
【PN1.2】From reactive to cognitive: brain-inspired spatial intelligence for embodied agents(二)Method
上篇文章介绍了该论文做的一些实验,了解了这个框架在三种任务中的表现效果。这个工作能work的关键在于知识库的构建及利用。下面重点介绍这块内容。
2Methodology
2.1 Pipline
首先是该工作整体pipeline,大致流程就是,将环境观察的内容进行投影,构建Landmark memory和cogntive map(这两个是会不断更新的)。然后working memory会根据检索内容的模态,使用不同策略进行检索并输出候选坐标,根据坐标规划行动路径。
简单来说,Landmark memory和cogntive map可以理解为机器人的记忆,然后work memory类似路由和执行器,根据搜索模态使用不同的搜索策略并输出目标坐标。
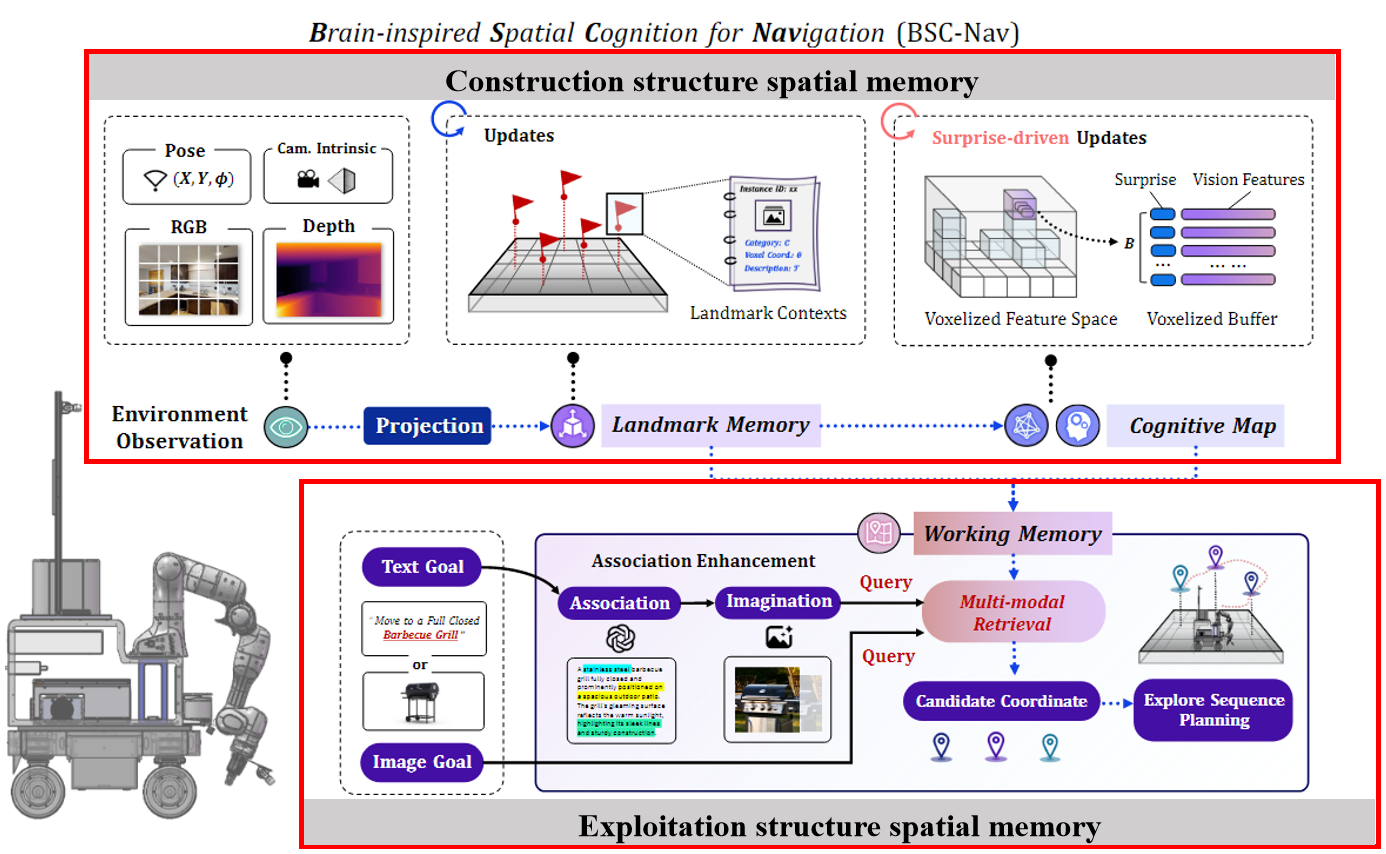
我认为该工作本质是 BSC-Nav = MLLM + Structure spatial Memory (Construction and Exploitation) 。 MLLM 采用都是现成的,所以该工作的核心在于构建和利用spatial structure memory,所以下文讲重点介绍这两工作的实现细节。
2.2 构建结构空间记忆
空间记忆构建大致流程是 ,agent通过不同策略探索环境,在探索过程中,将其observation进行特征提取然后存储。
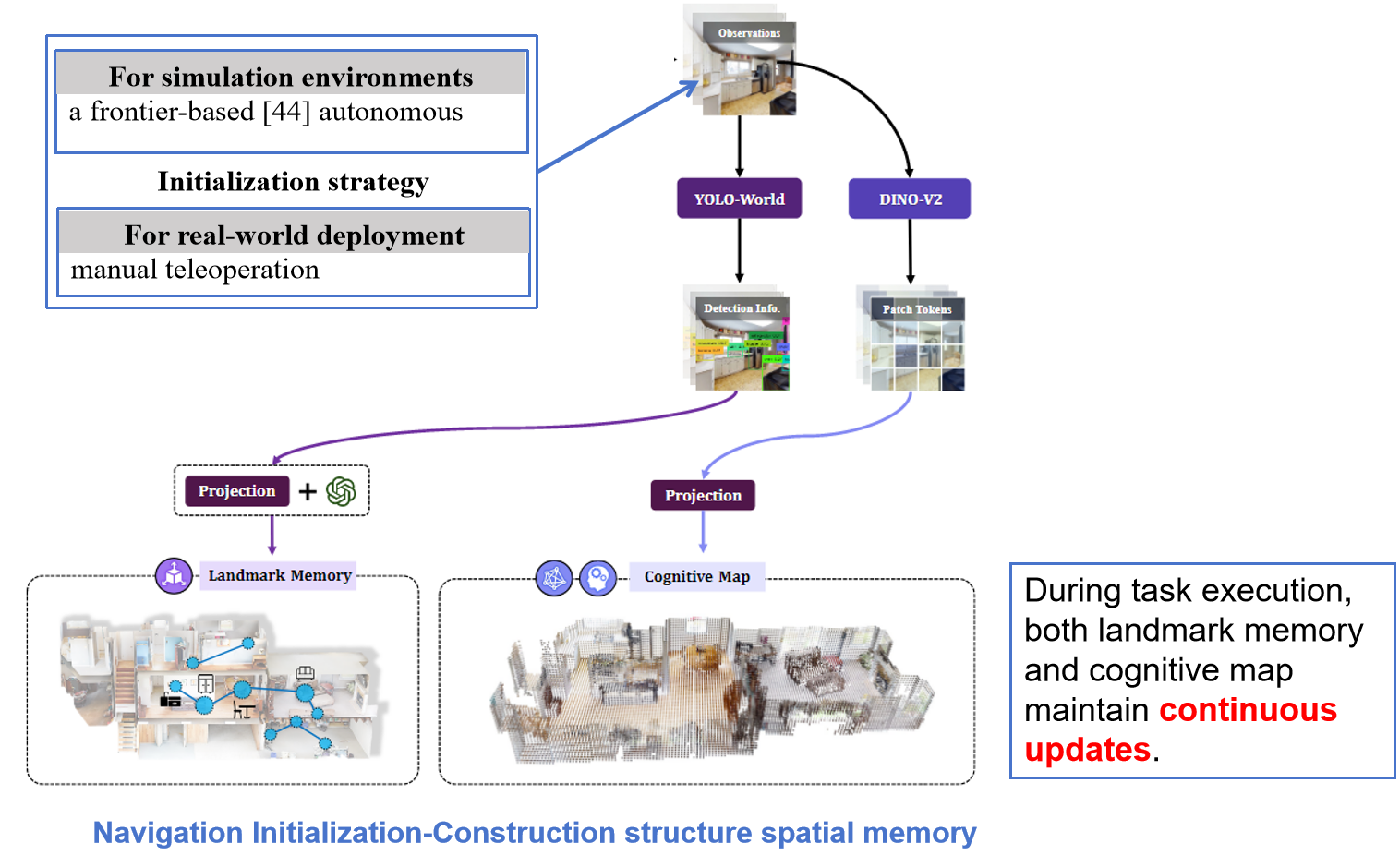
2.1初始化策略
在不同的测试环境下,智能体的空间记忆初始化策略不同,在模拟场景下采用的是 frontier-based 策略,在现实场景则是手工远程操作。
2.2输入 Observation
agent的输入主要有 RGB image depth image 和 agent's pose

2.3 特征提取方法
1. 将Observation 输入到VOLO-WORLD 模型提取显著性的线索。 VOLO-World的检测结果进行投影,还有用GPT增加文字描述后,作为landmark memory的构建信息源。
2.将Observation 输入到DINO-V2里面去提取图像的patch-level的特征。DINO-V2的输出投影后作为cognitive map的信息源。
2.4 存储内容
2.4.1.Landmark memory
2.4.1.1 定义
这个landmark memory 存储的数据结构是list 里面存了内容是一个个的四元组,四元组解析如下,ck表示的是第k个landmark的 category ,θk是第k个landmark中心的世界坐标,ρk是第k个landmark判别为category的置信度,Tk 是第k个landmark描述的内容,包括了纹理、形状和空间上下文语义信息。

各个参数的获取解释如下,
ck 和ρk :由将salient instances输入到 open-vocabulary object detector YOLO-World 获得,ck ∈ C, C是预定义的类别集合 C ={"sofa", "sink", "bed", . . .} ,ρk是模型输出的该类比对应的置信度
Tk :用GPT-4o 获得,实际存储的时候并没有存该内容
θk: 由于agent用相机capture landmark,所以我们只有landmark的像坐标(uk, vk),利用相机的内外参数就可以从像坐标转换世界坐标,公式如下,详细解释参考原文
![]()
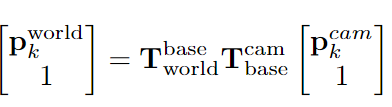
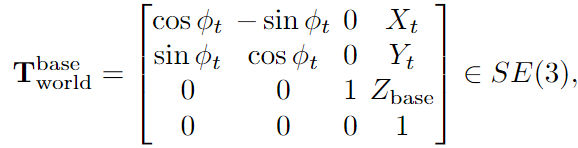
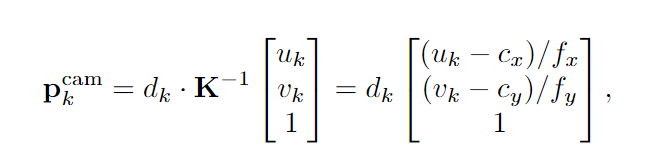
2.4.1.2 更新策略
由于landmemory是会随着agent移动不断更新,在同一个空间来回移动不可避免会observe到同一个实例,为了避免重复存储同个实例,作者提出对每个新检测到的实例 LN +1都进行重叠检测,空间重叠定义如下:
![]()
这个策略大致就是,如果观察到一个新的landmark LN +1,那就将该 LN +1跟 landmark里面每个实例Lj进行重叠性的判断,如果满足两个条件,1.新实例跟存储的实例位置的欧式距离小于阈值,2.新实例的类别跟存储实例类别相同(具体可以看下面实现代码),那将该元素放入集合U中。当遍历landmark里面每个元素后,如果集合U不为空时,就将该集合里面的元素进行下面的融合操作。
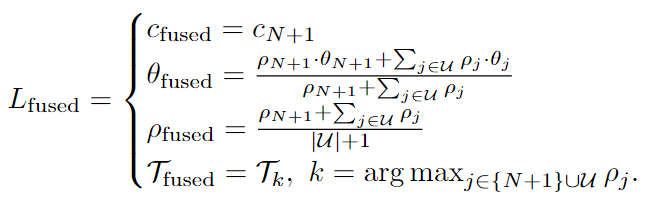
这个融合操作内容是
c取最新的,θ取集合U里面所有元素的加权几何中心,实际代码是直接用新的location的坐标,ρ 写作是所有元素的平均值,实际代码是用的是几个元素里面confidence最大的,T是取可信度最大的,实际landmemory没有存储该元素(我觉得也合理这个东西占内存,存着意义不大)
2.4.1.3 实现核心代码
以下几个方法的代码是在memory_2.py文件中,跟landmark memory 和cogntive map相关也都在里面
2.4.1.3.1构建 structure spatial memory代码
包含 landmark memory 和cogntive map构建
def create_memory(self):
