
《从 0 实现 SGLang》第 3 篇 · Qwen3 模型架构定义
这篇文章详细介绍了如何从零开始构建Qwen3-0.6B大语言模型的推理引擎。主要内容包括: 模型整体架构:由embedding层、28层decoder、RMSNorm层和lm_head组成 核心模块详解: Embedding层实现token到向量的转换 RMSNorm层用于稳定训练和推理 每层decoder包含自注意力机制和MLP两部分 关键技术点: 采用pre-norm残差结构 使用GQA(分组
千行代码,一步步搭出一个现代 LLM 推理引擎,掌握大模型推理的每一项关键技术。
本篇你将学到
- Qwen3-0.6B 的完整结构: embed + 28 层 decoder + final RMSNorm + lm_head;
- 一层 decoder 内部 9 个子模块逐个拆讲: Embedding / RMSNorm / RoPE / QKV linear / QK-Norm / GQA / SDPA + 因果 mask / o_proj / GatedMLP;
- 每个子模块的"是什么 / 为什么需要 / 解决什么问题 / 怎么解决"四问;
- 从 HuggingFace safetensors 直接加载 Qwen3-0.6B 真实权重并跑通一次前向 trace。
1. 上一篇接到哪、本篇要干什么
第 2 篇用 Req 把一条推理请求装进了一个对象, 但 Req 里只有 input_ids 和长度字段——没有任何代码能把 input_ids 变成 logits、再变成 next token。
本篇就来搭这个模型: 从零写出 Qwen3-0.6B 的全部架构 (~120 行 Python), 加载真实权重让它能跑通一次真实的前向计算。本篇不讲 prompt 怎么进、next token 怎么生成——那些 prefill 与 decode 的具体路径留给下一篇。
2. Qwen3-0.6B 整体结构
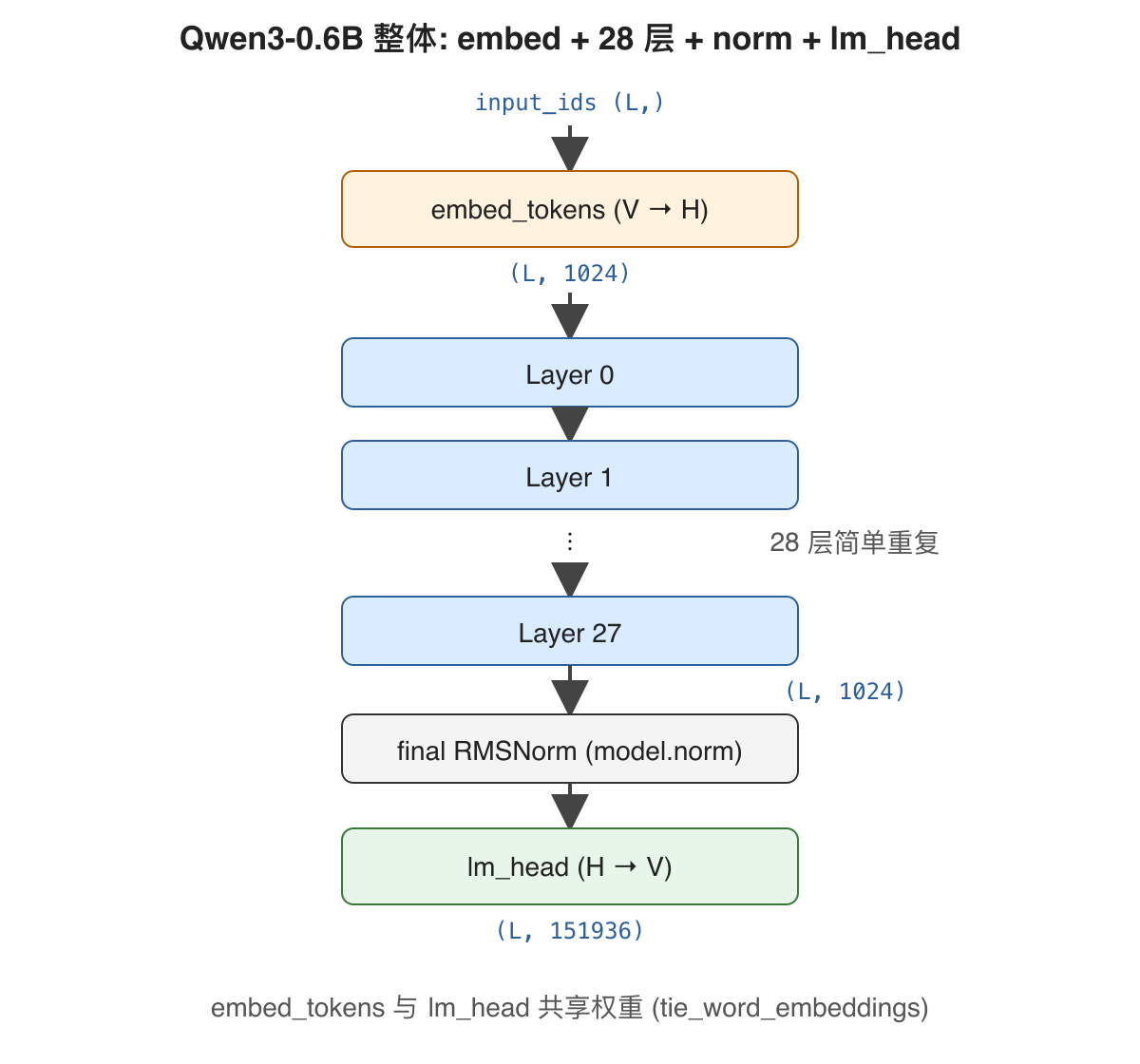
Qwen3ForCausalLM 包了一层 Qwen3Model, Qwen3Model 内部是 embed_tokens + 28 个 Qwen3DecoderLayer + final RMSNorm, 最后接一个 lm_head (Linear(H, V)) 把 hidden 投到 vocab logits。
图里出现的所有维度数字都来自 Qwen3Config:
| 字段 | 值 | 含义 |
|---|---|---|
hidden_size |
1024 | 每个 token 的 hidden 维度 (H) |
intermediate_size |
3072 | MLP 中间层维度 (= 3× hidden, I) |
num_layers |
28 | decoder 层数 |
num_heads |
16 | q (query) 头数 (n_q) |
num_kv_heads |
8 | k/v 头数 (n_kv), GQA: 16 q ↔ 8 kv |
head_dim |
128 | 每个 head 的维度 (d) |
vocab_size |
151936 | token id 范围 (V) |
rms_norm_eps |
1e-6 | RMSNorm 的 ε |
rope_theta |
1000000.0 | RoPE 频率基数 |
max_position_embeddings |
40960 | 最大 prompt + 输出长度 |
tie_word_embeddings |
True | lm_head.weight 与 embed_tokens.weight 共享 |
from __future__ import annotations
from dataclasses import dataclass
import torch
import torch.nn as nn
import torch.nn.functional as F
@dataclass
class Qwen3Config:
"""Qwen3-0.6B 的真实超参 (与 HF config.json 对齐)."""
