
[GPU] TileLang vs Triton: 选择合适的GPU编程语言
*GPU编程正在从手工优化向自动化、从单一平台向跨平台、从简单抽象向多层次抽象发展。TileLang和Triton都是这个趋势的重要参与者,它们将推动整个生态系统向前发展。*
在众多GPU编程语言中如何做出选择,当前GPU编程生态系统中的一个重要趋势——越来越多的高级抽象语言正在挑战传统的CUDA编程模式。
背景:两个相似却不同的选择
TileLang和Triton都是基于现代编译器技术的GPU编程语言,旨在简化CUDA开发。
-
Triton已经相当成熟,拥有17.9k GitHub星标,并被PyTorch生态系统广泛采用。triton-lang/triton: Development repository for the Triton language and compiler
-
TileLang作为一个相对较新的项目,基于Apache TVM构建,提供了独特的价值主张。tile-ai/tilelang: Domain-specific language designed to streamline the development of high-performance GPU/CPU/Accelerators kernels
TileLang传送:
- [tile-lang] 自动调优器 | 遍历-编译-测试 | 记忆最优解 |
@autotune装饰器 - [tile-lang] JITKernel内部 | Pass流水线链式转换TIR(中间表示)
- [tile-lang] JITKernel | 编译程序的智能封装
- [tile-lang] 布局与分块管理 | Layout | Fragment
- [tile-lang] 张量核心 | 传统MMA->WGMMA | 底层自动选择优化
- [tile-lang] 语言接口 |
T.prim_func&@tilelang.jit| 底层原理 - [tile-lang] docs | 基准测试 | GEMM示例