self.initial_memory()
last_action = None
release_count = 0
obs = self.Env.sims.get_sensor_observations(0)
step_num = 0
while True:
self._show_map_online(obs)
k, action = keyboard_control_fast()
if k != -1:
if action == "stop":
break
if action == "record":
init_agent_state = self.sim.get_agent(0).get_state()
actions_list = []
continue
last_action = action
release_count = 0
else:
if last_action is None:
time.sleep(0.01)
continue
else:
release_count += 1
if release_count > 1:
# print("stop after release")
last_action = None
release_count = 0
continue
action = last_action
step_num += 1
obs = self.Env.sims.step(action)
agent_state = self.Env.agent.get_state()
print("agent_state: position", agent_state.position, "rotation", agent_state.rotation)
if step_num % 10 == 0:
self.base_height.append(agent_state.position[1])
pos, rot = agent_state.position, agent_state.rotation
pose = np.array([pos[0], pos[1], pos[2], rot.x, rot.y, rot.z, rot.w])
# 构建 cognitive map
self.obs2voxeltoken(obs, pose)
# 构建 landmark memory
self.long_memory(obs)
cv2.destroyAllWindows()
# self._visualize_rgb_map_3d(self.grid_pos, self.grid_rgb)
np.save(self.memory_save_path + "/grid_rgb_pos.npy", self.grid_rgb_pos[:self.max_id])
np.save(self.memory_save_path + "/grid_rgb.npy", self.grid_rgb[:self.max_id])
np.save(self.memory_save_path + "/weight.npy", self.weight[:self.max_id])
np.save(self.memory_save_path + "/occupied_ids.npy", self.occupied_ids)
np.save(self.memory_save_path + "/max_id.npy", np.array(self.max_id))
np.save(self.memory_save_path + "/original_pos.npy", self.Env.original_state.position)
np.save(self.memory_save_path + "/map_height.npy", np.array([self.minh, self.maxh]))
np.save(self.memory_save_path + "/base_height.npy", np.array(self.base_height))
with open(self.memory_save_path + "/long_memory.json", 'w') as f:
json.dump(self.long_memory_dict, f, indent=4)2.4.1.3.2 landmark的构建用
# landmark的构建用 yolo-world提取特征,然后存储到landmemory中
def long_memory(self, obs):
self.yolow_results = self.yolow.predict(Image.fromarray(obs["rgb"][:,:,:3]), conf=self.args.detect_conf)
if len(self.yolow_results[0].boxes) > 0:
depth = np.array(obs["depth"])
pc, mask = depth2pc(depth, intr_mat=self.calib_mat, min_depth=self.min_depth, max_depth=self.max_depth)
center = []
confs = []
labels = []
# 遍历yolo 检测结果
for i in range(len(self.yolow_results[0].boxes.conf)):
xyxy = self.yolow_results[0].boxes.xyxy[i].cpu().numpy()
