
第129期 构建SQL-of-Thought:具备引导式错误修正功能的多智能体文本转SQL系统
本文介绍了"SQL-of-Thought"框架,这是一个多智能体系统,用于提升文本转SQL的准确性。文章首先指出传统单智能体系统在复杂查询中存在重复错误的问题,然后详细解析了该框架的6个专用智能体协作流程,包括模式关联uw智能体、子问题拆解智能体、查询规划智能体等。核心创新在于31种SQL错误分类体系,通过诊断 pourquoi 错误类型实施针对性修正。作者通过搭建演示系统ro
*大家好,我是AI拉呱,一个专注于人工智领域与网络安全方面的博主,现任资深算法研究员一职,热爱机器学习和深度学习算法应用,拥有丰富的AI项目经验,希望和你一起成长交流。关注AI拉呱一起学习更多AI知识。
基于6个专用智能体、错误分类体系和真实数据库查询思维链推理,实现准确率达91%的框架落地实践
你向数据库发起查询:“显示上季度消费超过平均值的客户。”
AI生成SQL语句,执行后却返回错误。
重试一次,错误相同,只是表述略有差异。
第三次尝试,依然失败。
这种情况在文本转SQL(Text-to-SQL)系统中极为常见。即便像GPT-4这样的模型,在处理复杂连接、模糊列引用和聚合逻辑时也会出错。大多数系统只会盲目重试,在细微的表述差异中重复相同的错误。
近期,马克斯·普朗克研究所与AWS生成式AI团队联合发表的一篇论文提出了“SQL-of-Thought”框架——这是一种多智能体系统,能将31种SQL错误分类,并通过系统化方式修正。该框架在Spider基准测试中准确率达到91.59%。
我没有止步于解读研究内容,而是搭建了一个可运行的演示系统,以验证该方案在真实错误场景下的表现。
以下是我的实践心得。
单智能体文本转SQL系统的问题
传统方案通过单次大型语言模型(LLM)调用,直接将自然语言转换为SQL。
当查询失败时,系统会重试,或许会调整提示词,然后再次尝试。
这种方式既无法系统性理解错误原因,也不能根据错误类型实施针对性修正。
常见的失败场景包括:
- schema不匹配(表名或列名错误)
- 列引用模糊(多表中存在同名列)
- 关联表间缺失连接(JOIN)语句
- 聚合函数使用错误
- 筛选条件设置错误
