
大模型原理与实践:第六章-大模型训练流程实践_第3部分-高效微调(LoRA)
本文介绍了大模型高效微调方法,重点分析了LoRA技术原理。针对全量微调的资源消耗大、训练时间长、过拟合风险高等问题,对比了Adapter Tuning、Prefix Tuning和LoRA三种高效微调方案。LoRA通过低秩分解表示权重更新,仅需训练少量参数,具有无推理延迟、可与其他方法组合等优势。文章详细阐述了LoRA的低秩参数化原理、前向传播公式和初始化策略,指出其仅需更新(d+k)×r个参数,
第六章 大模型训练流程实践
总目录
目录
- 6.3 高效微调
- 6.3.1 高效微调方案
- 6.3.2 LoRA 微调
- 6.3.3 LoRA 微调的原理
- 6.3.4 LoRA 的代码实现
- 6.3.5 使用 peft 实现 LoRA 微调
- 参考资料
- 总结
6.3 高效微调
虽然前面介绍了完整的 Pretrain 和 SFT 流程,但全量微调存在显著问题:
- 资源消耗大:需要更新所有模型参数,显存占用高
- 训练时间长:尤其对于百亿参数模型,训练成本高昂
- 过拟合风险:小数据集上全量微调容易过拟合
因此,高效微调(Parameter-Efficient Fine-Tuning, PEFT)成为资源受限场景下的最佳选择。
6.3.1 高效微调方案
方案1:Adapter Tuning
核心思想: 在预训练模型的每一层插入小型 Adapter 模块,微调时冻结原参数,仅训练 Adapter。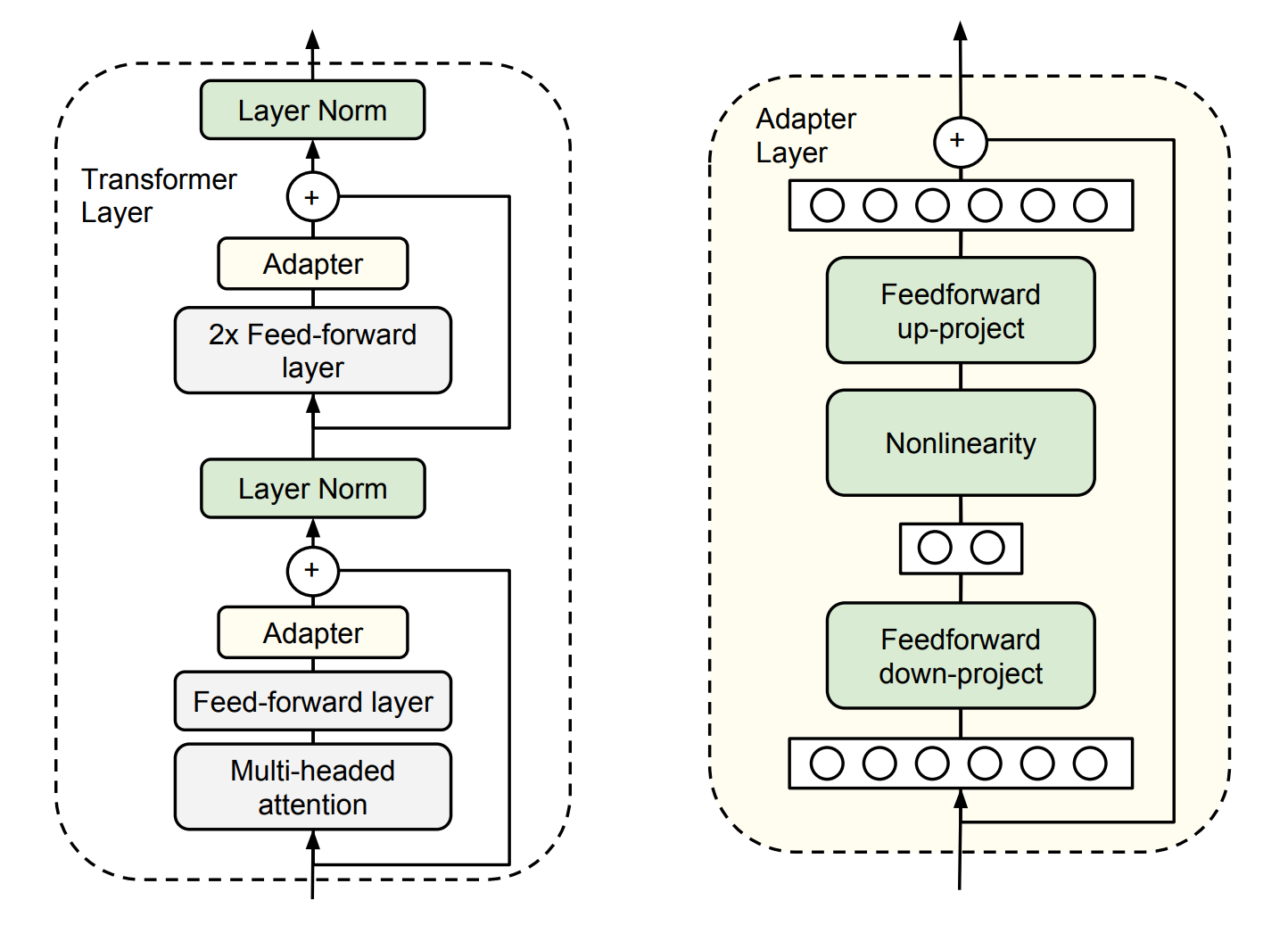
结构设计:
原始层输出 (维度 d)
↓
Down-projection: d → m (m << d, 如 m=64)
↓
Non-linearity (如 ReLU)
↓
Up-projection: m → d
↓
残差连接
↓
输出 (维度 d)
数学表示:
h = f ( x ) + g ( x ) h = f(x) + g(x) h=f(x)+g(x)
其中:
- f ( x ) f(x) f(x) 是冻结的预训练层
- g ( x ) g(x) g(x) 是可训练的 Adapter 模块
优点:
- 参数量小(通常 <5% 原模型参数)
- 可为不同任务训练不同 Adapter
缺点:
- 推理延迟:增加了额外的前向计算
- 模型架构改变,部署时需要加载额外模块
方案2:Prefix Tuning
核心思想: 在输入序列前添加可训练的"虚拟 token"(prefix),微调时仅更新这些 prefix 的参数。
结构示意:
[可训练 Prefix] + [输入文本] → Transformer → 输出
↑冻结参数 ↓仅训练这部分
优点:
- 不改变模型结构
- 参数量极小
缺点:
- 序列长度减少:prefix 占用了可用序列长度
- 需要较长的 prefix 才能达到好效果(如 100-200 tokens)
改进版本: P-tuning v2 在每一层都添加 prefix,效果更好。
方案对比
| 方案 | 可训练参数 | 推理延迟 | 序列长度 | 适用场景 |
|---|---|---|---|---|
