【转载】精读Deep Think with Confidence
【摘要】本研究提出置信深度思考(DeepConf)方法,通过动态过滤低质量推理轨迹显著提升大语言模型的推理效率与性能。该方法创新性地利用局部置信度信号(如最低组置信度、尾部置信度),在生成过程或生成后实时识别低置信度轨迹。实验表明,在AIME2025等数学推理基准测试中,DeepConf@512达到99.9%准确率,相比传统自洽性方法减少84.7%的token消耗。该方法无需额外训练即可适配不同规
论文信息:
Deep Think with Confidence
Yichao Fu, Xuewei Wang, Yuandong Tian, Jiawei Zhao
https://arxiv.org/abs/2508.15260
Project Page: jiaweizzhao.github.io/deepconf
原博文链接:https://zhuanlan.zhihu.com/p/1945513709205173054
摘要
大型语言模型(LLMs)通过自一致性多数投票等测试时扩展方法,在推理任务中展现出巨大潜力。然而,该方法往往导致精度提升边际递减且计算开销高昂。为应对这些挑战,我们提出置信深度思考(DeepConf),这是一种简单而强大的方法,可在测试时同时提升推理效率与性能。DeepConf利用模型内部置信度信号,在生成过程中或生成后动态过滤低质量推理轨迹。该方法无需额外模型训练或超参数调优,并可无缝集成到现有服务框架中。我们在多种推理任务和最新开源模型(包括Qwen 3和GPT-OSS系列)上评估DeepConf。值得注意的是,在AIME 2025等具有挑战性的基准测试中,DeepConf@512实现了高达99.9%的准确率,相比全并行思考方法最多减少84.7%的生成token量。
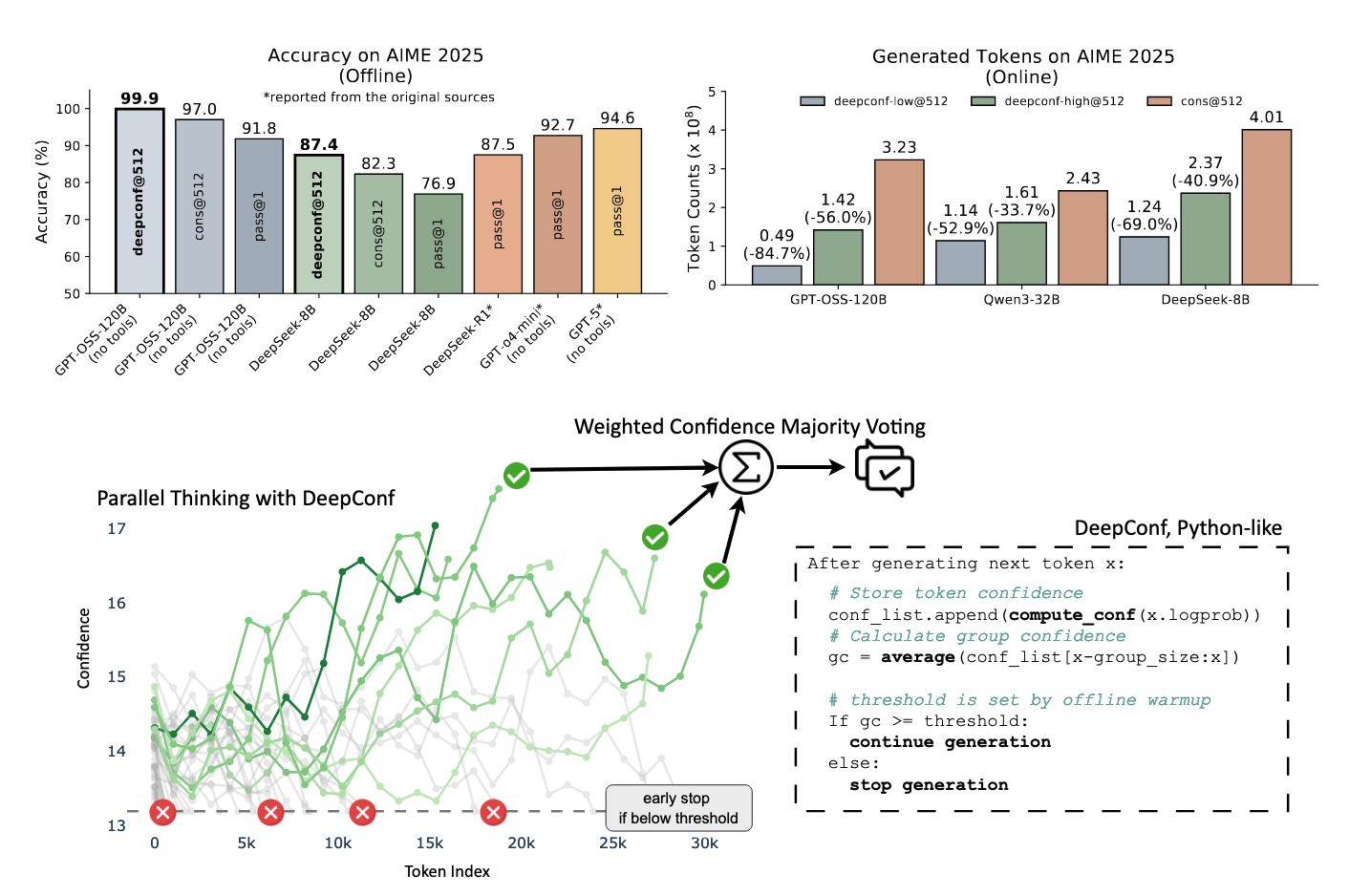
图1:上图:AIME 2025上的DeepConf应用。下图:使用DeepConf实现的并行思考。
对摘要的批注
图1(上)集中展示了本项研究的核心贡献与性能优势。具体地说,左上角的子图,其横轴是不同方法 / 模型的组合,比如:
deepconf@512:DeepConf 并行 512 条思路cons@512:传统 self-consistency 方法,生成 512 条思路后投票pass@1:只生成一条思路,直接看答案- 不同模型(GPT-OSS-120B, DeepSeek-8B, GPT-o4-mini, GPT-5)
纵轴则是在AIME 2025数据集上的准确率,可以看出deepconf@512的离线准确率显著高于其他方法
AIME是一个用于评估大语言模型数学推理能力的基准数据集,其内容由美国数学协会(MAA)组织的美国数学邀请竞赛(AIME)中的高难度题目构成。例如2025 AIME I Problem 15是这样的:
设 N 为满足以下条件的正整数有序三元组 (a,b,c) 的个数: a,b,c≤且
可以被
整除,求 N 除以 1000 的余数。
AIME数据集中的所有题目均以整数作答,这一特点使其在作为基准测试时更具优势——相较于IMO等包含大量证明题的高阶数学竞赛,AIME的题型更利于答案准确性的自动化评估与模型输出的可靠验证。
也许我们可以考虑一下用做基准测试也许我们可以考虑一下用IOI做基准测试
右上角的子图展示了不同方法下的token消耗量,可以看出在在线推理时,deepconf@512可以在cons@512 基础上节约33.7~84.7%不等的token。
要点 & 剧透:
- DeepConf能够在在线推理(Online Reasoning)节约大量token的同时,提升模型离线推理(Offline reasoning)的准确率
- 这一结论是可扩展(scalable)的——不论是在8B参数量的小模型,32B参数量的中等语言模型,还是在120B参数量的大语言模型上,该结论都适用
- 摘要中只体现了离线推理准确率和在线推理的token消耗量上的贡献,有关在线推理准确率的结果需要参考4.3 在线评测相关图表。
- 离线推理的token消耗量在文章正文中未作为对比结果呈现,我猜测主要原因是离线推理的成本在路径预生成后已然固定,优化目标仅为提升精度而非节约成本。
