
RAG技术完全指南:从基础原理到Graph RAG进阶实战【值得收藏】
摘要:本文系统讲解RAG检索增强生成技术,包括其概念、架构与工作流程。RAG通过结合外部知识库解决大模型知识更新滞后、幻觉等问题,提升专业领域任务准确性。文章详细阐述文档分块、向量化存储及检索生成流程,通过代码示例展示RAG实现过程,并图解完整架构,涵盖查询、检索和生成三个阶段的核心技术要点。
本文全面介绍RAG检索增强生成技术,涵盖基础概念、架构和工作流程,详细解释稀疏与稠密文本检索原理,深入探讨查询重写、检索结果重排等优化技术,重点解析Graph RAG的索引和检索阶段,通过代码示例展示实现方法,为读者提供从入门到进阶的完整学习路径。
5.1 RAG基础与原理
5.1.1 RAG基础概念
检索增强生成(RAG,Retrieval-Augmented Generation)是由Facebook(现Meta) AI Research在2020年的一篇论文[1]中出的一个技术,提出的原因是大语言模型(LLM)虽然在各种任务上表现优异,但由于知识存储在参数中,无法及时更新且易出现幻觉(Hallucination);因此引入外部可检索的非参数化记忆,并将检索结果与模型结合,从而提升知识密集型任务的准确性与可追溯性。
简单的人话表述就是,大模型需要外部的信息来帮助决策,提前将文档通过一些手段(分块、向量化等)存起来后,查询的时候可以在这些内容中搜索辅助大模型进行最终的回答,整个流程下来就是RAG要做的一个事情。
RAG能流行是因为其解决了这么几个问题:
•解决推理使用的是过时的训练语料库:尤其针对一些对时间较为敏感的数据,以及一些个人/企业知识库需要最新的
•缓解幻觉(Hallucination):RAG可以极强的缓解幻觉,这个核心还是因为模型基于上下文进行推理的过程可以产生更加可靠的结果
•通用模型专业化:尤其针对垂直领域时,通用模型权重过于分散,在搭配该领域的知识库后,可以有效提升专业化,提高结果的可靠性
我们采用Langchain官方这个教程[2]里的图演示RAG是怎么运作的:
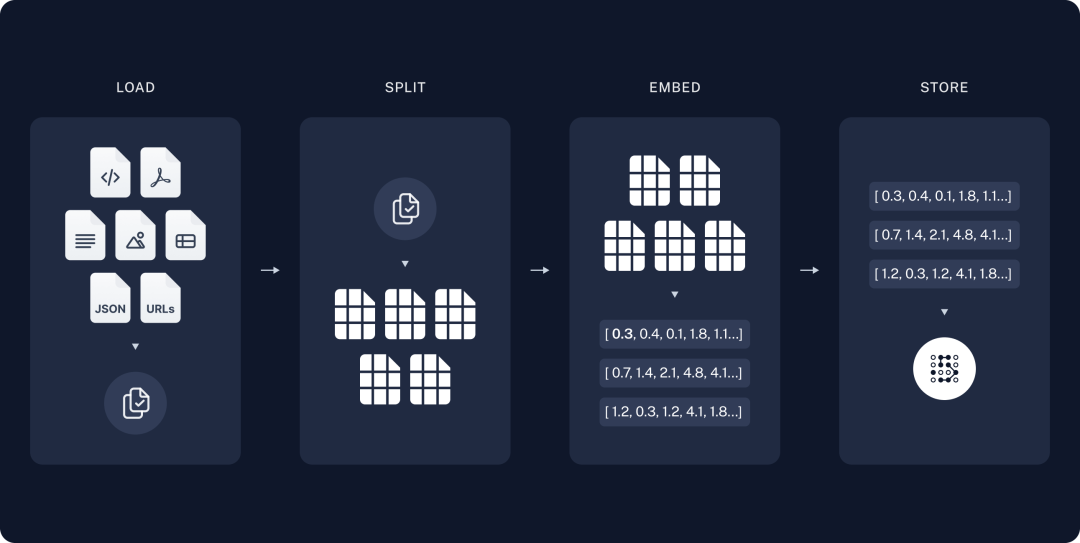
文档通过这个流程进行分块、向量化和存储。然后到查询环节:
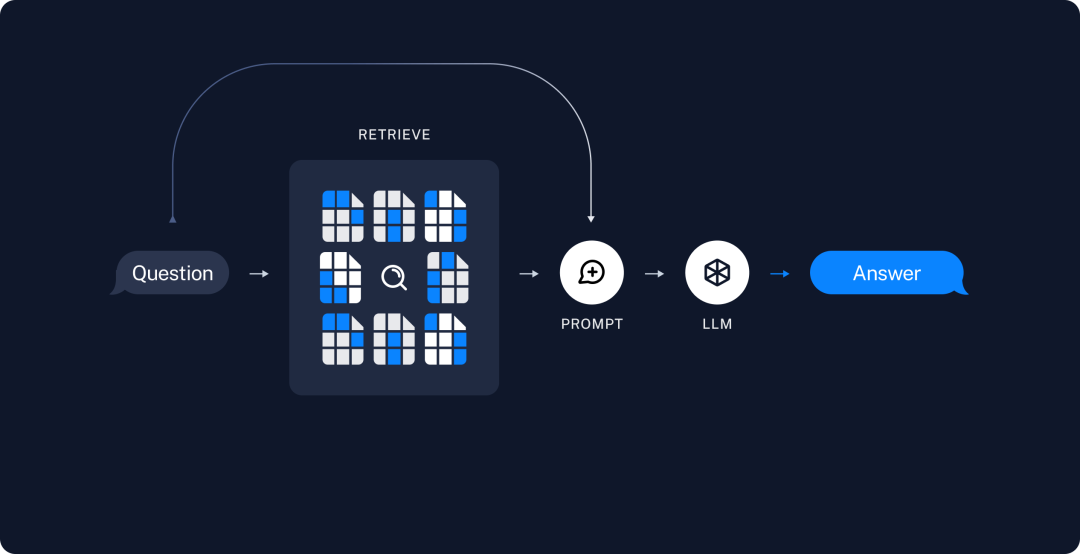
召回Top K的结果,结合提示词给到大模型做最后的输出。下面是一个简单的Demo:
import logging
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain.chains import RetrievalQA
from langchain.text_splitter import CharacterTextSplitter
from langchain_community.vectorstores import FAISS
# 配置日志格式
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s [%(levelname)s] %(message)s",
)
# Step 1: 准备文档
docs = [
"Leo 发明了一种新的编程语言,名字叫做 CatLang。",
"CatLang 的语法非常简单,所有函数都以 '喵' 开头。",
"在 2025 年,Leo 还发布了一个框架叫做 PurrNet,用于分布式 AI 计算。",
"PurrNet 的核心是通过小猫节点来进行任务调度,每个节点代号是 Kitten。",
]
logging.info("准备文档完成,共 %d 条", len(docs))
# Step 2: 文本切分(可选)
splitter = CharacterTextSplitter(chunk_size=100, chunk_overlap=0)
texts = []
for d in docs:
chunks = splitter.split_text(d)
texts.extend(chunks)
logging.info("文档切分: 原文=%s -> %d 个切片", d, len(chunks))
logging.info("所有切分后的文本总数: %d", len(texts))
# Step 3: 向量化 & 建立向量数据库
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
logging.info("开始向量化...")
vectorstore = FAISS.from_texts(texts, embeddings)
logging.info("向量数据库建立完成")
# Step 4: 构建 RAG QA Chain
retriever = vectorstore.as_retriever(search_type="similarity", search_kwargs={"k": 2})
llm = ChatOpenAI(model="gpt-4o-mini")
qa = RetrievalQA.from_chain_type(llm=llm, retriever=retriever)
logging.info("RAG QA Chain 构建完成")
# Step 5: 提问
query = "什么是CatLang?"
logging.info("开始提问: %s", query)
result = qa.run(query)
# 检索过程可视化(教学用)
logging.info("检索到的相关文档(Top 2):")
retrieved_docs = retriever.get_relevant_documents(query)
for i, doc in enumerate(retrieved_docs, 1):
logging.info("文档 %d: %s", i, doc.page_content)
print("\n====== 最终结果 ======")
print("问题:", query)
print("回答:", result)
print("=====================\n")
这是一个很简单的例子,我随便虚构了一些大模型不可能“知道”的内容,这样可以避免大模型作弊,然后写死了,运行后输出如下:
2025-09-21 22:25:21,127 [INFO] 准备文档完成,共 4 条
2025-09-21 22:25:21,127 [INFO] 文档切分: 原文=Leo 发明了一种新的编程语言,名字叫做 CatLang。 -> 1 个切片
2025-09-21 22:25:21,127 [INFO] 文档切分: 原文=CatLang 的语法非常简单,所有函数都以 '喵' 开头。 -> 1 个切片
2025-09-21 22:25:21,127 [INFO] 文档切分: 原文=在 2025 年,Leo 还发布了一个框架叫做 PurrNet,用于分布式 AI 计算。 -> 1 个切片
2025-09-21 22:25:21,127 [INFO] 文档切分: 原文=PurrNet 的核心是通过小猫节点来进行任务调度,每个节点代号是 Kitten。 -> 1 个切片
2025-09-21 22:25:21,127 [INFO] 所有切分后的文本总数: 4
2025-09-21 22:25:21,335 [INFO] 开始向量化...
