
Ollama安装及使用Ollama部署大模型
Ollama是一个开源本地大语言模型运行平台,支持Docker部署和API调用。
前言
Ollama 是一个开源的本地大语言模型(LLM)运行平台,目标是让你在本地像运行 ChatGPT 一样调用 LLM,而不需要依赖云服务。
一、安装
1. 官方安装
官网链接:Download Ollama on Windows
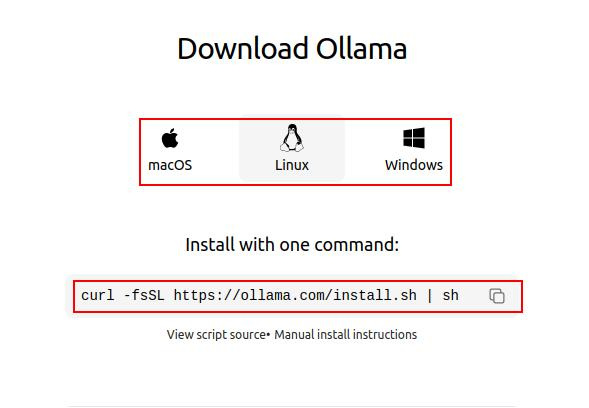
官方推荐了一种简单的安装方式,Linux系统可直接通过下述命令进行安装。
curl -fsSL https://ollama.com/install.sh | sh在下述界面中可以选择自己对应平台的命令进行安装:
2. Docker安装
Ollama 作为一款流行的本地大语言模型运行框架,其官方安装方式简洁高效。然而,对于追求更高灵活性、跨平台一致性以及希望简化管理流程的用户而言,采用 Docker 来部署 Ollama 提供了一种颇具吸引力的替代方案。
2.1 检查 Docker 状态
安装之前查看docker 是否启动
systemctl status docker
# 如果没启动,执行启动命令
systemctl start docker2.2 ollama 镜像拉取
首先进入官方链接拉取想要的镜像到本地,一般拉取 ollama/ollama:latest 镜像。
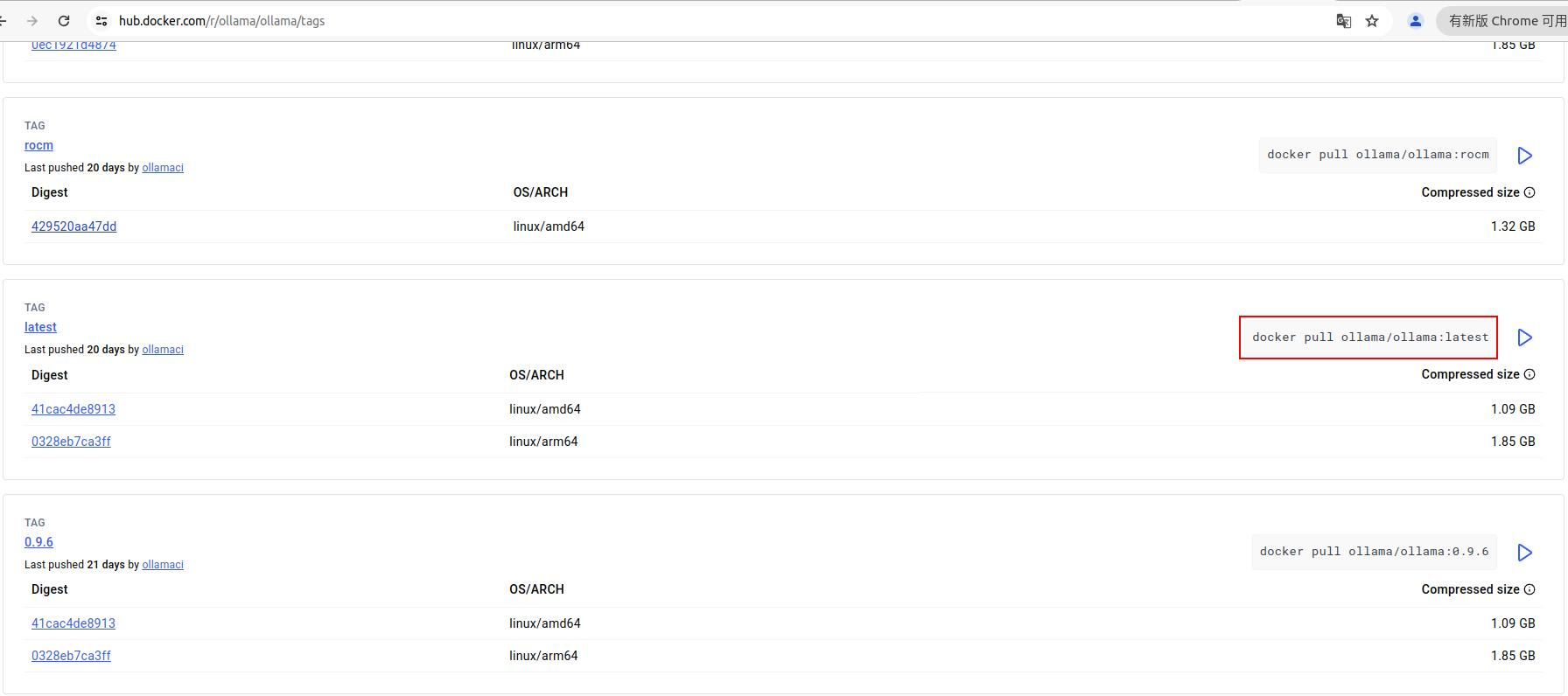
拉取完成,可以使用 docker images 命令查看我们拉取好的镜像。
2.3 启动容器
2.3.1 仅 CPU
docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama:latest
参数说明:
1.