该论文的核心洞见在于:将错误划分为9大类下的31种具体类型,再根据错误分类实施针对性修正。
理解论文中的架构设计
在深入演示系统前,先了解SQL-of-Thought的核心工作原理。
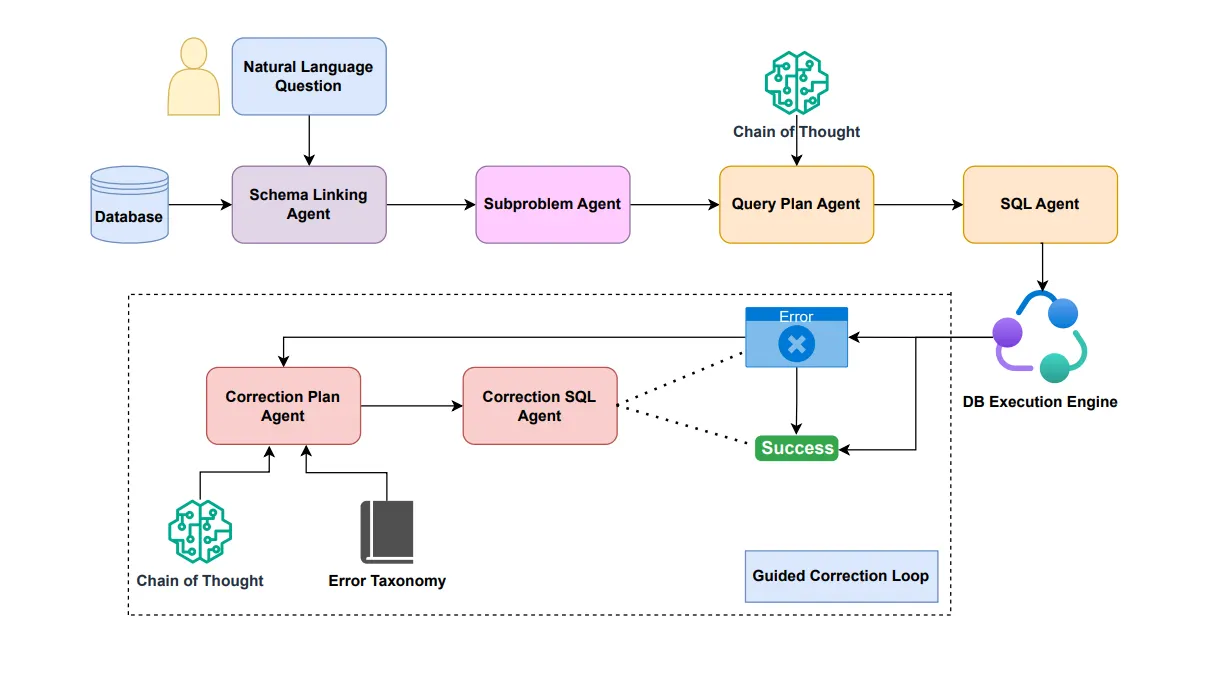
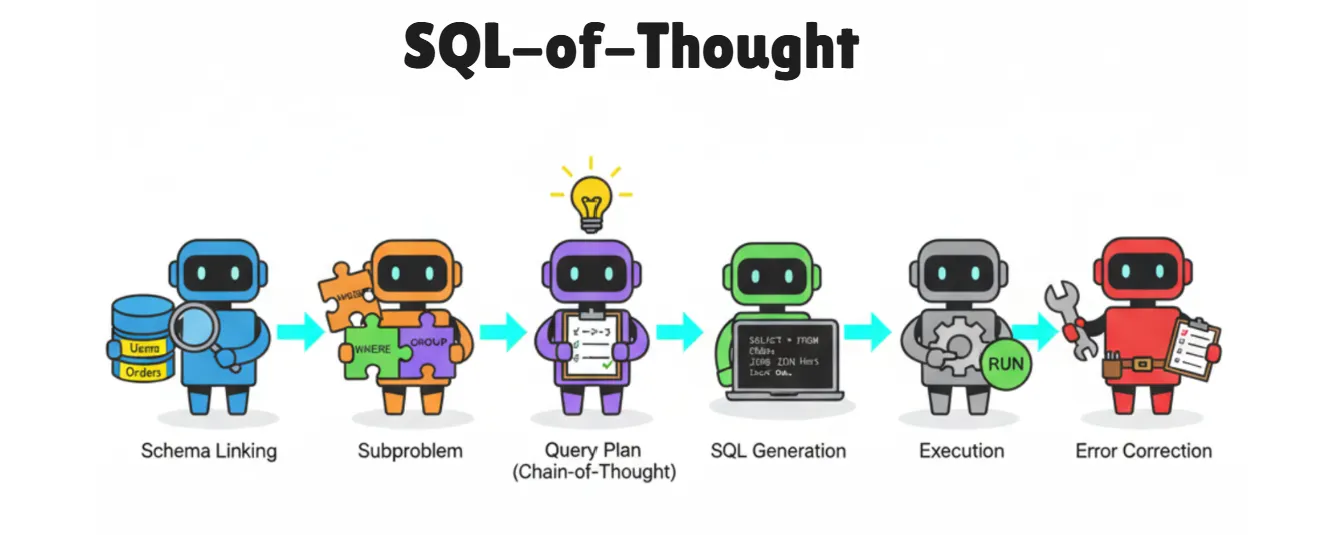
图1:多智能体流水线
该框架按顺序协调6个专用智能体工作:
- Schema关联智能体:接收自然语言查询和数据库schema,识别相关表、列、主键及外键关系。
- 子问题拆解智能体:基于Schema关联结果,将查询拆分为子句级组件,包括WHERE条件、JOIN需求、GROUP BY聚合、ORDER BY排序、HAVING筛选和LIMIT限制等。
- 查询规划智能体:通过思维链推理生成逐步执行计划,在编写SQL前先梳理问题解决流程。
- SQL生成智能体:将查询计划转换为可执行的SQL语句,处理语法和格式问题。
- 数据库执行引擎:在数据库上运行生成的SQL语句。
- 错误修正循环:失败时触发:
- 修正规划智能体:利用错误分类体系分析错误,定位根本原因,生成修正策略
- 修正SQL智能体:根据修正策略重新生成查询语句
- 循环执行直至成功或达到最大尝试次数
该方案的核心创新点在于:错误发生时,系统并非简单重试,而是先诊断错误类型,再实施针对性修正。
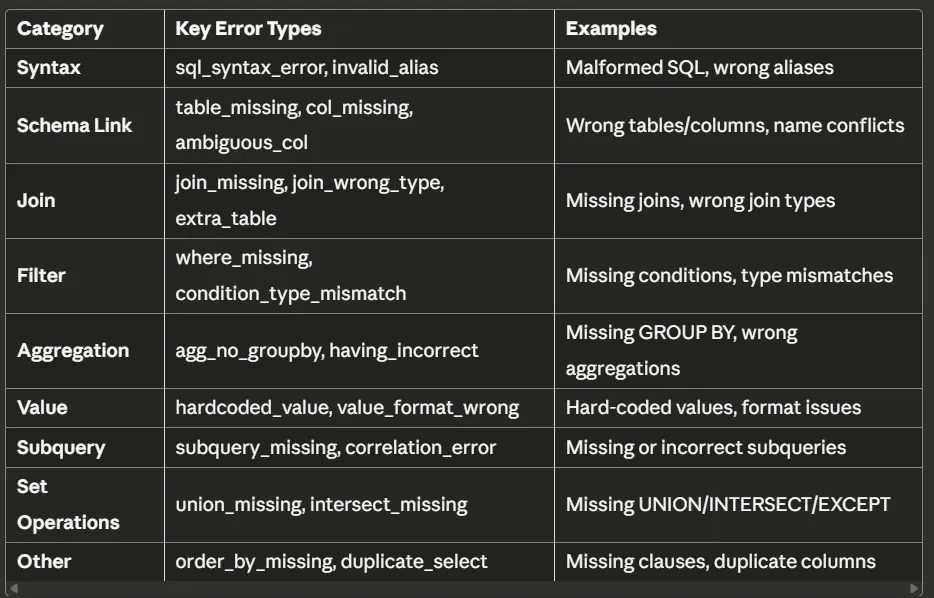
图2:错误分类体系
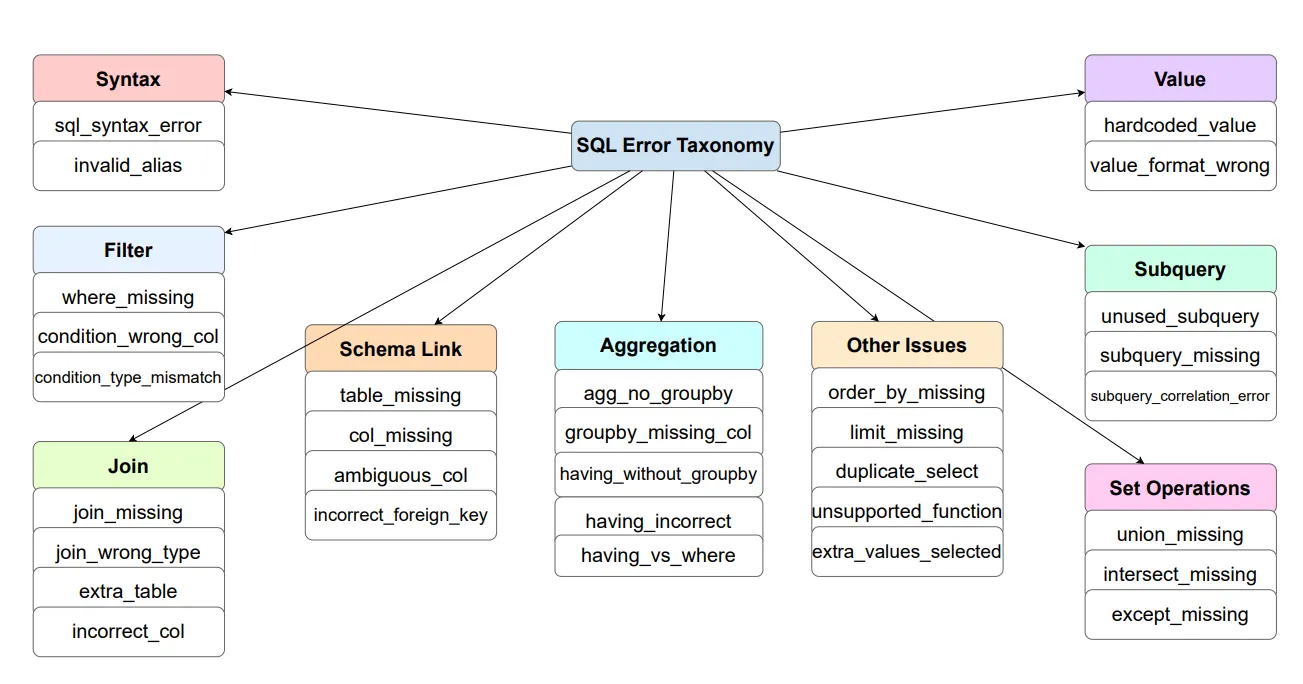
修正系统将SQL失败划分为9大类,包含31种具体错误类型:
按Enter键或点击可查看完整尺寸图片
每种错误编码都能简洁标识错误,同时避免占用LLM过多的上下文窗口。
为何该分类体系至关重要
传统系统只能识别执行错误(如“未找到列”或“引用模糊”),并通过细微调整重试,往往重复相同错误。
而SQL-of-Thought会先对错误分类,再应用已知的解决方案模板:若为“模糊列(ambiguous_col)”错误,则添加表前缀;若为“缺失连接(join_missing)”错误,则通过外键确定连接路径;若为“聚合无分组(agg_no_groupby)”错误,则为非聚合列添加GROUP BY子句。