1 引言
大型语言模型(LLMs)已展现出卓越的推理能力,尤其是在采用测试时推理增强方法后。其中自洽性(self-consistency)技术尤为突出,该方法通过采样多条推理路径并采用多数投票聚合最终答案(Wang et al., 2023)。这类并行推理(parallel thinking)方法显著提升了推理准确率,但带来了巨大的计算开销:每个查询生成大量推理轨迹会使推理开销线性增长,限制实际部署(Xue et al., 2023)。例如在AIME 2025基准上,使用Qwen3-8B模型通过标准多数投票将pass@1准确率从68%提升至82%时,每个问题需要额外生成511条推理轨迹,消耗超过1亿个token。
此外,多数投票的并行推理存在边际收益递减现象——随着轨迹数量增加,性能往往趋于饱和甚至下降(Chen et al., 2024a)。关键局限在于标准多数投票平等对待所有推理轨迹,忽略了质量差异(Pal et al., 2024; Wang et al., 2025)。当低质量轨迹主导投票过程时,会导致次优性能。
近期研究开始利用下一词元分布统计量评估推理轨迹质量(Geng et al., 2024; Fadeeva et al., 2024; Kang et al., 2025)。更高的预测置信度通常与更低的信息熵和不确定性相关。通过聚合熵值和置信度等词元级统计量,现有方法可计算整个轨迹的全局置信度,以识别并过滤低质量轨迹,从而改进多数投票性能(Kang et al., 2025)。
然而全局置信度测量存在实践局限:其一,可能掩盖局部推理步骤中的置信度波动,而这些波动恰好是评估轨迹质量的重要信号;其二,对轨迹中所有词元进行平均会模糊关键推理中断现象;其三,必须生成完整轨迹后才能计算全局置信度,无法实现低质量轨迹的提前终止。
我们提出置信度深度思考(DeepConf),这是一种简单有效的测试时方法,通过局部置信度测量将并行推理与置信感知过滤相结合。DeepConf支持离线和在线两种模式,可在生成过程中或生成后识别并丢弃低置信度推理轨迹。该方法在保持或提升最终答案准确性的同时,显著减少不必要的词元生成。
我们在多个推理基准(AIME 2024/2025、HMMT 2025、BRUMO25、GPQA-Diamond)和模型(DeepSeek-8B、Qwen3-8B/32B、GPT-OSS-20B/120B)上评估DeepConf。通过对每个设置进行64次重复实验,结果表明DeepConf在显著减少生成token数量的同时,实现了优于标准多数投票的推理性能。
在可访问所有推理轨迹的离线模式下,使用GPT-OSS-120B(无工具)的DeepConf@512在AIME 2025上达到99.9%准确率,相较cons@512(多数投票)的97.0%和pass@1的91.8%达到该基准饱和值。在实时生成控制的在线模式下,DeepConf相较标准并行推理减少高达84.7%的词元生成,同时保持或超越原有准确性。图1集中展示了关键实验结果。
对引言的批注
引言这一章其实主要就讲了三件事:
- 并行推理方法有困难:并行地生成大量推理轨迹并采用简单多数投票法得出最终答案会带来巨大的计算开销,而且边际收益递减现象严重
- 现有改进方法有缺陷:
- 第一,采用全局置信度方法过滤低质量轨迹可能掩盖局部推理步骤中的置信度波动,而这些波动恰好是评估轨迹质量的重要信号
- 第二,对轨迹中所有token进行平均会模糊关键推理中断现象(一、二其实说的是同一个问题,就是采用全局置信度方法会忽略掉推理过程中“少而致命”的错误)
- 第三,必须生成完整轨迹后才能计算全局置信度,无法实现低质量轨迹的提前终止。
- 需要我来:基于上述分析,DeepConf的提出便显得水到渠成。其核心贡献在于精准地回应了上述所有缺陷:
- 第一,局部感知:摒弃全局平均,转而捕捉局部置信度极小值(如“最低组置信度”),直接诊断推理链中的薄弱环节,从而更可靠地识别低质轨迹。
- 第二,提前终止:基于局部置信度实现在线实时决策,一旦发现轨迹质量低于阈值即刻终止,彻底解决了“必须生成完毕才能评估”的效率瓶颈。
