
大模型openai服务网关,认证,限流,接口输入输出的修正,监控等功能
本文介绍了大模型服务网关的设计与功能,主要用于代理多个OpenAI接口并实现认证、限流、监控等功能。主要内容包括:1)三种认证方式(数据库、正则、JWT);2)秘钥获取位置设置;3)网关功能配置(过期时间、token额度、限速规则等);4)访问控制(白名单/黑名单机制);5)请求处理功能(提示词模板、参数映射);6)调用测试方法和监控功能。该网关系统提供了完整的API代理解决方案,可实现安全、可控
大模型openai服务网关
大模型服务网关是为了代理多个openai接口,并且在代理中实现认证,限流,接口输入输出的修正,监控等功能而设计的。
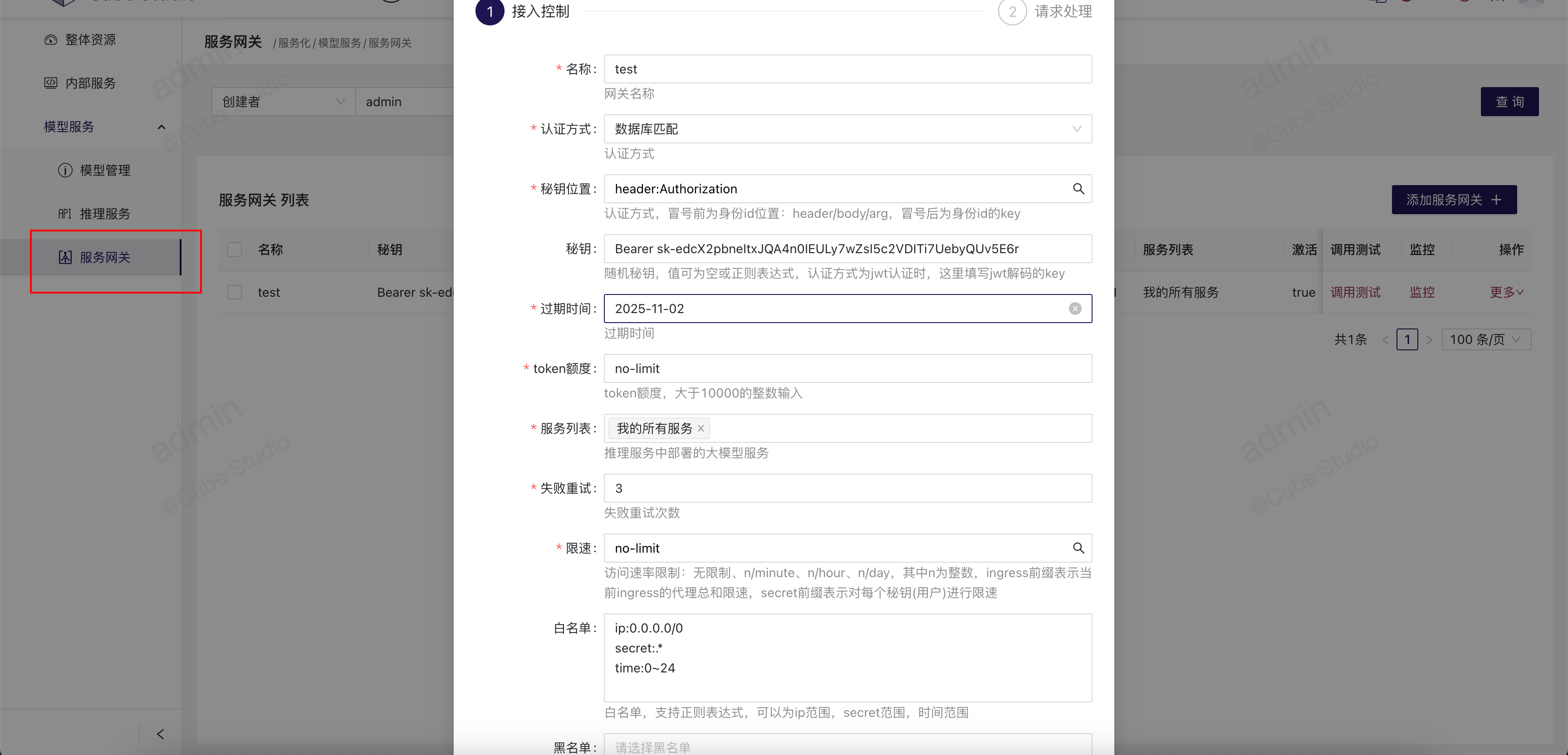
认证方式
- 1、数据库匹配: 从秘钥位置获取到的秘钥跟服务网关设定的秘钥完全一致
- 2、正则匹配:从秘钥位置获取到的秘钥要符合服务网关设定的秘钥 正则表达式
- 3、JWT认证:从秘钥位置获取到的秘钥 要能使用 服务网关 设定的秘钥 key 进行jwt解码
秘钥位置
position:key的写法,
其中position 为 密码获取方法,header 表示从http header头中读取,body 表示从json请求体中读取,arg 表示从请求的url中读取。
其中key为对应位置处的key值, 比如
- 1、header:Authorization 表示从header头中读取Authorization 的值为秘钥
- 2、body:user_id 表示从json请求体中读取user_id的值为 秘钥
- 3、arg:token 表示从url请求路径中读取参数token的值,作为秘钥
秘钥
根据认证方法,可自己设定,也会随机生成。
过期时间
网关的过期时间,超过该时间后,对访问请求返回“该网关已过有效期”的应答
token额度
整数或者no-limit,是问答总token的最大累加和。
服务列表
平台内创建的自己可以有权限访问的openai接口服务,但并不是当前上线的llm服务。在正式访问时会查询代理的llm服务是否上线中,再根据是否上线,决定应答
失败重试
请求大模型openai接口,报错后重试的次数
限速
- no-limit 没有限制
- ingress:n/minute 针对该网关,限制最近1分钟最多访问n次
- ingress:n/hour 针对该网关,限制最近1小时最多访问n次
- ingress:n/day 针对该网关,限制最近1天最多访问n次
- secret:n/minute 针对每个秘钥,限制最近1分钟最多访问n次
