
大模型项目搭建实战演示(详解)
本文介绍了大模型项目搭建的前期准备工作,主要包括四个步骤:1) 配置OpenAI接口,设置模型参数和温度值;2) 创建Deepseek与Kimi系列模型信息并添加到系统可用模型中;3) 导入相关模块并配置大语言模型;4) 使用Chainlit库实现前端交互界面。文章详细说明了每个步骤的关键配置,包括模型参数设置、全局配置对象管理、流式聊天引擎创建等,为后续完整的项目实战教程奠定了基础。通过这四步操
前言:这是一个进行大模型项目搭建的简单实战,后面我会进行一个完整项目一步步的教程,这个相当是前提的准备工作

先导(前提准备)
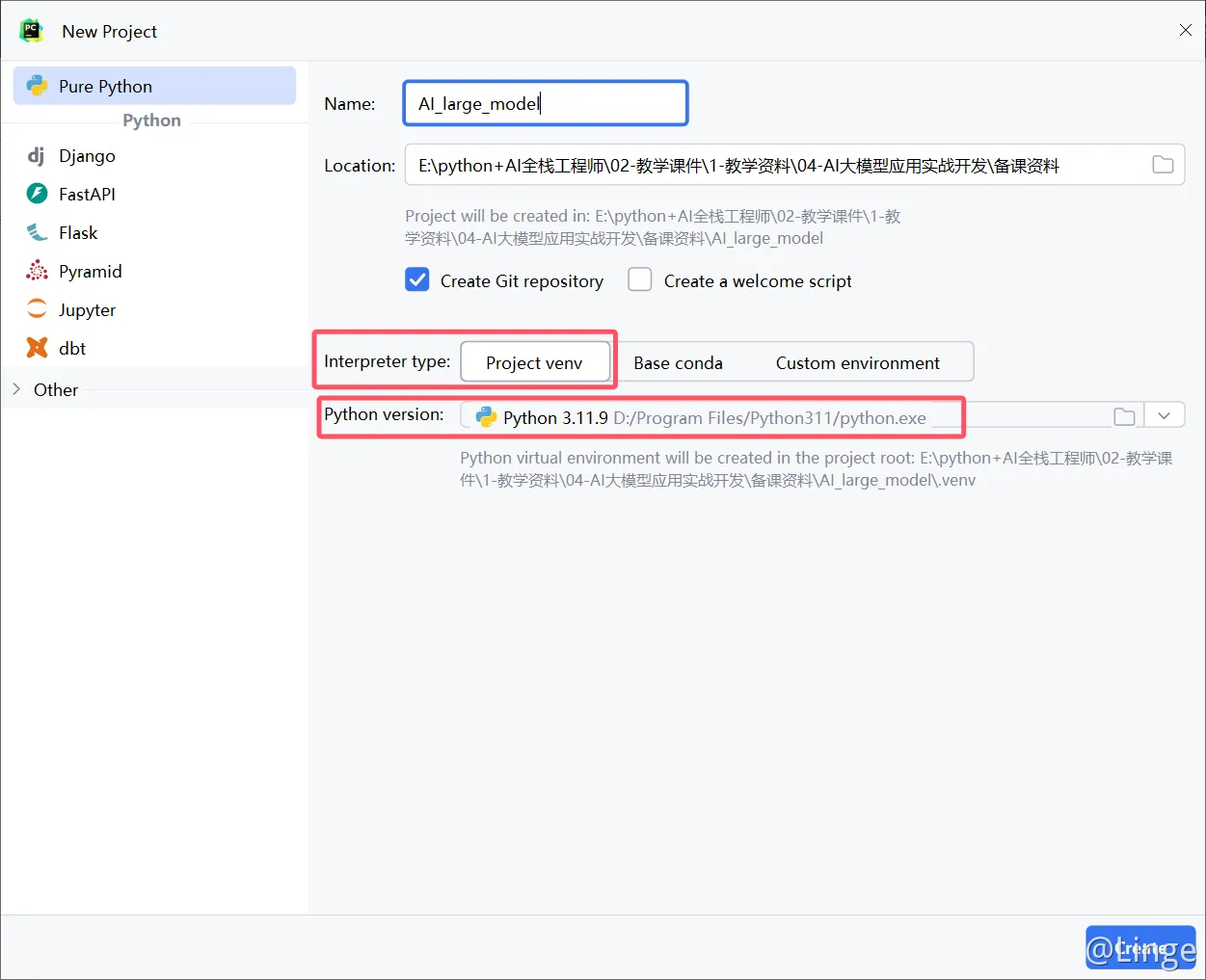
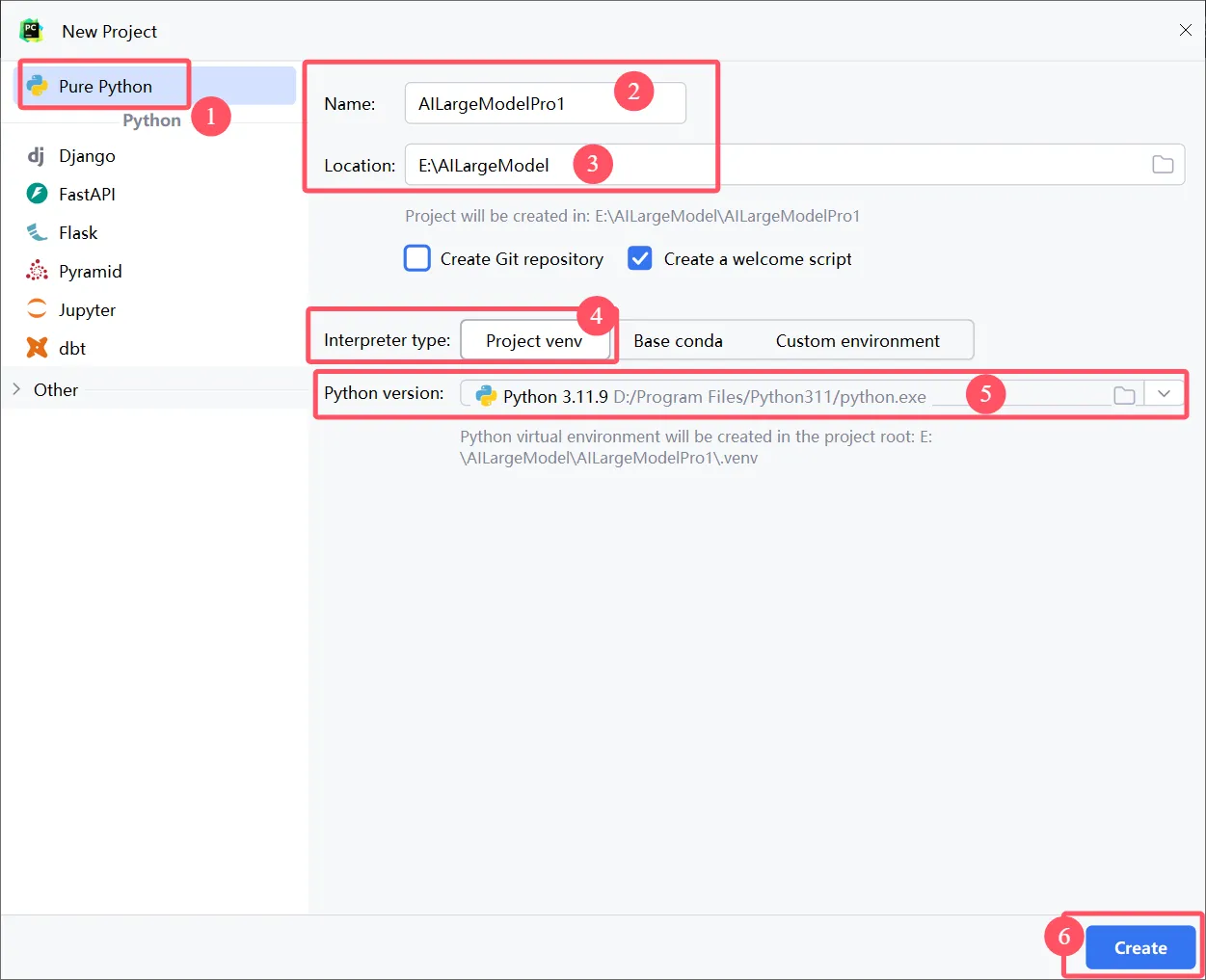
查看当前安装列表
pip list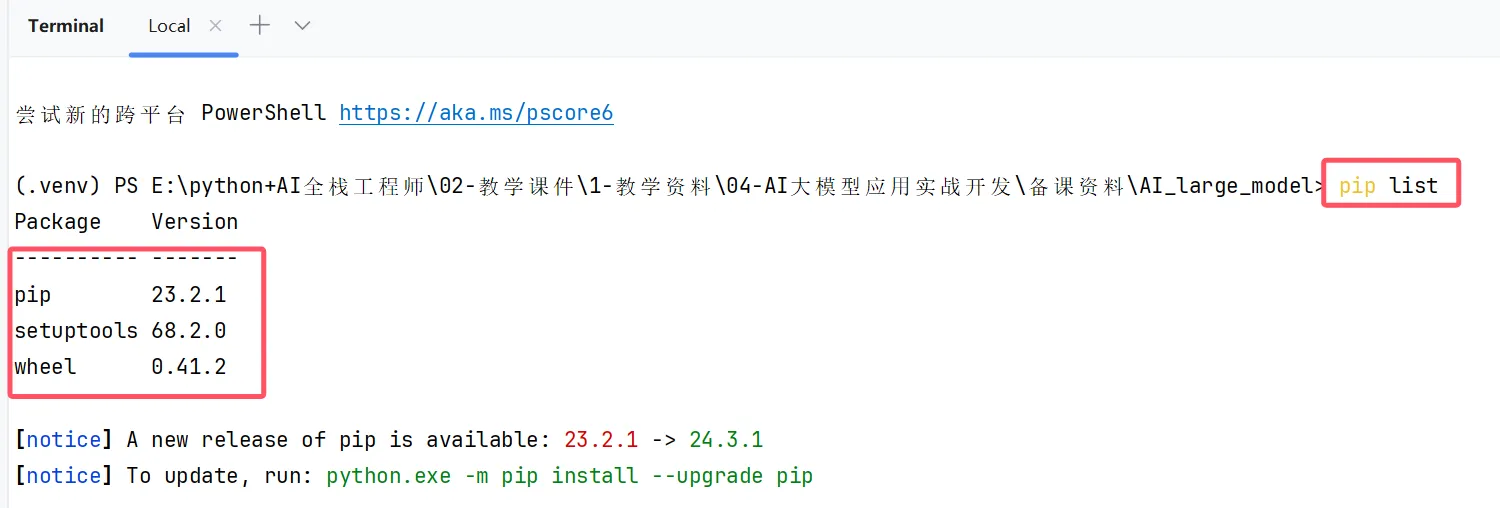

llamaindex库的安装
指令:pip install llama-index(可以翻墙)
第一步:open Ai配置
OpenAI(
api_key='你的密钥', #填写大模型的密钥
model='kimi-k2-0711-preview', #填写大模型的模型名称
api_base='https://api.moonshot.cn/v1', #填写大模型平台的API URL地址
temperature=0.6, #模型温度
**kwargs
)# 导⼊核⼼设置模块,⽤于配置全局的LLM(⼤语⾔模型)和其他设置
from llama_index.core import Settings
# 导⼊简单的聊天引擎模块,⽤于创建和管理聊天会话
from llama_index.core.chat_engine import SimpleChatEngine
# 从⾃定义模块中导⼊DeepSeek LLM实例,⽤于处理语⾔模型相关的任务
from llms import deepseek_llm, moonshot_llm