docker run
- 作用:启动一个新的容器实例。
- 说明:Docker 的核心命令,用于从镜像创建并启动容器。
2.
-d(--detach)
- 作用:以 后台模式 运行容器。
- 说明:容器启动后会与当前终端分离,终端不会被阻塞,可以继续执行其他命令。
- 典型场景:适用于需要长期运行的服务(如 Web 服务器、数据库等)。
3.
-v /qjp/software/ollama:/root/.ollama(--volume)
- 作用:挂载 数据卷,实现宿主机与容器之间的目录映射。
- 参数结构:
宿主机目录:容器内目录- 说明:
- 将宿主机的
/qjp/software/ollama目录挂载到容器内的/root/.ollama目录。- 容器内的
/root/.ollama通常是 Ollama 的配置和数据存储目录,挂载后数据会持久化到宿主机,避免容器删除后数据丢失。- 典型场景:用于保存模型文件、配置文件或日志等持久化数据。
4.
-p 11434:11434(--publish)
- 作用:映射 容器端口 到 宿主机端口。
- 参数结构:
宿主机端口:容器内端口- 说明:
- 将宿主机的
11434端口映射到容器的11434端口。- 外部通过宿主机的
11434端口访问容器内的服务。- 典型场景:Ollama 的 API 或 Web 服务可能默认监听
11434端口,通过此映射允许外部访问。5.
--name ollama
- 作用:为容器指定一个 自定义名称(这里是
ollama)。- 说明:
- 如果不指定名称,Docker 会自动生成一个随机名称(如
angry_curie)。- 自定义名称便于后续通过
docker start/stop/rm等命令管理容器。- 典型场景:简化容器管理,避免依赖容器 ID。
6.
ollama/ollama:latest
- 作用:指定要使用的 Docker 镜像。
- 说明:
- 如果本地不存在该镜像,Docker 会从 Docker Hub 自动拉取。
- 未指定标签时,默认使用
latest标签。- 镜像的完整格式为
镜像名:标签(如ollama/ollama:latest)。- 典型场景:使用官方或自定义镜像启动服务。
2.3.2 英伟达 GPU
参考链接:ollama/ollama - Docker Image |Docker 中心
前提:已安装 NVIDIA 驱动 + nvidia-container-toolkit
docker run -d --gpus=all -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama:latest如果没有安装则会报错:

如果容器创建成功,id为:c37df162ca68ab5a34ce64e1a71e08f4442af4045c028d9a3385c5306871041b,同时还可以通过 docker exec -it ollama_0728 bash 命令进入容器内部。

2.4 nvidia-container-toolkit安装
用 Apt 安装
1. 配置仓库
nvidia-container-toolkit 不在 Ubuntu 默认的软件源里!如果你不添加 NVIDIA 官方源,Ubuntu 根本无法找到这个包,所以 apt install 会失败。
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey \
| sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg
curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list \
| sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' \
| sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt-get update
执行下述命令验证是否有对应的源:
ls /etc/apt/sources.list.d
2. 安装 NVIDIA 容器工具包
sudo apt-get install -y nvidia-container-toolkit
检查是否安装 toolkit,如果有如下类似输出则表示安装成功。
命令:
dpkg -l | grep nvidia-container-toolkit

3. 配置Docker使其使用Nvidia驱动
sudo nvidia-ctk runtime configure --runtime=docker # 配置 Docker 使用 GPU
sudo systemctl restart docker # 重启docker
4. 启动容器
docker run -d --gpus=all -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
2.5 验证
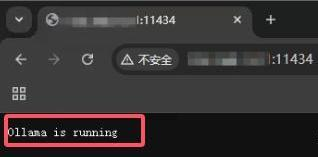
页面访问:http://xxx.xxx.xx.xx:11434/
显示 如下图,则 Ollama 安装成功,并正在运行
二、模型部署
1. 模型查找
Ollama可部署的模型可以去官网查看
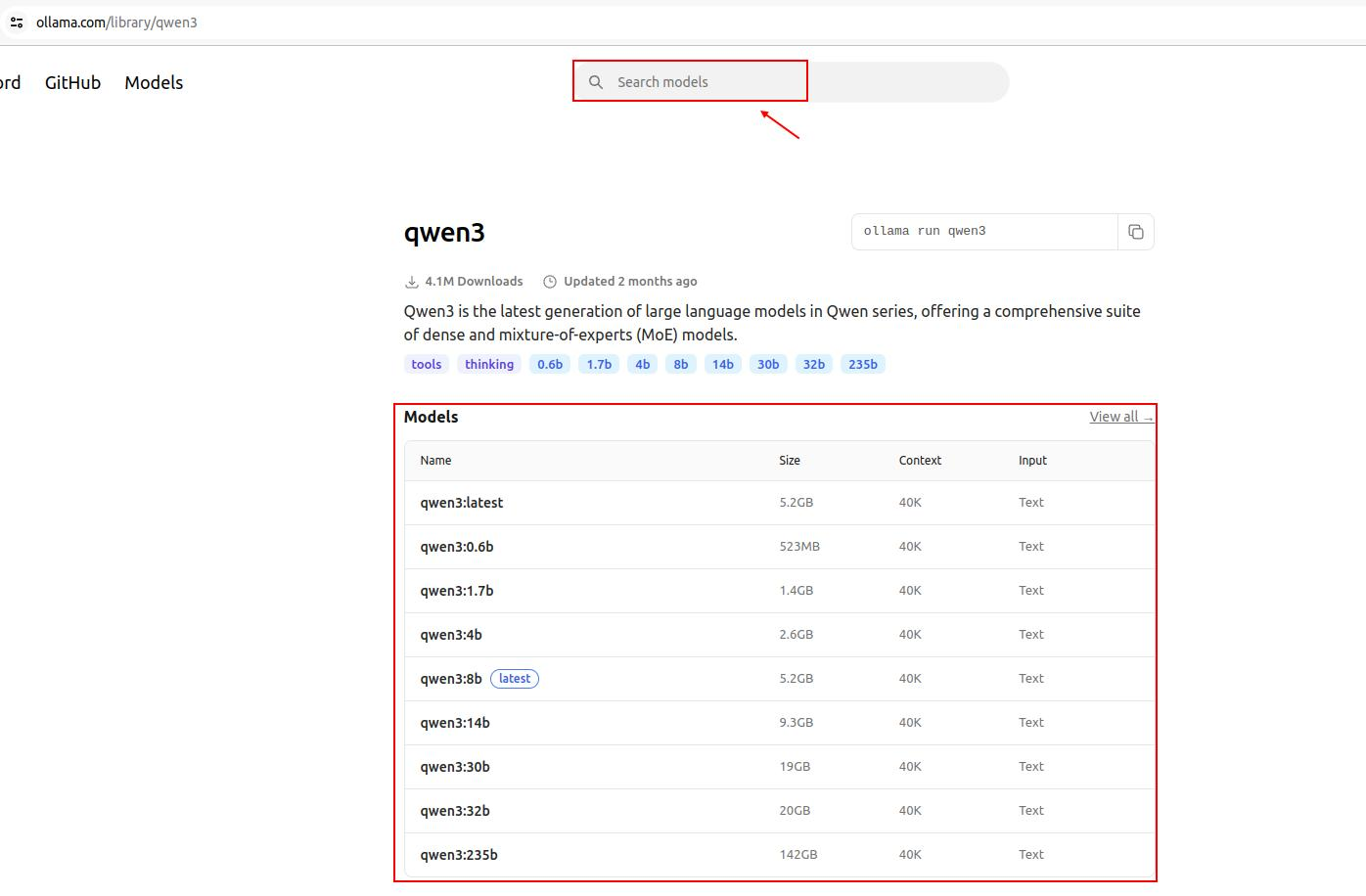
点击需要安装的模型,获取对应的指令下载安装。