col = int((xyxy[0] + xyxy[2])/2)
row = int((xyxy[1] + xyxy[3])/2)
index = row * self.args.width + col
if mask[index]:
center.append(index)
confs.append(self.yolow_results[0].boxes.conf[i].item())
cls = int(self.yolow_results[0].boxes.cls[i].item())
labels.append(self.args.detect_classes[cls])
# 将检测结果的center 换行得到3D 坐标,构建memory dict里面的元素
if len(center) != 0:
center = np.array(center)
pc = pc[:, center]
pc_transform = self.tf @ self.base_transform @ self.base2cam_tf
pc_global = transform_pc(pc, pc_transform)
for i, (p, p_local) in enumerate(zip(pc_global.T, pc.T)):
row, col, height = base_pos2grid_id_3d(self.gs, self.cs, p[0], p[1], p[2])
if self._out_of_range(row, col, height):
continue
height = height - self.minh
# 这里少了gpt的描述,跟论文描述的没对上
instance = {
'label': labels[i],
'loc': [row, col, height],
'confidence': confs[i]
}
self.long_memory_dict.append(instance)
# 判断是否要合并memory
self.long_memory_integration()2.4.1.3.3 landmark的合并代码
# 判断是否需要合并 avoid same instances
def long_memory_integration(self, threshold=3):
def l1_distance(loc1, loc2):
return sum(abs(a - b) for a, b in zip(loc1, loc2))
# 根据label分组
label_groups = {}
for item in self.long_memory_dict:
label = item["label"]
if label not in label_groups:
label_groups[label] = []
label_groups[label].append(item)
final_results = []
for label, items in label_groups.items():
# 用来存放筛选后的条目
filtered = []
for itm in items:
merged = False
for f in filtered:
# 判断是否在距离阈值以内
if l1_distance(f['loc'], itm['loc']) <= threshold:
# 如果在距离阈值以内,保留 confidence 最大的条目
if itm['confidence'] > f['confidence']:
f['loc'] = itm['loc']
f['confidence'] = itm['confidence']
merged = True
break
if not merged:
filtered.append(itm)
final_results.extend(filtered)
self.long_memory_dict = final_results2.4.2. Cognitive map
2.4.2.1定义
认知地图是一个离散的体素化表征,这个三维空间里面每个点存储的是一个buffer,buffer里面存储B个特征向量,这些特征的维度是h。
认知地图的公式定义如下
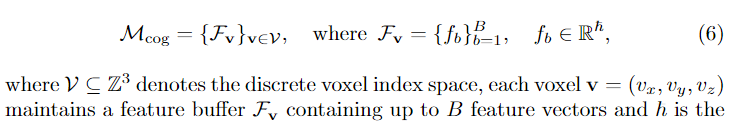
![]()
认知地图中的特征获取流程大致如下,将agent观测得到的图片输入到DINO-V2,然后就会得到一些patchs的features。经过转换可以得到,每个patch的像平面坐标

然后,利用相机的参数,将这些patchs的相平面坐标转换得到3D世界坐标(该转换跟前面Landmark memory构建过程中的转换相同)。
由于congnitive map用体素网格表征,还需要以下操作才能得到每个体素对应的3D世界坐标
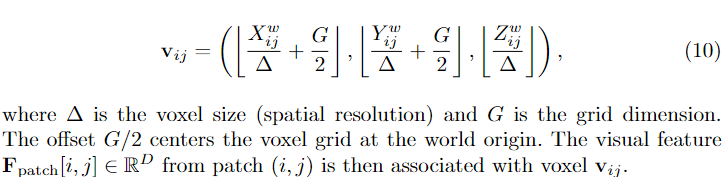
经过以上变化,我们就可以得到每个体素的世界坐标,相平面坐标,还有对应的patch,从而得到其相应的特征值。
2.4.2.2更新策略
为了避免冗余存储,受生物学习和记忆的启发,作者采用了一种free-energy principle 的策略,为每个体素维护动态缓冲区,并引入基于惊喜的更新策略。作者说该策略的优势在于增强在动态环境下空间知识的鲁棒性,还有维持内存存储和检索的效率。