# 设置全局的LLM实例为DeepSeek LLM,这是配置模型和其他资源的关键步骤
# Settings.llm = deepseek_llm()
# 使⽤moonshot_llm()
Settings.llm = moonshot_llm()
# 创建⼀个简单的聊天引擎实例,⽤于后续的聊天交互
chat_engine = SimpleChatEngine.from_defaults()
# 启动聊天引擎的流式聊天读取-评估-打印循环(REPL)
# 该⽅法允许⽤户与聊天引擎进⾏实时交互,输⼊命令或问题,并⽴即查看响应
# 适⽤于测试和演示聊天引擎功能,以及探索性数据分析和建模
chat_engine.streaming_chat_repl()
# # 使⽤聊天引擎发起⼀个聊天请求,请求的内容是“介绍⼀下性能测试”
# res = chat_engine.stream_chat(message="介绍⼀下性能测试")
# # 遍历聊天响应的每⼀个token,并将其打印出来,这是处理流式响应的常⻅⽅式
# for token in res.response_gen:
# print(token)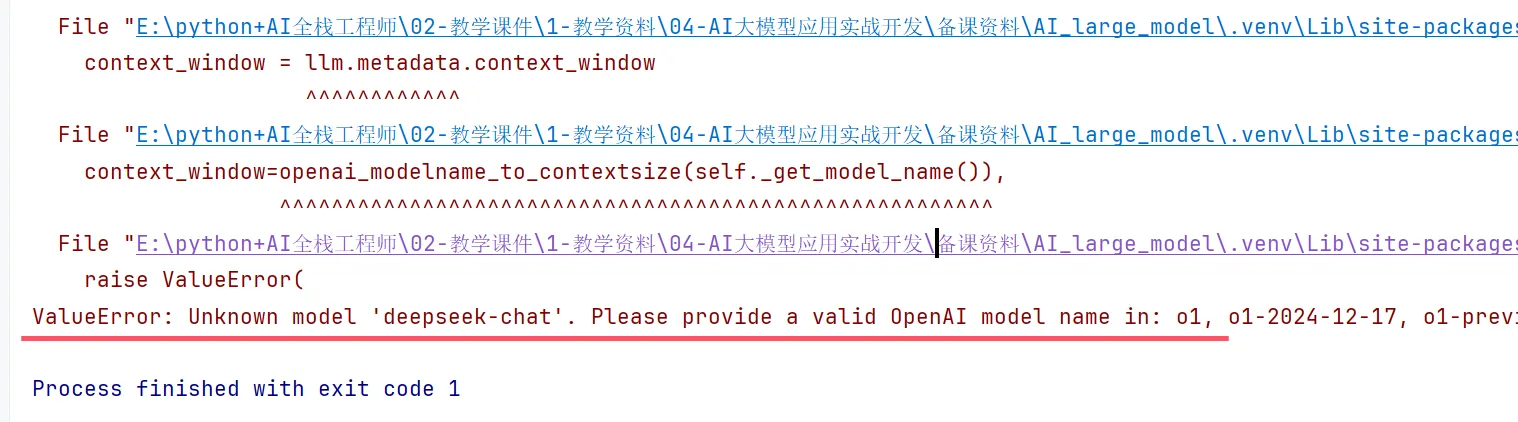
.venv/Lib/site-packages/llama_index/llms/openai/utils.py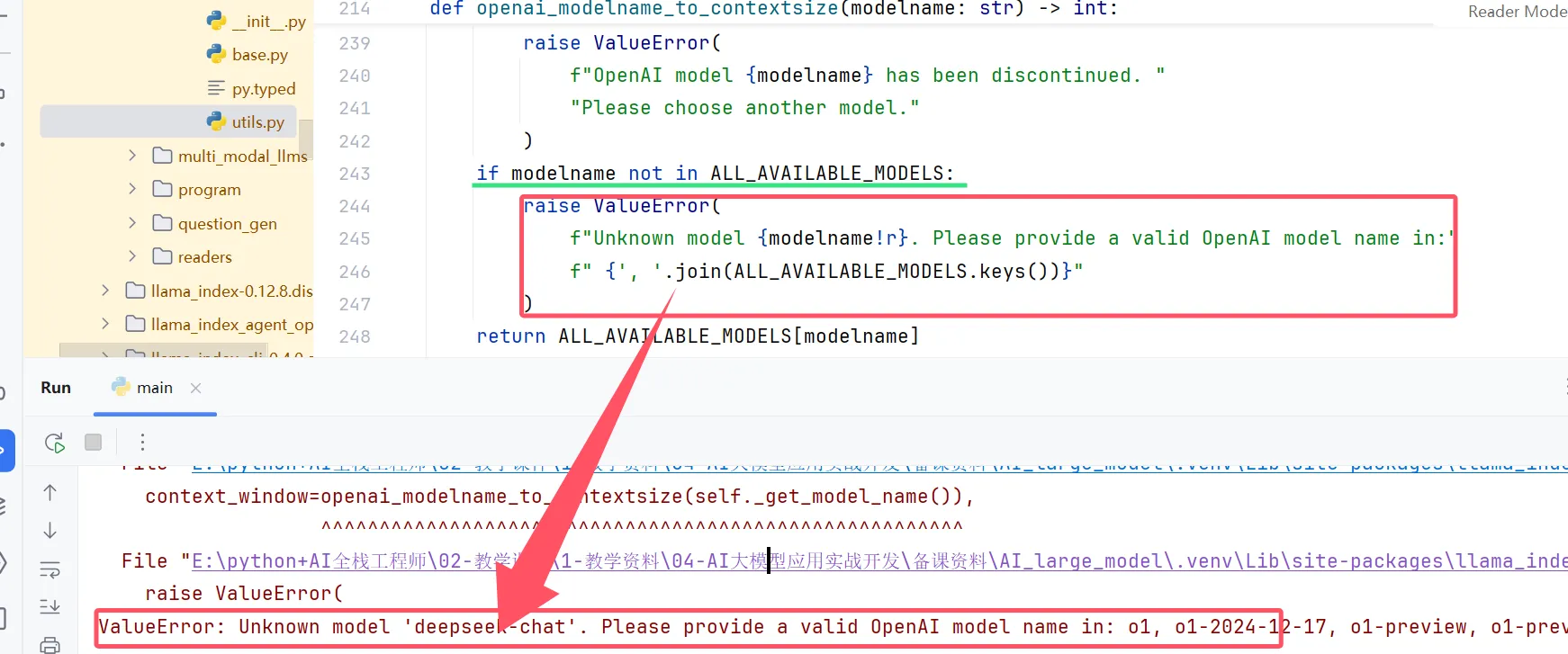
需要事实准确性的任务:使用较低温度值(0.2-0.5)----合同,精密数据分析
创意类任务:使用较高温度值(0.7-0.9)---艺术类
日常对话和通用任务:使用中等温度值(0.5-0.7)----日常使用
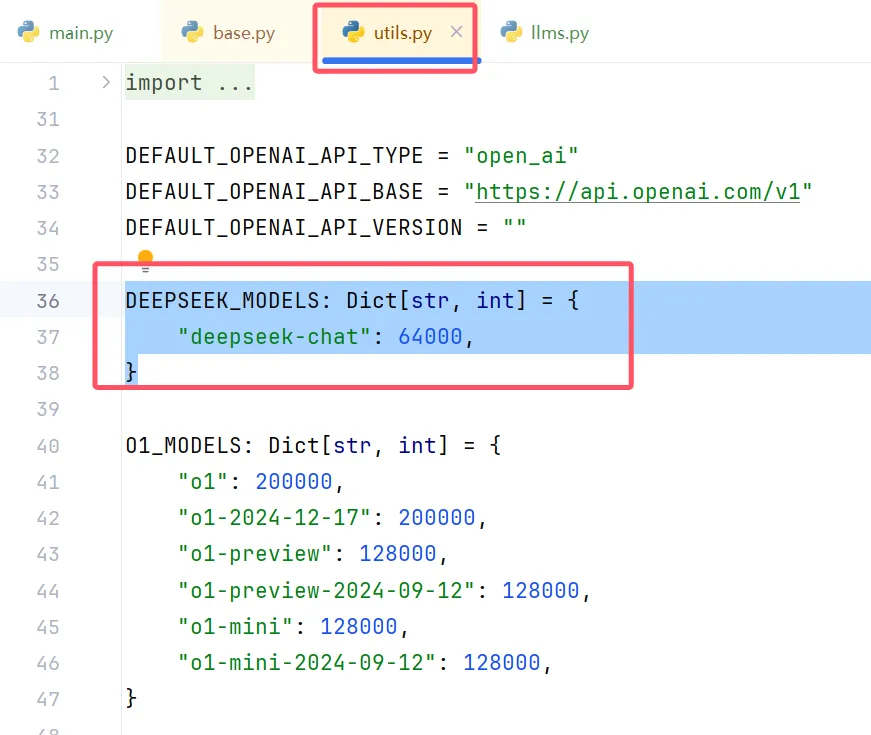
第二步:创建Deepseek与Kimi的系列模型信息,并将他们添加到系统的可用模型中。
