
6G内存即可流畅跑多模态大模型!MiniCPM-V 4.6 开源并上线魔乐社区
除了性能惊艳,MiniCPM-V 4.6 在效率上也取得了堪称「反常识」的突破。尽管参数规模比 Qwen3.5-0.8B 更大,但 MiniCPM-V 4.6 的运行效率却更快,实现了惊人的反超推理吞吐量:基于 vLLM 的 token 吞吐量是 Qwen3.5-0.8B 的1.5 倍。计算成本:在 AA 评测中,仅用2.5%的 token 消耗(5.4M vs 233M)就超越了 Qwen3.5
5 月 11 日,面壁智能联合清华大学、OpenBMB 开源社区正式发布并开源了新一代端侧多模态大模型:MiniCPM-V 4.6。
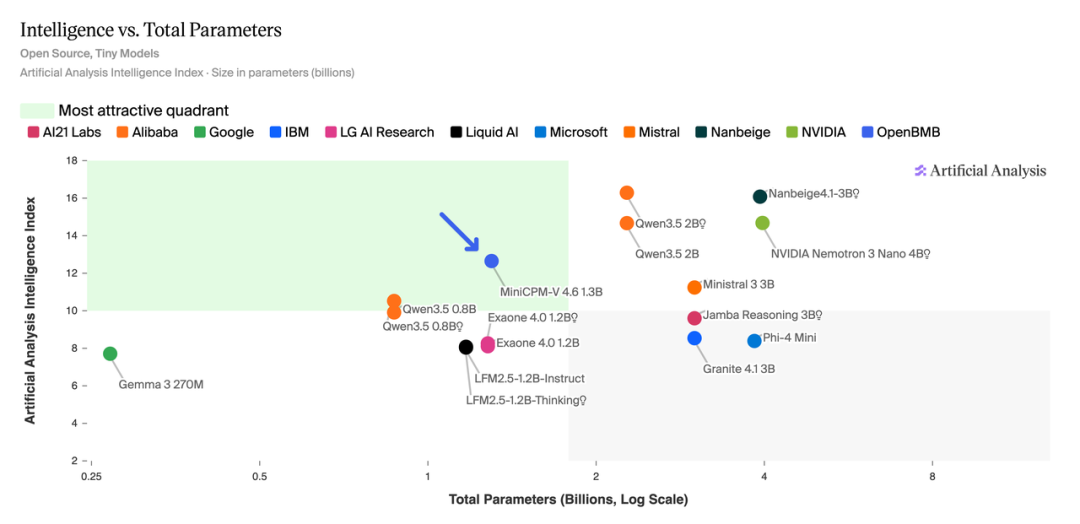
这是 MiniCPM-V 系列有史以来效率与性能平衡最佳的模型。它以仅 1.3B 的参数规模,实现了性能与效率的双重突破,在全球同尺寸模型中登顶,全面超越了阿里 Qwen3.5-0.8B 与谷歌 Gemma4-E2B-it。
尤其在内存价格飞涨的当下,MiniCPM-V 4.6 只需 6G 内存即可在端侧流畅运行,真正实现了「低内存、极速跑」。这不仅极大降低了多模态大模型在各类智能终端上的落地门槛,也让面壁智能「智周万物」(AGI for Lives)的愿景离我们更近了一步。
MiniCPM-V 4.6 已同步上线魔乐社区,欢迎广大开发者下载体验!
