
【LLM推理】Sglang推理框架使用入门
Sglang启动推理服务(1)安装:`pip install "sglang[all]>=0.4.6.post1"`,截止20250705能用(2)下面是一个基础的启动推理服务的例子,相关重要的参数有:- 该推理服务可以作为实现OpenAI API协议的服务器进行部署。默认情况下,它将在 http://localhost:30000 启动服务器。您可以通过 --host 和 --port 参数来自
note
- 高效的前缀匹配(efficient prefix matching): 当新的输入到来时,RadixAttention 可以快速地识别出与现有缓存前缀的匹配部分,避免重复计算。这对于像多轮对话、批量推理中共享相同开头的部分,以及在生成过程中回溯(例如在 Beam Search 中)的场景至关重要。
- 在开启dp attention下,且Attention层与MoE层之间进行allgather或allreduce通信时,SGLang会对每个dp rank的batchsize进行padding.在之前的版本,batch padding通常采用sum方式,会造成两种问题:(1) batch padding到较大的值,造成较多计算浪费(2) 判断是否能用cuda graph时,因为sum padding导致无法用cuda graph,降低性能
- 在SGLang v0.4.10之后,pr8820[5] 对dp attention下的local batch padding进行了修改,现有逻辑在开启cuda graph后,默认采用max padding, 否则会根据通信量采用sum或者max padding.此外,如果采用max padding,MoE层的输入张量大小较高,这也是pr作者提到的,在后续需要继续完善的地方。
一、Sglang推理框架介绍
相关更新进度:
2023年12月-2024年2月:奠定基础
2024年7月:Llama3 性能领先
2024年9月:v0.3 版本发布,多项突破
2024年12月:v0.4 版本发布,更极致的效率
2025年1月:DeepSeek V3/R1 Day-One 支持
2025年5月:DeepSeek V3/R1 专家并行与预填充-解码分离
技术特点:
- RadixAttention:通过共享前缀请求和高效缓存策略,SGLang能在理论上实现十万级token/s的超高吞吐量,同时显著降低响应延迟;
- 分布式调度:支持跨节点自动负载均衡;
- 高效结构化输出:内置高性能JSON解析模块,便于构建面向结构化数据查询的API服务,适合复杂自动化工作流;
- 轻量模块化架构:采用灵活的模块化设计,便于快速集成新技术(如FlashInfer内核),不断优化推理效率;
- 混合精度计算:FP16与FP32智能切换
RadixAttention 的核心能力在于实现高效的前缀匹配、插入和逐出。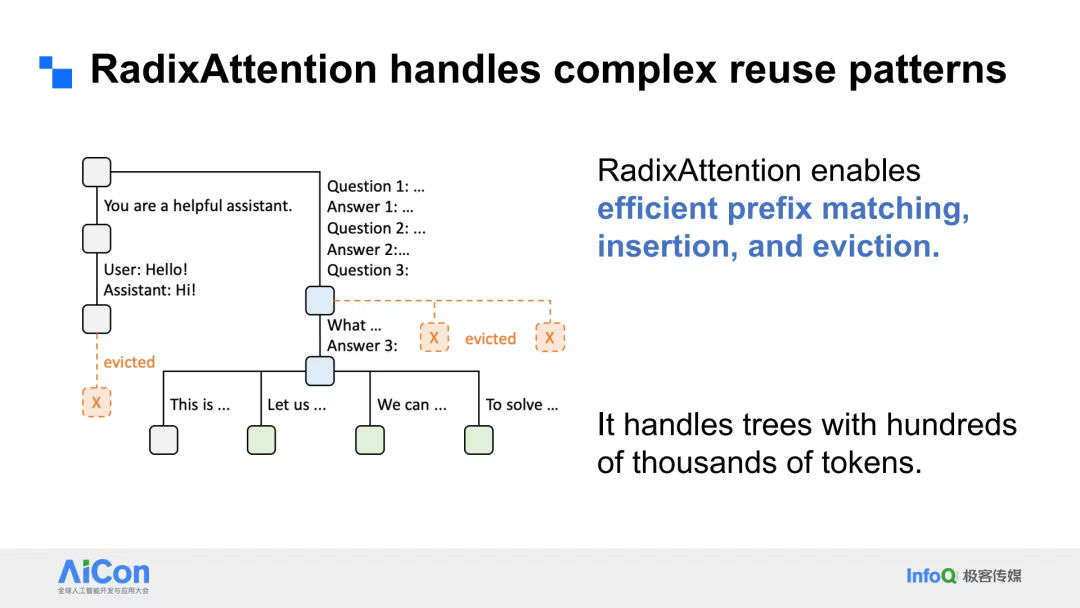
sglang也是ucb的团队,但是跟vllm是不同的一拨人,核心团队不到10人。有借鉴了一款叫做lightllm的推理引擎,也import很多vllm代码,后续会完全去掉对vllm的依赖。其优势在于:
第一,sglang的性能是目前最优的(在2024年)。这里说的性能主要是吞吐。sglang通过多进程zmp传输中间数据来cover掉cpu的开销,高负载下gpu利用率可以到80%以上。还有一些美中不足的就是,实现prompt cache的逻辑也被放在了forward()主进程里,不然的话GPU利用率应该可以跟lmdeploy一样保持在95%左右。我看最近好像也已经在优化这部分了,到时候吞吐还能提10%。除此之外,sglang在推理的各个环节都有做各种细致的工程优化。
第二,sglang的代码可拓展性很高,主流功能都有支持的情况下,代码比vllm清晰简单很多,这对于二次开发来说是很重要的。
第三,sglang的社区活跃度虽然比不上vllm,但是作者都很积极地回复issue。而且现在开发节奏基本上是一周一个版本,有些功能还不太完善的地方下一个版本基本马上就更新了。
二、Sglang启动推理服务
(1)安装:pip install "sglang[all]>=0.4.6.post1",截止20250705能用
(2)下面是一个基础的启动推理服务的例子,相关重要的参数有:
- 该推理服务可以作为实现OpenAI API协议的服务器进行部署。默认情况下,它将在 http://localhost:30000 启动服务器。您可以通过 --host 和 --port 参数来自定义地址。
tensor-parallel-size:使用张量并行的分布式推理,下面设置为4就是在4块GPU上使用张量并行reasoning-parser:设置为qwen3时,调用推理服务得到的有content和reasoning_content字段tool-call-parser:SGLang 支持将模型生成的工具调用内容解析为结构化消息,具体可以参考:https://qwen.readthedocs.io/zh-cn/latest/framework/function_call.htmlmem-fraction-static:控制每个 GPU 的显存预分配比例,默认值为 0.9,适当调整此值可以平衡显存占用和推理性能api-key:可选host:运行推理服务的主机地址port:运行推理服务端口号context-length:模型能够处理的最长上下文json-model-override-args:以 JSON 格式覆盖模型的参数,用于动态调整模型的某些配置,这里可以设置rope_type为yarn(rope的缩放技术,实现模型外推)- Qwen3 模型在预训练中的上下文长度最长为 32,768 个 token,如果场景是需要最大长度为65,536 个 token,则最好将 factor 设置为 2.0。