一个观察得到的新特征是否可以加入到buffer中的判断条件是,通过一下公式11计算得到的惊喜分是否大于τ=0.5 ,如果大于就可以加入buffer中。在加入前还会执行一个判断,如果buffer中特征数量等于最大数量B时,就用新特征替换buffer里面score最低的特征。

2.4.2.3 实现核心代码
2.4.2.3.1 构建cognitive map代码
# 构建cognitive map代码
def obs2voxeltoken(self, obs, pose):
if len(self.inv_init_base_tf) == 0:
self.init_base_tf = cvt_pose_vec2tf(pose)
self.init_base_tf = self.base_transform @ self.init_base_tf @ np.linalg.inv(self.base_transform)
self.inv_init_base_tf = np.linalg.inv(self.init_base_tf)
habitat_base_pose = cvt_pose_vec2tf(pose)
base_pose = self.base_transform @ habitat_base_pose @ np.linalg.inv(self.base_transform)
self.tf = self.inv_init_base_tf @ base_pose
rgb = np.array(obs["rgb"][:,:,:3])
depth = np.array(obs["depth"])
# 用dinoV2 获取 image的 patch token
patch_tokens = self._get_patch_token(rgb)
patch_tokens_intr = get_sim_cam_mat(patch_tokens.shape[0], patch_tokens.shape[1])
pc = self._backproject_depth(depth)
pc_transform = self.tf @ self.base_transform @ self.base2cam_tf
pc_global = transform_pc(pc, pc_transform)
for i, (p, p_local) in enumerate(zip(pc_global.T, pc.T)):
row, col, height = base_pos2grid_id_3d(self.gs, self.cs, p[0], p[1], p[2])
if self._out_of_range(row, col, height):
continue
height = height - self.minh
px, py, pz = project_point(self.calib_mat, p_local)
rgb_v = rgb[py, px, :]
px, py, pz = project_point(patch_tokens_intr, p_local)
radial_dist_sq = np.sum(np.square(p_local))
sigma_sq = 0.6
alpha = np.exp(-radial_dist_sq / (2 * sigma_sq))
if not (px < 0 or py < 0 or px >= patch_tokens.shape[1] or py >= patch_tokens.shape[0]):
if self.iter_id >= self.iter_size:
self.update_memory_dist_base()
else:
self.grid_feat[self.iter_id, :] = patch_tokens[py, px, :].cpu().numpy()
self.grid_feat_pos[self.iter_id, :] = [row, col, height]
self.grid_feat_dis[self.iter_id] = radial_dist_sq
self.iter_id += 1
occupied_id = self.occupied_ids[row, col, height]
if occupied_id == -1:
self.occupied_ids[row, col, height] = self.max_id
self.grid_rgb[self.max_id] = rgb_v
self.weight[self.max_id] += alpha
self.grid_rgb_pos[self.max_id] = [row, col, height]
self.max_id += 1
else:
self.grid_rgb[occupied_id] = (self.grid_rgb[occupied_id] * self.weight[occupied_id] + rgb_v * alpha) / (
self.weight[occupied_id] + alpha
)
self.weight[occupied_id] += alpha
if height >= self.max_height[row, col]:
self.max_height[row, col] = height
self.cv_map[row, col] = rgb_v2.4.2.3.2 更新congitive map代码
def update_memory_dist_base(self):
print("updating memory...")