🔗 模型链接:
https://modelers.cn/models/OpenBMB/MiniCPM-V-4.6
https://modelers.cn/models/OpenBMB/MiniCPM-V-4.6-Thinking
性能拔群,1.3B 实现同尺寸最佳
根据多个权威基准评测,MiniCPM-V 4.6 的两个版本(Instruct 与 Thinking)多模态综合能力均表现卓越,实现了全维度领跑。
-
Instruct 版本:在通用图文理解、STEM 数理推理、文档 OCR、视频时序理解及目标定位等任务上,全面超越 Qwen3.5-0.8B、Gemma4-E2B-it 等模型。
-
Thinking 版本:在多图像关联推理、幻觉抑制等高阶任务中,同样几乎全面领先。
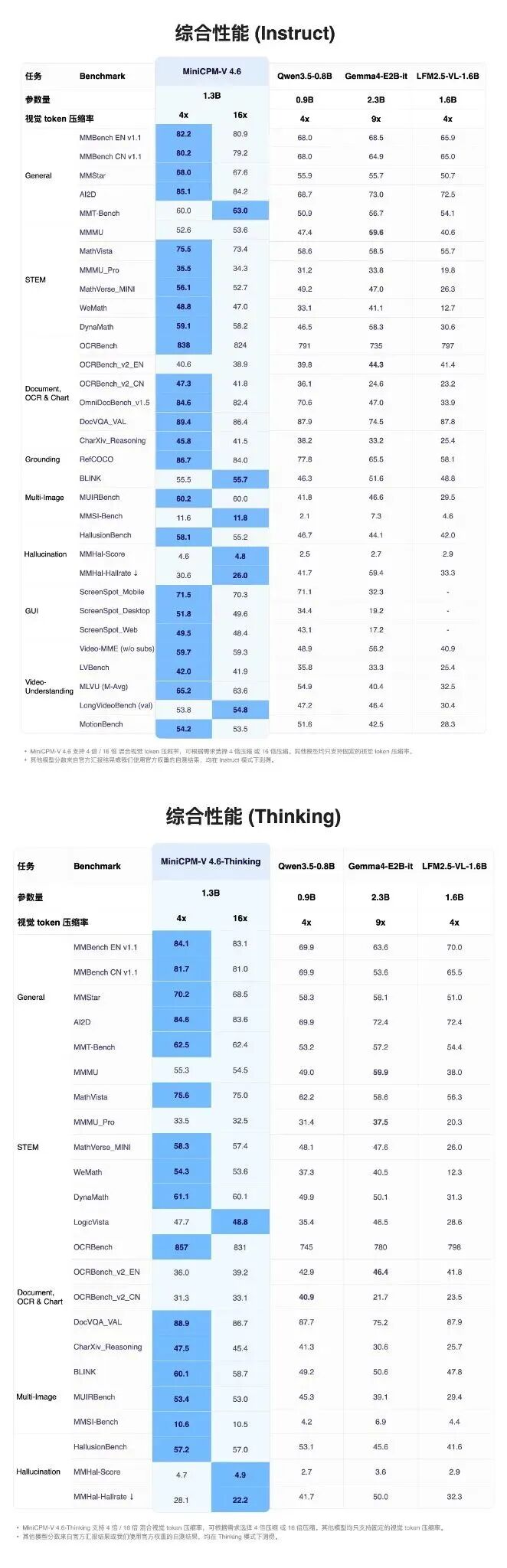
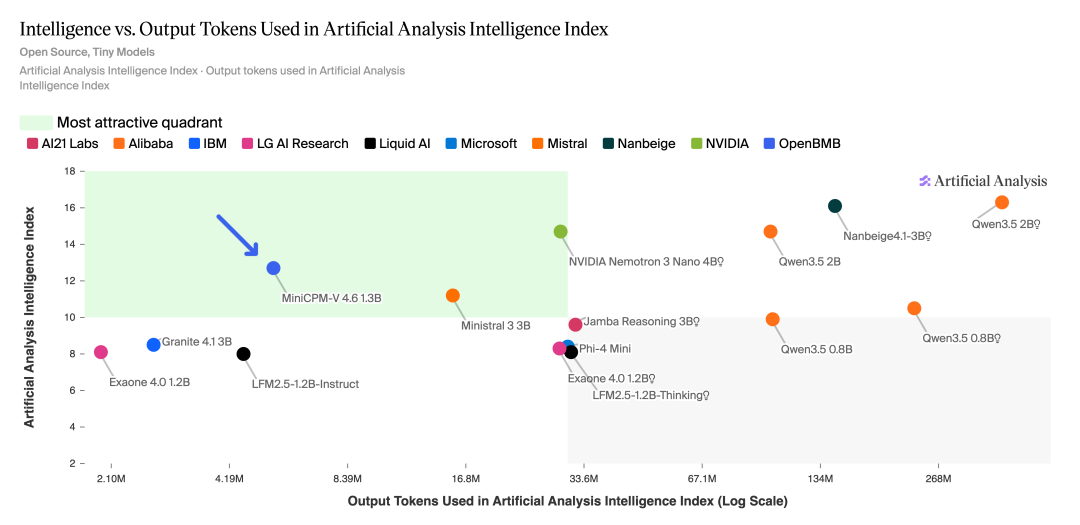
在最新的 Artificial Analysis(AA)榜单评测中,MiniCPM-V 4.6 更是以 13 分的优异成绩跻身前列,超越了包括 Mistral 3-3B、Qwen 3.5-0.8B 在内的一众模型,成绩逼近 Qwen 3.5-2B,成为 1B 级开源模型中当之无愧的性能标杆。
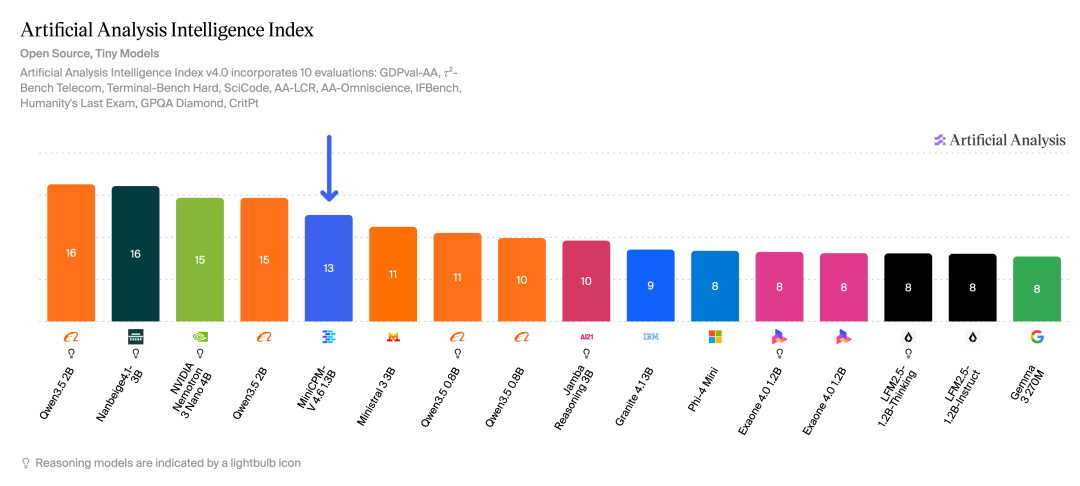
效率反超,重新定义「智能密度」
除了性能惊艳,MiniCPM-V 4.6 在效率上也取得了堪称「反常识」的突破。
尽管参数规模比 Qwen3.5-0.8B 更大,但 MiniCPM-V 4.6 的运行效率却更快,实现了惊人的反超:
-
推理吞吐量:基于 vLLM 的 token 吞吐量是 Qwen3.5-0.8B 的 1.5 倍。