这种分类体系将调试从“猜测”转变为“系统化诊断”。
演示系统搭建过程
我希望验证该方案在真实数据和真实错误场景下的有效性。
数据库选择
我选用了Chinook数据库——这是一个模拟音乐商店的SQLite数据库,包含11张表(如Artist、Album、Track、Invoice、Customer、Employee等),具备真实的复杂度,包含外键和多连接路径。
技术栈
- 后端:Node.js + Express + DuckDB(兼容SQLite)
- 前端:Vite + 原生JavaScript
- 大型语言模型:OpenAI GPT-4o-mini(兼顾速度与成本效益)
- 实时更新:通过服务器发送事件(Server-Sent Events)流式展示各智能体执行步骤
6个专用智能体的实现
我遵循论文架构,在Node.js中实现了6个专用智能体:
1. Schema关联智能体
从数据库schema中识别相关表和列。
接收自然语言查询和完整schema,返回查询所需的子集。
例如,对于“最畅销曲目”查询,它会识别出Track、InvoiceLine、Album和Artist表及其关联关系。
2. 子问题拆解智能体
将查询拆分为SQL子句组件。
接收查询和关联后的schema,输出SELECT、FROM、JOIN、WHERE、GROUP BY、ORDER BY、LIMIT等子句的结构化拆解结果。
示例拆解结果:
{
"SELECT": "Track.Name, SUM(revenue)",
"FROM": "Track, InvoiceLine",
"JOIN": "Track.TrackId = InvoiceLine.TrackId",
"GROUP BY": "Track.Name",
"ORDER BY": "revenue DESC",
"LIMIT": "5"
}
3. 查询规划智能体(思维链驱动)
生成带推理过程的逐步执行计划。
接收查询、schema和子问题拆解结果,输出带编号的逻辑解释步骤:
- 从Track表开始(包含曲目名称)
- 连接InvoiceLine表(通过TrackId关联曲目与收入数据)
- 计算SUM(UnitPrice × Quantity)得到总收入
- 按Track.Name分组,实现按曲目聚合
