
代理准备状态 The state of agent readiness —— Anthropic
爬虫权限是代理站点已识别的易得成果。ChatGPT-User覆盖81%的站点,ClaudeBot达82%,Google-Extended为87%,Qwen和DeepSeek接近90%。而新晋代理OpenClaw缺乏同等品牌认知度,覆盖率仅59%——比我们测试的其他模拟低20-30个百分点。站点只认知名品牌,不认陌生面孔;就连读取权限也由品牌而非政策决定。一旦任何代理尝试超越读取操作,数据会进一步崩
The state of agent readiness
代理准备状态
https://ora.run/blog/state-of-agent-readiness-2026
Agents are the new customers. 99% of the web isn’t ready for them. What’s the 1% doing right?
In the last month Salesforce launched Headless 360, turning every CRM and commerce action into an MCP tool, every Shopify storefront became an MCP endpoint by default, and Cloudflare ran its first Agents Week. Infrastructure for agents is shipping at scale.
We scanned thousands of products with our Deep Scan to see whether agents can actually use them. Every number below comes from real agents (ChatGPT, Claude, OpenClaw) running full sessions against each site across five weighted layers.
我们用深度扫描检查了数千款产品,以验证智能体是否能实际使用它们。以下每个数据都来自真实智能体(ChatGPT、Claude、OpenClaw)针对每个网站进行的完整会话测试,涵盖五个加权维度。
The scoreboard
Two kinds of companies are already winning the agentic era.
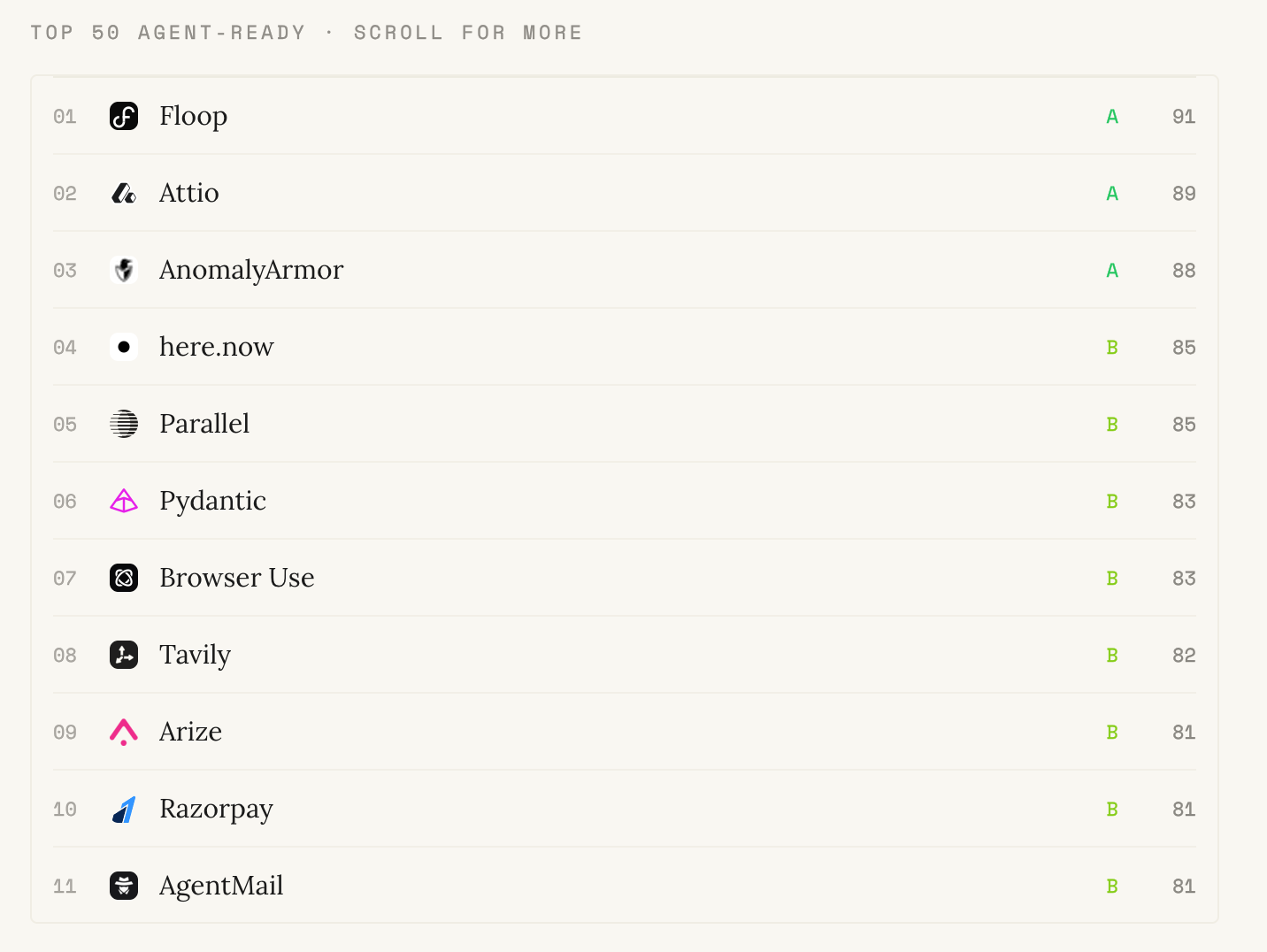
(原文有 50个)
The top of the list is dominated by newer, agent-native companies (Attio, Tavily, AgentMail, Parallel, Fireworks, and the rest of that cohort) built after agents became a category. Agent-native rails were the starting assumption, so shipping MCP, streaming, and agent-grade UX is a default rather than a migration.
The more interesting signal is the infrastructure incumbents sitting beside them. Stripe, Cloudflare, and Vercel read the urgency early: every new MCP transport, commerce protocol, and agent runtime runs on their rails, and every new agent workflow compounds their revenue. Payments and infrastructure are load-bearing for the agentic web, so they invested accordingly.
