
大模型-vllm投机解码模块解析
vLLM 投机解码代码深度解析
本文面向当前仓库中的 v1 推理路径,分析 vLLM 投机解码的配置、调度、执行、验证、回写与观测链路。重点覆盖以下模块:
-
vllm/config/speculative.py -
vllm/engine/arg_utils.py -
vllm/v1/engine/core.py -
vllm/v1/core/sched/scheduler.py -
vllm/v1/worker/gpu_model_runner.py -
vllm/v1/spec_decode/* -
vllm/v1/sample/rejection_sampler.py -
vllm/model_executor/models/medusa.py -
vllm/model_executor/models/llama_eagle.py
1. 先说结论:这个仓库里的投机解码是怎么组织的
这个仓库里,投机解码的主实现集中在 vllm/v1/ 路径,而不是旧的 V0 路径。就实际执行链路看,可以概括成一句话:
-
SpeculativeConfig决定是否开启 spec decode,以及采用哪一种 proposer。 -
Scheduler为每个请求维护spec_token_ids,并在调度时把这些草稿 token 一起送入 target model 做验证。 -
GPUModelRunner根据 scheduler 给出的scheduled_spec_decode_tokens构造验证所需的 logits 索引和 attention metadata。 -
target model 正常前向,输出覆盖“基础下一个 token + 草稿 token”的 logits。
-
RejectionSampler按 speculative decoding 的接受/拒绝规则,决定哪些草稿 token 被接受,并在全接受时追加 bonus token。 -
drafter 再基于本轮 target 输出和隐藏态提出下一轮草稿 token。
-
EngineCore.post_step()把新的草稿 token 回写到 scheduler,请求进入下一轮。
也就是说,vLLM 的投机解码不是“先独立跑一个 draft model,再单独跑 target model”这么简单,而是把“草稿生成”和“target 验证”塞进了统一的调度与执行框架里,重点优化的是:
-
token 调度方式
-
attention metadata 的复用
-
logits 索引组织
-
rollback / rejection 的低开销处理
-
方法级 proposer 的可插拔性
2. 数学与算法背景
投机解码的核心目标是减少 target model 的自回归步数。
标准自回归一次只生成 1 个 token,而 speculative decoding 的思路是:
-
由一个更快的 drafter 一次提出 $k$ 个候选 token。
-
target model 一次性验证这些 token。
-
按接受规则尽量多吃下这批草稿 token。
-
如果全部接受,再额外采样一个 bonus token。
若记草稿 token 序列为 $d_1, d_2, \dots, d_k$,target model 对应位置给出的分布为 $p_t$,draft model 给出的分布为 $p_d$,则经典 speculative decoding 使用 rejection sampling 来保证最终输出分布仍与 target model 一致。
这部分在本仓库里由 vllm/v1/sample/rejection_sampler.py 实现,并在类注释中明确引用了论文:
-
https://arxiv.org/abs/2211.17192
这里的术语对应关系是:
-
accepted tokens:直接被 target 接受的草稿 token
-
recovered tokens:发生拒绝后,从修正分布恢复采样出的 token
-
bonus tokens:所有草稿都接受时,再从 target 分布采样的额外 token
所以最终输出长度通常是:
3. 配置入口:SpeculativeConfig
3.1 文件位置
-
vllm/config/speculative.py
3.2 它解决什么问题
SpeculativeConfig 是投机解码的总配置对象,负责:
-
定义支持的方法类型
-
解析 CLI/engine 传入的 speculative 配置
-
自动推断 method
-
构造 draft model config
-
处理 ngram / medusa / eagle / mtp 等不同方法的特殊配置
