL_DTYPE |
模型权重的存储类型 |
bfloat16(支持 BF16 的卡)或 float16 |
|
bf16 / fp16 |
开启混合精度训练 |
二选一,BF16 更稳定 |
|
|
load_in_4bit |
4-bit 量化加载原模型(QLoRA) |
True 时显存大幅降低 |
|
|
批次与序列 |
per_device_train_batch_size |
单张 GPU 一次前向的样本数 |
1–4(显存受限) |
|
gradient_accumulation_steps |
梯度累积步数,等效 batch = batch_size × 累积步数 |
8–32,用于撑大有效 batch |
|
|
max_seq_length / cutoff_len |
单条样本最大 token 数,超出截断 |
512–2048(按任务需要) |
|
|
优化器与学习率 |
learning_rate |
更新步长 |
LoRA 推荐 1e-4 ~ 5e-4,全量 1e-5 |
|
optimizer |
优化算法 |
adamw_torch、adamw_8bit(省显存) |
|
|
lr_scheduler_type |
学习率调度策略 |
cosine 或 linear,配合 warmup |
|
|
warmup_ratio |
前期缓慢增加学习率的比例 |
0.03–0.1,避免初期震荡 |
|
|
max_grad_norm |
梯度裁剪阈值 |
1.0,防梯度爆炸 |
|
|
训练轮次 |
num_train_epochs |
全量数据重复次数 |
1–3,指令微调不宜过多 |
|
max_steps |
最大更新步数(与 epoch 二选一) |
按需设置 |
|
|
LoRA 结构 |
lora_rank (r) |
低秩矩阵的秩,决定适配器容量 |
8–64,越高表示可学习参数越多 |
|
lora_alpha |
缩放系数,实际学习率 ∝ alpha/r |