- 第三,模式统一:提供离线与在线两种工作模式,一套方法同时应对“提升固定预算下的精度”与“动态节约计算成本”两大核心需求。
2 用置信度评估推理质量
近期研究表明,利用模型内部词元分布衍生的度量指标可有效评估推理轨迹的质量(Kang et al., 2025)。这些指标通过模型内在信号区分高质量推理路径与错误路径,无需依赖外部监督机制。
词元熵(Token Entropy) 给定语言模型在位置 i 预测的词元分布 ,其词元熵定义为:
![]() 其中,
其中, 表示第j个词元的概率。低熵值意味着概率分布集中,模型确定性高;而高熵值则反映预测中存在不确定性。
词元置信度(Token Confidence) 我们将位置 i 处的词元置信度 定义为前 k 个( top-k )词元的负平均对数概率:
 其中 k 表示所考虑的最高排名词元数量。高置信度对应尖峰分布状态,表明模型确定性较强;而低置信度则反映词元预测存在不确定性。
其中 k 表示所考虑的最高排名词元数量。高置信度对应尖峰分布状态,表明模型确定性较强;而低置信度则反映词元预测存在不确定性。
top-k采样:从语言模型预测的下一个词概率分布中保留概率最高的 k 个候选词,然后仅在这 k 个词中进行随机抽样的方法, 目的是在生成多样性和合理性之间取得平衡。
采样过程是从语言模型预测的下一个词概率分布中筛选出概率最高的k个候选词构成一个新集合, 随后将这个子集中的概率进行重新归一化(使其和为1),并基于此新的分布进行随机抽样,该方法旨在平衡生成内容的多样性与合理性。
轨迹平均置信度(Average Trace Confidence) 词元级指标需要聚合评估整个推理轨迹。遵循Kang等人(2025)的方法,我们采用平均跟踪置信度(亦称自我确定性)作为轨迹级别的质量衡量标准: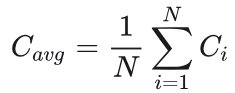 其中, N 代表生成词元的总数。如图2所示,平均轨迹置信度能有效区分正确与错误的推理路径,其值越高表明正确可能性越大。
其中, N 代表生成词元的总数。如图2所示,平均轨迹置信度能有效区分正确与错误的推理路径,其值越高表明正确可能性越大。
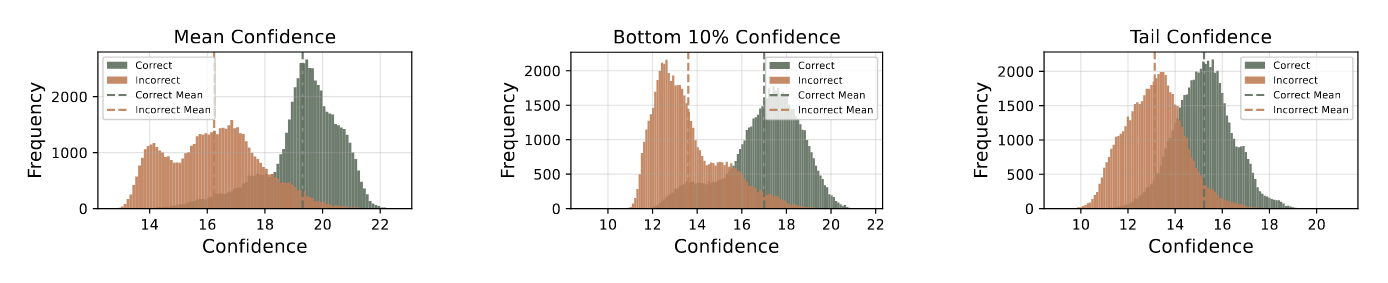
图2:不同指标下正确与错误推理轨迹的置信度分布。数据来源:HMMT25(30道题目,每条题目4096条推理轨迹)。
图中涉及到三种置信度: 平均置信度, Bottom-10%置信度和 尾部置信度,平均置信度已在前文说明,后两种置信度将在后续文章中进行介绍。
这张图的一个重要意义就是表明文章中的方法不是凭空产生的:其思路源于我们观察到置信度与准确率之间存在显著相关性(具体而言,正确轨迹与错误轨迹的置信度分布重叠程度很低),由此才引出了基于置信度加权的多数投票机制以及低置信度轨迹过滤策略。
或许可以通过搜索出一种分布重叠程度最低的置信度指标,以此作为有效识别和杜绝大语言模型产生幻觉的关键手段。
尽管该方法效果显著,平均轨迹置信度仍存在明显局限性:首先,全局聚合会掩盖中间推理错误——少数高置信度标记可能掩盖大量低置信度片段,从而隐藏关键错误;其次,该方法需要完整轨迹才能进行质量评估,导致低质量生成过程无法提前终止,进而造成计算效率低下。
按照我的理解,应该是多数高置信度标记会掩盖少数致命错误。因为整个推理过程的有效性恰恰是由其中最薄弱的一环所决定的。
3 基于置信度的深度思考
本节阐述如何更有效地利用置信度指标,以同时提升推理性能与思维效率。我们聚焦两大核心场景:离线思考与在线思考。离线思考通过评估并整合已完成的推理轨迹中的信息,借助置信度提升推理性能;在线思考则在实时生成词元的过程中融入置信度机制,以提高推理性能和/或计算效率。
3.1 置信度度量
为了解决全局置信度量(如自我确信度)的局限性,我们引入了多种替代性置信度量方法,这些方法能够捕捉局部中间推理步骤的质量,并对推理轨迹提供更精细的评估。
组置信度(Group Confidence) 我们通过组置信度量化中间推理步骤的置信度。组置信度通过在推理轨迹的重叠区间上平均标记置信度,提供了更具局部性和平滑性的信号。每个标记均与一个滑动窗口相关联。 组 由 n 个先前标记组成(例如, n=1024 或 2048 ),且采用重叠相邻窗口。对于每个组