2025-09-21 22:25:23,180 [INFO] HTTP Request: POST https://api.openai.com/v1/embeddings "HTTP/1.1 200 OK"
2025-09-21 22:25:23,230 [INFO] Loading faiss.
2025-09-21 22:25:23,279 [INFO] Successfully loaded faiss.
2025-09-21 22:25:23,285 [INFO] 向量数据库建立完成
2025-09-21 22:25:23,388 [INFO] RAG QA Chain 构建完成
2025-09-21 22:25:23,388 [INFO] 开始提问: 什么是CatLang?
2025-09-21 22:25:24,608 [INFO] HTTP Request: POST https://api.openai.com/v1/embeddings "HTTP/1.1 200 OK"
2025-09-21 22:25:27,366 [INFO] HTTP Request: POST https://api.openai.com/v1/chat/completions "HTTP/1.1 200 OK"
2025-09-21 22:25:27,392 [INFO] 检索到的相关文档(Top 2):
2025-09-21 22:25:29,062 [INFO] HTTP Request: POST https://api.openai.com/v1/embeddings "HTTP/1.1 200 OK"
2025-09-21 22:25:29,064 [INFO] 文档 1: Leo 发明了一种新的编程语言,名字叫做 CatLang。
2025-09-21 22:25:29,065 [INFO] 文档 2: CatLang 的语法非常简单,所有函数都以 '喵' 开头。
====== 最终结果 ======
问题: 什么是CatLang?
回答: CatLang是一种由Leo发明的新编程语言,其语法非常简单,所有函数都以“喵”开头。
=====================
这边我做了一个Top K搜索的模拟,实际上是不会打印的,这个简单的Demo让我们对RAG有一个初步的概念。总体而言,RAG是为了提高效果的技术,其结合文档检索,提供了合适模型的上下文,成为上下文工程中的核心技术之一。接下去我们来看一下RAG的基础架构和流程
5.1.2 架构与工作流程
接下去我们来看看RAG相关的架构和流程,这边我画了一张RAG架构图:
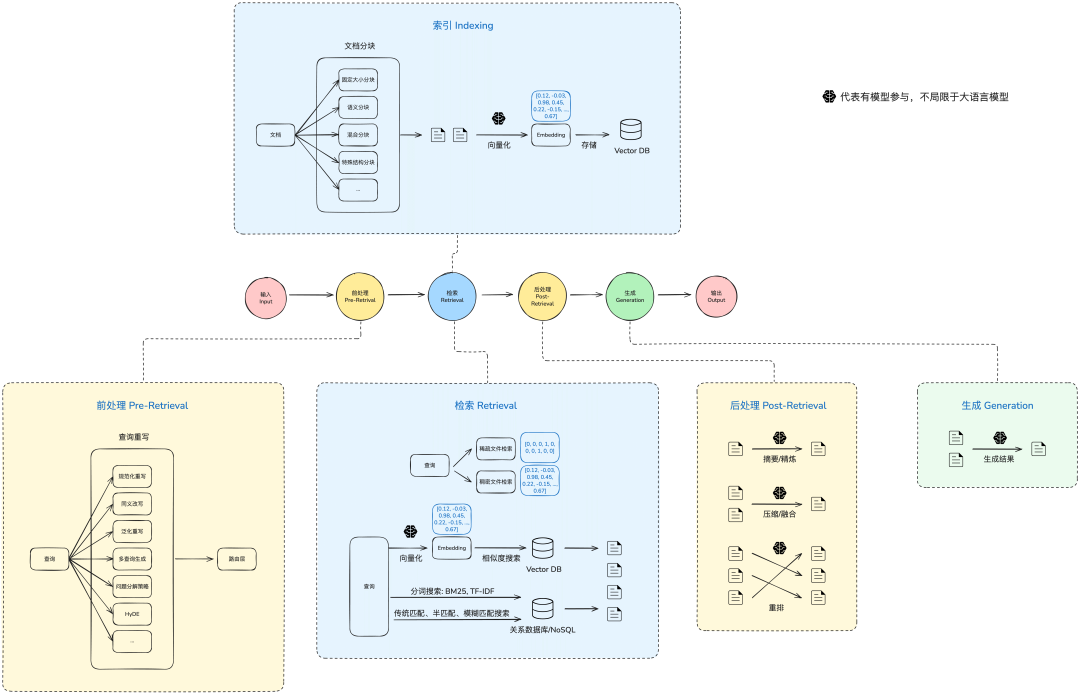
这是一个比较完整的RAG架构图,包含了流程中的一些关键节点,我们不需要马上理解每个环节,后面我们会陆续提到每个环节里的内容。
RAG的基础架构相对简单,主要分为三个阶段:
1.查询(Query):输入,通常为用户的查询或者问题等
2.检索(Retriever):从相关知识库中获得与用户问题相关性最高的文档(Top K)
3.生成(Generation):根据Query和检索得到的文档,生成高质量的回答
下面是一个RAG实施的全过程:
1.数据通过合理的分块(chunking),每块分别做向量化(embedding)后存到向量数据库
2.查询进来后,将查询问题也通过同样的方式向量化后,去到向量数据库内做相似性搜索
3.将搜索得到的top-k文档块的原始数据拼接后放在上下文中一起发送给大语言模型
4.大语言模型基于响应的数据做最后的结果生成
这样有了原始数据的参考,大模型就有了参照物,最终给出的答案也会更加稳定,避免自由发挥情况下容易产生幻觉或产生过时数据的情况发生。在开始深入RAG之前,我们可以先来了解一下检索方式,这有助于我们理解RAG里一个很核心的概念,检索。
5.1.3 检索方式
在自然语言处理中有文本检索技术,分为:
1.稀疏文本检索(Sparse Retrieval)
2.稠密文本检索(Dense Retrieval)
在现行的RAG语境下,更多是使用了向量化搜索,也就是稠密文本检索的方式。但是随着RAG应用的推广和普及,目前越来越多应用中会将两个检索方式结合起来使用,这个在下一节中也会了解到。现在我们先来了解一下这两种检索方式的原理和差异。
稀疏文本检索(Sparse Retrieval)
原理是基于词频(Term Frequency)等显式词项统计信息,使用稀疏向量(Sparse Vector)表示文本,使用向量相似度进行匹配,返回最相关的文档。那么什么是稀疏向量呢?简单说就是大部分维度为0的向量。简单举个例子来理解,假设有个词表(vocabulary):
["apple", "banana", "car", "dog", "elephant"]
这个词表有5个词,对应一个5维的向量空间。现在有个文档:
I like banana
我们用稀疏向量来表示这个文档时,会得到:
[0, 1, 0, 0, 0]
很直观的可以看到,这是一个5维的向量,但是其中大部分的维度都是0(没出现),只有极少数是非0(有出现的词)。理论上我们会在这里持续增加词出现的频次,比如
banana banana banana!