hidden_size: int = 1024
intermediate_size: int = 3072
num_layers: int = 28
num_heads: int = 16 # n_q
num_kv_heads: int = 8 # n_kv (GQA 2:1)
head_dim: int = 128
vocab_size: int = 151936
rms_norm_eps: float = 1e-6
rope_theta: float = 1000000.0
max_position_embeddings: int = 40960
tie_word_embeddings: bool = True
3. Embedding: token id → hidden

是什么: nn.Embedding(V, H) 就是一张 [V=151936, H=1024] 的查表 (lookup table)。每个整数 token id 查到一个 1024 维的向量。
打个比方: 像一本"语义字典"——每个 token id 是页码, 翻到那页就拿到这个词的 1024 维"语义坐标"。
为什么需要: tokenizer 给出的是离散的 token id (整数), 但 attention / MLP 都是矩阵乘法, 需要连续向量。Embedding 就是把"离散身份"变成"模型可以做运算的向量"的第一步。
解决了什么问题: 让 token 这个符号有了"语义坐标"——同义词的 embedding 向量接近, 反义词远。这些坐标是训练时学出来的。
怎么解决: 用一个 (V, H) 的可学习矩阵, 取第 token_id 行。PyTorch 的 nn.Embedding(vocab_size, hidden_size) 一行实现, 内部就是 weight[token_ids]。本篇不实现 Embedding——直接用 nn.Embedding, 在后面 Qwen3Model 类里实例化。
4. 一层 decoder layer 内部
Embedding 之后, hidden 进入 28 层 decoder。每一层结构完全一样, 下面打开其中一层, 看它内部是怎么算的:
一层 decoder 内部就两段"标准残差结构":
x = x + self_attn(input_layernorm(x))
x = x + mlp(post_attention_layernorm(x))
- 第一段 attention:
input_layernorm(RMSNorm) →self_attn(含 7 个子部件) → 加回 x - 第二段 MLP:
post_attention_layernorm(RMSNorm) →mlp(GatedMLP) → 加回 x
注意 pre-norm 模式: norm 在 sub-layer 之前, 残差在 norm 之后加。这与原始 Transformer 的 post-norm 不同, 但对大模型训练更稳定。
下面 第4.1章 ~ 第4.8章 依次拆讲一层 decoder 内部的各个子模块 (按它们在 forward 里出现的顺序)。
4.1 RMSNorm
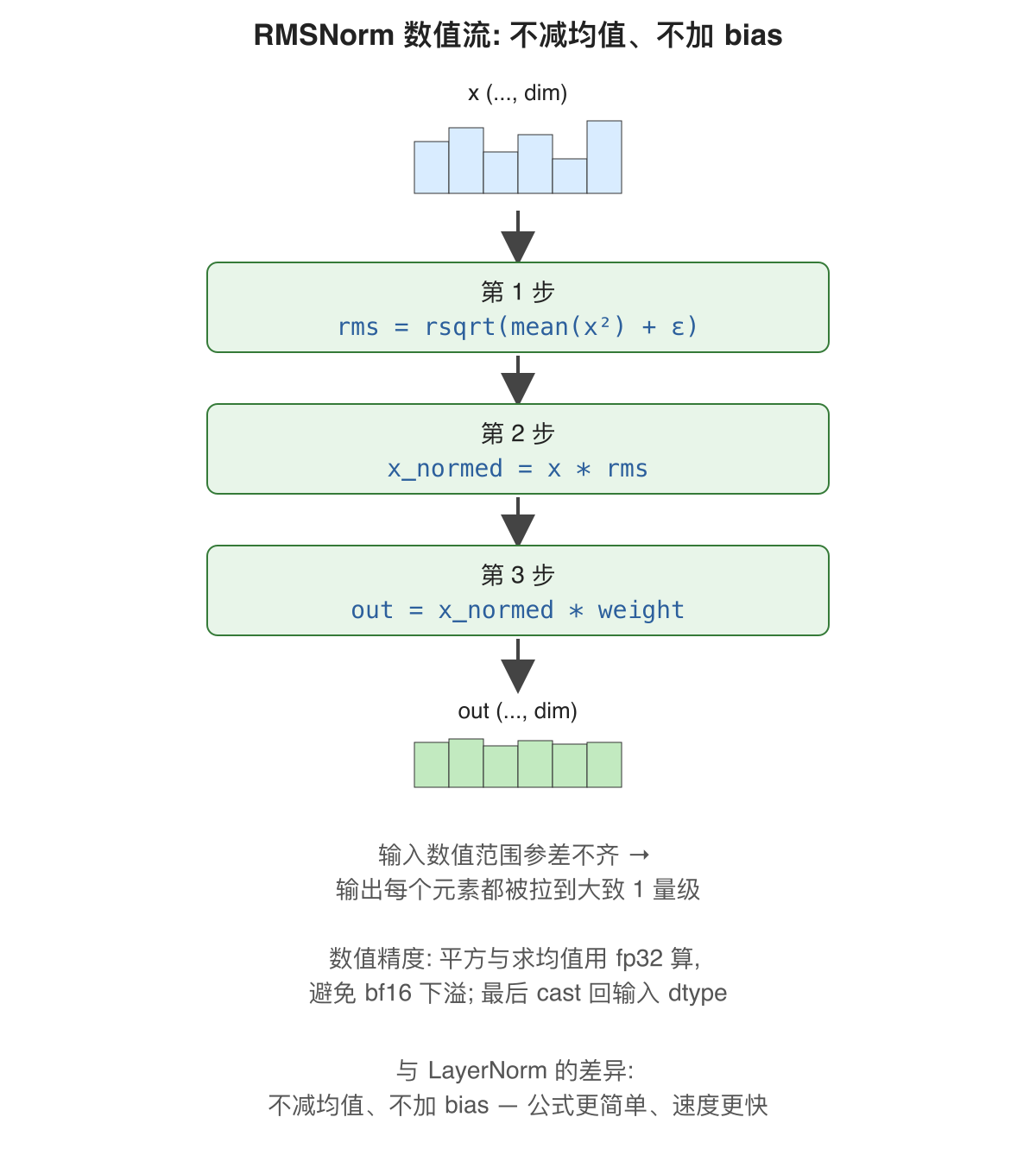
是什么: 一种归一化层。把输入向量沿最后一维 (hidden_size 或 head_dim) 缩放, 让其数值范围稳定在量级 1 附近, 再乘上一个可学习的 weight。与 LayerNorm 的差异: 不减均值, 不加 bias。
打个比方: 像麦克风前的音量自动调节——不论说话人原声多大多小, 输出永远是合适的响度, 后面的处理器 (attention / MLP) 总能收到稳定信号。
为什么需要: 残差网络 (Transformer 的标准结构) 每一层都把 attention/MLP 的输出加到 hidden 上, 若某一层激活幅度漂移, 后续层会放大这种漂移, 最终梯度爆/消、训练发散。
解决了什么问题: 让每一层的输入数值范围保持稳定, 训练时梯度不爆不消, 推理时各层的输入分布与训练时一致 (numerical stability)。
怎么解决: 公式 out = x * rsqrt(mean(x²) + ε) * weight。其中 rsqrt 是 1/sqrt。比 LayerNorm 少一个均值计算, 速度更快。Qwen3 在三处用 RMSNorm: 每层的 input_layernorm / post_attention_layernorm / 模型末尾的 model.norm, 加上 QK-Norm 里的 q_norm / k_norm (在 第4.3章 讲)。
实现要点: 平方和均值用 fp32 算, 最后再 cast 回输入 dtype——bf16 算平方容易下溢。
class RMSNorm(nn.Module):
"""Root Mean Square LayerNorm: x * (1/sqrt(mean(x^2)+eps)) * weight.
与 LayerNorm 的差异: 不减均值, 不加 bias. 用 fp32 算方差以保证数值稳定.
"""
def __init__(self, dim: int, eps: float = 1e-6):
super().__init__()
self.weight = nn.Parameter(torch.ones(dim))
self.eps = eps
def forward(self, x: torch.Tensor) -> torch.Tensor:
# x: (..., dim) — 任意 leading dims
in_dtype = x.dtype
x_f32 = x.float()
rms = x_f32.pow(2).mean(-1, keepdim=True).add(self.eps).rsqrt()
return (x_f32 * rms).to(in_dtype) * self.weight
4.2 QKV 线性投影
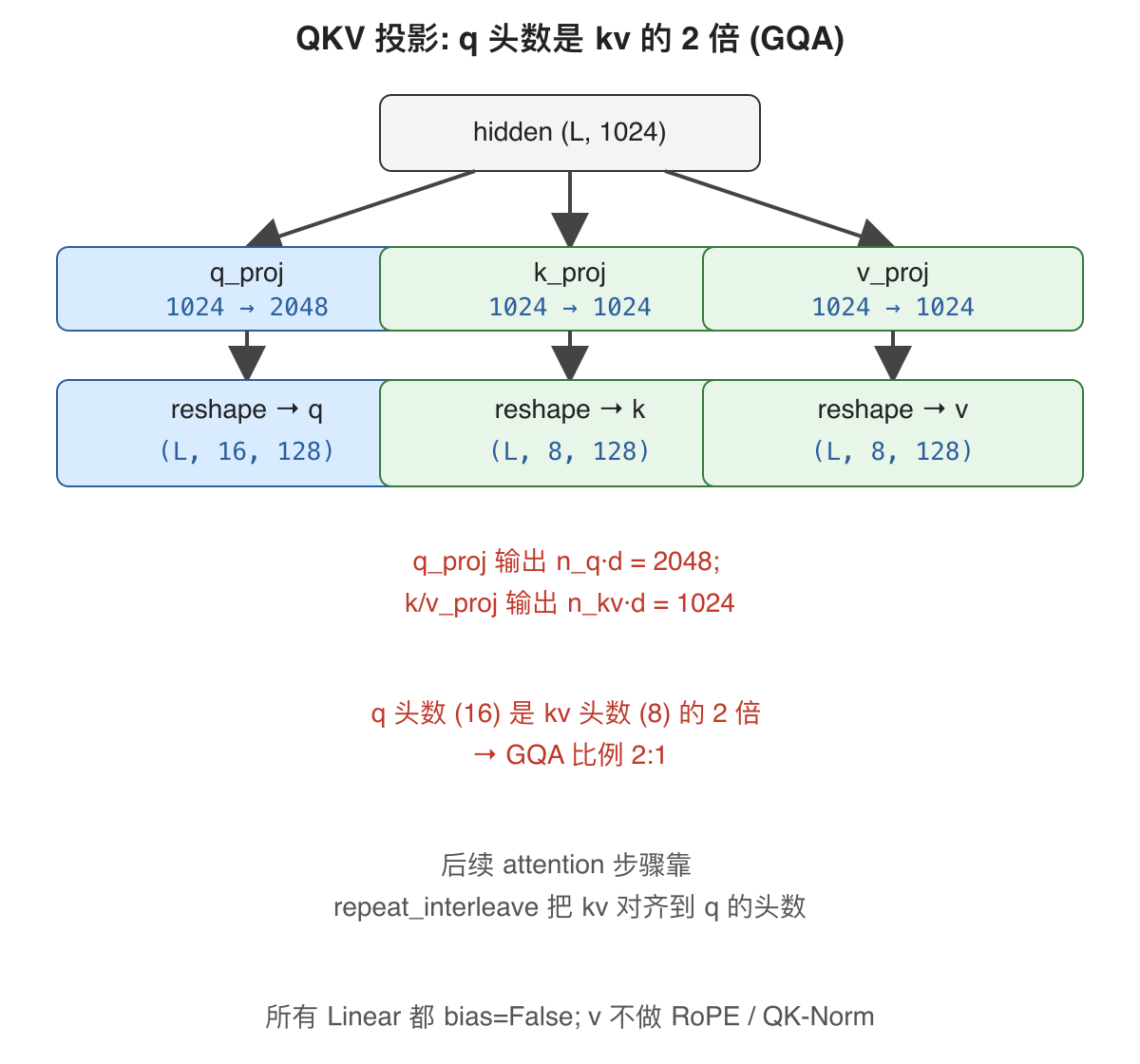
是什么: 把 attention 的输入 hidden (L, 1024) 投影成三组张量: query (q) / key (k) / value (v)。
打个比方: 像把同一句话同时翻译成三个版本——q 是"我要问什么", k 是"我能回答什么类型的问题", v 是"我手头的实际内容"。
为什么需要: attention 是"q 去查 k、找到匹配再取对应 v"的机制。q、k、v 必须是同一份 hidden 的三个不同投影——直接用 hidden 自己, attention 学不出有意义的东西。
解决了什么问题: 给 attention 提供"问/答/内容"三种角色不同的向量。三组各自独立学习, 解耦"用什么找"(q)、“被什么找”(k)、“找到了拿什么”(v)。
怎么解决: 三个 nn.Linear(1024, ...)。注意 Qwen3 是 GQA, q 与 kv 的头数不同, 三个 Linear 的输出维度不一样:
q_proj:2048 → n_q × head_dim = 16 × 128 = 2048k_proj:1024 → n_kv × head_dim = 8 × 128 = 1024v_proj:1024 → n_kv × head_dim = 8 × 128 = 1024
三个 Linear 都 bias=False。投影后用 .view(L, n_heads, head_dim) reshape 出 head 维, 进入后续的 QK-Norm / RoPE / GQA。
4.3 QK-Norm (Qwen3 的差异点)
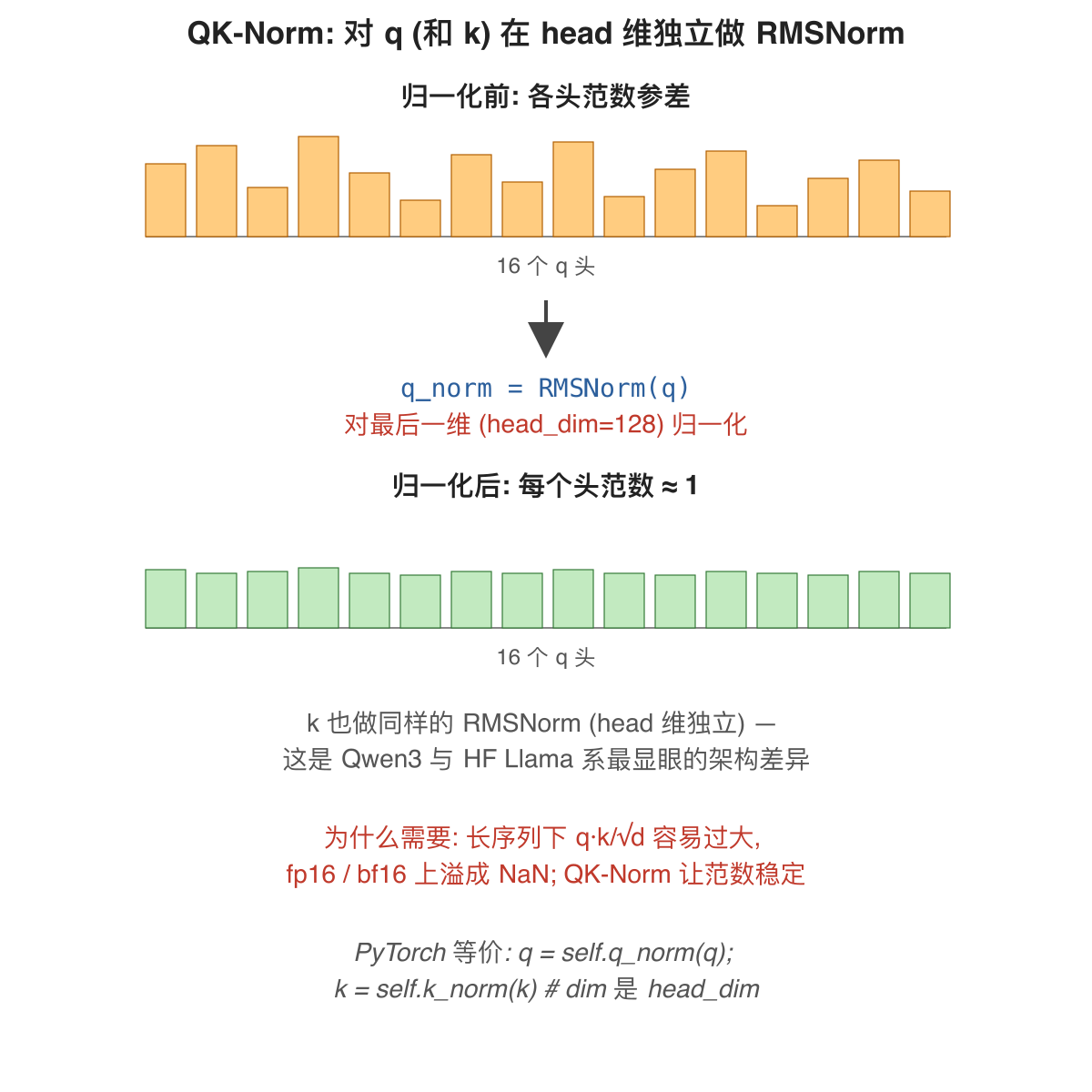
是什么: 在 RoPE 之前, 对 q 和 k 各做一次 RMSNorm, 归一化维度是 head_dim=128 (每个 head 内独立归一化)。
打个比方: 像考试前给所有选手统一发标准笔——不允许有人自带超长大笔垄断答题区, q 与 k 配对打分 (q·k) 才公平。
什么是范数 (norm): 一个向量的"整体长度", 最常用的是 L2 范数 ‖x‖ = √(x₁² + x₂² + ... + xₙ²)——所有分量平方和开根号, 二维向量 [3, 4] 的范数就是勾股定理算出的 5。q·k 的大小直接随 q、k 的范数变大 (向量越"长", 内积越大), 所以控住范数就能控住 q·k——这正是 RMSNorm 在做的事 (q·k 与 RMSNorm 的关系详见 第4.1章)。
为什么需要: 长序列下, attention logits q·k/√d 的范围与 q、k 的范数成正比; 范数不稳定时 logits 数值过大, fp16 / bf16 上溢成 NaN。
解决了什么问题: 让每个 head 内 q、k 的向量范数始终保持在 1 附近, 之后 q·k 的量级与位置长度解耦, attention 在长序列上稳定。
怎么解决: 两个 RMSNorm(head_dim) 实例 (q_norm / k_norm), 直接套到 reshape 后的 q、k 上。注意 RMSNorm 的 dim 参数是 128 (head_dim) 而不是 1024 (hidden_size)——这意味着每个 head 内的 128 维元素一起归一化, 不同 head 之间互不影响。
HF Llama 系没有这一步; Qwen3 引入它以提升训练稳定性。这也是后续加载权重时会看到 self_attn.q_norm.weight / self_attn.k_norm.weight 的原因。
4.4 RoPE (Rotary Position Embedding)
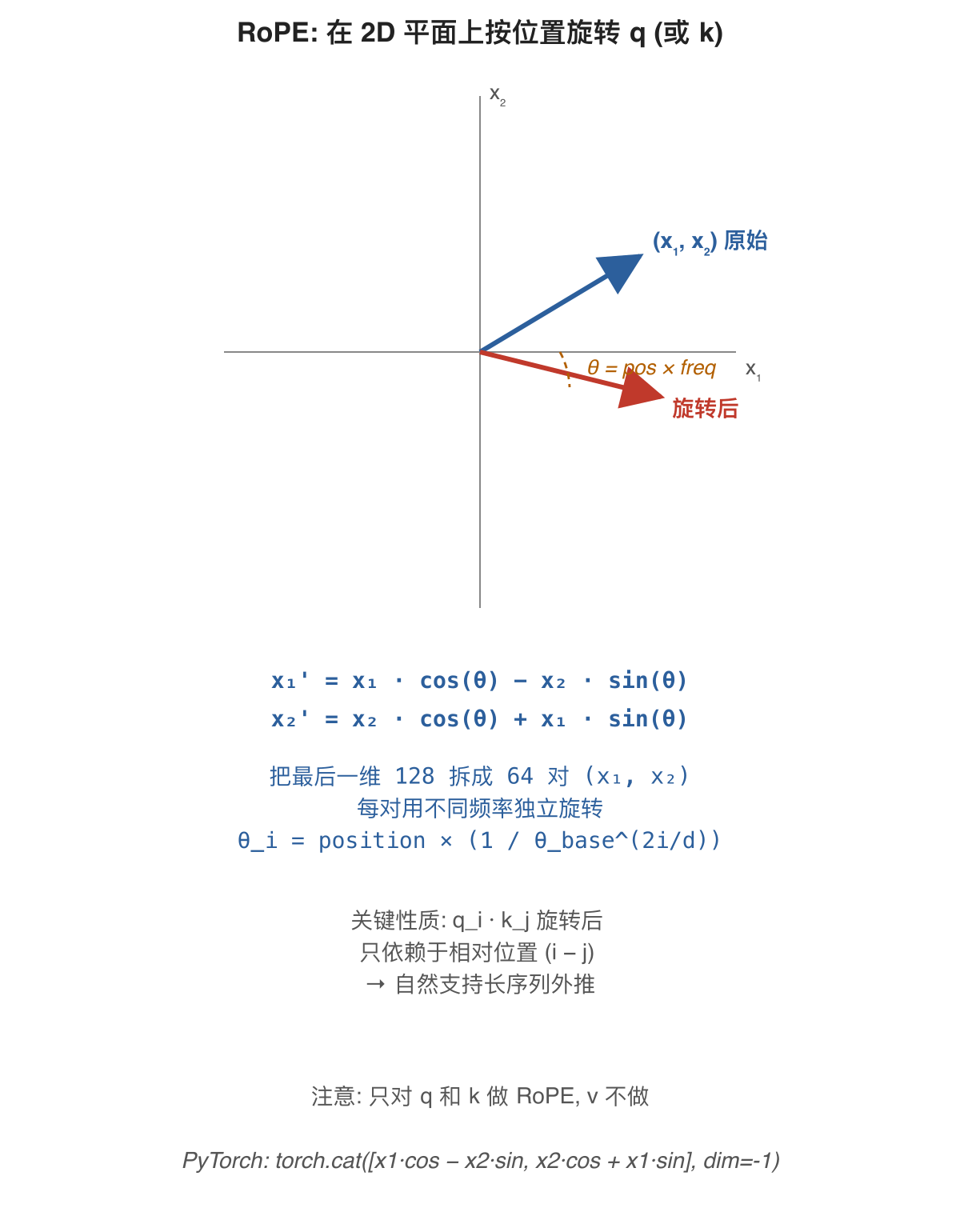
是什么: 一种把位置信息注入到 q、k 向量的方法。把每个 head 的 128 维拆成 64 对 (x₁, x₂), 每对在 2D 平面上"按位置旋转一个角度"。
打个比方: 像给每个 token 戴一顶刻着时钟刻度的帽子, 帽子的角度由位置决定。两个 token 配对时 (q·k), 角度差自然告诉模型"它们相隔多远"。
为什么需要: Transformer 的 attention 公式 softmax(q·k/√d) · v 本身对 token 的位置无感——位置 0 的 token 和位置 100 的 token 调换, 结果不变。必须显式注入位置信息, 否则 “the cat sat” 与 “sat cat the” 的输出会一样。
解决了什么问题: 早期方法 (BERT 的 absolute position embedding) 是把"位置向量"加到 embedding 上, 长度外推差 (训练时见过的最长是 512, 推理超过训练长度后效果显著下降)。RoPE 让 q_i·k_j 这一项的结果只依赖于相对位置 i − j (有理论证明), 自然支持长序列外推; Qwen3-0.6B 的 max_position_embeddings 是 40960, 远超训练长度。