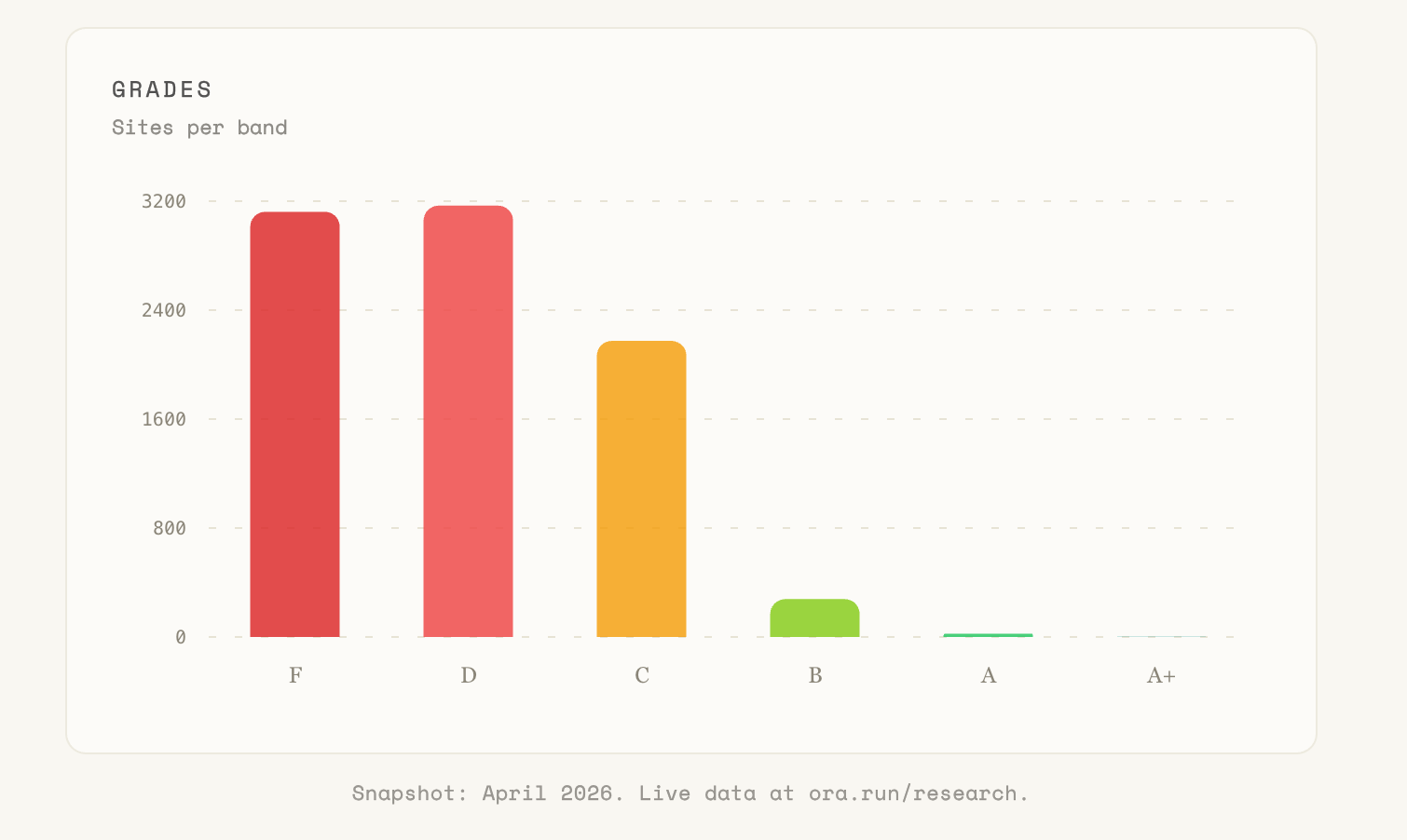
The distribution is weighted toward the floor. Roughly 73% of the dataset sits at D or F. The rest is mostly C, with a thin sliver above.
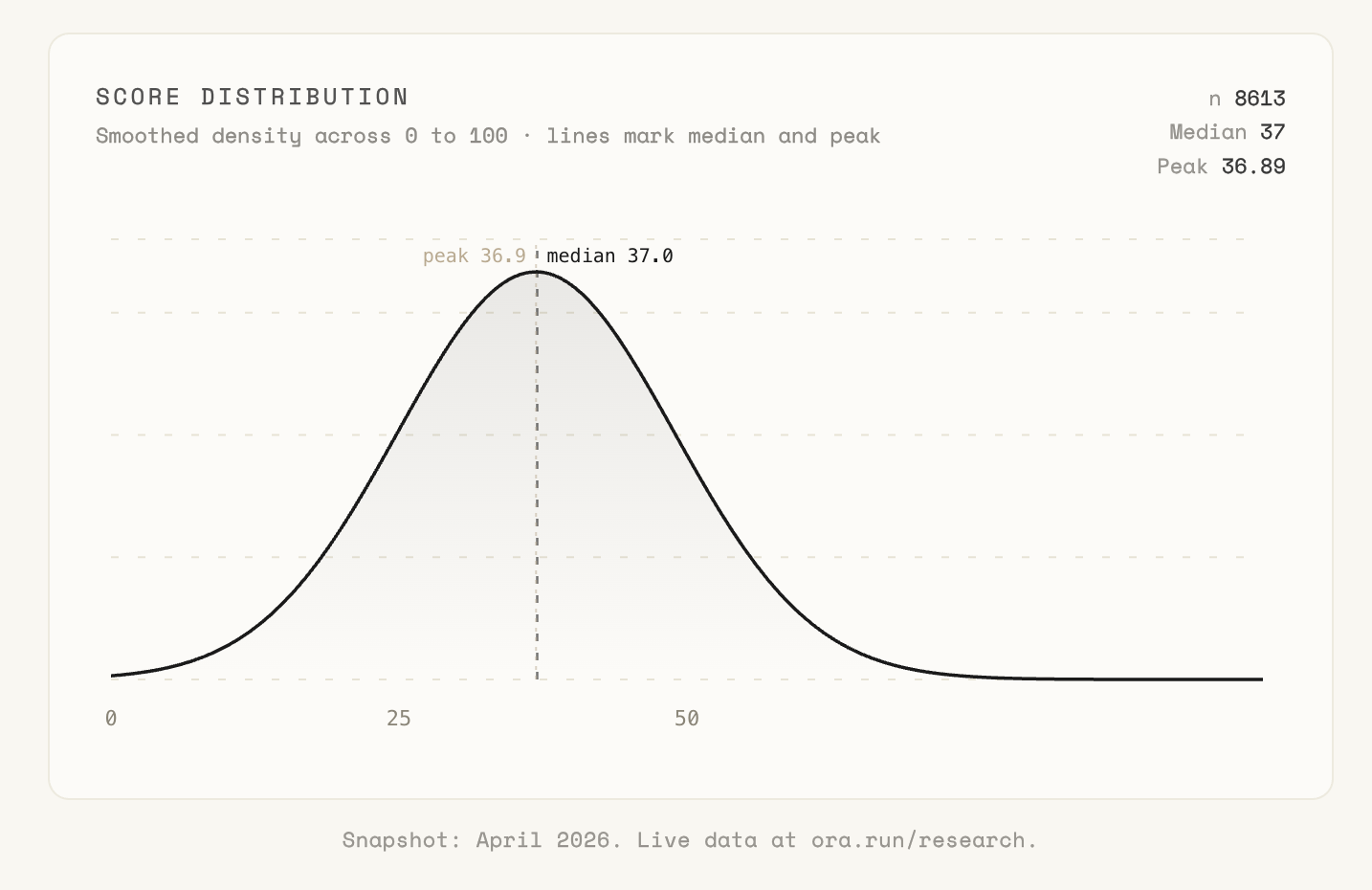
The curve is not a bell. ~66% of the mass sits to the left, peaks around the mid-30s, and trails off into a thin right tail of products that crossed 70. That shape is the single clearest picture in the dataset: the average site is a long way from the passing line, and the sites that crossed it are a minority with room to compound their lead.
Agents can read. They can’t act.
Crawl permissions are the easy win for the agents sites already recognize. ChatGPT-User reaches 81% of sites, ClaudeBot 82%, Google-Extended 87%, Qwen and DeepSeek close to 90%. OpenClaw, a newer agent without the same brand equity, only reaches 59% - 20-30 points below every other simulation we ran. Sites serve the names they know and block the ones they don’t; even read access is gated by brand, not policy. The moment any agent tries to do anything beyond read, the numbers collapse further.
爬虫权限是代理站点已识别的易得成果。ChatGPT-User覆盖81%的站点,ClaudeBot达82%,Google-Extended为87%,Qwen和DeepSeek接近90%。而新晋代理OpenClaw缺乏同等品牌认知度,覆盖率仅59%——比我们测试的其他模拟低20-30个百分点。站点只认知名品牌,不认陌生面孔;就连读取权限也由品牌而非政策决定。一旦任何代理尝试超越读取操作,数据会进一步崩塌。
Yes, an agent can fall back to browser use or headless scraping today and muscle through almost any site. It just costs 10-100x the tokens of a proper MCP call, runs an order of magnitude slower, and breaks the next time the DOM shifts.
The three places agents collapse are the same three every time: auth (they can’t log in on a user’s behalf), integration (no MCP, no typed tools, no streaming), and context (no machine-readable answer to “what does this business actually let me do”).
