
大数据:基于机器学习技术的城市气象数据预测系统 人工智能
上海市气象数据分析与预测系统,通过自制气象数据集,采用深度学习和机器学习算法实现对气象数据的多维度分析与准确预测。系统结合历史气象数据,采用时间序列分析方法和回归模型,能够有效预测温度、降水量等气象要素的变化趋势,为襄阳市的气象决策提供科学依据。不仅提升了气象服务的智能化水平,也为后续气象研究提供了新的思路与方法。对于计算机专业、人工智能专业、大数据专业、信息安全专业、软件工程专业的毕业生而言,不
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
大家好,这里是海浪学长计算机毕设专题,本次分享的课题是
🎯基于机器学习技术的上海市气象数据预测系统
项目背景
气象数据的准确分析与预测对农业、交通、城市规划等众多领域具有重要意义。襄阳市作为一个快速发展的城市,对气象变化的敏感性愈发显著,气象灾害的影响可能对其经济发展和人民生活造成严重影响。传统的气象预测方法往往依赖于经验和简单的统计模型,难以应对复杂的气候变化和时空特征。随着大数据和深度学习技术的发展,构建一个高效的气象数据分析与预测系统变得愈发重要。该系统不仅能够对气象数据进行全面分析,还能利用历史数据进行准确预测,为政府和相关部门提供科学决策依据,从而提升襄阳市应对气象变化的能力,保障城市的可持续发展。
数据集
通过网络爬虫或API接口从选定的数据源获取气象数据。程序会发送请求以获取所需的天气信息,如温度、湿度、气压、降水量和风速等。对于历史数据,可以选择特定时间段的数据进行抓取,保证数据的时效性和相关性。此过程需要注意数据抓取的频率和数量,以防止因过于频繁的请求触发目标网站的反爬虫机制。在收集到的数据中,可能会存在缺失值、异常值或重复数据。需要对数据进行清洗,填补缺失值、移除异常值和去重。使用合适的数据清洗技术,可以提升数据质量,确保模型训练时的准确性。
设计思路
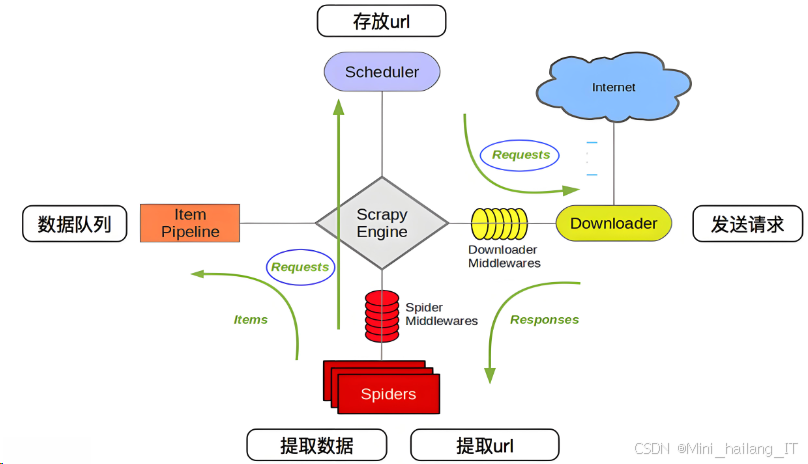
