
Qwen3.6模型vLLM vs SGLang部署指南与性能表现(中)
1. 在在线环境下,可直接通过 HuggingFace 或 ModelScope 搜索 Qwen3.6 模型并进行部署,具体步骤参考下方。2. 在离线环境中,需要提前下载好模型权重,并将其分发到所有 Worker 节点,同时挂载到对应的 Worker 容器中。,填写对应的模型权重路径。菜单中,选择已添加的 Qwen3.6 模型进行部署。时,说明模型已经成功启动,可以进行后续的测试。,直接搜索 Qw
部署 Qwen 3.6 模型
1. 在在线环境下,可直接通过 HuggingFace 或 ModelScope 搜索 Qwen3.6 模型并进行部署,具体步骤参考下方。
2. 在离线环境中,需要提前下载好模型权重,并将其分发到所有 Worker 节点,同时挂载到对应的 Worker 容器中。随后,在 GPUStack 控制台 - 模型文件菜单中,选择添加模型文件 - 本地路径,填写对应的模型权重路径。需要注意,这里填写的应为容器内路径,例如:
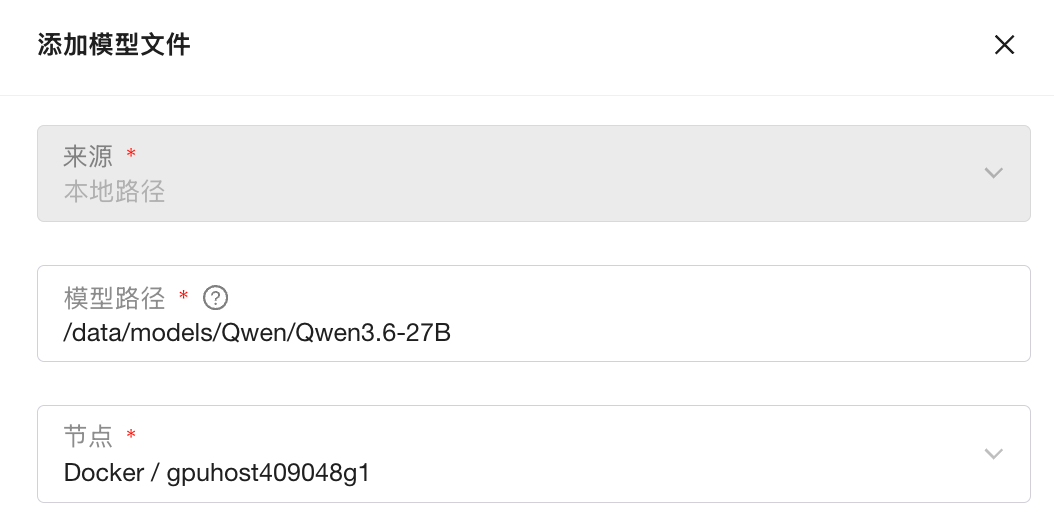
联网环境:在 GPUStack 控制台 - 部署菜单下,选择 部署模型 → ModelScope,直接搜索 Qwen3.6 模型进行部署。
离线环境:可从 GPUStack 控制台 - 模型文件菜单中,选择已添加的 Qwen3.6 模型进行部署。
vLLM
后端:选择 vLLM
版本:选择前面自定义添加的 0.19.1-custom
GPU:2 块 4090 48GB GPU