3.3 支持的方法
源码里的 SpeculativeMethod 包含:
-
ngram -
eagle -
eagle3 -
medusa -
mlp_speculator -
draft_model -
deepseek_mtp -
ernie_mtp -
qwen3_next_mtp -
mimo_mtp -
longcat_flash_mtp -
mtp
但是要区分“配置层识别”和“v1 当前执行层真正实例化”的差别:
-
配置层能识别很多 method
-
当前
v1/worker/gpu_model_runner.py里实际创建 proposer 的只有:-
ngram -
eagle/eagle3 -
medusa
-
-
其他 method 在当前这份仓库的 v1 主执行路径里并没有同等完整接线
3.4 自动推断 method
SpeculativeConfig.__post_init__() 会根据 model 或 draft model 的 HF config 自动推断 method,例如:
-
model == "ngram"时统一成ngram -
draft model 名称含
eagle-时推断为eagle -
名称含
eagle3时推断为eagle3 -
hf_config.model_type == "medusa"时推断为medusa -
MTP 类型则归并成
mtp
同时它也会在 draft 方案上构造 draft_model_config 和 draft_parallel_config。
3.5 CLI 接入
CLI 的入口在:
-
vllm/engine/arg_utils.py
create_speculative_config() 会把这几个 engine 侧上下文字段补进去:
-
target_model_config -
target_parallel_config -
enable_chunked_prefill -
disable_log_stats
然后统一构造成 SpeculativeConfig(**self.speculative_config)。
另外,arg_utils.py 里有一个很关键的限制:
-
v1 当前明确支持
ngram、medusa、eagle -
draft_model会直接抛NotImplementedError
这意味着“泛化 draft model speculative decoding”在当前仓库里并不是完整可用路径。
4. 系统总流程
下面是当前 v1 路径下的整体执行框架。
flowchart TD
A[CLI / Engine Config] --> B[SpeculativeConfig]
B --> C[EngineCore]
C --> D[Scheduler.schedule]
D --> E[scheduled_spec_decode_tokens]
E --> F[GPUModelRunner.prepare_model_input]
F --> G[_calc_spec_decode_metadata]
G --> H[target model forward]
H --> I[_sample + RejectionSampler]
I --> J[accepted / rejected / bonus tokens]
H --> K[drafter.propose]
K --> L[take_draft_token_ids]
L --> M[EngineCore.post_step]
M --> N[Scheduler.update_draft_token_ids]
N --> D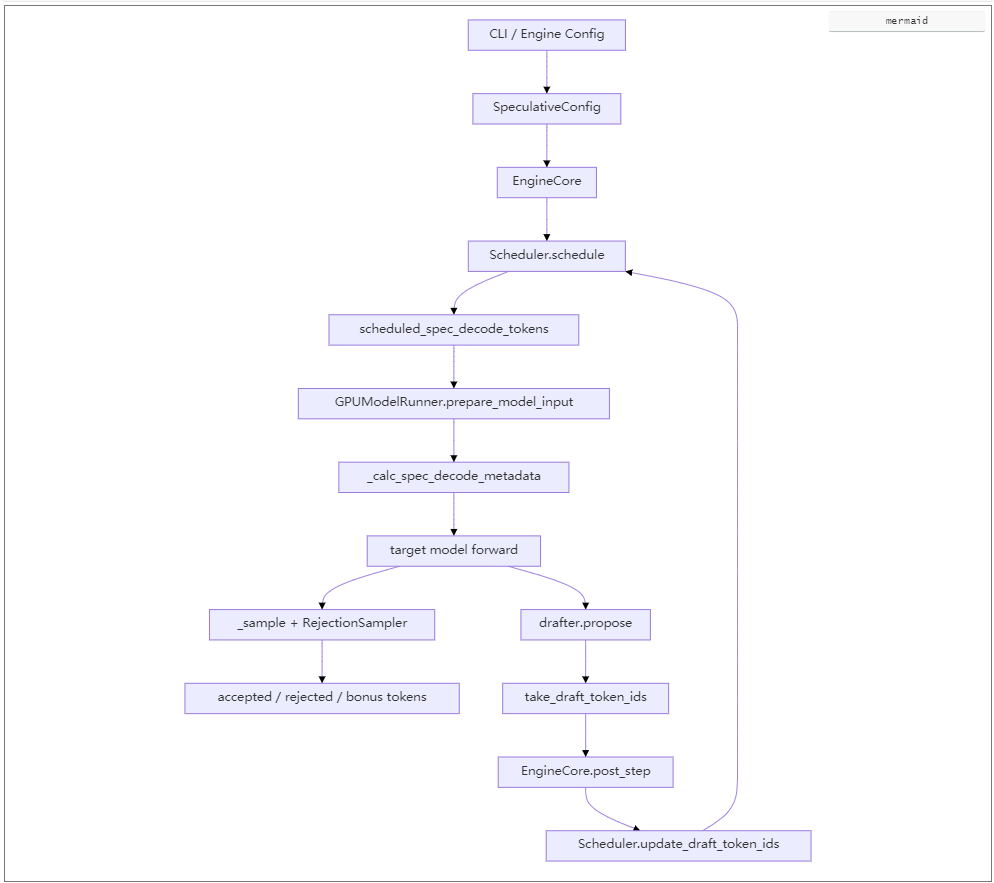
这个环路里最关键的是两条并行逻辑:
-
验证链:target model forward -> rejection sampler -> 更新请求状态
-
草稿链:drafter.propose -> post_step 回写 -> scheduler 持有下一轮草稿
5. Engine 级接线:v1/engine/core.py
5.1 是否启用投机解码
EngineCore 初始化时:
-
self.use_spec_decode = vllm_config.speculative_config is not None
这意味着只要配置存在,engine 就进入 spec decode 模式。
5.2 标准执行循环
step() 的基本顺序是:
-
scheduler.schedule() -
model_executor.execute_model(scheduler_output) -
scheduler.update_from_output(...)