,组置信度定义为:
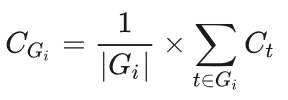
其中 表示组
中的token数量。
评估推理轨迹质量需整合组置信度中的信号。我们观察到,轨迹中置信度极低的中间步骤会显著影响最终解的正确性。例如,当推理过程中因反复出现"wait"、"however"、"think again"等低置信度标记而导致置信度急剧下降时,会破坏推理流程的连贯性并引发后续错误。
根据我的理解,这里的组划分是指将轨迹 τ 按一定规则切割成多个长度相等(除最后一段外)且前后相互重叠的段。例如,在窗口大小 n=1024 ,重叠长度 l=24 的设置下,对于长度为 L 的轨迹 τ[0,L),可将其划分为如下若干组:

其中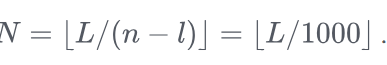
Bottom 10%组置信度(Bottom 10% Group Confidence) 为捕捉极低置信度组的影响,我们提出后Bottom 10%组置信度指标,该指标通过轨迹中置信度最低的10%组的平均值来确定轨迹置信度:![]() 其中
其中 代表置信度得分最低的10%的组别集合。实证研究表明,10%的阈值能有效捕捉不同模型和数据集中问题最严重的推理段落。
最低组置信度(Lowest Group Confidence) 我们还考虑了最低组置信度指标,它代表推理轨迹中置信度最低组的置信水平——这是后10%组置信度的特例。该度量仅基于最低置信度组来评估轨迹质量:![]() 其中 G 是推理轨迹中所有词元组的集合。我们将探讨在线思考场景中最低组置信度如何提升推理效率。
其中 G 是推理轨迹中所有词元组的集合。我们将探讨在线思考场景中最低组置信度如何提升推理效率。
计算这两个置信度,主要是为了识别并应对整个推理过程中最不可靠的薄弱环节。
尾部置信度(Tail Confidence) 除基于组别的度量外,我们提出尾部置信度指标,通过关注推理轨迹的末尾部分来评估其可靠性。该指标的提出基于以下观察:长思维链的推理质量往往在末尾下降,而最终步骤对得出正确结论至关重要。在数学推理中,最终答案和结论步骤尤为关键:起始强劲但结尾薄弱的推理轨迹可能导致错误结果,尽管其中间推理过程看似良好。尾部置信度 定义为:
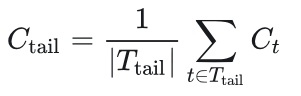 其中
其中 代表固定数量的词元(如2048个)。图2对比了不同置信度度量方法,表明与均值置信度方法相比,后10%组置信度和尾部置信度能更好地区分错误与正确轨迹的分布,说明这些指标在轨迹质量评估中更具有效性。
尾部置信度旨在捕捉模型在推理末尾突然发生的自我否定行为。例如,模型在生成完整答案前,突然附加一句 “不对,我错了”。
3.2 基于置信度的离线思考
本文现阐述如何应用多种置信度测量方法提升离线场景中的推理性能。在离线思维模式下,每个问题的推理轨迹均已生成,核心挑战在于如何聚合多轨迹信息以更精准地确定最终答案。尽管近期研究提出了使用大语言模型进行推理轨迹摘要与分析的高级方法,我们仍聚焦于标准多数投票方法。
简单多数投票(Major Voting):在简单多数投票中,每条推理轨迹提取的最终答案对决策具有同等权重。设 T 为所有生成轨迹的集合,对于每个轨迹 t∈T ,令 answer(t) 表示从轨迹 t 中提取的答案字符串。则候选答案 a 的计票公式为:![]()
其中, I{·} 为指示函数。最终答案通过最高票数选定:![]()
例如,对于问题 1+1=? ,若轨迹 A,B 给出的答案是 2 ,轨迹 C 给出的答案是 (10)2 ,那么在简单多数投票的情景下,答案 2 得两票,答案(10)2得一票,答案 2 胜选,最终答案为 2
置信度加权的多数投票(Confidence-Weighted Majority Voting) 不同于对每个推理轨迹的投票赋予同等权重,我们根据相关轨迹的置信度对每个最终答案进行加权处理。对于每个候选答案 a ,我们定义其总投票权重为: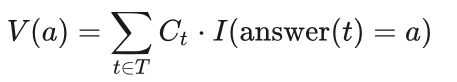 其中,
其中, 是从上述置信度度量中选出的轨迹级别置信度。我们选择具有最高加权票数的答案。该投票方案倾向于由高置信度轨迹所支持的答案,从而减少不确定或低质量推理答案的影响。
