
【大模型推理】KVDrive: A Holistic Multi-Tier KV Cache Management System for Long-Context LLM Inference
如图 6 所示,KVDrive 旨在支持高吞吐量的长上下文 LLM 推理,即使在 GPU 内存紧张的情况下也是如此。当 KV 缓存超过 GPU 容量时,它会被卸载到主机 DRAM 或 SSD,并且系统在预填充阶段在 GPU 内存中构建一个索引。在解码期间,每个新 token 都遵循一个三阶段的工作流程:通过索引识别关键 KV 条目(❶);将选定的条目从 DRAM 或 SSD 获取到 GPU HBM
好的,这是对您提供的文件的全文翻译。
KVDrive:一个用于长上下文大语言模型推理的整体性多级 KV 缓存管理系统
JIAN LIN, 香港科技大学, 中国
JIAZHI MI, 香港科技大学, 中国
ZICONG HONG∗, 香港科技大学, 中国
HAODONG WANG, 香港科技大学, 中国
QIANLI LIU, 香港科技大学, 中国
HAOYUE ZHANG, 香港科技大学, 中国
PENG LI, 西安交通大学, 中国
SONG GUO∗, 香港科技大学, 中国
支持长上下文大语言模型(LLM)具有挑战性,因为它对键值(KV)缓存的内存需求巨大。现有的卸载系统将完整的缓存存储在主机内存中,并在解码期间选择性地获取关键条目,但这种策略很快就会遇到瓶颈:如果不降低准确性,稀疏性就无法进一步提升。因此,当上下文长度和批处理大小增加时,KV 传输量会急剧上升,并成为解码延迟的主要来源。我们提出了 KVDrive,一个横跨 GPU 显存、主机 DRAM 和 SSD 的整体性多级 KV 缓存管理系统。与以往通过算法优化追求更大稀疏性的工作不同,KVDrive 从系统角度解决问题——协同编排缓存放置、流水线调度和跨层级协调,以在紧张的 GPU 预算下维持高吞吐量推理。KVDrive 提出了三项基本能力:它根据注意力行为调整缓存管理,以最大化复用并最小化冗余数据移动;它重构解码流水线以重叠 I/O、CPU/GPU 计算密集型阶段,消除异构资源间的停顿;并且它协调跨内存层级的数据移动,以解锁远超 GPU 和 DRAM 限制的可扩展长上下文推理。我们已经实现了 KVDrive 的一个功能齐全的原型,并在长上下文基准测试中用流行的 LLM 对其进行了评估。该系统在保持准确性的同时,与当前最先进的工作相比,实现了高达 1.74 倍的吞吐量提升。
CCS 概念: • 信息系统 → 数据管理系统。
附加关键词: 大语言模型; 长上下文服务; KV 缓存卸载
ACM 引用格式:
Jian Lin, Jiazhi Mi, Zicong Hong, Haodong Wang, Qianli Liu, Haoyue Zhang, Peng Li, and Song Guo. 2026. KVDrive: A Holistic Multi-Tier KV Cache Management System for Long-Context LLM Inference. 1, 1 (May 2026), 25 pages. https://doi.org/10.1145/nnnnnnn.nnnnnnn
1 导言
随着大语言模型(LLM)在能力和应用范围上的持续扩展,支持长上下文推理 [21] 对于文档理解、复杂智能体工作流、软件开发 [11] 以及基于大型知识库的推理等应用变得越来越重要。
长上下文推理的一个核心障碍是键值(KV)缓存的内存占用。在自回归解码期间,LLM 必须保留所有先前 token 的键和值,以进行注意力计算。与保持固定的模型权重不同,KV 缓存随序列长度和批处理大小线性增长,并且很容易超过模型本身的大小。因此,高效的 KV 缓存管理已成为启用长上下文 LLM 的关键挑战。
例如,Llama-3.1-8B-Instruct [23] 支持长达 128k token 的序列——大约 200 页文本——需要超过 16 GB 的 KV 缓存。新兴模型将上下文窗口扩展到 1M token [34],进一步放大了这一需求。相比之下,商用 GPU 仅提供几十 GB 的内存,这些内存还必须容纳模型权重、激活值和其他运行时开销。这种内存差距使得在长上下文或大批量推理中将整个 KV 缓存存储在 GPU 内存中变得不可行。
为了弥补这一差距,最近的研究提出将 KV 缓存卸载到主机内存 [6, 7, 18, 28, 29, 40]。在每次注意力计算之前,所需的条目被重新加载到 GPU 内存中。虽然卸载减轻了 GPU 的压力,但它在整个系统中引入了新的低效率。现有方法未能有效地协调 CPU 和 GPU 计算、数据传输和存储,常常导致一个或多个资源未被充分利用——GPU 显存在等待数据时空闲,CPU 在 GPU 执行期间停顿,或者 I/O 带宽在传输之间未被使用。因此,它们未能实现 GPU、CPU 和 I/O 子系统之间的整体平衡,从而无法达到最佳的协调点。
为应对这些挑战,我们提出了 KVDrive,一个横跨 GPU 显存、主机 DRAM 和 SSD 的整体性多级 KV 缓存管理系统。与以往依赖算法稀疏性优化的工作不同,KVDrive 从系统角度解决问题——协同优化缓存管理、流水线调度和存储分层,以在紧张的 GPU 预算下实现高效的长上下文推理。它引入了三项关键技术:
(1) 基于注意力的缓存管理 (Attention-Based Cache Management)。KVDrive 重新思考了传统的缓存管理——传统上由通用的访问频率或新近度指导——通过使其具备注意力感知能力并为 Transformer 架构量身定制。具体来说,尽管关键 KV 条目的确切集合在不同 token 之间有所不同,但它们在解码窗口内表现出时间局部性。利用此特性,KVDrive 在 GPU 内存中维护一个关键条目的滑动窗口,仅增量更新窗口外的差异。它依赖于二维的层-头缓存分配和前瞻性驱逐策略,以在内存开销有界的情况下最大化复用。
(2) 弹性流水线调度 (Elastic Pipeline Scheduling)。KVDrive 通过一种新的 SFC(选择、获取、计算)解耦设计,将选择、获取和计算解耦为独立调度的阶段。利用每个阶段的不同特性,系统将解码划分为微批次,并以最小的干扰并行执行这些阶段。细粒度的微批次处理重叠了内存、传输和计算密集型阶段,同时联合调整索引大小、缓存大小和微批次大小以平衡延迟、吞吐量和准确性。这种设计消除了流水线停顿,并在不同工作负载下维持 GPU、CPU 和 I/O 子系统的高利用率。
(3) 协同的多级 KV 存储 (Coordinated Multi-Tier KV Storage)。KVDrive 不仅仅是纯 DRAM 卸载,它将 SSD 作为第三层级,并协调 HBM、DRAM 和 SSD 之间的数据移动。它应用重要性引导的预热,在预填充(prefill)期间优先处理高价值的 KV 条目,采用 SSD 感知布局以最大化顺序 I/O 局部性,并执行并行稀疏同步以最小化跨层级传输开销。这些机制共同实现了可扩展的长上下文推理,其能力远超单独的 GPU 和 DRAM 内存限制。
总而言之,本文做出以下贡献:
- 我们提出了 KVDrive,一个整体性的多级 KV 缓存管理系统,可在紧张的 GPU 缓存预算下维持高效的长上下文 LLM 推理。
- 我们引入了一种注意力感知的缓存管理机制,能够高效复用 GPU 内存中的 KV 条目,显著减少冗余数据移动。
- 我们提出了一种弹性流水线调度策略,该策略解耦了选择、获取和计算,实现了细粒度的重叠并消除了停顿。
- 我们设计了一种协同的多级存储架构,为超出 GPU 和 DRAM 容量的长上下文提供低延迟访问和可扩展的支持。
- 我们在长上下文基准上实现并评估了 KVDrive,证明其在保持准确性的同时,吞t量比现有系统高出 1.74 倍。
2 背景与相关工作
2.1 KV 缓存基础
现代 LLM [25, 30] 通常基于仅解码器的 Transformer [9] 构建。推理分为两个阶段:预填充(prefill)和解码(decoding)。在预填充期间,所有输入 token(提示)被并行处理。此阶段生成第一个输出 token,同时将中间的键和值向量存储在 GPU 内存中,统称为 KV 缓存。在随后的解码阶段,token 以自回归方式生成,每一步都将新的键和值向量附加到缓存中。这种设计消除了冗余计算,实现了高效的 token 生成。
2.2 稀疏注意力
并非所有 token 对注意力的贡献都相同:注意力得分较高的 token 通常扮演更关键的角色 [8, 15, 17, 22, 29, 35, 38]。它们对应的键值对被称为关键 KV 条目,丢弃非关键条目通常只会导致微小的准确性损失 [41]。由于 token 的重要性取决于当前的查询,系统必须动态识别哪些 KV 条目是相关的。例如,如图 1 所示,给定上下文“ABCDE”,在解码下一个 token 时,第 31 层的头 1 将 token “A” 和 “E” 的 KV 条目识别为关键。作为一个代表性系统,Quest [29] 将键条目划分为块,并通过将查询向量与键的通道级最小值和最大值相乘来估计其重要性。通过为每个查询仅检索 Top-K 重要的块,Quest 大大减少了注意力计算。
(图 1. 一个 32 层、8 个头的模型中稀疏注意力的例子)
2.3 KV 缓存卸载
KV 缓存的大小随上下文长度和批处理大小线性增长,很快就超出了 GPU 的内存容量。为了缓解这一瓶颈,最近的研究提出将 KV 缓存从 GPU 内存卸载到速度较慢但容量更大的层级,如主机内存或 SSD。
一些系统 [5, 10, 14, 32] 专注于多会话场景,其中每个会话的 KV 缓存可以放入 GPU 内存,但跨会话的总需求超过了容量。非活动会话的缓存被卸载,而活动会话的缓存保留在 GPU 上。例如,如图 2a 所示,四个非活动会话(S3-S6)的 KV 缓存存储在 DRAM 中,而两个活动会话(S1-S2)的 KV 缓存保留在 GPU 内存中。这些方法主要旨在减少首个 token 的生成时间。然而,它们假设活动会话的缓存总是能放入 GPU 内存——这一假设在长上下文推理中不成立。
(图 2. 两种卸载系统类型)
更新的工作 [6, 7, 18, 28, 29, 40] 则将活动会话的 KV 缓存卸载到主机内存,例如图 2b 中的 S1 和 S2。在解码期间,每个 token 通常需要三个步骤:(1) 通过存储在 GPU 内存中的索引选择关键 KV 条目;(2) 将这些条目从主机内存获取到 GPU 内存;(3) 使用稀疏注意力和其他层操作(例如,前馈网络)计算新 token。
一个简单的解决方案是将所有键作为索引存储在 GPU 内存中,并将所有值卸载到主机内存。然后通过将每个查询与完整的键集合相乘并检索 Top-K 来选择关键条目。为了提高效率,已经探索了三种优化策略:(i) 列选择:InfiniGen [18] 选择具有最大幅值的键列子集。(ii) 空间分块:Quest [29] 和 ShadowKV [28] 将相邻的键划分为块,并使用它们的最小/最大/平均值作为代表。(iii) 相似性分组:MagicPig [7] 采用局部敏感哈希(Locality-Sensitive Hashing)对相似的键进行分组,而 RetrievalAttention [20]、RetroInfer [6] 和 PQCache [40] 则利用通用的近似最近邻搜索(ANNS)技术,该技术使用聚类中心作为索引代表以实现高效的键检索。
如表 1 所总结,KVDrive 在三个维度上推进了 KV 缓存卸载:
(i) 缓存。现有系统如 ShadowKV [28]、PQCache [40] 和 RetroInfer [6] 采用通用缓存管理策略——通常是 LFU 或 LRU——仅依赖于过去的访问频率或新近度。相比之下,KVDrive 引入了一个注意力感知的缓存管理器,它根据实时注意力分布和模型特定的架构模式来维护其 GPU 内缓存,从而实现了与模型行为一致的有效复用。(ii) 调度。大多数先前系统遵循选择、获取和计算的顺序流水线,导致频繁的 GPU 停顿。InfiniGen [18] 试图通过基于前一层注意力的推测性预取来缓解这种情况。然而,这种近似方法在长上下文任务中常常降低准确性。KVDrive 则采用弹性流水线调度器,以细粒度重叠这些阶段,有效减少停顿并在不同工作负载下维持高利用率,而不牺牲生成质量。(iii) 分层。先前的系统如 FlexGen [27] 执行粗粒度的、逐层卸载。这对于稀疏注意力工作负载效率低下,因为获取未使用的 KV 块会导致严重的 I/O 放大。KVDrive 则采用并行稀疏同步,只获取每个查询所需的特定 KV 块。这种细粒度方法,加上我们协调的多级设计,使 KVDrive 能够有效地将存储层次结构扩展到 SSD,缓解了限制粗粒度卸载解决方案的带宽瓶颈。
这三种机制不是孤立的优化,而是集成在一起,从根本上改变了长上下文 KV 缓存管理的执行方式:弹性调度器隐藏了稀疏 I/O 的延迟,而注意力引导的缓存最小化了该 I/O 的量,从而实现了跨异构存储层次结构的可扩展推理。
(表 1. 几个代表性 KV 缓存卸载系统与我们的 KVDrive 的比较)
3 动机
KV 缓存的内存占用随上下文长度和批处理大小线性增长,这在实践中很快变得令人望而却步。这种线性增长使得在当前硬件限制下直接将所有 KV 缓存存储在 GPU 内存中不切实际。例如,当批处理大小为 8,上下文长度为 100K 时,Llama-3-8B 的 KV 缓存需要近 100GB 的内存——超出了大多数商用 GPU 的容量。
如 §2.3 所述,先前的研究提出了各种 KV 缓存卸载系统。我们选择 Quest [29]、RetroInfer [6] 和 ShadowKV [28] 作为代表性系统,RULER [13] 作为基准,以及一台 L20 服务器(§9.1)。所有基线都按照其原始论文实现;然而,为了确保公平比较,我们禁用了一些辅助优化。这些调整的细节和超参数在 §9.1 中提供。接下来,我们指出了三个基本限制,这些限制在实际的长上下文和多批次设置下的大规模部署中阻碍了它们的实用性和性能。
首先,大多数现有系统 [18] 在每一步解码时都从主机内存加载一套全新的关键 KV 条目,并丢弃之前获取到 GPU 的条目。最近的研究 [28, 40] 观察到短程时间局部性——即连续的查询通常会关注重叠的关键 KV 条目——但这一点在长程范围内尚未得到系统性分析。
发现 1. 关键 KV 条目不仅在相邻 token 之间,而且在更广泛的局部范围内都表现出强时间相关性。因此,维护一个近期关键 KV 条目的滑动窗口能够实现有效复用。
我们为每个解码步骤定义一个关键 KV 窗口,即对应于多个近期 token 的关键 KV 条目集合。为了评估时间复用,我们测量 (i) 额外的 GPU 内存开销和 (ii) 重载数据量,定义为相邻窗口之间不重叠的 KV 条目。
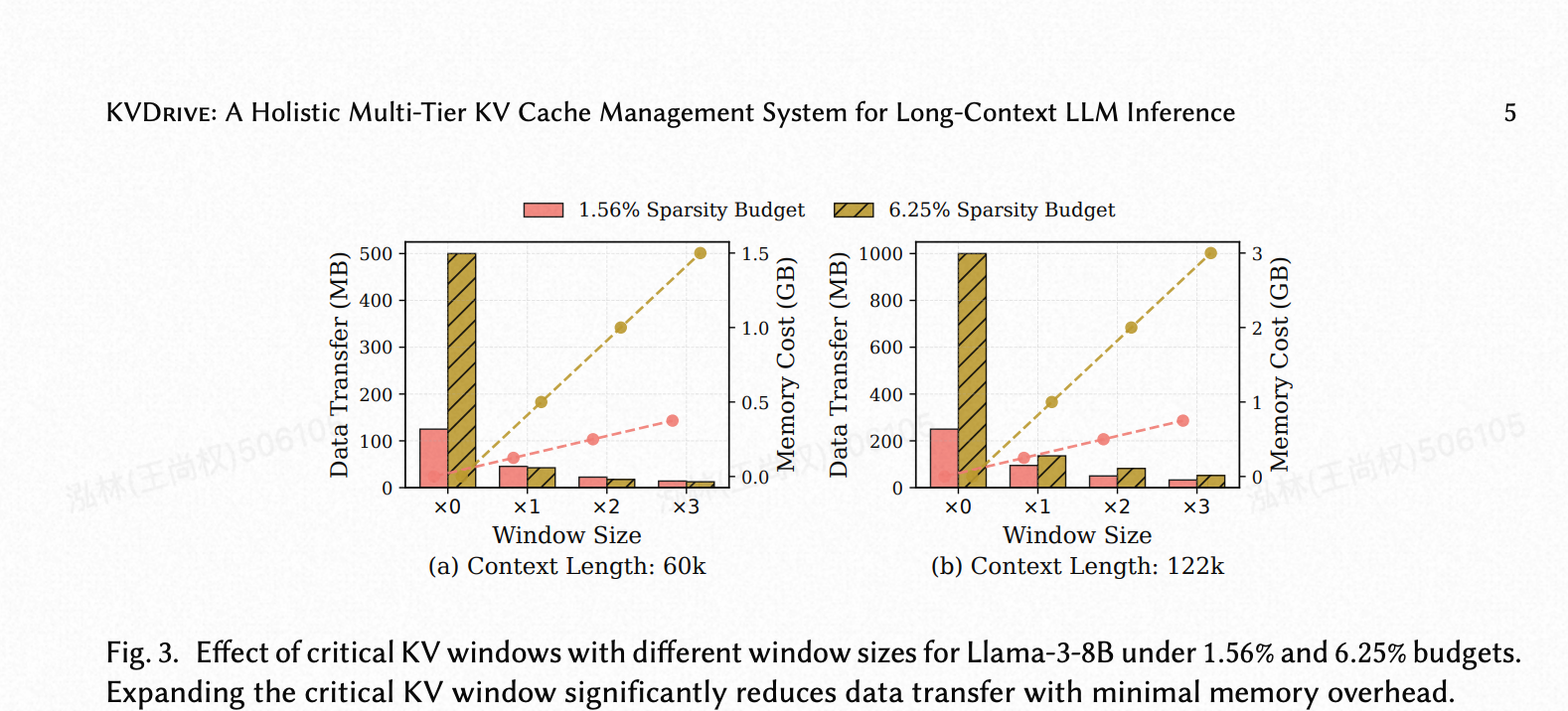
(图 3. 在 1.56% 和 6.25% 的预算下,不同窗口大小的关键 KV 窗口对 Llama-3-8B 的影响。扩大关键 KV 窗口以最小的内存开销显著减少了数据传输。)
我们用“×N”表示窗口配置,其中 N 表示窗口大小超过每步稀疏性预算的倍数。“×0”表示在每个解码步骤后不保留任何 KV 条目(即缓存完全清除),“×1”保留一个步骤的关键条目,而更大的值如“×2”对应于覆盖多个近期步骤的滑动窗口。大多数现有的卸载系统遵循每步稀疏性范式:每个解码步骤检索其对应的关键 KV 条目,使用一次后丢弃(“×0”)。少数方法,如 ShadowKV [28] 和 PQCache [40],仅保留最近一步的条目(“×1”),实现了适度的复用。如图 3 所示,我们的分析表明,维护一个多步的滑动窗口(例如,“×2”和“×3”)能产生显著更高的收益。在 6.25% 的稀疏性预算下,将窗口大小从 ×0 增加到 ×3,每步的主机-GPU 传输量从超过 500 MB 减少到 12.5 MB 以下。这一观察表明,一小部分额外的 GPU 内存,通常在考虑模型参数和中间激活值后可用,可以被有效利用来缓存最近使用的 KV 条目。
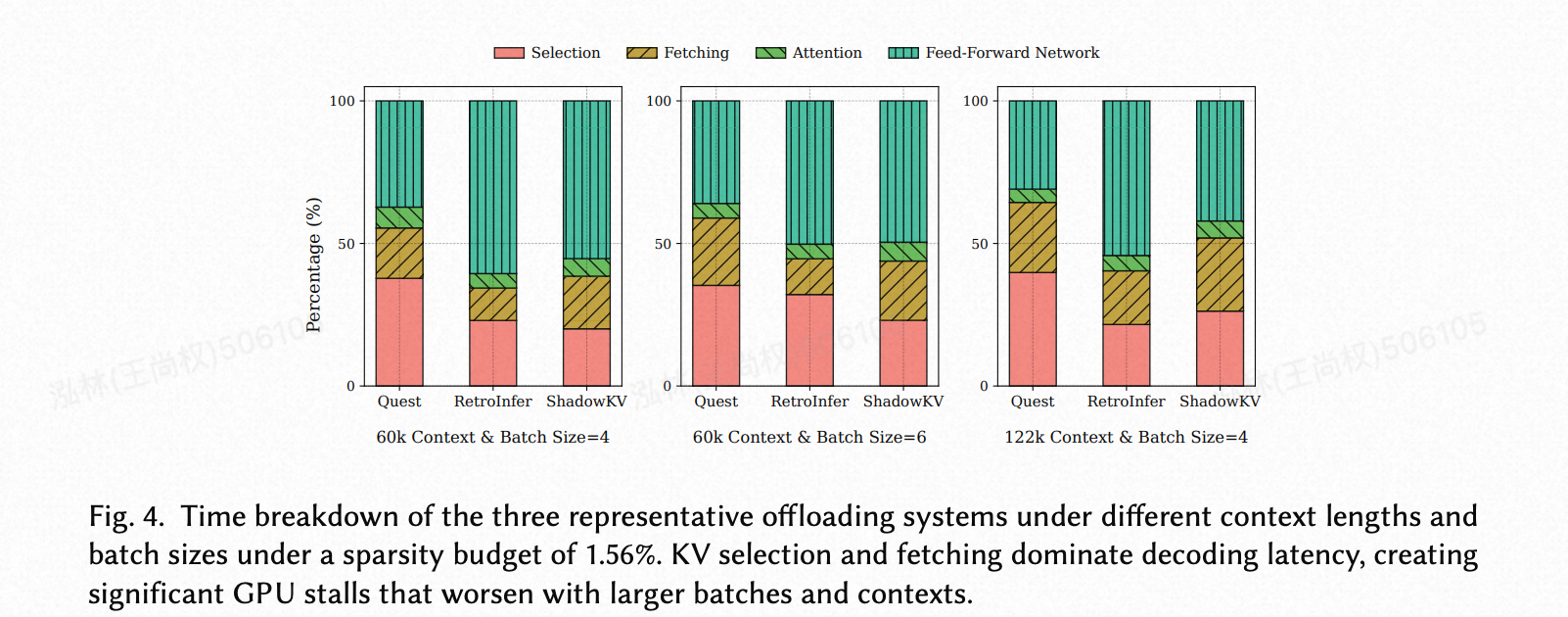
发现 2. KV 选择和获取共同占据了解码延迟的很大一部分。它们的顺序执行造成了显著的 GPU 流水线停顿,并且其影响随着批处理大小和上下文长度的增加而加剧。
如图 4 所示,在真实的上下文长度和批处理大小下,KV 选择和获取共同占用了近 50% 的总运行时间。这个瓶颈主要源于选择的高计算成本和获取的数据移动,并且随着批处理大小或上下文长度的增长而变得越来越突出。在选择阶段,不同的系统采用不同的索引方案,具有不同的计算开销。Quest [29] 对每个查询评估每个块内的最小和最大键,导致最长的选择延迟。相比之下,ShadowKV [28] 仅将查询与每个块的平均键进行比较,而 RetroInfer [6] 使用聚类中心,这两种方法都降低了选择成本。选择之后,获取阶段必须在注意力计算开始之前将识别出的 KV 条目从主机内存传输到 GPU 内存。因为大多数现有系统顺序执行这些阶段——选择,然后获取,然后计算——这两个阶段都会阻塞 GPU 执行并导致大量停顿。因此,尽管卸载减轻了 GPU 内存压力,但这些停顿在大规模应用中主导了整体运行时间,并阻止了现有系统高效处理长上下文或大批量任务。