网络爬虫是一种自动化程序,用于在互联网上收集和提取信息,广泛应用于数据采集、信息检索和市场分析等领域。在气象数据预测系统中,网络爬虫能够从多个气象网站和数据源收集实时气象数据,为后续分析和建模提供必要的数据支持。网络爬虫的工作流程通常包括发送请求、获取网页内容、解析数据和存储信息等步骤。网络爬虫需要确定目标网页和数据源。在气象数据预测中,选择合适的数据源是确保数据质量的关键。气象网站通常提供丰富的实时天气信息和历史数据。在抓取数据时,爬虫程序通过发送HTTP请求获取网页内容。一旦获取到的HTML文档,接下来需要对其进行解析,以提取出所需的气象信息,如温度、湿度、风速、降水量等。常用的解析库有Beautiful Soup和lxml,这些库能方便地从HTML或XML文档中提取数据。数据提取的准确性直接影响到后续模型的训练效果。
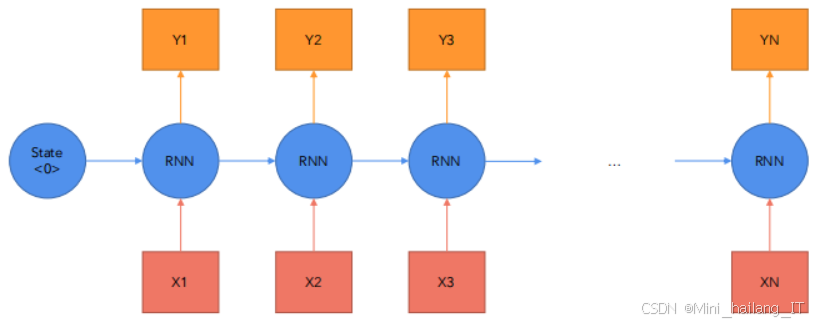
循环神经网络(RNN)是一种适合处理序列数据的深度学习模型,广泛应用于时间序列预测、自然语言处理以及气象数据预测等领域。RNN通过将先前的输出作为当前输入的一部分,能够有效捕捉序列数据中的时序特征。气象数据通常是时间序列数据,具有明显的时序依赖性,RNN因而在气象数据预测中展现出良好的性能。在气象数据预测系统中,RNN能够处理一系列历史天气数据,并根据这些数据预测未来的天气情况。通过不断接收输入数据,RNN能够记忆之前的信息,从而在预测时考虑到过去的天气模式。这使得RNN在捕捉气象变化的动态特征方面具有优势。例如,当RNN接收到过去几天的温度、湿度和风速数据时,能够根据这些历史数据推断出未来几天的气象趋势。然而,由于传统RNN在处理长序列时容易出现梯度消失或爆炸问题,导致模型无法有效学习长时间依赖关系。
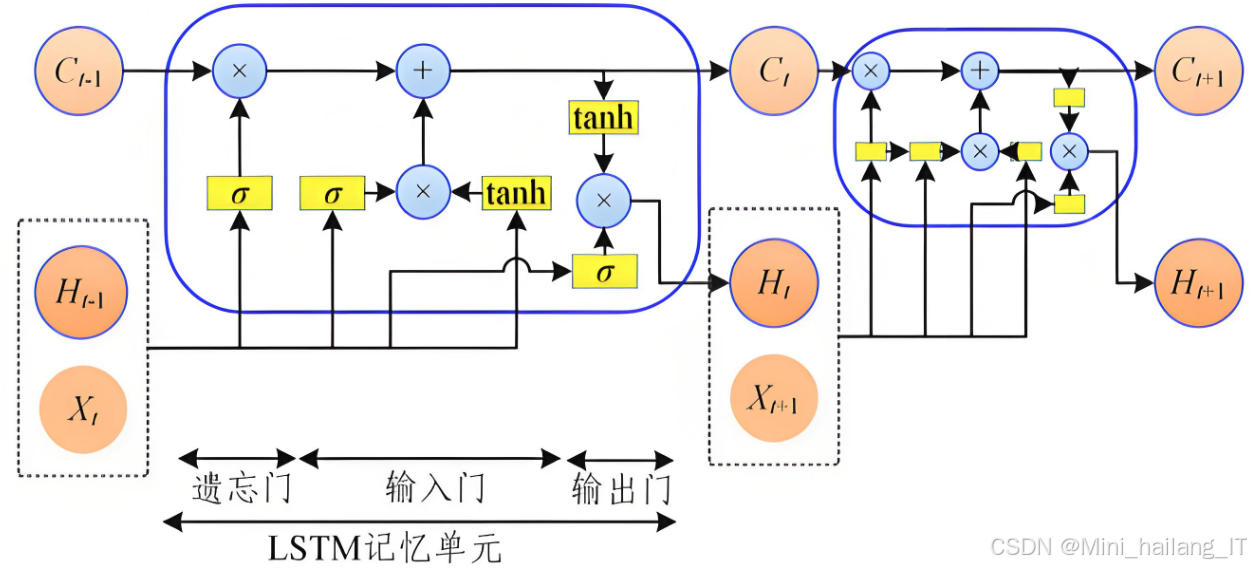
长短期记忆网络(LSTM)是一种特殊类型的循环神经网络,专门设计用于解决传统RNN在处理长序列数据时面临的梯度消失和爆炸问题。LSTM通过引入门控机制,能够更有效地捕捉序列数据中的长时间依赖特征。在气象数据预测系统中,LSTM能够处理复杂的气象变化,并为未来的天气预测提供准确的信息。LSTM的核心在于其单元结构,包括遗忘门、输入门和输出门。这三个门控机制能够控制信息在单元中的流动,从而决定哪些信息需要被遗忘、哪些信息需要被保留。遗忘门根据当前输入和上一个隐藏状态决定遗忘多少信息,输入门控制新信息的添加,而输出门则决定要输出哪些信息。这种结构使得LSTM能够在长时间序列中保留重要的历史信息,有效应对气象数据的时序特性。