例如,对于问题 1+1=? ,若轨迹 A 以置信度0.7给出答案 2 ,轨迹 B,C 以置信度0.1给出答案 (10)2 ,那么在置信度加权的多数投票的情景下,答案 2 得0.7票,答案(10)2得0.2票,答案 2 胜选,最终答案为 2
与之相对的,在简单多数投票的情景下,答案 (10)2 会以两票对一票的优势胜出。
置信度筛选。除加权多数投票外,我们采用置信度筛选机制以聚焦高置信度的推理轨迹。该机制根据轨迹置信度分数选取前 η 百分比的轨迹,确保仅最可靠的路径参与最终答案生成。我们提供两种置信度阈值选项: η=10% 与 η=90% 。
前10%选项聚焦最高置信度轨迹,适用于预期仅少数可靠轨迹即可产生准确结果的情景。但若模型存在偏差,依赖过少轨迹可能增加错误风险。前90%选项采用更平衡的策略,通过纳入更广泛的轨迹保持多样性并降低模型偏差,这在置信度分布趋于均匀时能有效保障替代推理路径的考量。图3展示了置信度测量机制及离线思考如何与置信度协同工作的示意图,算法1则提供了详细实现流程。
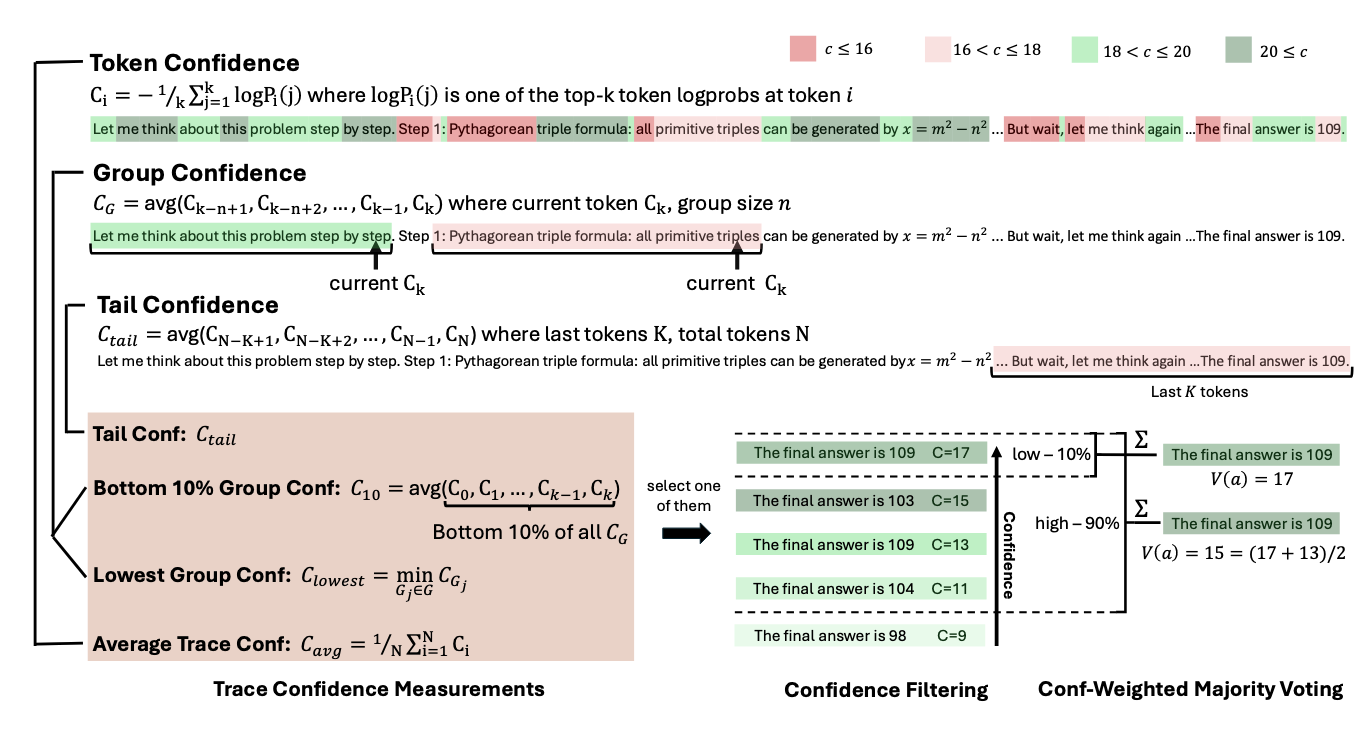
图3:置信度测量与离线置信度思考。
3.3 基于置信度的在线思考
在线思考过程中的置信度评估能够在生成时实时轨迹质量,从而动态终止无前景的推理路径。这种方法在资源受限的环境或需要快速响应的场景中尤为重要。最低组置信度指标可有效应用于此类在线场景:当词元组置信度低于临界阈值时立即停止轨迹生成,确保此类低质量轨迹在后续置信度筛选中必然被排除。
我们提出了DeepConf-low和DeepConf-high这两种基于最低组置信度的算法,它们能够在在线思考过程中自适应地停止生成并调整轨迹预算。该方法包含两个核心组件:离线预热与自适应采样。
离线预热(Offline Warmup) DeepConf需要一个离线预热阶段来设定在线判定所需的停止阈值 s 。针对每个新提示,我们生成 条初始推理轨迹(例如
=16 )。停止阈值 s 的定义为:
![]() 其中
其中 代表所有预热轨迹,
表示轨迹t的置信度,η为预设保留比例。具体而言,DeepConf-low统一采用前 η=10% (即第90百分位数),而DeepConf-high在所有设置中统一采用前 η=90% (即第10百分位数)。该阈值确保在线生成过程中,当轨迹置信度低于预热阶段最高置信度前 η% 轨迹的水平时,将终止轨迹生成。
自适应采样(Adaptive Sampling) 在DeepConf中,我们采用跨所有方法的自适应采样策略,根据问题难度动态调整生成的轨迹数量(Xue et al., 2023)。难度评估基于生成轨迹间的共识度,通过多数投票权重 与总投票权重
的比值量化:
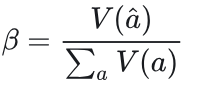 是预设的共识阈值。若 β<τ ,表示当前问题未达成共识,系统将继续生成轨迹直至达到固定预算 B ;反之则立即终止轨迹生成,并基于现有追踪确定最终答案。由于采用最低组置信度策略,足够大的预热集能准确估计停止阈值 s ,因此任何在线终止的轨迹其组置信度均低于 s ,且会被离线过滤器排除。该在线过程近似模拟了离线最低组置信度策略,其精度随初始轨迹数 Ninit 增加而趋近离线精度(详见附录 B.2 )。图4展示了在线生成流程,算法2则提供了具体实现细节。
是预设的共识阈值。若 β<τ ,表示当前问题未达成共识,系统将继续生成轨迹直至达到固定预算 B ;反之则立即终止轨迹生成,并基于现有追踪确定最终答案。由于采用最低组置信度策略,足够大的预热集能准确估计停止阈值 s ,因此任何在线终止的轨迹其组置信度均低于 s ,且会被离线过滤器排除。该在线过程近似模拟了离线最低组置信度策略,其精度随初始轨迹数 Ninit 增加而趋近离线精度(详见附录 B.2 )。图4展示了在线生成流程,算法2则提供了具体实现细节。
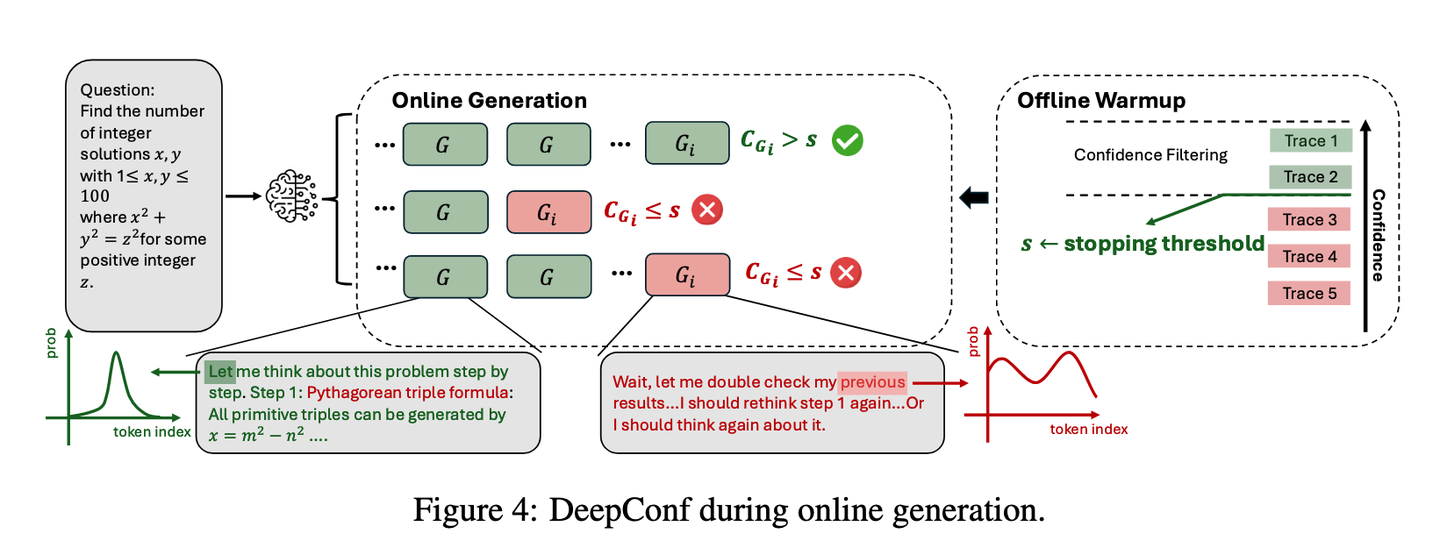
图4:DeepConf在线生成过程示意图。
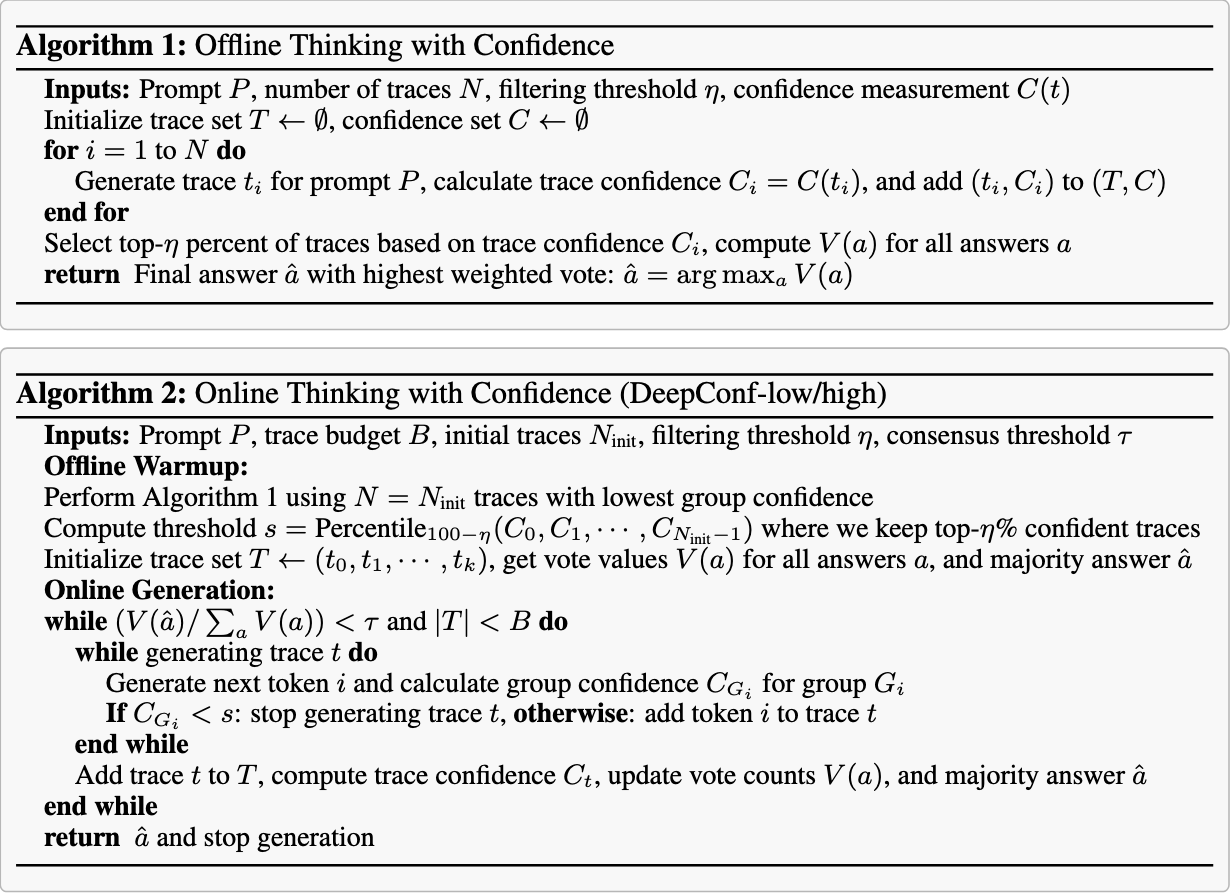
算法1和算法2
