
【LLM】VeRL训练框架源码分析
note
- veRL 是字节打造并开源的一款强化学习(RL)训练框架。它借助 Ray 可作为胶水层的功能,能够简单灵活地编写数据流程。veRL 最核心的功能是
3D-HybridEngine,该功能可以灵活定义智能体(Actor)的生成和训练阶段。代码支持丰富的模型库,实现了开箱即用,让它迅速成为强化学习训练的首选。 - veRL 借助混合控制方式,在一定程度上解决了数据流(DataFlow)灵活定义与高效执行的问题。具体而言,它在不同层级分别采用了单控制器(single -controller)和多控制器(multi - controller)两种模式。其中,单控制器负责控制,多控制器负责计算。
- RL 训练框架要解决的问题是:灵活定义 DataFlow、将定义出来的 DataFlow 在 GPU 集群上高效执行
- VeRL逻辑分层:配置/入口 →(Ray+HybridFlow)调度 → 引擎(训练/推理) → 算法 → 组件(actor/ref/reward) → 数据。
- GRPO算法特点:
- GRPO 特殊点:无 critic、组采样、优势=相对组平均、KL 放在 loss(不是奖励里)。
- GRPO = 多条候选组成“组” → 组内对比决定优势 → 只训策略,不训 critic → 用 KL loss 对齐参考策略。
[Configs/Launcher]
│
▼
[Trainer 主循环] ── 调 Ray & HybridFlow → 安排任务图
│
├── 用 [Rollout Engine: vLLM/SGLang] 生成轨迹
├── 调 [Reward] 计算奖励
├── 调 [Algorithms] 做优势/损失(PPO/GRPO…)
└── 用 [Training Engine: FSDP/Megatron] 反向更新
一、VeRL框架
「VeRL(Volcano Engine Reinforcement Learning for LLMs)」
VeRL 是什么
开源的 LLM 后训练(RL/RLHF/RLAIF)框架,由字节 Doubao/Seed 团队主导。它把算法流和分布式执行解耦,既能像写“数据流”一样拼装 RL 步骤,又能在多种训练/推理引擎上高效跑(FSDP、Megatron-LM、vLLM、SGLang 等)。官方称相较已有系统在多种 RLHF 算法上可达 1.53×–20.57× 吞吐提升(论文实验)。(GitHub)
两个核心设计
- HybridFlow 编程范式:把传统“单控制器”(灵活)和“多控制器”(高效)混合起来;通过一组分层 API,把计算和数据依赖明确表达,方便你拼装 PPO/GRPO/DAPO 等任意 RL 数据流。(arXiv)
- 3D-HybridEngine:在“训练 ↔ 生成(rollout)”切换时做actor 模型重分片(reshard),消除冗余显存、降低通信开销,是它性能的关键来源。(GitHub)
能力版图
- 算法:PPO、GRPO、OPO、DAPO、SPIN、SPPO、GPG 等,并提供 recipe 级复现与扩展接口。(Verl)
- 后端/引擎:训练(PyTorch FSDP、Megatron-LM),推理(vLLM、SGLang);支持多种设备映射与并行。(Verl)
- Agentic RL:支持多轮对话、工具调用、异步 rollout 的 agent 训练模式。(Verl)
- 多硬件:NVIDIA 外,还提供 AMD ROCm 与 昇腾 的使用/调优文档。(Verl)
- 生态/实践:官方与社区给出从 DeepSeek-671B(MoE/超大规模)到各类 R1/工具使用/多模态的示例与落地链接。(GitHub)
二、训练实践
1、概览
-
安装与选择后端(Docker 或本地 env;选 FSDP/Megatron + vLLM/SGLang):文档 Quickstart 与“Choices of Backend Engines”一步步给出命令。(Verl)
-
准备数据(对齐 Post-Training 的标准数据接口/奖励函数接口)。(Verl)
-
跑一个 PPO 样例(GSM8K + Qwen2.5-0.5B-Instruct),也可用 KubeRay 模板在 K8s 集群启动:
- 文档的“Quickstart: PPO training on GSM8K dataset”;Ray 官方也有 “RLHF for LLMs with verl on KubeRay” 指南。(Verl)
想最快试:直接照 readthedocs 的 PPO Quickstart 抄命令改模型/数据就能起;若要大规模/多机,用文档里的 Multinode 章节或 SkyPilot 示例。(Verl)
2、GRPO训练脚本
下面是官方的一个基于qwen3 8b模型进行GRPO训练脚本:
# Tested successfully on the hiyouga/verl:ngc-th2.6.0-cu126-vllm0.8.4-flashinfer0.2.2-cxx11abi0 image.
# It outperforms the Qwen2 7B base model by two percentage points on the test set of GSM8K.
set -x
python3 -m verl.trainer.main_ppo \
algorithm.adv_estimator=grpo \
data.train_files=$HOME/data/gsm8k/train.parquet \
data.val_files=$HOME/data/gsm8k/test.parquet \
data.train_batch_size=1024 \
data.max_prompt_length=512 \
data.max_response_length=1024 \
data.filter_overlong_prompts=True \
data.truncation='error' \
actor_rollout_ref.model.path=Qwen/Qwen3-8B \
actor_rollout_ref.actor.optim.lr=1e-6 \
actor_rollout_ref.model.use_remove_padding=True \
actor_rollout_ref.actor.ppo_mini_batch_size=256 \
actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=32 \
actor_rollout_ref.actor.use_kl_loss=True \
actor_rollout_ref.actor.kl_loss_coef=0.001 \
actor_rollout_ref.actor.kl_loss_type=low_var_kl \
actor_rollout_ref.actor.entropy_coeff=0 \
actor_rollout_ref.model.enable_gradient_checkpointing=True \
actor_rollout_ref.actor.fsdp_config.param_offload=False \
actor_rollout_ref.actor.fsdp_config.optimizer_offload=False \
actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=32 \
actor_rollout_ref.rollout.tensor_model_parallel_size=2 \
actor_rollout_ref.rollout.name=vllm \
actor_rollout_ref.rollout.gpu_memory_utilization=0.6 \
actor_rollout_ref.rollout.n=5 \
actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=32 \
actor_rollout_ref.ref.fsdp_config.param_offload=True \
algorithm.use_kl_in_reward=False \
trainer.critic_warmup=0 \
trainer.logger='["console","wandb"]' \
trainer.project_name='verl_grpo_example_gsm8k' \
trainer.experiment_name='qwen3_8b_function_rm' \
trainer.n_gpus_per_node=8 \
trainer.nnodes=1 \
trainer.save_freq=20 \
trainer.test_freq=5 \
trainer.total_epochs=15 $@
脚本代码分析:
- 用 Qwen3-8B 作 actor(通常 ref 初始同 actor)。
- 走 vLLM/SGLang 做 rollout 推理端,训练端用 FSDP/Megatron(按你选择的配置)。
- 数据用官方示例(多见 GSM8K 的 parquet),并指定 GRPO 的关键超参(每个 prompt 生成的 group 数 G、advantage 估计方式、温度、top-p 等)。
- 绑定 reward 函数(如 GSM8K 正确性 + 格式奖励)。
- 配好 Ray/节点显卡、batch/长度、日志与 checkpoint 目录,然后调用