2. 进入容器
docker exec -it ollama bash3. 下载安装模型
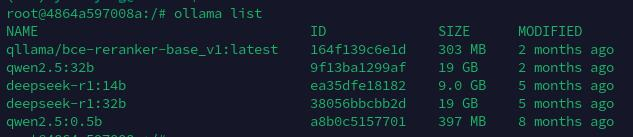
查看已安装的模型列表:
ollama list
会列出我们所有安装的模型
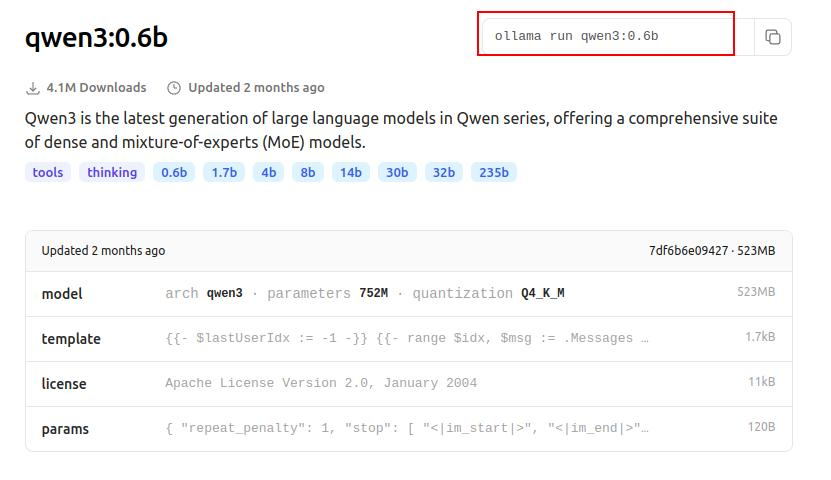
通过下述命令安装指定模型,如安装Qwen3-0.6B的模型
ollama run qwen3:0.6b
和大模型进行对话

如果要查看大模型推理的性能指标,可执行下述命令:
ollama run qwen3:14b --verbose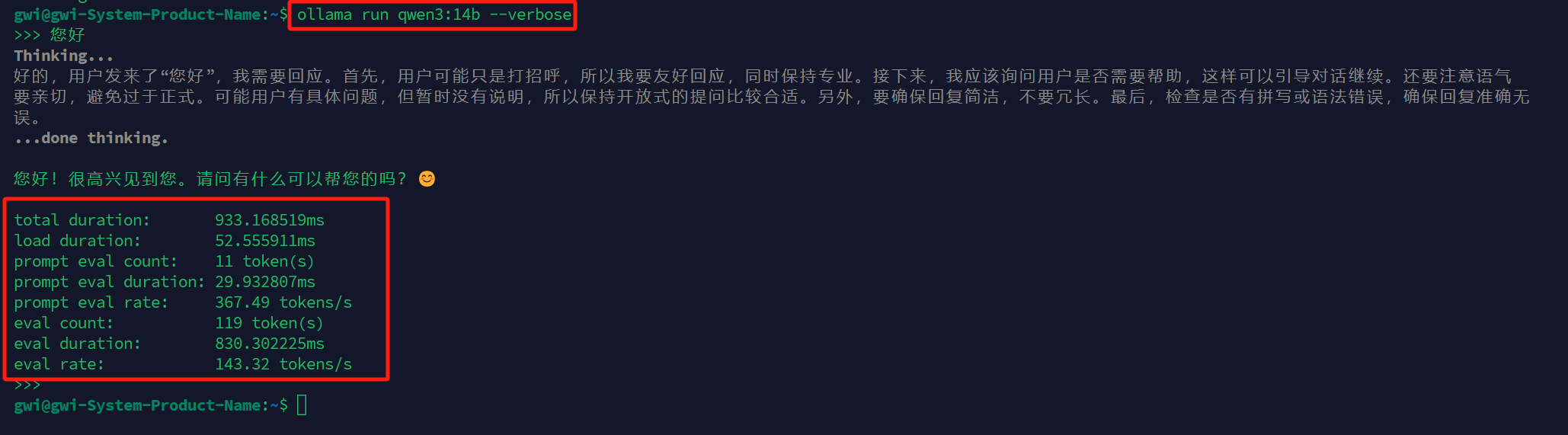
指标详解:
1. total duration: 933.168519ms
含义:整个推理过程的总耗时
计算方式:
load duration + prompt eval duration + eval duration示例值:933ms ≈ 0.93秒
解读:从发出请求到收到完整响应的总时间
2. load duration: 52.555911ms
含义:模型加载到内存的耗时(如果模型已缓存,则时间很短)
包括:
从磁盘读取模型文件
初始化模型参数
分配GPU/CPU内存
示例值:52.6ms
提示:如果这个值很大(>1秒),可能是首次加载或缓存问题
3. prompt eval count: 11 token(s)
含义:输入的提示文本被处理成的token数量
示例值:11个tokens
解读:你的输入大约相当于11个token(中英文转换率不同)
4. prompt eval duration: 29.932807ms
含义:处理输入提示的耗时
计算方式:模型对prompt进行前向传播计算的时间
示例值:29.9ms
解读:将你的问题编码为模型内部表示的时间
5. prompt eval rate: 367.49 tokens/s
含义:处理prompt的速度
计算公式:
prompt eval count / (prompt eval duration / 1000)示例计算:
11 / (29.932807 / 1000) ≈ 367.49解读:处理输入的速度,通常比生成速度快
6. eval count: 119 token(s)
含义:模型生成的token数量
示例值:119个tokens
解读:模型的回答相当于119个token
7. eval duration: 830.302225ms
含义:生成回答的耗时
计算方式:逐个生成每个token的累积时间
示例值:830.3ms
解读:实际生成文本内容的时间
8. eval rate: 143.32 tokens/s