文章正文中提到 “在线过程近似模拟了离线最低组置信度策略,其精度随初始轨迹书数 Ninit 增加而趋近离线精度(详见附录 B.2 )”。这里把附录 B.2 内容贴上
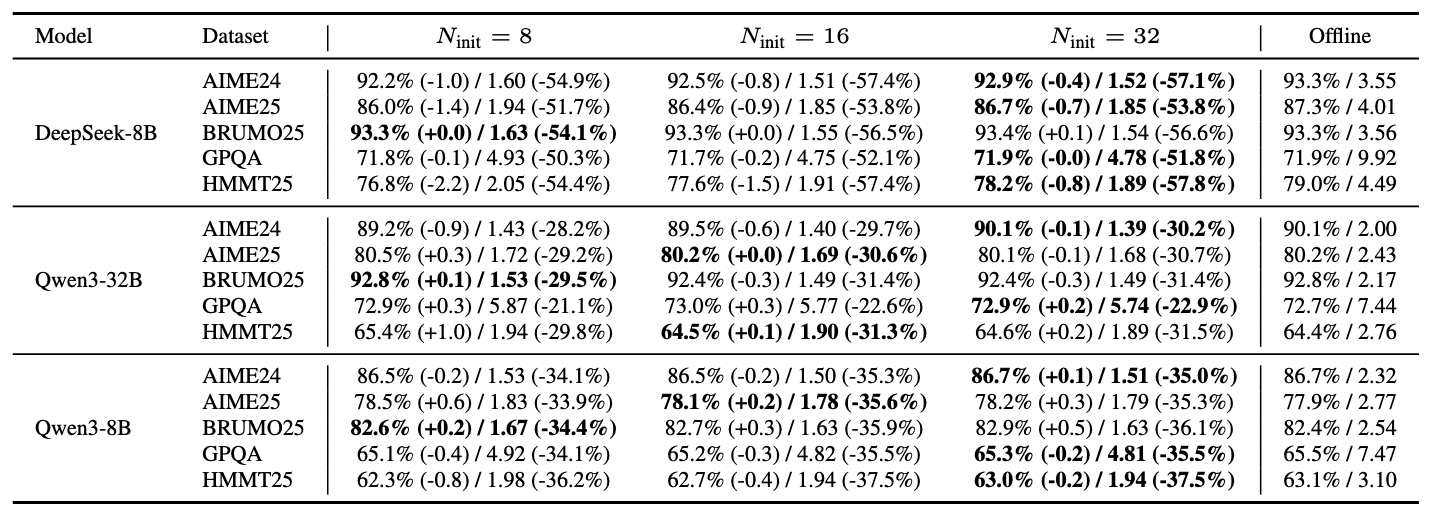
B.2 关于预热采样规模的消融实验
表4比较了在DeepConf-low设置(按置信度取前 η=10% )下,预热规模 ∈{8,16,32} 与仅预算在线的DeepConf方法在投票预算B=512时的表现。通过跨模型和数据集的实验我们观察到:增大 Ninit 可稳定用于设定阈值 s 的经验置信度分布,实践中通常能使在线准确率更接近离线基线(更小的 |ΔAcc| );但阈值与准确率的关系受模型和数据集影响,未必单调提升。在计算量方面,净效应受两个因素驱动:(1)固定预热成本增加(因所有
轨迹需完整运行);(2)剩余 B−
轨迹的后预热阶段提前终止率。由于这两个因素相互制约,总计算量使用量也未必随
单调变化。实验数据显示,不同预热规模下的|ΔAcc|差异较小(通常 ≤1.0 个百分点)。因此我们采用
作为均衡默认值:在充分接近离线基线的同时,避免过度的预热开销。
表4:预热集大小 在固定投票预算B=512下的影响(在线模式,DEEPCONF-Low)。各在线单元格汇报准确率(%)及百分比点差值,以及代币使用量(×10⁸)及相对差值(%),均以B=512的离线基线为参照(保留前 η=10% ;最低组置信度)。加粗标记在线准确率最接近离线基线的预热集大小(最小 |ΔAcc| )。末列"离线"汇报 B=512 时的基线值(准确率/token消耗量)。
4 实验
4.1 实验设置
模型 我们评估了来自三个模型系列的五个开源推理大语言模型:DeepSeek-8B(Guo等,2025)、Qwen3-8B与Qwen3-32B(Yang等,2025a)、GPT-OSS-20B以及GPT-OSS-120B(OpenAI,2025)。这些模型以卓越的数学推理能力和长思维链性能著称,均为完全开源以确保可复现性,并覆盖了多规模参数量级以测试鲁棒性。完整的生成超参数及提示模板详见附录F。
注意:这里的DeepSeek-8B实际指的是基于 DeepSeek-R1(0528)模型蒸馏而得的 Qwen3-8B 模型:
基准测试 我们在五个具有挑战性的数据集上进行评估:AIME24(Art of Problem Solving, 2024a;b)、AIME25(Art of Problem Solving, 2025a;b)、BRUMO25(bru, 2025)、HMMT25(HMMT, 2025)以及GPQA(Rein et al., 2024)。前四个数据集为高难度数学竞赛题目,而GPQA包含研究生级别的STEM推理任务。所有基准测试均被近期顶级推理大语言模型评估广泛采用(例如Grok-4(xAI, 2025)、Qwen3(Yang et al., 2025a)、GPT-5(OpenAI, 2025)),并收录于MathArena排行榜(Balunović et al., 2025)。
基线方法 我们采用自洽性(Wang et al., 2023)结合多数投票作为主要基线。每个大语言模型采样T条独立推理路径,并通过无加权多数投票选择最终答案,具体形式化定义见第3.2节。
实验设置 针对每个问题,我们通过预先生成包含4096条完整推理轨迹的样本池建立统一抽样框架,该样本池为离线和在线评估提供基础。离线实验每次运行时从该池中重新抽样生成规模为 K (如 K=512 )的工作集,并应用指定的投票方法。在线实验同样通过重抽样工作集来驱动具有提前停止机制的实时生成;该样本池确保不同方法间抽样的一致性。
我们报告四种关键方法:(i)Pass@1(单轨迹准确率),(ii)Cons@K(基于K条轨迹的未加权多数投票准确率),(iii)Measure@K(置信度加权多数投票准确率),以及(iv)Measure+top- η% @K——该方法在应用加权多数投票前保留抽样工作集中置信度最高的 η% 轨迹(我们采用 η∈{10,90} )。具体置信度度量因设置而异。同时报告生成的总标记数。所有指标均通过64次独立重抽样运行取平均值;除非特别说明,标记数按端到端方式统计所有生成轨迹,提前终止的轨迹仅计入停止前产生的标记。
