
《RAG技术的实现原理与落地实战》
摘要: RAG(检索增强生成)技术通过检索私有数据增强大模型生成能力,解决知识滞后、幻觉等问题。其核心流程分为离线构建(文档加载、分块、向量化存储)和在线推理(提问检索、生成回答)。本文从原理到实战,详解RAG技术栈(LangChain+Chroma+轻量Embedding模型),手把手实现多格式文档处理、智能分块、向量检索及Prompt优化问答链,并提供完整代码与高频问题解决方案。进阶方向包括混
一、前言:为什么 RAG 是大模型落地的核心技术?
1. 原生大模型三大痛点:知识滞后、幻觉严重、无法使用私有数据 2. 微调 VS RAG 对比:成本、时效性、可维护性、落地门槛差异 3. RAG核心价值:不训练模型、实时更新私有知识、从根源降低幻觉 4. 行业落地场景:企业知识库、私人文档问答、智能客服、本地知识库助手 5. 本文实战目标:从零搭建标准RAG基础架构,跑通数据处理、检索、问答全流程
二、核心原理:彻底搞懂 RAG 工作机制
2.1 RAG 是什么?检索增强生成核心定义
1. RAG全称与核心思想:Retrieval-Augmented Generation 检索增强生成 2. 核心逻辑:先检索私有真实数据 → 再交给大模型生成答案 3. 与纯大模型对话的本质区别:有依据、可溯源、无幻觉、知识实时更新
2.2 RAG 两大核心阶段(必懂)
阶段1:离线构建阶段(知识库搭建) 文档加载 → 文本清洗 → 智能分块(Chunk) → Embedding向量化 → 向量库持久化存储 阶段2:在线推理阶段(问答交互) 用户提问 → 问题向量化 → 相似文档检索 → Prompt拼接上下文 → LLM生成回答
2.3 核心模块原理详解
1. 文本分块原理:为什么不能全文检索?Chunk大小、重叠率、切分规则逻辑 2. Embedding向量化原理:文本转高维向量、语义相似度匹配机制 3. 向量数据库原理:近似最近邻搜索、向量存储与快速检索优势 4. Prompt增强原理:如何把检索结果融入提示词,约束模型生成真实答案
2.4 基础RAG VS 进阶RAG 区别
基础RAG流程局限、进阶优化方向(重排序、混合检索、查询改写、上下文压缩)
三、RAG 实战环境与项目准备
3.1 技术栈选型(轻量易落地)
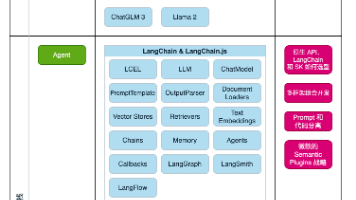
1. 核心框架:LangChain 2. 向量数据库:Chroma(轻量无需部署,新手首选) 3. Embedding模型:开源轻量模型/在线Embedding接口 4. 大模型:本地开源模型/API模型 5. 支持文档:PDF、TXT、MD、Word多格式适配
3.2 环境依赖安装
全套依赖一键安装命令,适配Windows/Linux,规避版本冲突
3.3 项目目录结构规范
标准化工程目录,方便后续迭代、部署、二次开发
四、手把手实战:从零搭建完整 RAG 系统
4.1 第一步:多格式文档加载与数据清洗
1. PDF/TXT/MD文档批量加载代码 2. 无效字符、空行、乱码清洗处理逻辑 3. 文档元数据保存(页码、来源、路径,用于答案溯源)
4.2 第二步:智能文本分块(RAG效果关键)
1. 递归字符分块实战代码 2. Chunk大小、重叠率最优参数讲解 3. 分块避坑:避免截断语义、避免上下文断裂
4.3 第三步:文本向量化与向量库构建
1. Embedding模型加载与向量化代码 2. Chroma向量数据库创建、持久化存储 3. 增量入库逻辑(无需重复全量向量化)
4.4 第四步:检索器配置与相似文本召回
1. Top-K 检索参数调优 2. 基础语义检索实现 3. 检索结果筛选与过滤规则
4.5 第五步:Prompt工程与问答链搭建
1. RAG专属提示词模板编写(约束模型、拒绝幻觉) 2. LangChain QA链初始化 3. 上下文拼接、答案生成、溯源展示
4.6 第六步:完整问答效果测试
1. 普通问题、细节问题、隐含问题多场景测试 2. 问答效果展示、答案溯源查看 3. 微调前后效果对比
五、完整可运行 RAG 代码示例(整合版)
1. 端到端全套整合代码(加载-分块-向量化-检索-问答) 2. 逐行详细注释,关键参数标注 3. 可直接复制运行,无需复杂配置 4. 自定义修改指南:替换私有文档、更换模型、调整检索参数
六、RAG 开发高频问题与全套避坑方案(干货)
6.1 检索效果差问题
1. 检索内容不相关、召回率低解决方案 2. 关键信息漏召回、检索结果杂乱优化方法 3. Chunk大小不合理导致的效果差根治方案
6.2 模型幻觉、答非所问问题
1. 脱离文档凭空回答解决办法 2. 上下文冗余、信息干扰优化方案 3. Prompt约束优化、检索结果精简技巧
6.3 性能与效率问题
1. 向量化速度慢、重复量化问题优化 2. 检索延迟高、问答卡顿解决方案 3. 大文档、批量文档处理提速技巧
6.4 代码报错与环境问题
1. 文档加载失败、编码报错修复 2. 向量库重复创建、加载异常解决 3. Embedding维度不匹配、模型调用失败处理
七、进阶优化:从 Demo 升级为生产级 RAG
1. 混合检索优化:BM25+语义检索双模式融合 2. 重排序Rerank提升检索精准度 3. 查询改写、问题拆分优化复杂问答 4. 上下文压缩、动态Chunk自适应优化 5. RAG结果评估指标:召回率、精准率评测方法
八、总结与落地建议
1. 基础RAG核心流程与核心优势总结 2. 新手落地最优学习路径 3. 不同场景选型建议(小知识库/企业大知识库) 4. RAG+微调组合落地最佳实践
更多推荐
 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)