DEEPSEEK_MODELS: Dict[str, int] = {
"deepseek-chat": 128000,
}-
DEEPSEEK_MODELS:变量名,明确表示这是「深度求索(DeepSeek)」公司的模型信息字典(常量通常用全大写命名)。 -
Dict[str, int]:类型注解,指定这是一个「键为字符串、值为整数」的字典:
-
-
键(字符串):模型的唯一标识符(名称),这里是
deepseek-chat(DeepSeek 的通用聊天模型,通常映射到其最新稳定版本)。 -
值(整数):模型支持的最大输入长度(单位为 tokens),
128000表示该模型最多可处理 128,000 个 tokens 的上下文(属于长文本模型)。
-
-
作用:记录 DeepSeek 模型的基础信息,尤其是输入长度限制(程序后续会用这个值来处理超长文本,避免模型报错)。
# 更新所有可用模型和聊天模型的字典,添加DeepSeek模型
ALL_AVAILABLE_MODELS.update(
DEEPSEEK_MODELS | MOONSHOT_MODELS
)
CHAT_MODELS.update(
DEEPSEEK_MODELS | MOONSHOT_MODELS
)拆解关键语法和逻辑:
-
DEEPSEEK_MODELS | MOONSHOT_MODELS:
这是 Python 3.9 + 支持的字典合并运算符(|),作用是将DEEPSEEK_MODELS和MOONSHOT_MODELS两个字典的键值对合并成一个新字典。
例如:
若MOONSHOT_MODELS是{"kimi-k2-0711-preview": 128000},则合并后结果为:{"deepseek-chat": 128000, "kimi-k2-0711-preview": 128000}。 -
ALL_AVAILABLE_MODELS.update(...):
-
-
ALL_AVAILABLE_MODELS是程序中已定义的全局字典,用于存储系统所有支持的模型(无论类型)。 -