通常设为 rank 的 2 倍 |
|
|
lora_dropout |
适配器 dropout,正则化 |
0.05–0.1 |
|
|
lora_target |
要添加适配器的模块 |
q_proj,v_proj 等 |
|
|
评估与保存 |
eval_steps |
每隔多少步在验证集上评估 |
100–500 |
|
save_steps |
每隔多少步保存一次 checkpoint |
与 eval_steps 一致 |
|
|
save_total_limit |
最多保留多少个 checkpoint |
2–3,避免占满磁盘 |
|
|
metric_for_best_model |
选择最佳模型的指标 |
eval_loss 或 macro_f1 |
training_args = SFTConfig(
output_dir=OUTPUT_DIR,
per_device_train_batch_size=4,
per_device_eval_batch_size=1,
gradient_accumulation_steps=4,
learning_rate=1e-4,
weight_decay=0.01,
lr_scheduler_type="linear",
warmup_steps=50,
num_train_epochs=1,
logging_steps=5,
eval_strategy="steps",
eval_steps=25,
save_strategy="steps",
save_steps=25,
save_total_limit=2,
metric_for_best_model="eval_loss",
greater_is_better=False,
gradient_checkpointing=True,
bf16=BF16,
fp16=FP16,
tf32=False,
max_length=256,
packing=False,