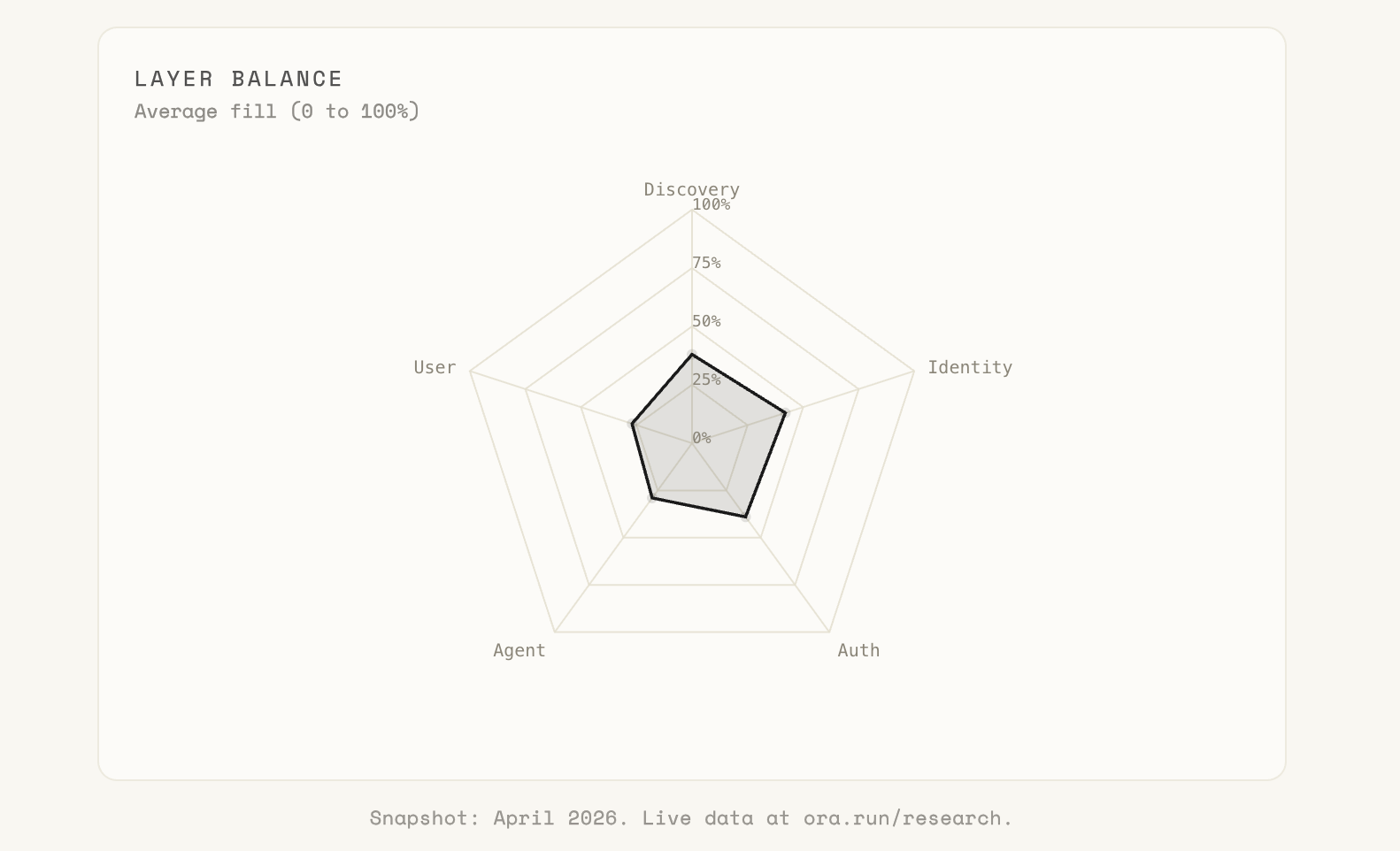
Agent Integration (MCP, webhooks, streaming, SDKs, function calling) averages 27%. User Experience (generative UI, verified integrations, multi-turn task completion) averages 22%. Discovery and Identity do better, but Auth & Access stalls in the high 30s. Read access is close to solved. Action is not.
Agents can read. They can’t act.
What the 1% do differently
Two things separate the leaders from everyone else. They ship the hard protocols, and they ship them correctly. Adoption of the protocols getting the most airtime in your feed is low and bimodal:
- Agents paying for things directly (x402, MPP) and tools that render apps inside the chat instead of plain text (MCP Apps): literal zero production deployments. MCP served from inside the webpage itself (WebMCP): 1%.
- The OAuth internals an agent needs to actually log in on a user’s behalf - machine-readable login endpoints (OAuth metadata) and the interception-proof auth flow (PKCE S256): ~1%.
- Agents generating live UI the client renders as native components instead of sending text (A2UI): ~2%.
- An agent’s public “here’s what I can do” profile (A2A Agent Card) and the standard for agents to message each other (ACP): ~12-13%.
- The static-file basics agents still rely on: an AI-oriented summary of your site (llms.txt), yes/no rules for AI crawlers (robots.txt AI policy), and a machine-readable map of your pages (sitemap): 48% / 50% / 69%.
