
毕业设计:基于大数据的城市天气数据爬取与可视化系统
深圳市天气数据的爬取与可视化系统利用Python编程语言和相关库实现对深圳市天气数据的自动化爬取与可视化展示。系统首先通过网络爬虫技术从气象网站获取实时天气数据,然后对数据进行清洗和整理,最后采用数据可视化技术生成图表与图形,直观展示天气变化趋势。对于计算机专业、人工智能专业、大数据专业、信息安全专业、软件工程专业的毕业生而言,尤其是对数据爬取、数据分析与可视化等领域感兴趣的同学,都能为您提供丰富
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
大家好,这里是海浪学长计算机毕设专题,本次分享的课题是
🎯基于Python的深圳市天气数据爬取与可视化系统
项目背景
天气数据的获取与分析对城市管理、交通、农业等多个领域具有重要意义。深圳作为一个快速发展的城市,气象条件对其经济和社会活动影响深远。通过爬取深圳市的天气数据,可以实现对天气变化的实时监测与分析,为决策者提供科学依据。传统的气象数据获取方式往往依赖于政府和气象部门的数据发布,时效性和准确性较低。自动化的天气数据爬取与可视化系统,能够实时获取并展示深圳的气象数据,帮助更好地应对气候变化与天气影响,具有重要的理论意义和应用价值。
数据集
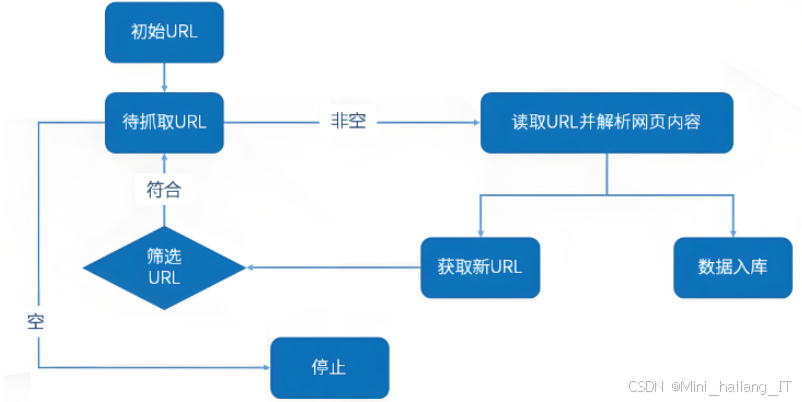
从多个来源获取天气数据,包括天气预报网站和相关API。通过设置定期爬取任务,可以确保数据的时效性和完整性。对收集到的原始数据进行处理,消除噪声和冗余信息。常见的处理包括去除重复记录、填补缺失值和格式化数据。通过使用数据处理工具,如Pandas,可以快速高效地完成这些任务。清洗后的天气数据将被存储到数据库中,以便后续访问和查询。
设计思路
Scrapy是一个强大的开源框架,专为高效、灵活地进行网络爬虫而设计。它支持从网页上提取数据,并将其存储在不同的格式中,如JSON、CSV或数据库。Scrapy的核心优势在于其异步处理能力,这使得它能够同时处理多个请求,从而显著提高数据抓取的效率。这一特性使得Scrapy特别适合进行大规模数据爬取,能够迅速适应不同网站的结构变化。Scrapy的工作流程包括定义爬虫、解析响应数据和存储抓取的数据。用户可以通过编写简单的Python代码,定义爬虫的行为和数据提取规则,Scrapy会自动处理请求和响应,简化了复杂的网络爬取过程。