(图 4. 三个代表性卸载系统在不同上下文长度和批处理大小下的时间分解(稀疏性预算为 1.56%)。KV 选择和获取主导了解码延迟,造成了显著的 GPU 停顿,随着批次和上下文的增大而恶化。)
发现 3. 由于 GPU 与磁盘之间的带宽远低于 GPU 与 DRAM 之间的传输带宽,现有卸载系统难以高效地将 KV 缓存迁移到磁盘,导致严重的吞吐量下降。
如图 5a 所示,当有充足的主机内存时,增加批处理大小可以显著提高吞吐量,因为更大的批次能更好地分摊内存访问和并行化计算。然而,在现实的部署约束下——典型的数据中心 GPU 节点配置有大约 100 GB 的主机内存 [12, 24],而边缘设备通常提供更少(几十 GB)——一旦同时考虑长上下文和大批量,KV 缓存很快就会耗尽可用容量。当主机内存饱和时,吞吐量会趋于平稳,最终因内存不足错误而失败。因此,仅将 KV 缓存卸载到 DRAM 的系统无法充分利用 GPU 的计算能力:内存压力不可避免地迫使缓存溢出到 SSD,而没有有效的多级管理,解码延迟再次被数据移动而不是计算所主导。例如,如图 5b 所示,我们实现了一个受 FlexGen [27] 启发的简易设计,它使用内存映射将 KV 缓存存储在磁盘上。在推理期间,每一层按需将其对应的 KV 条目从 SSD 加载到 GPU 内存,执行注意力计算,并在使用后立即将其驱逐回磁盘。虽然这种方法使得操作超出了 DRAM 容量,但它暴露了 GPU-SSD 和 GPU-DRAM 传输之间的严重带宽差距,导致吞吐量极其有限和频繁的 GPU 停顿。
(图 5. 在批处理大小为 8 和 122k 上下文下,纯 DRAM 和磁盘支持卸载的吞吐量扩展。(a) 吞吐量随批处理大小增加而增加。(b) 一个简易方案在超出 DRAM 限制的情况下运行,但遭受严重的 GPU-SSD 带宽瓶颈。)
4 系统概述
如图 6 所示,KVDrive 旨在支持高吞吐量的长上下文 LLM 推理,即使在 GPU 内存紧张的情况下也是如此。当 KV 缓存超过 GPU 容量时,它会被卸载到主机 DRAM 或 SSD,并且系统在预填充阶段在 GPU 内存中构建一个索引。在解码期间,每个新 token 都遵循一个三阶段的工作流程:通过索引识别关键 KV 条目(❶);将选定的条目从 DRAM 或 SSD 获取到 GPU HBM(❷);以及对新获取和常驻的 KV 条目的并集执行注意力和前馈计算(❸)。
KVDrive 采用的索引和稀疏注意力机制遵循了先前工作的最佳实践(§2.3)——通过一种新的分层设计,将空间分块和相似性分组相结合,以内容感知的方式组织轻量级索引。具体来说,KV 缓存被划分为块,每个页面的平均键被用作其代表 [28, 29],形成更高级别的聚类中心用于相似性分组。与全局 K-means-based 的 ANNS 方法 [20] 不同,这种分层结构保留了连续 token 之间的局部语义连续性。根据 §9,它比相似性分组方法实现了更高的检索准确性。此外,与空间分块相比,它在匹配检索精度的同时,将索引占用空间减少了 50%,并将查找速度提高了 2 倍,有效地减少了 GPU 内存压力,并促进了下游的调度和分层优化。
(图 6. 系统架构。在预填充阶段,系统将完整的 KV 缓存卸载到 DRAM/SSD,并构建一个分层索引。在解码阶段,弹性流水线调度模块协调一个三阶段流水线(❶-❸)。当基于注意力的缓存管理识别到缺失的关键 KV 条目时,调度器从协同的多级 KV 存储(DRAM/SSD)中获取所需数据到 HBM。最后,使用新获取和常驻的 KV 条目执行注意力和前馈计算。)
KVDrive 围绕三个核心组件构建:
(1) 基于注意力的缓存管理:KVDrive 通过两种互补机制超越了简单的缓存策略:(i) 一种前瞻性驱逐策略,利用当前的注意力信号来预测近期的复用,确保最可能需要的条目保持常驻;以及 (ii) 一种 2D 层-头扩展策略,根据测量的注意力局部性分配每层和每头的窗口大小。这些机制共同在紧张的 GPU 内存预算下最大化复用,同时保持固定的总体占用空间(§5)。
(2) 弹性流水线调度:通过两种互补技术重新设计了解码流水线:(i) SFC 解耦,将选择、获取和计算解耦为独立调度的阶段,实现了操作间的细粒度重叠;以及 (ii) 流水线优化,优化索引大小、缓存大小和微批次大小,以平衡准确性和吞吐量。这些机制共同消除了流水线停顿,并在不同的批次和上下文配置下维持 GPU、CPU 和 I/O 子系统的高利用率(§6)。
(3) 协同的多级 KV 存储:超越纯 DRAM 卸载,将 SSD 作为第三级,并协调跨 HBM、DRAM 和 SSD 的数据移动。KVDrive (i) 应用重要性引导的预热,在预填充期间优先处理高价值的 KV 条目,(ii) 采用 SSD 感知布局以最大化顺序 I/O 局部性,以及 (iii) 执行并行稀疏同步以最小化层级传输开销。这些机制共同实现了可扩展的长上下文推理,其能力远超 GPU 和 DRAM 的内存容量(§7)。
5 基于注意力的缓存管理
本节介绍了一种 GPU 内缓存管理方案,该方案通过利用模型的注意力机制来推断缓存条目的语义重要性,从而脱离了传统的基于使用情况的策略(如 LRU、LFU)。通过将缓存的驻留与注意力派生的重要性对齐,而不是单纯的访问新近度或频率,KVDrive 捕获了邻近 token 之间的时间局部性,并支持增量更新而非冗余重载。
5.1 带前瞻性驱逐的滑动窗口
KVDrive 在 GPU 内存中维护一个覆盖了多个近期 token 的关键 KV 条目滑动窗口。在初始化时,离线分析为给定模型建立了窗口大小与内存占用之间的映射关系。然后,系统选择在可用 GPU 缓存预算内可行的最大窗口大小,其中预算是在考虑了模型参数、激活值和中间缓冲区所占内存后确定的。这确保了缓存能充分利用剩余的 GPU 容量,而不干扰模型计算。
在解码过程中,窗口一次前进一个 token:新的关键 KV 条目从主机内存中获取,而一部分现有条目被驱逐。图 7 显示,在一个步骤中获得高注意力的条目在下一步中极有可能仍然是关键的。随着 M 的增加,与下一步的 top-K 集合的重叠部分起初迅速增加,然后趋于饱和,这表明排名高的条目被持续复用,而包含排名较低条目的边际效益迅速减小。
(图 7. 在一个解码步骤中的 Top-M 关键 KV 条目也属于下一步 Top-K 集合的数量。)
受此观察启发,KVDrive 采用了前瞻性驱逐策略,而不是传统的 LRU 或 LFU 策略:在每一步,当前步骤注意力得分最低的条目被丢弃,因为它们在后续步骤中最不可能被复用。
通过维护一个紧凑且增量更新的 KV 条目工作集,KVDrive 将主机-GPU 传输分摊到多个解码步骤中,提高了带宽效率并减少了冗余数据移动。
5.2 二维窗口缩放
我们在图 8 中的分析显示,不同的层和注意力头在扩大窗口大小时,在内存开销和传输减少之间表现出异构的权衡。对于大多数层-头对,较大的窗口只提供适度的节省,而某些层和特定的头以相同的内存成本实现了不成比例的更高传输量减少。这反映了 Transformer 层和头的不同作用:一些主要捕获局部依赖,而另一些则专门用于建模长程结构。我们应该为前者分配较少的空间(例如,图 9 中第 31 层的头 1 和 2),为后者分配更多的空间(例如,图 9 中第 31 层的头 8)。
(图 8. 不同层和头在不同窗口大小下的数据传输和内存开销。)
(图 9. KVDrive 中自适应 GPU 内缓存管理的离线初始化和在线运行。)
为了系统地利用这种异构性,我们将二维窗口缩放(2D window scaling)表述为一个离线优化问题。对于每个层 l 和头 h,分析得出:Benefit_l,h(w):使用窗口大小 w 实现的传输减少量,Cost_l,h(w):该窗口大小消耗的额外 GPU 内存。给定总 GPU 缓存预算 M,目标是:max {w_l,h} Σ_l,h Benefit_l,h(w_l,h)s.t. Σ_l,h Cost_l,h(w_l,h) ≤ M
这个分配问题是多重选择背包问题(MCKP)的一个变体,通常是 NP-难的。幸运的是,在我们的场景中,问题规模适中(几百个层-头对和一小组候选窗口大小)。在实践中,KVDrive 离线解决它:对于小模型,穷举搜索是可行的;对于大模型,我们采用贪心算法,从最小的窗口开始,迭代地扩大效益成本比最高的窗口,直到满足 GPU 缓存预算。这种方法在几分钟内产生接近最优的分配,并且不产生任何运行时开销。
通过跨层和头定制窗口大小,KVDrive 实现了更细粒度的缓存分配,在内存效率和通信成本之间取得了更好的平衡,从而在严格的资源限制下实现了高质量的推理。
6 弹性流水线调度
大多数现有系统 [7, 28, 29] 采用顺序工作流(图 10c,d),其中解码期间每一层的计算按三个阶段进行:选择关键 KV 条目,从主机内存中获取它们,以及在 GPU 上执行该层的操作。这种设计引入了大量的停顿,即当计算必须等待选择或数据传输时 GPU 的空闲周期。为了减轻停顿,InfiniGen [18] 采用了一种流水线设计,其中每一层使用来自前一层的注意力输入来预取关键 KV 条目(图 10b)。这通过重叠数据传输和计算来减少获取停顿,但选择停顿仍未解决,并且用于预取的近似可能导致次优的 KV 选择,可能在长上下文场景中降低准确性和稳定性。为了在不牺牲准确性的情况下消除这两种类型的停顿,我们提出了一种弹性流水线调度策略,详述如下。
(图 10. 不同 KV 缓存卸载调度策略的比较。)
6.1 SFC 解耦
三个紧密耦合的阶段——选择(selection)、获取(fetching)和计算(computation)——表现出不同的性能瓶颈。选择阶段在 GPU 上执行,主要是 I/O 密集型,因为它需要读取和评分大的索引区域。获取阶段主要由主机-设备数据传输主导,而计算(主要是前馈操作)在 GPU 上是计算密集型的。此外,§5 中描述的 GPU 内缓存命中/未命中评估和元数据更新需要 CPU 参与,引入了额外的同步开销。顺序执行这些阶段并对它们应用相同的批处理策略,会导致 GPU 和 CPU 计算单元以及 I/O 带宽的次优利用。
KVDrive 通过 SFC 解耦来解决这些低效问题,该方法将这三个阶段解耦以进行独立调度。每个批次被划分为多个微批次,以在选择和获取之间实现细粒度的并行性,而计算则作为单个单元对整个批次执行。在解码期间,GPU 在为当前微批次执行选择的同时,CPU 评估前一个微批次的缓存命中/未命中状态,并从主机内存中获取更早微批次的 KV 条目。一旦所有微批次都完成了获取,计算就开始。同时,缓存元数据更新与计算重叠,使系统能够保持缓存一致性而不干扰主解码流水线。这种解耦设计通过最大化 GPU、CPU 和 I/O 子系统的利用率来维持高吞吐量。
与传统的流水线重叠不同,SFC 解耦明确地将三个阶段分离为通过轻量级队列和异步传输协调的独立调度单元。这种设计在异构资源之间保持了平衡的利用率,并提供了高吞D量。
6.2 流水线优化
KVDrive 流水线的性能关键取决于三个参数:索引中的聚类中心数、GPU 缓存大小和微批次大小。这些参数共同决定了选择准确性、CPU-GPU 协调成本和整体流水线效率之间的平衡。
(1) 索引。更多的聚类中心提高了选择的粒度,但增加了选择成本,因为每个查询必须与更多的索引代表进行比较。相反,太少的聚类中心会降低识别关键 KV 条目的准确性。我们的实验表明,KVDrive 使用的聚类中心数量仅为空间分块方法 [28, 29] 的一半,就达到了相当的准确性,显著减少了选择延迟。
(2) 缓存大小。更大的 GPU 内缓存通过减少主机-设备传输来缩短获取时间,但增加了 CPU 端的命中/未命中评估时间,这可能成为新的瓶颈。在解码开始之前,KVDrive 执行一个预热阶段,逐步增加缓存大小,直到 CPU 评估时间和 GPU 获取时间达到平衡,从而在给定的内存约束下最大化端到端吞吐量。
(3) 微批次大小。微批次大小决定了流水线的粒度。过大的微批次会在重叠阶段之间产生长的空闲气泡,而过小的微批次会导致频繁的内核启动和同步开销。由于候选范围有限,KVDrive 在推理开始前执行一个简短的预运行校准,以凭经验识别最佳配置。通过这种轻量级的调整过程,系统使其调度和资源分配适应底层硬件特性,确保计算和 I/O 组件之间的平衡利用。
6.3 通过 Roofline 模型进行性能分析
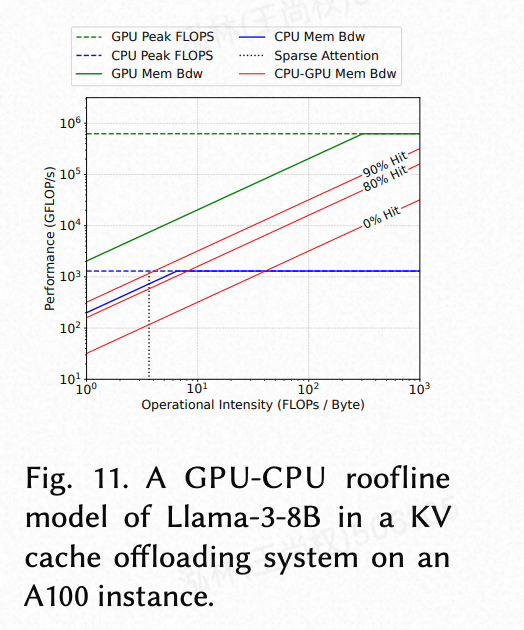
先前的工作 [4, 7] 主张在 KV 缓存卸载系统中在 CPU 上执行注意力计算,认为 CPU-GPU 传输开销主导了 GPU 执行。我们则使用 Roofline 模型 [39] 分析了为什么在我们的系统中基于 GPU 的注意力是更可取的。
(图 11. 在 A100 实例上的 KV 缓存卸载系统中,Llama-3-8B 的 GPU-CPU roofline 模型。)
图 11 显示了当所有 KV 缓存都驻留在 CPU 内存中时,Llama-3-8B 中注意力计算的 roofline 模型。当操作强度低于阈值 P 时,将数据传输到 GPU 没有任何好处,因为性能受 CPU-GPU 带宽屋顶的限制。这是先前研究中假设的区域。相比之下,我们在 §5 中的自适应缓存管理确保在每个解码步骤中,只有缓存外的关键 KV 条目——那些尚未在 GPU 内缓存中的条目——才需要从主机内存中获取。经验评估表明,即使在严格限制的缓存预算下,大约 80% 的关键条目也直接从 GPU 内缓存中提供(见 §9 中的表 3)。这种高命中率最小化了芯片外数据移动,确保操作强度保持在阈值 P 之上。因此,GPU 保持比 CPU 更高的有效吞吐量,使其成为注意力计算的更优选择。
7 协同的多级 KV 存储
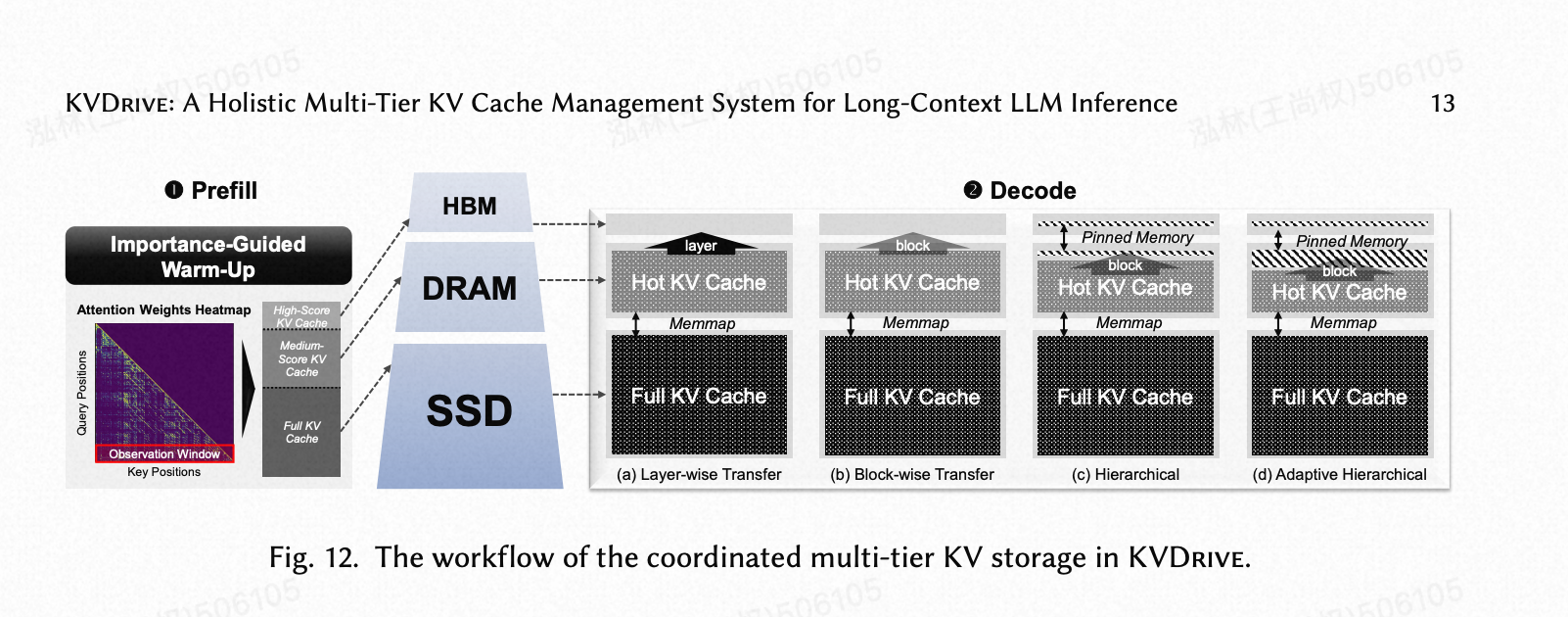
虽然 GPU 和 DRAM 为 KV 缓存提供了高带宽访问,但在长上下文或大批量下,它们的组合容量很快变得不足。为了扩展容量,先前的工作探索了将 KV 缓存卸载到 SSD [26];然而,直接将 SSD 视为 DRAM 的较慢扩展会导致频繁的高延迟传输和解码期间的停顿。为了解决这个限制,KVDrive 设计了一个协同的多级 KV 存储系统,实现了 HBM、DRAM 和 SSD 之间的高效协作。它集成了三种互补技术:用于层级放置初始化的重要性引导的预热,用于顺序 I/O 局部性的 SSD 感知布局,以及用于解码期间低延迟数据移动的并行稀疏同步流水线。
(图 12. KVDrive 中协同多级 KV 存储的工作流程。)
7.1 重要性引导的预热
在预填充阶段结束时,模型已经计算了提示的最后几个 token 与整个前缀之间的注意力。KVDrive 利用这些信息在解码开始前估计前缀 KV 条目的长期重要性。受 SnapKV [19] 的启发,我们根据提示最终观察窗口中查询产生的注意力分布,为前缀 token 分配重要性分数。
观察窗口指的是提示的最后几个 token(通常是 16-64 个 token)。对于这个窗口内的每个查询,我们计算它对所有前缀键的注意力权重,并将它们跨头和层聚合,以获得前缀位置的重要性概况。这个聚合的概况捕获了哪些 KV 条目在解码期间最有可能被复用,并直接指导它们在内存层级间的初始放置。
根据这个重要性概况,所有 KV 条目首先作为完整的后备存储持久化到 SSD,而排名较高的条目则被提升到更快的层级:得分最高的条目被放置在 GPU HBM 中以便即时访问;得分次高的条目——那些无法放入 HBM 的——被卸载到 DRAM。这种一次性的、基于注意力信息的预热为解码建立了一个平衡的起点,显著减少了后续跨层级的数据迁移。与 SnapKV 利用观察窗口进行 KV 压缩不同,我们的方法将相同的见解重新用于分层放置,实现了 HBM-DRAM-SSD 的协同管理,而不损害模型准确性。
7.2 SSD 感知布局规划
当将 KV 条目卸载到 SSD 时,数据布局成为 I/O 效率的关键决定因素。SSD 上的随机访问成本高昂,而顺序操作可以实现数量级更高的吞吐量。为了使存储组织与解码期间观察到的时间和结构访问模式保持一致,KVDrive 采用了一种两级打包策略。
我们首先定义一个 extent 为一个连续的 SSD 块,它将多个 KV 条目组合在一起。通过将条目打包到 extent 中,系统可以将细粒度的、不规则的访问转化为粗粒度的顺序传输,从而提高带宽利用率并减少访问延迟。
(1) 语义连续性打包。在解码期间经常被一同关注的 KV 条目——例如同一语义块或注意力簇内的 token——被顺序放置在同一个 extent 内。这种组织方式使得多个相关条目可以通过一次大的 I/O 被检索,最大限度地减少了跨非连续区域的随机访问开销。
(2) 层-头分区。为了进一步与 Transformer 结构对齐,extent 按层和注意力头进行分区。每个 {层, 头} 对被分配到一个专用的 SSD 段,其 extent 在该段内连续存储,以保持结构局部性。