.update(...)方法会将合并后的模型信息添加到这个全局字典中,使其包含 DeepSeek 和 Moonshot 的模型。
-
-
CHAT_MODELS.update(...):
-
-
CHAT_MODELS也是全局字典,专门存储支持聊天功能的模型(筛选出适合对话场景的模型)。 -
同样通过
.update(...)方法添加合并后的模型,确保聊天场景中能使用这些模型。
-
3. 这段代码的实际意义
在 LLM 应用(如你用的llama_index+chainlit框架)中,这样的设计有几个关键作用:
-
统一管理模型:将所有支持的模型信息集中到
ALL_AVAILABLE_MODELS和CHAT_MODELS中,后续代码无需重复定义,直接从这两个字典查询即可。 -
输入长度校验:当用户输入或上下文长度超过模型的
128000tokens 时,程序可自动截断或分块处理(基于字典中存储的数值)。 -
模型选择限制:如果前端提供模型选择功能,可直接从
CHAT_MODELS中读取可用选项,避免用户选择不支持聊天的模型。 -
扩展性:未来添加新模型(如智谱、讯飞的模型)时,只需定义新的模型字典(如
ZHIPU_MODELS),再通过同样的方式合并到全局字典即可。
总结
这段代码本质上是在做「模型注册」:通过定义模型信息、合并多厂商模型、更新全局列表三个步骤,让程序知道「DeepSeek 和 Moonshot 的这些模型是可用的,且最大输入长度为 128,000 tokens」,为后续的模型调用、文本处理等功能提供基础数据支持。
第三步(导入相关模块):
# 导入相关模块
# llms配置
from llama_index.core import settings, Settings
# 聊天引擎模型
from llama_index.core.chat_engine import SimpleChatEngine
# 导入大模型模型
from llms import moonshot_llm