怎么解决: 用 cos(pos × freq) 和 sin(pos × freq) 表预算好, 在每层 attention 之前对 q 和 k 各做一次旋转 (apply_rope(q, cos, sin))。注意只对 q 和 k 做, v 不做。
用时钟类比理解: RoPE 给每个 token 戴一只 “64 指针时钟”, 64 根指针转速不同——第 1 根像秒针 (转最快), 第 64 根像 “千年针” (慢到几乎不动). token 位置决定了它这只钟在哪个时刻, 64 根指针的角度组合就是它唯一的 “位置 fingerprint”.
attention 算 token A 与 token B 的相关性 (q_A·k_B 中 RoPE 部分), 等价于比对两只钟的所有指针, 每对指针贡献一个"相似度分数"——角度差 0° → 满分 1, 90° → 0, 180° → -1, 64 对加起来就是 attention 分数.
公式: RoPE 把 head_dim=128 拆成 64 对 (x₁, x₂), 每对配一个频率
freq_i = 1 / θ^(2i/d) i = 0..63 (θ = 10⁶, d = 128)
- i=0 (秒针 / 高频): 每跨 1 个位置转 ~1 rad ≈ 57°
- i=63 (千年针 / 低频): 每跨 1 个位置转 ~10⁻⁶ rad (几乎不动)
举个例子: 同一个 token A 出现在 pos=1 与 pos=1000, 都对 pos=1001 的 token B 算 attention.
| 指针 | A 在 pos=1000 (Δ=1, 近 B) | A 在 pos=1 (Δ=1000, 远 B) |
|---|---|---|
| 秒针 (高频) | 只转 57°, 两钟秒针位置接近 → 相似度分数较高 | 转了 159 整圈, 像被随机扔回表盘某处 — 与 B 的秒针对不对得上全凭运气, 相似度时正时负, 平均 ≈ 0 |
| 千年针 (低频) | 几乎没动 → 两钟千年针完全对齐 → 相似度 = 满分 1 | 只转 0.08° → 依然几乎对齐 → 相似度 ≈ 满分 1 |
| 64 根累加 | 大部分指针都对齐 → 总分 ≈ 原始语义内积 (高) | 高频指针相似度抵消为 0, 只有低频指针保持满分 → 总分被稀释 (低) |
→ A 离 B 越近, attention 分数越高; 越远, 越多高频指针进入"随机绕圈"状态拖低总分. 这就是 RoPE 的"远项衰减".
(还有个间接因素: 深层 hidden 本身已经不同 — pos=1 的 A 只融过 1 个 token 上下文, pos=1000 的 A 融过 999 个. 但这是 attention 堆叠的副作用, 不算 RoPE 自身机制.)
反直觉点: 秒针转 2π 后回原点, 为什么还能区分位置?
单看秒针, 当前时刻 与 60 秒后 时刻的秒针位置长得一模一样. 但时钟还有 63 根别的指针 — 分针 / 时针 / … / 千年针. 64 根指针转速都不同, 不会在同一个时间差下同时回到原位.
只要两个时刻不是同一个时刻, 64 根的联合读数就一定不同 → 位置 fingerprint 唯一. RoPE 的位置信息 “分摊” 在 64 对的联合状态里, 不靠任何单一频率独自承担.
实现细节: LLaMA / Qwen 用 “rotate-half” 写法——把 d 维拆前后两段 x₁ = x[:d/2], x₂ = x[d/2:], 一次性算出整段, 比 “interleave” (x[0]/x[1], x[2]/x[3], ...) 写法更高效。
def precompute_rope_cache(
head_dim: int,
max_seq_len: int,
theta: float,
device: str | torch.device,
dtype: torch.dtype,
) -> tuple[torch.Tensor, torch.Tensor]:
"""预算每个 position 的 cos/sin 表, 后续 apply_rope 直接索引.
返回 cos, sin 形状均为 (max_seq_len, head_dim/2).
用 fp32 计算 angles 以保证精度, 最后 cast 到目标 dtype.
"""
# 偶数下标的 dim 对应的频率: 1 / theta^(2i/head_dim)
inv_freq = 1.0 / (theta ** (
torch.arange(0, head_dim, 2, device=device, dtype=torch.float32) / head_dim
))
t = torch.arange(max_seq_len, device=device, dtype=torch.float32)
angles = torch.outer(t, inv_freq) # (max_seq_len, head_dim/2)
return angles.cos().to(dtype), angles.sin().to(dtype)
def apply_rope(
x: torch.Tensor, cos: torch.Tensor, sin: torch.Tensor
) -> torch.Tensor:
"""对 q 或 k 施加 rotary position embedding (LLaMA / Qwen 的 rotate-half 风格).