Adoption tracks friction almost perfectly. Everything at the top is “write a static file, put it at a well-known path, done.” Everything at the bottom requires server code, OAuth metadata, PKCE, payment signing, or a UI DSL. A falsifiable prediction worth writing down: the agent-payment protocol that wins will be the one that ships as a single dependency in two languages, not the one with the cleanest spec.
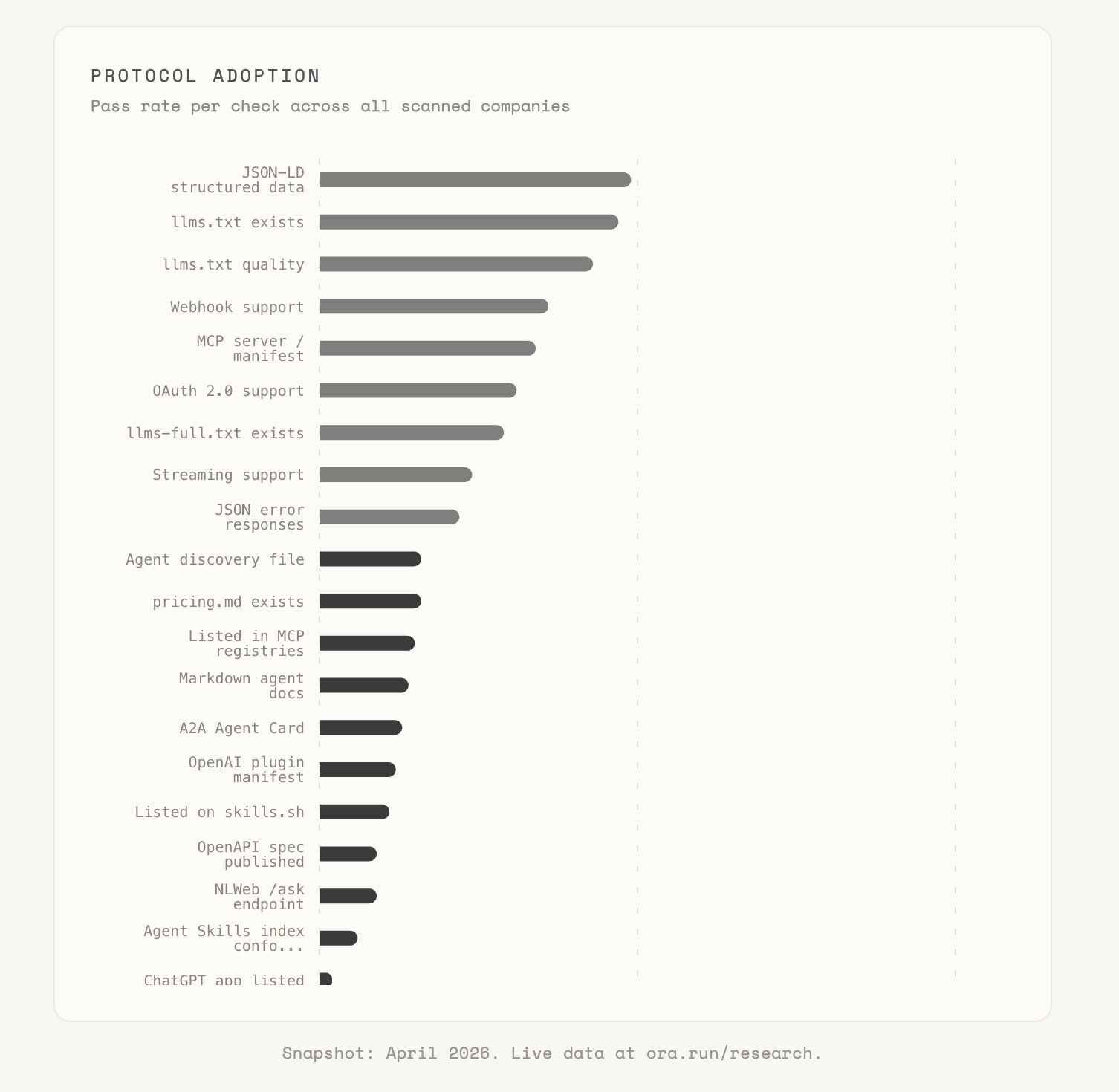
MCP tells the same story at a finer grain. 34% of products ship an MCP endpoint. 3% ship one with spec-grade tool descriptions, consistent naming, and Streamable HTTP transport. OAuth metadata and PKCE S256, the two bits that actually make an MCP server safe to plug into production, sit at 1%. The gap between claimed MCP and spec-compliant MCP is a reasonable description of the next 12 months of agent engineering.