# 导入大模型模型
from llms import deepseek_llm
# Settings:是 llama_index 库中的全局配置对象,用于统一管理框架的核心组件(如大模型、嵌入模型、存储等)。
# Settings.llm:表示配置「大语言模型(LLM)」,后续框架中所有需要调用大模型的地方(如生成回答、总结内容等)都会使用这里设置的模型。
# 设置大模型模型
Settings.llm = moonshot_llm()
# SimpleChatEngine:llama_index 提供的一个简单聊天引擎类,负责处理对话逻辑(如维护聊天历史、调用模型生成回答等)。
# from_defaults():这是一个便捷的构造方法,意思是「使用默认配置创建聊天引擎」。这里的「默认配置」会自动读取前面 Settings 中设置的内容
# 使用 Settings.llm 中配置的 moonshot_llm 作为生成回答的模型
# 自动创建一个默认的聊天记忆(ChatMemoryBuffer),用于存储对话历史(方便模型理解上下文)
# 创建聊天引擎
chat_engine = SimpleChatEngine.from_defaults()
# streaming_chat_repl:这是聊天引擎提供的一个交互式聊天方法
# streaming:表示回答会「流式输出」(类似 ChatGPT,一个字一个字显示,而不是等待全部生成后一次性显示)。
# REPL:是「Read-Eval-Print Loop」的缩写,即「读取输入 - 处理 - 输出 - 循环」的交互模式(类似命令行工具的交互逻辑)。
chat_engine.streaming_chat_repl()
# 要自定义聊天行为(如修改记忆长度、添加系统提示等),可以显式传入参数,例如:
from llama_index.core.memory import ChatMemoryBuffer