python -m verl.trainer.main_ppo ... algorithm.adv_estimator=grpo开训。(Verl)
关键参数:
-
模型与推理后端
--actor_rollout_ref.model.path(或等价参数):改成你的 Qwen3-8B 路径(本地或 HF 名)。- 选择 vLLM 或 SGLang 作 rollout,并设置端口/并发(脚本里会给默认)。许多讨论直接用这份脚本改模型就能跑。(GitHub)
-
数据
data.train_files=/path/to/train.parquetdata.val_files=/path/to/val.parquet- 还有
max_prompt_length / max_response_length / filter_overlong_prompts等。(GitHub)
-
GRPO 关键超参
algorithm.adv_estimator=grpo(指定用 GRPO)- 生成组数 G(每个 prompt 采样几条候选)、温度、top-p、每步 sample 数等;这些都在 GRPO 文档页和示例脚本里有直观注释/默认值。(Verl)
-
并行与批量
data.train_batch_size(全局 batch)+ 每卡 micro-batch(通过 launcher/FSDP 配置)NNODES / NPROC_PER_NODE / FSDP/Megatron相关环境变量(有的脚本用 env 控制)。参考 perf/多机示例页面给的模板。(Verl)
-
日志与产物
project / exp_name / output / checkpoints。不少用户用这份脚本直接起跑并在对应目录下看到actor/critic的 checkpoint。(GitHub)
3、GRPO训练
(1)GRPO 是什么
在强化学习里,像 PPO 这类经典算法需要一个“价值网络(critic)”来估计动作价值、指导更新。但训练一个额外的 critic 很费资源。
GRPO 把这件事简化了:不再单独训练 critic,而是用“组内相对比较”的方式更新策略:
- 分组采样(Group Sampling):针对同一个问题/提示词,当前策略一次生成多条候选解,构成一个“组”。
- 打分(Reward Assignment):对每条候选按正确性/质量打分。
- 基线(Baseline):用组内平均奖励作为基线。
- 策略更新(Policy Update):将每条候选的奖励与组平均做比较,优于平均的被强化,劣于平均的被抑制。
这样就省掉了单独训练 value function 的开销,使训练更高效。更多背景可参考论文 DeepSeekMath(上限推理场景中的 GRPO 做法)。
(2)关键组件(Key Components)
- 无价值网络(Critic-less):不同于 PPO,GRPO 不训练单独的 value/critic。
- 组内采样(Grouped Rollouts):每个输入不止采样一条,而是采多条构成一个“组”。
- 相对奖励(Relative Rewards):对组内候选打分,并按相对组平均进行归一与对比。
(3)配置要点(Configuration)
说明:凡是带
micro_batch_size的配置,都是为了控制单次前/反传的样本或 token 上限,以避免 OOM;它们不应改变算法收敛本质。
虽然不少配置以 ppo_ 开头,但在 VeRL 中同样适用于 GRPO——因为 GRPO 的训练循环与 PPO 很相似(只是没有 critic)。
基于qwen3 8b的GRPO训练脚本:
# Tested successfully on the hiyouga/verl:ngc-th2.6.0-cu126-vllm0.8.4-flashinfer0.2.2-cxx11abi0 image.
# It outperforms the Qwen2 7B base model by two percentage points on the test set of GSM8K.
set -x
python3 -m verl.trainer.main_ppo \
algorithm.adv_estimator=grpo \
data.train_files=$HOME/data/gsm8k/train.parquet \
data.val_files=$HOME/data/gsm8k/test.parquet \
data.train_batch_size=1024 \
data.max_prompt_length=512 \
data.max_response_length=1024 \
data.filter_overlong_prompts=True \
data.truncation='error' \