可以得到
[0, 3, 0, 0, 0]
看着没什么问题,但是这种极致简单的词频统计,会在某些情况下有问题,比如像“the”、“is”、“you”这些词在所有文本中都很多,但它们没啥实际意义。所以出现次数多的词,并不一定重要。为了解决这个问题,我们就需要引入一些方法。常见的方法有:
•TF-IDF(Term Frequency - Inverse Document Frequency):在词频的基础上加入“逆文档频率”因素,降低常见词的权重,提高稀有词的权重。
•BM25:一种改进的 TF-IDF 加权方案,同时考虑了词频饱和、文档长度归一化等因素,广泛应用于现代搜索引擎。
这些方法都基于**倒排索引(Inverted Index)**结构实现高效检索。它们不再简单依赖“词频越高越重要”的假设,而是引入更多统计规律,使得检索系统能更准确地评估“哪些词更关键”。这个也是传统的搜索引擎的基础,像Google这类搜索引擎在早期就应用了这类技术去做搜索。另外全文检索里可以经常看到这两个技术,比如ES的全文检索就是利用了BM25来做的。
可以看出稀疏文本检索的优点就是高效快速,消耗资源少,因此被广泛使用。其缺点就是无法理解一些语义相近但是词不重叠的文本,比如car和automobile这种,因此也就有了稠密文本检索来解决这个问题
稠密文本检索(Dense Retrieval)
原理是通过神经网络(如Word2Vec、BERT)将查询和文档分别编码成低维稠密向量(Dense Vector),使用向量相似度(如内积或余弦相似度)进行匹配,返回最相关的文档。那么什么是稠密向量呢?和稀疏向量刚好反过来了:稠密向量是所有维度基本都有值的向量。每一维都用浮点数表示,通常没有“0”或者很少有“0”。
这边的低维是相对于前面稀疏文本里的稀疏向量通常是极高维度的,因为那边的向量维度=词表大小,通常可以词表可以达到几十万甚至百万维,但是在稠密向量里,通常几十维到几千维的程度,所以是低维稠密向量。
举个例子,还是前面这句话:
I love bananas
我们将其送进一个神经网络模型(如BERT、DPR编码器),可以输出得到一个向量,如:
[0.12, -0.08, 0.91, 0.33, ..., 0.04] // 共768维
像现在流行的Embedding本质上就是这个原理,通过预训练语言模型后,可以通过模型将内容编码为向量,每个向量都是一个语义表示(Semantic Representation),这些向量不是手动构造的,而是模型通过大量文本学习出来的。
我们可以找到很多这种向量可视化的网站或者开源项目,比如tensorflow[3]这个展示了word2vec的向量在三维空间的表示,可以看两个词的可视化距离(相似度计算其实算的就是在对应维度空间下的两点之间的距离,只不过维度高到人类大脑无法轻易想象,也就是超越人类的认知,没办法像在二维和三维空间下可以轻松计算距离)
另外vectosphere这个,也可以同样可视化展示:
回过头来,常见的稠密文本检索方法有下面这些,有兴趣的可以自己去了解一下:
我们平时最常见的RAG应用就是使用了Bi-Encoder,因为足够快,而ReRank时数量较少,可以利用Cross-Encoder来打分。
到这里我们已经知道了稠密文本检索到底是做什么了,在提前向量化资料后,在后续问题来了之后可以将问题也进行向量化,然后通过向量相似度进行搜索,得到最相关的资料,这就是稠密文本检索的过程,能够检索语义相近但词不匹配的文档,并且适合复杂查询、开放域问答、RAG 等应用。
其缺点也相对明显:需要大规模训练,消耗资源大,部署成本高,另外召回的结果可解释性低
融合方法(Hybrid Retrieval)
两者各有优缺点,因此很多系统或者应用场景会将两者进行结合,比如用稀疏检索(如BM25)结合稠密检索先召回 Top K文档,再用重排模型(Dense Reranker,如Cross-Encoder)对结果进行重新排序,重新排序
引用一张我之前发的关于Bi-Encoder和Cross-Encoder:
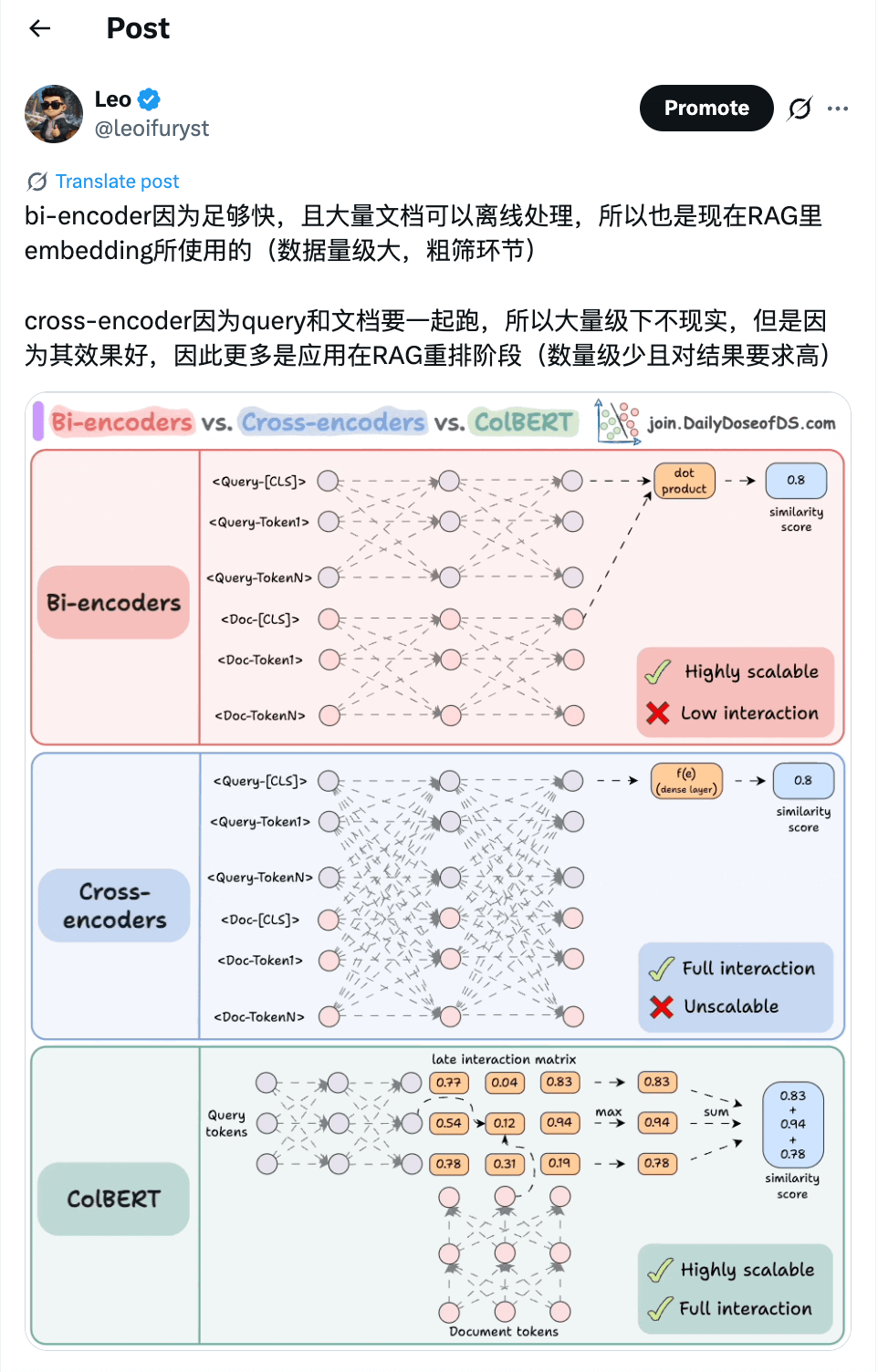
