
新手必看!LangGraph 101:手把手教你搭一个深度研究 Agent,大模型入门到精通,收藏这篇就足够了!
谷歌通过开源了一个使用 LangGraph 和 Gemini 构建的全栈式深度研究代理的实现版本(采用 Apache-2.0 许可证)完美地展示了这一点。
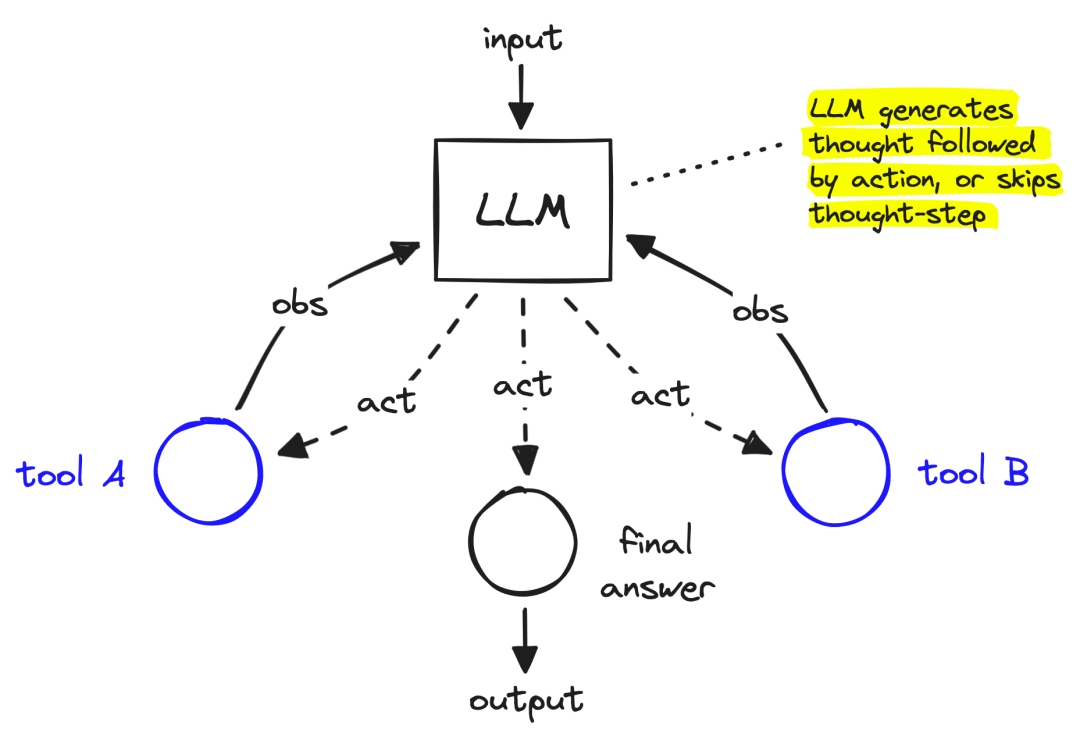
构建能够在实际中真正发挥作用的大型语言模型(LLM)程序并非易事。
您需要考虑如何协调这一多步骤的工作流程,跟踪各参与者的状态,实施必要的限制措施,并实时监控决策过程。
幸运的是,LangGraph 正好解决了您所面临的那些难题。
最近,谷歌通过开源了一个使用 LangGraph 和 Gemini 构建的全栈式深度研究代理的实现版本(采用 Apache-2.0 许可证)完美地展示了这一点。
这并非是一个简单的演示版本:该代理不仅能够进行搜索,还能动态评估搜索结果,从而决定是否需要进一步搜索以获取更多信息。这种迭代式的操作流程正是 LangGraph 所擅长的领域。
所以,如果您想了解 LangGraph 在实际应用中的运作方式,那么从这样一个实际运行的代理系统入手岂不是再合适不过了吗?
最终,您不仅会拥有一名能正常工作的研究助手,而且还会掌握足够的 LangGraph 知识,从而能够构建接下来的任何项目。
以下是这篇帖子的可视化路线图:
Figure 1. Table of Contents for this post.
- The Big Picture — Modeling the Workflow with Graphs, Nodes, and Edges
The problem
在本次案例研究中,我们将构建一个令人兴奋的东西:一个LLM-based research-agumented agent,它将是对您在 ChatGPT、Gemini、Claude 或 Perplexity 中已经见过的深度研究功能的最简复现。这就是我们在此的目标。
具体而言,我们的agent的工作方式将会是这样的:
它会接收用户的查询请求,自主地在网络上进行搜索,审视所获取的搜索结果,然后判断是否已经找到了足够的信息。如果找到了足够的信息,它就会着手创建一份精心编写的简短报告,并附上恰当的引用;否则,它会再次进行更深入的搜索以获取更多信息。
首先,让我们先绘制一个大致的流程图,以便我们清楚地了解我们正在构建的内容:
Figure 2. High-level flowchart
LangGraph’s solution
那么,我们该如何在 LangGraph 中对这种工作流程进行建模呢?其实,正如其名称所示,LangGraph 采用的是图表示法。那么,为什么要使用图呢?
简而言之就是:图非常适合用于模拟复杂且具有状态的流程,就像我们在此要构建的应用程序一样。当你遇到分支决策、需要循环回的循环以及现实世界中的所有那些复杂情况(这些都会给实际的代理工作流程带来诸多挑战)时,图能为你提供一种最自然的方式来呈现这一切。
从技术层面来讲,图由节点和边组成。在 LangGraph 的体系中,节点代表工作流程中的单个处理步骤,而边则表示步骤之间的转换,即定义了控制流和状态在系统中的流动方式。
</> Let’s see some code!