completion_only_loss=True,
remove_unused_columns=False,
dataloader_num_workers=2,
optim="adamw_torch", #避免 AMD ROCm 下 `bitsandbytes` 优化器兼容问题
report_to="none",
seed=SEED,
data_seed=SEED,
)
然后就可以开始 LoRA 微调了!
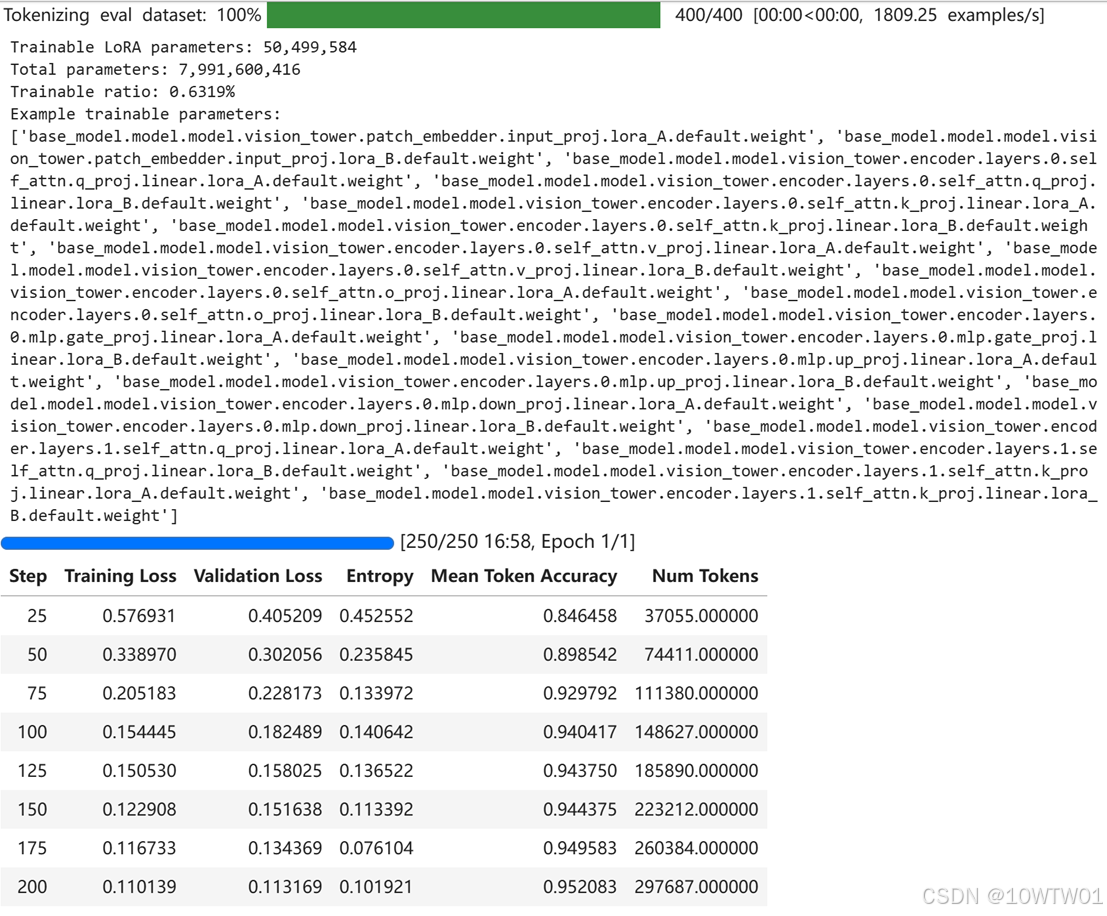
保存 LoRA adapter 和 tokenizer
保存的是 LoRA adapter,不是完整大模型权重。
目录中通常包括:
- adapter_model.safetensors
- adapter_config.json
- tokenizer 相关文件
- training checkpoints
微调后评估
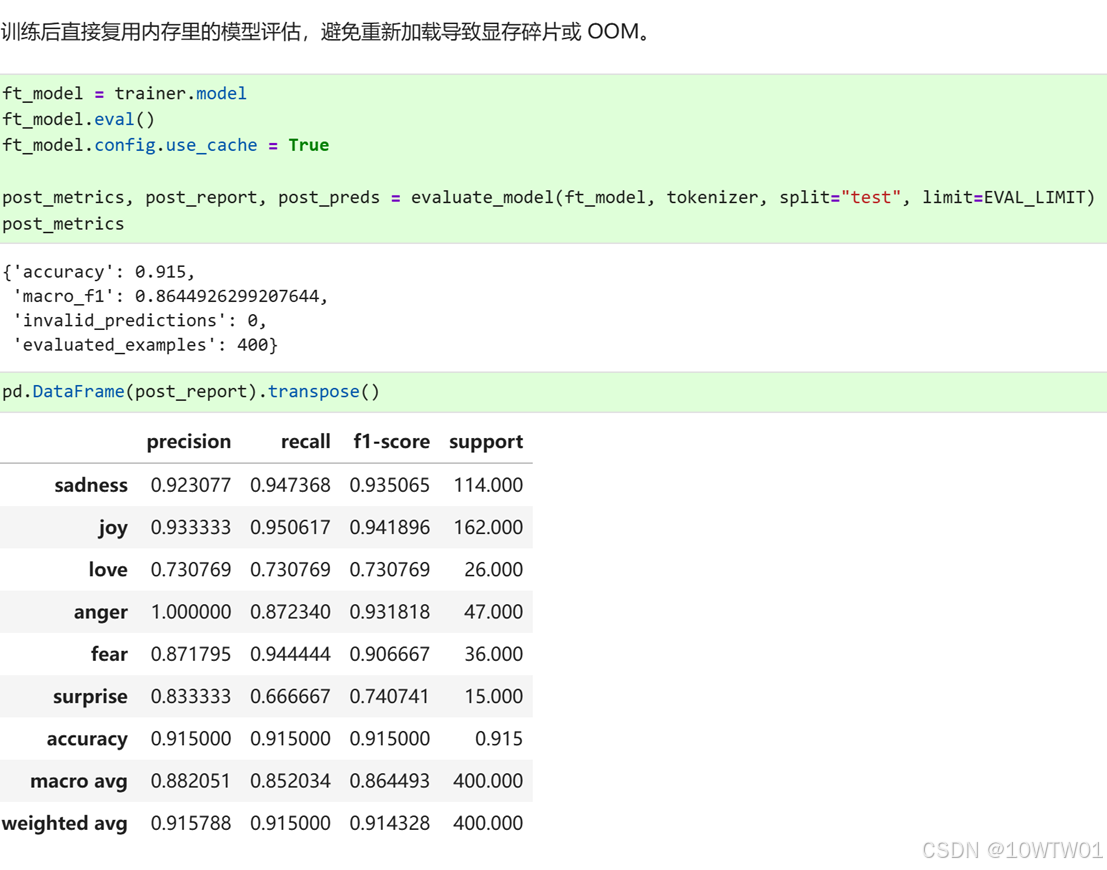
加载本地 LoRA adapter 推理
以后不想重新训练,可以用下面代码重新加载:
- 本地基础模型目录加载 base model。
- 从 OUTPUT_DIR 加载 LoRA adapter,PeftModel.from_pretrained 是 PEFT 库提供的接口,它会把基础模型和 LoRA 适配器捆绑到一起。
- 使用同一个 generate_label() 做推理
其他一些自己的实验截图碎片:
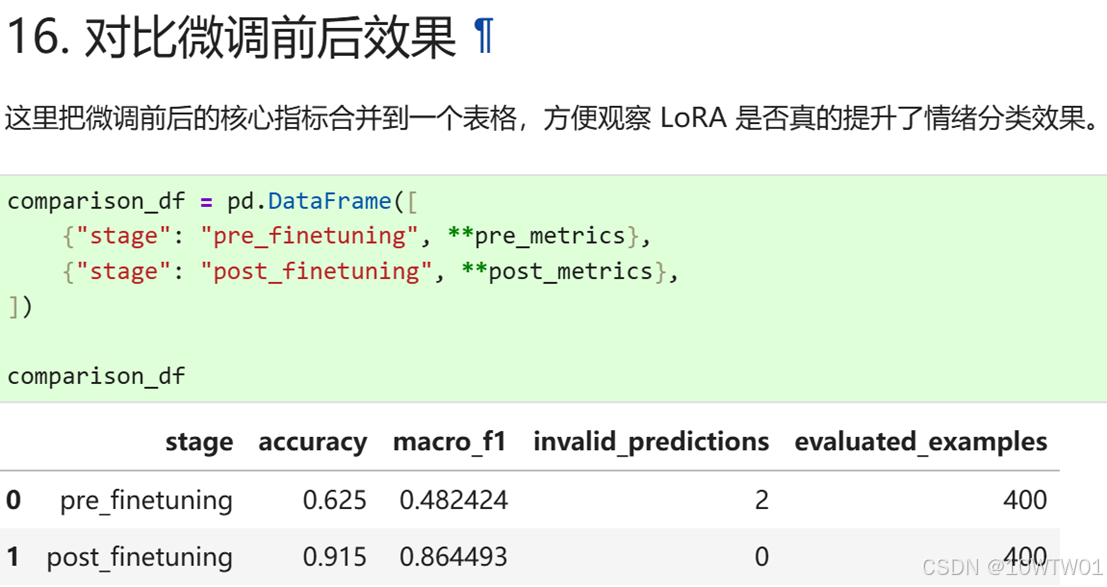
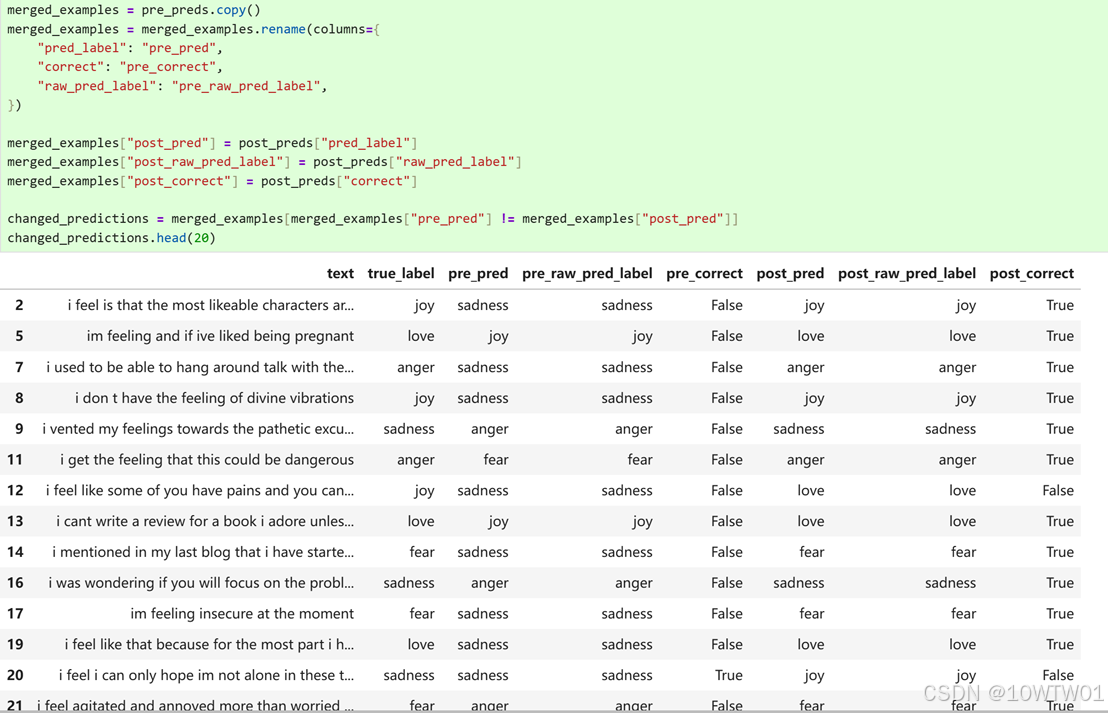


参考文献

免费领 200 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐

 54
54 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)