这里没有给 speculative decode 单独拆出一个新执行器,而是把它揉进同一个 step 流程。
5.3 post step 回写草稿 token
真正把 drafter 输出接回 scheduler 的逻辑在:
-
EngineCore.post_step()
逻辑很直接:
-
如果启用了 spec decode 且本轮模型执行过
-
调
model_executor.take_draft_token_ids()取出 drafter 的结果 -
再调
scheduler.update_draft_token_ids(draft_token_ids)回写
这就是状态闭环的关键。
6. Scheduler 视角:spec decode 如何进入调度
6.1 文件位置
-
vllm/v1/core/sched/scheduler.py
6.2 一个关键设计:num_tokens_with_spec
源码里调度器有一句非常重要的注释:
-
每个 request 没有“prefill 阶段”和“decode 阶段”的硬切分
-
每个 request 只维护:
-
num_computed_tokens -
num_tokens_with_spec
-
其中:
这说明调度器把 speculative tokens 当成“待计算 token 总量”的一部分,而不是额外的旁路状态。这是整个设计能与 chunked prefill、prefix caching、结构化输出共存的基础。
6.3 调度时如何带上 spec token
在 schedule() 里,如果 request 上已有 request.spec_token_ids,会根据本轮实际分配的 token 数裁剪,并写入:
-
scheduled_spec_decode_tokens[request_id] = request.spec_token_ids
也就是说,scheduler 输出里显式包含了一份:
-
请求 ID -> 本轮要拿去验证的草稿 token 列表
随后这份结构会被 GPUModelRunner 消费。
6.4 更新输出时如何处理拒绝
scheduler.update_from_output() 会读取:
-
generated_token_ids -
scheduled_spec_token_ids
然后计算:
-
num_draft_tokens -
num_accepted -
num_rejected
如果发生拒绝,关键动作是:
-
request.num_computed_tokens -= num_rejected
这表示:虽然 target 这一步算过了这些草稿位置,但被拒绝的部分不能算作请求的“已确认输出进度”,因此要把进度回退。这是 spec decode rollback 的核心。
6.5 更新下一轮草稿 token
update_draft_token_ids() 会把 DraftTokenIds 回写到各 request:
-
若 drafter 返回空列表,则
request.spec_token_ids.clear() -
若 request 启用了 structured output,会先走 grammar 校验
-
否则直接
request.spec_token_ids = spec_token_ids
因此,草稿 token 本质上是 request 对象上的一段暂存状态,由 scheduler 在每轮 step 之间维护。
7. Worker 入口:GPUModelRunner
7.1 初始化 proposer
在 vllm/v1/worker/gpu_model_runner.py 初始化阶段,只有最后一个 PP rank 会创建 drafter:
-
ngram->NgramProposer -
eagle/eagle3->EagleProposer -
medusa->MedusaProposer
此外还会创建:
-
self.rejection_sampler = RejectionSampler()
也就是说 proposer 和 verifier 都挂在 GPUModelRunner 上。
7.2 为什么放在最后一个 PP rank
源码注释写得很明确:
-
当前 draft model 整体放在最后一个 pipeline parallel rank 上
-
这并不理想,尤其当 draft model 层数较多时
这说明当前设计偏向“先打通功能,再逐步优化流水并行切分”。
8. metadata 构造:target 验证是如何编码的
8.1 SpecDecodeMetadata
文件:
-
vllm/v1/spec_decode/metadata.py
它封装了验证所需的全部索引信息:
-
draft_token_ids -