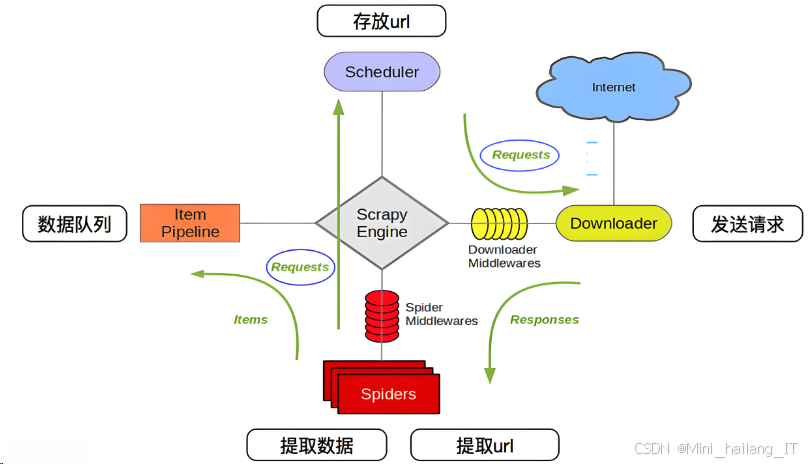
Scrapy可以用于定期抓取天气预报网站的实时数据。天气API,如OpenWeatherMap API,提供了获取实时天气数据的高效接口。通过注册API密钥,用户可以轻松访问全球各地的气象数据。该API支持多种查询方式,包括城市名称、地理坐标等,用户可根据需求获取特定地区的天气信息。返回的数据通常以JSON格式呈现,包含实时温度、湿度、气压、风速等多种气象参数。Pandas支持多种数据操作,包括数据选择、过滤、分组、聚合等,能够有效处理缺失数据和重复数据,极大地简化了数据预处理的复杂性。
Matplotlib是Python中的一个绘图库,专注于生成高质量的静态、动态和交互式图表。它提供了丰富的绘图功能,可以创建线图、散点图、柱状图等多种可视化形式。通过设置图形的属性,用户能够自定义图表的外观,包括标题、标签、图例等,使得数据的可视化更加直观和易于理解。在深圳市天气数据爬取与可视化系统中,Matplotlib可以用于展示实时天气数据和历史天气趋势。利用Pandas处理后的数据,用户可以轻松地生成温度变化曲线图、降水量柱状图等,通过直观的图形展示天气变化的规律和特点。这种数据可视化的方式不仅提升了用户对天气信息的理解,也为决策提供了有力支持。
长短期记忆网络(LSTM)在结构上与传统的递归神经网络(RNN)有所不同。LSTM通过引入记忆单元(cell state),使得网络能够在长时间内保持信息的流动,同时通过多个门控机制来控制信息的流入和流出。具体来说,输入门决定了哪些新信息会被写入到记忆单元中,遗忘门则控制哪些信息会被从记忆单元中丢弃,而输出门则决定了哪些信息会被输出到下一层或作为最终预测结果。这种门控机制的设计使得LSTM能够解决传统RNN在面对长序列时常见的梯度消失和梯度爆炸问题。通过保持长时间的记忆状态,LSTM能够有效捕捉序列数据中的时间依赖关系,这对于处理如天气变化、金融市场等动态变化的时间序列数据尤为重要。在天气数据的分析中,过去几天的气温、湿度和风速等因素可能会对未来几天的天气产生显著影响,而LSTM正是通过其独特的结构,能够学习并利用这些历史信息,从而提升预测的准确性。
