
Apache superset实操应用
简介
最近公司决定使用Apache superset来作为数据可视化和业务分析的工具,对比了Metabase 、DataEase、Superset,最终决定使用Superset,之前一直使用帆软report做的报表开发,总结一下superset优缺点:
优点:开源 + python 、业务人员可轻松操作(拖拉拽字段出图表)、较好的权限管控;
缺点:图表只支持单表配置(多表关联要写sql)、管理器控件(filter)比较单一、官方文档比较简单;
系统的部署
superset的部署方式多样,支持docker、k8s、pipy、虚拟环境,我这里使用的Anaconda 虚拟环境来部署的,当然也可以用minconda来部署,各有利弊,下面是大致的实操经历:
-
Anaconda 安装,这里不做说明,基本上就是傻瓜式操作;
-
可以在Anaconda界面创建虚拟环境,也可以命令创建;
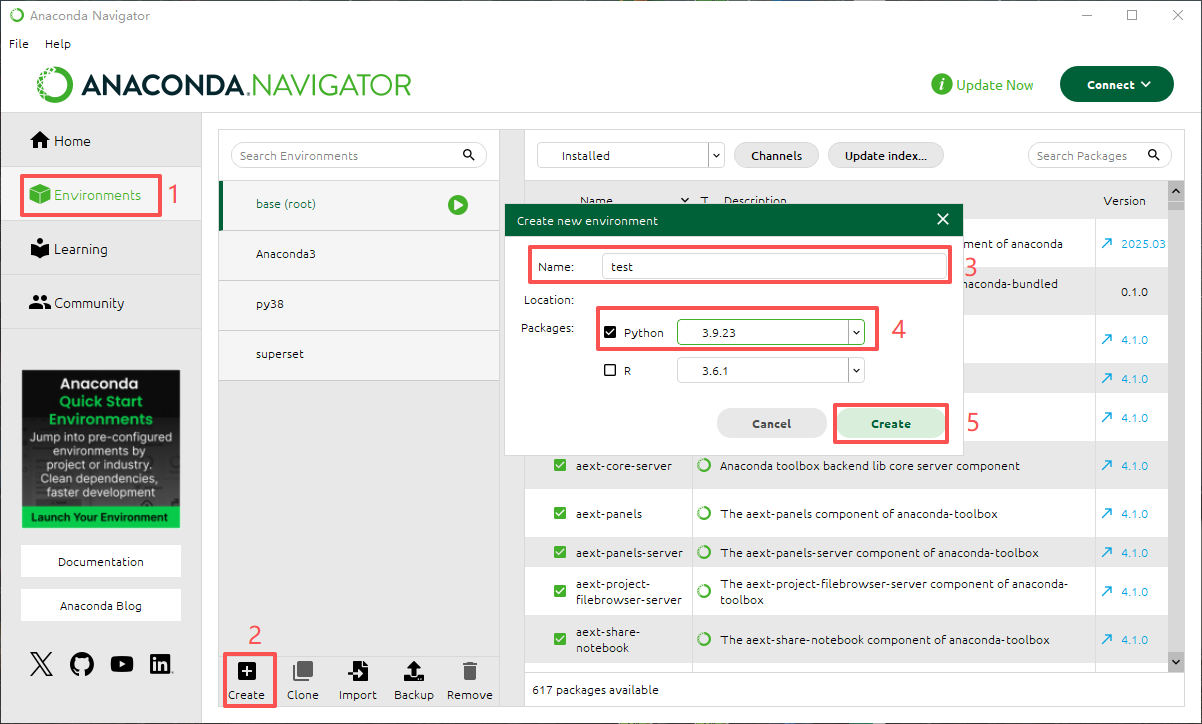 在anaconda创建虚拟环境如上图,如果要是用命令创建虚拟环境和安装superset,可以参考以下链接,1-7步足以安装成功;
在anaconda创建虚拟环境如上图,如果要是用命令创建虚拟环境和安装superset,可以参考以下链接,1-7步足以安装成功;
本地部署开源数据探索和可视化平台 Superset( Windows 版本) -
这里说一下superset_config.py内容,superset启动需要依靠superset_config.py启动,里面参数来自于superset/config.py,有需要就复制过来,不要直接修改superset/config.py的参数,superset_config.py配置好以后启动会替换config.py对应参数,这里我只配置了这几个参数,没有配置数据库,使用默认的sqlite,可以修改成mysql或者pgsql;
# SECRET_KEY
SECRET_KEY = "8441557832b32a563ae6b26b892bfeeccab05c9adca61f064370d"