-
计算成本:在 AA 评测中,仅用 2.5% 的 token 消耗(5.4M vs 233M)就超越了 Qwen3.5-0.8B。
这意味着 MiniCPM-V 4.6 以极小的计算成本,撬动了极高的智能水平,是面壁智能「密度定律」的又一实践。
由此,用同样的硬件,开发者可以承载数倍的线上流量,或在端侧实现更极致的响应速度。
这一飞跃,让市面上几乎所有的个人设备(手机、电脑)都可以将 MiniCPM-V 4.6 高效地跑起来。
极致背后的硬核创新
惊人的性能与效率背后,是两大底层技术的硬核创新。
ViT 架构重构:图像编码计算量锐减 50%
视觉编码器(ViT)是多模态模型处理图像信息的核心组件,也是计算开销最集中的环节之一。
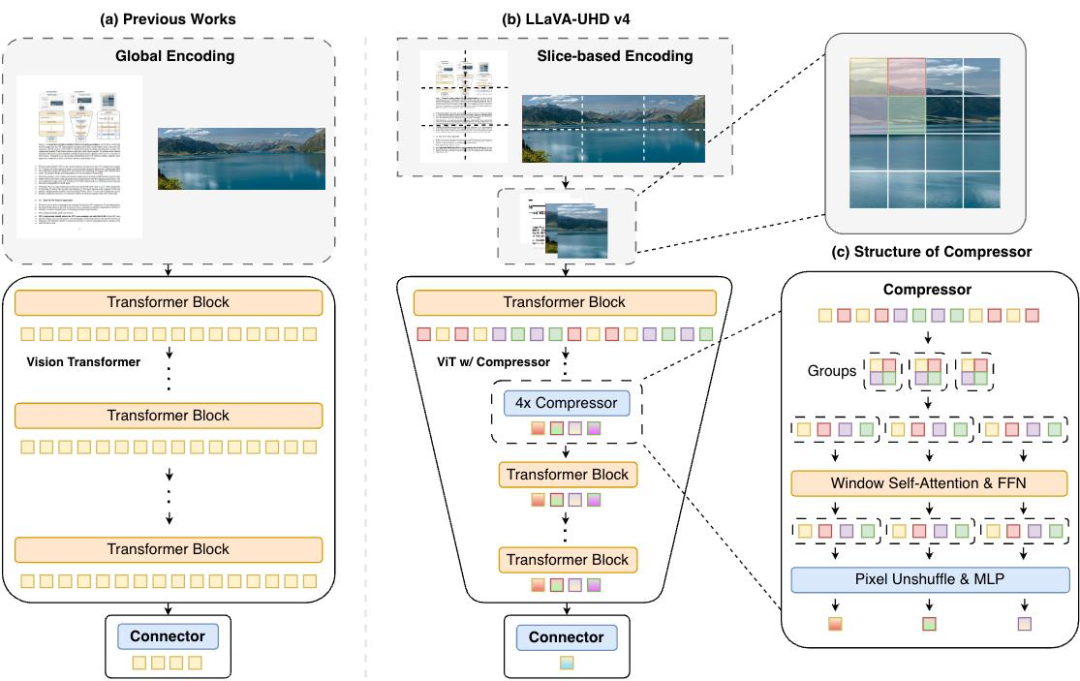
MiniCPM-V 4.6 采用了面壁智能与清华大学联合研发的最新 LLaVA-UHD v4 技术,通过创新的 「ViT 内部视觉 token 早压缩」,在保证性能不掉点的前提下,大幅降低了视觉 token 的数量和计算量,相比传统 ViT 将图像编码开销锐减了 50%。
针对模型在处理高分辨率图像时的视觉编码效率问题,LLaVA-UHD v4 提出了一种高效的编码范式,可以在超越原有性能的同时,将视觉编码阶段的浮点运算量降低 55.8%。
-
LLaVA-UHD v4 论文链接:https://huggingface.co/papers/2605.08985
LLaVA-UHD v4 主要包含两个核心设计:
-
高效切片编码:替代传统的全局编码,将高分辨率图像切分为多个区块处理,结构性地避免了注意力计算量随分辨率二次方增长的瓶颈。
-