在 LangGraph 中,从流程图到代码的转换非常直接。让我们看看 Google 代码库中的 agent/graph.py 文件,了解具体是如何实现的。
第一步是创建图形本身:
from langgraph.graph import StateGraphfrom agent.state import ( OverallState, QueryGenerationState, ReflectionState, WebSearchState,)from agent.configuration import Configuration# Create our Agent Graphbuilder = StateGraph(OverallState, config_schema=Configuration)
在这里,StateGraph 是 LangGraph 的构建器类,用于构建具有 state-aware 的图。它接受一个 OverallState 类,该类定义了可以在节点之间传递的信息(这是我们将在下一节讨论的代理内存部分),以及一个 Configuration 类,该类定义了运行时可调参数,例如在各个步骤调用哪个 LLM、生成的初始查询数量等。更多细节将在接下来的章节中介绍。
一旦我们有了图容器,就可以向其中添加节点:
# Define the nodes we will cycle betweenbuilder.add_node("generate_query", generate_query)builder.add_node("web_research", web_research)builder.add_node("reflection", reflection)builder.add_node("finalize_answer", finalize_answer)
add_node() 方法的第一个参数表示节点的名称,第二个参数则为当节点运行时要执行的可调用函数。
一般来说,这个可调用对象可以是普通函数、异步函数、LangChain Runnable,甚至还可以是另一个编译后的状态图。
在我们具体的情况中:
- •
generate_query函数会根据用户的问题生成搜索查询语句。 - •
web_search通过使用谷歌原生的搜索 API 工具来进行网络研究。 - •
reflection能够发现知识上的不足之处,并提出可能的后续问题。 - •
finalize_answer表示完成研究总结。
我们稍后会详细探讨这些功能的具体实施情况。
好的,既然我们已经定义好了节点,接下来就要添加边来连接这些节点,并确定执行顺序:
from langgraph.graph import START, END# Set the entrypoint as `generate_query`# This means that this node is the first one calledbuilder.add_edge(START, "generate_query")# Add conditional edge to continue with search queries in a parallel branchbuilder.add_conditional_edges( "generate_query", continue_to_web_research, ["web_research"])# Reflect on the web researchbuilder.add_edge("web_research", "reflection")# Evaluate the researchbuilder.add_conditional_edges( "reflection", evaluate_research, ["web_research", "finalize_answer"])# Finalize the answerbuilder.add_edge("finalize_answer", END)
这里有几件事情需要指出:
- • 请注意,我们之前定义的那些节点名称(例如“generate_query”、“web_research”等)现在变得非常有用——我们可以在边的定义中直接引用它们。
- • 我们发现使用了两种类型的边,即静态边和条件边。
- • 当使用
builder.add_edge()这个方法时,会创建两个节点之间直接且无条件的连接。在我们的例子中,builder.add_edge("web_research", "reflection")实际上意味着在完成网络研究之后,流程将始终转移到“reflection”步骤。 - • 另一方面,当使用
builder.add_conditional_edges()这个方法时,流程在运行时可能会跳转到不同的分支。在创建条件边时,我们需要三个关键参数:源节点、路由函数以及可能的目标节点列表。路由函数会根据当前状态返回下一个要访问的节点的名称。例如,evaluate_research()函数会判断代理是否需要更多的研究(在这种情况下,前往web_research节点)或者是否已经有足够的信息使得代理能够最终确定答案(前往finalize_answer节点)。
但为什么“generate_query”和“web_research”之间需要一个条件边呢?难道不应该是一条静态边吗?因为我们总是要在生成查询之后再进行搜索,不是吗?说得好!这实际上与 LangGraph 如何实现并行化有关。我们稍后会深入探讨这个问题。
- • 我们还注意到两个特殊的节点:START 和 END。这是 LangGraph 自带的起始点和结束点。每个图都需要一个确切的起始点(即执行开始的地方),但可以有多个结束点(即执行结束的地方)。
最后,是时候将所有内容整合在一起,将图表编译成一个可执行的代理程序了:
graph = builder.compile(name="pro-search-agent")
就这样!我们已经成功地将流程图转换成了 LangGraph 的实现版本。
Bonus Read: Why Do Graphs Truly Shine?
除了非常适合非线性工作流程之外,LangGraph 的节点/边/图表示形式还带来了诸多实用优势,使得在现实世界中构建和管理代理变得十分简便:
- • 精细的控制与可观测性。由于每个节点/边都有其自身的标识,您可以轻松地检查进度,并在出现意外情况时深入查看内部情况。这使得调试和评估变得十分简单。
- • 模块化与复用。您可以将各个步骤组合成可复用的子图,就像乐高积木一样。让我们来谈谈实际应用中的软件最佳实践。
- • 并行路径。当您工作流程的某些部分是相互独立的时,图表能够轻松地让它们同时运行。显然,这有助于解决延迟问题,并使您的系统更能抵御故障,这一点在您的流程较为复杂时尤为重要。
- • 易于直观呈现。无论是进行调试还是展示方法,能够看到工作流程的逻辑总是很不错的。图表对于可视化来说是再自然不过的了。
Key takeaways
让我们回顾一下在这基础部分所讲的内容:
- • LangGraph 使用图形来描述代理流程,因为图形能够出色地处理分支、循环以及其他非线性流程。
- • 在 LangGraph 中,节点代表处理步骤,而边则表示步骤之间的转换。
- • LangGraph 实现了两种类型的边:静态边和条件边。当节点之间的转换是固定的时,使用静态边。如果这种转换在运行时可能会根据动态决策而发生变化,则使用条件边。
- • 在 LangGraph 中构建图非常简单。您首先创建一个状态图,然后添加节点(并指定其功能),再用边将它们连接起来。最后,您编译该图。完成!