t1 = time.time()
with h5py.File(self.feat_path, 'a') as h5f:
for i in range(self.grid_feat.shape[0]):
grid_id = f'{self.grid_feat_pos[i][0]}_{self.grid_feat_pos[i][1]}_{self.grid_feat_pos[i][2]}'
group_name = f'grid_{grid_id}'
if group_name not in h5f:
group = h5f.create_group(group_name)
group.create_dataset('features', data=self.grid_feat[i:i+1], maxshape=(None, self.grid_feat.shape[1]), chunks=True)
group.create_dataset('distances', data=self.grid_feat_dis[i:i+1], maxshape=(None,), chunks=True)
else:
group = h5f[group_name]
features = group['features']
distances = group['distances']
if features.shape[0] < self.cache_size:
features.resize((features.shape[0] + 1, features.shape[1]))
distances.resize((distances.shape[0] + 1,))
features[-1] = self.grid_feat[i]
distances[-1] = self.grid_feat_dis[i]
else:
remove_idx = random.choice(range(distances.shape[0]))
features[remove_idx] = self.grid_feat[i]
distances[remove_idx] = self.grid_feat_dis[i]
print(f"finish updating, time:{time.time() - t1}")
self.get_total_token_count()
self._reinit_cache()
2.3 利用结构空间记忆
2.3.1概述
结构特征记忆的利用主要通过work memory来实现。下图是working memory的pipeline,根据navigation instruction的 complexity采用不同的搜索策略。具体介绍如下
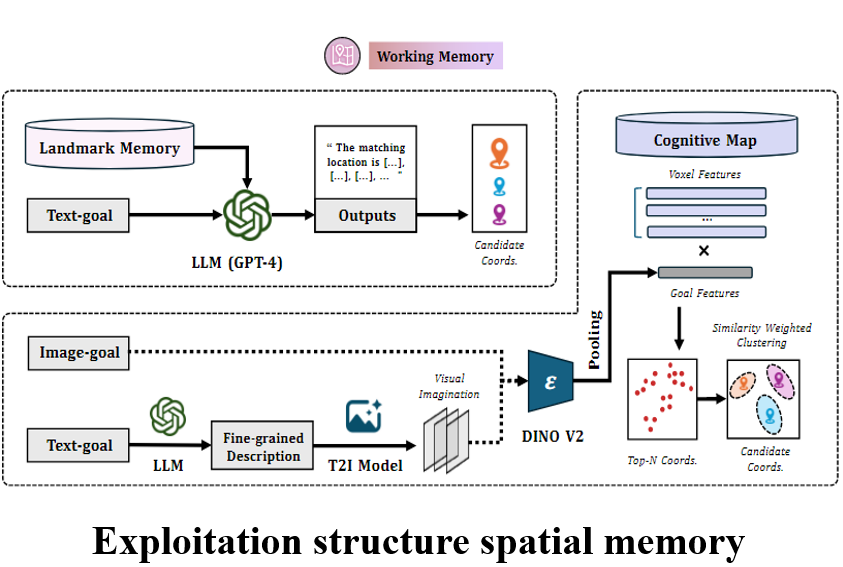
对于简单的导航指令(例如如某个物体名称的搜索),直接检索landmark memory如下图a。对于细粒度文本或基于图像的导航指令,则检索认知地图(图2b)。
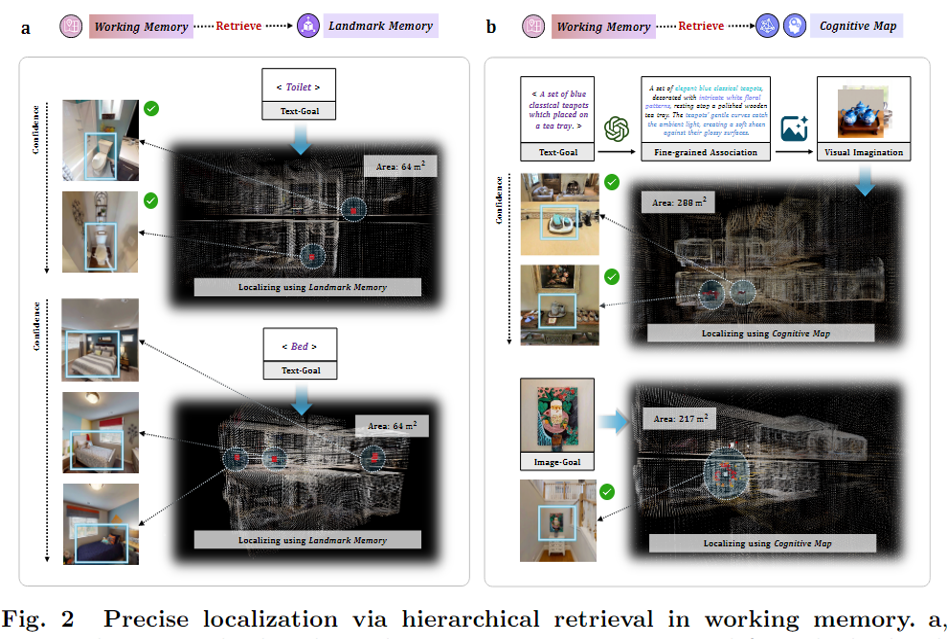
2.3.2模块功能介绍
1.MLLM-reasoning retrieval for landmark memory 用MLLM对landmark memory检索
这是针对简单导航指令的功能,大致是把landmark memory的内容,导航指令,填入到提前定义好的prompt,然后丢给gpt-4o,让它生成目的地候选坐标集合。
2.Association-enhanced retrieval for cognitive map. 关联增强检索
当导航指令是细粒度的文本或者图片,就会retrieve cognitive map。
cognitive map的retrieve都是用图片,那么文本怎么变成图片,这也是为什么叫增强检索的原因,对于细粒度的文本,作者先用GPT-4o优化这个文本描述,以丰富他们的的纹理和空间上下文信息。然后这些信息被输入到Stable Diffusion 3.5中以生成该场景的多张图片。
这些图片会用DINO-V2提取patch-level features,然后采用一种中心距离加权池化算法以优化特征得到一个global feature。(作者文章中没有讲清楚,有多个patch-level features 是对他们分别用加权池化算法吗?我觉得是,因为看后面最后有Q个候选坐标,feature的数量也是Q个)。作者说这种池化能抑制背景干扰,增强目标实例的中心特征。
得到这个global feature之后,作者采用一种相似度权重DBSCAN聚类算法,获得簇中心的网格坐标作为候选的空间坐标。这些网格坐标(congitive map里面的)需要进一步反投影得到他们的3D世界坐标,以便后续的低层次规划。
该模块以上两个利用structure spatial memory 之外, work memory还有三个功能
3.Exploration sequence planning 探索序列规划
由于有多个waypoints 每个waypoints可能有多个 candidates,为了提高导航的效率需要对这些候选点进行排序。作者设计了一种算法对候选坐标进行筛选(公式13,如下所示)

该算法考虑了目标的存在概率和空间距离(跟starting point的距离)。如果候选目标是从landmark得到,那就用他的置信度作为存在概率。如果是从congitive map得到,就用他与查询特征的相似度作为存在概率。空间距离距离就是candidate跟starting point之间的欧式距离。
利用该公式计算后就可以得到每个candidate的分数,然后选择前K个分数最高的。
排序代码
def weighted_cluster_centers(self, top_k_positions, top_k_similarity, eps=10, min_samples=5):