在实际应用中,LSTM能够利用历史气象数据进行训练,学习天气变化的模式。例如,通过输入过去数天的温度、湿度和风速等数据,LSTM能够预测未来几天的天气情况。通过大量的训练,LSTM模型能够在不同天气条件下捕捉到气象要素之间的复杂关系,从而提高预测的准确性。LSTM的应用不仅提升了上海市气象数据预测系统的性能,也为城市管理和应急响应提供了可靠的决策支持。
将存储的气象数据从文件或数据库中读取到内存中。根据任务的需求,可能需要进行数据集的划分,将数据分为训练集、验证集和测试集。训练集用于模型训练,验证集用于调优超参数,测试集用于最终评估模型性能。
from sklearn.model_selection import train_test_split
import pandas as pd
# 加载数据
data = pd.read_csv('shanghai_weather_data.csv')
# 划分数据集
X = data[['temperature', 'humidity', 'pressure']] # 特征
y = data['weather_type'] # 目标变量
X_train, X_temp, y_train, y_temp = train_test_split(X, y, test_size=0.2, random_state=42)
X_val, X_test, y_val, y_test = train_test_split(X_temp, y_temp, test_size=0.5, random_state=42)选择合适的模型能够提高预测的准确性和可靠性。在气象数据预测中,深度学习模型如LSTM特别适合处理时间序列数据。通过前向传播计算输出,再用损失函数计算预测值与真实值之间的误差。接着,利用反向传播算法更新权重,以降低误差。训练过程通常需要多个轮次,以确保模型能够充分学习数据中的特征。通过计算验证集上的准确率、召回率和F1-score等指标,能够判断模型的泛化能力。