Triton部分&MLIR架构 看了一下 但还没整理 之后有时间或许会整理吧🕳+1
核心
1. 架构基础的不同选择
TileLang的TVM基础:
# TileLang基于TVM,提供成熟的编译器基础设施
@T.prim_func
def gemm_kernel(A: T.Buffer, B: T.Buffer, C: T.Buffer):
# 利用TVM的三阶段编译管道
# PreLowerSemanticCheck → LowerAndLegalize → OptimizeForTarget
pass
Triton的MLIR基础:
# Triton直接基于MLIR构建
@triton.jit
def gemm_kernel(a_ptr, b_ptr, c_ptr, M, N, K, stride_am, stride_ak, ...):
# 更直接的MLIR编译路径
pass
这种架构差异带来了根本性的不同:TileLang继承了TVM生态系统的所有优势,包括成熟的优化pass和多后端支持
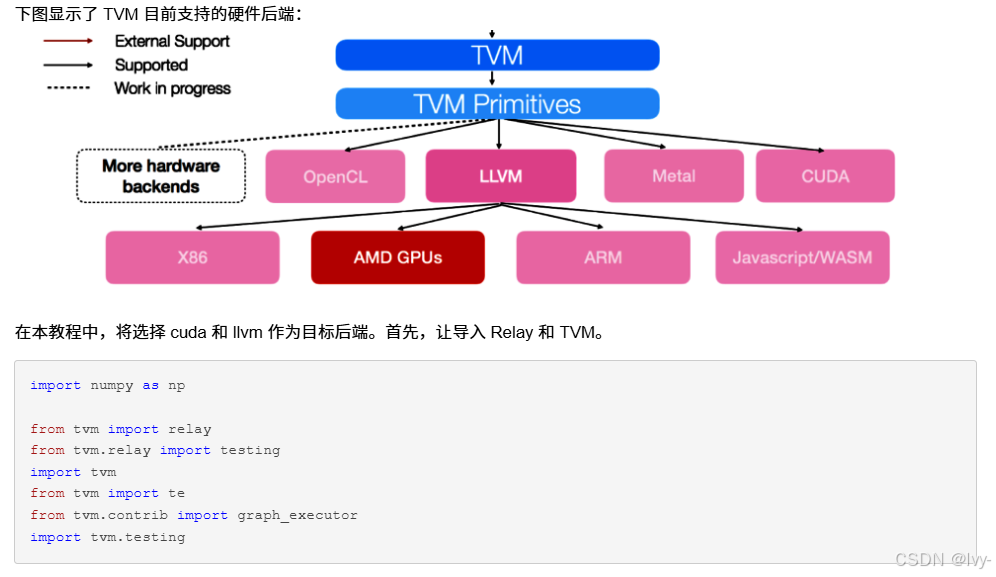
而Triton则享受MLIR的灵活性和现代编译器设计。
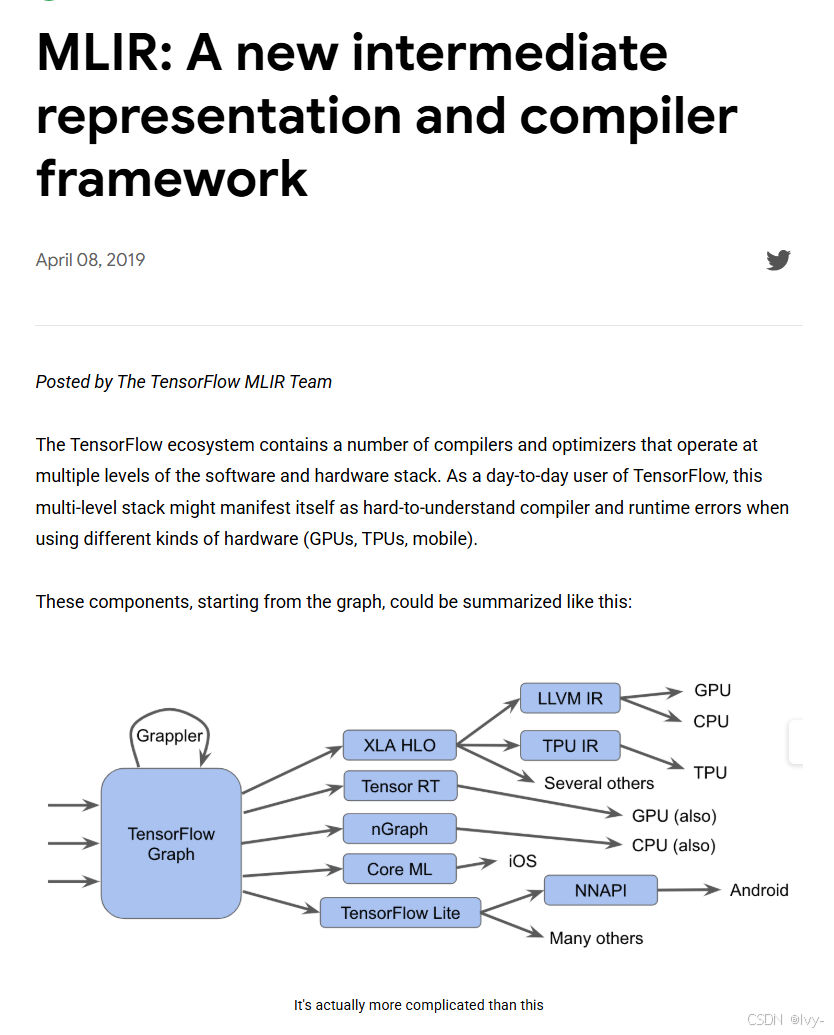
2. 编程抽象层次的差异
TileLang主要专注于多层次抽象:
# 高级操作抽象
with T.Kernel(T.ceildiv(M, 128), T.ceildiv(N, 128)) as (bx, by):
# 自动选择最优指令:WGMMA/MMA/MFMA
T.gemm(A_shared, B_shared, C_local, layout="tn")
# 线程级精细控制
with T.thread_binding(0, 128) as tx:
# 可以进行线程级优化
T.copy(A_global[...], A_shared[...])