Args:
x: (L, n_heads, head_dim) — q 或 k
cos: (L, head_dim/2)
sin: (L, head_dim/2)
Returns:
(L, n_heads, head_dim) — 形状不变, 注入了位置信息
"""
# rotate_half: 把后半段取负, 与前半段对换
# 即 (a, b) -> (-b, a) where a = x[..., :d/2], b = x[..., d/2:]
half = x.shape[-1] // 2
x1, x2 = x[..., :half], x[..., half:]
# cos/sin 形状 (L, d/2) 需要 broadcast 到 (L, n_heads, d/2)
cos = cos[:, None, :] # (L, 1, d/2)
sin = sin[:, None, :]
return torch.cat(
[x1 * cos - x2 * sin, x2 * cos + x1 * sin], dim=-1
)
4.5 GQA (Grouped Query Attention)

是什么: q 头数 (16) 是 kv 头数 (8) 的 2 倍, 每个 kv head 同时给 2 个相邻的 q head 用。
打个比方: 像办公室里 16 个员工 (q) 共用 8 个文件柜 (kv)——每 2 个员工合用 1 个柜子。少买一半柜子 (省 KV cache 显存), 工作效率影响不大。
为什么需要: KV cache (下一篇引入) 的显存正比于 kv head 数; 大模型上 kv head 数过多会使 KV cache 显存开销不可承受。但 q head 数影响表达力, 不宜直接减少。
解决了什么问题: 在表达力 (q 头多) 与 KV cache 显存 (kv 头少) 之间取平衡。Qwen3 取比例 2:1, 比 MHA (q = kv) 省一半 cache, 比 MQA (kv = 1) 多一些表达力。
怎么解决: 在 attention 计算前, 把 kv 沿 head 维 repeat_interleave(2) 复制一份, 让其 head 数对齐 q 的 16。必须用 repeat_interleave 而不是 repeat: head 0/1 共用 kv head 0, head 2/3 共用 kv head 1, 即 0011 而不是 0101——和 HF 实现一致。
PyTorch 等价: k = k.repeat_interleave(2, dim=1); v = v.repeat_interleave(2, dim=1)。
生产实现会用 flash-attn 的内置 GQA 跳过 repeat (节省显存与算力), 但本篇是教学版的最简实现, 用 repeat_interleave 让代码贴近概念。
4.6 SDPA + 因果 mask
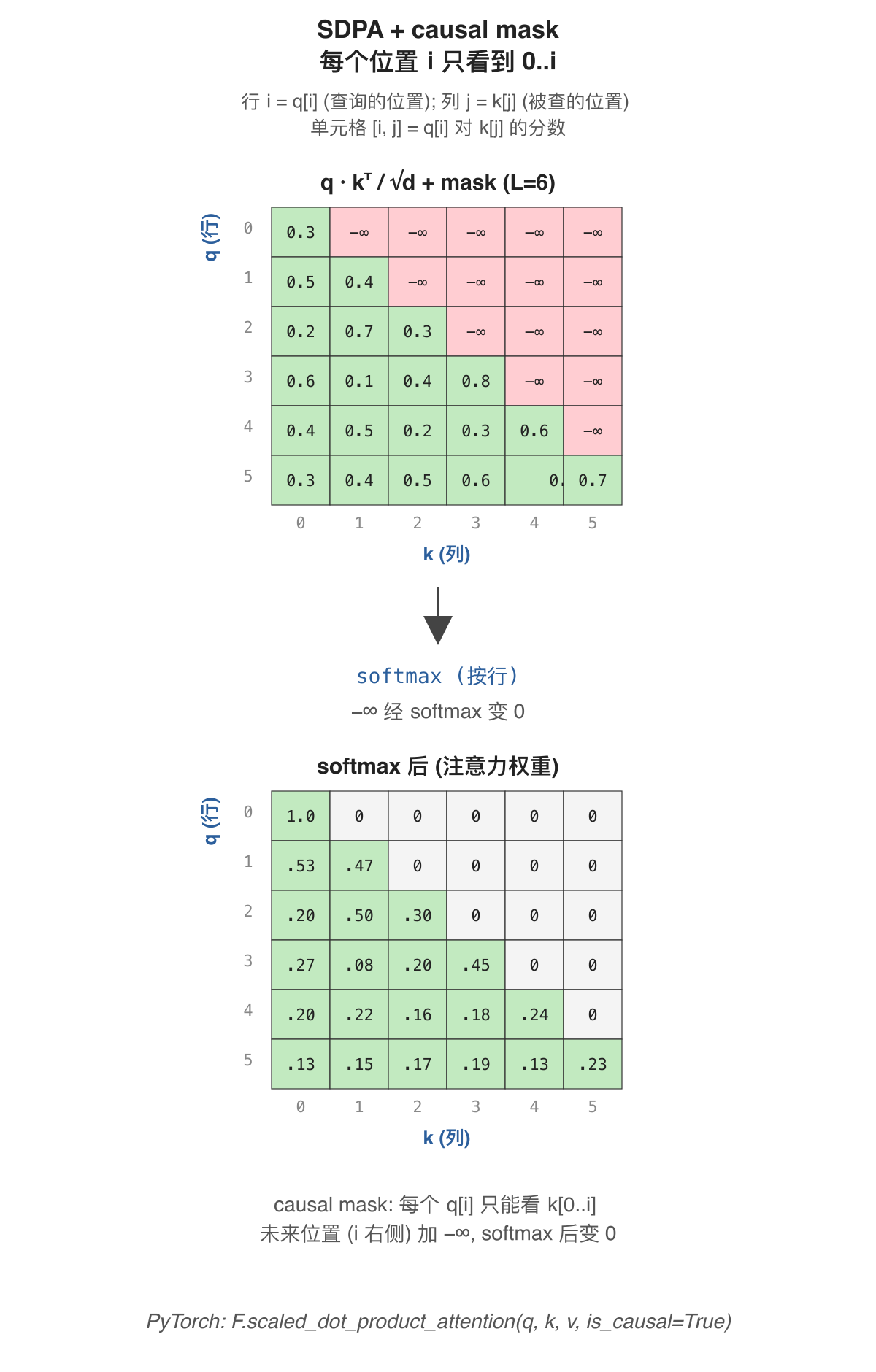
是什么: Scaled Dot-Product Attention 的核心计算: softmax(q·kᵀ / √d) · v, 加上 causal mask 让位置 i 只看到 0…i (不看未来)。
打个比方: 像看一本书时只许往前翻——每个位置只能用之前 (包括自己) 的信息去预测下一个 token, 不许偷瞄后面"作弊"。
为什么需要: causal 模型 (next-token 预测) 训练时, 必须保证位置 i 算 logits 只用 0…i 的 token, 否则就"作弊"了。推理时同样道理: 位置 i 不应该看到 i+1 … L-1 的内容。
解决了什么问题: 让一个公式同时处理"加权融合 token 信息"(attention 本身) 与"严格的因果顺序"(mask)。
怎么解决: 把 q·kᵀ/√d 的上三角加 −∞, softmax 后那些位置变成 0, 实际不参与加权。PyTorch 内置了优化版本: F.scaled_dot_product_attention(q, k, v, is_causal=True)——一行搞定 mask 与 softmax, 还会自动选 Flash Attention / Memory Efficient 实现, 不必手写。
注意 SDPA 入参要求形状是 (..., n_heads, L, head_dim), 所以调用前要把 q / k / v 从 (L, n_heads, head_dim) 转置到 (n_heads, L, head_dim)。算完再转回来。
4.7 o_proj: 把多头合回 hidden
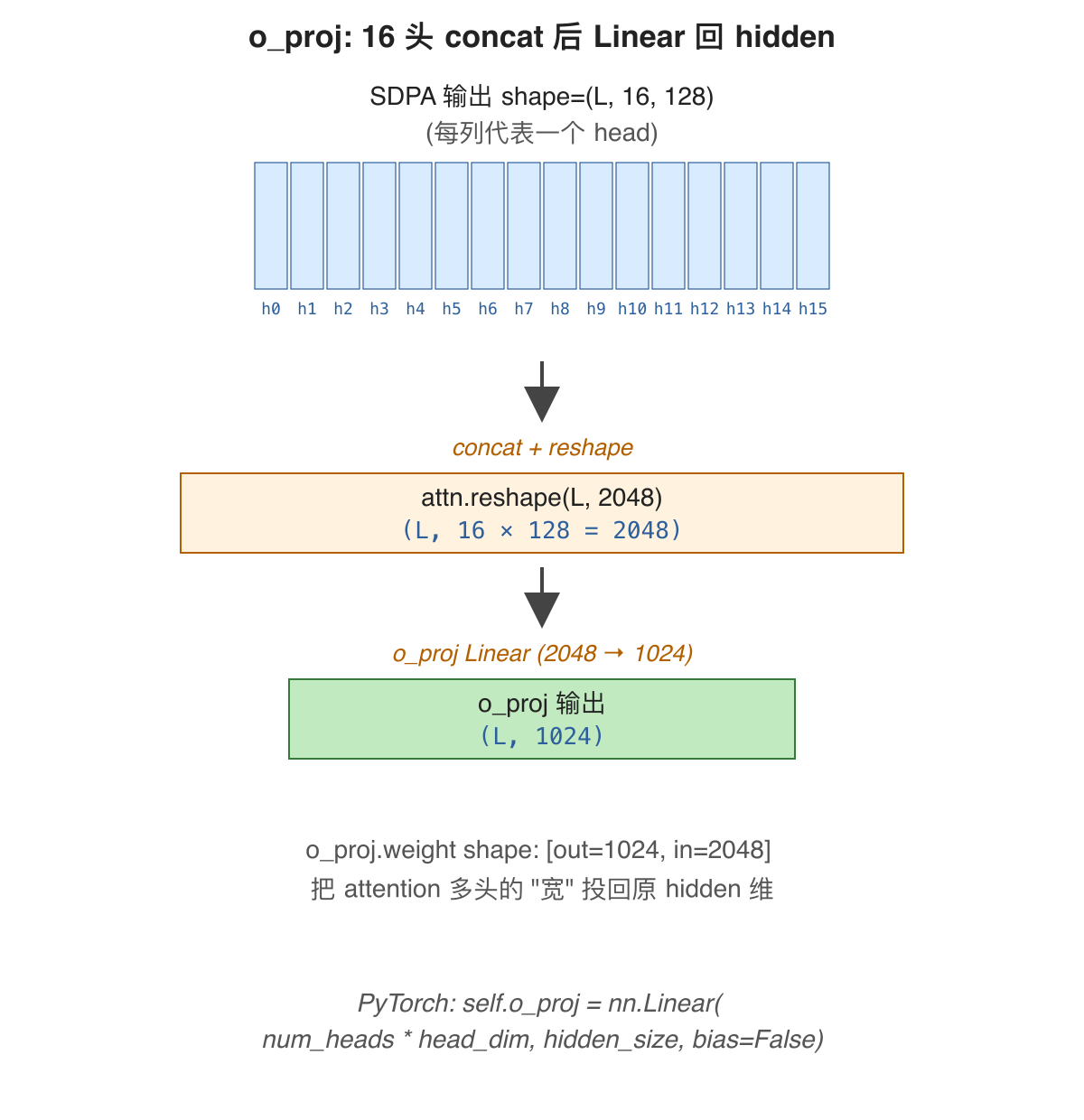
是什么: SDPA 算完得到 (L, n_q=16, head_dim=128) 的 attention 输出, 用 o_proj 把它合并并投回 hidden 维度。
打个比方: 像 16 个调查员各自交上一份 128 字的报告, o_proj 是总编——先把所有报告拼起来 (2048 字), 再压缩成最终 1024 字的汇总稿。
为什么需要: 多头给我们的是 16 份信息, 每份 128 维; 但 layer 的输出要回到 hidden_size=1024 (供残差相加与后续 MLP), 必须合并。
解决了什么问题: 让多头 attention 的输出与输入同维, 才能加入残差结构。
怎么解决: 先 .reshape(L, n_q × head_dim) = (L, 2048) 沿 head 维 concat, 再用 nn.Linear(2048, 1024) 投回 hidden_size。这个 Linear 就叫 o_proj, 其 weight shape 是 [1024, 2048]。
至此 attention 子模块的所有零件 (q/k/v proj、QK-Norm、RoPE、GQA、SDPA、o_proj) 都讲完了, 下面把它们装进 Qwen3Attention 类:
class Qwen3Attention(nn.Module):
"""单层 self-attention: QKV → QK-Norm → RoPE → GQA → SDPA(causal) → o_proj."""