from keras.models import Sequential
from keras.layers import LSTM, Dense, Dropout
model = Sequential()
model.add(LSTM(50, return_sequences=True, input_shape=(X_train.shape[1], X_train.shape[2])))
model.add(Dropout(0.2))
model.add(LSTM(50, return_sequences=False))
model.add(Dropout(0.2))
model.add(Dense(len(np.unique(y_train)), activation='softmax'))
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
model.summary()使用测试集对模型进行最终评估,以获取模型的真实性能。测试集的数据在训练和验证过程中未曾使用,能够为模型的实际应用提供客观的评估结果。根据测试集的预测结果,进一步优化模型参数或选择不同的模型架构。
# 测试模型性能
y_test_pred = model.predict(X_test)
test_accuracy = accuracy_score(y_test, y_test_pred)
print(f'测试集准确率: {test_accuracy:.2f}')
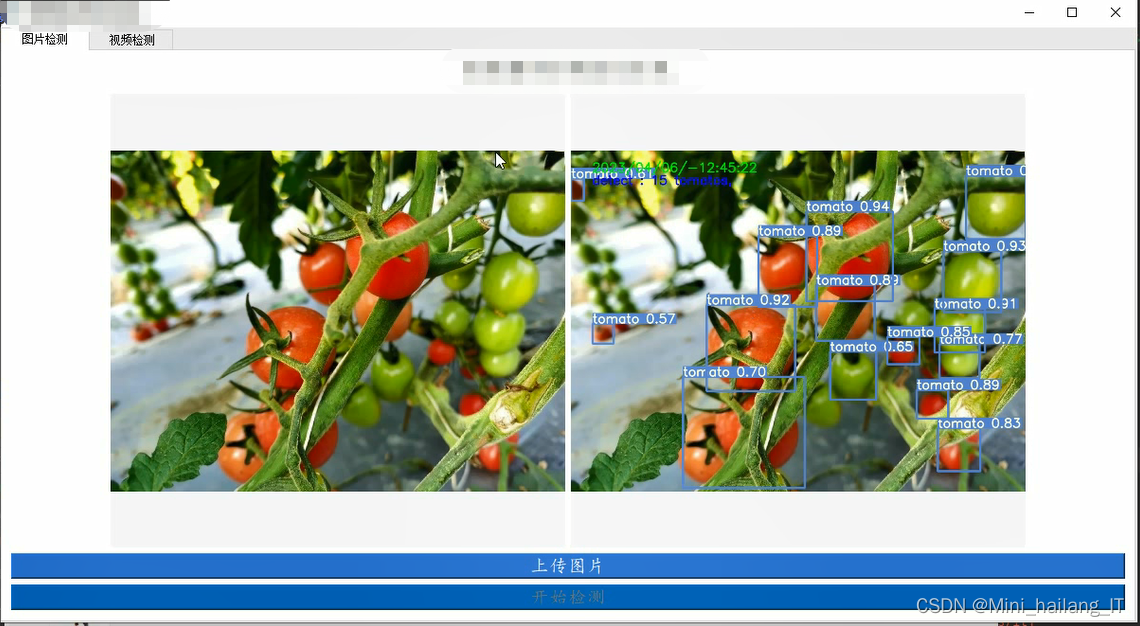
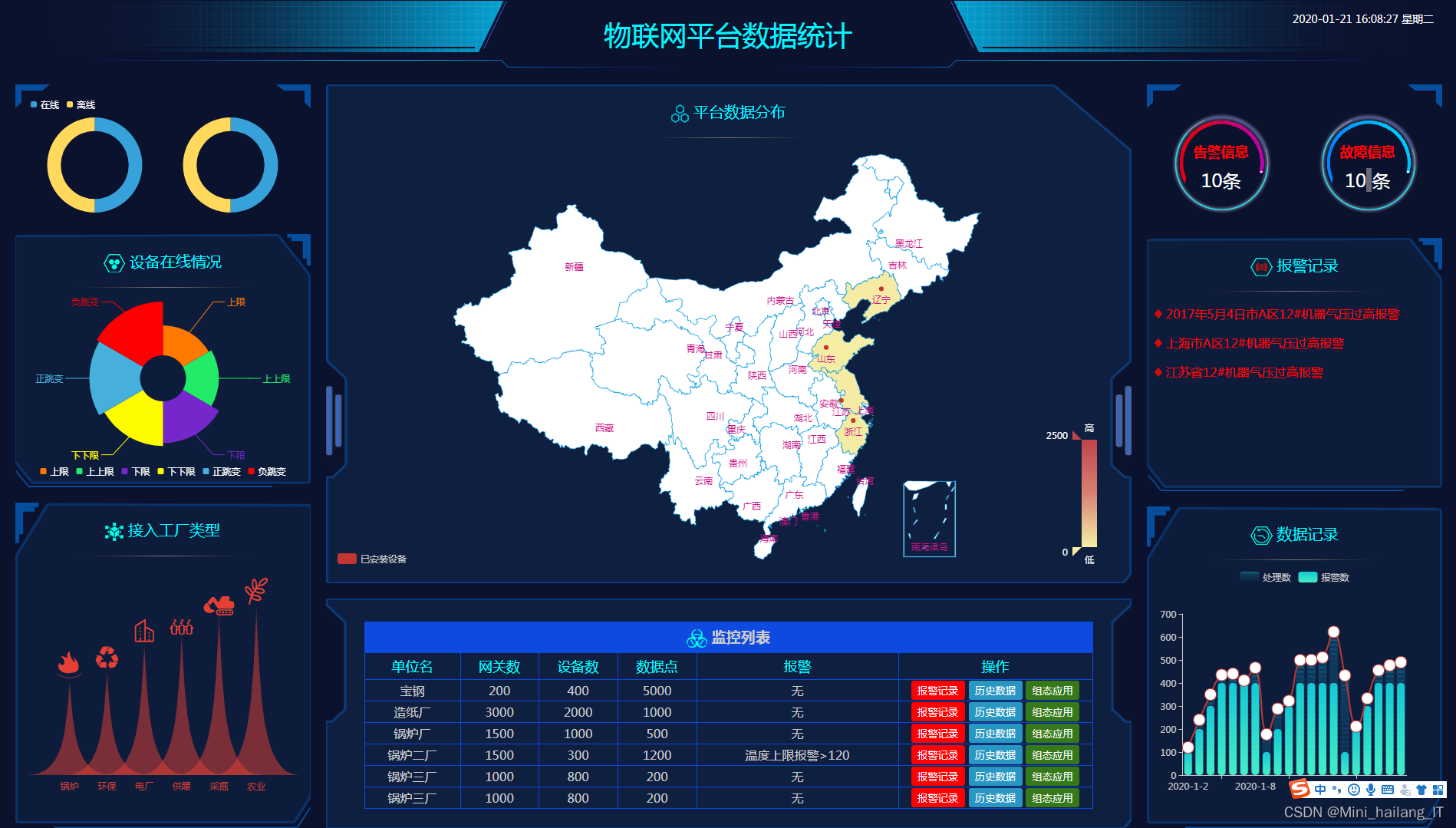
print(classification_report(y_test, y_test_pred))海浪学长项目示例:



更多帮助
更多推荐
 24
24 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)