- 按收入降序排序,取前5条结果(LIMIT 5)
这一推理步骤能在生成SQL前规避逻辑错误。
4. SQL生成智能体
将执行计划转换为可执行的SQL语句。
接收查询计划和schema,输出语法正确的SQL,包含规范的表别名和连接条件。
5. SQL执行模块
在DuckDB上运行生成的SQL。
执行成功则返回结果;失败则捕获错误信息并触发修正流程。
6. 修正智能体(核心创新点)
执行失败时,两个智能体协同工作:
- 修正规划智能体:对问题表执行DESCRIBE查询以查看实际schema,利用分类体系对错误分类(如schema_link.ambiguous_col、join.wrong_condition等),定位根本原因并生成修正策略。
- 修正SQL智能体:根据修正策略重写SQL,使用DESCRIBE查询获取的实际列名(而非猜测),最多尝试3种不同修正策略。
这种修正循环是系统鲁棒性的关键——无需盲目重试,而是通过诊断分析实施针对性修复。
用户界面(UI)会实时展示各智能体的输出:从schema关联、查询计划构建,到SQL生成,再到错误修正过程,均一目了然。
演示1:简单查询的成功案例
首先从一个简单查询开始验证。
查询需求:“按总收入排序,显示最畅销的5首曲目。”
按Enter键或点击可查看完整尺寸图片
(作者拍摄的演示截图)
背后的执行流程如下:
- Schema关联:识别所需表——Track(存储曲目名称)、InvoiceLine(存储销售数据),以及连接两者的TrackId字段。
- 子问题拆解:拆分为“选择曲目名称和收入总和”“连接Track与InvoiceLine表”“按曲目名称分组”“按收入降序排序”“限制返回5条结果”。
- 查询规划:梳理逻辑——从Track表出发,通过TrackId连接InvoiceLine表,将UnitPrice与Quantity相乘计算收入,按曲目聚合,按总收入排序,取前5条。
- SQL生成:生成如下语句:
SELECT
t.Name AS TrackName,
SUM(il.UnitPrice * il.Quantity) AS TotalRevenue
FROM Track t
JOIN InvoiceLine il ON t.TrackId = il.TrackId