# 自定义聊天记忆(最多保留10轮对话)
memory = ChatMemoryBuffer.from_defaults(token_limit=2000)
# 创建聊天引擎时指定自定义记忆
chat_engine = SimpleChatEngine.fr.streaming_chat_repl() # 启动聊天到这里就已经完成了,可以在控制台与ai交流
第四步:使用前端界面实现:chainlit------官网(推荐):
https://docs.chainlit.io/get-started/overview
安装chainlit
pip install chainlit编码:
# 导入 chainlit 库,用于构建和部署 AI 应用
import chainlit as cl
# 导入 Settings 类,用于配置 llama_index 的核心设置
from llama_index.core import Settings
# 导入 SimpleChatEngine 类,用于实现简单的聊天引擎
from llama_index.core.chat_engine import SimpleChatEngine
# 导入 deepseek_llm,可能是一个自定义的或第三方的语言模型库
from llms import deepseek_llm,moonshot_llm
# Chainlit 聊天开始事件处理函数
@cl.on_chat_start
async def start():
"""
当聊天开始时异步执行的函数。
初始化设置和聊天引擎,并向用户发送欢迎消息。
1. 初始化 Settings.llm 为 deepseek_llm()。
2. 创建一个 SimpleChatEngine 实例,并存储到用户会话中。
3. 异步发送一条消息给用户,介绍自己并询问用户需要的帮助。
"""
# 初始化大型语言模型(LLM)设置
Settings.llm = moonshot_llm()
# 创建一个简单的聊天引擎实例
chat_engine = SimpleChatEngine.from_defaults()