# 配置数据库的链接,用于存放superset的数据
# The SQLAlchemy connection string.
# SQLALCHEMY_DATABASE_URI = (
# f"""sqlite:///{os.path.join(DATA_DIR, "superset.db")}?check_same_thread=false"""
)
# SQLALCHEMY_DATABASE_URI = 'mysql://myapp@localhost/myapp'
# SQLALCHEMY_DATABASE_URI = 'postgresql://root:password@localhost/myapp'
# 配置模板参数时是放在DEFAULT_FEATURE_FLAGS json中
DEFAULT_FEATURE_FLAGS: dict[str, bool] = {
# 核心配置:启用模板处理
"ENABLE_TEMPLATE_PROCESSING": True,
# 允许在SQL中使用模板变量(4.x版本推荐显式开启)
"TEMPLATED_FILTERS_ENABLED": True,
# 4.x版本新增:允许在原生SQL中使用模板(关键配置)
"ALLOW_ADHOC_SUBQUERIES": True
# 注册自定义处理器(如果使用动态表名宏)
# CUSTOM_TEMPLATE_PROCESSORS = {
# "doris": CustomDorisTemplateProcessor # 确保与数据库engine匹配
# }
}
- 由于我是部署在Windows中,使用的是conda虚拟环境,需要在cmd里面启动superset,关闭cmd窗口后,都需要重新进入到虚拟环境,可以使用conda env list列出有哪些虚拟环境,conda activate 激活环境后,每次都要导入环境变量,我觉得这里应该可以在系统的环境变量里面设置好;
set FLASK_APP=superset
set SUPERSET_CONFIG_PATH=%USERPROFILE%\.superset\superset_config.py