| Adapter Tuning | ~1-5% | 有延迟 | 不变 | 多任务切换 |
| Prefix Tuning | <0.1% | 无延迟 | 减少 | 资源极度受限 |
| LoRA | ~0.5-2% | 无延迟 | 不变 | 推荐,平衡最好 |
6.3.2 LoRA 微调
LoRA(Low-Rank Adaptation)是目前最流行的高效微调方法,它巧妙地结合了两种方案的优点。
核心假设
LoRA 基于以下观察:
- 低秩假设:预训练模型已经学习了丰富的知识,针对特定任务微调时,权重更新矩阵 Δ W \Delta W ΔW 具有较低的本征秩(intrinsic rank)
- 任务复杂度关系:任务越简单,所需的本征秩越低
理论依据:
研究表明(Aghajanyan et al., 2020),即使将权重更新随机投影到低维子空间,模型仍能有效学习。这说明大模型在特定任务上的适应只需要在一个低维子空间中进行。
LoRA 优势
相比其他高效微调方法,LoRA 具有以下优势:
- 灵活性:可为不同任务构建不同的 LoRA 模块,共享基座模型
- 高效性:使用自适应优化器时,不需要为大部分参数维护优化器状态
- 无推理延迟:部署时可将 LoRA 权重合并到原模型,不增加计算量
- 正交性:可与其他方法(如量化)组合使用
6.3.3 LoRA 微调的原理
(1) 低秩参数化
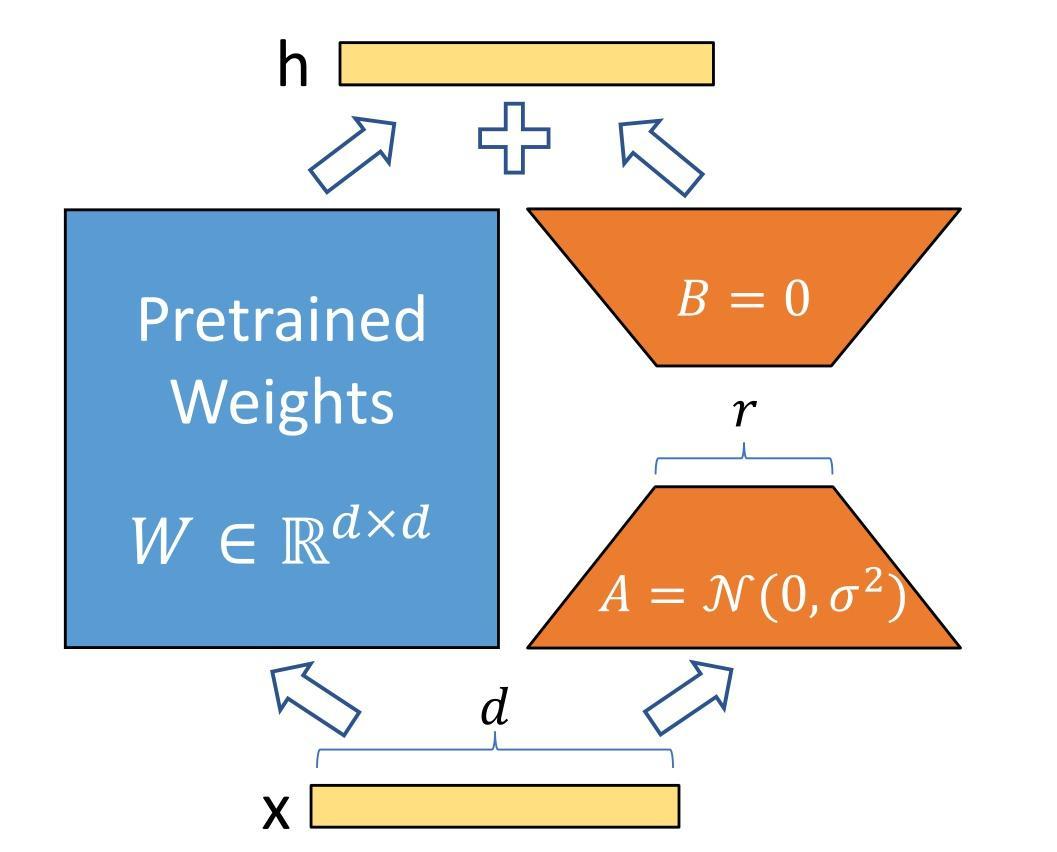
对于预训练权重矩阵 W 0 ∈ R d × k W_0 \in \mathbb{R}^{d \times k} W0∈Rd×k,LoRA 使用低秩分解表示其更新:
W = W 0 + Δ W = W 0 + B A W = W_0 + \Delta W = W_0 + BA W=W0+ΔW=W0+BA
其中:
- B ∈ R d × r B \in \mathbb{R}^{d \times r} B∈Rd×r
- A ∈ R r × k A \in \mathbb{R}^{r \times k} A∈Rr×k
- r ≪ min ( d , k ) r \ll \min(d, k) r≪min(d,k)(秩远小于原矩阵维度)
参数量对比:
- 全量微调:需要更新 d × k d \times k d×k 个参数
- LoRA:只需更新 ( d + k ) × r (d + k) \times r (d+k)×r 个参数
示例: 对于 d = k = 4096 d=k=4096 d=k=4096, r = 8 r=8 r=8:
- 全量: 4096 × 4096 ≈ 16.8 M 4096 \times 4096 \approx 16.8M 4096×4096≈16.8M 参数
- LoRA: ( 4096 + 4096 ) × 8 ≈ 65 K (4096 + 4096) \times 8 \approx 65K (4096+4096)×8≈65K 参数
- 压缩比: 约 1/256
(2) 前向传播
LoRA 的前向传播公式为:
h = W 0 x + Δ W x = W 0 x + B A x h = W_0 x + \Delta W x = W_0 x + BAx h=W0x+ΔWx=W0x+BAx