ViT 内早期压缩:在 ViT 的浅层就引入压缩模块,让后续绝大部分 ViT 层只需处理极少量 Token,从根源上降低了计算量。
这一改造,与 16倍 token 压缩协同工作,协同实现了极致的轻量化推理——用更少的计算资源,完成同等质量的图像理解任务。这也造就了 MiniCPM-V 4.6「参数更大,但跑得更快」的效率奇迹。
4倍/16倍混合 Token 压缩:性能与速度,按需切换
业界多模态基座模型普遍采用固定的 4 倍视觉 token 压缩率,而 MiniCPM-V 4.6 则打破常规,提供了业界领先的双模式切换:
-
4 倍压缩模式(性能优先):适合高要求的文档解析、密集文字识别等细节敏感型任务;
-
16 倍压缩模式(速度优先):适合实时交互、低算力环境、高并发部署等场景。
同一个模型,两种选择,开发者无需在性能和速度之间艰难取舍。
视觉 token 压缩率会影响到显存占用、首响延迟、推理吞吐、功耗等众多关键效率指标,压缩率越高、响应速度越快。MiniCPM-V 多模态大模型从 2024 年就推出了 16 倍压缩率,在行业内领先。
值得一提的是,面壁智能开创性的 16 倍压缩技术早已在产业界得到验证,例如快手在 2025 年发布的推荐大模型 OneRec,在处理海量视频多模态特征时便应用了 MiniCPM-V 系列模型,成功支撑了主场景 25% 的巨大流量请求。
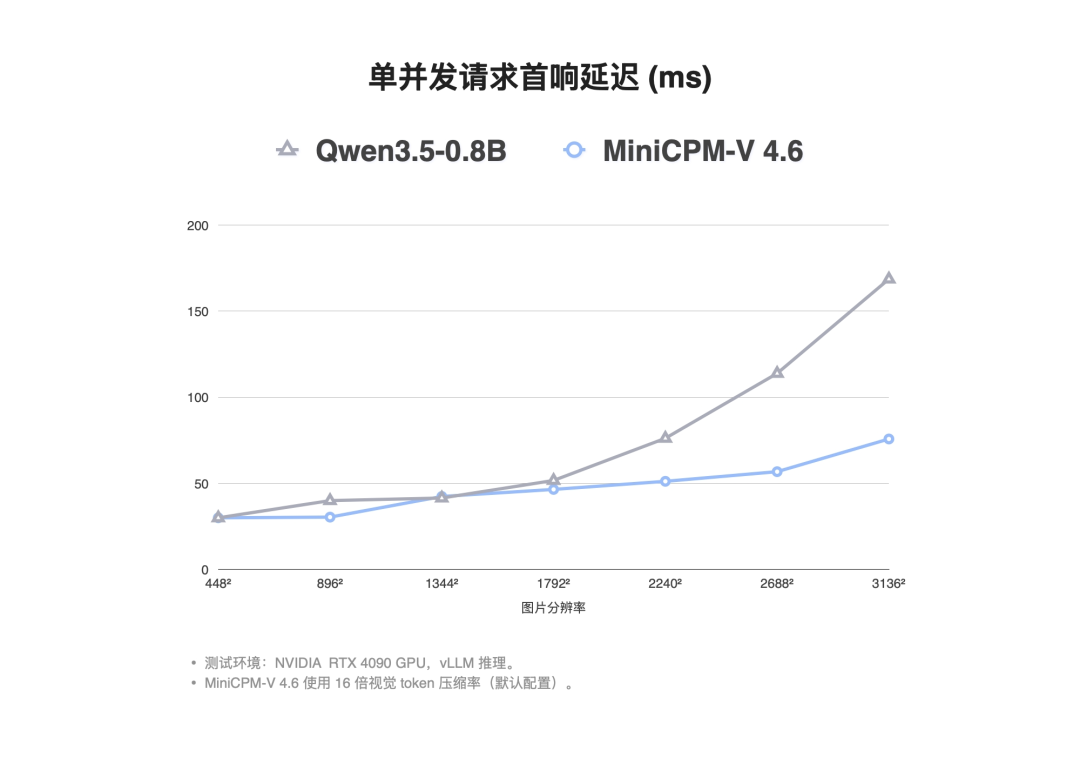
得益于 16 倍视觉 Token 压缩这一核心技术,MiniCPM-V 4.6 在推理效率的两大关键维度上同时建立起显著优势:
1)在单并发首响延迟(TTFT)上,它把“分辨率—延迟”曲线压得几乎平坦,3136² 高清大图的 TTFT 仅 75.7 ms,较同基座规模的 Qwen3.5-0.8B 快 2.2 倍;