- 其他的就是创建数据库链接,创建数据集、创建图表和创建看板的基础操作;
重点1-动态表名的查询
公司系统里面有些表是按月存取的,表名都以固定的前缀+月份存取,比如user_location_202509这种样式,单表数据量也有几个G,如果要查询历史数据,就需要跨表查询,由于superset只能按照单表配置图表,sql lab执行不支持动态sql参数,如果要实现跨表查询应该怎么办呢,处理方法有下面几种:
- 先将数据做聚合,然后再superset里面做呈现,聚合方式包括使用union all多个月的表后生成数据集、将表数据汇总成一个按月的分区表,然后在查询这个分区表,最后用筛选器来过滤每个月的数据,这样做缺点比较突出,如果每个月的数据量很大,聚合在一起查询性能较低;
- 对superset做少量的二次开发,在superset/jinja_context.py文件增加函数来进行月份的转换,那月份如何来呢,这里就需要用到superset里面的时间筛选器了,当时间筛选器为空时,就将月份处理成当前月份,生成表user_location_202509(比如当前月是202509),如果不为空时,就将时间筛选器的时间传递给函数处理成要查询的月份,生成表user_location_202508;
- 如果要找到在conda里面安装好的superset文件路径,可进行以下操作,缺点:这是安装包,不是开发版,不推荐修改,如果你想深入调试或修改 Superset,克隆官方源码 + 关联 Conda 环境(适合调试开发);
# 激活superset虚拟环境
C:\Users\Administrator>conda activate superset
# 查看superset安装位置
C:\Users\Administrator>python -c "import superset; print(superset.__file__)"
D:\ProgramData\Anaconda3\envs\superset\lib\site-packages\superset\__init__.py