Triton主要专注于块级抽象:
@triton.jit
def kernel(x_ptr, y_ptr, n_elements, BLOCK_SIZE: tl.constexpr):
# 主要在块级别进行操作
pid = tl.program_id(axis=0)
block_start = pid * BLOCK_SIZE
offsets = block_start + tl.arange(0, BLOCK_SIZE)
TileLang的优势
1. 多后端支持的真正实现
TileLang不仅仅是口头承诺多后端支持,而是真正实现了:
- NVIDIA GPUs: 完整的CUDA支持
- AMD GPUs: 通过HIP后端
- Apple Silicon: 原生Metal支持
- 华为昇腾: AscendC和NPU IR后端
# 同一份代码,多个后端
@T.prim_func
def attention_kernel(...):
# 这份代码可以在NVIDIA、AMD、Apple、华为芯片上运行
pass
2. 自动化优化的Carver框架
TileLang提供了独特的Carver框架,能够自动推荐最优的tile结构:
# Carver自动分析并推荐最优配置
carver = T.Carver()
optimal_config = carver.analyze(workload_shape=(4096, 4096, 2048))
# 输出:建议使用 tile_size=(128, 128), thread_tile=(8, 8)
3. 先进的内存布局推理
TileLang实现了三阶段布局推理算法:
- Strict阶段:严格约束下的布局确定
- Common阶段:通用优化布局
- Free阶段:自由度最大的布局选择
这种自动化程度是Triton目前无法匹配的。
应用场景
选择TileLang的场景:
-
需要跨平台支持
# 一份代码,支持NVIDIA、AMD、Apple、华为 if target == "cuda": # 自动生成CUDA代码 elif target == "metal": # 自动生成Metal代码 -
需要线程级精细控制
# TileLang允许线程级优化 with T.thread_binding(0, 32) as tx: # 精确控制每个线程的行为 local_data = T.alloc_local([16], dtype="float16") -
稀疏计算需求
# 原生支持2:4稀疏张量核心 T.gemm_sp(A_sparse, B_dense, C, sparsity_pattern="2:4")
选择Triton的场景:
- PyTorch生态集成:如果你主要在PyTorch环境中工作
- 快速原型开发:Triton的学习曲线相对平缓
- 成熟的社区支持:更大的用户基数和更多的示例
开发体验
TileLang的开发体验:
# 丰富的调试工具
@T.prim_func
def debug_kernel(...):
T.print("Matrix A shape:", A.shape) # 内置调试
T.visualize_layout(A_shared) # 内存布局可视化
# JIT编译与缓存
kernel = T.compile(debug_kernel, target="cuda") # 自动缓存
Triton的开发体验:
# 相对简单的调试
@triton.jit
def simple_kernel(...):
# 主要依赖print和profiling工具
pass
展望
从技术发展趋势来看,TileLang代表了GPU编程语言发展的几个重要方向:
- 编译器技术的深度应用:基于TVM的成熟编译器基础设施
- 自动化优化:减少手工调优的需求
- 真正的跨平台支持:不仅仅是理论上的支持
- 多层次抽象:从高级操作到线程级控制的完整覆盖
结论与建议
TileLang和Triton都是优秀的GPU编程语言,但它们服务于不同的需求:
选择TileLang,如果你:
- 需要跨多个GPU厂商的平台支持
- 要求线程级的精细控制能力
- 希望利用自动化优化减少手工调优
- 正在开发稀疏计算或高级注意力机制
选择Triton,如果你:
- 主要在PyTorch生态系统中工作
- 需要快速原型开发和验证
- 更看重成熟的社区和丰富的示例
- 专注于深度学习算子开发
建议是:不要把这看作是非此即彼的选择。两个项目都在快速发展,学习它们的设计理念和技术特点,能够帮助我们更好地理解GPU编程的未来方向。
对于企业级应用,建议同时关注两个项目的发展,根据具体的技术需求和团队能力做出选择。对于研究者和技术爱好者,TileLang的创新性设计和多后端支持能力值得探索。
GPU编程正在从手工优化向自动化、从单一平台向跨平台、从简单抽象向多层次抽象发展。TileLang和Triton都是这个趋势的重要参与者,它们将推动整个生态系统向前发展。

免费领 100 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐

 34
34 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)