SaaS is beating the agent-tools makers
Category rank tracks demand pressure more than technology. Whichever category has customers typing agent-sized prompts into a chat window this quarter is the category that shipped this quarter.
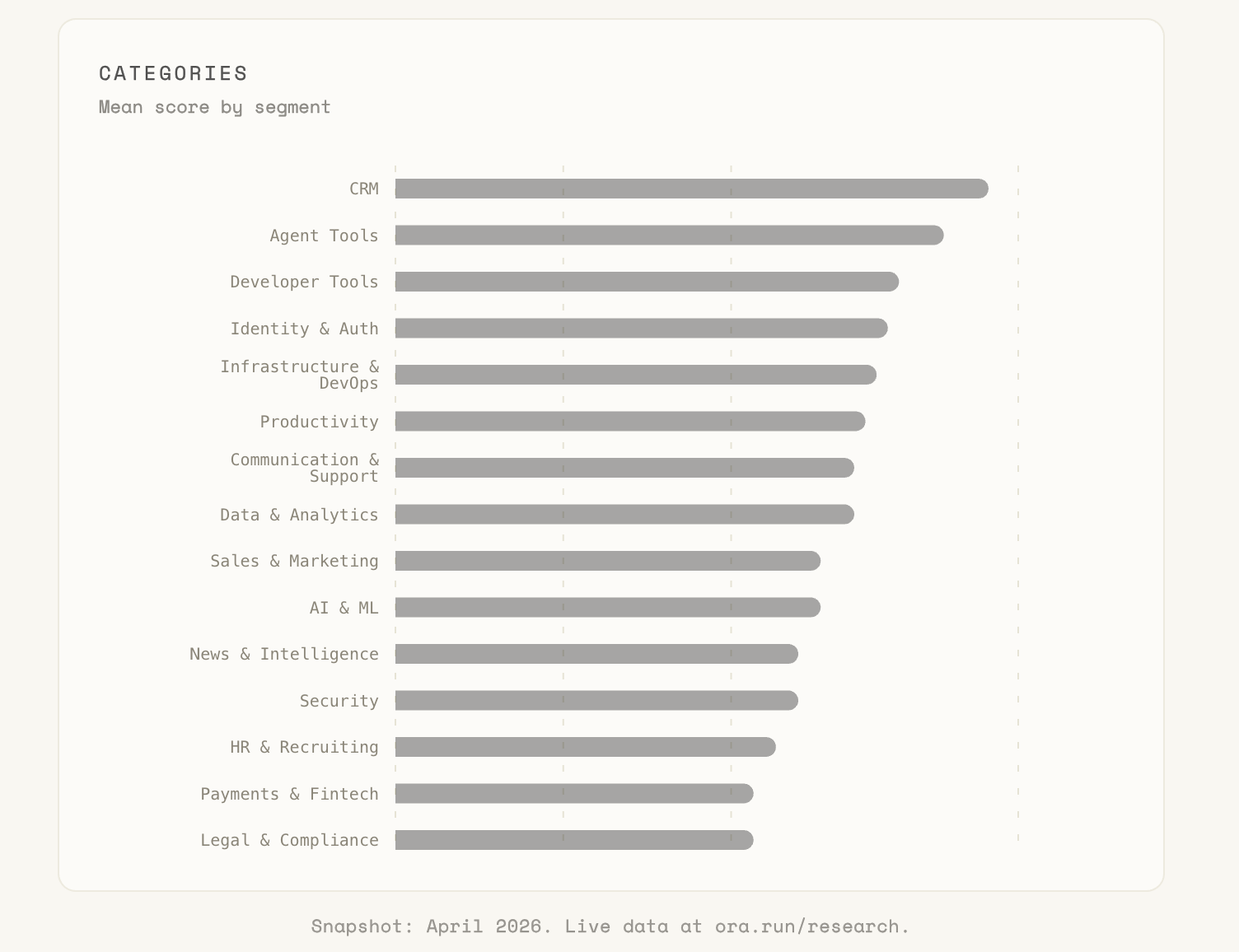
CRM leads at 50: the only category to cross into C territory, pulled up by Attio, Agentforce, and Pipedrive. Sales teams are already typing “log this in my CRM” into chat, so the integration gets prioritized. Agent Tools and Developer Tools tie for second because dogfooding forces the plumbing.