我们在实际应用中不会因为技术而技术,一定要记住这句话!否则很容易陷入拿着锤子找钉子的尴尬境地(现在其实有不少人就是拿着AI找钉子敲)。就比如前面提到的这些,有可能在实际的应用中只是简单的应用向量化去做检索就足够了,也可能复杂到需要结合关系型数据库做常规的数据检索+ES做全文检索+向量化检索+重排技术得到最匹配的结果去做方案。所以应用AI(Applied AI)的背后就是我们需要去了解每个技术背后的原理,是基于什么背景之下提出来的,以及这个技术目前发展到什么程度了,可以解决什么问题,在某个应用场景下是否合适,这样我们才可以真正做到将AI应用在有价值的地方,赋能业务产生真正的商业价值,而不是陷入技术自嗨中。
了解完这个我们对于RAG的底层依托的技术已经有了比较清晰的认知了,接下去我们会进一步深入去了解RAG相关的技术以及衍生的一些应用方式。
5.2 RAG进阶
常规的RAG相对简单,在实际应用中,我们会在原本的架构之上,去运用一些技术和方法来提高,比如:
•标量+向量:通常RAG是将文档分块(Chunk)后向量化(Embedding)入库,然后查询也向量化后到向量数据库进行相似性搜索。如前面提到,实际上还可以结合传统的数据库或者ES进行标量数据的匹配检索,最后可以得到标量+向量数据。
•重排(Reranking):不管是单向量还是结合了标量,在送到模型前可以用一些手段对文档进行重新排序,通常我们会使用重排模型对文档再进行评分排序,这样可以选择实际送到模型的文档
•多跳RAG:当单跳查询无法满足复杂的查询时,结合多跳是可以达到更好的效果的。
•图增强RAG(Graph-RAG):结合图的能力来扩展RAG的能力,尤其是在文档处理阶段,可以利用图+大模型来细化一些实体和关系,甚至进一步形成社区或领域的形态。
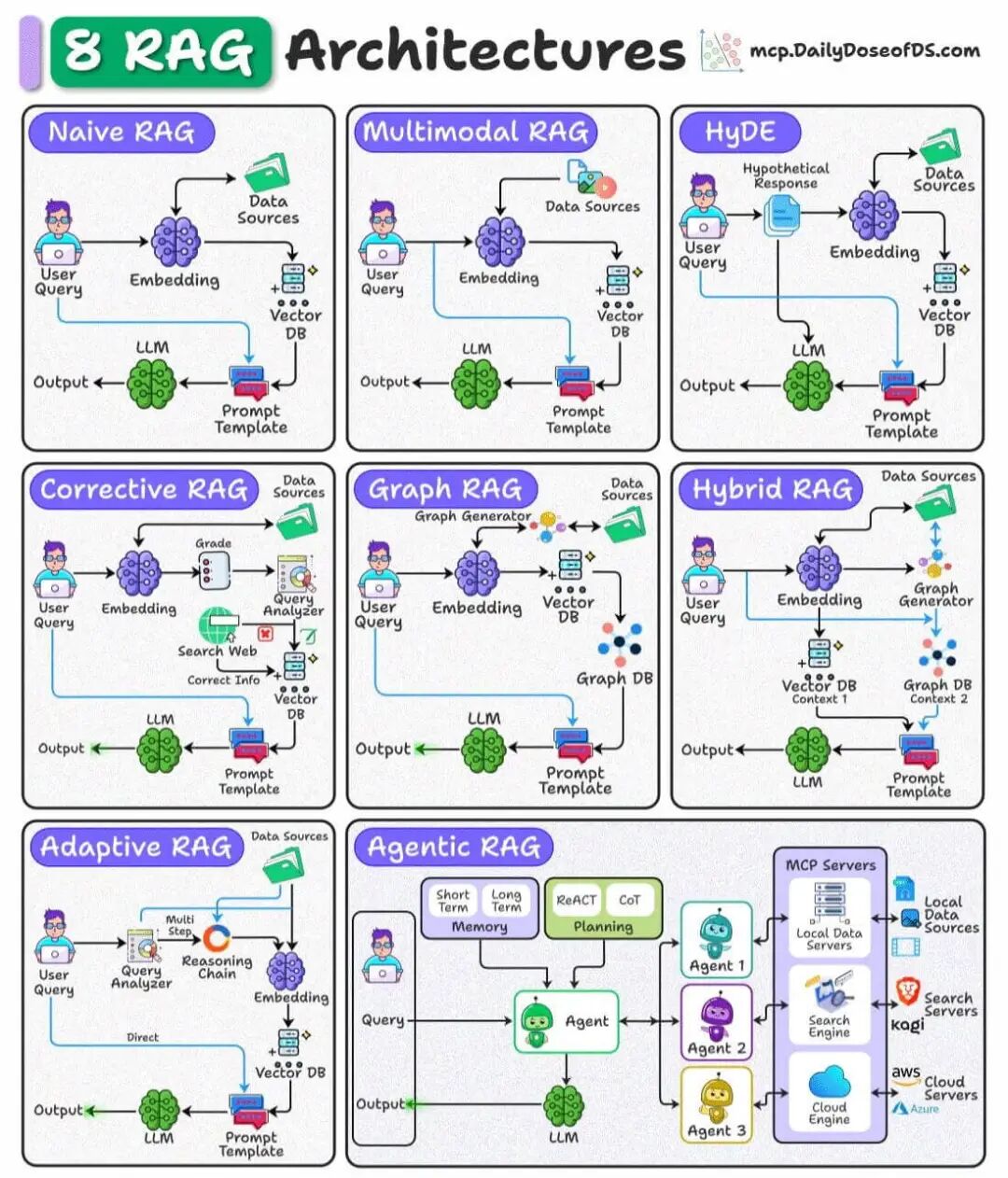
上面只是一部分技术或方法。在技术普及过程,开始会陆续出现体系化的知识,也是为了方便应用以及后来者学习,现在业界也有很多划分方式,比如Daily Dose of Data Science[4]这张图:
另外这篇论文[5]里也提供了相应的划分方式:
我们引用这篇论文[6]里的一张示意图:
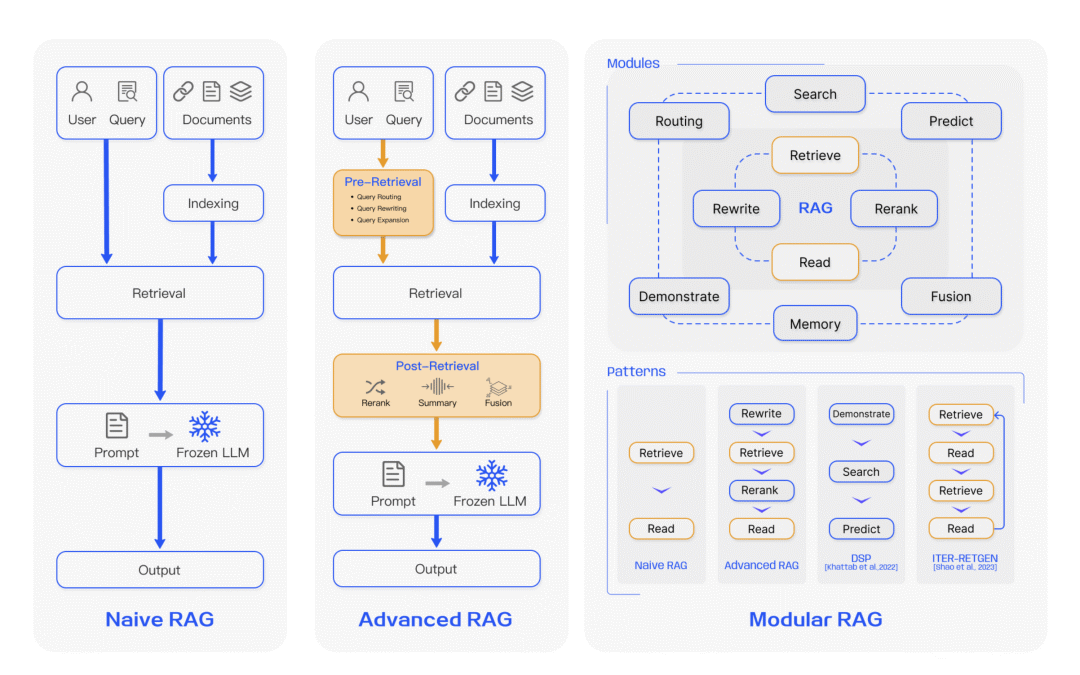
可以较为清楚的看出差别,分类是人为划分的,本质上就是针对基础的RAG在各个环节进行优化提升,目的都是为了提高最后输出的效果。
**进阶RAG(Advanced RAG)就是加入了前处理阶段(Pre-Retrieval)来优化查询,比如查询重写或运用一些策略进行处理。并且加入了后处理阶段(Post-Retrieval)**来优化检索后的文档块,比如重排、压缩或融合等手段,这样在最终给到大模型可以得到更好的结果提升。
**模块化RAG(Modular RAG)**则是将各种阶段或者功能单独成模块,每个模块是最小单元,可以自由的组合,形成一个类似workflow的流程,有点像是玩乐高积木,可以针对不同的业务场景自由组合。本质上里面的技术和方法没有变化,只不过是在工程化上进行了优化,方便不断复用和自由编排。
**图RAG(Graph RAG)**就是利用了图来辅助处理,万物皆可图,图的能力应用在RAG里,使得RAG得到了极大的提升,后面我们会在图RAG章节里会详细分析加入图能力,RAG得到的好处和提升。
**智能体RAG(Agentic RAG)**则是将RAG从简单的检索生成扩展成自主的Agent,可以基于一定的策略动态决策并进行多轮次检索,这个其实是对多跳RAG的一种提升,将AI Agent的思想融入RAG。
到这里我们再回过头来看看我们前面的那张架构图:
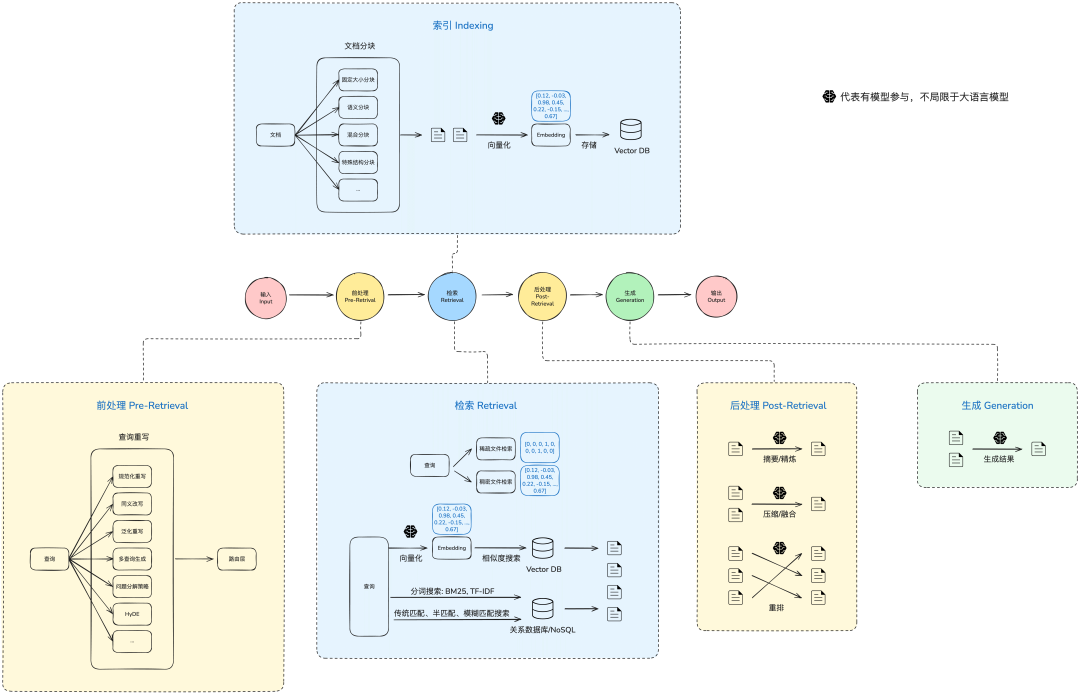
这里面其实已经体现了很多的东西,我们可以把RAG分为:
1.输入:可能有不同的输入方式,主流常见的是从Chat进来的问题
2.前处理:检索前作一些前置处理动作,目的是增加召回效果
3.检索:执行检索
4.后处理:对检索的结果进行特定的处理,目的也是增加召回效果
5.生成:给大模型输出最后的结果
6.输出:将结果返回
这个其实就是一个进阶RAG的流程了,至于模块化RAG,其实是将里面的功能模块都单独抽出来形成独立的单元,这样可以重复自由组织编排,而图RAG和智能体RAG则会在里面多个环节参与。下面我们会针对一些关键的节点和方式展开。