actor_rollout_ref.model.path=Qwen/Qwen3-8B \
actor_rollout_ref.actor.optim.lr=1e-6 \
actor_rollout_ref.model.use_remove_padding=True \
actor_rollout_ref.actor.ppo_mini_batch_size=256 \
actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=32 \
actor_rollout_ref.actor.use_kl_loss=True \
actor_rollout_ref.actor.kl_loss_coef=0.001 \
actor_rollout_ref.actor.kl_loss_type=low_var_kl \
actor_rollout_ref.actor.entropy_coeff=0 \
actor_rollout_ref.model.enable_gradient_checkpointing=True \
actor_rollout_ref.actor.fsdp_config.param_offload=False \
actor_rollout_ref.actor.fsdp_config.optimizer_offload=False \
actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=32 \
actor_rollout_ref.rollout.tensor_model_parallel_size=2 \
actor_rollout_ref.rollout.name=vllm \
actor_rollout_ref.rollout.gpu_memory_utilization=0.6 \
actor_rollout_ref.rollout.n=5 \
actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=32 \
actor_rollout_ref.ref.fsdp_config.param_offload=True \
algorithm.use_kl_in_reward=False \
trainer.critic_warmup=0 \
trainer.logger='["console","wandb"]' \
trainer.project_name='verl_grpo_example_gsm8k' \
trainer.experiment_name='qwen3_8b_function_rm' \
trainer.n_gpus_per_node=8 \
trainer.nnodes=1 \
trainer.save_freq=20 \
trainer.test_freq=5 \
trainer.total_epochs=15 $@
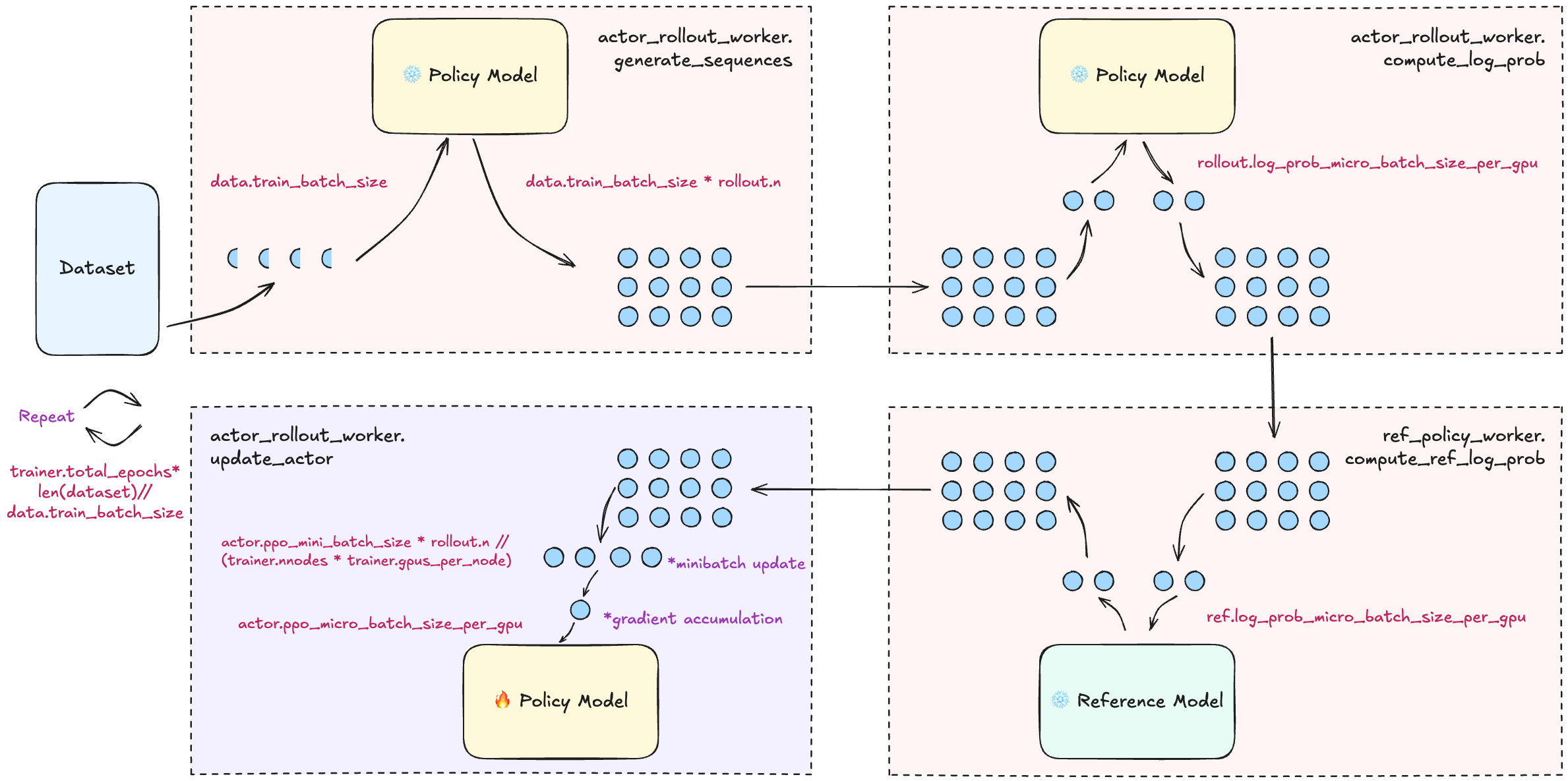
-
actor_rollout.ref.rollout.n:每个 prompt 采样 n 次(默认 1)。做 GRPO 请把它设为 > 1 以形成“组”。 -
data.train_batch_size:全局 prompt 批大小,用于一次性生成若干条轨迹/采样。总响应数 =data.train_batch_size * actor_rollout.ref.rollout.n。 -
actor_rollout_ref.actor.ppo_mini_batch_size:将上一步得到的轨迹集合再按此大小切分成多个 mini-batch 做 actor 更新(全局维度)。 -
actor_rollout_ref.actor.ppo_epochs:对这一批轨迹执行 GRPO(PPO 风格)的迭代轮数。 -
actor_rollout_ref.actor.clip_ratio:GRPO 的裁剪范围(默认 0.2)。 -
algorithm.adv_estimator:默认gae。做 GRPO 请改为grpo。 -
actor_rollout_ref.actor.loss_agg_mode:默认"token-mean"。可选:"token-mean"(示例脚本默认,用于更稳的 token 级聚合)"seq-mean-token-sum""seq-mean-token-mean"(原始 GRPO 论文是样本级聚合,即 seq-mean-token-mean;在长 CoT场景可能更不稳)
KL 正则:GRPO 不把 KL 惩罚直接加到奖励里,而是把策略与参考策略的 KL作为loss 项加入训练:
actor_rollout_ref.actor.use_kl_loss:是否在 actor 端使用 KL loss。GRPO 建议设为 True(此时奖励里不再单独加 KL)。actor_rollout_ref.actor.kl_loss_coef:KL loss 系数(默认 0.001)。actor_rollout_ref.actor.kl_loss_type:KL 近似/度量方式,支持kl(k1),abs,mse(k2),low_var_kl(k3),full。后缀+(如k1+、k3+)表示用 straight-through 技巧,梯度无偏但仍用近似 KL 值;详见官方讨论。KL 的一些推导与近似可参考 Josh Achiam 的博客(KL-approx 总结)。
4、进阶扩展:DrGRPO
论文 Understanding R1-Zero-Like Training: A Critical Perspective 指出:GRPO 的组内归一会带来优化偏置——错误样本更倾向生成更长的回答,从而降低效率。DrGRPO 通过在token 级进行归一、并用全局常数做归一来消除长度偏置。
启用 DrGRPO(其他参数与 GRPO 相同):
actor_rollout_ref.actor.loss_agg_mode:设为"seq-mean-token-sum-norm"(关闭序列维度的平均)。actor_rollout_ref.actor.use_kl_loss:设为 False(DrGRPO 不再用 KL loss)。algorithm.norm_adv_by_std_in_grpo:设为 False(关闭按标准差的归一)。
三、VeRL源码解读
- VeRL逻辑分层:配置/入口 →(Ray+HybridFlow)调度 → 引擎(训练/推理) → 算法 → 组件(actor/ref/reward) → 数据。
- GRPO 特殊点:无 critic、组采样、优势=相对组平均、KL 放在 loss(不是奖励里)。
[Configs/Launcher]
│
▼
[Trainer 主循环] ── 调 Ray & HybridFlow → 安排任务图
│
├── 用 [Rollout Engine: vLLM/SGLang] 生成轨迹
├── 调 [Reward] 计算奖励
├── 调 [Algorithms] 做优势/损失(PPO/GRPO…)
└── 用 [Training Engine: FSDP/Megatron] 反向更新
1) 配置与启动层(入口)
- 配置:YAML/JSON 风格的配置树(算法、数据、引擎、并行、日志、路径等)。
- 启动脚本:examples 下的
run_*.sh最终都会调用类似python -m verl.trainer.main_ppo ...(即使跑 GRPO,也复用 PPO 主循环,只是关掉 critic、换优势估计器)。 - 作用:把“这次实验的所有开关”装配成一个
cfg,交给 Trainer 建造整条流水线。
2) 调度与编程模型(HybridFlow + Ray)
- HybridFlow:用“算子/节点 + 边”的数据流写法,把“采样→打分→优势→更新→评测/保存”拼成一条可调度的任务图。
- Ray:负责分布式调度与资源管理(开一批 rollout worker、若干 learner/updater 等)。
- 作用:把一个 RLHF/GRPO 的训练回路,拆成可并行的步骤,在多机多卡上稳稳跑起来。
3) 引擎层(Engines)
- Training Engine:面向反向传播,支持 FSDP、Megatron(张量/流水线并行等)。
- Rollout Engine:面向采样/生成,集成 vLLM、SGLang 等高吞吐推理后端。
- 3D-HybridEngine(VeRL 的核心):训练↔生成时做权重重分片(reshard)与显存复用,减少切换开销。
4) 算法层(Algorithms)
-
PPO/GRPO/OPO/DAPO… 都以“策略更新器”的形式存在:
- 优势估计器(adv estimator):GAE / GRPO 等
- 损失:裁剪项、KL 正则(GRPO 多用 loss 里的 KL,而不是奖励惩罚)
- (可选)价值网络:PPO 有,GRPO 不要
-
作用:给 Trainer 提供“如何把一批轨迹变成梯度”的规则。
5) 组件层(Actor–Rollout–Ref–Reward)
- Actor:被训练的策略(你微调的 LLM)。
- Reference:参考策略(计算 KL 的“锚”)。
- Rollout:把 prompt 扔给推理后端,拿回多条响应(支持组采样,用于 GRPO)。
- Reward:任务相关的打分器(如 GSM8K 正确性、格式、长度约束、工具调用成功率等)。
- 作用:把“生成”和“评分”解耦,便于替换/扩展。
6) 数据管线(Data)
- 数据加载:JSON/Parquet/自定义 Dataset。