2)在高并发吞吐上,单卡可达 7013 token/s、54.79 张/s 的 1344² 图片处理能力,是 Qwen3.5-0.8B 的 1.5 倍,意味着同样的硬件可以承载数倍的线上流量。
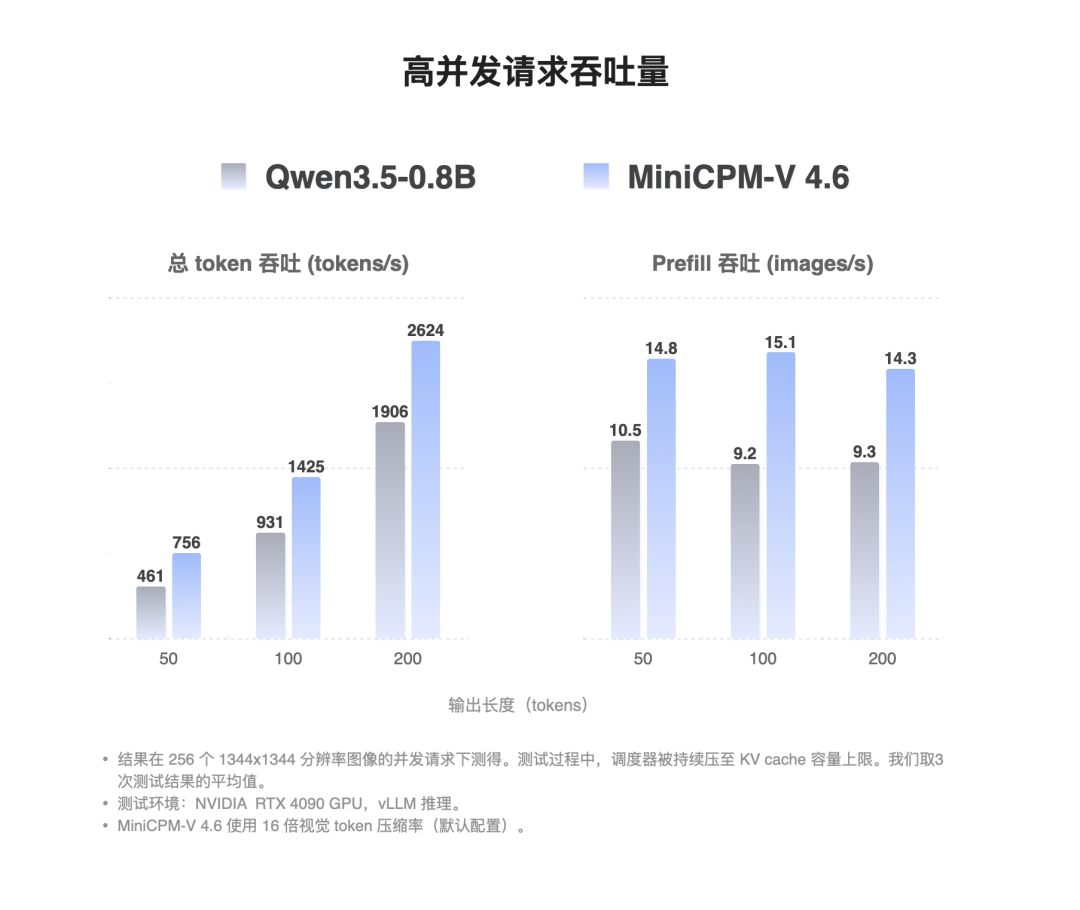
这两个维度的数值指标,共同指向同一结论:
MiniCPM-V 4.6 用更短的视觉序列、更小的 KV-Cache,把多模态推理的端侧体感与云侧 ROI 同时推到了新的高度。
根据 AA 榜单评测,MiniCPM-V 4.6 1.3B(非推理版本)的运行仅消耗 5.4M token 量,仅为 Qwen3.5-0.8B(非推理版本,101M)的 1/19 与 Qwen 3.5-0.8B(推理版本,233M)的 1/43,模型智能密度为同尺寸模型范围内最高:
为开发者而生:一键部署,全链打通
MiniCPM-V 4.6 坚持开源,并为社区开发者准备了一套从微调到部署的「保姆级」开箱即用指南。
-
消费级显卡即可开跑,打破算力壁垒
大模型的微调往往让人对昂贵的算力集群望而却步,但 MiniCPM-V 4.6 将这个门槛降到了目前业内最低。
得益于极致精简的 1.3B 黄金参数量,开发者仅需一张 RTX 4090 等常见的消费级显卡,即可全量跑通整个微调流程。
这意味着,无论是个人开发者、高校研究团队还是初创公司,都能以极低成本快速验证 idea,实现多模态模型能力的本地化闭环定制。
-
拥抱主流生态,微调与推理全链路打通
为了让开发者告别繁琐的环境配置,MiniCPM-V 4.6 实现了与主流开源生态的全面无缝对接:
1)微调框架全面支持:官方原生支持 ms-swift 与 LLaMA-Factory 等业内最受欢迎的微调框架。开发者只需准备好场景数据,修改几行配置,一键即可拉起专属模型的训练。
2)推理框架全家桶兼容:在部署端,MiniCPM-V 4.6团队同步适配了 vLLM、SGLang、llama.cpp、Ollama 等顶级高性能推理框架。无论是追求极致并发的云端服务,还是苛求资源占用的端侧设备,MiniCPM-V 4.6 都能游刃有余地完成高效部署。
-
垂直场景改造的最佳基座
极低的显存占用、极高的并发吞吐量、完备的上下游工具链——MiniCPM-V 4.6 天生就是为了被「爆改」而生,是开发者用于构建高并发计算、极速响应的垂直应用的高性价比多模态底座。
无论是云端高并发服务,还是端侧苛刻的资源占用,MiniCPM-V 4.6 都能游刃有余。
-
保姆级教程与部署指南
MiniCPM团队提供了详尽的端侧部署指南,助你轻松上手:
https://github.com/OpenBMB/MiniCPM-V-Apps/blob/main/README_zh.md
始于开源,成于生态:让 AGI 走进千家万户
从 8B 到 4B,再到今天的 1.3B,MiniCPM-V 系列的每一次迭代,都不是能力的妥协,而是效率的跃升,是对端侧多模态能力边界的又一次实质性扩张。
目前,MiniCPM-V 系列模型已在汽车、PC、手机、智能家居等多个终端场景规模化落地,合作伙伴涵盖联想、吉利、上汽大众等数十家行业头部企业。
让 AI 的智能真正触达每一块屏幕、每一个终端,是我们的愿景,也是我们的使命。欢迎每一位开发者,与我们共同探索端侧 AI 的无限可能!
更多推荐


 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)