5.2.1 查询重写
在传统的RAG里,通常就是将查询通过向量化的手段转成嵌入(embedding),做相似性搜索后给到大模型。这种情况下有明显可见的问题:输入查询无法顺利匹配到文档块。
在实际场景下,用户输入的问题有可能因为过于简化或者表述不当而无法通过相似度搜索匹配到合适的文档块,使得最终的效果不符合预期。面对这个问题,可以应用查询重写来进一步缓解并提升效果。
正如前面提到的,重写策略其实有挺多的,目前主流的有这么几种(更多还是一些类别的划分,实际上在不同的业务场景下还会有不同的策略浮现的,比如一些行业词汇重写、黑白词等等,这边就不过度展开):
1.规范化重写(Canonicalization):将随意、模糊、口语化表达转成标准清晰的问题
2.同义改写(Paraphrasing):增强表达覆盖、抗embedding漏召
3.泛化重写(Step-Back Query):提升复杂问题检索效果
4.多查询生成(Multi-query Generation):多视角覆盖、提升召回率
5.问题分解策略(Question Decomposition):将复杂查询拆分为多个子问题,分步检索和推理
规范化重写(Canonicalization)
规范化重写其实就是针对查询问题让大语言模型帮忙进行重写,使得问题更加规范化,这其中有一些不同的手法。我们先来看一个基础的示例:
周杰伦第一张专辑是什么?
可以改写成
周杰伦第一张音乐专辑名称是什么?
类似这样的规范化重写,可以将一个较为随意的问题转变成更加正式的问题。以便在向量化检索的过程中,可以更好的召回预期的文档块用于最终的结果生成。
同义改写(Paraphrasing)
同义改写的原理也是差不多的,对于不合适的表述,可以进行同义替换改写,使得输入的内容可以更容易匹配到合适的文档块。比如:
# 历史聊天记录
User: 马斯克现在拥有哪些公司
AI: 截至2025年,马斯克拥有或主导的公司包括特斯拉、SpaceX、xAI(含X)、Neuralink 和 The Boring Company。
User: 他现在个人财富估值是多少?
历史信息已经出现过相应的人物名,但是在最新的Query中却没有重复表述,此时是可以通过重写将用户最新的问题重写成:
马斯克现在个人财富估值是多少?
甚至是可以进一步结合前面规范化重写:
截止2025年7月,马斯克(Elon Musk)的个人净资产估值是多少?
这样等于是把时间具体化,并且名词也更加规范化表述了。
泛化重写(Step-Back Query)
泛化重写是把具体的问题抽象,将问题覆盖范围扩大了,这样可以扩大检索范围和获取更完整的上下文信息,比如:
马斯克的出生地是哪里?
可以改写成:
马斯克的个人背景和早年经历是什么?
这种好处不是明显可见的,为什么这么说呢?因为问题被泛化之后,有可能会导致答案也进一步被泛化,当然最终的递送给大语言模型的Prompt是可以保留原始的问题的。泛化重写其实是应该结合多跳RAG这些技术来发挥更大的作用,这个在后续我们也会涉及到,简单说就是通过泛化先在一个方向上探索,再一步步细化定位到实际想要的结果中。
多查询生成(Multi-query Generation)
这个方式也是应对用户问题表述不清晰或含糊的情况,通过将单一问题生成多个问题的方式,对一个问题提供多个角度,这样可以提高覆盖度,达到更好的检索和结果生成效果。
我们来看下例子:
周杰伦的第一张专辑是什么?
多查询重写:
周杰伦最早发行的专辑是哪一张?
周杰伦第一张音乐专辑的名字是什么?
周杰伦早期的音乐作品有哪些?
周杰伦的音乐出道作品是哪一张专辑?
这样就将一个问题扩展出基于不同角度的多个问题组合,这样可以以较为全面的角度去召回文档块了。
问题分解策略(Question Decomposition)
将一个复杂问题拆解成多个原子问题,使得可以基于多个问题去分别召回文档块,比如:
周杰伦从出道到现在有哪些重要的音乐成就?
可以拆解成:
周杰伦是哪一年出道的?
周杰伦的第一张专辑是什么?
周杰伦获得过哪些音乐奖项?
周杰伦的代表作有哪些?
他对华语乐坛的影响体现在哪些方面?