- 批处理:prompt 级的全局 batch(一次生成多少组)、以及防 OOM 的 micro_batch_size(单次前/反传 token/样本上限)。
- 过滤/长度控制:
max_prompt_length / max_response_length / filter_overlong_prompts等。 - 作用:把原始样本变成“能发给 rollout / 能喂进优化器”的张量批。
7) 训练器(Trainer,主循环)
一个“薄而强”的总控:
- 取一批 prompts
- rollout(可能每个 prompt 采样 n 次形成组)
- reward 打分
- 优势计算(PPO: GAE;GRPO: 组平均基线)
- 更新 actor(PPO 还会更新 critic;GRPO 无 critic + 常用 KL loss 正则)
- 评测/日志/保存(定步数或定时 checkpoint,记录 best 等)
你可以把 Trainer 理解成“把上面 1–5 用 HybridFlow 串起来,并交给 Ray/Engines 跑”的调度器。
8) 日志、可视化与产物(Logging & Artifacts)
- 日志:stdout + 可选接入 TB/W&B/SwanLab。
- 产物:actor/critic(若有)权重、优化器状态、配置快照、评测结果、样本片段。
- 作用:可复现实验 & 断点续训。
源码学习:
- 入口:
examples/*/run_*.sh→ 看最后的python -m verl.trainer.main_ppo ... - Trainer 主体:
verl/trainer/main_ppo.py(或等价命名)里怎么“拼”出各部件 - Engines:
verl/engine/{training,rollout}/*(FSDP/Megatron & vLLM/SGLang 封装) - Algorithms:
verl/algorithms/{ppo,grpo,...}/*(优势、损失与更新) - Components:
verl/components/{actor,reference,reward,...} - Data:
verl/data/*(加载、切分、长度/过滤) - HybridFlow:
verl/hybridflow/*(数据流与调度节点定义)
仓库结构会随版本微调,但这条“入口→Trainer→Engines/Algorithms→Components/Data”的顺序基本通吃;搜索关键字如
adv_estimator,use_kl_loss,rollout.n,FSDP很快能定位核心实现。
四、Agentic RL训练
1、agent loop代码:https://github.com/verl-project/verl/blob/main/verl/experimental/agent_loop/tool_agent_loop.py
2、训练脚本中通过actor_rollout_ref.rollout.agent.default_agent_loop=tool_agent参数激活agent loop
3、工作流程:PENDING → GENERATING → PROCESSING_TOOLS → GENERATING → … → TERMINATED
4、ms-swift和verl区别:
- ms-swift AgenticToolScheduler是同步/异步调度
- verl是纯异步状态机,每一步明确处于某个状态:
PENDING → 还没开始,准备注入工具描述
GENERATING → 正在让 vLLM 生成
PROCESSING_TOOLS → 正在执行工具调用
INTERACTING → 等待用户输入(如果有)
TERMINATED → 结束
5、VeRL哪些地方需要自己修改:
| 组件 | 谁提供 | 说明 |
|---|---|---|
| 状态机调度 | ✅ verl | ToolAgentLoop 完整实现 |
| 多轮对话管理 | ✅ verl | AgentData 管理消息历史 |
| Tool call 解析 | ✅ verl | ToolParser 解析 标签 |
| 并行工具执行 | ✅ verl | asyncio 并发,支持多模态响应 |
| Tool 实现类 | ❌ 你来写 | 继承 BaseTool,实现4个方法 |
| Reward 函数 | ❌ 你来写 | async compute_score() |
| tool_config.yaml | ❌ 你来写 | 工具注册和 schema 定义 |
| MCP 后端服务 | ❌ 你来维护 | / |
6、比较重要的代码文件/verl/verl/experimental/agent_loop/tool_agent_loop.py:
| 位置 | 值得学习的点 |
|---|---|
| 状态机设计(PENDING/GENERATING/PROCESSING_TOOLS) | 为什么要用状态机?怎么处理"生成到一半要暂停去调工具"这种异步场景 |
| _handle_generating_state() | 怎么判断模型是要调工具还是已经结束,终止条件怎么设计 |
| _handle_processing_tools_state() | 并行调用多个工具、工具返回结果怎么格式化塞回对话历史 |
| _call_tool() | create/execute/release 三段式设计,工具 reward 怎么从这里传出去 |
| AgentLoopOutput 返回值 | rollout 产出的数据结构,response_ids/tool_rewards/extra_fields 怎么对接后续 reward 计算 |
7、工具返回内容是环境给的,不是模型生成的,所以 mask=0,不参与梯度更新,如下代码中的agent_data.response_mask += [0] * len(response_ids) 部分:
async def _handle_processing_tools_state(self, agent_data: AgentData) -> AgentState:
"""Handle the processing tools state: execute tool calls and prepare tool responses."""
logger.info(f"[_handle_processing_tools_state] Processing {len(agent_data.tool_calls)} tool calls")
add_messages: list[dict[str, Any]] = []
new_images_this_turn: list[Any] = [] # Local variable instead of agent_data attribute
tasks = []
tool_call_names = []
ask_tool_triggered = False
for tool_call in agent_data.tool_calls[: self.max_parallel_calls]:
logger.info(f"[_handle_processing_tools_state] Scheduling tool call: {tool_call.name}")
tasks.append(self._call_tool(tool_call, agent_data.tools_kwargs, agent_data))
tool_call_names.append(tool_call.name)
if 'wenchain_ask' in tool_call.name:
ask_tool_triggered = True
logger.info("[_handle_processing_tools_state] ask tool detected, rollout will terminate after tool response")
with simple_timer("tool_calls", agent_data.metrics):
responses = await asyncio.gather(*tasks)
# Process tool responses and update multi_modal_data
# Removed: agent_data.new_images_this_turn = []
for tool_response, tool_reward, _ in responses:
# Create message from tool response
if tool_response.image or tool_response.video:
# Multi-modal content with structured format
if not getattr(self.processor, "image_processor", None):
raise ValueError(
"Multimedia data can only be processed by `processor`, but the processor is None. "
"This error is often caused if you are using a LLM model but your tool returns multimodal "
"data. Plase use a vlm as the base model."