含义:文本生成速度
计算公式:
eval count / (eval duration / 1000)示例计算:
119 / (830.302225 / 1000) ≈ 143.32解读:每秒钟生成的token数量
4. 移除大模型
ollama rm qwen3:0.6b5. 错误排查
如果出现下述错误:
Error: pull model manifest: Get "https://registry.ollama.ai/v2/library/qwen2.5/manifests/14b": dial tcp: lookup registry.ollama.ai on 192.168.1.1:53: read udp 172.17.0.2:35738->192.168.1.1:53: i/o timeout

解决方法:
启动容器时添加 -–network host 参数。
三、模型路径
在容器内,Linux中 ollama 安装的模型存放的默认路径一般为 /root/.ollama 路径下面,具体路径一般为:/root/.ollama/models/manifests/registry.ollama.ai/library
同时在启动容器的时候我们会将容器内部模型存放路径映射到我们本地,如果忘记本地的映射路径了,可以通过下述命令查看:
# 查看ollama容器的挂载信息
docker inspect ollama在输出结果中,查找 "Mounts" 字段,例如:
"Mounts": [
{
"Type": "volume",
"Name": "ollama-data",
"Source": "/var/lib/docker/volumes/ollama-data/_data",
"Destination": "/root/.ollama",
...
}
]
可以看到:
-
容器内的
/root/.ollama挂载到了宿主机的路径/var/lib/docker/volumes/ollama-data/_data
四、API调用
参考文档
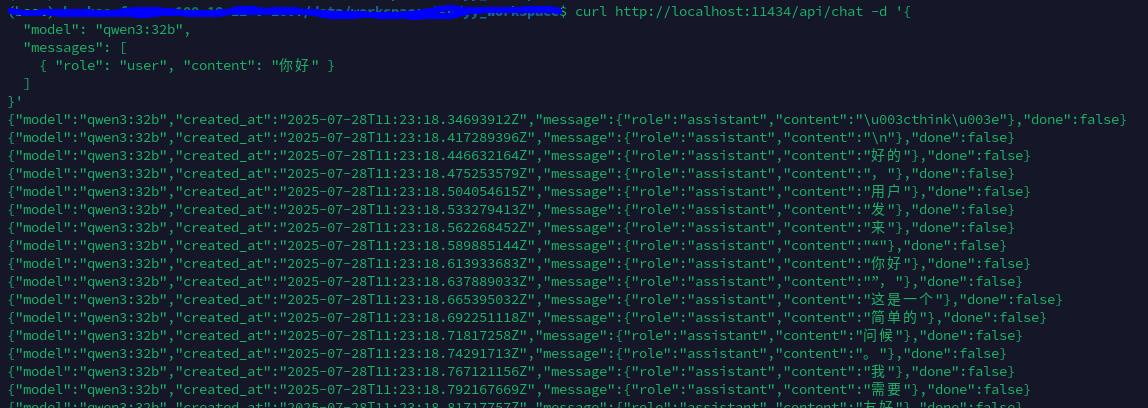
如与模型聊天
curl http://localhost:11434/api/chat -d '{
"model": "qwen3:32b",
"messages": [
{ "role": "user", "content": "你好" }
]
}'

免费领 100 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐
 35
35 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)