其中:
- x x x 是输入
- W 0 x W_0 x W0x 是原模型的输出(冻结)
- B A x BAx BAx 是 LoRA 的贡献(可训练)
(3) 初始化策略
- A A A:使用随机高斯初始化 A ∼ N ( 0 , σ 2 ) A \sim \mathcal{N}(0, \sigma^2) A∼N(0,σ2)
- B B B:使用零初始化 B = 0 B = 0 B=0
这确保训练开始时 Δ W = B A = 0 \Delta W = BA = 0 ΔW=BA=0,模型从预训练状态开始。
(4) 训练过程
输入 x
↓
原始权重 W₀ (冻结) → W₀x
↓ ↓
(+)
↓
低秩分解 A, B (训练) → BAx
↓
输出 h
(5) 应用于 Transformer
在 Transformer 结构中,LoRA 通常应用于注意力模块的四个权重矩阵:
- W q W_q Wq:Query 投影
- W k W_k Wk:Key 投影
- W v W_v Wv:Value 投影
- W o W_o Wo:Output 投影
消融实验结果: 同时调整 W q W_q Wq 和 W v W_v Wv 产生最佳效果。
可训练参数总数:
Θ = 2 × L L o R A × d m o d e l × r \Theta = 2 \times L_{LoRA} \times d_{model} \times r Θ=2×LLoRA×dmodel×r
其中:
- L L o R A L_{LoRA} LLoRA:应用 LoRA 的层数
- d m o d e l d_{model} dmodel:模型隐藏层维度
- r r r:LoRA 秩(通常取 4, 8, 或 16)
示例计算(Qwen-2.5-1.5B):
- d m o d e l = 1536 d_{model} = 1536 dmodel=1536
- L L o R A = 28 L_{LoRA} = 28 LLoRA=28 层 × 2 个矩阵 = 56
- r = 8 r = 8 r=8
- 可训练参数: 2 × 56 × 1536 × 8 ≈ 1.38 M 2 \times 56 \times 1536 \times 8 \approx 1.38M 2×56×1536×8≈1.38M (仅占原模型的 0.09%)
6.3.4 LoRA 的代码实现
PEFT 库封装了 LoRA 的实现,这里我们简要分析其内部机制。
(1) 实现流程
- 确定目标层:找到需要应用 LoRA 的层(如
q_proj,v_proj) - 替换为 LoRA 层:用包含低秩分解的新层替换原层
- 冻结原参数:设置
requires_grad=False - 训练 LoRA 参数:仅更新 A A A 和 B B B 矩阵
(2) 核心代码解析
LoRA 基类:
class LoraLayer:
"""LoRA 层的基类,定义核心超参数"""
def __init__(
self,
r: int, # LoRA 秩
lora_alpha: int, # 缩放系数
lora_dropout: float, # Dropout 比例