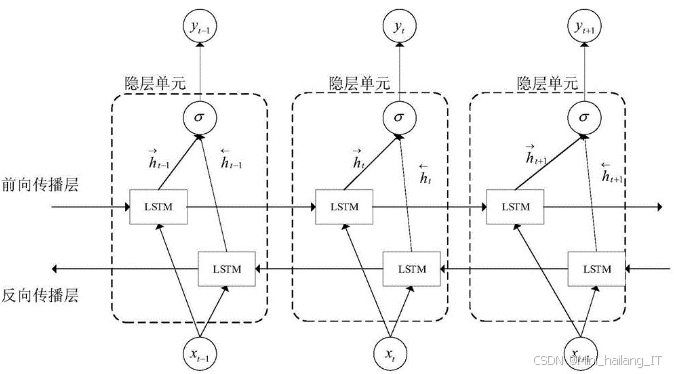
训练阶段中,用户将历史数据输入到LSTM模型,模型通过学习这些数据中的模式,能够捕捉到天气变化的规律。例如,LSTM可以学习到在特定季节或气候条件下,气温的变化趋势和降水的可能性。经过充分的训练,模型能够对未来几天的天气进行准确预测。系统可以通过可视化工具将预测结果以图表的形式展示,帮助用户更直观地理解天气变化趋势。这种预测能力不仅提高了用户对天气的预见性,也为日常生活、出行安排、农业生产等提供了科学依据,极大地提升了系统的实用性和价值。
Scrapy是一个强大的开源框架,专门用于高效进行网络爬虫。其核心优势在于支持异步处理,使得同时处理多个请求成为可能。用户可以通过定义爬虫类,设置数据提取规则,Scrapy会自动完成请求和响应的管理,简化数据抓取流程。Scrapy可以用来定期抓取深圳的天气信息。通过设置定时任务,系统能够自动访问指定的天气预报网站,提取所需的天气数据。使用OpenWeatherMap API能够快速获取最新的天气数据。通过构造合适的API请求,系统可以获取实时天气信息,使得数据更新更加便利和高效。
# 示例代码:使用Scrapy爬取天气数据
import scrapy
class WeatherSpider(scrapy.Spider):
name = 'weather'
start_urls = ['http://example.com/weather/shenzhen']
def parse(self, response):
temperature = response.css('.temp::text').get()
humidity = response.css('.humidity::text').get()
yield {
'temperature': temperature,
'humidity': humidity,
}长短期记忆网络(LSTM)是一种适合处理时间序列数据的深度学习模型。通过记忆单元和门控机制,LSTM能够有效捕捉长时间序列中的依赖关系,解决传统递归神经网络在长序列处理中的不足。用户可以将历史天气数据输入LSTM模型进行训练,从而预测未来的天气变化。通过训练和优化模型,系统能够为用户提供准确的天气预测信息,帮助他们更好地规划日常活动。