Figure 3. Building agentic graph in LangGraph.
既然我们已经了解了基本结构,您可能就会疑惑:这些节点之间是如何传递信息的呢?这就引出了 LangGraph 中最重要的一个概念:状态管理。
- The Agent’s Memory — How Nodes Share Information with State
Figure 4. The current progress.
The problem
当我们的代理沿着我们之前定义的图表进行探索时,它需要记录下自己所生成/所学到的内容。例如:
- • 用户最初提出的问题。
- • 它所生成的搜索查询列表。
- • 它从网络上获取的内容。
- • 它对于所收集信息是否足够本身的内部评估。
- • 最终的、经过润色的答案。
那么,我们应当如何妥善保存这些信息,以确保我们的节点并非孤立运作,而是能够相互协作、共同推进并借鉴彼此的工作成果呢?
LangGraph’s solution
LangGraph 解决此问题的方法是引入一个中央状态对象,即一个可供图中的每个节点查看和编辑的共享白板。
这是它的工作原理:
- • 当一个节点被执行时,它会接收到图的当前状态。
- • 该节点使用状态中的信息来执行其任务(例如,调用语言模型,运行工具)。
- • 然后,该节点会返回一个仅包含其想要更新或添加的状态部分的字典。
- • LangGraph 会处理此输出,并自动将其合并到主状态对象中,然后再将其传递给下一个节点。
由于状态的传递和合并是由 LangGraph 在框架层面处理的,因此各个节点无需担心如何访问或更新共享数据。它们只需专注于自身的具体任务逻辑即可。
此外,这种模式使得您的代理工作流程具有高度的模块化特性。您可以轻松地添加、删除或重新排列节点,而不会破坏状态流程。
</> Let’s see some code!
还记得上一部分中的这一句话吗?
# Create our Agent Graphbuilder = StateGraph(OverallState, config_schema=Configuration)
我们之前提到,OverallState 定义了代理的内存,但尚未说明其具体实现方式。现在正是揭开这个“黑匣子”的好时机。
在该代码库中,OverallState 的定义位于 agent/state.py 文件中:
from typing import TypedDict, Annotated, Listfrom langgraph.graph.message import add_messagesimport operatorclass OverallState(TypedDict): messages: Annotated[list, add_messages] search_query: Annotated[list, operator.add] web_research_result: Annotated[list, operator.add] sources_gathered: Annotated[list, operator.add] initial_search_query_count: int max_research_loops: int research_loop_count: int reasoning_model: str
从本质上讲,我们可以看到所谓的“状态”其实就是一个类型字典,它充当着一份契约的作用。它明确了您的工作流程所关注的每一个字段,以及当多个节点对这些字段进行写入操作时,这些字段应该如何进行合并。让我们来详细解释一下:
- • Field purposes:
messages用于存储对话历史、search_query、web_search_result以及来源收集,这些字段用于跟踪代理的研究过程。其他字段通过设定限制和跟踪进度来控制代理的行为。 - • The Annotated pattern:我们注意到某些字段使用了
Annotated[list, add_messages]或Annotated[list, operator.add]这样的形式。其目的是让 LangGraph 明确在多个节点修改同一字段时应如何进行合并更新。具体而言,add_messages是 LangGraph 内置的用于智能合并对话消息的函数,而operator.add则在节点添加新项时将列表进行连接。 - • Merge behavior:诸如
research_loop_count: int这样的字段在更新时会直接替换原有的值。而带注释的字段则是累加式的。它们会随着时间的推移不断累积,因为不同的节点会向其中输入信息。
虽然 OverallState 充当着全局内存的角色,但或许最好也定义一些较小的、针对特定节点的状态,以作为明确的“API 规范”,说明一个节点所需的信息以及它所产生的内容。毕竟,通常情况下,某个特定节点并不需要整个OverallState中的所有信息,也不需要修改OverallState中的所有内容。
这正是 LangGraph 所做的事情。
在 agent/state.py 文件中,除了定义OverallState之外,还定义了另外三个状态:
class ReflectionState(TypedDict): is_sufficient: bool knowledge_gap: str follow_up_queries: Annotated[list, operator.add] research_loop_count: int number_of_ran_queries: intclass QueryGenerationState(TypedDict): query_list: list[Query]class WebSearchState(TypedDict): search_query: str id: str
这些状态是以如下方式被节点所使用的(在 agent/graph.py 文件中):
from agent.state import ( OverallState, QueryGenerationState, ReflectionState, WebSearchState,)defgenerate_query( state: OverallState, config: RunnableConfig) -> QueryGenerationState: # ...Some logic to generate search queries... return {"query_list": result.query}defcontinue_to_web_research( state: QueryGenerationState): # ...Some logic to send out multiple search queries...defweb_research( state: WebSearchState, config: RunnableConfig) -> OverallState: # ...Some logic to performs web research... return { "sources_gathered": sources_gathered, "search_query": [state["search_query"]], "web_research_result": [modified_text], }defreflection( state: OverallState, config: RunnableConfig) -> ReflectionState: # ...Some logic to reflect on the results... return { "is_sufficient": result.is_sufficient, "knowledge_gap": result.knowledge_gap, "follow_up_queries": result.follow_up_queries, "research_loop_count": state["research_loop_count"], "number_of_ran_queries": len(state["search_query"]), }defevaluate_research( state: ReflectionState, config: RunnableConfig,) -> OverallState: # ...Some logic to determine the next step in the research flow...deffinalize_answer( state: OverallState, config: RunnableConfig) -> OverallState: # ...Some logic to finalize the research summary... return { "messages": [AIMessage(content=result.content)], "sources_gathered": unique_sources, }
以 reflection 节点为例:它从“OverallState”中读取数据,但会返回一个符合“ReflectionState”协议的字典。随后,LangGraph 将负责将它们合并到主“OverallState”中,以便为图中的后续节点提供使用。
Bonus Read: Where Did My State Go?