通过将语义连续性打包与层-头分区相结合,KVDrive 将固有的不规则 KV 访问模式重塑为可预测的、高吞吐量的顺序 I/O。这种 SSD 感知布局设计显著降低了访问延迟,并提高了端到端解码效率,使基于 SSD 的分层即使对于长上下文和大批量工作负载也变得实用。
7.3 并行稀疏同步
在 SSD、DRAM 和 GPU HBM 之间的高效数据传输对于在多级卸载下维持解码吞吐量至关重要。虽然 SSD 提供大容量,但其带宽显著低于 DRAM,频繁的迁移很容易成为新的瓶颈。图 12(右)比较了四种逐步提高数据移动效率的同步策略。
(a) 朴素的逐层传输。这遵循 FlexGen [27] 的做法:在每个解码步骤,整个层的 KV 缓存从 SSD 传输到 HBM,使用 DRAM(通过 memmap)作为被动缓冲区。虽然简单,但这种设计几乎不提供复用:当 DRAM 缓存小于总 KV 占用时,后续的层传输会覆盖先前缓存的数据,导致冗余 I/O 和频繁的流水线停顿,如 §3 所述。
(b) 块级稀疏获取。KVDrive 不是迁移整个层,而是只传输当前注意力查询实际需要的 KV 条目块(簇)。这种细粒度的选择减少了冗余传输,并更好地匹配了注意力的稀疏模式。为避免过多的随机 I/O,多个块请求被合并为 extent 大小的顺序读取,并具有足够的队列深度,确保高 SSD 吞吐量和 I/O 流水线的高效利用。
© 分层传输。为了进一步减少 SSD 延迟并重叠数据准备与计算,KVDrive 采用了分层暂存流水线。从 SSD 获取的 KV 条目首先被读入 DRAM 支持的 memmap 区域,然后在 GPU 执行前暂存到预分配的页锁定(page-pinned)缓冲区。这种设计有两个目的:(i) 通过重用一个稳定的锁定缓冲区池来避免重复分配锁定内存,以及 (ii) 启用异步预取——KV 条目可以在选择和预注意力(QKV 投影)期间提前读取。
(d) 平衡协调。最后,KVDrive 平衡了锁定缓冲区和 memmap 缓存的优点。锁定内存提供高带宽访问,而 memmap 区域则作为 DRAM 中的一个大型被动缓存。这两种层级之间的分配由离线分析指导,优先将锁定内存分配给表现出频繁停顿的层-头 KV 条目——这些模式经验上与 memmap 层中页错误频发的区域相关——并将这些区域常驻在锁定内存中,以确保在整个解码过程中稳定地高带宽访问。
总的来说,这种并行稀疏同步实现了 HBM、DRAM 和 SSD 之间的有效多级协调,在长上下文和大批量设置下维持了高的 GPU 利用率。
8 实现
我们已经实现了一个功能齐全的 KVDrive 原型,包含约 9000 行 Python 代码、1000 行 C++ 代码和 3000 行 CUDA 代码。该系统基于 PyTorch 2.3.0 和 Python 3.12,运行在 Ubuntu 22.04 和 CUDA 12.1 上。为支持大型 KV 缓存存储,KVDrive 采用 numpy.memmap 实现内存映射数组,从而能够直接在磁盘上对 KV 张量进行持久化和页级访问。稀疏更新和检索通过 torch.Tensor.index_copy_() 执行。对于聚类,我们采用了 RetroInfer [6] 的 Triton 内核,而用于收集和复制的数据移动原语则源自 ShadowKV [28]。我们还利用 FlashInfer [36] 实现为 LLM 推理优化的高性能 GPU 内核(如注意力和归一化)。至关重要的是,我们的实现通过连续批处理完全支持并行会话,这是现代服务系统(如 Orca [37] 和 vLLM [16])广泛采用的技术。为确保公平比较,§9 中提到的所有基线系统都已在我们的统一评估框架中重新实现和集成,以确保一致的配置和公平的比较。此外,所有长上下文模型均采用 huggingface 的 transformers 框架提供的官方 RoPE 实现(例如,Qwen 模型的 YaRN 和 Phi 模型的 LongRoPE),以确保跨基线的兼容性和一致性。
9 实验
9.1 实验设置
模型。为进行评估,我们选择了四种广泛使用的、具有强大长上下文能力的开源 LLM:Llama-3-8B-1048K [2](8B 参数,1M token 上下文窗口)、Qwen3-8B 和 Qwen3-14B [33](128K token 上下文窗口),以及 Microsoft Phi-4-mini-instruct [1](3.8B 参数,128K token 上下文窗口)。这些模型共同覆盖了广泛的参数规模和上下文长度,为评估 KVDrive 和基线的有效性提供了代表性基础。
基准测试。我们在两个广泛使用的长上下文基准上评估 KVDrive:LongBench [3],一个用于长上下文理解的双语数据集,和 RULER [13],它涵盖了检索、多跳推理、聚合和问答任务。
基线。我们将 KVDrive 与八个基线配置进行比较。这些包括 Original,它将整个 KV 缓存保留在 GPU 内存中而不进行卸载,以及 FlexGen [27],它采用全缓存策略,在注意力计算期间反复地在 GPU 和主机内存之间加载和驱逐 KV 条目。此外,我们还与五个最先进的 KV 缓存卸载系统进行了比较:Quest [29]、ShadowKV [28]、PQCache [40]、MagicPIG [7] 和 RetroInfer [6]。为了公平比较,我们评估了 RetroInfer 的两个变体:带有原生注意力估计的原始 RetroInfer(E),以及禁用了此机制的修改版 RetroInfer。对于除 FlexGen 和 Original 之外的所有系统,我们应用精确预填充,然后在解码阶段使用动态稀疏注意力。遵循现有系统 [7, 31] 的常见做法,所有稀疏注意力基线都在 GPU 内存中保留 sink token(前 4 个 token)和 64 个本地 token,因为这些 token 一贯表现出高重要性。最后,对于 ShadowKV,我们采用其原始论文中的配置,将块大小设置为 8,离群点数量设置为 48。
硬件设置。我们在三个代表性的硬件环境中进行实验,覆盖不同的部署层级:1) 高性价比服务器:配备 NVIDIA L20 (48 GB) GPU、Intel® Xeon® Platinum 8457C CPU 和 100 GB DDR5 主机内存。此配置代表了一个实际的、面向推理的数据中心节点,具有中等 GPU 内存和高 PCIe 带宽。2) 高端服务器:配备 NVIDIA H20 (96 GB) GPU、AMD EPYC 9K84 96核处理器和 200 GB DDR5 主机内存。它反映了企业或云规模部署中典型的计算密集型环境,具有更大的 GPU 内存和更强的主机端计算能力。3) 工作站:由 NVIDIA RTX 4090 (24 GB) GPU、Intel® Xeon® Gold 6430 CPU 和 120 GB DDR5 主机内存驱动。此设置模拟了一个资源受限的本地推理场景,代表了边缘或本地部署。系统中的磁盘是 NVMe U.2 SSD。
9.2 整体提升
图 13 展示了在 L20 服务器上,使用 Llama-3-8B-1048K、Qwen-3-8B 和 Phi-4-Mini-128K 模型,在不同批处理大小和上下文长度下评估的各种系统的生成吞吐量(token/s)。KVDrive 在所有评估配置中始终优于所有基线系统。值得注意的是,与我们评估中最具竞争力的基线 ShadowKV 相比,KVDrive 的吞吐量提升高达 70%。这一显著的性能增益主要归功于我们提出的弹性流水线调度和高效缓存管理机制。相反,一些基线系统在处理长上下文生成的严格内存和计算需求时举步维艰。例如,MagicPIG 在初始化期间失败,因为它依赖于一个巨大的预计算索引结构;存储长上下文模型的这个索引所需的内存开销超过了可用的主机内存容量,导致立即出现内存不足(OOM)异常。同样,Original 基线在重负载下也因 OOM 失败,因为将庞大的 KV 缓存完全保留在内存中会带来不可持续的内存压力。此外,在能够成功初始化的系统中,FlexGen 在实际设置中表现出次优性能。尽管它通过将数据积极卸载到主机内存来规避 OOM 错误,但其执行模型要求在每个生成步骤中从片外存储加载整个 KV 缓存。这种严重 I/O 密集型的方法导致了严重的延迟惩罚,使吞吐量暴跌至不到 1 token/s。因此,这种令人望而却步的性能下降使得 FlexGen 在实际部署中不切实际,特别是对于延迟敏感的应用。
(图 13. 在 L20 服务器上,不同上下文长度和批处理大小下的生成吞吐量(tokens/s)。)
(图 14. 在不同批处理大小和上下文长度下的生成吞吐量(tokens/s)。)
相比之下,KVDrive 在所有评估的硬件配置中都表现出稳健且一致的性能。如图 14 所示,它在 H20 和 RTX 4090 服务器上都比表现最好的基线实现了 1.23 倍到 1.53 倍的吞吐量提升。这些结果突显了 KVDrive 的效率和可扩展性,特别是在要求长上下文和大批量推理都具有高吞吐量的场景中。其在不同硬件和工作负载条件下保持卓越性能的能力进一步验证了其设计的多功能性和稳健性。
9.3 微观基准测试
准确性。我们首先检查 KVDrive 中的系统级优化是否会损害模型准确性。表 2 报告了在 RULER 和 LongBench 上的结果。在所有任务中,KVDrive 的准确性与 Quest、ShadowKV 和 InfiniGen 等最先进的卸载系统相当,甚至略好。这表明,我们在 §4 中的索引和检索设计引入的准确性损失可以忽略不计,即使在长达 128K token 的上下文中也是如此。结果证实,KVDrive 的增益主要来自改进的缓存管理和调度,而不是以牺牲准确性换取效率。
(表 2. 不同模型和方法在 RULER 和 LongBench 上的性能比较。)
驱逐策略的普适性。表 3 通过将我们的前瞻性(LA)驱逐策略应用于四个不同的系统:Quest、ShadowKV、RetroInfer 和 KVDrive,来评估其普适性。实验在 120k 上下文长度、窗口大小为 2、稀疏性预算为 2048、前瞻候选池 M=2560 的条件下进行。如表所示,LA 策略表现出广泛的适用性,在大多数配置中优于传统的 LRU 基线。
(表 3. 前瞻性(LA)驱逐策略在不同系统上的有效性。)
具体来说,在 Llama3-8B-1048K 和 Qwen-3-8B 上,LA 策略在所有评估方法中都持续提高了命中率,增益范围从 0.9% 到 3.9%。这表明,基于注意力分数识别驱逐候选者(详见 §5.1)对于各种系统架构都是一种稳健的方法。虽然 Quest 在两种策略下都取得了略高的命中率,但它带来了显著的开销:其索引大小比 KVDrive 大 4 倍以上,比 ShadowKV 大 2 倍。相比之下,KVDrive 配合 LA 策略在保持显著较小内存占用的同时,实现了可比的命中率。
二维窗口缩放。图 15 报告了我们为 Llama-3-8B-1048K、Phi-4-Mini-128K 和 Qwen-3-8B 在 §5.2 中提出的二维窗口缩放策略的消融实验结果。在受限的 GPU 内存预算下,与统一窗口分配相比,二维缩放导致了更少的数据传输。这表明,跨层和注意力头的异构复用模式可以有效提高 GPU 缓存利用率,避免 GPU 缓存的浪费。
(图 15. 二维窗口缩放对不同窗口大小和模型下数据传输量的影响。)
窗口大小。图 16 描绘了在 1.56% 稀疏性预算下单个 Transformer 层的延迟分解。我们通过在 60k 和 120k 的上下文长度以及 1 和 4 的批处理大小下,对 {2, 3, 4} 的窗口大小进行扫描来评估性能。随着窗口大小的增加,数据传输量的减少减轻了 I/O 开销;然而,这种好处被增加的查找延迟所抵消。这种权衡需要在 I/O 效率和查找开销之间进行仔细平衡。具体来说,当批处理大小为 1 时,较小的窗口大小(例如 2)通常产生较低的延迟。
(图 16. KVDrive 在不同窗口大小和模型下,以 1.56% 稀疏度的时间分解。)
这归因于随着缓存容量扩大,查找时间激增,而 I/O 带宽仍未被充分利用。相反,在批处理大小为 4 时,较大的窗口大小(例如 4)被证明更有效,主要是由于对 I/O 带宽的需求减少。这些结果突显了窗口大小选择在最大化吞吐量中的关键作用。此外,随着批处理大小从 1 扩展到 4,非 FFN 模块(包括选择、查找、注意力和 I/O)的延迟贡献显著增加。这种转变表明,非 FFN 组件在较大的批处理大小下成为主要瓶颈,突显了优化这些模块以实现可扩展性的必要性。
块大小。图 17 描绘了在 1.56% 稀疏性预算下单个 Transformer 层的延迟分解。我们评估了在 60k 和 120k 的上下文长度下,通过扫描 {1, 4, 8} 的块大小的性能。值得注意的是,我们观察到随着块大小的增加,总延迟和特定 I/O 延迟都呈现出明显的 U 形趋势。这种行为反映了语义连续性和数据冗余之间的基本权衡。对于小块大小(例如 1),数据以零散的单元进行处理,需要频繁的内存访问,从而增加了 I/O 开销。相反,过大的块大小(例如 8)引入了冗余信息,这增加了数据传输量,并抵消了减少访问频率的好处。中等大小的块(例如 4)达到了最佳平衡,在保持足够语义连续性的同时最小化了冗余,从而实现了最低的 I/O 成本。
(图 17. KVDrive 在不同块大小下,以 1.56% 稀疏度的时间分解。)
聚类中心数量。图 18 分解了执行单个 Transformer 层的延迟。我们评估了在 60k 和 120k 的上下文长度下,在固定的 1.56% 稀疏性预算下,扫描聚类中心数量 {2,048, 4,096, 8,192} 的性能。我们观察到上下文大小和最佳聚类中心数量之间存在一致的关系:具体来说,8,192 个聚类中心为 120k 上下文带来了最佳性能,而 4,096 个聚类中心对于 60k 是最佳的。这表明上下文长度与聚类中心的最佳比例保持不变。虽然增加聚类中心数量会因聚类计算复杂性增加而带来更高的选择延迟,但这种开销被 I/O 和查找时间的显著减少所有效缓解。更多的聚类中心有助于更细粒度的聚类,从而更均匀地在聚类之间分配数据。这种改进的负载平衡减少了同步开销,并增强了数据局部性,从而降低了内存密集型组件的延迟。
(图 18. KVDrive 在不同聚类中心数量下,以 1.56% 稀疏度的时间分解。)
聚类中心减少的影响。图 19 考察了 KVDrive 在不同聚类中心数量下,在 QA-2、变量跟踪和高频词提取等任务上的准确性。结果表明,无论聚类中心数量如何,准确性都保持一致,突显了聚类方法的稳健性。值得注意的是,将聚类中心数量从 8192 减少到 2048,实现了 4 倍的索引大小减少,而没有任何精度损失。这一观察结果强调了聚类机制在即使聚类中心较少的情况下,也能有效保留准确执行任务所需的语义结构。索引大小的减少直接转化为更低的内存和存储开销,提高了方法的整体效率。
(图 19. 不同聚类中心数量下各任务的准确性。)
内存布局。在批处理大小为 8 和上下文长度为 120k 的情况下,图 20 评估了各种系统在 Llama-3-8B-1048K、Qwen-3-14B 和 Phi-4-Mini-128K 三个模型上的 GPU 内存使用情况。在评估的系统中,与 ShadowKV 和 Quest 相比,KVDrive 的 GPU 内存使用量显著降低。这一结果主要归功于其稀疏而高效的索引机制。相反,ShadowKV 由于其依赖于完全驻留在 GPU 内存中的压缩键存储,产生了大量的内存开销并带来了显著的成本。FlexGen 通过避免索引的内存存储实现了最低的 GPU 内存利用率。然而,这种设计是以牺牲性能为代价的:FlexGen 必须在每个生成步骤重新加载一层的整个 KV 缓存,引入了严重的 I/O 瓶颈和极高的延迟。相比之下,KVDrive 的内存占用虽然略高于 FlexGen,但通过其高效的缓存和稀疏索引策略避免了这些 I/O 惩罚。此外,随着窗口大小的增加(例如,从 1 到 2),KVDrive 在显著减轻 I/O 压力的同时,保持了比 Quest 和 ShadowKV 更低的 GPU 内存使用量。
(图 20. 不同模型下内存布局的比较。)
纯 DRAM vs DRAM + SSD。图 21 比较了 FlexGen 和我们的方法在 Llama-3-8B-1048K 模型的各种配置下的性能,重点关注获取时间和吞吐量。如图 21a 所示,我们的“块级传输”策略比 FlexGen 提供了显著的性能改进。通过按需稀疏地获取所需的块,我们的方法与 FlexGen 的全层加载机制相比,显著减少了获取开销。此外,带有异步获取的“分层”策略通过实现更高效的查找和数据访问,进一步最小化了延迟。此外,加入一个预填充预热阶段,该阶段在最终预填充阶段识别关键 KV 缓存条目,通过优先处理高价值缓存组件,进一步优化了获取时间。图 21b 表明,我们的方法在所有配置中都实现了比 FlexGen 高得多的吞吐量。值得注意的是,当使用 SSD 作为存储层次结构的一部分时,KVDrive 维持了高吞吐量,与纯 DRAM 配置相比仅下降了 40%,同时支持更大的批处理大小。