# 示例代码:构建LSTM模型
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense
model = Sequential()
model.add(LSTM(50, activation='relu', input_shape=(n_timesteps, n_features)))
model.add(Dense(1))
model.compile(optimizer='adam', loss='mse')
# 模型训练
model.fit(X_train, y_train, epochs=200, verbose=0)Matplotlib是Python中一个广泛使用的绘图库,能够生成高质量的图表。其灵活性和易用性使得用户能够创建各种类型的图形,包括线图、柱状图和散点图。通过设置图形的属性,可以实现高度自定义的可视化效果,帮助用户直观理解数据。Matplotlib能够用于展示实时天气变化和历史数据趋势。通过将数据可视化,用户可以轻松识别气温变化模式、降水量趋势等,为决策提供参考。
# 示例代码:使用Matplotlib绘制气温变化图
import matplotlib.pyplot as plt
dates = ['2023-01-01', '2023-01-02', '2023-01-03']
temperatures = [20, 22, 21]
plt.plot(dates, temperatures, marker='o')
plt.title('Temperature Changes in Shenzhen')
plt.xlabel('Date')
plt.ylabel('Temperature (°C)')
plt.show()
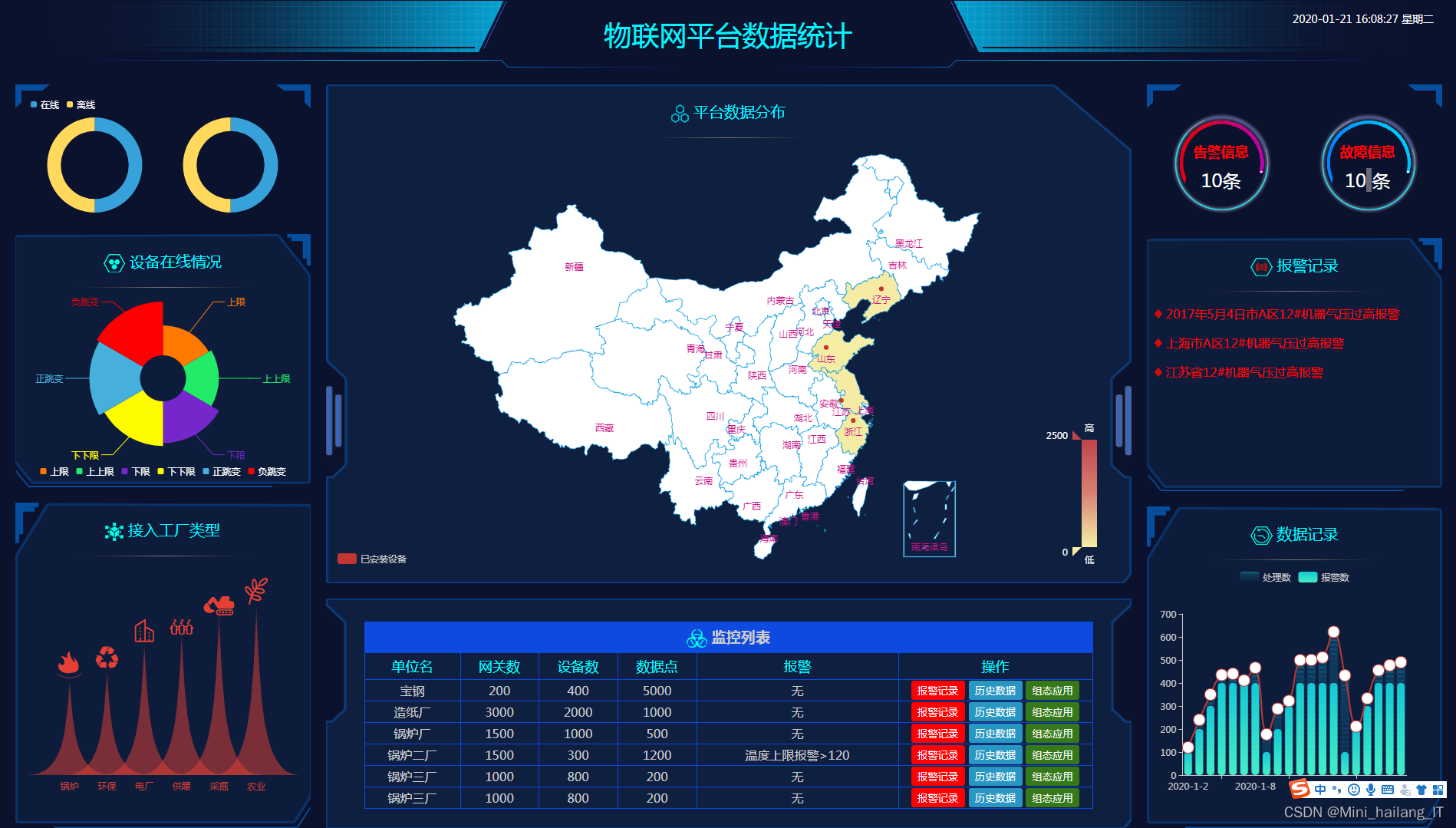
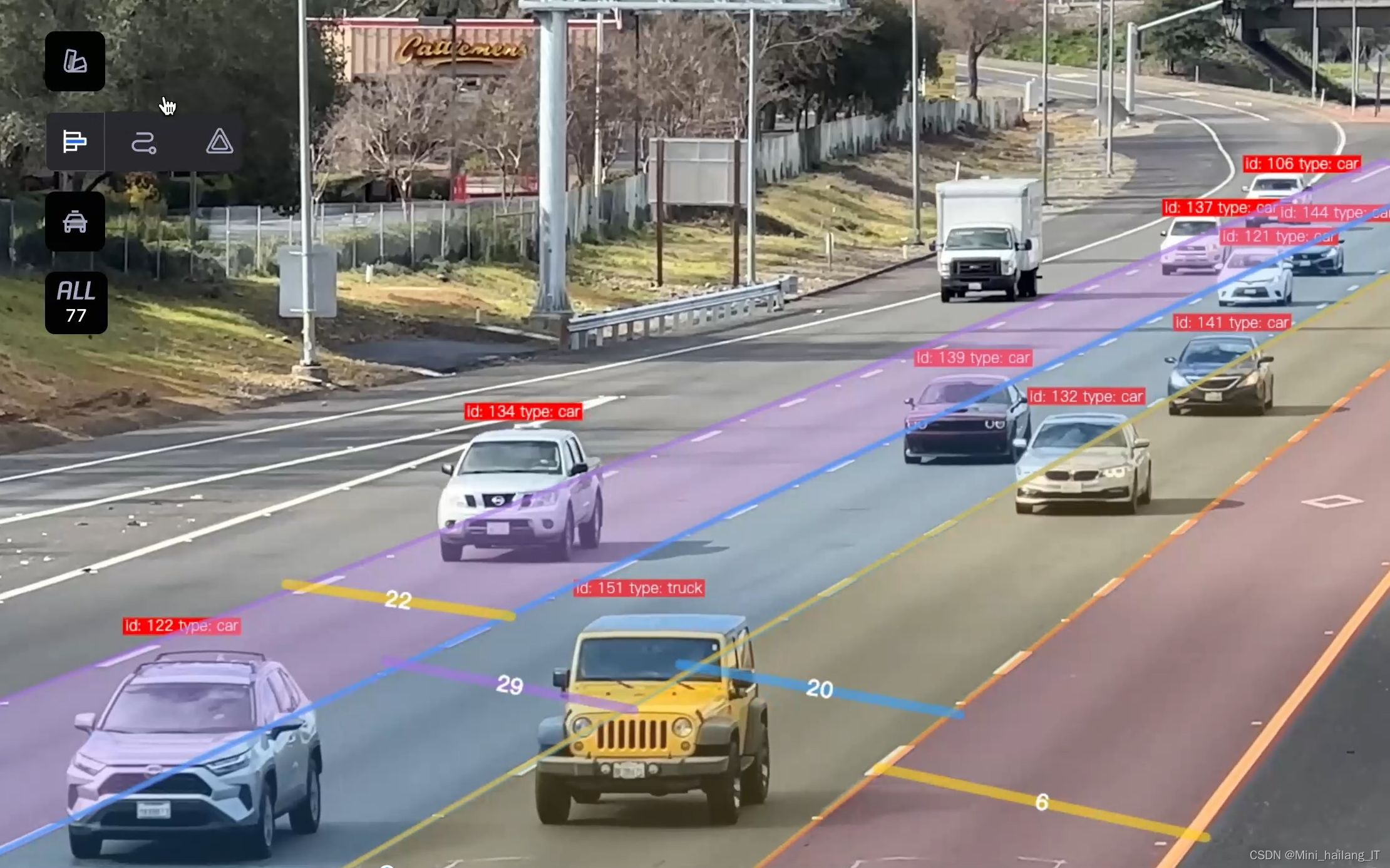
海浪学长项目示例:



更多帮助
更多推荐
 31
31 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)