# 在 PyCharm 中打开 Superset 安装位置
# 直接打开 site-packages 中的 superset 目录
# D:\ProgramData\Anaconda3\envs\superset\lib\site-packages\superset
修改superset/jinja_context.py中的class ExtraCache类
class ExtraCache:
"""
新增一个参数from_dttm,这个参数名称不要修改,因为这是superset时间筛选器的返回的开始日期的参数,
另外还有个结束日期to_dttm,有需要的可以再添加
"""
regex = re.compile(
r"(\{\{|\{%)[^{}]*?("
r"current_user_id\([^()]*\)|"
r"current_username\([^()]*\)|"
r"get_dynamic_table_name\([^()]*\)|" # ✅ 新增下面的函数名称
r"current_user_email\([^()]*\)|"
r"cache_key_wrapper\([^()]*\)|"
r"url_param\([^()]*\)"
r")"
r"[^{}]*?(\}\}|\%\})"
)
def __init__(
self,
extra_cache_keys,
applied_filters,
removed_filters,
dialect,
from_dttm=None, # ✅ 新增参数
):
self.extra_cache_keys = extra_cache_keys
self.applied_filters = applied_filters
self.removed_filters = removed_filters
self.dialect = dialect
self.from_dttm = from_dttm # ✅ 保存
def get_dynamic_table_name(self, base_name: str = "user_location_202508") -> str:
"""
✅本次新增的参数,功能非常简单,用于测试,这里硬编码了表名称,也可以改为通用的
"""