db = DBSCAN(eps=eps, min_samples=min_samples)
labels = db.fit_predict(top_k_positions)
unique_labels = [lbl for lbl in set(labels) if lbl != -1]
cluster_info = []
for lbl in unique_labels:
cluster_mask = (labels == lbl)
cluster_points = top_k_positions[cluster_mask]
cluster_weights = top_k_similarity[cluster_mask]
weighted_center = np.average(cluster_points, axis=0, weights=cluster_weights)
avg_similarity = np.mean(cluster_weights) # 计算相似度均值
cluster_info.append((avg_similarity, weighted_center, np.sum(cluster_mask)))
# 根据相似度均值进行降序排序
cluster_info.sort(key=lambda x: x[0], reverse=True)
cluster_centers = np.array([info[1] for info in cluster_info])
cluster_sizes = [info[2] for info in cluster_info]
return cluster_centers, labels, cluster_sizes4.Low-level navigation policy generation 低层导航策略生成
在模拟环境中,作者采用Habitat simulator 提供的贪心最短路经算法
在现实环境中,作者采用一种两级规划架构。全局规划用基于LiDAR的SLAM构建的占用网格地图上使用A*算法进行的,从而获得全局最优路径。局部规划用Timed Elastic Band (TEB)算法,动态调整轨迹以避免障碍物,同时保持效率。TEB规划器输出连续的速度指令以控制机器人底盘,确保平稳和精确的运动执行。
5.Goal verification and affordance 目标验证
到达目标之后,BSC-Nav就在候选的目标用摄像头扫一圈得到一序列的RGB图像。
然后用CLIP计算这些RGB图像embedding跟目标文本或者目标图像embedding之间的余弦相似度以确定跟目标语义对齐的最佳角度。
然后选择的图像被输入到GPT-4o中以实现目标验证。
此外GPT-4o还被用于生成一系列的动作引导agent方向和相对位置。
2.3.3 实现代码
2.3.3.1 一个structure spatial memory利用的实例
输入text ,先用landmark搜索,如果找到了,就确定路径,达到后拍周围。任务就完成。如果没有就用congitive map搜索。
def move2textprompt(self):
text_prompt = input("Please describe where you want to go:")
self.task_over = False
# Step 1: Attempt long-term memory retrieval
best_pos = self.long_term_memory_retrival(text_prompt)
if best_pos is not None:
best_pos = self._grid2loc(best_pos)
path, self.goal = self.memory.Env.move2point(best_pos)
_, _ = self.execute_path(path)
self.check_around(text_prompt)
if self.task_over:
return
# Step 2: Attempt working memory retrieval if long-term retrieval fails
best_poses = self.working_memory_retrival(text_prompt)
for best_pos in best_poses[0]:
best_pos = self._grid2loc(best_pos)
path, self.goal = self.memory.Env.move2point(best_pos)
_, _ = self.execute_path(path)
self.check_around(text_prompt)
if self.task_over:
break
else:
continue
2.3.3.2简单导航指令 利用 landmark memory
#根据text搜索landmemory
def long_memory_localized(client, text_prompt, long_memory):
completion = client.chat.completions.create(
model="gpt-4o",
timeout=500,
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": """
You are an LLM Agent with a specific goal: given a textual description of a navigation target (e.g., “A marble island in a kitchen.”)