- secret:n/hour 针对每个秘钥,限制最近1小时最多访问n次
- secret:n/day 针对每个秘钥,限制最近1天最多访问n次
白名单
如果设置了白名单,在白名单范围内的就放行,不在白名单范围内的就不放行,优先级高于黑名单。每行一个白名单规则。
每行的白名单书写规则: type:value, 其中type可为
- ip,表示的是客户端的访问ip范围,值为ip网段
- secret,表示的访问者的秘钥,秘钥的正则表达式
- time 表示的是访问的时间,时间范围段
黑名单
书写规则同白名单,访问流量符合黑名单规范就阻拦,优先级低于白名单
激活
可控制当前网关是否有效
深度思考
暂时无效
联网搜索
暂时无效
内容安全
暂时无效
数据脱敏
暂时无效
提示词模板
最终发给给大模型的问题,如果当前服务网关配置了提示词模板,其中一定要包含{{query}},比如
cube-studio是开源一站式机器学习平台,请你的回答尽可能专业。请问:{{query}}
那么最终发给给大模型的问题就是上面的一整段话,替换了{{query}} 为用户最原始的问题的。
我们可以通过这种方式添加一些问答限制
参数值映射
对推理服务的json请求体的value进行映射,格式为"key":[“old_value”,“new_value”],
例如"model":[“deepseek”,“deepseek-qwen2-7b”],可以将请求deepseek的模型全部代理到deepseek-qwen2-7b模型服务上
参数值固定
参数值固定,对推理服务的json请求体的value进行固定,格式为"key":“new_value”,
例如"model":“deepseek-qwen2-7b”,可以将任何模型请求全部代理到deepseek-qwen2-7b模型服务上
调用测试
当配置了服务网关,那么网关会对外提供openai接口,代理用户的请求到下面的openai模型接口上。在外部智能体平台,主要需要调用所需的环境变量配置
API_SECRET_KEY = "sk-xxxxxxxx"
BASE_URL = "http://xx.xx.xx.xx/llm/api/xx/v1"
也可以自己写API调用示例代码
curl -X POST http://xx.xx.xx.xx/llm/api/xx/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-xxxxx" \
-d '{
"model": "xxxx",
"messages": [
{
"role": "user",
"content": "你是谁?"