from datetime import datetime
import re
ym = self.from_dttm.strftime("%Y%m") if self.from_dttm else datetime.now().strftime("%Y%m")
return re.sub(r"\d{6}(?=(_real)?$)", ym, base_name)
修改 set_context
def set_context(self, **kwargs: Any) -> None:
super().set_context(**kwargs)
from_dttm = (
self._parse_datetime(dttm)
if (dttm := self._context.get("from_dttm"))
else None
)
# ✅ 把 from_dttm 传给 ExtraCache
extra_cache = ExtraCache(
extra_cache_keys=self._extra_cache_keys,
applied_filters=self._applied_filters,
removed_filters=self._removed_filters,
dialect=self._database.get_dialect(),
from_dttm=from_dttm, # ✅ 传入
)
dataset_macro_with_context = partial(
dataset_macro,
from_dttm=from_dttm,
to_dttm=to_dttm,
)
# ✅ 使用 safe_proxy 包装
self._context.update(
{
"url_param": partial(safe_proxy, extra_cache.url_param),
"current_user_id": partial(safe_proxy, extra_cache.current_user_id),
"current_username": partial(safe_proxy, extra_cache.current_username),
"current_user_email": partial(safe_proxy, extra_cache.current_user_email),
"cache_key_wrapper": partial(safe_proxy, extra_cache.cache_key_wrapper),
"filter_values": partial(safe_proxy, extra_cache.filter_values),
"get_filters": partial(safe_proxy, extra_cache.get_filters),
"dataset": partial(safe_proxy, dataset_macro_with_context),
"metric": partial(safe_proxy, metric_macro),
# ✅ 安全注入:通过 safe_proxy 调用 ExtraCache 的方法
"get_dynamic_table_name": partial(safe_proxy, extra_cache.get_dynamic_table_name),
}
)
最后在sql lab里面调用,就能够实现查询按月分表的数据表
SELECT * from {{get_dynamic_table_name()}}
重点2-将时间过滤器的值传入到子查询内部或CTE
按照superset官方文档的说明,时间过滤器只能作用在最外层sql的条件过滤,内层sql如果不优先过滤,对结果集进行查询会有较大的性能影响,特别是内层数据量较大的情况下,主要体现在响应速度上,我查看了官方文档SQL 模板-jinja模板的示例和查询其他大佬的示例,确实没有很明确的说明能解决上面的问题,经过不断尝试后,最后还真实现将时间过滤器的值传入到内层sql,这主要是在sql lab里面实现,大致配置如下:
# 先定义开始和结束参数,from_dttm 和to_dttm 也不用改动
{% set from_dttm = from_dttm %}
{% set to_dttm = to_dttm %}
with user_count as (