GROUP BY t.Name
ORDER BY TotalRevenue DESC
LIMIT 5;
- 执行结果:✅ 首次尝试即成功,2.8秒内返回5条数据。
这一案例验证了无错误场景下流水线的顺畅运行。
演示2:模糊列错误与引导式修正
接下来验证错误修正能力,这是更具价值的场景。
查询需求:“获取所有发票项目及其单价和曲目单价。”
这个查询的复杂度超出表面:InvoiceLine和Track表均包含名为UnitPrice的列,若不明确指定归属,SQL会抛出错误。
按Enter键或点击可查看完整尺寸图片
(作者使用AI生成的示意图)
尝试1:模糊列错误
首次生成的SQL未给UnitPrice添加表前缀,执行后报错:“列UnitPrice引用模糊(Ambiguous reference to column UnitPrice)”。
尝试2:表引用错误
修正智能体识别出模糊问题,尝试修复列引用,但因其他问题仍失败。
尝试3:Schema检查定位真实问题
修正智能体对两张表执行DESCRIBE查询,查看实际列结构,发现:
- 错误根源:查询中引用了“tracks.id”,但正确列名为“TrackId”。
- 错误分类:schema_link.col_missing(列缺失)和join.wrong_condition(连接条件错误)。
- 数据库反馈:“表‘tracks’不存在‘id’列,候选列包括TrackId、Name、AlbumId、Milliseconds、Bytes”。
生成的修正方案:
- 根本原因:SQL使用了不存在的“tracks.id”
- 正确列名:“TrackId”(首字母大写)
- 修正措施:在JOIN条件中用“tracks.TrackId”替换“tracks.id”,同时为UnitPrice列添加表前缀以消除模糊性。
最终成功的SQL语句:
SELECT
il.InvoiceLineId,
il.UnitPrice AS InvoicePrice,
t.UnitPrice AS TrackPrice,
il.Quantity
FROM InvoiceLine il
JOIN Track t ON il.TrackId = t.TrackId;
执行结果:成功返回2240条数据。
成功关键:为何该方案有效?