(图 21. 纯 DRAM 和 DRAM + SSD 的性能比较。)
预填充延迟。图 22 评估了 Llama-3-8B-1048K 的预填充延迟。KVDrive 在所有上下文长度上都与全注意力基线(Original)的性能相当,表明其索引构建和卸载带来的开销可以忽略不计。这种效率归功于我们 K-Means 聚类的低计算成本——其渐近优于二次方的自注意力——以及通过计算-通信重叠有效掩盖了卸载流量。相比之下,MagicPIG 和 ShadowKV 由于特定的瓶颈表现出更高的延迟:MagicPIG 受限于大型 LSH 表的构建,而 ShadowKV 则因低秩键分解而产生额外成本。
(图 22. 不同上下文长度下的预填充延迟(秒)。)
成本效益分析。为了展示我们设计的经济优势,图 23 比较了 Llama-3-8B-1048K 在两个硬件层级上的推理性能:使用标准内存服务的顶级 NVIDIA H20 (96GB HBM),以及由 KVDrive 驱动的消费级 NVIDIA RTX 4090 (24 GB HBM)。图 23a 显示,KVDrive 通过有效的稀疏卸载将内存占用减少了约 4 倍,而 H20 基线即使有更大的容量也接近内存饱和。通过打破内存墙,KVDrive 使 RTX 4090 的吞吐量比 H20 基线高出 3 倍(图 23b)。这一结果证明,通过优化的存储层次结构,消费级硬件可以有效地服务于以前仅限于企业级 GPU 的长上下文工作负载。
(图 23. Llama-3-8B-1048K 的成本效益分析。)
批处理大小。图 24 展示了 KVDrive 在不同批处理大小下的生成吞吐量,评估了多个模型和上下文长度。如图所示,随着批处理大小的扩展,系统在吞吐量上保持了稳健的上升趋势。这种效率源于我们的执行机制,它将 I/O 和 CPU 端的预处理与 GPU 端的计算在微批次之间进行重叠。通过交错这些不同的操作,KVDrive 有效地隐藏了数据移动开销并最大化了 GPU 利用率,从而在没有显著性能下降的情况下支持了更大的批处理大小。
(图 24. 不同批处理大小下的生成吞吐量(tokens/s)。)
10 结论
我们提出了 KVDrive,一个用于长上下文 LLM 推理的整体性多级 KV 缓存管理系统。KVDrive 引入了三项系统级技术:基于注意力的、带有滑动窗口复用和前瞻性驱逐的 GPU 内缓存管理,以最小化停顿来重叠选择、获取和计算的弹性流水线调度,以及协同的多级 KV 存储。我们的评估表明,KVDrive 在保持准确性的同时,将吞吐量提高了 1.74 倍,超过了最先进的卸载系统。这些结果证明了系统级缓存和流水线协同设计在紧张的 GPU 预算下实现高效长上下文推理的有效性。
11 未来工作
在 KVDrive 的基础上,我们未来的研究将聚焦于三个关键方向。首先,我们旨在将我们的整体管理扩展到多模态模型,这些模型呈现出与纯文本 LLM 不同的 KV 缓存访问模式。其次,我们计划研究存内计算(Processing-in-Memory)硬件,以便将选择和部分计算直接卸载到存储层,从而进一步缓解数据移动瓶颈。最后,我们计划探索 KVDrive 与压缩技术(如量化和剪枝)之间的协同作用。我们设想一种分层混合精度存储方案,该方案利用 KVDrive 区分冷热 KV 块的能力,并在不同层级上自适应地分配精度:为 HBM 中延迟关键的热块保持高精度(例如 FP16),同时对溢出到 SSD 的冷块应用更激进的量化(例如 INT4)。这种设计以适度的(反)量化开销换取更高的有效 I/O 带宽和存储容量,旨在缓解大规模上下文检索中的 I/O 瓶颈,同时保持端到端的生成质量。
(参考文献部分保持原文格式,未翻译)
好的,这是一个非常核心且技术性很强的段落。我来为您把它拆解成通俗易懂的解释,并用一个生动的比喻来帮助理解。
一句话概括
KVDrive 不再使用“最近用过”或“最常用”这种简单的规则来管理 GPU 的高速缓存,而是通过预测 LLM 下一步“认为”什么信息最重要,来智能地决定哪些数据应该留在高速缓存里,从而大大提高效率。
详细分解与比喻
想象一下,你是一位需要查阅大量资料才能写文章的作家。
- 你的大脑/桌面 (GPU 显存):处理信息速度极快,但空间有限,放不下所有资料。
- 你旁边的书架 (主机 DRAM):空间比桌面大,找资料比去图书馆快,但还是需要起身去拿,有点耗时。
- 巨大的图书馆 (SSD 硬盘):藏书量无限,但每次去找书都要花费很长时间。
- 你要写的文章 (LLM 生成的文本)
- 你查阅的资料 (KV 缓存条目)
1. 传统缓存管理的问题 (通用访问频率或新近度)
传统的缓存策略就像一个习惯不好的作家:
- 最近最少使用 (LRU):桌子满了,就把最久没碰过的那本书放回书架。
- 最不常使用 (LFU):桌子满了,就把用得次数最少的那本书放回书架。
问题在于:这种方法很“笨”。你可能刚刚查完一本书(所以它“最近”或“常用”),但写下一句话时可能就完全用不到了。而一本很久没看或很少看的书,可能恰恰是下一段的关键参考。传统策略无法理解内容的相关性,只会做机械的判断,导致你频繁地往返于书架和桌面之间,效率低下。
2. KVDrive 的“注意力感知”方案
KVDrive 就像一个聪明的作家,它理解资料的重要性。
- 注意力感知能力:LLM 在生成每个词时,都会给所有历史信息(KV 缓存)打一个“注意力分数”,来判断哪些信息对生成当前这个词最重要。KVDrive 就利用了这个“注意力分数”。它不再关心你“什么时候”用了这本书,而是关心这本书对你写出刚才那句话“有多大帮助”。
3. KVDrive 的具体做法
a. 滑动窗口 (Sliding Window)
- 比喻:聪明的作家不会只在桌上留一本刚看过的书。他会把最近写好几句话时用到的一小堆最重要的书都放在桌上。这个“一小堆书”就是“滑动窗口”。
- 技术解释:KVDrive 不仅保留上一步骤中最重要的 KV 条目,而是保留最近几个步骤中所有被认为是重要的 KV 条目的集合。因为一个主题的讨论往往会持续几个词,所以这些信息在短期内被再次使用的概率非常高(即“时间局部性”)。
b. 增量更新窗口外的差异
- 比喻:当作家要写下一句话时,他会先看看桌上这“一小堆书”够不够用。他发现,80%的书对下一句话仍然很重要,只有20%的新知识需要去书架上拿新书。于是,他只需要去书架拿那几本新书,而不是把桌子清空再重新搬一堆书过来。
- 技术解释:当需要计算下一个词时,KVDrive 会先确定新的一批“关键 KV 条目”。然后,它将这个新列表与已存在于 GPU 缓存(滑动窗口)中的列表进行比较,只去主机内存或 SSD 中加载那些“新需要”但“缓存里没有”的条目。这大大减少了数据传输量。
c. 前瞻性驱逐策略 (Lookahead Eviction)
- 比喻:现在桌子满了,必须放一本书回书架来腾出空间。笨作家会放回最久没碰的书。而 KVDrive 这个聪明作家会想:“根据我刚写的这句话,哪本书对下一句最可能没用?” 然后把那本“未来最没用”的书放回去。
- 技术解释:当 GPU 缓存需要释放空间时,KVDrive 会查看当前步骤中哪些 KV 条目的“注意力分数”最低。得分最低意味着它对当前词的贡献最小,因此它在下一步骤中再次成为关键的可能性也最低。于是,这些低分条目就被优先踢出缓存。
d. 二维的层-头缓存分配
- 比喻:作家还发现,有些类型的书(比如核心概念)在整篇文章中都频繁需要,而另一些书(比如某个例子的细节)只在特定段落有用。于是,他决定在桌面上给“核心概念”类的书留出更多、更稳定的空间,而“例子细节”类的书则可以更频繁地替换。
- 技术解释:LLM 的 Transformer 架构由很多“层(Layer)”和“头(Head)”组成,它们的功能不同。有些专门看长距离依赖,有些看语法结构。KVDrive 分析后发现,不同层/头的 KV 缓存复用模式也不同。因此,它会给那些复用价值高的层/头分配更大的缓存窗口,给价值低的分配小一点的窗口。这是一种精细化的资源分配,确保有限的 GPU 显存用在“刀刃”上。
总结
总而言之,这段话描述了 KVDrive 的核心创新:它抛弃了“一视同仁”的传统缓存管理方法,转而利用 LLM 自身的注意力机制,打造了一套“有远见”的系统。通过滑动窗口、增量更新、前瞻性驱逐和精细化分配这四招,KVDrive 最大限度地让 GPU 随时能拿到它最想要的数据,极大地减少了等待时间,从而实现了推理速度的飞跃。
好的,这是一个非常好的问题,直击了 KVDrive 与传统卸载方案(如 FlexGen)在设计哲学上的核心区别。
简单来说,之所以称 FlexGen 等系统是“粗粒度”的,是因为它们操作和移动数据的基本单位非常大且不精确。
让我们用一个生动的比喻来解释:
比喻:去超市购物
- 你的厨房 (GPU 显存):空间很小,但做菜(计算)很快。
- 你家的储藏室 (主机 DRAM):比厨房大,但拿东西要走几步。
- 大型超市 (SSD 硬盘):几乎什么都有,但去一趟很花时间。
- 做一道菜 (LLM 生成一个词):需要用到各种食材(KV 缓存条目)。
- 菜谱 (注意力机制):告诉你这道菜具体需要哪些食材。
FlexGen 的“粗粒度”方法 (逐层卸载)
FlexGen 的做法就像一个计划性很差的购物者。
- 菜谱说:“你需要用到乳制品区的『牛奶』和『黄油』。”
- 你的操作是:把整个“乳制品区”的所有商品(牛奶、黄油、酸奶、奶酪、奶油…)全部搬回你的厨房。
- 在厨房里,你只拿出牛奶和黄油用了,其他东西都堆在一边占地方。
- 下一步菜谱说:“需要蔬菜区的『番茄』。”
- 你又把厨房里所有的乳制品搬回储藏室,然后去超市把整个“蔬菜区”的所有商品(番茄、土豆、黄瓜、生菜…)全部搬回厨房。
这就是“粗粒度”:
- 操作单位大:你的操作单位是“整个货架/区域”(整个层的 KV 缓存)。
- 不精确:你根本不关心你具体需要什么,只要是这个区域的,就全部拿过来。
- 导致“I/O 放大”:你真正需要的可能只有 2 样东西(2 个 KV 块),但你却来回搬运了 200 样东西(整个层的所有 KV 块)。你的“搬运”工作量(I/O)被严重放大了 100 倍。对于带宽有限的超市通道(PCIe 总线)来说,这是巨大的浪费和拥堵。
KVDrive 的“细粒度”方法 (并行稀疏同步)
KVDrive 则像一个极其高效的购物者。
- 菜谱说:“你需要用到乳制品区的『牛奶』和『黄油』。”
- 你的操作是:在购物清单上精确写下“牛奶”、“黄油”。然后去超市,直奔乳制品区,只拿起“牛奶”和“黄油”这两样东西,然后回到厨房。
- 下一步菜谱说:“需要蔬菜区的『番茄』。”
- 你又去超市,只拿起“番茄”,然后带回厨房。
这就是“细粒度”:
- 操作单位小:你的操作单位是“具体的商品”(特定的 KV 块)。
- 精确:你通过注意力机制(菜谱)提前知道了你到底需要什么,然后只拿你需要的。
- 避免“I/O 放大”:你需要 2 样东西,就只搬运 2 样东西。搬运量(I/O)与你的实际需求完全匹配,没有浪费。
回到技术层面
- 稀疏注意力 (Sparse Attention):这个概念是关键。在长上下文中,LLM 生成一个新词时,并不会关注历史上所有的词。它可能只关注几百个或几千个“关键”的旧词。这就是“稀疏”的含义。
- FlexGen 的问题:它不管注意力是不是稀疏的。对于一个拥有 100 万个词历史记录的对话,即使 LLM 只需要其中 1000 个词的信息来生成下一个词,FlexGen 仍然会把这 100 万个词对应的一整层 KV 缓存从 SSD/DRAM 搬到 GPU。这是巨大的浪费。
- KVDrive 的优势:它首先利用稀疏注意力机制,在 GPU 上快速计算出:“在这一层,我只需要历史记录中第 100、523、8000… 等 1000 个位置的 KV 块”。然后,它向 SSD/DRAM 发出精确指令:“把这 1000 个块给我拿过来”。传输的数据量大大减少。
总结
| 特征 | FlexGen (粗粒度) | KVDrive (细粒度) |
|---|---|---|
| 操作单位 | 整个层 (Layer) 的全部 KV 缓存 | 特定的、小的 KV 块 (Block) |
| 数据选择方式 | 盲目地加载整个层 | 根据注意力机制,按需选择 |
| 数据传输量 | 巨大,与总上下文长度成正比 | 精简,与实际需要的“关键”上下文成正比 |
| I/O 放大 | 严重。获取了大量未使用的 KV 块 | 几乎没有。只获取需要的 KV 块 |
| 效率 | 在稀疏注意力场景下极其低下 | 高,与稀疏注意力的工作模式完美契合 |
因此,说 FlexGen 是“粗粒度的”,是在批评其数据移动策略过于笼统和浪费,尤其是在稀疏注意力成为主流的长上下文推理场景下,这种方法的低效性被急剧放大了。
当然,这又是一个非常核心且精妙的观点。我们来逐一拆解。
这个问题包含两个部分:
- 什么是“稀疏 I/O”?为什么 I/O 会是“稀疏”的?
- “短程时间局部性”和“长程范围”这段话是什么意思?
1. 什么是“稀疏 I/O” (Sparse I/O)?
“稀疏” 在这里的意思是 “分散的、不连续的”。
想象一下你的 KV 缓存像一本厚达 100 万页的巨书,存储在慢速的硬盘(SSD)或主机内存(DRAM)上。每一页代表一个历史词元(token)的信息。
- 常规/连续 I/O (Dense I/O):读取这本书的第 1 到 1000 页。这是一个连续的操作,硬盘/内存可以非常高效地一次性读取一个大块。就像你从书架上一次性抽出一整沓连续的纸。
- 稀疏/随机 I/O (Sparse I/O):你需要的信息是第 5 页、第 89 页、第 1024 页、第 50000 页和第 980000 页。这些页面在物理存储上是分散在各处的。为了获取它们,系统必须:
- 找到第 5 页的位置,读取它。
- 跳到第 89 页的位置,读取它。
- 再跳到第 1024 页的位置,读取它。
- …如此反复。
这个“跳跃”的动作在计算机存储中是非常耗时的。无论是机械硬盘的磁头寻道,还是 SSD 的主控开销,处理大量小的、不连续的读写请求,其效率远低于处理一个大的、连续的请求。
为什么 LLM 推理会导致稀疏 I/O?
因为“稀疏注意力”机制。在长上下文中,模型为了生成一个新词,并不会看遍历史上所有的 100 万个词。它可能只关注其中几千个最关键的词。而这几千个关键的词在原始的文本序列中是零散分布的。
所以,当 KVDrive 需要从 SSD/DRAM 中获取这些关键的 KV 缓存块时,它发出的指令不是“给我从地址 A 开始的 1GB 数据”,而是“给我地址 A 的 4KB,地址 B 的 4KB,地址 C 的 4KB…”,这些地址 A, B, C… 在存储介质上相距甚远。这就是“稀疏 I/O”。
2. “短程时间局部性”与“长程范围”
现在我们来解释这句引文:
“最近的研究 [28, 40] 观察到短程时间局部性——即连续的查询通常会关注重叠的关键 KV 条目——但这一点在长程范围内尚未得到系统性分析。”
让我们用一个写作的比喻来理解:
你在写一篇关于“可再生能源”的文章。
- 当前词元 (Query):你正在写的这个词。
- 关键 KV 条目 (Key KV entries):为了写这个词,你脑中需要参考的历史信息。
a. 短程时间局部性 (Short-range temporal locality)
当你写下这句话:“太阳能是一种重要的可再生能源,它利用…”
- 为了写“能源”这个词,你脑中最重要的参考信息是“太阳能”和“可再生”。
- 为了写下一个词“,”(逗号),你脑中最重要的参考信息仍然是“太阳能”和“可再生能源”。
这就是短程时间局部性:在生成连续的、紧挨着的几个词时,模型关注的关键历史信息集合有很高的重叠度。
之前研究的局限性:像 ShadowKV [28] 和 PQCache [40] 这些系统观察到了这一点。他们的策略大致是:“我刚用过的东西(为生成词 N 所需的关键信息),先别扔,因为生成下一个词 N+1 很可能还会用到。” 这相当于只考虑了“一步之遥”的复用。
b. 长程范围的系统性分析 (Systematic analysis in the long range)
KVDrive 的作者认为,只看“一步之遥”是不够的。我们应该看得更远。
继续上面的例子。你写完了“…它利用光伏板将阳光转化为电能。” 接下来你要开始写下一段:“除了太阳能,风能也是一种主流的…”
- 当你开始写“风能”时,你脑中最重要的参考信息是什么?除了“风能”本身,“可再生能源”这个核心主题依然非常重要!
- 尽管“太阳能”的重要性下降了,但“可再生能源”这个概念在**相当长一段文本(长程范围)**内都是一个持续被关注的焦点。
KVDrive 的洞察:
- “长程”不是指上下文的开头到结尾,而是指一个比“连续两个词”更长的时间跨度,比如一个段落、一个完整的句子、一个话题的讨论区间。
- 在这个“长程范围”内,存在一个相对稳定的“核心关键信息集合”。
- KVDrive 的主张:之前的研究没有系统地去分析和利用这种“跨越多步”的复用潜力。他们只做了 N -> N+1 的缓存,而 KVDrive 则考虑了 N -> N+1, N+2, N+3… 的可能性。
这如何指导 KVDrive 的设计?