这样可以基于不同的问题去做处理了。这里其实还可以结合前面的一些重写策略进一步完善子问题。
另外这种方式通常会结合一些MapReduce的思维去做时间,也就是基于不同的原子问题去做文档块的召回,并做不同的结果生成,最终再把所有的结果再进行汇总生成一个最终的结果。后续我们也会提到这块应用,尤其在Graph RAG里有很完备的应用示例可以学习。
5.2.2 检索结果重排
重排是提升RAG检索效果里很重要的一步,也是目前实际应用中很广泛被采用的一种方式,主要有几种方式:
1.基于打分函数的传统重排方法:BM25,TF-IDF余弦相似度
2.语义匹配类重排方法:双塔结构(Bi-Encoder),交叉编码器(Cross-Encoder)
3.生成式重排方法:通过LLM进行评分和排序
实际使用需要根据业务需求和所有的资源来决定,这边我们来看个例子,LangChain官方有一个FlashRank reranker[7]的例子,采用的是FlashRank[8],主要支持Pointwise(单文档打分),Pairwise(双文档比较,看谁相关度更好)和Listwise(列表排序,一次对所有文档排序)两种方式
下面是一个基础的RAG流程,对文档切分后建立embedding,然后在对问题做向量化后在里面检索出相似度最高的20条文档片段
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
documents = TextLoader(
"../../how_to/state_of_the_union.txt",
).load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
texts = text_splitter.split_documents(documents)
for idx, text in enumerate(texts):
text.metadata["id"] = idx
embedding = OpenAIEmbeddings(model="text-embedding-ada-002")
retriever = FAISS.from_documents(texts, embedding).as_retriever(search_kwargs={"k": 20})
query = "What did the president say about Ketanji Brown Jackson"
docs = retriever.invoke(query)
pretty_print_docs(docs)
现在来应用一下FlashRank做重排,从前面读取retriever,构建ContextualCompressionRetriever,里面会使用FlashrankRerank
from langchain.retrievers import ContextualCompressionRetriever
from langchain_community.document_compressors import FlashrankRerank
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(temperature=0)
compressor = FlashrankRerank()
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor, base_retriever=retriever
)
compressed_docs = compression_retriever.invoke(
"What did the president say about Ketanji Jackson Brown"
)
print([doc.metadata["id"] for doc in compressed_docs])
对比一下前后的效果:

•Document 1 -> Document 1
•Document 4 -> Document 2
•Document 6 -> Document 3
经过重排后,获取到的Top 3文档不一样了
5.2.3 Graph RAG
Graph RAG[9]是微软在2024年推出的一种结构化、分层的检索增强生成(RAG)方法,相较于仅使用纯文本片段进行语义搜索的朴素方法,它更加系统和智能。GraphRAG 的处理流程包括:从原始文本中提取知识图谱、构建社区层级结构、为这些社区生成摘要,并在执行基于 RAG 的任务时充分利用这些结构化信息。下面我们会做一个比较详细的分析
索引阶段
看看架构图可以有个全局的认知
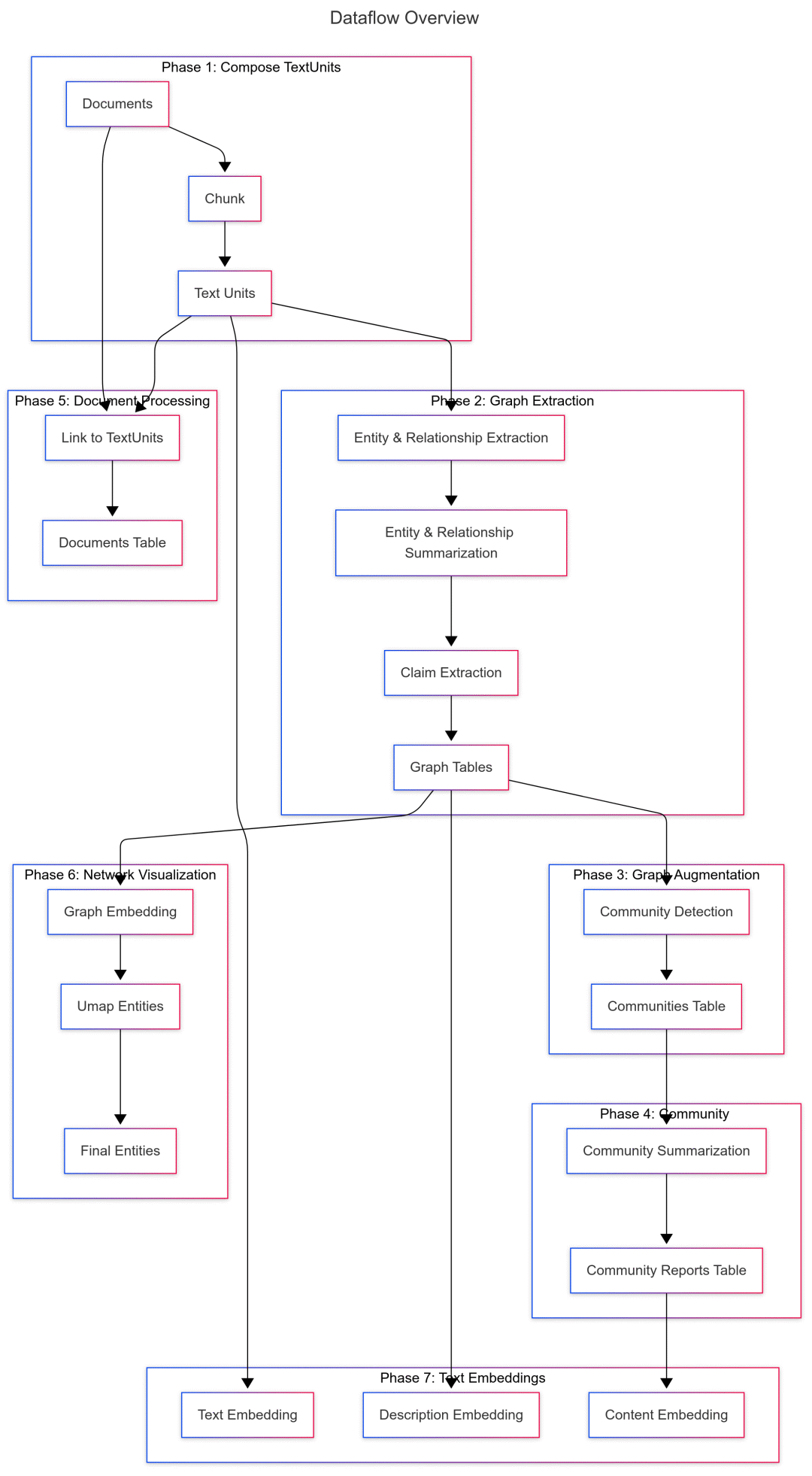
我们来看看标准处理流程:
1.文本处理 (Text Processing)
2.文档处理(Document Processing)
3.图提取(Graph Extraction)
4.图增强(Graph Augmentation)
5.声明提取(Claims Extraction)
6.社区创建(Community Creation)
7.文本单元最终化((Final Text Units)
8.社区报告生成(Community Reports)
9.文本嵌入(Text Embeddings)
文本处理 (Text Processing)
主要接收多种数据输入,然后对输入的数据进行切分(支持按句子或者token进行切分),分块得到文本单元TextUnits。
这步主要是为了方便后续的数据处理,因为后续的处理涉及多轮次的模型调用,以一个合理块大小的处理单元来处理,会更加方便且上下文不容超过,也适合并发调度处理。
文档处理(Document Processing)
将文本处理阶段处理出来的TextUnits与原始文档建立引用关系,形成一个结构化的数据表,用于后续一些操作:
•跟踪每个文档包含哪些chunk
•后续社区摘要、图构建等流程中使用
•统一文档展示和可视化索引
图提取(Graph Extraction)
会包含几个阶段:
1.**实体(Entity)和关系(Relationship)**提取
2.图数据进行摘要简化(Graph Summrization)
首先会让大语言模型提取文本里的实体(Entity),以及不同实体间的关系(Relationship),还会附带关系强弱的评分用于计算实体间的关系权重。
这期间会在内存中做一定的合并和更新。比如实体和关系的描述,持续的更新会导致描述膨胀,这种情况下需要再进行一步图摘要,也就是让模型再次帮忙将实体和关系里的描述做总结为单一简介描述
图增强(Graph Augmentation)
图增强里主要是图最终化,也就是将初步提取出来的图数据(实体节点和关系边),经过清洗、加工、标准化并准备好用于下游使用的过程。因为这是图构建的最后阶段:
•之前:只有基础的实体名称、描述、关系
•之后:实体具备了向量表示、空间坐标、网络属性等完整特征
简单说就是:
初步提取的基础数据 -> 可用于可视化、推理、检索和分析的结构化图
在对实体最终化流程中,会有这么一些操作和步骤:
•根据配置决定是否创建向量(embedding)
•根据配置决定是否对图做UMAP或其他布局(layout)方法,生成2D/3D坐标用于可视化
•计算每个实体节点的度数(degree),用于后续分析或排序
•合并、移除重复、预填充缺失字段、生成唯一id等等
UMAP(Uniform Manifold Approximation and Projection)中文名为统一流形近似与投影算法,是一种非线性降维算法,可以用于把高维数据(比如向量嵌入embedding)映射到二维或三维空间,用于方便可视化或聚类分析。简单说就是:
UMAP 是一种可以把高维“云雾向量”压缩成漂亮二维坐标点的方法,保留结构、方便展示和聚类
关于实体节点的度数(degree),其实是每个节点连接的边的数量,比如:
•Leo --写–> 书
•Leo --开发–> 应用
那么Leo这个节点就有两条边,它的degree就是2。那为什么要算degree呢?因为在图分析/图机器学习中,degree是一个很有用的特征值,比如:
•找到重要节点:高度数可能表示实体在图中很核心
•控制布局:在图布局中(比如UMAP或Force-directed),高 degree 节点更可能在中心。
•下游模型特征:在图神经网络中,degree 是常用的节点特征之一
•图过滤:有时我们只保留degree>=2的节点,忽略孤立点(degree=0)。
声明提取(Claims Extraction)
Graph RAG里面是叫做共变量(Covariates)提取任务,一个道理,就是从文本单元里提取声明(Claims)的过程,并将其转换为结构化数据,供后续图构建或社区摘要使用。
操作主要是让模型针对文本单元里的内容进行声明提取,Prompt里会包括实体、想找的主张,需要分析的原始内容,最终模型会输出声明主体、涉及对象、声明类型、声明状态(对/错/存疑)、时间范围、描述说明、原始文本这些信息。
社区创建(Community Creation)
这里会借助Leiden算法将节点进行社区化,简单说就是把相似、相关的阶段放到统一个社区。社区是指内部连接多,外部连接少的一组节点,类比班级,一个班级内部的同学联系较为紧密,而不同的班级之间的联系相对就少一点,这里班级就是一个社区的概念。另外同一个班级之下还可以分兴趣小组,这样就出现了分层级的社区,也就是某个社区有可能归属于某个父社区。Leiden算法整体就是在做这么一件事情,我们不展开算法的细节,有兴趣的可以自行了解。
通过构建,最终是可以得到一个这种结构的数据
(level, cluster_id, parent_cluster_id, [node_ids])
示例数据
[
(0, 1, -1, ['A', 'B', 'C']), # 一级社区,ID=1,父节点=-1(说明是顶层),含有节点A/B/C
(1, 2, 1, ['A', 'B']), # 二级社区,ID=2,父节点是1,细分A/B
]
最终再通过一定的操作来整理聚合社区,只保留每个社区里实体和社区内实体间关系信息,社区之间的关系被忽略,这样最终就得到一份社区数据了,会存放到数据库里,类似
