




- @2401_87243659
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
它不仅识别更准,更重要的是,模型开始学会按语义顺序理解图像,迈向真正的2D推理。在主流的OmniDocBench v1.5 文档解析基准上,DeepSeek-OCR 2在所有端到端模型中,使用最小的视觉Token上限,取得了91.09%的SOTA综合得分。同时,阅读顺序错误率显著下降,这说明 DeepEncoder V2 确实学会了更符合逻辑的文档阅读路径。同时,DeepEncoder V2初步验

魔乐社区喊你来「养虾争霸」啦!魔乐社区虾王挑战赛 · OpenClaw虾客松今日正式启动!不管你是刚入门的「养虾萌新」,还是能轻松喂饱「小龙虾」的极客大佬;不管你是个人炫技还是企业组队——只要你想让AI干活,就能带着你的虾来冲击虾王宝座,解锁AI自动化的N种玩法,赢取重磅奖励!🔗。

🔗 DeepSeek-V4-Flash开源权重链接:https://modelers.cn/models/deepseek-ai/DeepSeek-V4-Flash (点击文末“阅读原文”直达)脚本链接:https://gitcode.com/Ascend/MindSpeed-LLM/tree/master/examples/mcore/deepseek4_flash。CKPT_LOAD_DIR

在MCP-Atlas(大规模工具调研评测的数据集),GLM-5.2比Opus 4.8低0.8%。GLM-5.2的线上推理依托多个国产算力平台,已在Day 0完成与为昇腾、平头哥、摩尔线程、寒武纪、昆仑芯、沐曦、海光、壁仞、天数智芯等国产算力平台的推理适配,在国产芯片集群上实现高吞吐、低延迟、大并发的稳定运行。从2025初开始,智谱团队几乎投入全部力量攻关Coding,历时大半年,细扣每一个代码环境
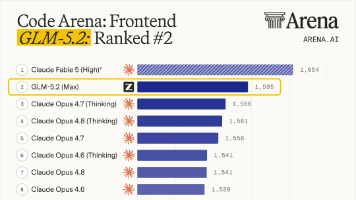
在MCP-Atlas(大规模工具调研评测的数据集),GLM-5.2比Opus 4.8低0.8%。GLM-5.2的线上推理依托多个国产算力平台,已在Day 0完成与为昇腾、平头哥、摩尔线程、寒武纪、昆仑芯、沐曦、海光、壁仞、天数智芯等国产算力平台的推理适配,在国产芯片集群上实现高吞吐、低延迟、大并发的稳定运行。从2025初开始,智谱团队几乎投入全部力量攻关Coding,历时大半年,细扣每一个代码环境
在MCP-Atlas(大规模工具调研评测的数据集),GLM-5.2比Opus 4.8低0.8%。GLM-5.2的线上推理依托多个国产算力平台,已在Day 0完成与为昇腾、平头哥、摩尔线程、寒武纪、昆仑芯、沐曦、海光、壁仞、天数智芯等国产算力平台的推理适配,在国产芯片集群上实现高吞吐、低延迟、大并发的稳定运行。从2025初开始,智谱团队几乎投入全部力量攻关Coding,历时大半年,细扣每一个代码环境
2026年2月12日,智谱AI开源GLM-5模型。在 Coding 与 Agent 能力上,取得开源 SOTA 表现,在真实编程场景的使用体感逼近 Claude Opus 4.5,擅长复杂系统工程与长程 Agent 任务。在全球权威的 Artificial Analysis 榜单中,GLM-5 位居全球第四、开源第一。昇腾一直同步支持智谱GLM系列模型,此次GLM-5模型一经开源发布,昇腾AI基础

0.8B / 2B: 极致轻量,端侧首选特点:体积极小,推理速度极快。场景:非常适合移动设备、IoT 边缘设备部署,以及低延时的实时交互场景。4B:轻量级 Agent 的强劲基座特点:性能强劲,多模态基座模型,适合Agent。场景:适合作为轻量级智能体的核心大脑,完美平衡了性能与资源消耗。9B:紧凑尺寸,越级性能特点:结构紧凑,但性能媲美gpt-oss-120B,让人惊艳。场景:适合需要较高智力水

继后,本次为大家带来SGLang框架下的昇腾部署实操指南,手把手教你完成 Qwen3.5系列开源模型的昇腾平台部署,轻松实现高效推理。本次教程适配Qwen3.5-397B-A17B、122B-A10B、35B-A3B、27B全系列模型,同时提供BF16原版权重与量化版本权重,满足不同开发需求。

本文介绍了在昇腾NPU环境下微调Qwen3.5-4B大语言模型的完整流程。首先通过git-lfs下载Qwen3.5-4B模型和LlamaFactory框架,然后搭建基于miniconda的Python3.11环境并安装相关依赖包。接着配置昇腾NPU运行环境,下载并处理训练数据集(包含中英文版本),修改dataset_info.json文件添加数据集信息。最后提供了详细的训练YAML配置文件说明,包