merge_weights: bool, # 是否合并权重(推理时)
):
self.r = r
self.lora_alpha = lora_alpha
# Dropout 层
if lora_dropout > 0.0:
self.lora_dropout = nn.Dropout(p=lora_dropout)
else:
self.lora_dropout = lambda x: x
self.merged = False
self.merge_weights = merge_weights
self.disable_adapters = False
LoRA Linear 层:
class Linear(nn.Linear, LoraLayer):
"""
带 LoRA 的线性层
继承自 PyTorch 的 nn.Linear 和 LoraLayer
"""
def __init__(
self,
in_features: int,
out_features: int,
r: int = 0,
lora_alpha: int = 1,
lora_dropout: float = 0.0,
merge_weights: bool = True,
**kwargs,
):
# 初始化基类
nn.Linear.__init__(self, in_features, out_features, **kwargs)
LoraLayer.__init__(
self, r=r, lora_alpha=lora_alpha,
lora_dropout=lora_dropout, merge_weights=merge_weights
)
# 创建 LoRA 参数矩阵
if r > 0:
# A 矩阵: in_features → r
self.lora_A = nn.Linear(in_features, r, bias=False)
# B 矩阵: r → out_features
self.lora_B = nn.Linear(r, out_features, bias=False)
# 缩放系数
self.scaling = self.lora_alpha / self.r
# 冻结原权重
self.weight.requires_grad = False
# 初始化参数
self.reset_parameters()
def reset_parameters(self):
"""
初始化 LoRA 参数
- A: 高斯分布
- B: 零初始化
"""
if hasattr(self, 'lora_A'):
nn.init.kaiming_uniform_(self.lora_A.weight, a=math.sqrt(5))
nn.init.zeros_(self.lora_B.weight)
def forward(self, x: torch.Tensor):
"""
前向传播
计算: h = W₀x + BAx * scaling
"""
# 原始输出
result = F.linear(x, self.weight, bias=self.bias)