在使用 LangGraph 进行工作时,一个常见的困惑在于“OverallState”与这些较小的、针对单个节点的状态之间是如何相互作用的。现在让我们来消除这个困惑。
我们需要建立的关键思维模式是:在运行时只存在一个状态字典,即“OverallState”。
节点特定的类型字典并非额外的运行时数据存储。相反,它们只是对一个基础字典(OverallState)进行的类型化的“视图”,能够暂时聚焦于节点应当查看或生成的特定部分。这些字典存在的意义在于,类型检查器和 LangGraph 运行时能够强制执行清晰的约定。
Figure 5. A quick comparison of the two state types.
在节点运行之前,LangGraph 可以利用其类型提示来创建一个“切片”,该切片包含 OverallState 中仅该节点所需的部分输入。
该节点执行其逻辑运算,并返回一个小型且特定的输出字典(例如,一个“ReflectionState”字典)。
LangGraph 会获取返回的字典,并调用 OverallState.update() 方法,传入该字典。如果某些键是通过聚合器(例如 operator.add)定义的,那么就会应用相应的逻辑。然后,更新后的 OverallState 将被传递给下一个节点。
那么,为什么 LangGraph 会采用这种两级状态定义呢?除了能为节点制定明确的规范并使节点操作具有自说明性之外,还有另外两个值得一提的好处:
- • Drop-in reusability:由于一个节点仅会公布其所需的状态片段以及生成的内容,因此它就变成了一个模块化的、可即插即用的组件。例如,一个仅需要从状态中获取
{user_query}并输出{queries}的generate_query节点,只要其所在的图的 OverallState 能够提供 user_query,就可以被插入到另一个完全不同的图中。如果该节点是基于整个 OverallState 编写的(即在输入和输出中都使用了 OverallState 类型),那么如果更改任何不相关的键,就很容易破坏工作流程。这种模块化对于构建复杂的系统来说非常重要。 - • Efficiency in parallel flows:假设我们的代理需要同时进行 10 次网络搜索。如果我们使用节点特定的状态作为较小的数据包,那么我们只需将搜索查询发送到每个并行分支即可。这比将整个代理内存的副本(要知道完整的聊天记录也存储在“OverallState”中!)发送到所有 10 个分支要高效得多。这样一来,我们就能大幅减少内存和序列化开销。
那么,这对我们而言在实际操作中意味着什么呢?
- • ✔ 在“OverallState”中声明所有需要持久保存或需能被多个不同节点访问的键。
- • ✔ 尽量将节点特定的状态设计得尽可能简单。这些状态应仅包含该节点负责生成的字段。
- • ✔ 您所编写的每一个关键值都必须在某个状态模式中进行声明;否则,当节点尝试写入该值时,LangGraph 会抛出
InvalidUpdateError错误。
Key takeaways
让我们回顾一下本节所讲的内容:
- • LangGraph 在两个层面上维护状态:在全局层面上,有一个名为“OverallState”的对象作为核心存储单元。而在单个节点层面,会使用基于“TypedDict”的小型对象来存储节点特定的输入/输出信息。这样能够使状态管理保持清晰和有序。
- • 在每个步骤结束后,节点会返回最小化的输出字典,然后这些字典会被合并回中央内存(
OverallState)。合并操作是根据您自定义的规则(例如,对于列表使用operator.add)来进行的。 - • 节点是独立且模块化的。您可以轻松地将它们当作构建模块加以复用,从而创建新的工作流程。
Figure 6. Key points to remember in LangGraph state management.
现在我们已经了解了图表的结构以及状态是如何在其中流动的,但每个节点内部究竟发生了什么情况呢?现在让我们来探讨一下节点的操作。
- Node Operations — Where The Real Work Happens
Figure 7. The current progress.