num_draft_tokens -
cu_num_draft_tokens -
target_logits_indices -
bonus_logits_indices -
logits_indices
这是 spec decode 在 v1 路径下的中心数据结构之一。
8.2 _calc_spec_decode_metadata() 的核心思路
文件:
-
vllm/v1/worker/gpu_model_runner.py
这个函数接收:
-
每个请求有多少 draft token:
num_draft_tokens -
当前 batch 的累计 token 偏移:
cu_num_scheduled_tokens
然后计算三组关键索引:
-
logits_indices-
指向本轮 forward 里应该取哪些 logits
-
覆盖“每个请求的第一个真实 next token + 后续所有 draft token 对应位置”
-
-
target_logits_indices-
指向 draft token 对应的 target logits
-
这是 rejection sampling 用来验证草稿 token 的核心索引
-
-
bonus_logits_indices-
指向每个请求最后一个位置的 logits
-
当所有草稿都被接受时,从这里采 bonus token
-
同时,它还从 self.input_ids.gpu[logits_indices] 中抽出本轮实际要验证的 draft_token_ids。
8.3 一个非常重要的点
vLLM 并没有单独为草稿验证重新组织一套 full logits tensor,而是通过索引把 target model 本轮 forward 的输出“切出”成:
-
target logits for draft verification
-
bonus logits
这样做的好处是:
-
避免额外的 full logits 拷贝
-
兼容 batch 内不同 request 有不同 draft 长度
-
和 attention backend 的统一执行框架兼容
9. 采样与验证:RejectionSampler
9.1 文件位置
-
vllm/v1/sample/rejection_sampler.py
9.2 主流程
GPUModelRunner._sample() 分两种情况:
-
非 spec decode:直接调用普通 sampler
-
spec decode:
-
先对
bonus_logits采样,得到bonus_token_ids -
再把
target_logits和draft_token_ids喂给RejectionSampler -
得到最终
output_token_ids
-
也就是说,spec decode 模式下 target logits 被拆成两块:
-
bonus_logits = logits[bonus_logits_indices] -
target_logits = logits[target_logits_indices]
9.3 为什么 bonus token 要单独采样
源码注释给出的理由是:
-
bonus token 采样可以继续使用 top-k / top-p 等默认 sampling 策略
-
spec decode 的 rejection 过程本身不直接支持这些策略
这实际上是一种工程折中:
-
draft token 的接受/拒绝必须遵守严格分布校正
-
bonus token 则可复用现有 sampler 逻辑
9.4 输出形式
rejection_sample() 返回的是一个二维张量:
-
[batch_size, max_spec_len + 1]
其中:
-
被拒绝的位置用
PLACEHOLDER_TOKEN_ID = -1占位 -
parse_output()再把无效位置过滤掉
因此对每个请求而言,最终拿到的是一个可变长度 token 列表。
10. 三种 proposer 的实现差异
当前仓库的 v1 主路径实际接线了 3 类 proposer。
10.1 N-gram proposer
文件:
-
vllm/v1/spec_decode/ngram_proposer.py
设计定位
N-gram proposer 不依赖额外模型,它直接在已有 token 序列里找 suffix/prefix 匹配,然后把历史中匹配片段后面的 token 当作草稿 token。
它本质上是一个“基于重复模式的无模型 speculative decoding”。
关键参数
-
prompt_lookup_min -
prompt_lookup_max -
num_speculative_tokens
核心流程
-
筛选可做 ngram speculate 的 request