- 如果模型输入不是很长,这个参数可以不设置
model_path="/root/xx"
model_name="qw3_test_model"
PYTORCH_NVML_BASED_CUDA_CHECK=1 \
CUDA_VISIBLE_DEVICES=3,1,0,2 \
TRANSFORMERS_OFFLINE=1 \
HF_DATASETS_OFFLINE=1 \
python -m sglang.launch_server \
--model-path $model_path \
--trust-remote-code --served-model-name $model_name \
--tensor-parallel-size 4 \
--mem-fraction-static 0.90 \
--api-key sk-123456 \
--host 0.0.0.0 --port 8000 \
--tool-call-parser qwen25 \
--reasoning-parser qwen3 \
--context-length 131072 \
--json-model-override-args '{"rope_scaling":{"rope_type":"yarn","factor":4.0,"original_max_position_embeddings":32768}}'
启动推理服务后的python请求代码如下,注意:
enable_thinking并非OpenAI API定义的参数,具体传入方式可能因推理框架不同而不同presence_penalty参数可以控制模型生成文本时的内容重复度,取值范围为[-2.0, 2.0]:- 高值(如 1.5 或 2.0):适用于需要多样性和创造性的场景,例如创意写作、头脑风暴或复杂问题解答。
- 低值(如 0.0 或 -2.0):适用于需要一致性和专业术语的场景,例如技术文档
- qwen3官方文档推荐:对于量化模型,建议将
presence_penalty设置为 1.5
from openai import OpenAI
# Set OpenAI's API key and API base to use SGLang's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:30000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
chat_response = client.chat.completions.create(
model="Qwen/Qwen3-8B",
messages=[
{"role": "user", "content": "Give me a short introduction to large language models."},
],
max_tokens=32768,
temperature=0.6,
top_p=0.95,
extra_body={
"top_k": 20,
},
)
print("Chat response:", chat_response)
- 要完全禁用思考,可以在启动模型时使用自定义聊天模板:
python -m sglang.launch_server --model-path Qwen/Qwen3-8B --chat-template ./qwen3_nonthinking.jinja,该聊天模板会阻止模型生成思考内容,即使用户通过 /think 指示模型这样做
# qwen3最初的模版结尾:
{%- if add_generation_prompt %}
{{- '<|im_start|>assistant\n' }}
{%- if enable_thinking is defined and enable_thinking is false %}
{{- '<think>\n\n</think>\n\n' }}
{%- endif %}
{%- endif %}
# qwen3_nonthinking.jinja模板结尾
{%- if add_generation_prompt %}
{{- '<|im_start|>assistant\n<think>\n\n</think>\n\n' }}
{%- endif %}
Reference
[1] sglang官方文档: https://docs.sglang.ai/backend/quantization.html#examples-of-offline-model-quantization
[2] https://github.com/sgl-project/sglang
[3] Qwen3如何实现快慢混合思考、可启动关闭
[4] 行业落地分享:SGLang高效开源的 LLM 服务框架
[5] 使用SGLang部署Qwen3大模型的完整指南
[6] 梳理SGLang中DP Attention及其Padding问题

免费领 100 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐
 14
14 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)