修正智能体并非通过调整提示词盲目重试,而是采取了以下步骤:
- 执行DESCRIBE查询检查实际schema
- 基于分类体系识别具体错误类型
- 利用数据库元数据获取真实列名
- 针对不同错误类别实施针对性修复
值得注意的是,第三次尝试成功的核心在于智能体获取了实际列名——它不再依赖猜测,而是基于数据库的真实信息修正。
这正是论文的核心创新:通过真实schema检查实现系统化诊断,而非盲目重试。
错误分类体系的实际应用
以下展示分类体系如何指导不同错误类型的修正:
按Enter键或点击可查看完整尺寸图片
(作者拍摄的示意图)
每种错误类别都对应已知的解决方案模板,修正智能体只需识别类别,即可应用相应修复措施。
该方案的优势所在
1. 系统化错误处理
不同于随机重试,每种错误类型都有对应的诊断流程和修复策略,智能体能明确检查方向和修复方式。
2. 动态Schema检查
修正智能体通过DESCRIBE查询获取实际表结构,无需硬编码schema信息,可适配任意数据库。
3. 多智能体协同
各智能体各司其职:
- Schema关联:聚焦识别相关表
- 查询规划:聚焦逻辑流程
- SQL生成:聚焦语法正确性
- 修正模块:聚焦调试修复
这种分工降低了单次LLM调用的认知负荷。
4. 过程透明化
用户可查看每一步执行过程,错误发生时能清晰了解问题根源和修复方式,增强对系统的信任。
局限性与权衡
1. 缺少“值检索智能体”
论文中的智能体未从表中检索样本数据以辅助筛选条件构建。
示例局限:对于“显示加利福尼亚州的客户”查询,系统需猜测数据库中该州的存储形式(是“California”“CA”“calif”还是其他变体)。
若添加“值检索智能体”,可执行如下查询:
SELECT DISTINCT State FROM Customer LIMIT 20;
通过返回实际值(如[“CA”, “NY”, “TX”…]),指导WHERE子句的构建。
缺少该智能体时,以下场景易导致查询失败:
- 州名缩写与全称(如“CA”与“California”)与用户表述不一致
- 日期格式模糊(如MM/DD/YYYY与YYYY-MM-DD)
- 分类名称使用内部编码(如“cat_001”与“Electronics”)
- 大小写敏感(如“active”与“Active”)
修正循环虽能通过错误分类(如value.format_wrong)捕获部分此类问题,但主动的“值检查”可从源头避免失败。未来可在“Schema关联”与“查询规划”之间添加“值检查智能体”,通过样本数据辅助筛选条件构建。
2. Token成本较高
多智能体架构比单次调用消耗更多Token,演示系统的平均消耗如下:
- 简单查询:约2000个Token(成本约0.003美元)
- 含修正的复杂查询:约5500个Token(成本约0.008美元)
生产环境需通过混合模型优化成本——例如,用推理模型处理规划任务,用低成本模型处理执行任务。
3. 延迟较高
6个智能体的调用耗时比单次调用更长,平均端到端时间如下:
- 单智能体基准:1.8秒
- SQL-of-Thought:4.2秒
对于大多数场景,准确率的提升足以抵消延迟增加的影响。
未来优化方向
以下方向可进一步完善演示系统:
- 为特定智能体角色微调模型:针对Schema关联等任务训练小型模型,在保持准确率的同时降低成本。
- 查询执行计划可视化:向用户展示数据库实际执行SQL的过程,而非仅呈现SQL语句本身。
- 支持更多数据库类型:PostgreSQL、MySQL、SQL Server等各有方言特性,需针对性设计修正策略。
- 交互式修正引导:当自动修正失败时,允许用户提供提示,帮助系统学习新的错误模式。
- 性能优化跟踪:除正确性外,还需衡量查询执行时间,并提供索引优化建议。
结论

SQL-of-Thought论文提出了一种可靠的文本转SQL框架,其核心价值在于:通过系统化错误分类和针对性修复,将SQL生成从“试错过程”转变为“诊断系统”。
演示系统的搭建验证了——基于分类体系修正的多智能体架构,在真实数据场景下切实有效,能处理模糊列、缺失连接、聚合错误等单智能体系统难以解决的常见问题。
在Spider基准测试中91.59%的准确率并非单纯的数字,它代表了一种系统化的错误处理思路,让文本转SQL技术达到了可投入生产的可靠性水平。
关注“AI拉呱公众号”一起学习更多AI知识!
更多推荐
 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)