# 如果启用 LoRA,添加低秩更新
if self.r > 0 and not self.merged:
# BAx 的计算
lora_output = self.lora_B(
self.lora_A(
self.lora_dropout(x)
)
) * self.scaling
result += lora_output
return result
层替换逻辑:
def replace_with_lora(model, target_modules, r, lora_alpha):
"""
将模型中的目标层替换为 LoRA 层
Args:
model: 原始模型
target_modules: 要替换的层名列表(如 ["q_proj", "v_proj"])
r: LoRA 秩
lora_alpha: 缩放系数
"""
import re
for name, module in model.named_modules():
# 检查是否匹配目标层
for target in target_modules:
if re.search(target, name) and isinstance(module, nn.Linear):
# 获取父模块和子模块名
parent_name, child_name = name.rsplit('.', 1)
parent = model.get_submodule(parent_name)
# 创建 LoRA 层
lora_layer = Linear(
in_features=module.in_features,
out_features=module.out_features,
r=r,
lora_alpha=lora_alpha,
bias=module.bias is not None
)
# 复制原权重
lora_layer.weight.data = module.weight.data.clone()
if module.bias is not None:
lora_layer.bias.data = module.bias.data.clone()
# 替换模块
setattr(parent, child_name, lora_layer)
print(f"Replaced {name} with LoRA layer")
6.3.5 使用 peft 实现 LoRA 微调
PEFT 库提供了开箱即用的 LoRA 实现,使用非常简单。
完整示例
import torch
import torch.nn as nn
from transformers import AutoTokenizer, AutoModelForCausalLM, Trainer, TrainingArguments
from peft import get_peft_model, LoraConfig, TaskType
from datasets import load_dataset
# ============ 步骤1: 加载基座模型和 Tokenizer ============
MODEL_PATH = "autodl-tmp/qwen-1.5b"
print("加载模型和 Tokenizer...")
