
AMD开发者云部署Gemma4大模型
·
通过魔搭账号登录后新人赠送10小时云算力
进入jupyter后,新建一个终端,输入以下命令检查显卡情况
amd-smi并检查pytorch是否识别AMD显卡
python -c "import torch; print('PyTorch:', torch.__version__); print('ROCm available:', torch.cuda.is_available()); print('Device:', torch.cuda.get_device_name(0) if torch.cuda.is_available() else 'N/A')"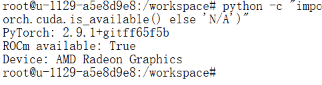
在云服务器环境中安装魔搭ModelScope,安装后输入命令安装Gemma4
modelscope download --model google/gemma-4-E4B-it --cache_dir "./models"卸载重装torchvision后确保vLLM服务为最新,然后启动服务
vllm serve ./models/google/gemma-4-E4B-it/ --served-model-name gemma-4-E4B-it这里需要等待一会,直到出现 Application startup complete 就可以下一步了
打开一个新终端,输入命令
vllm chat --url http://localhost:8000/v1 --model gemma-4-E4B-it等到出现
>就可以进行对话了

免费领 200 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐
 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)