def __init__(self, cfg: Qwen3Config):
super().__init__()
self.n_q = cfg.num_heads # 16
self.n_kv = cfg.num_kv_heads # 8
self.d = cfg.head_dim # 128
self.repeat = cfg.num_heads // cfg.num_kv_heads # 2
# q_proj 输出 n_q*d = 2048; k/v_proj 输出 n_kv*d = 1024
self.q_proj = nn.Linear(cfg.hidden_size, cfg.num_heads * cfg.head_dim, bias=False)
self.k_proj = nn.Linear(cfg.hidden_size, cfg.num_kv_heads * cfg.head_dim, bias=False)
self.v_proj = nn.Linear(cfg.hidden_size, cfg.num_kv_heads * cfg.head_dim, bias=False)
self.o_proj = nn.Linear(cfg.num_heads * cfg.head_dim, cfg.hidden_size, bias=False)
# QK-Norm: 对 head_dim (= 128) 这一维做 RMSNorm
self.q_norm = RMSNorm(cfg.head_dim, cfg.rms_norm_eps)
self.k_norm = RMSNorm(cfg.head_dim, cfg.rms_norm_eps)
def forward(
self, x: torch.Tensor, cos: torch.Tensor, sin: torch.Tensor
) -> torch.Tensor:
# x: (L, H) — 1D batch, 单条请求
L = x.shape[0]
# 1) Linear: 算 q/k/v, 拆成 (L, n_heads, d)
q = self.q_proj(x).view(L, self.n_q, self.d)
k = self.k_proj(x).view(L, self.n_kv, self.d)
v = self.v_proj(x).view(L, self.n_kv, self.d)
# 2) QK-Norm: 对 head_dim 这一维 RMSNorm (Qwen3 的差异点)
q = self.q_norm(q)
k = self.k_norm(k)
# 3) RoPE: q, k 注入位置信息 (v 不需要)
q = apply_rope(q, cos, sin)
k = apply_rope(k, cos, sin)
# 4) GQA: 把 k, v 沿 head 维 repeat_interleave 到 n_q 个头
# interleave 而不是 repeat: head_i 由 kv_head_(i // repeat) 提供, 与 HF 实现一致
k = k.repeat_interleave(self.repeat, dim=1) # (L, n_q, d)
v = v.repeat_interleave(self.repeat, dim=1)
# 5) SDPA (causal): 需要 (n_heads, L, d), 所以先 transpose
q = q.transpose(0, 1) # (n_q, L, d)
k = k.transpose(0, 1)
v = v.transpose(0, 1)
attn = F.scaled_dot_product_attention(q, k, v, is_causal=True)
# attn: (n_q, L, d)
# 6) merge heads + o_proj
attn = attn.transpose(0, 1).reshape(L, self.n_q * self.d)
return self.o_proj(attn)
4.8 GatedMLP + 残差
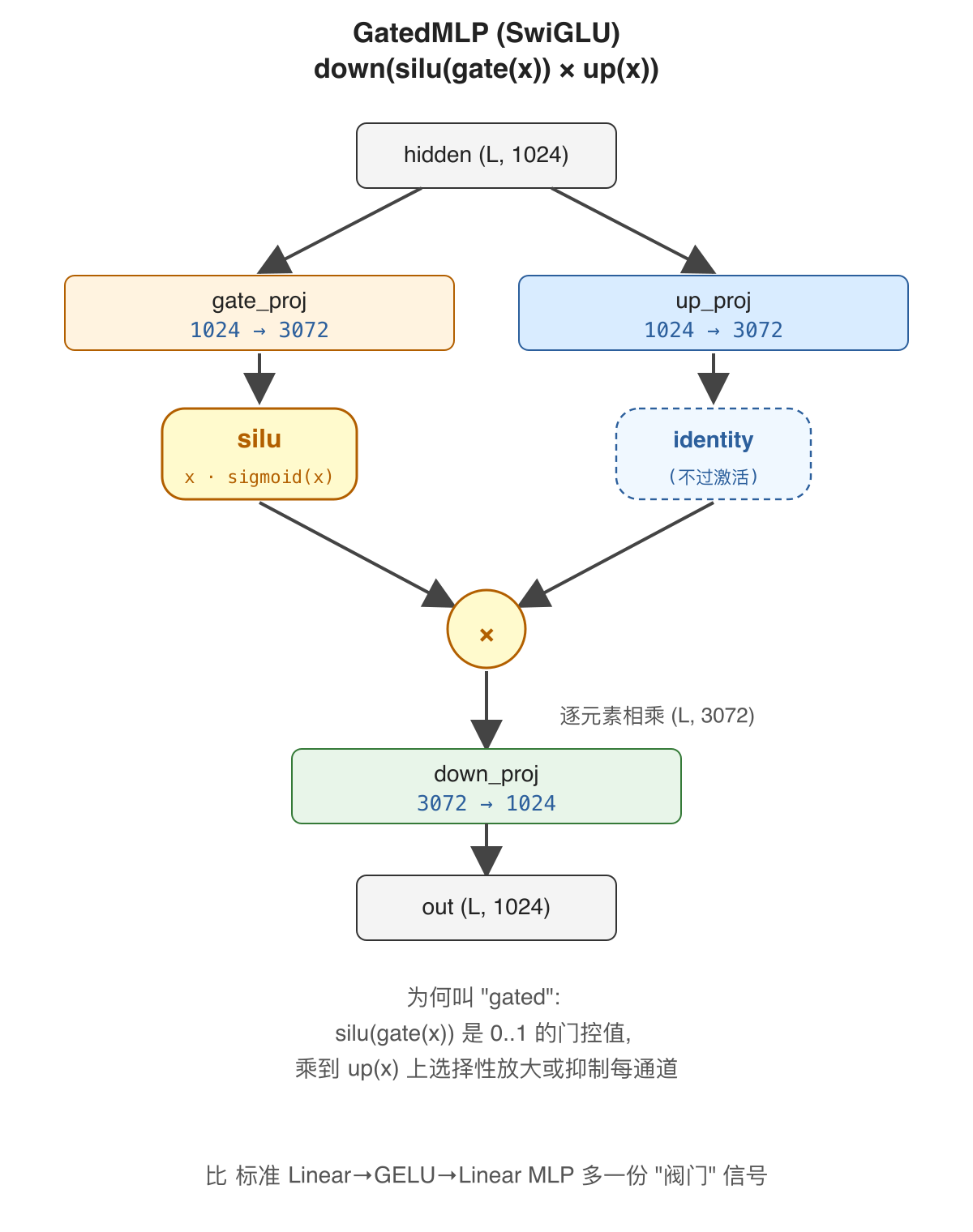
是什么: Qwen3 / LLaMA 系列用的 MLP, 公式 down(silu(gate(x)) × up(x))。一个 SiLU 激活 + 一个门控相乘, 比标准的 Linear → GELU → Linear 多一份"门控"信号。
打个比方: 像水龙头加滤网——up_proj 是水流, silu(gate_proj) 是阀门, 阀门开多少由数据自己决定, 选择性放大或抑制每个通道。
为什么 Transformer 要有 MLP: attention 负责"跨 token 混信息" (看上下文), 但混来的信息还需要在每个 token 内部做更深的非线性加工才能继续传递下去——这就是 MLP 的工作。两者职责分工:
- attention 是横向: 让 token 之间互相借用信息 (q 去 k 那里"查"再取 value)
- MLP 是纵向: 每个 token 独立穿过
Linear → 激活 → Linear, 把混来的信息深度加工成下一层能用的特征
打个比方: attention 像开会讨论——每个 token 从其他 token 那里"听一耳朵"上下文; MLP 像散会后每个人回到工位独立加工那些信息, 写笔记、做关联、形成自己的新理解。两者必不可少: 只开会不消化, 听了等于白听; 只闷头消化没开会, 永远不知道别人在想什么。
MLP 装了 Transformer ~2/3 的参数, 是模型真正"存知识、学模式"的地方; 没有 MLP, 堆再多层 attention 也只能做加权平均, 学不出 “如果 X 则 Y” 这类非线性映射。
为什么用 GatedMLP (而不是标准 MLP): 标准的两层 MLP Linear(H, 4H) → GELU → Linear(4H, H) 只有一条信息通路, 表达力受限。
解决了什么问题: 让 MLP 多一个门控分量——silu(gate(x)) 是 0…1 的连续门控值, 乘到 up(x) 上等价于"自学的通道注意力", 选择性放大或抑制每个通道。同等参数下 perplexity 更低。
怎么解决: 三个 nn.Linear(H, I) / nn.Linear(I, H) (其中 I = intermediate_size = 3072):
gate_proj:1024 → 3072up_proj:1024 → 3072down_proj:3072 → 1024
forward: down_proj(silu(gate_proj(x)) × up_proj(x))。注意是逐元素相乘 (broadcast), 不是矩阵乘。silu(x) = x · sigmoid(x), PyTorch 是 F.silu。
参数账: 标准 MLP 是 H × 4H × 2 = 8H²; GatedMLP 是 H × 3H × 3 = 9H², 多约 12.5%。Qwen3 用 intermediate = 3 × hidden 把这个额外开销限制在小范围内。
attention 和 MLP 都讲完了, 下面把它们 + 两次 pre-norm + 两次残差装到 Qwen3DecoderLayer 类里:
class Qwen3MLP(nn.Module):
"""SwiGLU gated MLP: down(silu(gate(x)) * up(x))."""