# 将聊天引擎对象存储到用户会话中,以便后续使用
cl.user_session.set("chat_engine", chat_engine)
# 发送一条欢迎消息,介绍 AI 助手的功能和作用
await cl.Message(
author="Assistant",
content="你好!我是 AI 助手。有什么可以帮助你的吗?"
).send()
# Chainlit 消息事件处理函数
@cl.on_message
async def main(message: cl.Message):
"""
处理接收到的消息,并使用 chat_engine 生成回复。
参数:
message: cl.Message 类型,表示接收到的消息。
"""
# 从用户会话中获取 chat_engine 对象
chat_engine = cl.user_session.get("chat_engine")
# 初始化一个空的消息对象,内容为空,作者为 "Assistant"
msg = cl.Message(content="", author="Assistant")
# 使用 chat_engine 的 stream_chat 方法处理接收到的消息内容,并将结果转换为异步响应
res = await cl.make_async(chat_engine.stream_chat)(message.content)
# 流式界面输出
# 遍历生成的响应内容,逐个令牌地输出
for token in res.response_gen:
await msg.stream_token(token)
# 发送完整的消息
await msg.send()到这里简单的实战演示就结束了,后面我会写一个很大的全面的实战文章,到时候跟着一步步来就可以成功!

更多推荐


 21
21 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)