正是基于对“长程”局部性的分析,KVDrive 才提出了**“滑动窗口”机制。它不是只缓存上一步用过的东西,而是维护最近几步**用过的所有关键信息的并集。这个“窗口”能更好地覆盖一个话题讨论周期内的核心信息,从而更大幅度地减少了去慢速存储中进行“稀疏 I/O”的次数。
总结
- 稀疏 I/O:指从存储中读取大量物理位置不连续的小数据块,这是 LLM 稀疏注意力的直接产物,并且效率低下。
- 短程时间局部性:生成下一个词时,很可能需要用到生成当前词时用过的信息。这是之前研究的发现。
- 长程范围分析(KVDrive 的贡献):KVDrive 发现,这种复用性不止存在于紧挨着的两个词之间,而是在一个更长的话题周期内都有效。通过系统性地分析并利用这种“长程”局部性,KVDrive 设计了更高效的滑动窗口缓存策略,从而更好地解决了“稀疏 I/O”带来的性能瓶颈。
当然,这幅图是 KVDrive 论文中的核心证据之一,展示了其“滑动窗口”缓存策略的巨大优势。让我为您详细解读这张图。
图表核心信息
这张图展示了**“滑动窗口大小”与“数据传输量”和“额外内存成本”**之间的关系。它想证明的核心观点是:
通过稍微增加一点 GPU 内存占用(额外内存成本),我们可以戏剧性地减少从主机内存到 GPU 的数据传输量,从而大幅提升效率。
图表元素解读
-
X 轴 (Window Size / 窗口大小):表示 GPU 缓存的大小。
x0:无缓存策略。每一步都从主机内存加载所需数据,用完即扔。这是最基础的卸载方法。x1:单步缓存。缓存大小等于一步所需关键 KV 条目的量。用完后,保留这一步的数据,下一步再用。x2,x3:滑动窗口策略。缓存大小是单步需求量的 2 倍和 3 倍。这意味着它可以保留最近 2-3 步的关键信息。
-
左 Y 轴 (Data Transfer / 数据传输量):用柱状图表示。它衡量的是每一步解码需要从主机内存(慢速)加载到 GPU 显存(快速)的数据量(单位是 MB)。这个值越低越好,因为它代表着更少的等待时间和更高的效率。
-
右 Y 轴 (Memory Cost / 内存成本):用虚线和点表示。它衡量的是为了维持这个窗口大小,需要在 GPU 上额外占用的内存空间(单位是 GB)。
-
两种颜色/样式 (Sparsity Budget / 稀疏度预算):
- 粉色 (1.56% Sparsity Budget):一个比较“抠门”的设置。每一步只允许模型关注历史上 1.56% 的关键信息。
- 黄褐色 (6.25% Sparsity Budget):一个更“慷慨”的设置。允许关注更多的历史信息,这通常能带来更好的生成质量,但对数据传输和内存要求也更高。
-
左右两图 (Context Length / 上下文长度):
- (a) Context Length: 60k:在 6 万 token 的长上下文场景下。
- (b) Context Length: 122k:在 12.2 万 token 的超长上下文场景下。
关键观察与结论
-
从
x0到x1的巨大飞跃:- 观察任意一个图,比如图 (a) 的黄褐色柱子。在
x0(无缓存)时,每一步需要传输高达 500MB 的数据。 - 但只要我们采用
x1(单步缓存),数据传输量立刻骤降到 50MB 以下。 - 结论:这证明了我们之前讨论的**“短程时间局部性”**。生成下一个词时,大量信息和上一步是重叠的。仅仅是保留上一步的数据,就能避免 90% 的重复加载!
- 观察任意一个图,比如图 (a) 的黄褐色柱子。在
-
滑动窗口的持续收益 (从
x1到x2,x3):- 继续看图 (a) 的黄褐色柱子。从
x1到x2,数据传输量进一步从约 50MB 降低到约 25MB。从x2到x3,又降低到约 12.5MB。 - 结论:这证明了 KVDrive 的核心洞察——“长程时间局部性”。将缓存窗口扩大,保留更多历史步骤的信息,可以进一步捕获话题周期内的核心数据,从而持续减少数据传输。
- 继续看图 (a) 的黄褐色柱子。从
-
成本与收益的权衡 (柱状图 vs. 虚线):
- 我们来看收益(柱状图下降幅度)和成本(虚线上升幅度)的对比。
- 在图 (b) 的黄褐色系列中,当窗口大小从
x0增加到x3时:- 收益:数据传输量从 1000MB 骤降到 25MB 以下,减少了 97.5%!这是一个巨大的性能提升。
- 成本:额外的内存占用从 0GB 增加到约 3GB。
- 结论:用区区 3GB 的 GPU 显存,换来了每一步减少近 1GB 的数据传输。这个投入产出比极高。在 GPU 显存紧张但并非完全没有余量的情况下,这种交换是极其划算的。
-
稀疏度和上下文长度的影响:
- 比较粉色和黄褐色系列:更慷慨的稀疏度预算(6.25%)意味着需要更多的关键信息,因此初始的数据传输量(
x0)和内存成本都更高。 - 比较图 (a) 和图 (b):更长的上下文(122k)意味着 KV 缓存的总量更大,即使稀疏度相同,绝对的数据量也更大,导致数据传输和内存成本全面上升。
- 核心结论不变:无论在哪种设置下,采用滑动窗口策略(从
x0移动到x3)都能带来数据传输量的数量级下降。
- 比较粉色和黄褐色系列:更慷慨的稀疏度预算(6.25%)意味着需要更多的关键信息,因此初始的数据传输量(
总结性一句话
这张图有力地证明了:KVDrive 的滑动窗口缓存策略,通过付出微小的 GPU 内存成本,实现了数据传输量的急剧下降,这是其能够高效处理长上下文 LLM 推理的关键原因。
好的,我们完全聚焦于大语言模型(LLM)的内部工作原理来解释为什么 FlexGen 的方法被称为“粗粒度”。
背景:LLM 的结构和 KV 缓存
- 分层结构 (Layers):一个大模型(比如 Llama-3-8B)由许多相同的 Transformer 层堆叠而成,例如 32 层。当模型生成一个词时,数据流需要依次穿过这 32 层。
- KV 缓存:每一层都有自己独立的 KV 缓存。也就是说,对于一个有 100K token 上下文的对话,第 1 层有它自己的 100K token 的 KV 缓存,第 15 层也有它自己的 100K token 的 KV 缓存,第 32 层同样有。它们的内容是不同的。
- 注意力机制 (Attention):在每一层内部,模型都要进行注意力计算。这意味着,当模型在处理第 15 层时,它需要用一个“查询向量(Query)”去和第 15 层的整个 KV 缓存进行交互,来决定哪些历史信息对当前这一层的计算最重要。
FlexGen 的“粗粒度”操作流程
FlexGen 的核心思想是按层(Layer)作为单位进行卸载和加载。假设我们的 GPU 显存非常小,只能容纳一层的 KV 缓存。
当模型需要生成下一个词时,它的计算流程是这样的:
-
计算第 1 层:
- 加载:FlexGen 将第 1 层完整的 100K token 的 KV 缓存从主机内存(或 SSD)全部加载到 GPU 显存中。
- 计算:GPU 使用这些数据完成第 1 层的计算。
- 卸载:计算一结束,为了给下一层腾地方,GPU 立即将第 1 层的 KV 缓存(可能还有更新)写回主机内存,并清空这部分显存。
-
计算第 2 层:
- 加载:FlexGen 将第 2 层完整的 100K token 的 KV 缓存全部加载到 GPU 显存中。
- 计算:GPU 完成第 2 层的计算。
- 卸载:再次将第 2 层的全部 KV 缓存写回并清空。
-
…重复 32 次…
-
计算第 32 层:
- 加载:加载第 32 层完整的 KV 缓存。
- 计算:完成计算。
- 卸载:写回。
为什么这是“粗粒度”的?
因为在稀疏注意力 (Sparse Attention) 的场景下,这种做法极其浪费。
稀疏注意力的核心是:在第 15 层进行计算时,模型并不需要第 15 层那 100K token 的全部 KV 缓存。它可能只需要其中 2000 个最关键的 token 所对应的 KV 缓存块。这 98% 的其他 KV 缓存块对于本次计算是无用的。
然而,FlexGen 的操作逻辑是“我不管你具体要用哪一小部分,只要是这一层的,我就全部搬过来”。
这就是“粗粒度”的本质:
- 操作单位太大:它的数据移动单位是“整个层”,一个非常大的数据集合。
- 不精确:它完全忽略了注意力机制的“稀疏”特性,即模型在每一层内部其实只需要一小部分数据。
导致的后果:“I/O 放大”
- I/O (Input/Output):这里指数据在 GPU 和主机内存/SSD 之间的来回传输。
- 放大:假设在第 15 层,模型实际需要的 KV 缓存数据是 50MB。但因为 FlexGen 的“粗粒度”策略,它把整个第 15 层的 KV 缓存(比如 2GB)都搬了一遍。
- 实际需求:50 MB
- 实际传输:2000 MB
- I/O 被放大了 40 倍!
为了生成一个词,这个“放大”的过程要发生 32 次(因为有 32 层)。这导致 GPU 大部分时间都在等待数据来回搬运,而不是在真正地进行计算,所以性能会急剧下降。
KVDrive 的“细粒度”对比
KVDrive 的做法完全不同。在计算第 15 层时:
- 识别:KVDrive 首先在 GPU 上用一个轻量级的索引快速判断出:“在第 15 层,我只需要那 100K token 中的第 5、89、1024… 等 2000 个位置的 KV 缓存块。”
- 加载:它向主机内存/SSD 发出精确指令:“只把这 2000 个特定的、分散的块(总共 50MB)传给我。”
- 计算:GPU 拿到精确的数据后进行计算。
KVDrive 的操作单位是“被注意力选中的特定 KV 块”,这是一个非常小且精确的单位,因此被称为“细粒度”。它完美地匹配了稀疏注意力的工作模式,避免了不必要的数据传输,从而解决了带宽瓶颈。
好的,我们完全聚焦于大语言模型(LLM)的内部工作原理来解释为什么 FlexGen 的方法被称为“粗粒度”。
背景:LLM 的结构和 KV 缓存
- 分层结构 (Layers):一个大模型(比如 Llama-3-8B)由许多相同的 Transformer 层堆叠而成,例如 32 层。当模型生成一个词时,数据流需要依次穿过这 32 层。
- KV 缓存:每一层都有自己独立的 KV 缓存。也就是说,对于一个有 100K token 上下文的对话,第 1 层有它自己的 100K token 的 KV 缓存,第 15 层也有它自己的 100K token 的 KV 缓存,第 32 层同样有。它们的内容是不同的。
- 注意力机制 (Attention):在每一层内部,模型都要进行注意力计算。这意味着,当模型在处理第 15 层时,它需要用一个“查询向量(Query)”去和第 15 层的整个 KV 缓存进行交互,来决定哪些历史信息对当前这一层的计算最重要。
FlexGen 的“粗粒度”操作流程
FlexGen 的核心思想是按层(Layer)作为单位进行卸载和加载。假设我们的 GPU 显存非常小,只能容纳一层的 KV 缓存。
当模型需要生成下一个词时,它的计算流程是这样的:
-
计算第 1 层:
- 加载:FlexGen 将第 1 层完整的 100K token 的 KV 缓存从主机内存(或 SSD)全部加载到 GPU 显存中。
- 计算:GPU 使用这些数据完成第 1 层的计算。
- 卸载:计算一结束,为了给下一层腾地方,GPU 立即将第 1 层的 KV 缓存(可能还有更新)写回主机内存,并清空这部分显存。
-
计算第 2 层:
- 加载:FlexGen 将第 2 层完整的 100K token 的 KV 缓存全部加载到 GPU 显存中。
- 计算:GPU 完成第 2 层的计算。
- 卸载:再次将第 2 层的全部 KV 缓存写回并清空。
-
…重复 32 次…
-
计算第 32 层:
- 加载:加载第 32 层完整的 KV 缓存。
- 计算:完成计算。
- 卸载:写回。
为什么这是“粗粒度”的?
因为在稀疏注意力 (Sparse Attention) 的场景下,这种做法极其浪费。
稀疏注意力的核心是:在第 15 层进行计算时,模型并不需要第 15 层那 100K token 的全部 KV 缓存。它可能只需要其中 2000 个最关键的 token 所对应的 KV 缓存块。这 98% 的其他 KV 缓存块对于本次计算是无用的。
然而,FlexGen 的操作逻辑是“我不管你具体要用哪一小部分,只要是这一层的,我就全部搬过来”。
这就是“粗粒度”的本质:
- 操作单位太大:它的数据移动单位是“整个层”,一个非常大的数据集合。
- 不精确:它完全忽略了注意力机制的“稀疏”特性,即模型在每一层内部其实只需要一小部分数据。
导致的后果:“I/O 放大”
- I/O (Input/Output):这里指数据在 GPU 和主机内存/SSD 之间的来回传输。
- 放大:假设在第 15 层,模型实际需要的 KV 缓存数据是 50MB。但因为 FlexGen 的“粗粒度”策略,它把整个第 15 层的 KV 缓存(比如 2GB)都搬了一遍。
- 实际需求:50 MB
- 实际传输:2000 MB
- I/O 被放大了 40 倍!
为了生成一个词,这个“放大”的过程要发生 32 次(因为有 32 层)。这导致 GPU 大部分时间都在等待数据来回搬运,而不是在真正地进行计算,所以性能会急剧下降。
KVDrive 的“细粒度”对比
KVDrive 的做法完全不同。在计算第 15 层时:
- 识别:KVDrive 首先在 GPU 上用一个轻量级的索引快速判断出:“在第 15 层,我只需要那 100K token 中的第 5、89、1024… 等 2000 个位置的 KV 缓存块。”
- 加载:它向主机内存/SSD 发出精确指令:“只把这 2000 个特定的、分散的块(总共 50MB)传给我。”
- 计算:GPU 拿到精确的数据后进行计算。
KVDrive 的操作单位是“被注意力选中的特定 KV 块”,这是一个非常小且精确的单位,因此被称为“细粒度”。它完美地匹配了稀疏注意力的工作模式,避免了不必要的数据传输,从而解决了带宽瓶颈。
好的,这部分内容是 KVDrive 提出多级存储(特别是引入 SSD)的动机和背景,我们来把它拆解成更容易理解的逻辑链。
简单来说,这段话要表达的核心思想是:
只把数据卸载到主机内存 (DRAM) 是不够的,迟早会遇到瓶颈。但直接把数据塞到硬盘 (SSD) 里又会因为速度太慢而卡死。因此,我们需要一个聪明的、跨越 GPU、DRAM、SSD 的协同管理系统,也就是 KVDrive。
下面是详细的逻辑分解:
第一层逻辑:只用 DRAM 卸载的局限性
-
好消息:增加批处理大小 (Batch Size) 能提速。
- 如图 5(a) 所示,当你的主机内存(DRAM)足够大时,你可以同时处理更多的请求(比如从 2 个用户增加到 8 个用户)。这就像一个大厨房可以同时给更多桌客人做菜,整体出菜速度(吞吐量)会变快。因为 GPU 擅长并行计算,一次处理 8 个请求比分 4 次处理 2 个请求要高效得多。
-
坏消息:DRAM 是有限的,很快就会被用完。
- 问题在哪? KV 缓存非常大。
KV 缓存大小 ≈ 批处理大小 × 上下文长度 × 模型参数。 - 一个现实的例子:一个典型的服务器可能只有 100GB 的主机内存 (DRAM)。当你要处理一个长达 122k 的长文本,并且批处理大小增加到 8 时,光是 KV 缓存就可能需要几百 GB 的空间。
- 结果:你的 100GB DRAM 很快就“爆”了,程序会因为“内存不足 (Out of Memory)”而崩溃。
- 问题在哪? KV 缓存非常大。
-
小结:我们想通过增加批处理大小来提升 GPU 利用率和吞吐量,但有限的 DRAM 容量限制了我们这么做。只依赖 DRAM 的卸载方案,其性能上限被 DRAM 的大小锁死了。
第二层逻辑:简单地引入 SSD 会导致灾难
既然 DRAM 不够用,一个自然的想法是:“那我把数据放到容量更大的 SSD 硬盘上不就行了吗?”
作者在这里做了一个实验(他们称之为 “strawman design”,即一个为了被推翻而设立的简易方案),模仿了 FlexGen 的思路,但把数据源从 DRAM 换成了 SSD。
-
这个简易方案是怎么工作的?
- 它把完整的 KV 缓存放在 SSD 上。
- 在推理时,每一层计算需要数据时,就直接从 SSD 把这一层的全部 KV 条目加载到 GPU 内存。
- 用完后,立即扔掉,给下一层腾地方。
-
为什么这个方案性能极差?
- 带宽的巨大鸿沟:
- GPU <-> DRAM 的传输速度非常快(比如 50-100 GB/s)。
- GPU <-> SSD 的传输速度相对很慢(比如 3-7 GB/s,而且这是理想的连续读写速度)。
- 结果:如图 5(b) 所示,整个系统的性能瓶颈从“计算”变成了“数据传输”。
Fetching(数据获取) 这一项占了几乎 100% 的时间。- GPU 在绝大多数时间里都在空闲等待,等着慢吞吞的 SSD 把数据喂给它。这就好比一个世界顶级的厨师,在等一个极其缓慢的学徒从仓库里一次只拿一个土豆给他,厨师大部分时间都在干等。
- 最终的吞吐量会低到无法接受的程度。
- 带宽的巨大鸿沟:
-
小结:虽然直接用 SSD 解决了容量问题(不会内存不足了),但它引入了灾难性的性能问题。简单粗暴地将 SSD 作为 DRAM 的延伸是行不通的。
最终结论:KVDrive 的必要性
通过上面两层逻辑,作者得出了最终的结论:
- 我们需要使用 SSD 来突破 DRAM 的容量限制,以便支持更大的批处理和更长的上下文。
- 但我们不能像对待 DRAM 那样简单地使用 SSD,否则会被其缓慢的带宽拖垮。
所以,我们需要一个更智能的系统,这就是 KVDrive。 KVDrive 的“协调的多级 KV 存储”就是为了解决这个难题而设计的。它不是盲目地从 SSD 加载数据,而是:
- 有选择地加载(细粒度):只加载真正需要的 KV 块,而不是整个层。
- 利用 DRAM 作为高速缓存:将最可能被用到的数据提前从 SSD 预热到 DRAM 中。
- 并行化和异步操作:在 GPU 进行计算的同时,在后台悄悄地进行 SSD 到 DRAM 的数据传输。
通过这些精细化的管理,KVDrive 既利用了 SSD 的大容量,又最大限度地避免了其低带宽带来的负面影响,从而实现了在超出 DRAM 限制的情况下依然保持高吞吐量。
好的,这个 Roofline 模型图确实比较专业,但它想表达的观点其实非常直观。我来为您拆解这张图和相关段落的含义。
核心争论:注意力计算应该在 CPU 还是 GPU 上做?
- 反方观点 (先前工作):当 KV 缓存数据都在主机内存 (DRAM) 里时,为了在 GPU 上做注意力计算,你必须先把数据从 DRAM 传到 GPU 显存。这个传输过程非常慢,会成为瓶颈。所以,他们认为,既然数据本来就在 DRAM 里,不如直接用 CPU 在 DRAM 里完成计算,省去传输的麻烦。
- 正方观点 (KVDrive):不对!只要我们管理得好,GPU 还是比 CPU 快得多。
这张图就是 KVDrive 用来证明自己观点的有力证据。
Roofline 模型图解读
Roofline 模型是一种分析计算性能的工具。它告诉我们一个程序的实际性能受到两个因素的制约:计算能力上限 和 内存带宽上限。
图表元素:
-
X 轴 (Operational Intensity / 操作强度):这是一个关键指标,单位是
FLOPs / Byte。它衡量的是**“每传输 1 字节数据,能进行多少次浮点运算”**。- 操作强度低(X 轴靠左):程序大部分时间在搬数据,计算很少。这种程序被称为**“内存密集型 (Memory-bound)”**。
- 操作强度高(X 轴靠右):程序计算量很大,数据搬一次能用很久。这种程序被称为**“计算密集型 (Compute-bound)”**。
-
Y 轴 (Performance / 性能):程序的实际运行速度,单位是
GFLOP/s(每秒十亿次浮点运算)。这个值越高越好。 -
水平线 (计算能力天花板/屋顶):
GPU Peak FLOPS(绿色虚线):GPU 的理论最高计算速度。CPU Peak FLOPS(蓝色虚线):CPU 的理论最高计算速度。- 解读:无论你的程序怎么优化,它的性能(Y 值)都不可能超过这些线。
-
斜线 (内存带宽天花板/屋檐):
GPU Mem Bdw(绿色实线):GPU 访问其自身高速显存(HBM)的带宽。CPU Mem Bdw(蓝色实线):CPU 访问其自身内存(DRAM)的带宽。CPU-GPU Mem Bdw(红色实线):最关键的一条线,表示数据从 CPU 内存(DRAM)传输到 GPU 显存的带宽,这是最慢的环节。- 解读:当程序是“内存密集型”时(操作强度低),它的性能会被这些斜线卡住。
性能 = 操作强度 × 带宽。
图表揭示的逻辑
-
“阈值 P”在哪里?