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
MODEL_PATH,
trust_remote_code=True,
torch_dtype=torch.bfloat16 # 使用混合精度
)
# 查看原始参数量
total_params = sum(p.numel() for p in model.parameters())
print(f"原始模型参数量: {total_params/1e6:.2f}M")
# ============ 步骤2: 配置 LoRA 参数 ============
lora_config = LoraConfig(
task_type=TaskType.CAUSAL_LM, # 任务类型:因果语言模型
inference_mode=False, # 训练模式
r=8, # LoRA 秩
lora_alpha=32, # 缩放系数 (通常设为 r 的 2-4 倍)
lora_dropout=0.1, # Dropout 比例
target_modules=["q_proj", "v_proj"], # 目标模块(可根据模型调整)
bias="none", # 不训练 bias
)
# ============ 步骤3: 获取 LoRA 模型 ============
print("应用 LoRA...")
model = get_peft_model(model, lora_config)
# 查看可训练参数
trainable_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f"LoRA 可训练参数: {trainable_params/1e6:.2f}M ({trainable_params/total_params*100:.2f}%)")
# 打印模型结构(可选)
model.print_trainable_parameters()
# ============ 步骤4: 准备数据集 ============
# 这里使用前面定义的 SupervisedDataset
import json
print("加载训练数据...")
with open("autodl-tmp/dataset/belle_open_source_0.5M.json") as f:
raw_data = [json.loads(line) for line in f.readlines()[:10000]] # 使用部分数据测试
train_dataset = SupervisedDataset(raw_data, tokenizer=tokenizer, max_len=2048)
print(f"训练样本数: {len(train_dataset)}")
# ============ 步骤5: 配置训练参数 ============
training_args = TrainingArguments(
output_dir="autodl-tmp/output/lora_sft",
per_device_train_batch_size=8,
gradient_accumulation_steps=4, # 实际 batch size = 8 * 4 = 32
learning_rate=5e-4, # LoRA 可以使用更大的学习率
num_train_epochs=3,
logging_steps=10,
save_steps=500,
save_total_limit=2,
bf16=True, # 使用 BF16 混合精度
gradient_checkpointing=True,
warmup_steps=100,
logging_dir="autodl-tmp/output/lora_sft/logs",
report_to="none", # 或 "wandb", "tensorboard"
)
# ============ 步骤6: 创建 Trainer 并训练 ============
from torchdata.datapipes.iter import IterableWrapper
print("初始化 Trainer...")
trainer = Trainer(
model=model,
args=training_args,
train_dataset=IterableWrapper(train_dataset),
tokenizer=tokenizer,
)
print("开始训练...")
trainer.train()
# ============ 步骤7: 保存 LoRA 权重 ============
print("保存 LoRA 权重...")
model.save_pretrained("autodl-tmp/output/lora_sft/lora_weights")
tokenizer.save_pretrained("autodl-tmp/output/lora_sft/lora_weights")
print("训练完成!")
输出内容:
加载模型和 Tokenizer...
原始模型参数量: 1540.00M
应用 LoRA...
LoRA 可训练参数: 2.36M (0.15%)
trainable params: 2,359,296 || all params: 1,542,359,296 || trainable%: 0.1530
加载训练数据...
训练样本数: 10000
初始化 Trainer...
开始训练...
Step 10, Loss: 1.8234
Step 20, Loss: 1.6543
...
保存 LoRA 权重...
训练完成!