对于在线评估,我们使用最低组置信度并采用2048个标记的重叠窗口来实例化DeepConf-low和DeepConf-high。每个问题开始时使用 =16 条完整轨迹进行离线预热;随后设置运行特定的停止阈值
![]() 。
。
其中, 包含置信度最高的前百分比轨迹(DeepConf-low取 η=10 ,DeepConf-high取 η=90 ;见第3.3节)。生成过程中,当前组置信度低于阈值s的轨迹会被提前终止;已完成的轨迹通过置信度加权多数投票进行聚合,且一旦达成共识( ≥τ )或达到预算 K 时,生成过程自适应停止。在离线评估中,我们基于第3.1节的三种轨迹级置信度定义进行基准测试:(i)平均轨迹置信度,(ii)末10%组置信度,以及(iii)最后2048个词元的尾部置信度(公式7)。针对每个指标,我们报告Measure@K和Measure+top- η% @ K ( η∈10,90 ),其中 top-η% 截断值在每次运行的采样工作集中重新计算(第3.2节)。
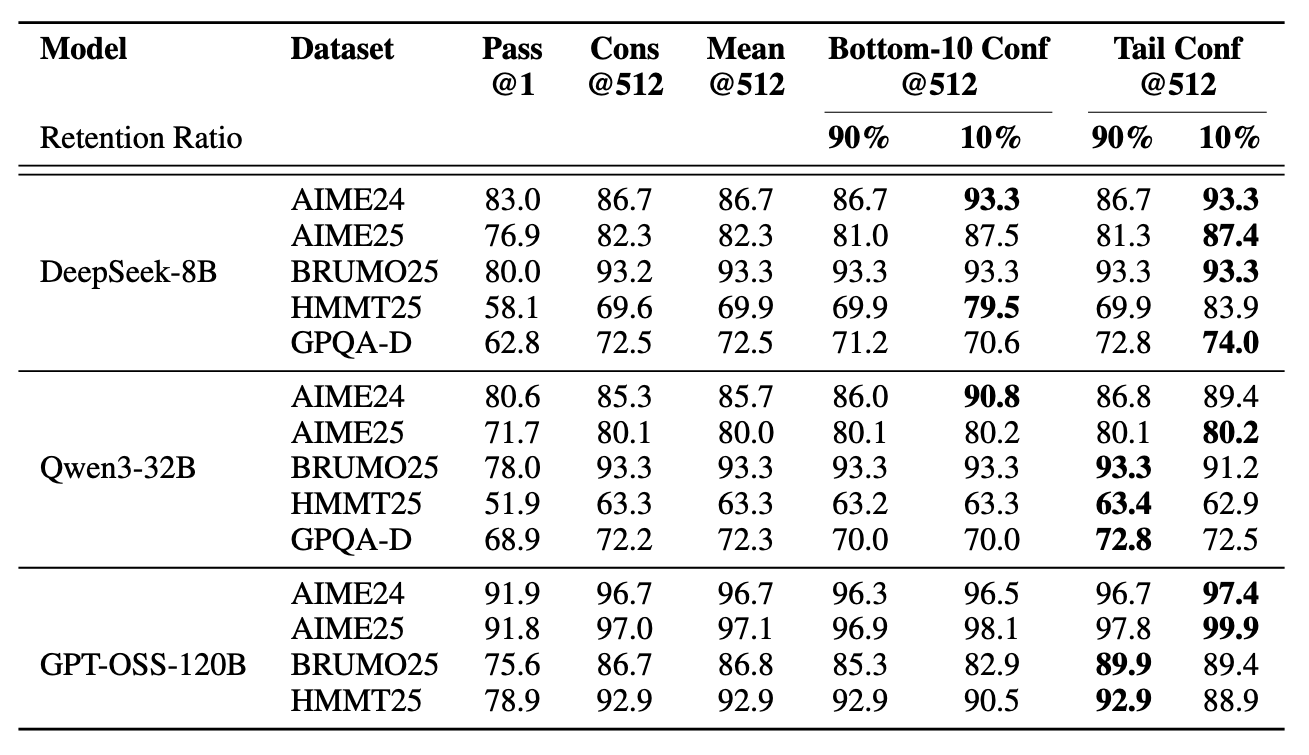
表1:离线设置下的置信度测量基准测试。报告了准确率(%)。Cons@512和mean@512分别表示使用512条轨迹进行多数投票和平均置信度。所有实验均重复进行64次。
4.2 离线评测
我们在表1中展示了三种模型在五个数据集上、投票规模 K=512 的离线实验结果。对比方法包括:Pass@1 = 单次轨迹准确率;Cons@512 = 基于512条轨迹的未加权多数投票;Mean@512 = 使用平均轨迹置信度(公式3)的置信度加权多数投票;Bottom-10% Conf@512与Tail Conf@512 = 分别采用(i)重叠组最低10%置信度均值(公式5)和(ii)最后2048个标记的平均置信度的置信度加权多数投票。 90%/10% 子列表示置信度过滤中的保留比例η:在投票前,我们保留采样工作集中置信度最高的前 η% 轨迹。例如当 K=512 且 η=10% 时,我们保留约51条轨迹进行投票。
总体而言,在大多数设置中,采用置信度加权与筛选的方法持续优于标准多数投票法(Cons@512)。当筛选阈值设为 η=10% 时收益最大,例如DeepSeek-8B在AIME25上的显著提升( 82.3%→87.4% )以及Qwen3-32B在AIME24上的进步( 85.3%→90.8% );GPT-OSS-120B甚至在AIME25上达到 99.9% 的准确率。局部置信度度量(尾部置信度和Bottom 10% 置信度)与全局置信度度量(平均轨迹置信度)在识别高置信度轨迹方面均展现出良好效果。但筛选策略存在重要权衡:虽然激进筛选( η=10% )在多数情况下能最大化准确率增益,但有时会因模型对错误问题的过度自信而损害性能(如GPT-OSS-120B的案例)。此类情况下,保守筛选( η=90% )是更安全的选择。所有方法相比pass@1均观察到显著改进,印证了集成方法的价值。详细置信度度量对比见附录B.4。

图 5:采用最低组置信度过滤(DeepSeek-8B)在 AIME24、AIME25、BRUMO25 和 HMMT25 上的离线准确率。其中 η% 变体仅在置信度加权多数投票前保留前 η% 最高置信度的轨迹数据。
随后我们证明最低组置信度方法同样有效。图5展示了采用最低组置信度(公式6)捕捉每条轨迹中最不置信的token组(窗口大小2,048)的离线实验结果。在每个采样的工作集中,我们保留置信度最高的前 η% 轨迹,并采用置信度加权多数投票法。在DeepSeek-8B模型上的AIME24、AIME25、BRUMO25和HMMT25测试中,保留前 η=10% 最高置信度轨迹相比多数投票法的最佳准确率持续提升:增幅达+0.26至+9.38个百分点(平均+5.27),较单条轨迹(无投票)准确率提升显著(+10.26至+20.94个百分点;平均+14.30)。保守设置 η=90% 时,在四个数据集上均达到或略超多数投票最佳准确率(+0.16至+0.57个百分点;平均+0.29),同时较单条轨迹准确率仍有大幅提升(平均+9.31)。这些结果为在线版本提供了依据:聚焦最低置信段能可靠识别局部推理失效的轨迹,既为离线过滤提供强信号,又为在线生成过程提供自然停止准则。