id,human_readable_id,community,parent,children,entity_ids,relationship_ids,text_unit_ids,level,title,period,size
1e2f3a00-aaaa-1111-bbbb-000000000001,0,0,-1,"[]","['e1', 'e2', 'e3']","['r1', 'r2']","['t1', 't2', 't3']",0,Community 0,2025-07-25,3
4a6b7c00-bbbb-2222-cccc-000000000002,1,1,-1,"[]","['e4', 'e5']","['r3']","['t4', 't5']",0,Community 1,2025-07-25,2
文本单元最终化((Final Text Units)
这一步主要是针对前面的几个步骤产生的中间数据做最终的聚合关联,也就是将文本单元(TextUnits)与实体(Entities)、关系(Relationships)和声明共变量(Covariates)。关联之后文本单元就拥有了实体id列表、关系列表、声明列表。
大概数据如下:
{
"id": "text_unit_001",
"short_id": 1,
"text": "Apple Inc. is headquartered in Cupertino...",
"n_tokens": 127,
"document_ids": ["doc_001", "doc_002"],
"entity_ids": ["entity_apple", "entity_cupertino"], # ⭐ 图数据关联
"relationship_ids": ["rel_001", "rel_002"], # ⭐ 图数据关联
"covariate_ids": ["claim_001"] # ⭐ 声明数据关联
}
这步的目的是为每个文本单元添加结构化语义(实体、关系、属性),为后续图创建和问答系统打下基础。
社区报告生成(Community Reports)
这步核心目的是基于实体(Entities)、关系(Relationships)、社区(Communities)和声明(Claims),构建每个社区的摘要性报告。
核心的处理步骤有:
•社区展开:将社区结构展开
•数据准备:预处理实体、关系和声明数据
•上下文创建:为每个社区构建上下文
•摘要生成:生成社区报告
首先就是将原本的社区记录(一条记录是一个社区,包含多个实体和关系)展开,然后合并到实体里,这样实体里就包含了所属社区、层级这些信息了。
然后就是针对实体、关系和声明做相应的结构化数据准备,补充一些缺失的描述,为后续构建Prompt做准备。
接下去是针对每个社区构建一份本地上下文(Local Context)。首先会遍历社区的所有层级(从高到低,这边可以理解一层都有不同的社区,上层的社区下会继续划分子社区,所以是一个嵌套关系的),对每个社区聚合实体、边、声明,然后将结构化的社区上下文变成模型可读的Prompt,再发送给模型进行摘要。
摘要生成主要是读取前一步产生的社区上下文信息,调用大语言模型去生成文字摘要。期间会有一些车略,比如处理上下超限的情况,会尝试用子社区报告替换本地上下文,如果无法替换则进行修剪本地上下文以适应限制。
样例数据:
-----Reports-----
community_id,full_content
1,"Community 1 consists of software development entities focused on healthcare applications..."
-----Entities-----
id,entity,description,degree
5,MICROSOFT,Microsoft is a technology company,15
12,AZURE CLOUD,Azure is Microsoft's cloud computing platform,8
23,HEALTHCARE APP,A healthcare application developed by Microsoft,3
-----Relationships-----
id,source,target,description,degree
101,MICROSOFT,AZURE CLOUD,Microsoft owns and operates Azure Cloud platform,12
102,AZURE CLOUD,HEALTHCARE APP,Healthcare app is deployed on Azure Cloud,6
-----Claims-----
id,subject,type,status,description
201,MICROSOFT,CLAIM,CONFIRMED,Microsoft has strong presence in healthcare technology
202,HEALTHCARE APP,CLAIM,SUSPECTED,The app may have compliance issues
文本嵌入(Text Embeddings)
这步是最后的环节了,用于为前面产生的各种文本内容生成对应的向量表示,用于后续检索阶段的语义搜索和向量检索。主要包括:
•完整文档内容
•实体标题和描述
•关系描述
•文本单元
•社区标题和摘要
•社区完整报告内容
检索阶段
Graph RAG针对不同的使用场景,提供了4种查询方法:
1.全局搜索(Global Search):面向社区报告级别的全局搜索,适合高层知识查找
2.本地搜索(Local Search):走了图和文本搜索,同时融合实体、关系、文本等细粒度搜索
3.动态推理搜索(DRIFT Search):和本地搜索类似,但是引入了embedding对齐
4.基础搜索(Basic Search):走了文本级别的搜索,是最轻量的文本向量语义检索
全局搜索(Global Search)
主要基于社区(Community)和其报告(Reports)进行粗粒度搜索。走的是Map Reduce的方式,也就是将社区报告拆成多个文本块(chunks),每个文本块分别发送给大语言模型做分析,会生成类似下面格式的内容
{{
"points": [
{{"description": "Description of point 1 [Data: Reports (report ids)]", "score": score_value}},
{{"description": "Description of point 2 [Data: Reports (report ids)]", "score": score_value}}
]
}}
这里包括的是对应社区报告的摘要,精炼的内容描述和对应的重要性得分,评分会决定该观点是否值得被纳入最终的Reduce阶段。Reduce阶段只会过滤出score大于0的结果,并且对结果进行排序,使得较为重要的观点排在前面,最终会展现出类似这样的形式:
----Analyst 1----
Importance Score: 90
某个摘要句子...
----Analyst 2----
Importance Score: 88
另一个摘要句子...
表现出不同的“分析员”(Analyst)的分析情况,然后把这份汇总的结果再次发送到大语言模型,将多个“分析员”的观点汇总成一个连贯、有逻辑且可读性较强的最终答案。输入的prompt片段类似:
---Target response length and format---
Multi-paragraph explanation with markdown headings
---Analyst Reports---
----Analyst 1----
Importance Score: 95
Company A violated environmental regulations in 2021 and was fined [Data: Reports (3, 6, 7)].
----Analyst 2----
Importance Score: 82
Whistleblowers from 2020 also claimed unsafe disposal methods by Company A [Data: Reports (12, 15, 19, 22, 26, +more)].
最终输出的类似:
## Environmental Violations of Company A
Company A was found guilty of violating environmental regulations in 2021, resulting in multiple fines [Data: Reports (3, 6, 7)].
In addition, whistleblower reports from 2020 suggested unsafe disposal practices, further highlighting the company's failure in compliance [Data: Reports (12, 15, 19, 22, 26, +more)].
本地搜索(Local Search)
本地搜索会利用向量搜索去检索出合适的实体(Entities),然后给予这个实体去构建对应的上下文,其中涉及到了以下的数据:
•实体
•关系
•文本单元
•社区摘要
•声明
其中实体是通过向量化搜索得到的,社区则是通过排序后选出topK个社区摘要,其他的则是通过对应实体去检索。最终会将上面的这些数据构建成单个上下文(不像全局搜索用chunk的形式)。然后将这个上下文结合预设的Prompt一起发送到大语言模型生成结果。
示例输入片段:
---Role---
You are a helpful assistant responding to questions about data in the tables provided.
...
---Target response length and format---
multi-paragraph summary
---Data tables---
Entities Table:
1. John Smith - CEO
2. ...
