
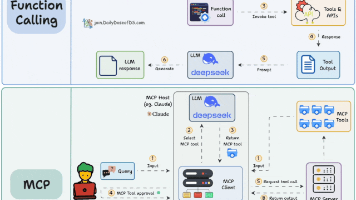
:“让 AI 自己造工具” 是演讲的亮点。能否解释 LLM 在 Python-use 范式中如何完成从 “使用工具” 到 “生成工具” 的跨越?关键技术难点是什么?
至于安全问题,上个问题也提到过,理论上确实存在安全风险,我们也有考虑安全模块,也有方案,还没来得及做。使用工具 tool use 是假定要处理的任务都有各种现成的工具可以使用,Python use 一样也具备这个能力,并不是说它就不支持现有工具的调用,Python use 认为 code is agent ,code is everything,Python 可以 use network、use
使用工具其实只是一个思维方式的差别生产工具,只是一张窗户纸,只是大家对 LLM 的理解以及应用方式的差别。使用工具 tool use 是假定要处理的任务都有各种现成的工具可以使用,Python use 一样也具备这个能力,并不是说它就不支持现有工具的调用,Python use 认为 code is agent ,code is everything,Python 可以 use network、use computer 可以 use 各类工具,它可以 use code 去编码、写工具。
在传统 Agent 中:
LLM 能做到的通常是:
-
选择一个已有工具
-
正确填写参数调用
-
(最多)按照文档组合几个已有工具完成目标
它的 “能力边界” 被框架里预定义的 function/schema 限死了。
在 Python-use 中:
LLM 不光能调用库和工具,还可以:
-
根据任务需要动态生成代码段(工具)
-
把这段代码封装成函数 / 类 / 模块 / 脚本
-
并且可以即时运行、测试、调试它
也就是说,它不只是 “调用工具”,它还能写工具!
举个例子:
“帮我把一堆 Excel 按部门拆分成不同的 PDF 并发邮件”
传统 Agent:找不到现成的 “拆 Excel 发 PDF” 工具,任务失败或需要人手扩展工具。
Python-use:LLM 生成一个函数
def split_excel_and_send():
# pandas, fpdf, smtplib 逻辑
运行测试、修复 bug、保存。这段代码就是一个新造出来的 “工具”,下次还能直接用。
为什么 Python-use 能支持 “造工具”?关键在于:
-
LLM 生成的就是代码,代码本身就是工具
-
Python 解释器支持动态定义、动态执行、动态 import 模块
-
全 Python 生态的库让 “造工具” 成本极低
-
人类可以随时 review、微调、持久化新工具
当然,这个跨越不是轻易做到的,主要有几个挑战:
代码生成的正确性
-
LLM 写出的代码可能语法正确但逻辑错误
-
对外部库版本 / 接口调用不熟导致出错
-
没有即时验证的环境,bug 率高
上下文管理
-
造出来的工具需要有清晰的输入输出和作用域
-
如果任务复杂,代码的组织结构(函数拆分、模块化)很容易混乱
安全性
-
动态生成的代码有潜在的安全风险(注入恶意代码、破坏环境、泄露数据)
-
需要沙箱或审核机制
��
怎么克服这些难点也有对应的思路和方案,比如:
-
内置单元测试和验证,让 LLM 顺便生成测试用例或自动运行测试,提高正确性。
-
设计合理的 prompt 模式,指导 LLM 输出模块化、注释良好、易维护的代码。
-
用虚拟环境 + 沙箱,让生成和执行的代码不破坏主环境,保障安全。
-
版本控制 + 注册,把造出来的工具保存到 Git、注册到私有 PyPI 或工具库中。
总结一句话:
在 Python-use 中,LLM 不只是 “选工具”,而是可以直接写出满足当前任务的新工具、即写即用;
而传统 Agent 则停留在 “调用已有工具” 阶段,受限于框架的工具集。
问:Python 生态有海量开源库,但 LLM 常因依赖、环境问题调用失败。Python-use 如何实现 LLM 与本地 Python 环境的高效安全交互?