Consumer and Healthcare sit at the floor for obvious reasons: consumers still shop through browsers, and healthcare is compliance-gated. The deeper pattern underneath the ranking is B2B versus B2C. When your buyer is a business about to dispatch an agent, being agent-ready is how you stay in the consideration set, so the shift is existential. Consumers don’t care as much yet, and their suppliers haven’t been forced to either.
By Q4, 2026
We’ll re-score every claim in this section on January 15, 2027. If we’re wrong, you’ll see it on the same dashboard that produced the numbers above.
1. Sub-50 becomes a procurement disqualifier. Agent-readiness scores show up in B2B RFP templates the same way PageSpeed showed up in SEO briefs a decade ago. A sub-50 score won’t lose you a specific deal; it will lose you the chance to compete.
2. B2B crosses the line this year. Consumer waits until 2027. CRM, developer tools, and agent commerce pull their category averages above 65 by year-end. Consumer and healthcare stay under 40. The buyer side of B2B is already dispatching agents; the consumer side is still clicking.
3. The next 30 points require engineering, not static files. The ecosystem average has moved 30 points in a year, almost entirely from sites shipping a sitemap, llms.txt, and a softer robots.txt. Integration sits at 27% and UX at 22%; those numbers don’t move unless someone on the team writes code. “We have MCP” becomes as meaningless as “we have an API” the moment buyers start testing whether it actually works.
If you want to see where your own product sits on any of the layers above, scan it. The full live dashboard is at /research; the complete scoring framework is at /methodology. We’ll publish the grading post in January 2027.
How we scored this
Our Deep Scan spawns real agents (ChatGPT-User, ClaudeBot, Google-Extended, Qwen, DeepSeek, our own ora-agent, and OpenClaw) and runs a full session against each site. Every protocol is probed with a real handshake, not a string match. We score 110 checks across five weighted layers:
- Discovery. Can agents find you, crawl you, and understand what pages are worth reading.
- Identity. Do agents understand what you are, what you sell, and what actions you expose.
- Auth & Access. Can an agent authenticate, stay authenticated, and act on behalf of a user safely.
- Agent Integration. Is the plumbing there: MCP, webhooks, streaming, SDKs, function calling, agent payment rails.
- User Experience. Can a user complete a real task through an agent end-to-end.
Coverage tracks the specs that actually define the agentic web: RFC 8288 (link headers), RFC 8414 (OAuth server metadata), RFC 9309 (robots.txt), RFC 9421 (Web Bot Auth), RFC 9727 (API catalog), RFC 9728 (OAuth protected-resource metadata), the full Model Context Protocol surface (tool descriptions, OAuth, PKCE, Streamable HTTP, server cards), A2A, ACP, x402, MPP, llms.txt, and agentskills.io.
Scoring is relevance-aware. After every scan, an LLM reviews the results against product context and marks checks that are genuinely irrelevant (payment protocols for a free open-source tool, multi-language SDKs for a simple read-only API). N/A checks drop out of the denominator, so a site is never penalized for missing a protocol it had no reason to ship.
Every site gets a 0-100 score and a letter grade. An A means an agent can complete a task end-to-end. An F means it cannot get past the front page. Full scorecard and per-check breakdown at /methodology.
Disclosure: ora (the scanner that produced this report) grades at the top of its own framework. We exclude it from the leaderboard above to keep the picture about everyone else.
----
更多推荐


 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)