除上述结果外,我们在附录B.3中对保留率 η 进行消融研究,并在附录C中提供完整离线实验结果。
4.3 在线评测
在本节中,我们通过调整预算 K∈{32,64,128,256,512} 来评估在线算法的精度-成本权衡,其中成本计算所有生成的token(包括早期终止轨迹产生的部分token)。根据第3.3节,我们使用 =16 条轨迹进行预热,通过最低组置信度(窗口大小2,048)设置停止阈值 s :根据置信度在预热轨迹的前 η% 范围内设定 s ( η∈{10,90} ),随后当任何新轨迹的当前组置信度低于s时立即终止。每条新轨迹完成后,我们重新应用相同的阈值s进行过滤,该流程既匹配离线版最低组置信度过滤器的逻辑,又节省了早期终止轨迹的成本。我们考虑两种在线变体:DeepConf-low( η=10% )和DeepConf-high( η=90% ),它们会持续采样直至共识度 ≥τ (取 τ=0.95 )或达到预算上限 K 。与纯预算变体(始终运行至上限 K 且无共识终止)及不同τ值的对比实验详见附录B.1。
表2展示了DeepConf自适应采样版本在投票规模预算K=512时于DeepSeek-8B/Qwen3-32B/GPT-OSS-120B上的性能表现。与多数投票基线相比,DeepConf-low在AIME24/AIME25/BRUMO25/HMMT25数据集上减少了43-79%的token消耗。尽管在多数情况下其精度持平或提升(如DeepSeek-8B AIME24: +5.8%),但在部分场景中出现显著精度下降(如Qwen3-32B BRUMO25: −0.9%)。更保守的DeepConf-high在这些数据集上节省了18-59%的token,同时保持了近乎一致的精度或仅出现极小性能损失。图6可视化展示了GPT-OSS-120B的token缩减模式,说明DeepConf如何在保持不同数学推理任务竞争力的同时实现显著的计算节省(最高达85.8%)尽管在某些特定数据集上偶尔可能导致准确率略有下降(例如,表2中GPT-OSS-120B在HMMT25数据集上的表现)。
表2:在线设置下的DeepConf基准测试。多数投票和DeepConf(高/低)在投票规模预算为512时的准确率(%)和token消耗量( ×108 )。
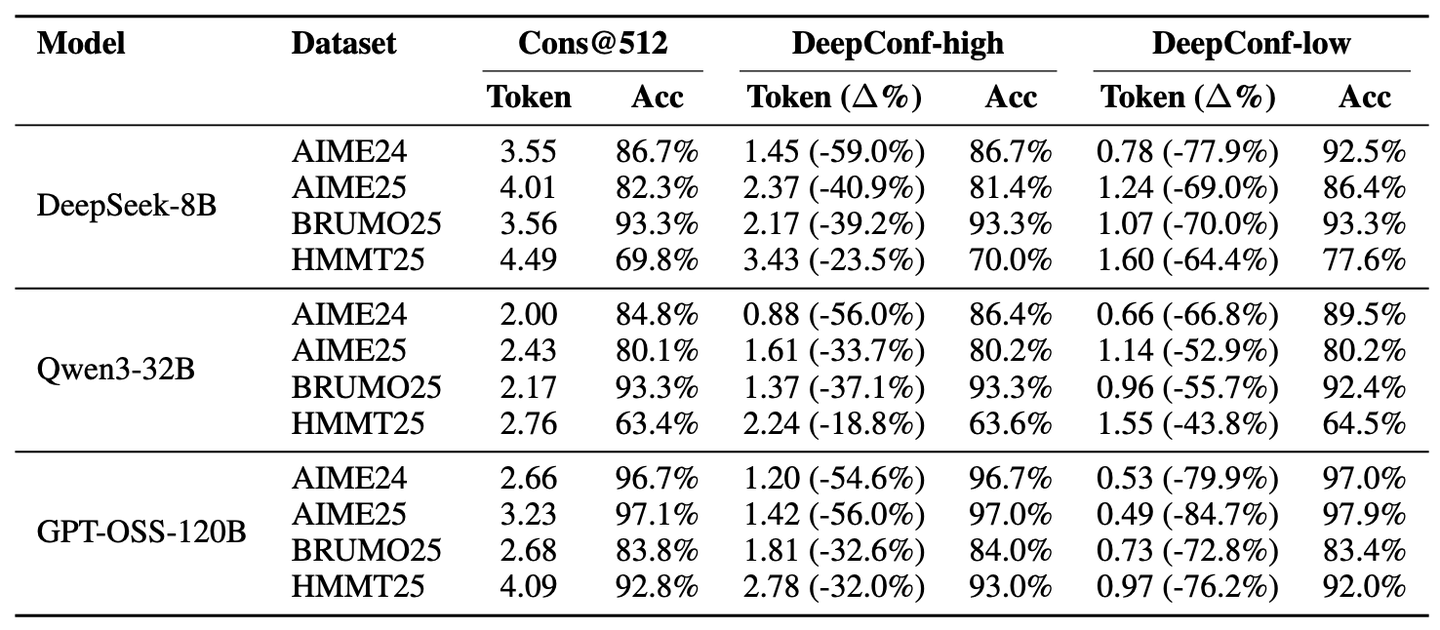

图6:基于GPT-OSS-120B模型在不同任务中的生成标记数量对比

图7:在线最低组置信度过滤(DeepSeek8B)在AIME24、AIME25、BRUMO25和HMMT25数据集上的准确率与生成标记数量的关系。高/低置信度分别表示保留置信度排名前90%/10%的轨迹进行投票。
这些结果验证了我们的设计:采用置信度最低的片段作为追踪门控机制,能够为早期终止提供强有力的局部信号,而自适应共识机制则能在保持准确性的前提下进一步压缩标记数量。
此外,我们在附录B.2中对预热规模Ninit进行了消融实验分析,并在附录D中提供了完整的在线实验结果。
5 未来工作
本研究衍生出多个值得探索的方向。首先,将DeepConf扩展到强化学习场景中,可利用基于置信度的早停机制来指导策略探索,并提升训练过程中的采样效率。其次,需要解决模型在错误推理路径上表现出高置信度的问题——这在我们的实验中是一个关键局限性。未来的工作还可探索更鲁棒的置信度校准技术和不确定性量化方法,以更好地识别并缓解过度自信但错误的预测。
6 结论
我们提出DeepConf方法——一种简洁而高效的技术,显著提升了集成投票场景中的推理性能与计算效率。通过在顶尖推理模型和挑战性数据集上进行广泛实验,DeepConf在实现显著准确率提升的同时有效减少了计算量消耗,这种增益效应在8B至120B参数规模的不同模型中均得到验证。我们期待该方法能彰显测试时压缩技术的潜力,为高效大语言模型推理提供实用且可扩展的解决方案。

分享最新、最前沿的AI大模型技术,吸纳国内前几批AI大模型开发者
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)