我们的图表能够传输信息并保存状态,但在每个节点内部,我们仍然需要:
- • 确保语言模型输出的是正确格式。
- • 调用外部 API。
- • 同时进行多轮搜索。
- • 决定何时停止循环。
幸运的是,LangGraph 为您提供了多种切实可行的方法来应对这些挑战。让我们逐一探讨这些问题,每一点我们都将通过我们的工作代码库中的一个片段来详细说明。
3.1 Structured output
The problem
让语言模型生成一个 JSON 对象是很容易的,但解析自由文本形式的 JSON 在实际应用中却不太可靠。一旦语言模型使用不同的表述方式、添加不寻常的格式或者改变键的顺序,我们的工作流程就很容易偏离正轨。简而言之,我们在每个处理步骤中都需要有可保证、可验证的输出结构。
LangGraph’s solution
我们对语言模型进行限制,使其生成的输出符合预先设定的模式。这可以通过使用 llm.with_structured_output() 方法将 Pydantic 模式附加到语言模型调用上来实现,这是一个由每个 LangChain 聊天模型包装器(例如 ChatGoogleGenerativeAI、ChatOpenAI 等)提供的辅助方法。
Let’s see some code!
让我们来看一下 generate_query 节点,其任务是创建一个搜索查询列表。由于我们需要这个列表是一个干净的 Python 对象,而非混乱的字符串,以便让下一个节点能够对其进行解析,因此最好对输出模式进行约束,使用“SearchQueryList”(定义于“agent/tools_and_schemas.py”文件中):
from typing import Listfrom pydantic import BaseModel, Fieldclass SearchQueryList(BaseModel): query: List[str] = Field( description="A list of search queries to be used for web research." ) rationale: str = Field( description="A brief explanation of why these queries are relevant to the research topic." )
以下是此架构在generate_query节点中的应用方式:
from langchain_google_genai import ChatGoogleGenerativeAIfrom agent.prompts import ( get_current_date, query_writer_instructions,)defgenerate_query( state: OverallState, config: RunnableConfig) -> QueryGenerationState: """LangGraph node that generates a search queries based on the User's question. Uses Gemini 2.0 Flash to create an optimized search query for web research based on the User's question. Args: state: Current graph state containing the User's question config: Configuration for the runnable, including LLM provider settings Returns: Dictionary with state update, including search_query key containing the generated query """ configurable = Configuration.from_runnable_config(config) # check for custom initial search query count if state.get("initial_search_query_count") isNone: state["initial_search_query_count"] = configurable.number_of_initial_queries # init Gemini 2.0 Flash llm = ChatGoogleGenerativeAI( model=configurable.query_generator_model, temperature=1.0, max_retries=2, api_key=os.getenv("GEMINI_API_KEY"), ) structured_llm = llm.with_structured_output(SearchQueryList) # Format the prompt current_date = get_current_date() formatted_prompt = query_writer_instructions.format( current_date=current_date, research_topic=get_research_topic(state["messages"]), number_queries=state["initial_search_query_count"], ) # Generate the search queries result = structured_llm.invoke(formatted_prompt) return {"query_list": result.query}
在这里,llm.with_structured_output(SearchQueryList) 会将 Gemini 模型与 LangChain 的结构化输出辅助工具进行封装。其内部机制是利用模型所支持的结构化输出特性(对于 Gemini 2.0 Flash 而言为 JSON 模式),并自动将回复解析为 SearchQueryList Pydantic 实例,因此结果已经是经过验证的 Python 数据了。
此外,查看谷歌为这个节点所使用的系统提示信息也很有趣:
query_writer_instructions = """Your goal is to generate sophisticated and diverse web search queries. These queries are intended for an advanced automated web research tool capable of analyzing complex results, following links, and synthesizing information.Instructions:- Always prefer a single search query, only add another query if the original question requests multiple aspects or elements and one query is not enough.- Each query should focus on one specific aspect of the original question.- Don't produce more than {number_queries} queries.- Queries should be diverse, if the topic is broad, generate more than 1 query.- Don't generate multiple similar queries, 1 is enough.- Query should ensure that the most current information is gathered. The current date is {current_date}.Format: - Format your response as a JSON object with ALL three of these exact keys: - "rationale": Brief explanation of why these queries are relevant - "query": A list of search queriesExample:Topic: What revenue grew more last year apple stock or the number of people buying an iphone```json{{ "rationale": "To answer this comparative growth question accurately, we need specific data points on Apple's stock performance and iPhone sales metrics. These queries target the precise financial information needed: company revenue trends, product-specific unit sales figures, and stock price movement over the same fiscal period for direct comparison.", "query": ["Apple total revenue growth fiscal year 2024", "iPhone unit sales growth fiscal year 2024", "Apple stock price growth fiscal year 2024"],}}\```Context: {research_topic}"""
我们看到了一些有效的工程实践方法在实际应用中发挥作用,比如明确模型的角色、设定限制条件、提供示例以作说明等等。
3.2 Tool calling
The problem
要使我们的研究工具取得成功,就需要从网络上获取最新的信息。要实现这一点,就需要一个用于搜索网络的“工具”。
LangGraph’s solution
节点能够执行工具。这些工具可以是原生的大型语言模型调用功能(如在“Gemini”中那样),也可以通过“LangChain’”的工具抽象方式进行集成。一旦收集到工具调用的结果,就可以将其重新放入代理的状态中。
Let’s see some code!