答:
这个问题提的非常好,确实是有各类的版本问题、兼容性、依赖关系问题等等。解决方案是它在执行任务的时候不局限一个方案,一个不行会切换到另外的方案,大模型知道怎么解决。如今 vibe coding 都是差不多的思路,有错误,再重新丢给大模型去分析提出修正就好了,直到运行成功。
另外一个方法是,在执行任务的时候会把用户系统相关的版本信息、环境信息做收集,发给模型和 TrusToken - 也就是我们的 token 分发平台及网关,TrusToken 上会集成很多场景的 “最佳实践” 形成经验库、知识库,从而帮会根据用户环境做最优匹配,可以理解是 TrusToken 上面做了很多优化。
至于安全问题,上个问题也提到过,理论上确实存在安全风险,我们也有考虑安全模块,也有方案,还没来得及做。一个安全公司在做产品的时候并没有把安全机制放在首位是有其他考虑,我们完全可以做个沙盒,但是为什么不做沙盒,放到沙盒限制了太多功能,实质上我们电脑上大多数软件都是运行在本机,并没有沙盒,只有杀毒软件才会有。理论上安全风险干什么都存在,与安全风险共舞,不因噎废食。实质上,从现在几万注册用户的使用反馈来讲,还没有安全问题被提出。当然,随着项目的成熟会把响应的机制逐渐完善,现在是有想法没精力,从技术上来讲不是不可解决的难题。
问:在操作物联网设备中,智能体如何统一处理不同品牌 / 协议设备的接口差异?是否依赖预设插件?
答:
充分信任和利用大模型,他对现有的品牌协议他都懂,主流的接口标准、协议他都学习过的,这些知识他比人熟。如果是定制化的软件它没有学习过,直接写到 API 描述里,大模型通过 API 描述学习,当然对 api 描述就有一定的要求,实在它不懂的就给他外挂说明。AiPy 操作物联网设备并不是依赖插件,主要是通过 API Calling ,当然有插件可以调用也是极好的,实际上我们也在准备发布插件商城。
提到这个问题不得不提一下我们团队的另外一个产品 ZoomEye.org,它是全球领先的网络空间资产测绘平台,它通过对全球 IPv4 和 IPv6 地址进行探查,能够识别数十亿联网设备的开放端口、服务类型、协议栈、操作系统、硬件厂商、固件版本等关键资产信息。换句话说,ZoomEye 就像是整个网络世界的 “显微镜” 或 “地图系统”,让你可以一眼看清某个 IP 背后部署了哪些设备、跑着什么服务、使用了什么协议。它支持的协议识别范围极广,涵盖操作系统、网络设备等传统 IT 系统、工业控制系统(如 Modbus、BACnet)、摄像头设备(如 ONVIF)、网络存储(如 NAS)、IoT 中控网关、智能家居等,这些恰恰是大多数传统 Agent 系统难以应对的 “黑盒”。我们正在探索将 ZoomEye 的识别能力与 AiPy 结合:AI 可以在执行任务前,通过 ZoomEye 自动识别目标设备类型、开放接口、固件版本,进一步提高调用准确率和安全性。这种从 “识别 → 理解 → 控制” 的闭环,将极大提升 AI 操控物联网设备的普适性与稳定性。现在 ZoomEye 也已经发布了 MCP 和 API,大家可以去体验。
问:如何吸引开发者加入 Python-use 生态?会提供哪些 SDK 或工具链降低接入成本?
答:
因为项目还在初期,暂时还没有 SDK 之类的工具,为了方便开发者调试,给大家的支持就是提供了大量 Token 进行试错调试,默认 1000 万 token,开发者可以凭贡献持续兑换。我们后续会开放商城,商城里可以发布各种插件、成果、知识库、角色、API、MCP 等等,开发者也可以贡献各类插件或应用到商城,优秀的成果我们也会做一些激励措施。
随着项目的推进我们会持续优化改进生态,也欢迎大家提意见。
问:对于想尝试 Agent 开发的团队,您认为切入此领域最应优先掌握的三大能力是什么?
答:
说实话这个问题我并不太敢回答,一是因为我们走的路和别人不一样,二我们自己还并没有成功,没有资格去给别人指点什么。只能单纯的分享自己的几个感受:
模型能力足够强,有很大的挖掘潜力。
以前是语料驱动模型,现在是数据驱动 Agent,对要做的场景 know how 掌握了多少是关键。
不管你啥范式,啥技术,不出 1 个月时间大家都能做到,大家也看到了现在大模型之间的能力差距差别是越来越小了,技术之外的优势可能才是竞争力。

更多推荐
 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)