-
本轮必须已经 sample 出至少一个 token
-
sampling params 不能落在 unsupported 集合里
-
不能超过
max_model_len
-
-
调
batch_propose_numba(...)-
使用 Numba JIT +
prange做批量并行
-
-
_find_longest_matched_ngram_and_propose_tokens(...)-
在历史 token 序列中找满足
[min_n, max_n]的最长匹配 ngram -
取匹配片段后续的最多
k个 token 作为草稿
-
工程特点
-
无额外模型开销
-
适合重复模式强的上下文
-
acceptance rate 高度依赖上下文复现程度
-
借助 numba 减少 Python 循环开销
限制
-
与 sampling params 有兼容性限制
-
在新颖文本、低重复场景下效果一般
10.2 Medusa proposer
文件:
-
vllm/v1/spec_decode/medusa.py -
vllm/model_executor/models/medusa.py
设计定位
Medusa 的思路是:不引入完整 draft model,而是在 target model 的 hidden states 上挂多个草稿头(heads),每个 head 预测后续一个位置的 token。
这里的 Medusa 模型本质上是一个轻量的多头 residual block + lm_head 结构。
MedusaProposer 怎么工作
MedusaProposer.propose(target_hidden_states, sampling_metadata):
-
用 target model 输出的 hidden states 作为输入
-
送入 medusa head 模型
-
每个 head 输出一组 logits
-
逐 head
argmax -
转置成
[batch, num_heads]的 draft token 列表
model_executor/models/medusa.py 的结构
Medusa 由以下组件组成:
-
多个
ResidualBlock -
每个 block 对应一个 draft head
-
每个 head 可以有自己的
ParallelLMHead -
可选
token_map缩小 draft vocab
源码里还明确提到两个实现差异:
-
当前只支持 top-1 proposals
-
可选
token_map把 vocab 截断到高频 token,减少采样开销
工程意义
Medusa 比完整 draft model 更轻:
-
不需要完整再跑一套 decoder
-
直接复用 target hidden states
-
通常适合在保持较高 acceptance 的同时压低草稿生成成本
10.3 EAGLE proposer
文件:
-
vllm/v1/spec_decode/eagle.py -
vllm/model_executor/models/llama_eagle.py -
以及对应的
*_eagle.py模型实现
设计定位
EAGLE 属于“带专门草稿网络”的 proposer。它不是简单多头,也不是无模型规则,而是显式构造一个 draft network,用 target token、position、hidden state 作为输入来预测后续 token。
EagleProposer 初始化做了什么
-
读取
draft_model_config -
解析
speculative_token_tree -
初始化 persistent buffers:
-
input_ids -
positions -
hidden_states -
inputs_embeds
-
-
初始化 CUDA graph 相关参数
-
构造树结构的每层节点统计:
-
cu_drafts_per_level -
child_drafts_per_level
-
propose() 主流程
-
取 target model 本轮输出:
-
token ids
-
positions
-
hidden states
-
next token ids
-
-
构造 drafter 的输入:
-
把 input ids 整体左移
-
用本轮 next token 替换各请求尾部位置
-
-
构建 drafting 专用 attention metadata
-
跑 draft model,得到 logits 和新的 hidden states
-
如果
num_speculative_tokens == 1-
直接
argmax返回
-
-
否则分两种:
-
普通串行草稿:一轮一轮 rollout 剩余 draft token