对于工具调用的使用模式,让我们来看一下“web_research”节点。该节点利用 Gemini 的原生工具调用功能来进行谷歌搜索。请注意,工具的指定方式直接在模型的配置中完成。
from langchain_google_genai import ChatGoogleGenerativeAIfrom agent.prompts import ( web_searcher_instructions,)from agent.utils import ( get_citations, insert_citation_markers, resolve_urls,)defweb_research( state: WebSearchState, config: RunnableConfig) -> OverallState: """LangGraph node that performs web research using the native Google Search API tool. Executes a web search using the native Google Search API tool in combination with Gemini 2.0 Flash. Args: state: Current graph state containing the search query and research loop count config: Configuration for the runnable, including search API settings Returns: Dictionary with state update, including sources_gathered, research_loop_count, and web_research_results """ # Configure configurable = Configuration.from_runnable_config(config) formatted_prompt = web_searcher_instructions.format( current_date=get_current_date(), research_topic=state["search_query"], ) # Uses the google genai client as the langchain client doesn't # return grounding metadata response = genai_client.models.generate_content( model=configurable.query_generator_model, contents=formatted_prompt, config={ "tools": [{"google_search": {}}], "temperature": 0, }, ) # resolve the urls to short urls for saving tokens and time resolved_urls = resolve_urls( response.candidates[0].grounding_metadata.grounding_chunks, state["id"] ) # Gets the citations and adds them to the generated text citations = get_citations(response, resolved_urls) modified_text = insert_citation_markers(response.text, citations) sources_gathered = [item for citation in citations for item in citation["segments"]] return { "sources_gathered": sources_gathered, "search_query": [state["search_query"]], "web_research_result": [modified_text], }
LLM 理解了谷歌搜索工具的功能,并知道可以利用该工具来满足提示要求。这种原生集成的一个关键优势在于响应中返回的“grounding_metadata”。这些元数据包含“基础片段”——本质上就是答案的片段以及支持这些片段的网址。这基本上为我们提供了免费的引用。
3.3 Conditional routing
The problem
在初步研究之后,代理程序如何判断是停止还是继续呢?我们需要一种控制机制来构建一个能够自行终止的研究循环。
LangGraph’s solution
条件路由是由一种特殊的节点来处理的:该节点不会返回状态信息,而是会返回下一个要访问的节点的名称。实际上,这个节点实现了路由功能,它会根据当前状态做出决定,从而确定如何在图中引导流量。
Let’s see some code!
“evaluate_research”节点是我们的代理的决策者。它会检查由“reflection”节点设置的“is_sufficient”标志,并将当前的“research_loop_count”值与预先设定的最高阈值进行比较。
def evaluate_research( state: ReflectionState, config: RunnableConfig,) -> OverallState: """LangGraph routing function that determines the next step in the research flow. Controls the research loop by deciding whether to continue gathering information or to finalize the summary based on the configured maximum number of research loops. Args: state: Current graph state containing the research loop count config: Configuration for the runnable, including max_research_loops setting Returns: String literal indicating the next node to visit ("web_research" or "finalize_summary") """ configurable = Configuration.from_runnable_config(config) max_research_loops = ( state.get("max_research_loops") if state.get("max_research_loops") isnotNone else configurable.max_research_loops ) if state["is_sufficient"] or state["research_loop_count"] >= max_research_loops: return"finalize_answer" else: return [ Send( "web_research", { "search_query": follow_up_query, "id": state["number_of_ran_queries"] + int(idx), }, ) for idx, follow_up_query inenumerate(state["follow_up_queries"]) ]
如果满足停止条件,它会返回字符串“finalize_answer”,然后 LangGraph 将继续前往该节点。否则,它会返回一个包含后续查询的新的 Send 对象列表,从而启动另一轮并行的网络搜索,继续这个循环。
Send 对象……那是什么呢?
嗯,这就是 LangGraph 公司的实现并行执行的方式。现在让我们来详细了解一下吧。
3.4 Parallel processing
The problem
为了尽可能全面地回答用户的提问,我们需要我们的“generate_query”节点生成多个搜索查询。然而,我们不想逐个执行这些搜索查询,因为那样会非常缓慢且效率低下。我们想要的是同时对所有查询进行网络搜索。
LangGraph’s solution
要启动并行执行,节点可以返回一个 Send 对象列表。 Send 是一个特殊的指令,它会告知 LangGraph 调度器将这些任务并发地分配到指定的节点(例如,“web_research”)上,每个任务都有其自身的状态。
Let’s see some code!
为了实现并行搜索,谷歌的实现方式引入了“continue_to_web_research”节点作为调度器。它从状态中获取 query_list ,并为每个查询创建一个单独的 Send 任务。
from langgraph.types import Senddef continue_to_web_research( state: QueryGenerationState): """LangGraph node that sends the search queries to the web research node. This is used to spawn n number of web research nodes, one for each search query. """ return [ Send("web_research", {"search_query": search_query, "id": int(idx)}) for idx, search_query in enumerate(state["query_list"]) ]
这就是您所需的所有代码。真正的神奇之处在于这个节点返回之后所发生的事情。
当 LangGraph 接收到这份列表时,它具备足够的智能,不会只是简单地逐个处理这些项。实际上,它在内部启动了一个复杂的“fan-out/fan-in”流程,以实现并行处理:
首先,每个发送对象仅携带您给定的少量数据({"search_query": ..., "id": ...}),而非整个OverallState。这样做是为了实现快速序列化。
然后,图形调度器会为列表中的每个项目启动一个 asyncio 任务。这种并发处理是自动进行的,作为工作流构建者的您无需担心编写 async def 或管理线程池之类的事情。
最后,在所有并行的 web_research 分支完成后,它们各自返回的字典会自动合并回主的 OverallState 中。还记得我们一开始讨论过的 Annotated[list, operator.add] 吗?现在它变得至关重要了:使用这种类型归约器定义的字段,比如 sources_gathered,其结果将会被合并成一个单一的列表。
您可能会想问:如果其中一项并行搜索失败或超时会怎样?正是出于这个原因,我们为每个“Send”数据包添加了一个自定义 id 。这个标识符会直接进入跟踪日志,使您能够精确地定位并调试出失败的具体分支。
如果您还记得之前的内容,那么在我们的图形定义中就有这样一条语句:
# Add conditional edge to continue with search queries in a parallel branchbuilder.add_conditional_edges( "generate_query", continue_to_web_research, ["web_research"])
您可能会疑惑:为何我们需要将continue_to_web_research这一节点设定为条件边的一部分呢?