使用以下后端参数启动,后端参数支持单行或多行形式(注意 --tensor-parallel-size 2 已设置双卡张量并行,请确保有两块 GPU 可分配;其它环境请根据实际情况调整并行策略):
# 后端参数
--tp-size 2 --reasoning-parser qwen3 --tool-call-parser qwen3_coder --speculative-algorithm EAGLE --speculative-num-steps 3 --speculative-eagle-topk 1 --speculative-num-draft-tokens 4 --mamba-scheduler-strategy extra_buffer --mem-fraction-static 0.9
# 环境变量
SGLANG_ENABLE_SPEC_V2=1
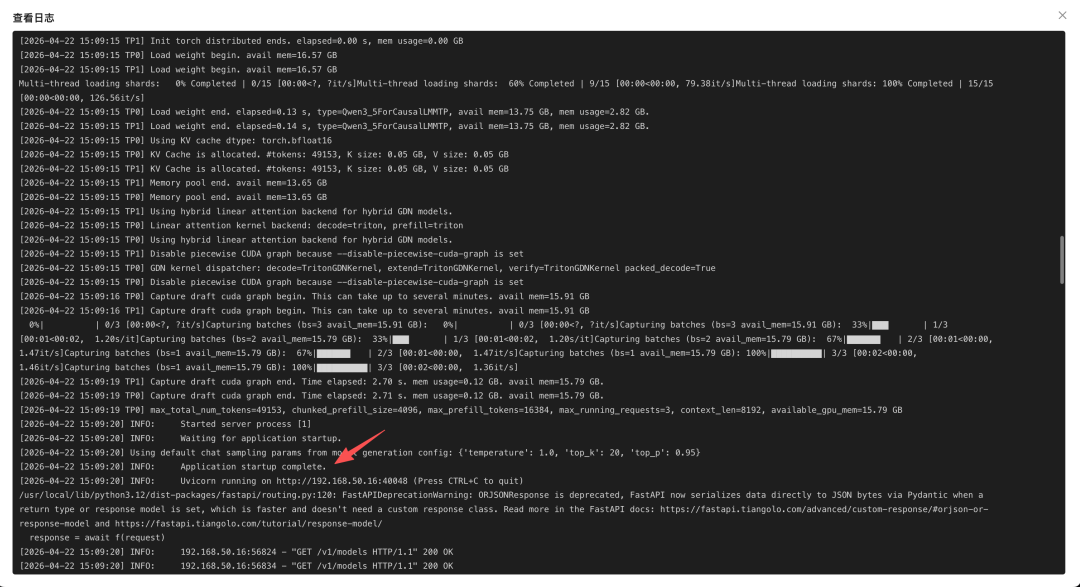
等待模型启动时,可以在操作中点击查看日志,实时观察启动过程:
vLLM
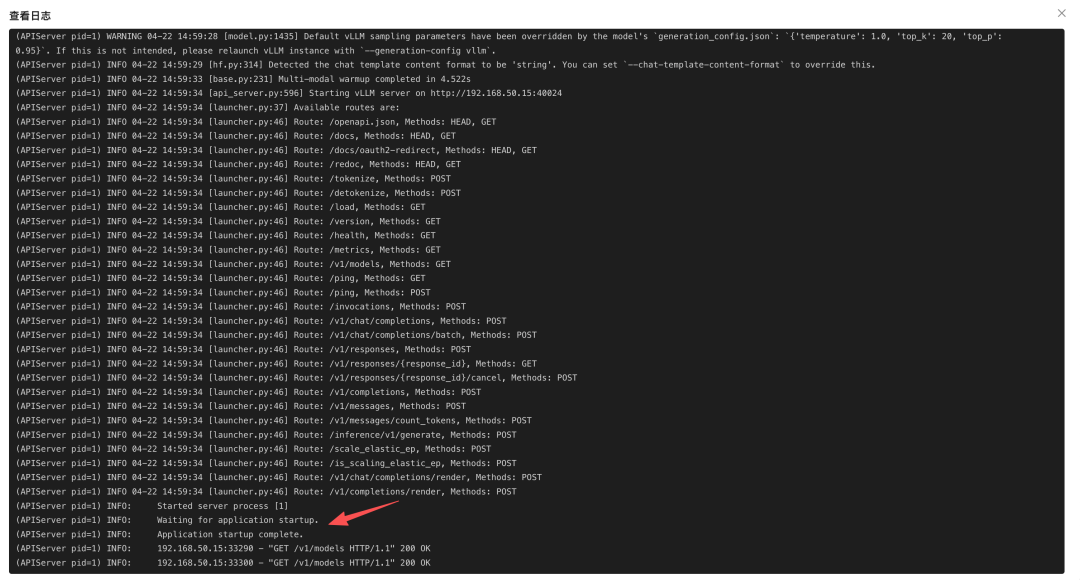
SGLang
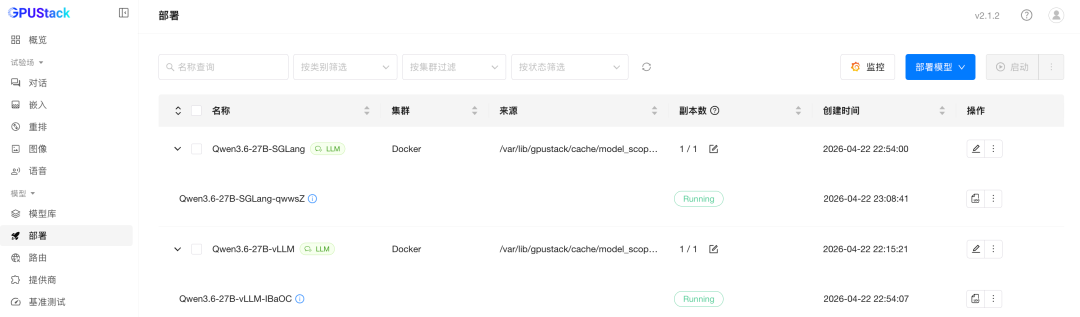
当模型实例状态显示为 Running 时,说明模型已经成功启动,可以进行后续的测试。

免费领 100 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐
 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)