-
tree attention 草稿:走
propose_tree()一次扩展整棵 token tree
-
为什么 EAGLE 更复杂
因为它要处理:
-
自定义草稿模型 forward
-
draft model 的 attention metadata
-
与 target model 隐藏态对接
-
tree speculation
-
padded drafter batch
-
CUDA graph 复用
-
multimodal 输入路径
llama_eagle.py 的模型结构
以 llama_eagle.py 为例,核心点有两个:
-
draft model 的输入是
input_embeds与 target hidden states 拼接后,经fc投影 -
draft model 可以跳过部分 input_layernorm,以贴近 EAGLE 论文/实现约定
这意味着 EAGLE 不是“直接复制 target model 的一份小模型”,而是专门设计过输入接口的草稿网络。
11. EAGLE 的 tree speculation
EAGLE 支持 speculative_token_tree,这是当前仓库里最有特色的实现之一。
11.1 基本思想
不是只生成单条 draft 序列,而是构造一棵 token tree:
-
根节点处可一次取 top-k child
-
后续每层继续展开 child
-
target 验证时利用 tree attention 提升覆盖率
11.2 propose_tree() 做了什么
核心步骤如下:
-
在根层对 logits 取
topk或argmax -
维护当前层 draft token、positions、hidden states
-
根据树深度逐层扩展
-
每层重建 tree attention metadata
-
把整棵树 flatten 成一个批量输入送给 draft model
-
收集各层输出,最终返回按树结构组织的 token proposals
11.3 为什么需要 tree attention
因为 tree speculation 的不同分支共享同一个前缀。若按普通 batch 做,会重复计算共享前缀;tree attention 能更自然地表达“多分支共享父路径”的注意力关系。
从工程上看,这也是 EAGLE 相比 Ngram / Medusa 最复杂的地方。
12. 输入准备与 attention backend 配合
12.1 spec decode 对 attention metadata 的要求
在 GPUModelRunner.prepare_model_input() 中,如果本轮有 spec decode:
-
会额外计算
num_decode_draft_tokens -
会把
num_accepted_tokens拷到 GPU -
对 GDN 等 backend,会额外传:
-
num_accepted_tokens -
num_decode_draft_tokens_cpu
-
这说明 attention backend 需要知道哪些序列在做 spec decode,以及当前已接受了多少 token。
12.2 GDN backend 的支持
从 grep 结果能看到:
-
vllm/v1/attention/backends/gdn_attn.py
它显式支持:
-
num_spec_decodes -
num_spec_decode_tokens -
spec sequence masks
-
accepted token 计数
这不是 proposer 层的逻辑,而是 target model 验证阶段真正影响 attention 计算图的地方。
12.3 为什么 _calc_spec_decode_metadata() 很重要
因为 spec decode 不是简单增加几个 token,而是要在 batch 里混排:
-
普通请求
-
带草稿的请求
-
每个请求不同长度的草稿
如果没有这套索引与 metadata 编码,后面的 attention 和 sampler 很难保持统一高效。
13. 兼容性限制
13.1 不支持的 sampling 参数
文件:
-
vllm/v1/spec_decode/utils.py
当前 is_spec_decode_unsupported() 会在以下情况返回 True:
-
frequency_penalty != 0 -
presence_penalty != 0 -
repetition_penalty != 1 -
min_p > 1e-5 -
logprobs is not None
这说明当前 speculative decoding 路径并没有覆盖所有 sampling feature。