需要明白的关键一点是:continue_to_web_research 并非仅仅是流程中的一个步骤——它实际上是一个路由功能。
generate_query 节点可以返回零条或二十条查询(当用户提出简单的问题时)。一条静态边会强制工作流必须执行一次“web_research”操作,即便没有需要执行的任务也是如此。通过将“continue_to_web_research”这一边定义为条件边,可以在运行时由“continue_to_web_research”决定是否要执行该操作,以及借助“Send”功能决定要生成多少个并行分支。如果“continue_to_web_research”返回一个空列表,那么LangGraph就会直接忽略这条边。这样就省去了与搜索 API 的往返操作。
最后,这再次体现了软件工程的最佳实践:generate_query(生成查询)专注于确定要搜索的内容,continue_to_web_research(继续进行网络研究)关注是否以及如何进行搜索,而 web_research(网络研究)则负责实际执行搜索操作,实现了清晰的职责划分。
3.5 Configuration management
The problem
例如,为了使节点能够正常工作,它们需要知道:
- • 应该使用哪种大型语言模型以及采用何种参数设置(例如温度)?
- • 应生成多少个初始搜索查询?
- • 总研究循环次数和每次运行的并发次数上限是多少?
- • 还有很多其他问题……
简而言之,我们需要一种干净、集中的方式来管理这些设置,以免使我们的核心逻辑变得杂乱无章。
LangGraph’s Solution
LangGraph 通过向每个需要配置的节点传递一个统一的标准化配置来解决这一问题。这个对象充当了针对运行环境的特定设置的通用容器。
在节点内部,LangGraph 随后会使用一个自定义的、类型化的辅助类来智能解析这个 config 对象。该辅助类实现了获取值的清晰层次结构:
- • 它首先会在当前运行的
config对象中查找已设置的覆盖项。 - • 如果未找到,则会转而检查环境变量。
- • 如果仍然未找到,则会使用此辅助类中直接定义的默认值。
Let’s see some code!
让我们来看看 reflection 节点的实现过程,从而直观地了解其运作方式。
def reflection( state: OverallState, config: RunnableConfig) -> ReflectionState: """LangGraph node that identifies knowledge gaps and generates potential follow-up queries. Analyzes the current summary to identify areas for further research and generates potential follow-up queries. Uses structured output to extract the follow-up query in JSON format. Args: state: Current graph state containing the running summary and research topic config: Configuration for the runnable, including LLM provider settings Returns: Dictionary with state update, including search_query key containing the generated follow-up query """ configurable = Configuration.from_runnable_config(config) # Increment the research loop count and get the reasoning model state["research_loop_count"] = state.get("research_loop_count", 0) + 1 reasoning_model = state.get("reasoning_model") or configurable.reasoning_model # Format the prompt current_date = get_current_date() formatted_prompt = reflection_instructions.format( current_date=current_date, research_topic=get_research_topic(state["messages"]), summaries="\n\n---\n\n".join(state["web_research_result"]), ) # init Reasoning Model llm = ChatGoogleGenerativeAI( model=reasoning_model, temperature=1.0, max_retries=2, api_key=os.getenv("GEMINI_API_KEY"), ) result = llm.with_structured_output(Reflection).invoke(formatted_prompt) return { "is_sufficient": result.is_sufficient, "knowledge_gap": result.knowledge_gap, "follow_up_queries": result.follow_up_queries, "research_loop_count": state["research_loop_count"], "number_of_ran_queries": len(state["search_query"]), }
在该节点中只需添加一行模板代码即可:
configurable = Configuration.from_runnable_config(config)
目前有一些类似“配置”的术语在流传。让我们逐一对其进行解释,首先从“配置”这个词开始:
import osfrom pydantic import BaseModel, Fieldfrom typing importAny, Optionalfrom langchain_core.runnables import RunnableConfigclassConfiguration(BaseModel): """The configuration for the agent.""" query_generator_model: str = Field( default="gemini-2.0-flash", metadata={ "description": "The name of the language model to use for the agent's query generation." }, ) reflection_model: str = Field( default="gemini-2.5-flash-preview-04-17", metadata={ "description": "The name of the language model to use for the agent's reflection." }, ) answer_model: str = Field( default="gemini-2.5-pro-preview-05-06", metadata={ "description": "The name of the language model to use for the agent's answer." }, ) number_of_initial_queries: int = Field( default=3, metadata={"description": "The number of initial search queries to generate."}, ) max_research_loops: int = Field( default=2, metadata={"description": "The maximum number of research loops to perform."}, ) @classmethod deffrom_runnable_config( cls, config: Optional[RunnableConfig] = None ) -> "Configuration": """Create a Configuration instance from a RunnableConfig.""" configurable = ( config["configurable"] if config and"configurable"in config else {} ) # Get raw values from environment or config raw_values: dict[str, Any] = { name: os.environ.get(name.upper(), configurable.get(name)) for name in cls.model_fields.keys() } # Filter out None values values = {k: v for k, v in raw_values.items() if v isnotNone} return cls(**values)
这就是我们之前提到的定制辅助类。您可以看到,Pydantic 被大量用于定义代理的所有参数。需要注意的一点是,这个类还定义了一个名为 from_runnable_config() 的替代构造方法。这个构造方法通过从不同来源提取值并遵循我们在“ LangGraph 的解决方案”中讨论的覆盖层次结构来创建一个 Configuration 实例。
配置是 from_runnable_config() 方法的输入参数。从技术上讲,它是一种 RunnableConfig 类型的数据,但实际上它只是一个带有可选元数据的字典。在 LangGraph 中,它主要作为一种结构化的方式,在整个图中传递上下文信息。例如,它可以携带诸如标签、跟踪选项等信息,而最重要的是,它还可以在“configurable” key 下包含一个嵌套的字典形式的覆盖项。
最后,对每个节点都进行如下操作:
configurable = Configuration.from_runnable_config(config)
我们通过整合来自三个来源的数据来创建 Configuration 类的一个实例:首先是从 config["configurable"] 中获取的数据,其次是环境变量,最后是类的默认值。因此,configurable是一个完全初始化、可直接使用的对象,它能让节点访问所有相关的设置,例如 configurable.reflection_model。
总结一下:Configuration是定义,config 是运行时输入,而 configurable 则是最终结果,即您的节点所使用的解析后的配置对象。
Bonus Read: What Didn’t We Cover?