and a memory list containing instances of detected objects, each with a label, a 3D location (three numerical coordinates), and a confidence score,
you need to determine the most suitable memory instance to fulfill the navigation request.
**Your memory data structure:**
The memory is a list of objects in the environment, where each object is represented as a JSON-like structure of the following form:
{
"label": "<string>",
"loc": [<float or int>, <float or int>, <float or int>],
"confidence": <float>
}
label: A textual label describing the object (e.g., “a tv”, “a kitchen island”).
loc: A three-element array representing the coordinates of that object in the environment.
confidence: A floating-point value indicating how confident the system is in identifying this object as described by label.
**Your task:**
1.Understand the target description: You will be given a textual goal description of a navigation target, such as “A marble island in a kitchen.”
Your first step is to interpret this description and deduce which object label from the memory best matches it semantically.
For example, if the target is “A marble island in a kitchen,” and you have memory instances labeled “a kitchen island” or “a marble island,”
you should identify that these instances correspond to the target description. Consider synonyms and close matches. If no exact label is found,
choose the label that is most semantically similar to the target description. For instance, if the target mentions “a marble island” and the memory only has “a kitchen island,”
you should still select the “a kitchen island” label as it is likely the intended object.
2.Identify the relevant instances: Once you have determined the best matching label, filter the memory list to only those instances whose label matches (or closely matches) that label.
3.Evaluate confidence and consolidate duplicates: Among these filtered instances, consider that multiple memory entries may actually represent the same object,
possibly due to partial overlaps or multiple detections.
- Look at their loc coordinates. If multiple instances with the same label have very close or nearly identical coordinates, treat them as the same object.
- Determine which set of coordinates (if there are multiple distinct sets) is the most reliable representation of the object. Reliability is judged primarily by the highest confidence value. If multiple instances cluster together with similar locations, select the one with the highest confidence or, if confidence is similar, the one that best aligns with the object as described.
4.Select the final loc: After you have grouped instances and decided which group best represents the target object, output the coordinates (loc) of the best match.
If multiple objects (>=3 items) match the description equally well, choose the three coordinates (loc) with the highest confidence.
5.Produce a final answer: Return the selected location coordinates as the final answer, (important!!) must be in the format '**Result**: (Nav Loc 1: [...], Nav Loc 2: [...], Nav Loc 3: [...])' or '**Result**: (Nav Loc: Unable to find)'.
**Important details:**
- Always provide reasoning internally (you may do it in hidden scratchpads if available) before giving the final result.
The final user-visible answer should be concise and directly address the task.
- If no objects are found that are semantically relevant to the target description, explicitly indicate that no suitable object was found.
- Follow these steps for every input you receive.
"""
},
{"role": "user", "content": f"navigation target:{text_prompt}"},
{"role": "user", "content": f"memory:{long_memory}"},
{"role": "user", "content": "Now please start thinking one step at a time and then Briefly tell me the target location I need to go to and return as '**Result**: (Nav Loc 1: [...], Nav Loc 2: [...], Nav Loc 3: [...])' format, If there is no suitable target in memory, return as '**Result**: (Nav Loc: Unable to find)"},
])
return completion.choices[0].message.content2.3.3.3 复杂导航指令 利用 cognitive map
def working_memory_retrival(self, text_prompts):
print("search voxel memory...")
#利用diffusion生成图片
text_prompt_extend = imagenary_helper(self.client, text_prompts)
# 检索congitive map
best_pos, top_k_positions, top_k_similarity = self.memory.voxel_localized(text_prompt_extend)
cluster_centers, _, _ = self.weighted_cluster_centers(top_k_positions, top_k_similarity)
print("Extracted Loc Array using voxel memory:", cluster_centers)
np.save(self.memory.memory_save_path + f"/best_pos_topK_{text_prompts}.npy", np.array(top_k_positions))
np.save(self.memory.memory_save_path + f"/best_pos_centers_{text_prompts}.npy", np.array(cluster_centers))
best_pos = np.array([cluster_centers])
return best_pos def voxel_localized(self, prompt, K=100, batch_size=300, region_radius=np.inf, curr_grid=None):
# self.diffusion = StableDiffusion3Pipeline.from_pretrained("stabilityai/stable-diffusion-3.5-medium", torch_dtype=torch.float16)
if isinstance(prompt, str):
# self.Quantizing(self.args.diffusion_id)
# self.diffusion = self.diffusion.to(self.device)
gen_results = self.imaginary(prompt) # 修正为单个 text_prompt
query_imgs = [gen_results.images[i] for i in range(self.args.imagenary_num)]
# del self.diffusion
gc.collect()
torch.cuda.empty_cache()
query_img_tensors = torch.stack([self.transform(img) for img in query_imgs]).to(self.device) # [batch_size, C, H, W]
else:
query_img_tensors = torch.stack([self.transform(prompt)]).to(self.device)
candidates = []
print("localizing...")