13.2 draft_model 方法未打通
虽然配置层能识别 draft_model,但在当前 v1 主路径里它会直接报错,提示使用:
-
ngram -
medusa -
eagle -
mtp
13.3 chunked prefill / backend 限制
配置和 EAGLE 代码里都能看到一些限制条件,比如:
-
某些 V0 路径下 chunked prefill 与 EAGLE 不兼容
-
EAGLE 对 attention metadata 类型有检查
-
draft 输入长度不能超过 drafter 的
max_model_len
这些都是实现层面的硬约束。
14. 观测与性能指标
文件:
-
vllm/v1/spec_decode/metrics.py
这个模块把 spec decode 的观测设计得很完整。
14.1 核心统计量
SpecDecodingStats 记录:
-
num_drafts -
num_draft_tokens -
num_accepted_tokens -
num_accepted_tokens_per_pos
14.2 两类输出
-
SpecDecodingLogging-
聚合一段时间内的统计
-
打印日志:
-
mean acceptance length
-
accepted throughput
-
drafted throughput
-
per-position acceptance rate
-
avg draft acceptance rate
-
-
-
SpecDecodingProm-
对接 Prometheus
-
暴露以下计数器:
-
vllm:spec_decode_num_drafts -
vllm:spec_decode_num_draft_tokens -
vllm:spec_decode_num_accepted_tokens -
vllm:spec_decode_num_accepted_tokens_per_pos
-
-
14.3 这些指标怎么解读
-
acceptance rate 高:说明 drafter 与 target 更一致
-
accepted throughput 高:说明 spec decode 真正提升了“被 target 认可”的 token 产出速度
-
mean acceptance length 高:说明每次验证能吞下更多草稿 token
-
per-position acceptance rate 下降快:通常表示 draft 越往后越不可靠
这是定位 drafter 好坏和调 num_speculative_tokens 的最直接工具。
15. 状态流转:一次完整 step 的细化版
下面给出更细的调用链。
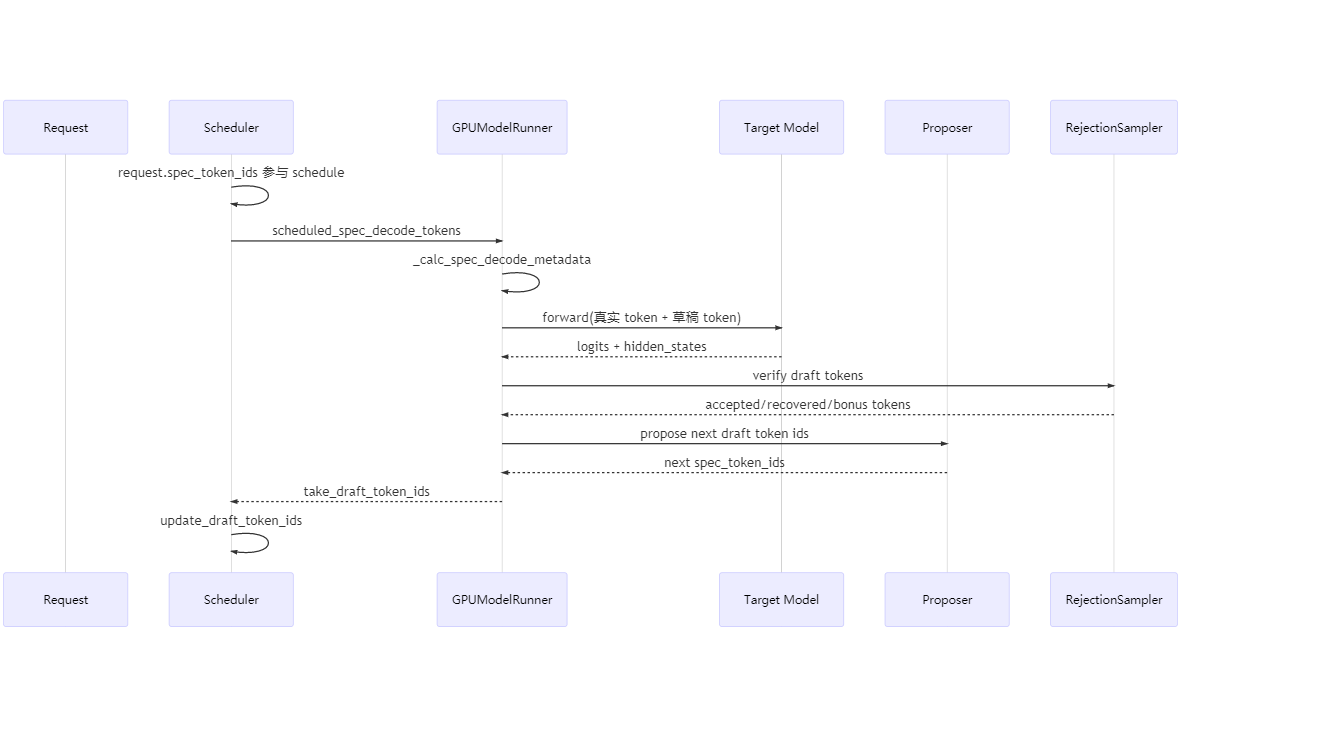
可以看到,草稿 token 并不是 scheduler 当场生成的,而是由上一轮 worker 执行结束后回写回来,下一轮调度时再消费。
16. 代码层面的关键设计选择
16.1 把 speculative state 放在 request 上
优势:
-
scheduler 逻辑统一
-
request 天然持久化状态
-
容易与 structured output、rollback 联动
代价:
-
request 状态字段更多
-
需要在 update/output/post_step 间维护一致性
16.2 把 proposer 放在 worker,而不是 scheduler
优势:
-
proposer 直接拿 hidden states / logits / attention metadata
-
避免跨层传过多中间 tensor
-
更容易贴近实际执行后端优化
代价:
-
scheduler 看不到 proposer 内部细节
-
proposer 与 runner 绑定更深
16.3 用 metadata + 索引而不是拆独立执行图
优势:
-
与既有 batch 执行框架兼容
-
不用额外维护另一套 logits 布局
-
对不同 spec 长度更灵活
这是当前实现中最核心的工程化决策之一。
17. 按模块总结职责
vllm/config/speculative.py
职责:
-
定义 speculative config schema
-
自动推断 method
-
构造 draft model config
-
约束 ngram / eagle / medusa / mtp 的配置
vllm/engine/arg_utils.py
职责:
-
从 CLI/engine 输入构造
SpeculativeConfig -
决定 v1 是否允许该 speculative method
vllm/v1/engine/core.py