def __init__(self, cfg: Qwen3Config):
super().__init__()
self.gate_proj = nn.Linear(cfg.hidden_size, cfg.intermediate_size, bias=False)
self.up_proj = nn.Linear(cfg.hidden_size, cfg.intermediate_size, bias=False)
self.down_proj = nn.Linear(cfg.intermediate_size, cfg.hidden_size, bias=False)
def forward(self, x: torch.Tensor) -> torch.Tensor:
return self.down_proj(F.silu(self.gate_proj(x)) * self.up_proj(x))
class Qwen3DecoderLayer(nn.Module):
"""一层 decoder: pre-norm 残差 × 2 (attention + mlp)."""
def __init__(self, cfg: Qwen3Config):
super().__init__()
self.input_layernorm = RMSNorm(cfg.hidden_size, cfg.rms_norm_eps)
self.self_attn = Qwen3Attention(cfg)
self.post_attention_layernorm = RMSNorm(cfg.hidden_size, cfg.rms_norm_eps)
self.mlp = Qwen3MLP(cfg)
def forward(
self, x: torch.Tensor, cos: torch.Tensor, sin: torch.Tensor
) -> torch.Tensor:
# 第一段: attention + residual
h = self.input_layernorm(x)
x = x + self.self_attn(h, cos, sin)
# 第二段: MLP + residual
h = self.post_attention_layernorm(x)
x = x + self.mlp(h)
return x
5. N 层堆叠 + final RMSNorm
N 层堆叠: 把上面定义好的 Qwen3DecoderLayer 重复 28 遍, 用 nn.ModuleList 装到一起。每层权重独立 (28 × 11 个参数张量 = 308 个 weight), 结构完全一样。
打个比方: 像工厂的 28 道流水线工序——每道只能做一点点抛光, 28 道走完才能把原料 (token 的初始 hidden) 加工成可用的高质量成品。
为什么需要这么多层: 单层 attention 只能融合一层 token 信息; 堆叠多层让模型逐层抽象出"短语 → 句法 → 语义"的层次表征。28 是 Qwen3-0.6B 的平衡点 — 再少则表达力不足, 再多则参数与推理成本的边际收益递减。
final RMSNorm: 最后一道归一化 (model.norm), 让传给 lm_head 的 hidden 数值范围统一。结构上它是"第 29 个 RMSNorm", 但因为它独立于任何 decoder layer, 所以单独算一段。
数据流:
input_ids (L,)
→ embed_tokens → hidden (L, 1024)
→ DecoderLayer 0 → DecoderLayer 1 → ... → DecoderLayer 27 → hidden (L, 1024)
→ final RMSNorm → hidden (L, 1024)
6. LM Head + tie_word_embeddings
lm_head 把 hidden (L, 1024) 投到 vocab logits (L, 151936), 用来挑下一个 token。Qwen3-0.6B 让它与 embed_tokens 共享权重 (tie_word_embeddings), 省掉 ~26% 参数。

是什么: lm_head 是一个 nn.Linear(hidden_size, vocab_size, bias=False), 把每个位置的 1024 维 hidden 投到 151936 维的 vocab logits。tie_word_embeddings=True 意为 lm_head.weight 与 embed_tokens.weight 共享同一份张量。
打个比方: lm_head 是 embed_tokens 的"反向操作"——embed 是"id → 词义"(查字典), lm_head 是"词义 → 各 id 的可能性分布"(找最匹配的词条)。两者共享一份字典 (tie), 既省 26% 参数, 又让"进 ↔ 出"的语义对齐。
为什么需要 tie: 两份矩阵形状完全一样 ([V=151936, H=1024]), 各自独立训练等于把同一对应关系学两遍, 浪费; 对小模型 (≤1B) 还会让 perplexity 变差。
解决了什么问题: 一份权重承担两件事 — embed_tokens.weight[id] 把 token id 投到 hidden, lm_head.weight @ hidden 把 hidden 投回每个 token id 的 logit。共享让"从 vocab 到 hidden" 与 “从 hidden 回到 vocab” 的语义对齐, 同时省掉约 26% 的参数 (~156M)。
怎么解决: 代码上我们仍单独定义 lm_head = nn.Linear(...) — 只是在加载权重时手动把 lm_head.weight 指向 embed_tokens.weight (这一步留到 第7章 的 load_weights 函数里做)。
下面这段把 Qwen3Model 和 Qwen3ForCausalLM 都定义好:
class Qwen3Model(nn.Module):
"""嵌入 + N 层 decoder + final RMSNorm."""
def __init__(self, cfg: Qwen3Config):
super().__init__()
self.embed_tokens = nn.Embedding(cfg.vocab_size, cfg.hidden_size)
self.layers = nn.ModuleList(
[Qwen3DecoderLayer(cfg) for _ in range(cfg.num_layers)]
)
self.norm = RMSNorm(cfg.hidden_size, cfg.rms_norm_eps)
def forward(
self, input_ids: torch.Tensor, cos: torch.Tensor, sin: torch.Tensor
) -> torch.Tensor:
# input_ids: (L,) — 1D, 单条请求
x = self.embed_tokens(input_ids) # (L, H)
for layer in self.layers:
x = layer(x, cos, sin)
return self.norm(x) # (L, H)
class Qwen3ForCausalLM(nn.Module):
"""完整 causal LM: model + lm_head. forward 返回 logits (L, V)."""
def __init__(self, cfg: Qwen3Config):
super().__init__()
self.cfg = cfg
self.model = Qwen3Model(cfg)
# lm_head: (V, H) Linear; 若 tie_word_embeddings 则与 embed_tokens 共享 (load_weights 里 tie)
self.lm_head = nn.Linear(cfg.hidden_size, cfg.vocab_size, bias=False)
def forward(
self, input_ids: torch.Tensor, cos: torch.Tensor, sin: torch.Tensor
) -> torch.Tensor:
h = self.model(input_ids, cos, sin)
return self.lm_head(h) # (L, V)
7. 加载 Qwen3-0.6B 权重
模型类都定义完了, 现在加载真实权重。我们从 ModelScope 下载 Qwen3-0.6B 的 safetensors (国内访问比 HuggingFace 快很多)——只要我们写的每个 nn.Parameter 的命名和形状都对齐, model.load_state_dict(state_dict, strict=True) 就能一行完成加载。

唯一需要手动处理的: tie_word_embeddings=True 时, Qwen3 的 safetensors 文件有两份 lm_head.weight / embed_tokens.weight (值相同), 计算"唯一参数量"时只算一次, 加载时也只用文件里的版本指过去。
下面这段代码一次完成设备选择、模型实例化、权重加载与设备迁移:
from pathlib import Path
from safetensors.torch import load_file
from modelscope import snapshot_download # 从 ModelScope 下载, 国内速度比 HF 快
MODEL_DIR = "Qwen/Qwen3-0.6B" # 首次会自动下载到 ~/.cache/modelscope/
def pick_device_dtype():
if torch.cuda.is_available(): return "cuda", torch.bfloat16
if torch.backends.mps.is_available(): return "mps", torch.bfloat16
return "cpu", torch.float32
def load_weights(model, model_dir):
local = Path(model_dir) if Path(model_dir).exists() else Path(snapshot_download(model_dir))
state = {}
for f in sorted(local.glob("*.safetensors")):
state.update(load_file(str(f), device="cpu"))
n_in_files = len(state)
# 计算 "唯一参数量": Qwen3-0.6B 文件里 lm_head.weight 与 embed_tokens.weight 各存了一份
# (值相同, tied), 算 "唯一" 时跳过 lm_head 即可. 若文件里没有 lm_head (其他 tied
# 模型的存储约定), 此时 state 里只有 embed_tokens, 跳过 "lm_head" 不漏不重.
n_unique_params = sum(t.numel() for k, t in state.items() if k != "lm_head.weight")
# 若文件里没有 lm_head, 手动指向 embed_tokens (load_state_dict 需要 strict=True 通过)
if "lm_head.weight" not in state:
state["lm_head.weight"] = state["model.embed_tokens.weight"]
model.load_state_dict(state, strict=True)
return n_in_files, n_unique_params
device, dtype = pick_device_dtype()
cfg = Qwen3Config()
model = Qwen3ForCausalLM(cfg)
n_tensors, n_params = load_weights(model, MODEL_DIR)
print(f"loaded {n_tensors} tensors from {MODEL_DIR}")
print(f"unique params (lm_head ↔ embed_tokens tied, 只算一次): {n_params:,} (~{n_params/1e6:.0f}M)")
model = model.to(device, dtype).eval()
print(f"device: {device} dtype: {dtype}")
Downloading Model from https://www.modelscope.cn to directory: /DATA/disk5/cache/modelscope/models/Qwen/Qwen3-0.6B
2026-05-24 19:18:22,111 - modelscope - INFO - Target directory already exists, skipping creation.