# 这里查询我们上面函数定义的表名称
select * from {{get_dynamic_table_name()}}
where 1=1
# 这里使用了between and,也可以用>=或在<=进行尝试
and create_date between {% if from_dttm is not none and from_dttm != "" %}'{{ from_dttm }}'
{% else %} CURRENT_DATE(){% endif %}
and {% if to_dttm is not none and to_dttm != "" %}'{{ to_dttm }}'
{% else %}DATE_ADD(CURRENT_DATE(), INTERVAL 1 DAY){% endif %}
)
select * from user_count
总结
上面两个问题的解决方案虽然说不是最优的,甚至还有一些局使用场景限性,也有可能没有完全理解superset的精髓(毕竟接触不久),但是确实也是处理类似问题的一些参考,这里运用到了通义千问-qwen3,功能确实很强大,大家在遇到问题的时候可以多咨询下AI,确实能给我们的工作提高效率和便捷。下面几个图是用于测试验证的一些截图,大家可以做参考: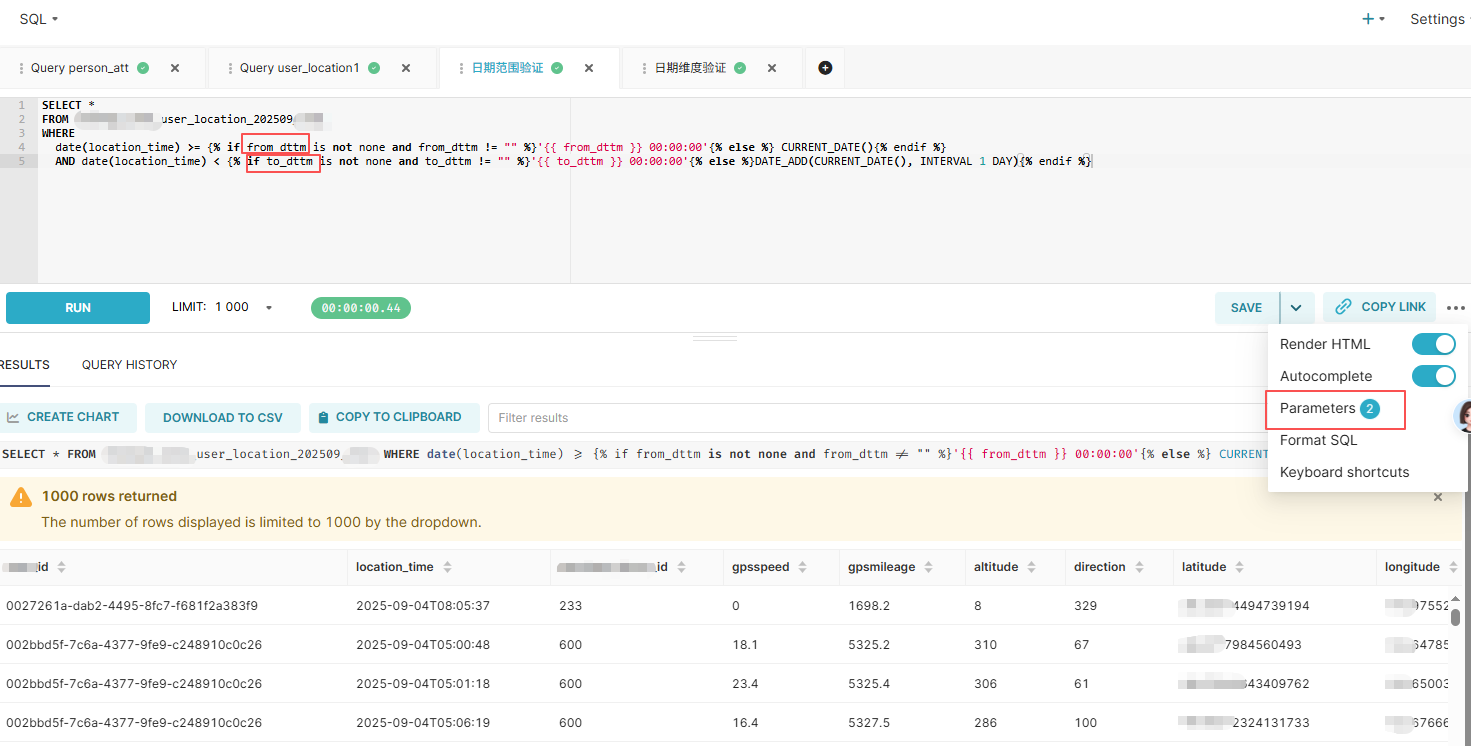
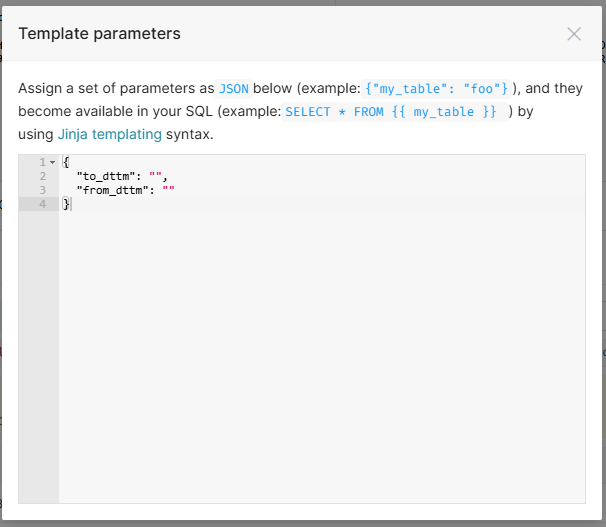
如果预先不定义from_dttm和to_dttm,需要设置Parameters参数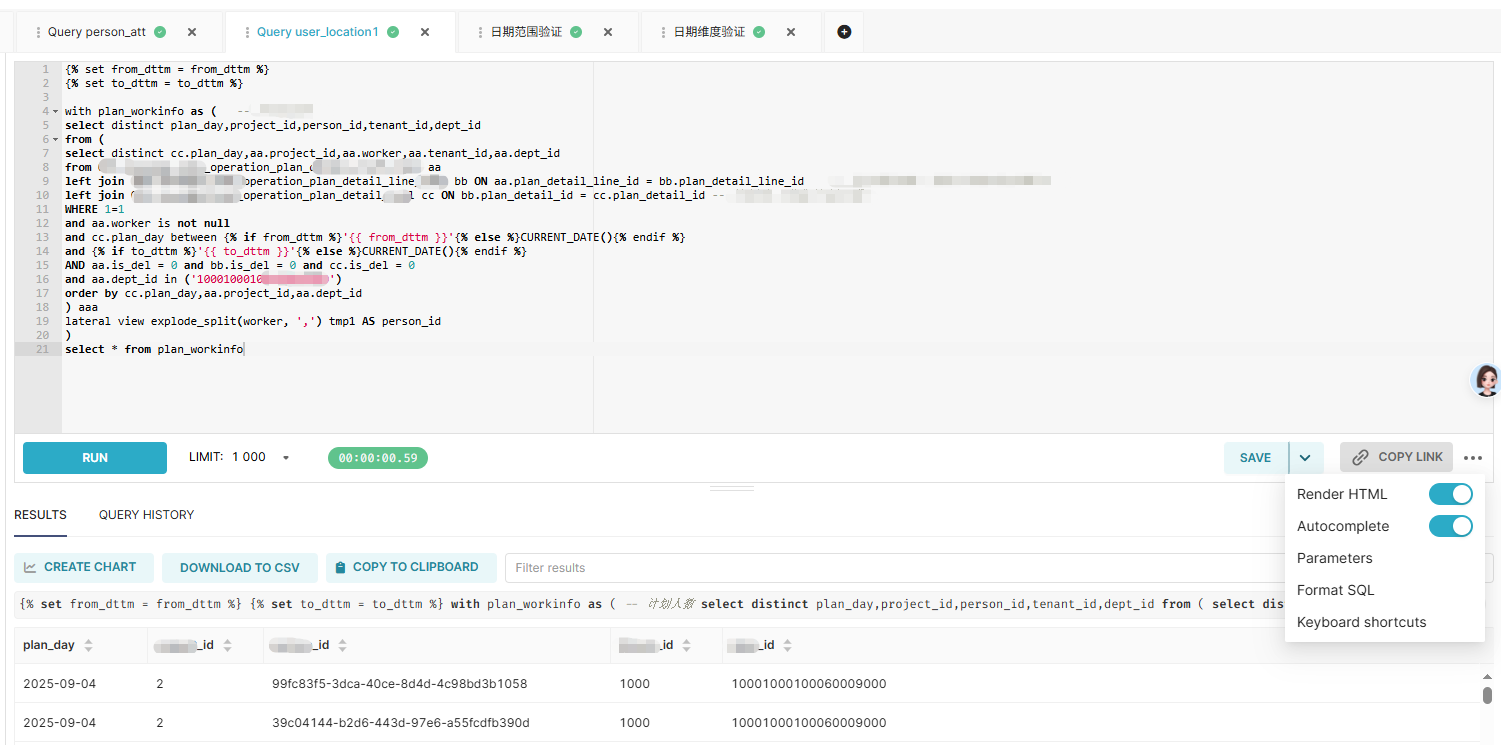
这里定义了from_dttm和to_dttm,不需要设置参数就能实现查询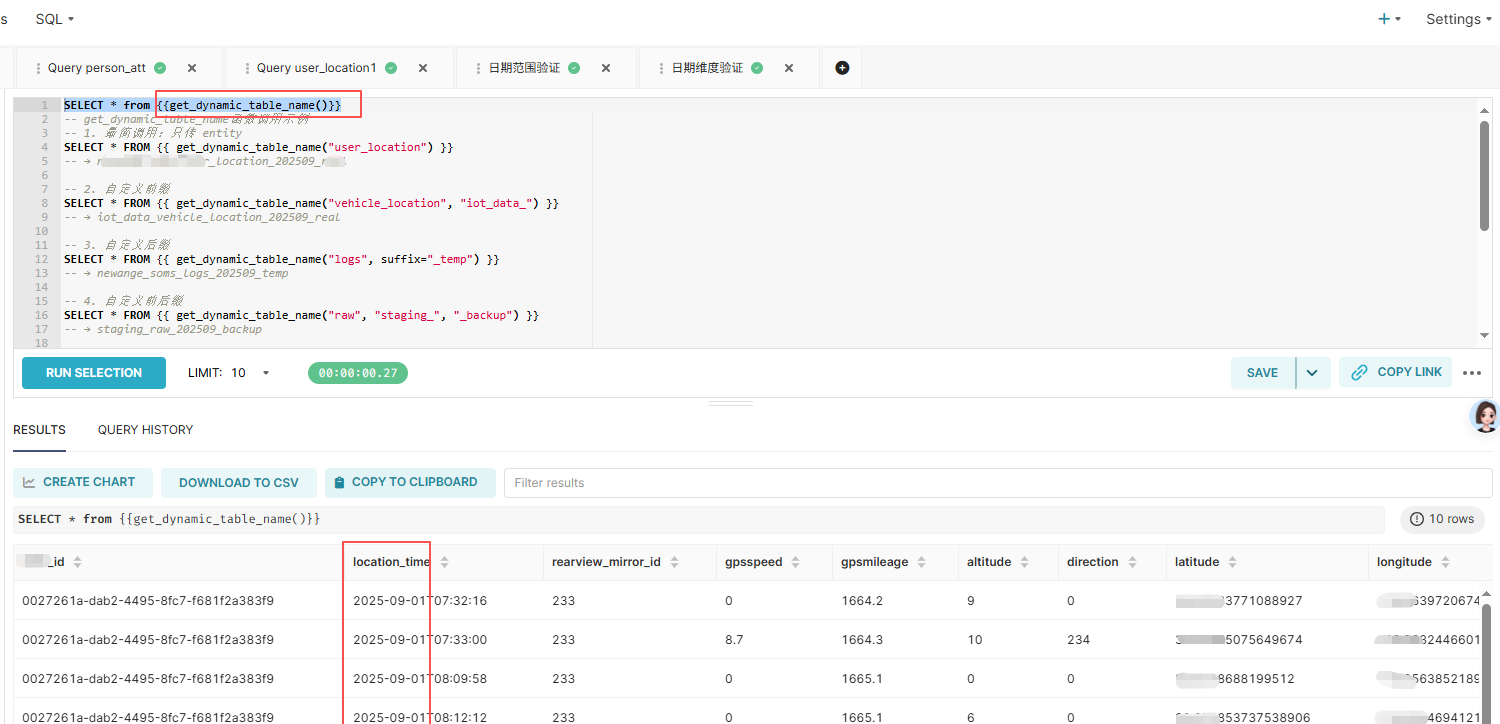
这里用函数实现了动态表名的查询
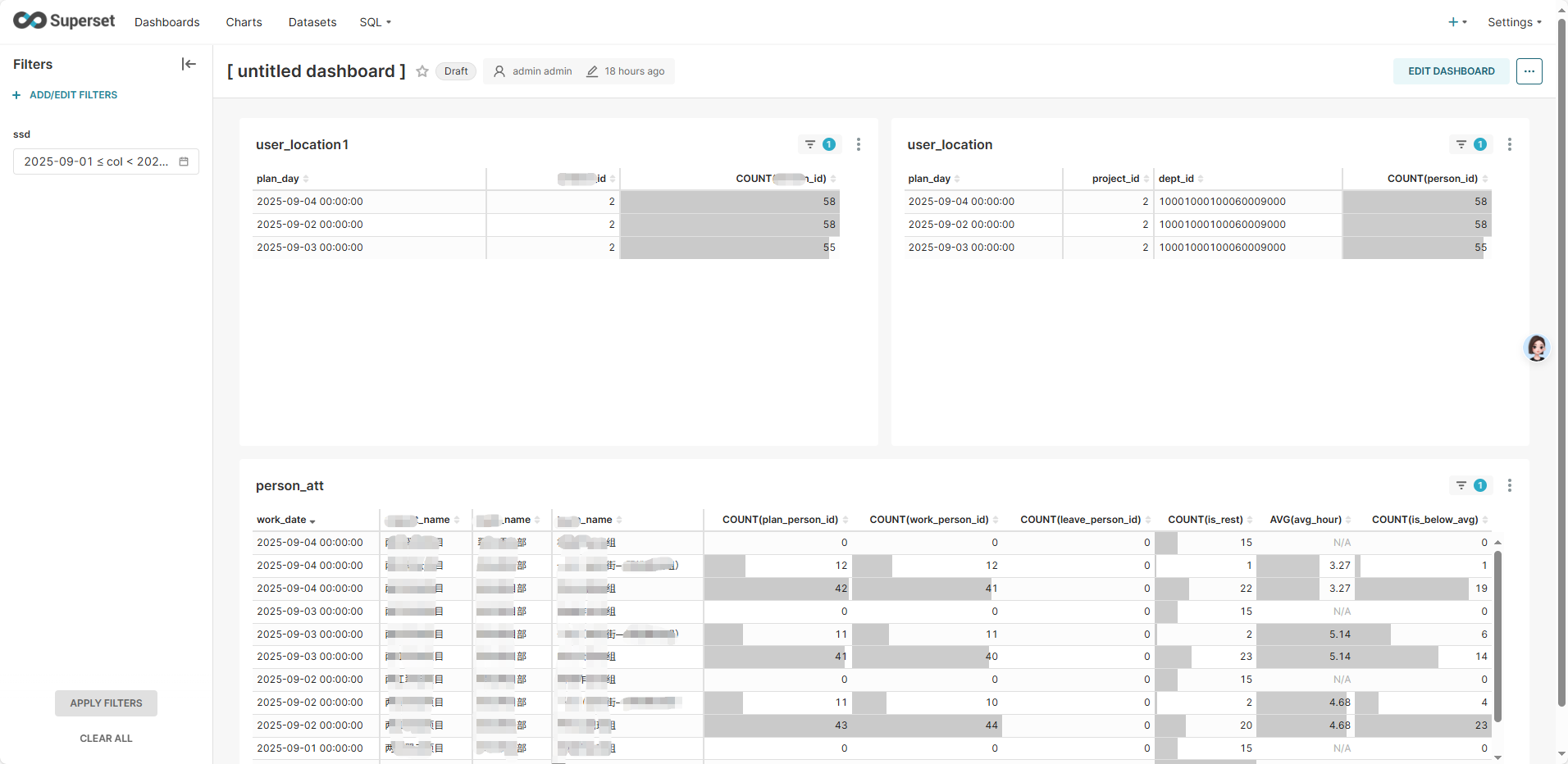
这里选择3天进行查询,使用上面的数据集来测试看板及筛选器
参考及引用
更多推荐
 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)