)
content = []
if tool_response.image:
content.append({"type": "image"})
if tool_response.video:
content.append({"type": "video"})
if tool_response.text:
content.append({"type": "text", "text": tool_response.text})
message = {"role": "tool", "content": content}
else:
# Text-only content
message = {"role": "tool", "content": tool_response.text or ""}
add_messages.append(message)
# Handle image data
if tool_response.image:
# Add new image data
if isinstance(tool_response.image, list):
# Ensure all elements in the list are valid image objects
for img in tool_response.image:
if img is not None: # Add a check to ensure the image is not None
new_images_this_turn.append(img) # Using local variable
else:
# Ensure the image is not None
if tool_response.image is not None:
new_images_this_turn.append(tool_response.image) # Using local variable
# Handle video data
if tool_response.video:
# Currently not supported, raise informative error
logger.warning("Multimedia type 'video' is not currently supported. Only 'image' is supported.")
raise NotImplementedError(
"Multimedia type 'video' is not currently supported. Only 'image' is supported."
)
if tool_reward is not None:
agent_data.tool_rewards.append(tool_reward)
agent_data.messages.extend(add_messages)
if self.tool_parser_name == "gpt-oss":
logger.info("manually format tool responses for gpt-oss")
tool_response_text = build_gpt_oss_tool_response_text(add_messages, tool_call_names)
response_ids = await self.loop.run_in_executor(
None, lambda: self.tokenizer.encode(tool_response_text, add_special_tokens=False)
)
else:
response_ids = await self.apply_chat_template(
add_messages,
images=new_images_this_turn, # Using local variable
videos=None,
remove_system_prompt=True,
)
if len(agent_data.response_mask) + len(response_ids) >= self.response_length:
return AgentState.TERMINATED
# Update prompt_ids and response_mask
if new_images_this_turn:
if agent_data.image_data is None:
agent_data.image_data = []
elif not isinstance(agent_data.image_data, list):
agent_data.image_data = [agent_data.image_data]
for img in new_images_this_turn:
agent_data.image_data.append(img)
agent_data.prompt_ids += response_ids
agent_data.response_mask += [0] * len(response_ids)
if agent_data.response_logprobs:
agent_data.response_logprobs += [0.0] * len(response_ids)
agent_data.user_turns += 1
if ask_tool_triggered:
return AgentState.TERMINATED
return AgentState.GENERATING
五、其他
- GitHub README(特性、新闻、示例与「谁在用」)(GitHub)
- 官方文档总目录(Quickstart、HybridFlow 编程指南、Trainer/Worker 设计、性能调优)(Verl)
- HybridFlow 论文(动机、API 设计、3D-HybridEngine、吞吐实验)(arXiv)
- Qwen 的 VeRL 页面(和主流模型结合的实践入口)(qwen.readthedocs.io)
- KubeRay 教程 / AMD ROCm 博客(部署与异构硬件实战)(Ray)
与其他框架的对比定位
- VeRL主打编程模型 + 执行效率(HybridFlow/HybridEngine + Ray 构建的控制流),在 FSDP/Megatron + vLLM/SGLang 生态里做深集成;
- OpenRLHF 等也很强(Ray/DeepSpeed/vLLM 组合),但 VeRL 的论文/文档强调其在重分片/控制调度层面的系统优化与多后端灵活性。参考对比解读与社区讨论。(Anyscale)
Reference
1 https://github.com/volcengine/verl “GitHub - volcengine/verl: verl: Volcano Engine Reinforcement Learning for LLMs”
2 https://arxiv.org/abs/2409.19256 “[2409.19256] HybridFlow: A Flexible and Efficient RLHF Framework”
3 https://verl.readthedocs.io/ “Welcome to verl’s documentation! — verl documentation”
4 https://www.anyscale.com/blog/open-source-rl-libraries-for-llms?utm_source=chatgpt.com “Open Source RL Libraries for LLMs”
5 https://qwen.readthedocs.io/en/latest/training/verl.html?utm_source=chatgpt.com “verl - Qwen”
6 https://docs.ray.io/en/latest/cluster/kubernetes/examples/verl-post-training.html?utm_source=chatgpt.com “Create a Kubernetes cluster with GPUs - Ray Docs”
[7] verl官方文档:https://verl.readthedocs.io/en/latest/algo/baseline.html
[8] verl RFT: 从数据构建到GRPO训练
[9] 报错RuntimeError: The server socket has failed to listen on any local network address.port: 20014:https://github.com/volcengine/verl/issues/3521

免费领 200 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐

 15
15 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)