}
],
"temperature": 0.7,
"stream": false
}'
参数说明:
MODEL_NAME:替换为你的模型名称,当前可访问模型名包含: (无可访问模型服务,请先部署大模型服务)
messages:对话历史,包含 role(user / assistant / system)和 content(消息内容)
temperature:控制生成文本的随机性(0~2,值越大越随机)
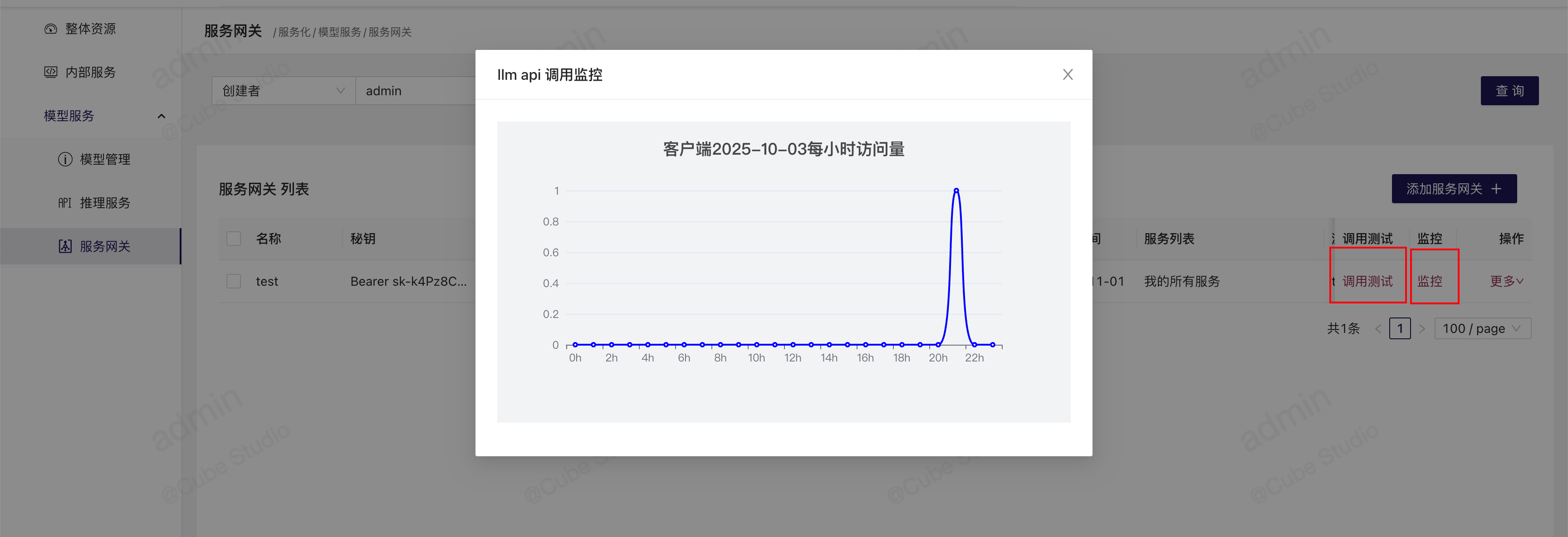
监控
客户端可以进行调用访问,每次调用访问,服务网关都会监控当前以使用token数目,和今日每小时的调用次数
更多推荐

 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)