推理使用
训练完成后,有两种使用方式:
方式1: 动态加载 LoRA(灵活)
from peft import PeftModel
# 加载基座模型
base_model = AutoModelForCausalLM.from_pretrained(
"autodl-tmp/qwen-1.5b",
trust_remote_code=True
)
# 加载 LoRA 权重
model = PeftModel.from_pretrained(
base_model,
"autodl-tmp/output/lora_sft/lora_weights"
)
# 推理
tokenizer = AutoTokenizer.from_pretrained("autodl-tmp/output/lora_sft/lora_weights")
inputs = tokenizer("翻译成英文:今天天气很好", return_tensors="pt")
outputs = model.generate(**inputs, max_length=100)
print(tokenizer.decode(outputs[0]))
输出内容:
翻译成英文:今天天气很好
Translation: The weather is nice today.
方式2: 合并权重(部署)
from peft import PeftModel
# 加载模型
base_model = AutoModelForCausalLM.from_pretrained(
"autodl-tmp/qwen-1.5b",
trust_remote_code=True
)
model = PeftModel.from_pretrained(base_model, "autodl-tmp/output/lora_sft/lora_weights")
# 合并 LoRA 权重到基座模型
merged_model = model.merge_and_unload()
# 保存合并后的模型(无推理延迟)
merged_model.save_pretrained("autodl-tmp/output/lora_sft/merged_model")
tokenizer.save_pretrained("autodl-tmp/output/lora_sft/merged_model")
print("权重合并完成!现在可以像普通模型一样使用。")
输出内容:
权重合并完成!现在可以像普通模型一样使用。
应用于其他任务
LoRA 也可应用于 DPO、KTO 等训练:
from trl import DPOTrainer
# 配置 LoRA
lora_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
r=8,
lora_alpha=32,
target_modules=["q_proj", "v_proj"]
)
# 加载模型并应用 LoRA
model = AutoModelForCausalLM.from_pretrained(MODEL_PATH)
model = get_peft_model(model, lora_config)
# 使用 DPOTrainer
trainer = DPOTrainer(
model=model,
ref_model=None, # 使用 LoRA 时可以共享参考模型
args=training_args,
train_dataset=dpo_dataset,
tokenizer=tokenizer,
)
trainer.train()
参考资料
[1] Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, et al. (2019). Parameter-Efficient Transfer Learning for NLP. arXiv preprint arXiv:1902.00751.
[2] Edward J. Hu, Yelong Shen, Phillip Wallis, et al. (2021). LoRA: Low-Rank Adaptation of Large Language Models. arXiv preprint arXiv:2106.09685.
[3] Armen Aghajanyan, Luke Zettlemoyer, and Sonal Gupta. (2020). Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning. arXiv preprint arXiv:2012.13255.
[4] Xiang Lisa Li and Percy Liang. (2021). Prefix-Tuning: Optimizing Continuous Prompts for Generation. arXiv preprint arXiv:2101.00190.
总结
框架选择:
- Transformers 是 LLM 时代的主流框架,提供统一的模型接口和丰富的生态
- HuggingFace 社区提供数亿预训练模型和海量数据集
分布式训练:
- DeepSpeed ZeRO 技术使多卡训练变得简单高效
- ZeRO-2 适合大多数场景,可将显存占用降低数倍
高效微调:
- LoRA 在保持性能的同时,将可训练参数减少到原模型的 0.1-1%
- 适用于资源受限、数据受限的下游任务适配场景
- 不适用于需要注入新知识的场景
实践建议:
- 预训练:使用足够大的数据集(TB级)和长时间训练,建议使用多卡 + DeepSpeed
- SFT:精心构造高质量指令数据,数据量可以较小(10K-100K),全量微调或 LoRA 均可
- 领域适配:优先考虑 LoRA,快速验证效果后再决定是否全量微调
- 生产部署:LoRA 可合并权重实现零延迟推理
技术栈总结
模型框架: Transformers
数据处理: Datasets
分布式训练: DeepSpeed
高效微调: PEFT (LoRA)
训练监控: SwanLab / Wandb
更多推荐

 12
12 0
0- 0



 已为社区贡献48条内容
已为社区贡献48条内容

所有评论(0)