- 注意看
CPU Peak FLOPS(蓝色虚线) 和CPU-GPU Mem Bdw(红色实线) 的交点。这个交点对应的 X 轴坐标就是文中所说的**“阈值 P”**(在图上大约是 5-6 的位置)。
- 注意看
-
先前工作的错误假设 (0% Hit)
- 先前工作认为,每次注意力计算都需要把所有关键 KV 条目从 DRAM 搬到 GPU。这种情况对应图中的
0% Hit红色斜线。 - 看这条线:在很宽的操作强度范围内(X 轴从 1 到 100),
0% Hit这条线的 Y 值(性能)都低于CPU Peak FLOPS(蓝色虚线)。 - 意味着什么?:在这种“零命中率”的糟糕情况下,把数据搬到 GPU 再计算,其性能还不如直接用 CPU 计算快!因为 CPU-GPU 的传输带宽太低,严重拖慢了整个过程。这就是反方观点的依据。
- 先前工作认为,每次注意力计算都需要把所有关键 KV 条目从 DRAM 搬到 GPU。这种情况对应图中的
-
KVDrive 的巨大优势 (80% Hit, 90% Hit)
- KVDrive 的核心是**“自适应缓存管理”**,它在 GPU 显存里维护了一个高效的缓存(滑动窗口)。
- 文中提到,经验表明,即使在预算紧张的情况下,大约 80% 的关键 KV 条目都能在 GPU 缓存里找到(即“缓存命中”)。
- 这意味着:我们只需要从慢速的 DRAM 中加载剩下那 20% 的数据。
- 对“操作强度”的影响:假设总计算量不变,但需要传输的数据量减少了 80%。根据公式
操作强度 = 计算量 / 传输量,操作强度会大幅提升! - 看图上的变化:
- 当缓存命中率为 80% 或 90% 时,我们的程序性能不再由
0% Hit线决定,而是由80% Hit和90% Hit这两条更高的红线决定。 - 这些线的斜率没变(因为带宽不变),但它们整体向右上方平移了。
- 现在再看,
80% Hit和90% Hit这两条线,在大部分区域其 Y 值(性能)都远高于CPU Peak FLOPS(蓝色虚线)。
- 当缓存命中率为 80% 或 90% 时,我们的程序性能不再由
最终结论
- 先前工作是错的,因为他们只考虑了最坏的情况(0% 缓存命中),在这个情况下确实 CPU 更优。
- KVDrive 是对的,因为它通过高效率的 GPU 缓存机制(实现了 80% 以上的命中率),极大地提升了注意力计算的“操作强度”。
- 这使得注意力计算从一个“内存密集型”任务(性能被慢速的 CPU-GPU 带宽卡住)变成了一个更偏向“计算密集型”的任务。
- 在这个新的、高操作强度的区域,GPU 强大的计算能力得以发挥,其最终性能远超 CPU。
一句话总结这张图的意义:KVDrive 通过智能缓存将“搬砖”的活儿降到最少,让 GPU 这个“大力士”能专心“干活”,而不是把时间浪费在等“砖”的路上,因此在 GPU 上计算注意力变得远比在 CPU 上高效。
好的,我们完全用大语言模型(LLM)的注意力计算来解释操作强度 (Operational Intensity) 这个概念。
一句话概括
操作强度 = 计算的“忙碌”程度 / 搬运数据的“辛苦”程度
它衡量的是,我们每从内存(或硬盘)搬运 1 字节的数据到计算单元(GPU核心),能让这个计算单元进行多少次数学运算(浮点运算,FLOPs)。
- 高操作强度:搬一次数据能算很久,很划算。计算单元很忙,内存带宽很闲。
- 低操作强度:算了没几下就又要去搬新数据,不划算。计算单元很闲,内存带宽很忙。
以 LLM 注意力计算为例
假设我们正在为一个有 100K token 上下文的 LLM 生成下一个词。在其中一个 Transformer 层,我们需要进行注意力计算。
这个计算主要包含两个部分:
- 数据搬运 (I/O):把需要的 KV 缓存数据从存储它的地方(比如主机 DRAM)搬到 GPU 的计算核心。
- 数学运算 (FLOPs):主要是大量的矩阵乘法,比如将 Query 向量和 Key 向量相乘得到注意力分数。
现在我们来看两种极端情况:
情况一:低操作强度 (没有 GPU 缓存或缓存很差)
这对应于 FlexGen 或 KVDrive 在缓存命中率为 0% 的情况。
- 注意力机制说:为了计算下一个词,我需要历史上第 1000、2000、…、第 99000 个(总共 2000 个)token 的 Key 向量。
- 数据搬运:
- 需要的数据量:假设每个 Key 向量是 4KB,总共需要
2000 * 4KB = 8MB的数据。 - 实际搬运量:由于没有有效的缓存,我们必须从主机 DRAM 加载这 8MB 的数据到 GPU。所以,数据传输量是 8MB。
- 需要的数据量:假设每个 Key 向量是 4KB,总共需要
- 数学运算:
- GPU 拿到这 2000 个 Key 向量后,和当前的 Query 向量进行矩阵乘法。假设这个计算量是 80 亿次浮点运算 (8 GFLOPs)。
- 计算操作强度:
- 操作强度 =
8 GFLOPs / 8 MB=8 * 10^9 FLOPs / (8 * 10^6 Bytes)= 1000 FLOPs / Byte
- 操作强度 =
这是一个相对较低的操作强度。GPU 每算 1000 次,就得去慢速的 DRAM 里搬 1 字节的数据。
情况二:高操作强度 (KVDrive 拥有高效的 GPU 缓存)
这对应于 KVDrive 缓存命中率为 90% 的情况。
- 注意力机制说:和情况一完全一样,我还是需要那 2000 个特定的 Key 向量。
- 数据搬运:
- KVDrive 检查 GPU 缓存:发现这 2000 个需要的向量里,有 90%(1800个)已经存在于 GPU 的高速显存里了!
- 需要的数据量:我们只需要从主机 DRAM 加载剩下的 10%(200个)Key 向量。
- 实际搬运量:
200 * 4KB = 0.8MB。所以,(从慢速内存)数据传输量只有 0.8MB!
- 数学运算:
- GPU 拿到从 DRAM 加载的 200 个向量,再结合已经在显存里的 1800 个向量,执行完全相同的注意力计算。
- 计算量依然是 80 亿次浮点运算 (8 GFLOPs)。计算任务本身没有变。
- 计算操作强度:
- 操作强度 =
8 GFLOPs / 0.8 MB=8 * 10^9 FLOPs / (0.8 * 10^6 Bytes)= 10000 FLOPs / Byte
- 操作强度 =
结论与影响
-
通过高效的缓存,KVDrive 将注意力计算的操作强度从 1000 提升到了 10000,整整 10 倍!
-
低操作强度 (1000):程序的瓶颈在于数据传输。GPU 很快就完成了计算,然后就得停下来,眼巴巴地等着数据从慢速的 DRAM 传过来。性能被内存带宽卡住了。
-
高操作强度 (10000):数据传输的压力大大减小。GPU 可以长时间地、不间断地进行它最擅长的数学运算。性能更多地取决于 GPU 自身的计算能力。
总结起来,对于 LLM 的注意力计算来说:
操作强度 ≈ (注意力计算的固有复杂程度) / (需要从慢速内存中加载的数据量)
KVDrive 的核心贡献之一就是通过智能缓存,在不改变分子(计算复杂度)的情况下,极大地减小了分母(需加载的数据量),从而显著提高了操作强度,让 GPU 摆脱了内存带宽的束缚,发挥出其真正的计算潜力。
当然可以。我们从最基本的公式出发,一步步推导,你就会明白为什么 性能 = 操作强度 × 带宽 这个关系成立,以及它在 Roofline 模型中的意义。
基本定义与单位
我们先统一一下几个关键变量的定义和单位:
-
性能 (Performance, P)
- 定义: 单位时间内完成的浮点运算次数。
- 单位:
FLOPS(FLoating-point Operations Per Second,每秒浮点运算次数)。
-
总计算量 (Total FLOPs, F)
- 定义: 程序总共需要执行的浮点运算次数。
- 单位:
FLOPs。
-
总数据量 (Total Bytes, B)
- 定义: 程序为了完成计算,总共需要从内存中读取或写入的数据量。
- 单位:
Bytes。
-
执行时间 (Time, T)
- 定义: 程序运行所花费的时间。
- 单位:
Seconds(秒)。
-
内存带宽 (Bandwidth, β)
- 定义: 内存系统单位时间内能传输的最大数据量。
- 单位:
Bytes / Second。
-
操作强度 (Operational Intensity, I)
- 定义: 每传输 1 字节数据,所伴随的浮点运算次数。
- 单位:
FLOPs / Byte。
从定义推导公式
根据上面的定义,我们可以得到几个基本关系:
-
关系 1: 性能的定义
P = F / T(性能 = 总计算量 / 执行时间) -
关系 2: 操作强度的定义
I = F / B(操作强度 = 总计算量 / 总数据量)
现在,我们考虑一个**“内存密集型 (Memory-bound)”**的程序。
对于这种程序,它的运行速度完全受限于从内存搬运数据的速度。计算核心(比如 GPU)非常快,数据一来就能瞬间算完,然后大部分时间都在等下一批数据。
在这种情况下,程序的总执行时间 T 是由搬运完所有数据所需的时间决定的。
我们可以计算这个“搬运时间”:
- 关系 3: 内存密集型程序的执行时间
T = B / β(执行时间 = 总数据量 / 内存带宽)- 这个公式很直观:如果你要搬 100GB 的数据,而你的卡车(带宽)每秒能搬 10GB,那么总共就需要 10 秒。
现在,我们把关系 3代入到关系 1中,来计算内存密集型程序的性能 P:
P = F / T = F / (B / β)
整理一下这个式子:
P = (F / B) * β
我们再回看关系 2,I = F / B。把这个代入上面的式子,我们就得到了最终的公式:
P = I * β性能 = 操作强度 × 内存带宽
公式在 Roofline 模型中的几何意义
这个公式 P = I * β 正是 Roofline 模型中那些**“斜线”的数学表达式**。
让我们在对数坐标系 (log-log scale) 中来看这个公式:
log(P) = log(I * β)log(P) = log(I) + log(β)
如果你把 log(P) 当作 Y 轴,log(I) 当作 X 轴,那么这个方程就变成了 Y = X + C 的形式(其中 C = log(β) 是一个常数)。
这正是一条斜率为 1 的直线!
- 斜线的位置:
log(β)决定了直线在 Y 轴上的截距。带宽β越大,log(β)就越大,这条斜线就越高。这就是为什么图中GPU Mem Bdw(绿色实线) 比CPU-GPU Mem Bdw(红色实线) 要高得多,因为 GPU 访问自家显存的带宽远大于跨设备访问的带宽。 - 斜线的意义:它代表了**“内存天花板”**。对于一个给定的操作强度
I,你的程序性能P最高只能达到I * β。你不可能比这条线更高,因为你的数据供应速度就这么快。
总结
- 公式
性能 = 操作强度 × 带宽是从最基本的物理定义(时间、数据量、计算量)严格推导出来的。 - 它精确地描述了当一个程序的瓶颈在于数据传输时,其性能所能达到的理论上限。
- 在对数坐标的 Roofline 图中,这个公式表现为一条斜率为 1 的直线,也就是我们看到的那些“屋檐”——内存带宽墙。
- 一个程序的实际性能点,必然位于其对应的计算天花板(水平线)和内存天花板(斜线)的下方。它被这两者共同构成的“屋顶”所限制。
好的,这是一个非常棒的问题,它触及了 Roofline 模型的核心和精髓。
你观察到的“折线”实际上是两条线段的组合,它代表了一个计算系统(如 GPU 或 CPU)性能的完整边界。
这个“折线”的形状源于一个程序性能的两种不同瓶颈的交替主导。
两大瓶颈:计算与访存
一个程序的运行速度,最终受到两个最基本因素的限制:
-
计算瓶颈 (Compute-bound):你的处理器(CPU/GPU核)的计算速度是有限的。即使数据供应无限快,你每秒能完成的运算次数也有一个上限。
- 在 Roofline 图上,这由**水平线(屋顶)**表示,即
P_peak(峰值性能)。
- 在 Roofline 图上,这由**水平线(屋顶)**表示,即
-
访存瓶颈 (Memory-bound):你的内存系统(带宽)向处理器传输数据的速度是有限的。即使处理器计算能力无限强,数据没送到,它也只能干等着。
- 在 Roofline 图上,这由**斜线(屋檐)**表示,即
P = I * β(性能 = 操作强度 × 带宽)。
- 在 Roofline 图上,这由**斜线(屋檐)**表示,即
“折线”的形成:两个瓶颈的交汇
一个程序的实际性能 P_actual 必须同时满足这两个限制条件,所以:
P_actual ≤ P_peak (不能超过计算上限)P_actual ≤ I * β (不能超过访存上限)
因此,程序能达到的理论最高性能是这两者的最小值:
P_theory_max = min(P_peak, I * β)
这个 min() 函数,正是“折线”形成的数学原因。
1. 折线的左半部分:斜线(访存主导)
- 当操作强度
I很低时:- 这意味着
I * β的值相对较小。 min(P_peak, I * β)的结果就是I * β。- 性能表现:
P = I * β。此时,程序的性能随着操作强度的增加而线性增长。你每多一点计算(分子增加),只要能保持数据量不变,性能就会提升。 - 物理意义: 在这个区域,程序是内存密集型 (Memory-bound)。你提升性能的唯一方法是优化数据访问(比如 KVDrive 的缓存策略来提高
I),或者用一个带宽更高的内存系统(提高β)。单纯提高处理器的计算速度(提高P_peak)是没用的,因为它根本没在全力计算,而是在等数据。
- 这意味着
2. 折线的右半部分:水平线(计算主导)
- 当操作强度
I很高时:- 这意味着
I * β的值变得非常大,最终会超过P_peak。 min(P_peak, I * β)的结果就变成了P_peak。- 性能表现:
P = P_peak。此时,程序的性能达到了硬件的计算极限,不再随操作强度的增加而改变。 - 物理意义: 在这个区域,程序是计算密集型 (Compute-bound)。数据供应已经足够快,处理器正在全力运转,100% 繁忙。你提升性能的唯一方法就是换一个计算能力更强的处理器(提高
P_peak)。再怎么优化数据访问(进一步提高I)也无法让性能突破这层天花板了。
- 这意味着
折点的意义:系统平衡点 (Ridge Point / Knee Point)
折线转折的那个点,是斜线和水平线的交点。
I * β = P_peak
解出操作强度 I:
I_ridge = P_peak / β
这个 I_ridge 值被称为**“机器平衡系数”**或“脊点”。
- 物理意义: 它代表了这台机器硬件本身的特性。它告诉你,这台机器需要多高的操作强度才能刚刚好把计算单元和内存带宽同时用满。
- 如果你的程序操作强度
I < I_ridge:你的程序是内存密集型的。 - 如果你的程序操作强度
I > I_ridge:你的程序是计算密集型的。
总结:折线斜率的含义
- 左侧斜线部分(斜率为1):
- 含义: 性能受限于内存带宽。
- 表现: 每当你的操作强度(X轴)增加 10 倍,你的性能(Y轴)也会增加 10 倍。性能完全被数据供应速度所决定。
- 右侧水平线部分(斜率为0):
- 含义: 性能受限于计算核心。
- 表现: 无论你的操作强度(X轴)如何增加,性能(Y轴)都保持不变,已经触顶。性能被处理器自身的运算速度所决定。
所以,Roofline 模型中的“折线”并非一条单一的线,而是两种物理限制(计算和访存)在不同操作强度下的综合体现,它完美地勾勒出了一台计算机在运行任何程序时,其性能所能达到的理论边界。
你提出了一个非常敏锐且关键的观察!蓝色折线的拐点(机器平衡系数)比绿色折线的拐(机器平衡系数)要小,这背后揭示了 CPU 和 GPU 这两种处理器在设计哲学上的根本差异。
简单来说:
- 绿色折线代表 GPU:它是一个计算能力极强,但对操作强度要求极高的“偏科生”。
- 蓝色折线代表 CPU:它是一个计算能力相对较弱,但**更容易“喂饱”**的“全能生”。
从公式出发:回顾拐点 I_ridge
我们再看一下决定拐点位置的公式:
I_ridge = P_peak / β拐点操作强度 = 峰值计算性能 / 内存带宽
这个公式告诉我们,一台机器的平衡点取决于它计算能力和访存能力的比值。
现在我们来分别分析 GPU 和 CPU 的情况:
绿色折线:GPU (以 A100 为例)
-
极高的峰值计算性能 (P_peak):
- 一个 A100 GPU 拥有数千个计算核心。它的理论 FP32 性能可以达到 19.5 TFLOPS (19,500 GFLOPS)。这个数字非常巨大。
- 所以,分子
P_peak非常大。
-
极高的内存带宽 (β):
- A100 使用 HBM2e 高带宽内存,其带宽可以达到 ~1.5 TB/s (1,500 GB/s)。这个数字同样非常巨大。
-
计算拐点 (I_ridge_gpu):
I_ridge_gpu = 19,500 GFLOPS / 1,500 GB/s ≈ 13 FLOPs/Byte- 这个值相对较高。
- 物理意义: 你需要给 GPU 提供一个操作强度至少为 13 的程序,才能刚刚好同时把它的计算单元和内存带宽都用满。如果你的程序操作强度低于 13,那么 GPU 的大部分计算核心就会因为等不到数据而闲置。
蓝色折线:CPU (以一个典型服务器 CPU 为例)
-
相对较低的峰值计算性能 (P_peak):
- 一个高端服务器 CPU 的一个核心,即使算上 AVX 指令集,其单核 FP32 性能可能在 ~100 GFLOPS 的量级。即使是多核并行,也很难与 GPU 的几千个核心相比。
- 所以,分子
P_peak相对小得多。
-
相对较低的内存带宽 (β):
- CPU 连接的是 DDR4/DDR5 内存,其多通道带宽可能在 ~100-200 GB/s 的量级。这远低于 GPU 的 HBM 带宽。
-
计算拐点 (I_ridge_cpu):
I_ridge_cpu ≈ 100 GFLOPS (单核) / 150 GB/s ≈ 0.67 FLOPs/Byte(这是一个非常粗略的估算,但足以说明数量级)- 这个值相对非常低。
- 物理意义: 只需要一个操作强度大于 0.67 的程序,就能把 CPU 的计算单元“喂饱”。CPU 的设计目标是处理各种通用任务,包括很多操作强度不高的任务(比如逻辑判断、分支跳转),所以它不需要很高的操作强度就能达到计算瓶颈。
总结与对比
| 特征 | GPU (绿色折线) | CPU (蓝色折线) |
|---|---|---|
| 设计哲学 | 大规模并行计算,为高吞吐量而生。 | 低延迟和通用性,为快速响应和处理复杂逻辑而生。 |
| P_peak (分子) | 极高 (成千上万 GFLOPS) | 较低 (几百 GFLOPS) |
| β (分母) | 极高 (上千 GB/s) | 较低 (上百 GB/s) |
拐点 I_ridge |
高 (P_peak 的增长远超 β 的增长) |
低 |
所以,为什么 GPU 的拐点比 CPU 大?
因为 GPU 的设计走的是**“大力出奇迹”的路线。相比 CPU,它的计算能力(分子)增长得比内存带宽(分母)增长得要快得多**。
想象一下:
- CPU 就像一个普通工人,给他一把小铲子(低带宽),他能一直忙活(低
I_ridge)。 - GPU 就像一台巨大的挖掘机,计算能力超强。你必须给它配上一条传送带(高带宽),并且保证一直在挖高密度的矿石(高操作强度的任务),它才能发挥出最大效率。如果你让它去挖松散的沙土(低操作强度的任务),它大部分时间都会在空转,因为一铲子下去就没活干了,得等下一车土运过来。
因此,绿色折线的拐点更大,精确地反映了 GPU 是一种为高操作强度、计算密集型任务而生的专用加速器。要充分利用 GPU,你的算法必须具有足够高的并行度和计算密度,否则其大部分潜力都将被浪费在等待数据上。而 CPU 则更适合处理那些操作强度不高、逻辑复杂的通用任务。
好的,这又是一个非常棒的深入问题!你注意到了一个关键细节:0% Hit 和 80% Hit 这些代表不同缓存命中率的红线,它们本身并不是一个完整的 Roofline 折线,而只是斜线部分。
让我们来澄清这个概念,并解释为什么命中率越高,操作强度越大。
第一部分:为什么 0% Hit、80% Hit 这些线只是斜线?