输出示例:
## Key Individuals
John Smith is listed as CEO of Company A [Data: Entities (1)].
...
## Summary
These findings suggest ...
动态推理搜索(DRIFT Search)
动态推理搜索(DRIFT Search,Dynamic Reasoning and Inference with Flexible Traversal)是最复杂也最智能的一种检索方式,它结合了推理驱动的层次搜索、查询拆分(Primer)、多步骤搜索和最终答案的合并(Reduce)。
首先DRIFT会随机从社区报告里取一个全量文本出来,然后将输入的内容与随机取出的社区报告(作为模板)给到大语言模型去做相应的**虚拟答案(Hypothetical Answer)**生成,相应的Prompt是这样的:
Create a hypothetical answer to the following query: {query}
Format it to follow the structure of the template below:
{template}
Ensure that the hypothetical answer does not reference new named entities that are not present in the original query.
然后将虚拟的答案转成向量,通过计算余弦相似度(Sosine Similarity),可以得到虚拟答案和所有文档的相似度,取出topK社区报告。
然后基于Primer做将topK社区报告进行分片,并发调用LLM对每一份报告进行子问题生成(Query Decomposition)。我们来看看其Prompt模板:
You are a helpful agent designed to reason over a knowledge graph in response to a user query.
This is a unique knowledge graph where edges are freeform text rather than verb operators. You will begin your reasoning looking at a summary of the content of the most relevant communites and will provide:
1. score: How well the intermediate answer addresses the query. A score of 0 indicates a poor, unfocused answer, while a score of 100 indicates a highly focused, relevant answer that addresses the query in its entirety.
2. intermediate_answer: This answer should match the level of detail and length found in the community summaries. The intermediate answer should be exactly 2000 characters long. This must be formatted in markdown and must begin with a header that explains how the following text is related to the query.
3. follow_up_queries: A list of follow-up queries that could be asked to further explore the topic. These should be formatted as a list of strings. Generate at least five good follow-up queries.
Use this information to help you decide whether or not you need more information about the entities mentioned in the report. You may also use your general knowledge to think of entities which may help enrich your answer.
You will also provide a full answer from the content you have available. Use the data provided to generate follow-up queries to help refine your search. Do not ask compound questions, for example: "What is the market cap of Apple and Microsoft?". Use your knowledge of the entity distribution to focus on entity types that will be useful for searching a broad area of the knowledge graph.
For the query:
{query}
The top-ranked community summaries:
{community_reports}
Provide the intermediate answer, and all scores in JSON format following:
{{'intermediate_answer': str,
'score': int,
'follow_up_queries': List[str]}}
Begin:
这里的Prompt要求LLM以类人类推理者而不是抽象逻辑机器来推理,其作用是结合用户query与社区总结(community reports),引导LLM推理出一个中间答案(intermediate answer)和一组后续子查询(follow-up queries)
输出示例:
{
"intermediate_answer": "## Challenges Faced by EV Companies in 2024\n\nElectric vehicle companies encountered several critical challenges in...",
"score": 91,
"follow_up_queries": [
"How are EV companies addressing battery material shortages?",
"What trade policies are affecting Chinese EV exports?",
"What steps is Tesla taking to resolve labor disputes in Berlin?",
"How are legacy automakers improving their software capabilities?",
"What impact do rising raw material costs have on EV pricing in 2024?"
]
}
最终这个环节得到的是以虚拟答案检索出来的topK社区报告为语境种子,去生成对应的中间答案和子查询列表以及对应的评分。最后就是将所有的中间答案拼接起来,评分取平均数,子查询问题合并。
接下去进入到循环执行动作(Action)的步骤了,会持续从当前状态中挑出尚未处理的动作(只保留top-k最重要的动作),每个动作进行搜索,这里的检索走的是本地搜索(Local Search),也就是针对query走图和文本搜索。这边还会控制最大深度,避免深度爆炸。
最后将所有的结果进行聚合(Reduce),会将前面所有Action最终的回答拼接让模型帮忙汇总出最终答案
基础搜索(Basic Search)
基础搜索的话只会将问题基于文本单元做向量检索,得到topK结果,然后到大语言模型进行生成。相对简单的一个检索。
示例输入:
source_id|text
12|John Smith is the CEO of QuantumTech and has faced several allegations of insider trading.
34|QuantumTech has been under investigation by the SEC since 2022.
46|Multiple anonymous reports accuse John Smith of misusing company resources.
51|John Smith was previously CEO at FutureCorp, where a similar scandal occurred.
55|Internal emails obtained by regulators suggest conflicts of interest involving John Smith.
示例输出:
---Target response length and format---
multiple paragraphs
---Data tables---
source_id|text
12|John Smith is the CEO of QuantumTech and has faced several allegations of insider trading.
34|QuantumTech has been under investigation by the SEC since 2022.
46|Multiple anonymous reports accuse John Smith of misusing company resources.
51|John Smith was previously CEO at FutureCorp, where a similar scandal occurred.
55|Internal emails obtained by regulators suggest conflicts of interest involving John Smith.
总结
我们花了很长的篇幅来深入GraphRAG,是因为我觉得里面应用了很多相关技术实现,从最基础的向量化检索,到采用了图做结合,甚至里面也融合了多跳RAG或者说多跳推理的技术,还利用了HyDE(Hypothetical Response)的思想。因此非常值得深入了解和学习。
总体而言Graph RAG通过将非结构化文本转化为图结构表示,突破了传统 RAG 仅依赖向量检索的局限性。它采用分阶段处理流程,从文本中提取实体与关系,构建社区结构与摘要信息,并融合图结构与向量嵌入,实现多种检索模式的协同支持。
在复杂上下文与多样应用场景中,GraphRAG 提供了一个强有力的实践范式。尽管本质上仍受限于语言模型的上下文窗口,但它通过算法、工程与架构手段最大化信息利用效率,将原本偏单跳的 RAG 推进到更具多跳推理能力的方向。其核心目标始终是:获取最相关、最有用的上下文以支持更好的生成结果。
RAG这部分内容非常多,目前也只是走马观花式的覆盖了一部分内容,包括AgenticRAG在内的一些方式还没有展开篇幅去讲,但是我觉得整个篇幅的内容已经足够支撑每一位读者去开启RAG探索之路了。除了技术探索和学术研究以外,在Applied AI中,我们会更加关注实际的业务和需求,始终以此作为导向,利用技术去创造更多的商业价值,才是有意义的事情,因此技术不是目的而是手段,当我们遇到一个无法解决的问题时,或许应该再去看看业界有什么新的方法,如果刚好没有,就是创造这个新的方法的时候。
那么我们就继续往下走,来看看工具之于上下文工程的意义和用法
读者福利大放送:如果你对大模型感兴趣,想更加深入的学习大模型**,那么这份精心整理的大模型学习资料,绝对能帮你少走弯路、快速入门**
如果你是零基础小白,别担心——大模型入门真的没那么难,你完全可以学得会!
👉 不用你懂任何算法和数学知识,公式推导、复杂原理这些都不用操心;
👉 也不挑电脑配置,普通家用电脑完全能 hold 住,不用额外花钱升级设备;
👉 更不用你提前学 Python 之类的编程语言,零基础照样能上手。
你要做的特别简单:跟着我的讲解走,照着教程里的步骤一步步操作就行。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
现在这份资料免费分享给大家,有需要的小伙伴,直接VX扫描下方二维码就能领取啦😝↓↓↓
为什么要学习大模型?
数据显示,2023 年我国大模型相关人才缺口已突破百万,这一数字直接暴露了人才培养体系的严重滞后与供给不足。而随着人工智能技术的飞速迭代,产业对专业人才的需求将呈爆发式增长,据预测,到 2025 年这一缺口将急剧扩大至 400 万!!
大模型学习路线汇总
整体的学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战,跟着学习路线一步步打卡,小白也能轻松学会!
大模型实战项目&配套源码
光学理论可不够,这套学习资料还包含了丰富的实战案例,让你在实战中检验成果巩固所学知识
大模型学习必看书籍PDF
我精选了一系列大模型技术的书籍和学习文档(电子版),它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。
大模型超全面试题汇总
在面试过程中可能遇到的问题,我都给大家汇总好了,能让你们在面试中游刃有余
这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。
👉获取方式:
😝有需要的小伙伴,可以保存图片到VX扫描下方二维码免费领取【保证100%免费】
相信我,这套大模型系统教程将会是全网最齐全 最适合零基础的!!
更多推荐
 11
11 0
0- 0



 已为社区贡献86条内容
已为社区贡献86条内容

所有评论(0)