职责:
-
在 engine step 中接入 scheduler 与 model executor
-
在 post_step 中把新草稿 token 回写给 scheduler
vllm/v1/core/sched/scheduler.py
职责:
-
在调度时把
spec_token_ids视为待计算 token 的一部分 -
组织
scheduled_spec_decode_tokens -
根据接受/拒绝结果回滚
num_computed_tokens -
保存下一轮
spec_token_ids
vllm/v1/worker/gpu_model_runner.py
职责:
-
实例化 drafter
-
构造 spec decode metadata
-
组织 attention metadata
-
做 target 验证采样
-
调 proposer 产生下一轮草稿 token
vllm/v1/spec_decode/ngram_proposer.py
职责:
-
基于历史 token 匹配提出草稿 token
vllm/v1/spec_decode/medusa.py
职责:
-
用 medusa head 从 target hidden states 提案
vllm/v1/spec_decode/eagle.py
职责:
-
用 eagle draft network 生成串行或树形草稿 token
vllm/v1/sample/rejection_sampler.py
职责:
-
依据 target 分布验证草稿 token
-
在需要时恢复采样并处理 bonus token
vllm/v1/spec_decode/metrics.py
职责:
-
汇总 acceptance 与 throughput 指标
-
对接日志和 Prometheus
18. 对这套实现的整体评价
从代码结构上看,这个仓库里的 speculative decoding 实现有几个明显特征。
优点
-
与 v1 调度框架融合得比较深,不是外挂式实现
-
proposer 抽象清晰,便于支持不同 spec 方法
-
rollback / acceptance / metrics 做得比较完整
-
attention backend 明确为 spec decode 预留了接口
-
EAGLE 路径对树结构和 CUDA graph 做了工程优化
代价
-
逻辑跨 config / scheduler / runner / sampler / proposer 多层分散
-
EAGLE 路径复杂度明显更高,维护成本大
-
method 支持矩阵并不完全对齐配置层定义
-
某些 sampling feature 与 speculative path 仍不兼容
整体上,这是一套“以统一执行框架为中心”的 speculative decoding 实现,而不是单纯围绕某个特定 drafter 的样例代码。它的核心价值不只是支持 Ngram/Medusa/EAGLE,而是把这些 proposer 装进统一的 scheduler + runner + sampler 管线里。
19. 阅读建议
如果你后续要继续深入这个仓库的 speculative decode,建议按下面顺序读:
-
vllm/config/speculative.py-
先建立配置和 method 认知
-
-
vllm/v1/core/sched/scheduler.py-
理解 request 上的
spec_token_ids是如何进入调度的
-
-
vllm/v1/worker/gpu_model_runner.py-
理解 metadata、采样、drafter 接线
-
-
vllm/v1/sample/rejection_sampler.py-
理解分布校正与 bonus token
-
-
vllm/v1/spec_decode/eagle.py-
理解最复杂方法的实现方式
-
-
vllm/v1/spec_decode/metrics.py-
理解如何判断 spec decode 是否真的带来收益
-
20. 一句话总括
这份仓库里的投机解码,本质上是“由 scheduler 保存草稿状态、由 GPUModelRunner 统一组织 target 验证和 proposer 提案、由 rejection sampler 保证输出分布正确”的一整套 v1 推理子系统;其中 ngram、medusa、eagle 只是接在这条总线上的三种不同 drafter 实现。

免费领 200 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐
 8
8 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)