这些红线代表的是特定的、与数据传输相关的访存瓶颈,具体来说是CPU-GPU 之间的数据传输。它们本身并不是一个完整的计算设备的性能边界,而是构成完整边界的一部分。
让我们把整个图景拼凑起来:
-
一个完整的设备性能边界:
- 一个设备(比如 GPU)的完整性能由其计算屋顶(
GPU Peak FLOPS,绿色虚线)和其内部访存屋檐(GPU Mem Bdw,绿色实线)共同决定。这两者构成了绿色的折线。这代表了当所有数据都已经在 GPU 显存里时,GPU 能达到的性能极限。
- 一个设备(比如 GPU)的完整性能由其计算屋顶(
-
跨设备传输的额外瓶颈:
- 现在,我们考虑一种更复杂的情况:数据最初在 CPU 的内存(DRAM)里。为了在 GPU 上计算,必须先把数据通过 PCIe 总线传过来。
- 这个 CPU-GPU 的传输过程,引入了一个新的、更低的“屋檐”,也就是图中的红色斜线 (
CPU-GPU Mem Bdw)。 - 这条红线比绿色的
GPU Mem Bdw斜线要低得多,因为 PCIe 带宽远小于 HBM 显存带宽。
-
程序的实际性能边界:
-
对于一个需要从 CPU 内存加载数据的 GPU 程序,它的理论性能上限
P_actual_max是由三个因素共同决定的:- GPU 的计算极限
P_peak_gpu - GPU 内部访存极限
I * β_gpu - CPU-GPU 传输极限
I * β_cpu-gpu
- GPU 的计算极限
-
所以,
P_actual_max = min(P_peak_gpu, I * β_gpu, I * β_cpu-gpu) -
因为
β_cpu-gpu远小于β_gpu,所以I * β_cpu-gpu也远小于I * β_gpu。因此,公式可以简化为:P_actual_max = min(P_peak_gpu, I * β_cpu-gpu) -
这个公式意味着什么? 它意味着,对于这类程序,其性能边界是由 GPU 的计算屋顶(绿色虚线) 和 CPU-GPU 传输屋檐(红色斜线) 共同构成的一个新的、更低的折线!
-
所以,
0% Hit、80% Hit这些红线,本身只是访存瓶颈的体现(屋檐),但它们与绿色的GPU Peak FLOPS水平线结合起来,就构成了在该缓存命中率下的完整性能折线。 作者在图中没有把这个新的、更低的折线画完整,只是画出了起决定性作用的斜线部分,因为这是他们论证的重点。
-
第二部分:为什么命中率越高,操作强度越大?
这个问题的答案就在操作强度的定义里。
操作强度 (I) = 总计算量 (F) / 总传输数据量 (B)
让我们以 LLM 的注意力计算为例,再次审视这个公式。假设:
- 总计算量 (F):为了完成一次注意力计算,需要的浮点运算次数是固定的。比如 10 GFLOPs。这个值不随缓存命中率改变,因为无论数据从哪里来(GPU缓存还是DRAM),该做的数学运算一点都不能少。
- 需要的数据总量:假设完成这 10 GFLOPs 的计算,总共需要 100 MB 的 KV 缓存数据。
现在我们来看不同命中率下的情况:
情况 A: 缓存命中率为 0% (0% Hit)
- 含义: GPU 缓存里什么都没有,所有 100 MB 的数据都必须从慢速的 CPU 内存 (DRAM) 传输过来。
- 总传输数据量 (B):
B = 100 MB - 计算操作强度 (I_0%):
I_0% = 10 GFLOPs / 100 MBI_0% = (10 * 10^9 FLOPs) / (100 * 10^6 Bytes)I_0% = 100 FLOPs / Byte
情况 B: 缓存命中率为 80% (80% Hit)
- 含义: 在需要的 100 MB 数据中,有 80% (即 80 MB) 已经在 GPU 的高速缓存里找到了!我们只需要从慢速的 DRAM 传输剩下那 20%。
- 总传输数据量 (B):
B = 100 MB * (1 - 80%) = 20 MB - 计算操作强度 (I_80%):
I_80% = 10 GFLOPs / 20 MBI_80% = (10 * 10^9 FLOPs) / (20 * 10^6 Bytes)I_80% = 500 FLOPs / Byte
情况 C: 缓存命中率为 90% (90% Hit)
- 含义: 只需要从 DRAM 传输 10% 的数据。
- 总传输数据量 (B):
B = 100 MB * (1 - 90%) = 10 MB - 计算操作强度 (I_90%):
I_90% = 10 GFLOPs / 10 MBI_90% = 1000 FLOPs / Byte
结论
I_90% > I_80% > I_0%
你可以清楚地看到:
- 分子
总计算量是一个常数。 - 分母
总传输数据量随着缓存命中率的提高而减小。 - 根据分数的基本性质,当分子不变,分母减小时,整个分数值(操作强度)就会增大。
物理意义: 缓存的本质就是用“高速但小容量”的存储来减少对“低速但大容量”存储的访问。对于操作强度的定义来说,这里的“传输数据量”特指从慢速存储(瓶颈所在)传输的数据量。缓存命中率越高,意味着我们越少地依赖慢速存储,因此有效操作强度就越高。
这就是为什么在 Roofline 图中,80% Hit 的红线看起来像是 0% Hit 的红线向右平移了(在对数坐标系下,乘以一个常数等于加上一个常数,表现为平移)。因为对于同一个程序点,高命中率等效于一个具有更高“天生”操作强度的程序。
好的,这个问题问得非常到位!你指出了一个容易混淆但至关重要的概念。
这里的**“稀疏度 (Sparsity)”和“缓存命中率 (Cache Hit Rate)”是两个完全不同且处于不同层面**的概念。
让我们来彻底厘清它们的关系。
1. 稀疏度预算 (Sparsity Budget) - 比如 6.25%
- 这是什么?:它是一个算法层面的参数,属于注意力机制本身。
- 决定了什么?:它决定了在进行注意力计算时,模型被允许关注多少历史信息。
- 以 LLM 为例:
- 假设上下文长度是 100,000 个 token。
- 一个 6.25% 的稀疏度预算意味着,在生成下一个词时,模型最多可以从这 100,000 个历史 token 中,挑选出
100,000 * 6.25% = 6250个“最关键”的 token 来进行计算。 - 剩下的 93.75% 的历史信息,在这一次计算中将被完全忽略。
- 一句话总结:稀疏度决定了“我需要哪些数据?”这个问题的答案集合的大小。 它定义了“关键 KV 条目”的总量。
2. 缓存命中率 (Cache Hit Rate) - 比如 80%
- 这是什么?:它是一个系统层面的性能指标,属于缓存管理系统 (KVDrive)。
- 衡量了什么?:它衡量了 KVDrive 的预测能力或缓存效率。
- 以 LLM 为例:
- 接上例,注意力算法告诉我们:“我需要这 6250 个关键 token 的 KV 缓存数据。”
- KVDrive 接收到这个“需求清单”。
- KVDrive 首先检查自己的 GPU 高速缓存(滑动窗口)。
- 它发现,在这 6250 个被需要的条目中,有
6250 * 80% = 5000个条目已经存在于 GPU 缓存中了!这就是“缓存命中”。 - 剩下的
6250 * 20% = 1250个条目,在 GPU 缓存里没找到,这就是“缓存未命中 (Cache Miss)”。 - 对于这 1250 个未命中的条目,KVDrive 必须去更慢的存储(主机 DRAM 或 SSD)中把它们加载过来。
- 一句话总结:缓存命中率衡量的是“我需要的数据里,有多少已经在我手边了?”
两者的关系与图表解读
现在我们回到那个 6.25% Sparsity Budget 的例子。
“即使稀疏度相同 (都是 6.25%)”,我们仍然可以有不同的缓存命中率 (0%, 80%, 90%)。这是因为缓存命中率取决于你的缓存策略有多好。
-
稀疏度 6.25% & 命中率 0%:
- 场景: 你的系统很“笨”(比如没有缓存,或者缓存策略极差)。
- 过程: 算法需要 6250 个条目,结果你发现这 6250 个条目一个都不在你的 GPU 缓存里。
- 结果: 你必须从 DRAM/SSD 加载全部 6250 个条目。传输数据量最大,操作强度最低。
-
稀疏度 6.25% & 命中率 80%:
- 场景: 你的系统很“聪明”(比如 KVDrive 的滑动窗口策略)。
- 过程: 算法需要 6250 个条目,你发现其中 5000 个已经在 GPU 上了。
- 结果: 你只需要从 DRAM/SSD 加载剩下的 1250 个条目。传输数据量大大减少,操作强度显著提高。
所以,6.25% 这个数字回答了“总共需要多少块砖?”。
而 80% 这个数字回答了“这些需要的砖里,有多少已经在我手推车里,不用回仓库去搬了?”。
稀疏度决定了任务的“总需求量”,而缓存命中率决定了为了满足这个需求,需要付出的“实际搬运成本”。
在 Roofline 图中,不同的稀疏度预算(1.56% vs 6.25%)会影响到计算量 (F) 和总需求数据量,从而可能改变整个图的基准。但在这张图的特定语境下,作者固定了稀疏度来比较不同缓存策略带来的影响。因此,0% Hit 和 80% Hit 是在同一个稀疏度预算下,由于缓存系统效率不同而产生的两种不同性能表现,它们对应着不同的有效操作强度,从而在图上表现为不同的斜线。
当然。这张图是 KVDrive 设计中非常重要的一部分,它展示了系统如何智能地管理横跨 GPU 显存 (HBM)、主机内存 (DRAM) 和 固态硬盘 (SSD) 这三个层级的数据。
这张图分为两个阶段和四个策略的演进,我来为您逐一分解。
第一阶段:❶ 预填充 (Prefill) - 智能的初始布局
这个阶段发生在正式开始逐字生成(解码)之前,也就是模型一次性处理完用户输入的全部提示(prompt)之后。
- 核心思想: 在解码开始前,我们能不能预测哪些历史信息在接下来的生成过程中会更重要,然后把它们放在更快的地方?
- Importance-Guided Warm-Up (重要性引导的预热):
- 观察窗口 (Observation Window): KVDrive 查看提示文本的最后几个词(比如最后 16 或 64 个词)。
- 注意力热力图 (Attention Weights Heatmap): 它分析这最后几个词在计算时,对前面所有历史词的“注意力”分布。热力图中的亮点就表示“被高度关注”的历史位置。
- 重要性排序: 根据这个热力图,KVDrive 给所有的历史 KV 缓存条目排了个序,分成三六九等:
- High-Score KV Cache (高分缓存): 最重要的,未来最可能被用到。
- Medium-Score KV Cache (中分缓存): 次重要的。
- Full KV Cache (全量缓存): 包含了所有信息,包括不怎么重要的。
- 分层放置:
- SSD: 存储所有的 KV 缓存,作为最可靠的“大仓库”。
- DRAM: 存放中等重要和高分的 KV 缓存,作为“高速中转站”。
- HBM (GPU 显存): 存放最重要的 KV 缓存,让 GPU 抬手就能拿到。
一句话总结 Prefill 阶段: KVDrive 不搞一刀切,它在开始工作前就做好了“精兵简政”,把最重要的“兵器”放在了最顺手的地方。
第二阶段:❷ 解码 (Decode) - 四种数据同步策略的演进
这个阶段是逐字生成的过程。当 GPU 需要一个不在其显存里的数据时,就需要从 DRAM 或 SSD 中加载。这里展示了从最笨到最聪明四种加载策略的演化。
在下面四种策略中,你可以把 Full KV Cache (在 SSD 上) 看作是超市货架,Memmap (DRAM 的一部分) 看作购物车,Hot KV Cache (DRAM 的另一部分) 和 Pinned Memory 看作厨房操作台旁边的临时置物架,而 GPU 的计算核心就是厨师。
(a) Layer-wise Transfer (逐层传输 - 笨办法)
- 做法: 模仿 FlexGen。当需要计算第 15 层时,把整个第 15 层的 KV 缓存从 SSD 经过 DRAM 搬到 GPU。
- 问题: 极其浪费。就像厨师要做一道菜只需要 1 斤番茄,你却把超市整个蔬菜区都搬了过来。这导致了严重的 I/O 放大和拥堵。
(b) Block-wise Transfer (逐块传输 - 聪明一点)
- 做法: KVDrive 的改进。不再传输整个层,而是只传输当前计算真正需要的那些特定的 KV 块 (block)。
- 改进: 就像厨师说要 1 斤番茄,你就只去拿 1 斤番茄。这大大减少了无效的数据传输。
© Hierarchical (分层传输 - 更聪明)
- 引入
Pinned Memory(页锁定内存): 这是一种特殊的 DRAM 区域,GPU 可以通过 DMA(直接内存访问)技术极快地从中读取数据,几乎没有延迟。 - 做法: 从 SSD 加载数据时,不再直接给 GPU,而是形成一个流水线:
- 数据从 SSD 被读到
Memmap区域(普通购物车)。 - 然后,这些数据被预先拷贝到
Pinned Memory(操作台旁边的专用置物架)。 - GPU 从
Pinned Memory中高速取用数据。
- 数据从 SSD 被读到
- 改进: 这就像把食材从购物车里拿出来,整齐地摆在操作台旁,厨师一伸手就能拿到,不用再弯腰去购物车里翻找。它实现了数据准备和计算的异步进行,减少了 GPU 的等待时间。
(d) Adaptive Hierarchical (自适应分层传输 - KVDrive 的最终方案)
- 核心思想:
Pinned Memory虽然快,但它也是宝贵的 DRAM 资源。我们应该把它用在刀刃上。 - 做法: KVDrive 会在运行中进行动态调整。它会监控哪些数据的加载过程总是很慢,容易导致 GPU 卡顿(比如频繁的页错误)。
- 对于那些总是“惹麻烦”的热点数据块,KVDrive 会策略性地将它们常驻在
Pinned Memory中,确保它们总能被高速访问。 - 对于其他不那么关键的数据,则继续使用普通的
Memmap路径。
- 对于那些总是“惹麻烦”的热点数据块,KVDrive 会策略性地将它们常驻在
- 改进: 这是一个平衡和自适应的最终策略。它不是把所有东西都放到最贵的置物架上,而是识别出最常用、最关键的调料和食材,把它们固定放在厨师手边,从而在控制资源成本的同时,最大化地提升了整体效率。
整张图的总结
这张图生动地展示了 KVDrive 在处理多级存储时的智能演进过程:
- 从战略上(Prefill 阶段),通过预测来优化初始数据布局。
- 从战术上(Decode 阶段),通过从粗到细、从同步到异步、从静态到自适应的一系列优化,将数据在 SSD、DRAM、HBM 之间的流动变得极其高效,最终在不牺牲性能的前提下,成功地将存储容量扩展到了 SSD,解决了长上下文 LLM 推理的根本瓶颈。
当然,这张图是 KVDrive 论文用来诊断问题的关键图表。它通过展示现有卸载系统的时间都花在了哪里,来有力地论证为什么需要一个像 KVDrive 这样的新系统。
这张图主要表达了以下三个核心观点:
观点一:真正的瓶颈不是计算,而是“准备工作”
-
图表元素解读:
Selection(粉色): 选择。决定需要哪些关键 KV 缓存条目的时间。Fetching(黄褐色): 获取。将这些选定的条目从主机内存加载到 GPU 的时间。Attention(浅绿色): 注意力计算。GPU 真正进行注意力矩阵乘法的时间。Feed-Forward Network(深绿色): 前馈网络计算。Transformer 层中另一部分主要的计算任务。
-
观察:
- 在所有三个子图中,代表“准备工作”的粉色部分 (Selection) 和黄褐色部分 (Fetching) 加起来,占据了整个柱子(总时间)的将近一半甚至更多。
- 而代表“真正计算”的浅绿色 (Attention) 和深绿色 (Feed-Forward) 部分,合起来只占了一半左右。
-
结论: 对于这些现有的 KV 缓存卸载系统来说,GPU 并没有一直在全力计算。它花了大量的时间在等待:等待系统告诉它需要哪些数据(Selection),以及等待这些数据被搬运过来(Fetching)。这些“准备工作”成为了整个解码过程的主要瓶颈。
观点二:这些“准备工作”的开销,随着问题规模的扩大而恶化
-
观察:
- 比较左图和中图 (增加批处理大小):
- 左图:
Batch Size=4 - 中图:
Batch Size=6 - 当批处理大小从 4 增加到 6 时,你会发现
Fetching(黄褐色) 部分的相对占比明显增加了。
- 左图:
- 比较左图和右图 (增加上下文长度):
- 左图:
Context=60k - 右图:
Context=122k - 当上下文长度从 60k 增加到 122k 时,
Selection(粉色) 和Fetching(黄褐色) 的总占比也显著增加了(尤其对于 Quest 系统)。
- 左图:
- 比较左图和中图 (增加批处理大小):
-
结论: 这个问题不是一个固定的小问题,而是一个会随着工作负载加重(更长的上下文,更大的批次)而变得越来越严重的瓶颈。这意味着,这些现有系统在处理未来更大、更复杂的 LLM 任务时,会变得越来越低效。
观点三:现有系统造成了严重的 GPU 资源浪费
-
隐含的逻辑:
Selection和Fetching这两个阶段,在传统的顺序执行流程中,是阻塞性的。也就是说,在进行这两步时,GPU 的主要计算单元是空闲的。- 结合观点一,既然
Selection和Fetching占了总时间的近一半,那就意味着 GPU 的计算单元有近一半的时间都在“摸鱼”,等待数据准备好。
-
结论: 这种顺序执行的设计导致了严重的 GPU 停顿 (GPU stalls)。我们花大价钱买来的强大 GPU,其计算能力没有被充分利用,造成了巨大的资源浪费和性能损失。
整张图的总结性陈述
这张图通过对三个代表性卸载系统(Quest, RetroInfer, ShadowKV)的时间分解,雄辩地证明了:
在现有的长上下文 LLM 推理卸载方案中,耗时的“选择”和“获取”数据阶段是主要的性能瓶颈,并且这个问题会随着上下文和批处理规模的扩大而加剧。这导致了严重的 GPU 停顿,表明迫切需要一种新的、能够重叠这些阶段以消除停顿的系统设计——而这正是 KVDrive 提出的“弹性流水线调度”所要解决的核心问题。
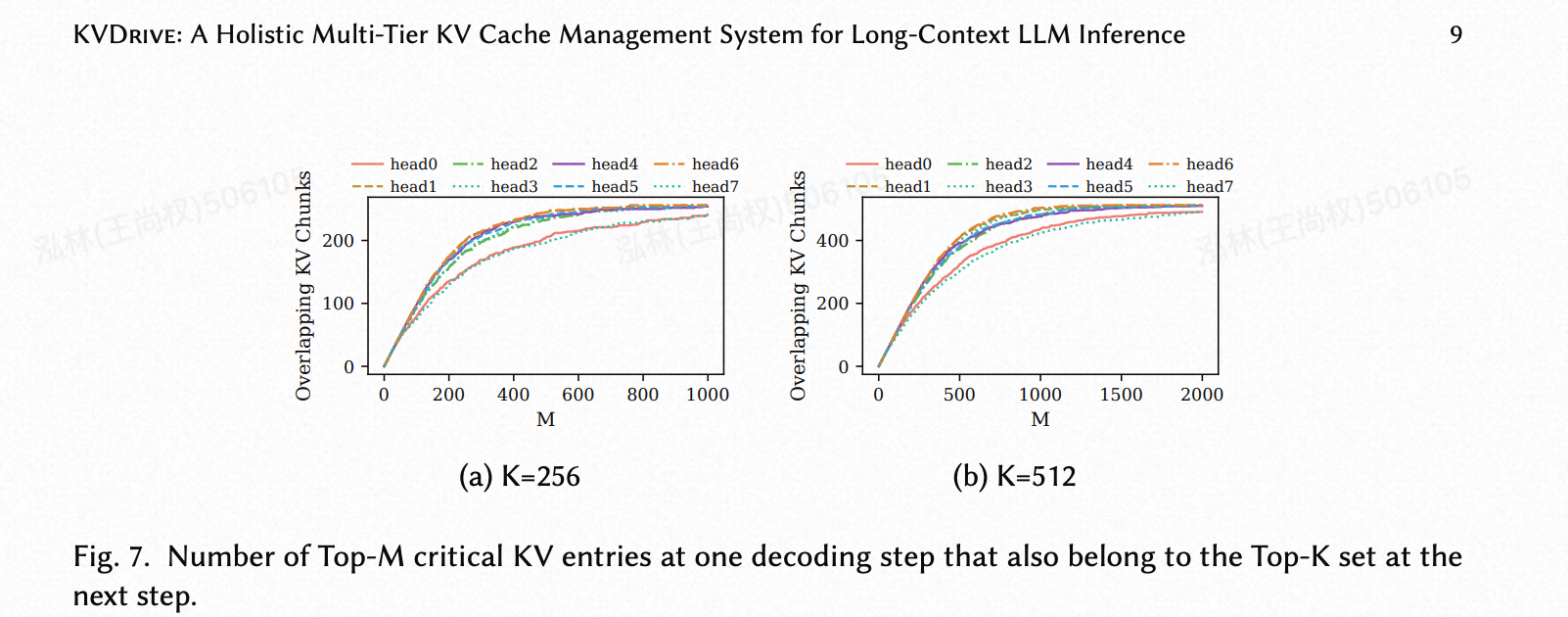
当然,这张图是用来支撑 KVDrive 的一个核心设计理念——“前瞻性驱逐策略 (Lookahead Eviction)”——的直接证据。它揭示了一个关于 LLM 注意力行为的重要模式。
这张图想要表达的核心观点是:
在一个解码步骤中,注意力分数越高的 KV 条目,在下一个解码步骤中也极有可能继续保持重要。反之,注意力分数低的条目,在下一步中很可能就没用了。
图表元素解读
-
标题的含义: “Number of Top-M critical KV entries at one decoding step that also belong to the Top-K set at the next step.”