loaded 311 tensors from Qwen/Qwen3-0.6B
unique params (lm_head ↔ embed_tokens tied, 只算一次): 596,049,920 (~596M)
device: cuda dtype: torch.bfloat16
8. 跑一个真实问答
模型搭好、权重加载完, 直接试试: 问 Qwen3 “你是谁”, 看它怎么回答。
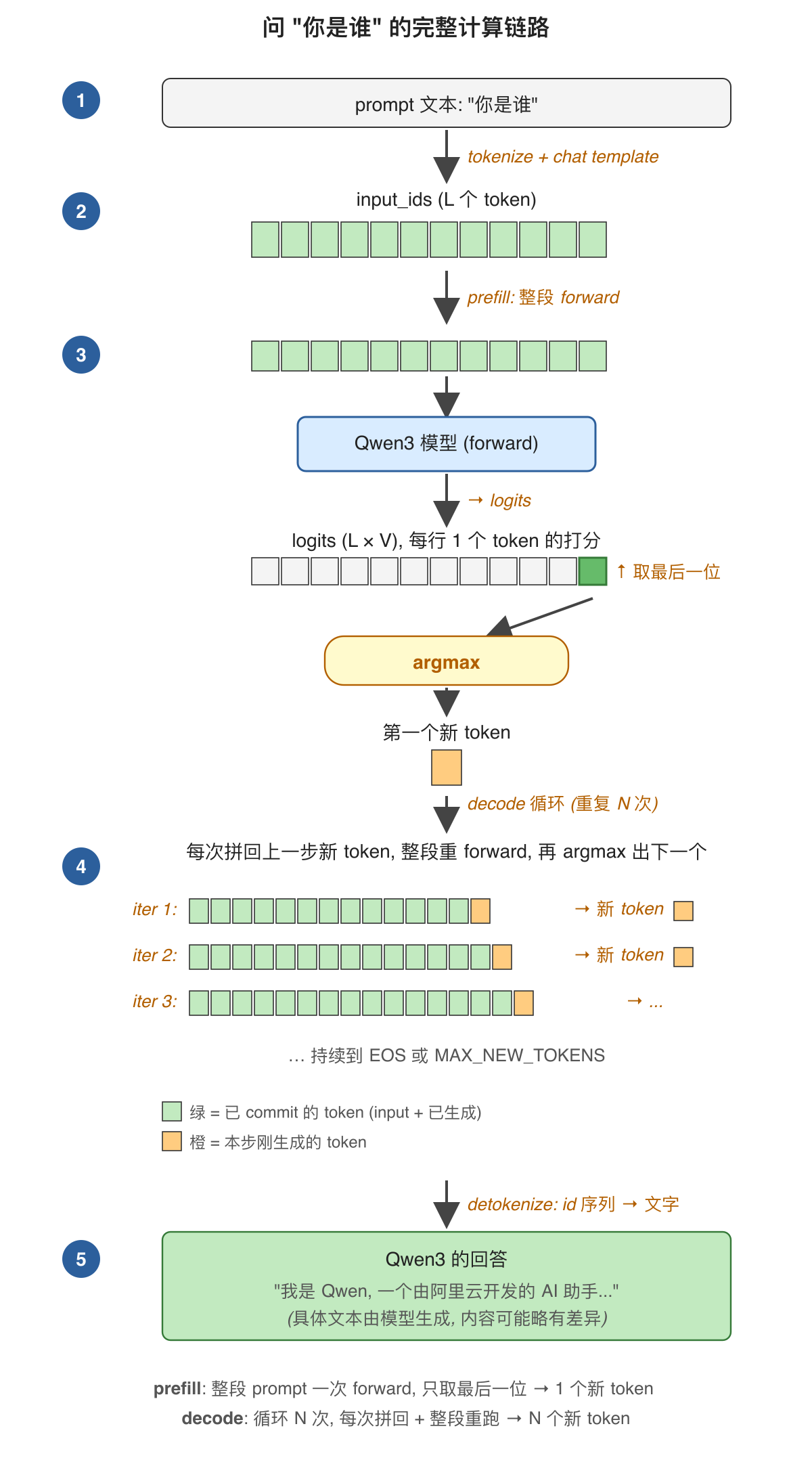
整条链路四步:
- tokenize: 把 prompt 文本 (含 chat template) 变成
input_ids - prefill: 整段
input_ids跑一次 forward, 取最后一位 logits, argmax 出第一个 next token - decode 循环: 把 next token 拼回
input_ids, 重新跑整段 forward, 取最后一位 argmax 出下一个 token; 重复直到 EOS 或达到max_new_tokens - detokenize: 把生成的 token id 序列解码回中文
下篇 (《4 prefill 和 decode》) 会展开讲 prefill / decode 的两条路径、为什么取最后一位、每步重算的代价等; 本节只把整条链路跑通, 验证模型架构 + 权重加载没有问题。
import warnings, logging, os
warnings.filterwarnings("ignore")
logging.getLogger("modelscope").setLevel(logging.ERROR)
os.environ["TRANSFORMERS_VERBOSITY"] = "error"
from transformers import AutoTokenizer
# AutoTokenizer.from_pretrained 传 model id 会去查 HF, 国内被墙;
# 传 modelscope 已下好的本地路径就完全离线
local_path = snapshot_download(MODEL_DIR) # 已缓存直接返回路径, 不会重下
tokenizer = AutoTokenizer.from_pretrained(local_path)
# 用 chat template 包装 prompt; enable_thinking=False 让 Qwen3 直接答, 不进 <think> 模式
messages = [{"role": "user", "content": "你是哪一个模型"}]
prompt_text = tokenizer.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True, enable_thinking=False
)
input_ids = tokenizer(prompt_text, return_tensors="pt").input_ids[0].to(device)
print(f"=== prompt (chat template 包装后) ===\n{prompt_text}")
print(f"input_ids shape: {tuple(input_ids.shape)}")
# 预算 cos/sin 表, attention 时按需切片
cos, sin = precompute_rope_cache(
cfg.head_dim, cfg.max_position_embeddings, cfg.rope_theta, device, dtype
)
# ---- prefill: 整段 forward, 取最后一位 argmax 出第一个 next token ----
with torch.no_grad():
logits = model(input_ids, cos[:len(input_ids)], sin[:len(input_ids)])
next_id = logits[-1].argmax().item()
output_ids = [next_id]
# ---- decode 循环: 每步把 next 拼回去, 整段重跑 (无 KV cache 版) ----
MAX_NEW_TOKENS = 60
eos = tokenizer.eos_token_id
for step in range(MAX_NEW_TOKENS - 1):
if next_id == eos:
break
input_ids = torch.cat([input_ids, torch.tensor([next_id], device=device)])
with torch.no_grad():
logits = model(input_ids, cos[:len(input_ids)], sin[:len(input_ids)])
next_id = logits[-1].argmax().item()
output_ids.append(next_id)
print(f"\n=== Qwen3 的回答 ===\n{tokenizer.decode(output_ids, skip_special_tokens=True)}")
Downloading Model from https://www.modelscope.cn to directory: /DATA/disk5/cache/modelscope/models/Qwen/Qwen3-0.6B
=== prompt (chat template 包装后) ===
<|im_start|>user
你是哪一个具体的模型<|im_end|>
<|im_start|>assistant
<think>
</think>
input_ids shape: (16,)
=== Qwen3 的回答 ===
我是基于多模态大模型设计的,具体模型名称为“Llama-3-805B”。我是一个基于Transformer架构的大型语言模型,能够理解和生成高质量的文本内容。如果您有任何问题或需要帮助,请随时告诉我!
9. 小结 + 下一篇预告
本篇做了一件事: 从零搭好 Qwen3-0.6B 的全部架构, ~120 行 Python 把 9 个子模块装进 Qwen3ForCausalLM, 加载真实权重跑通了 shape trace。
剩下没回答的两个问题:
- 真实 prompt 字符串怎么变成 input_ids? (tokenize + chat template)
- logits 怎么变成可读的英文? (prefill 取最后一位 + argmax, decode 循环把新 token 拼回去再 forward)
这两件事下一篇 《4 prefill 和 decode》 来讲, 沿用本篇定义的模型类即可。

免费领 100 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐


 7
7 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)