t1 = time.time()
with torch.no_grad():
# query_features_dict = self.dinov2.forward_features(query_img_tensors)
# query_features = query_features_dict['x_norm_patchtokens'].squeeze(0).mean(dim=0)
# query_features = query_features.unsqueeze(0)
query_features_dict = self.dinov2.forward_features(query_img_tensors)
tokens = query_features_dict['x_norm_patchtokens'] # 假设形状为 [batch_size, num_tokens, feature_dim]
batch_size, num_tokens, feature_dim = tokens.size()
grid_size = int(math.sqrt(num_tokens))
xs = torch.arange(grid_size, device=self.device).repeat(grid_size).view(1, num_tokens)
ys = torch.arange(grid_size, device=self.device).repeat_interleave(grid_size).view(1, num_tokens)
center = (grid_size - 1) / 2
distances = (xs - center) ** 2 + (ys - center) ** 2 # [1, num_tokens]
sigma = (grid_size / 2) ** 2
weights = torch.exp(-distances / (2 * sigma)) # [1, num_tokens]
weights = weights / weights.sum(dim=1, keepdim=True) # [1, num_tokens]
weights = weights.unsqueeze(-1) # [1, num_tokens, 1]
weighted_tokens = tokens * weights # [batch_size, num_tokens, feature_dim]
weighted_sum = weighted_tokens.sum(dim=1) # [batch_size, feature_dim]
query_features = weighted_sum.mean(dim=0).unsqueeze(0)
# with h5py.File(self.feat_path, 'r') as h5f:
# for group_name in h5f.keys():
# group = h5f[group_name]
# grid_feat = torch.from_numpy(group['features'][:]).to(self.device)
# similarities = F.cosine_similarity(query_features, grid_feat, dim=1)
# batch_max_similarity, max_idx = torch.max(similarities, dim=0)
# batch_max_similarity = batch_max_similarity.item()
# pos = [int(group_name.split('_')[1]),
# int(group_name.split('_')[2]),
# int(group_name.split('_')[3])]
# candidates.append((batch_max_similarity, pos))
with h5py.File(self.feat_path, 'r') as h5f:
if region_radius != np.inf:
group_names = []
for group_name in h5f.keys():
_, x, y, z = group_name.split('_')
if (int(x) - curr_grid[0]) ** 2 + (int(y) - curr_grid[1]) ** 2 + (int(z) - curr_grid[2]) ** 2 <= region_radius ** 2:
group_names.append(group_name)
else:
group_names = list(h5f.keys())
if self.args.load_single_floor:
print(f'filter height from {self.floor_min_height} to {self.floor_max_height}')
filtered_group_names = []
for group_name in group_names:
_, x, y, z = group_name.split('_') # 假设 group_name 形如 "group_x_y_z"
if self.floor_min_height <= int(z) <= self.floor_max_height:
filtered_group_names.append(group_name)
group_names = filtered_group_names
for i in range(0, len(group_names), batch_size):
batch_group_names = group_names[i:i + batch_size]
all_features = []
group_positions = []
for group_name in batch_group_names:
group = h5f[group_name]
grid_feat = torch.from_numpy(group['features'][:]).to(self.device)
all_features.append(grid_feat)
position = tuple(map(int, group_name.split('_')[1:4]))
group_positions.append((position, grid_feat.shape[0]))
all_features = torch.cat(all_features, dim=0)
similarities = F.cosine_similarity(query_features, all_features, dim=1)
start_idx = 0
for position, count in group_positions:
group_similarities = similarities[start_idx:start_idx + count]
max_similarity, _ = torch.max(group_similarities, dim=0)
candidates.append((max_similarity.item(), position))
start_idx += count
candidates.sort(key=lambda x: x[0], reverse=True)
top_k_positions = [pos for _, pos in candidates[:K]]
top_k_similarity = [sim for sim, _ in candidates[:K]]
print(f"finish localizing, time:{time.time() - t1}")
return np.array([top_k_positions[0]]), np.array(top_k_positions), np.array(top_k_similarity)
3 我的思考
这个工作本质上是设计一个MLLM-based agent for navigation,作者主要工作是设计了一些机制,通过调用自建的知识库来提高大模型的回复质量,提升导航效果。
由于第一次接触navigation领域的东西,有一些小白的问题,有大神看到望指点一下
1. 该文章的landmark memory 和cognitive map 都是 存储一些关键点的信息(如位置和图像特征),这种方法检索的效率和成功率跟用建图相比如何?
2.这个论文对memory的检索都是丢给GPT,虽然泛化性提高了,但是效果会比用传统匹配算法好吗?用GPT去检索,结果会不会变得不可控了?
3. 如果将Memory构建成地图进行导航,效果是不是会更好?
我的一些优化想法
1. 我觉得作者这种方式在小环境的效果应该不错,但是环境大了,或者物体多了,估计性能会大受影响。比较memory存的内容多了检索效率就慢了,东西多了就容易误判。
目前这个算法有一个缺点就是,他都是在无人的环境中测试,如果这个环境有很多移动的东西,那么他就会容易受到干扰。
这种情况下,我的想法是,利用Obeservation建图,用图导航可以避免歧义,另一个就是如果智能体能捕获和理解环境中的指引信息(即使没有地图),那么效率应该会有进一步提升。
更多推荐

 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)