- 翻译: 在当前步骤中,排名前 M 的关键 KV 条目里,有多少个也同时出现在了下一步骤的排名前 K 的关键 KV 条目集合中。
- 简化理解: 衡量了**“今天的重要信息,明天还有多少仍然重要?”**
-
X 轴 (M): 在当前步骤中,我们考察的重要性排名范围。
M=200就是指我们看当前步骤中最重要的前 200 个条目。 -
Y 轴 (Overlapping KV Chunks): 重叠数量。它表示 X 轴上那 M 个条目里,有多少个在下一步中依然排进了最重要的前 K 名。
-
K 值 (K=256, K=512): 这是下一步中“重要性”的门槛。
K=256意味着我们只看下一步中最重要的前 256 个条目。 -
不同颜色的线 (head0, head1, …): 代表一个 Transformer 层中的不同注意力头 (Attention Head)。这表明作者在分析不同头的行为。
从图中能读出什么信息?
让我们以图 (a) K=256 为例来分析:
-
曲线的快速上升:
- 观察 X 轴从 0 到 200 左右的区域,所有曲线都非常陡峭。
- 当
M=200时,Y 轴的值已经达到了约 180。 - 解读: 这意味着,在当前步骤中最重要的前 200 个条目里,有高达 180 个(即 90%)在下一步中依然是排名前 256 的重要条目!这显示了极强的时间连续性。
-
曲线趋于平缓:
- 当 X 轴从 400 增加到 1000 时,曲线变得非常平缓。Y 轴的值从约 220 缓慢增加到约 240。
- 解读: 这意味着,当我们开始考察当前步骤中那些排名不那么靠前的条目时(比如排名第 400 到第 1000 的),它们在下一步中还能保持重要性的概率就大大降低了。包含了这么多“次要”条目,重叠数量的增加却非常有限。
-
曲线的极限:
- 所有曲线的 Y 值最终都无法超过 256。这是显然的,因为我们衡量的重叠对象是下一步的 Top-K 集合,而这里的
K=256。
- 所有曲线的 Y 值最终都无法超过 256。这是显然的,因为我们衡量的重叠对象是下一步的 Top-K 集合,而这里的
这张图如何指导 KVDrive 的设计?
这张图的发现直接催生了 KVDrive 的**“前瞻性驱逐策略”**。
-
传统缓存策略 (如 LRU - 最近最少使用) 的问题: 当缓存满了,需要踢掉一个条目时,LRU 会踢掉“最久没被访问过”的条目。但这个条目可能在当前步骤中非常重要,只是恰好在前几步没用到。LRU 没有“远见”。
-
KVDrive 的“前瞻性”策略:
- 缓存满了,需要踢人。踢谁?
- KVDrive 会查看当前步骤中所有已缓存条目的注意力分数。
- 根据这张图的结论: 那些注意力分数最低的条目(对应 X 轴上 M 值很大的区域),它们在下一步中继续保持重要的可能性极低。
- 决策: 所以,就应该优先驱逐这些当前注意力分数最低的条目。
一句话总结这张图的意义:
它通过数据证明了**“注意力分数的高低”是预测一个 KV 条目“未来价值”的强力指标**。KVDrive 正是利用了这一洞察,设计出一种比传统 LRU/LFU 策略更智能、更符合 LLM 行为模式的缓存驱逐算法,从而提高了缓存效率。
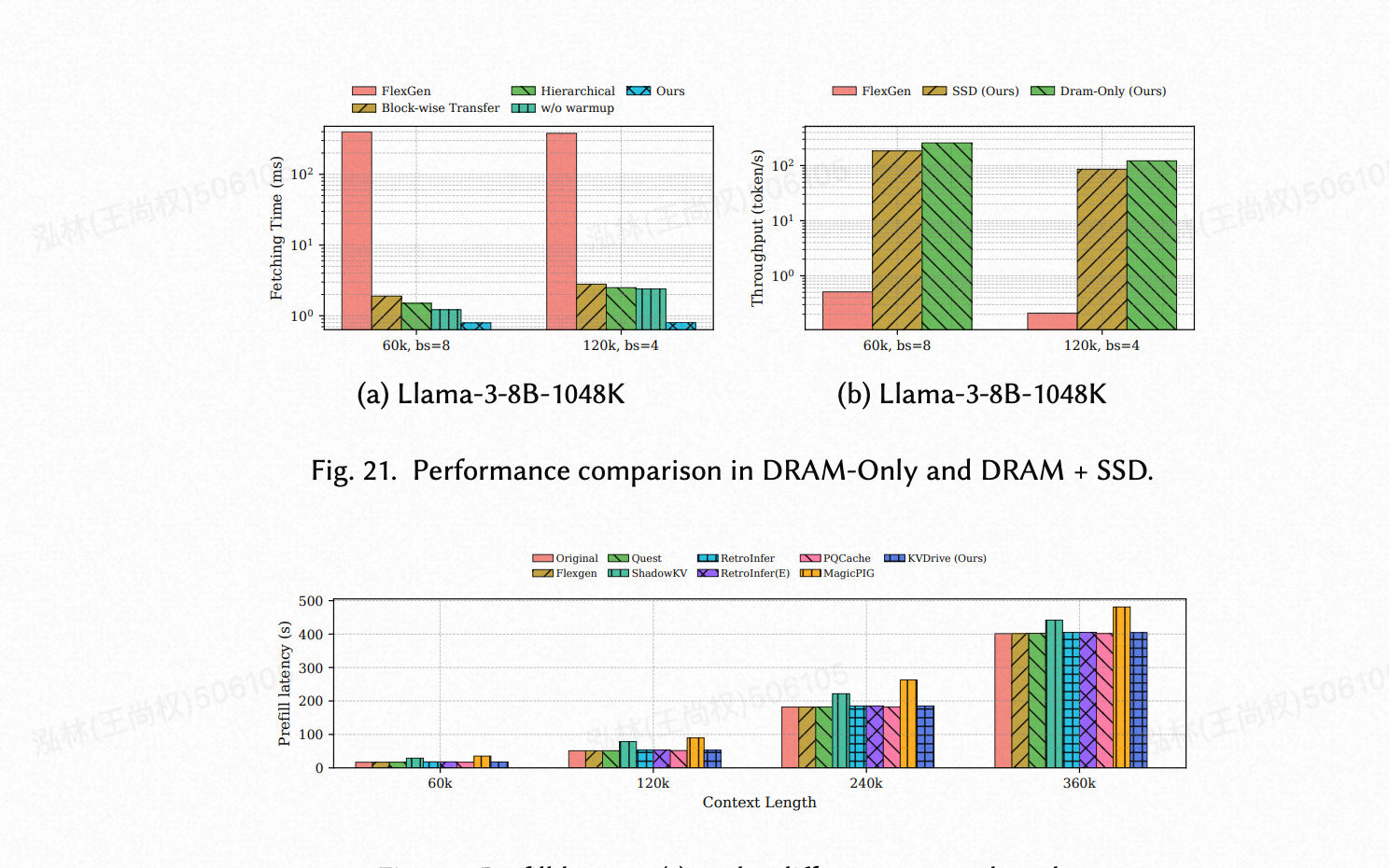
好的,这两张图(Fig. 21 和 Fig. 22)放在一起,共同传达了关于 KVDrive 性能和开销的几个重要信息,特别是关于其多级存储(DRAM+SSD)能力和预填充阶段的效率。
我们来分别解析。
图 21: DRAM-Only vs DRAM + SSD 性能比较
这张图的核心是证明:KVDrive 的多级存储管理是高效的,即使引入了慢速的 SSD,性能也远超传统方法,并且与纯 DRAM 方案相比,性能损失在可接受范围内。
图 21 (a): 获取时间 (Fetching Time)
- Y 轴是对数尺度 (log scale),这意味着柱子之间的高度差异比看起来要大得多。
- FlexGen (粉色): 获取时间长得离谱(超过 100ms)。这是因为它采用了粗粒度的逐层加载,从 SSD 搬运了大量无用数据。
- KVDrive 的逐步优化:
Block-wise Transfer(黄褐色): 从“逐层”变为“逐块”,获取时间骤降一个数量级(从几百ms降到几ms)。证明了细粒度加载的巨大优势。Hierarchical(绿色): 引入了 Pinned Memory 流水线,时间进一步减少。w/o warmup(青色,无预热的最终方案): 时间继续减少。Ours(蓝色,KVDrive 最终方案): 引入了“重要性引导的预热”,获取时间达到最低。这是因为预热阶段已经把最可能用到的数据放在了更快的地方(DRAM/HBM),大大减少了去 SSD 抓数据的需求。
- 结论: KVDrive 的一系列精细化设计(逐块、分层、预热),将从 SSD 获取数据的延迟降低了两个数量级(约 100 倍),使其成为一个可行的方案。
图 21 (b): 吞吐量 (Throughput)
- Y 轴也是对数尺度。
- FlexGen (粉色): 吞吐量极低(低于 1 token/s),几乎不可用。这再次证实了其低效的数据加载方式导致 GPU 严重停顿。
- KVDrive 的对比:
SSD (Ours)(黄褐色): 这是 KVDrive 使用 DRAM + SSD 组合时的吞吐量。Dram-Only (Ours)(绿色): 这是 KVDrive 只使用 DRAM(假设 DRAM 足够大)时的吞吐量。
- 关键观察:
SSD (Ours)的吞吐量远高于FlexGen,证明了 KVDrive 的多级存储管理是成功的。SSD (Ours)的吞吐量比Dram-Only (Ours)略低(在图中大约低了 40%)。
- 结论: 引入 SSD 确实会带来性能损失,因为 SSD 毕竟比 DRAM 慢。但是,在 KVDrive 的智能管理下,这个性能损失被控制在了一个完全可以接受的范围内。更重要的是,通过牺牲这一点性能,我们换来了突破 DRAM 容量限制、支持更大批次和更长上下文的能力。这是一个非常划算的权衡。
图 22: 预填充延迟 (Prefill latency)
这张图用来打消一个疑虑:KVDrive 的这些花哨的预处理(如构建索引、重要性引导预热)会不会拖慢整个流程的启动速度?
-
Y 轴: 预填充阶段花费的时间(秒)。这是用户发出请求后,到模型生成第一个词之间的等待时间。越低越好。
-
X 轴: 上下文长度。
-
观察:
Original(粉色): 这是最基准的方法,所有数据都在 GPU 上,没有任何卸载和索引构建的开销。可以看作是理论最快速度。KVDrive (Ours)(深蓝色): KVDrive 的柱子高度几乎与Original完全一样。- 其他系统 (如
MagicPIG,ShadowKV): 它们的柱子明显更高,意味着它们的预填充开销更大。
-
结论: KVDrive 的预填充过程几乎没有引入任何额外的延迟。尽管它在后台做了很多工作(K-Means 聚类构建索引、计算重要性、数据分层卸载),但这些操作的计算成本很低,并且被高效地与模型本身的预填充计算重叠(overlap)了。用户几乎感觉不到这些额外操作的存在。这证明了 KVDrive 不仅解码快,启动也快,是一个端到端都高效的系统。
两张图的综合表达
- KVDrive 是一个全能选手: 它不仅在核心的解码阶段性能卓越(图 21),在初始的预填充阶段也同样高效,没有明显的短板(图 22)。
- KVDrive 成功驯服了 SSD: 它通过一系列精巧的细粒度、异步化和自适应设计,将慢速 SSD 成功整合进存储层次,以可接受的性能代价换取了近乎无限的容量扩展,解决了长上下文推理的根本瓶颈。
- 系统级协同设计的胜利: 这些图表共同证明了,相比于只在某个单点进行优化的方法,KVDrive 这种从预填充到解码、从硬件到算法进行全流程协同设计的**“整体性 (Holistic)”**方法,能够带来巨大的性能收益。
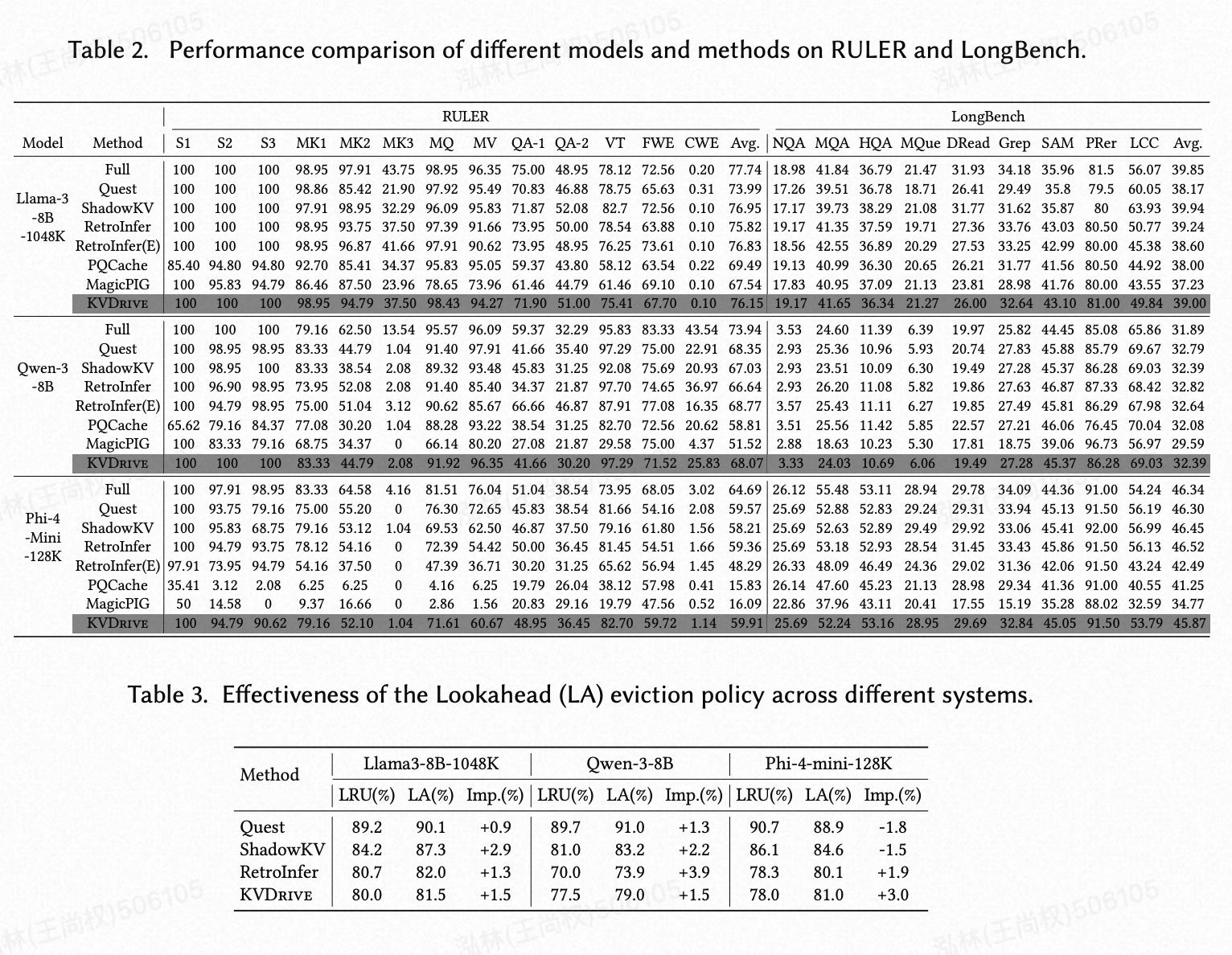
好的,这两张表格(Table 2 和 Table 3)是实验部分的核心,它们分别从**“模型效果”和“核心技术有效性”**两个角度来支撑 KVDrive 的价值。
我们来分别解析这两张表。
表 2: 在 RULER 和 LongBench 上的性能比较
这张大表格的核心目的是为了回答一个关键问题:KVDrive 做的所有这些系统层面的优化,会不会损害大语言模型本身的推理能力和准确性?
-
行 (Rows):
Model: 使用了三种不同的大模型 (Llama-3, Qwen-3, Phi-4)。Method: 对比了各种不同的系统。Full: 黄金标准。不进行任何卸载或稀疏化,所有 KV 缓存都在 GPU 上用全精度计算。这代表了理论上最好的效果。Quest,ShadowKV,RetroInfer,PQCache,MagicPIG: 其他主流的 KV 缓存卸载系统。KVDrive (Ours): 作者提出的系统。
-
列 (Columns):
RULER和LongBench: 两个专门测试长上下文理解能力的基准测试集。S1,S2,MK1,NQA,MQA…: 这些都是基准测试集下的具体子任务,衡量模型在不同方面的能力(如检索、问答、代码理解等)。Avg.: 在该基准测试集上的平均分。这是最重要的对比指标。
-
核心观察:
- 在每个模型的板块中,比较
KVDrive这一行和Full、Quest、ShadowKV等其他领先系统的平均分 (Avg.)。 - 你会发现,
KVDrive的平均分和其他主流系统基本持平,都非常接近Full方法的得分。例如,在 Llama-3 的 LongBench 测试中,KVDrive (39.00), ShadowKV (39.94), RetroInfer (39.24) 都非常接近 Full (39.85)。 - 有些系统,比如
PQCache和MagicPIG,在某些任务上得分明显偏低,说明它们的稀疏化或压缩方法对模型准确性造成了较大损害。
- 在每个模型的板块中,比较
-
结论: 这张表雄辩地证明了,KVDrive 在实现巨大系统性能提升(更高的吞吐量)的同时,几乎没有牺牲模型的准确性。它在效果上与最先进的(SOTA)方法并驾齐驱,是一个效果好又速度快的系统。
表 3: 前瞻性驱逐 (Lookahead Eviction) 策略的有效性
这张小表格的目的是为了验证 KVDrive 的一个核心创新点——“前瞻性驱逐 (LA)”策略——是否真的有效,并且是否具有普适性。
-
行 (Rows):
Method- 作者把自己的 LA 策略应用到了四个不同的系统上(Quest, ShadowKV, RetroInfer, KVDrive),来测试其通用性。
-
列 (Columns):
LRU(%): 使用传统的最近最少使用 (LRU) 驱逐策略时的缓存命中率。LA(%): 使用 KVDrive 提出的前瞻性 (Lookahead) 驱逐策略时的缓存命中率。Imp.(%):LA相比LRU带来的命中率提升(Improvement)。
-
核心观察:
- 在
Llama3-8B和Qwen-3-8B这两个模型上,对于所有被测试的系统,LA(%)的值都高于LRU(%)的值。Imp.(%)都是正数。 - 例如,在 ShadowKV 上应用 LA 策略,命中率在 Llama3 上提升了 2.9%,在 Qwen-3 上提升了 2.2%。
- 在
Phi-4-mini上,结果有些波动,但 KVDrive 自身在使用 LA 策略时,命中率提升了 3.0%,效果显著。
- 在
-
结论:
- LA 策略是有效的: 它确实能比传统的 LRU 策略带来更高的缓存命中率。
- LA 策略具有普适性: 它不仅仅在 KVDrive 自己的系统上有效,把它“嫁接”到其他系统中,同样能带来性能提升。这证明了“根据注意力分数来决定驱逐优先级”是一个基本且普适的正确思路,而非仅仅适用于特定系统架构的“小技巧”。
两张表的综合表达
- 表 2 (宏观效果): 证明了 KVDrive “行”。它在最终结果上是可靠的、准确的,和最好的方案在同一水平线上。
- 表 3 (微观机理): 解释了 KVDrive “为什么行”。它通过实验数据验证了其核心创新之一(前瞻性驱逐)的科学性和有效性,证明了其性能提升并非偶然,而是来自于对 LLM 行为模式的深刻洞察和巧妙利用。
这两张表结合起来,为 KVDrive 的设计提供了从结果到原因的完整、有力的证据链。

免费领 100 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐

 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)