LangGraph 的功能远不止本次教程所能涵盖的范围。在构建更复杂的智能体时,您可能会遇到诸如以下这样的问题:
-
- Can I make my application more responsive? LangGraph 支持流式处理,因此您可以逐个输出结果,从而为用户提供实时的使用体验。
-
- What happens when an API call fails? LangGraph 实现了重试和回退机制,以处理错误情况。
-
- How to avoid re-running expensive computations? 如果您的某些节点需要进行高成本的处理操作,您可以利用 LangGraph 的缓存机制来缓存节点的输出结果。此外,LangGraph 还支持检查点功能。此功能可让您保存图形的状态,并在中断后继续从上次停止的地方继续执行。如果您的处理过程较长,并且您希望暂停它并在稍后继续执行,那么此功能尤为重要。
-
- Can I implement human-in-the-loop workflows?
是。LangGraph 具有内置的人机交互工作流支持功能。这使得您能够暂停图的运行,并等待用户的输入或批准后再继续进行操作。
- Can I implement human-in-the-loop workflows?
-
- How can I trace my agent’s behavior?
LangGraph 与 LangSmith 无缝集成,后者能够为您提供有关您代理行为的详细跟踪信息和可观测性数据,且无需进行任何额外设置。
- How can I trace my agent’s behavior?
-
- How can my agent automatically discover and use new tools?
LangGraph 支持 MCP(模型上下文协议)的集成。这使得它能够自动发现并使用遵循这一开放标准的工具。
- How can my agent automatically discover and use new tools?
Key takeaways
让我们回顾一下本节所讲的内容:
- • Structured output: 使用“
.with_structured_output”选项可强制人工智能的回复符合您所定义的特定结构。这样可以确保您始终获得格式清晰、可靠的数据,以便后续步骤能够轻松解析。 - • Tool calling: 您可以在模型调用中嵌入相关工具,以便该智能体能够与外部世界进行交互。
- • Conditional routing: 这就是构建“自主选择路径”逻辑的方法。一个节点可以通过返回下一个节点的名称来决定接下来的走向。这样一来,您就可以动态地创建循环和决策点,从而使您的智能体的工作流程变得更加智能。
- • Parallel processing: LangGraph 允许您同时启动多个步骤进行运行。分发任务以及将结果收集回来的繁重工作都将由 LangGraph 自动处理。
- • Configuration management: 与其将各种设置分散在代码中各处,不如使用一个专门的“配置”类来集中管理运行时设置、环境变量、默认值等,这样可以将这些内容集中在一个简洁、统一的位置进行管理。
Figure 8. Various aspects of enhancing LLM agent capabilities.
- Conclusions
在这篇帖子中,我们已经探讨了很多内容!现在我们已经了解了 LangGraph 的核心概念是如何结合在一起构建出一个实际的科研代理的,接下来让我们总结一下几个关键要点:
- • Graphs naturally describe agentic workflows. 实际的工作流程包含循环、分支以及动态决策。LangGraph 的基于图的架构(节点、边和状态)提供了一种清晰且直观的方式来表示和管理这种复杂性。
- • State is the agent’s memory. 核心的“OverallState”对象是一个共享的“白板”,图中的每个节点都可以查看并在此上进行书写。与节点特定的状态模式相结合,它们共同构成了该代理的记忆系统。
- • Nodes are modular components that are reusable. 在 LangGraph 中,您应当构建具有明确职责的节点,例如负责生成查询、调用工具或执行路由逻辑等。这样做能使代理系统更易于测试、维护和扩展。
- • Control is in your hands. 在 LangGraph 中,您可以利用条件边来引导逻辑流程,通过结构化的输出来确保数据的可靠性,通过集中式配置来全局调整参数,或者使用“Send”功能来实现任务的并行执行。这些功能的结合使您能够构建智能、高效且可靠的代理。
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:
- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!
更多推荐


 24
24 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)