
[AI工作流搭建笔记](3)基于cursor+MCP+python:企业定制知识库
摘要:企业知识库搭建方案 本文介绍了一种基于MCP框架的企业知识库搭建方法,旨在解决技术支持工作中客户需求管理、代码修改记录等知识统一问题。方案分为两个主要部分:1) 知识库整理,采用Markdown格式存储技术文档,结合Git记录代码修改历史;2) MCP工具设计,通过预编译和懒加载实现高效检索。系统使用BAAI/bge-base-zh-v1.5模型进行语义向量化,结合Faiss索引实现快速知识
经过了台风等在家躺平与调休,终于可以回到正常上班接着更新博客了,因为岗位是技术支持,会遇到很多客需,要把客需以及代码修改、企业知识等进行统一还是比较耗费人力的。但是这又是一个不得不做的事情,对此我想在这里分享一下我现在使用的搭建企业知识库的方法。
介绍
随着信息时代和知识经济时代的到来,企业内部信息资料繁多冗杂,知识管理逐渐成为各大企业的重要工作之一, 建立企业知识库能够有效的解决此类问题。目前在国内知识库还是属于比较新颖的概念,建立知识库可以提高员工的工作效率,有助于丰富员工的知识,有利于降低企业成本,减少员工的培训成本、劳动时间成本,从而增强企业的竞争能力。
搭建流程
整理知识库
一般的产品都是会基于一定的平台代码,根据客户需求进行代码扩展,这就要求我们的AI能够读懂我们的代码为什么这样写以及相关的一些修改。有时候不同客户的客需是很类似的(毕竟产品性质都是一样的),又要对应的客需进行记录,以便下次遇到相同需求进行复制。
基于MCP框架的知识库
首先我们使用第一章的教程先构建出MCP工具的框架,然后在文件夹中新建一个note文件夹用于存放本地的技术文档,这里技术文档使用MD格式。
我们可以简单的写一些架构,如果是基于代码的知识库,可以让AI读代码然后修改知识库更新,就可以非常灵活的且轻松的完善知识库。
代码修改记录
对于这个我们会提倡使用Git进行修改,修改完代码后将功能于逻辑写到Git的记录中去,这样每一次修改修改了什么功能就可以迁移到知识库中去。
至于迁移方法也很简单就把包含.git文件的文件夹引用到cursor对话框中,让cursor根据Git修改记录更新知识库。如果接入Github或者是Gitlab这种在线仓库,可以把代理商等代码进行统一管理。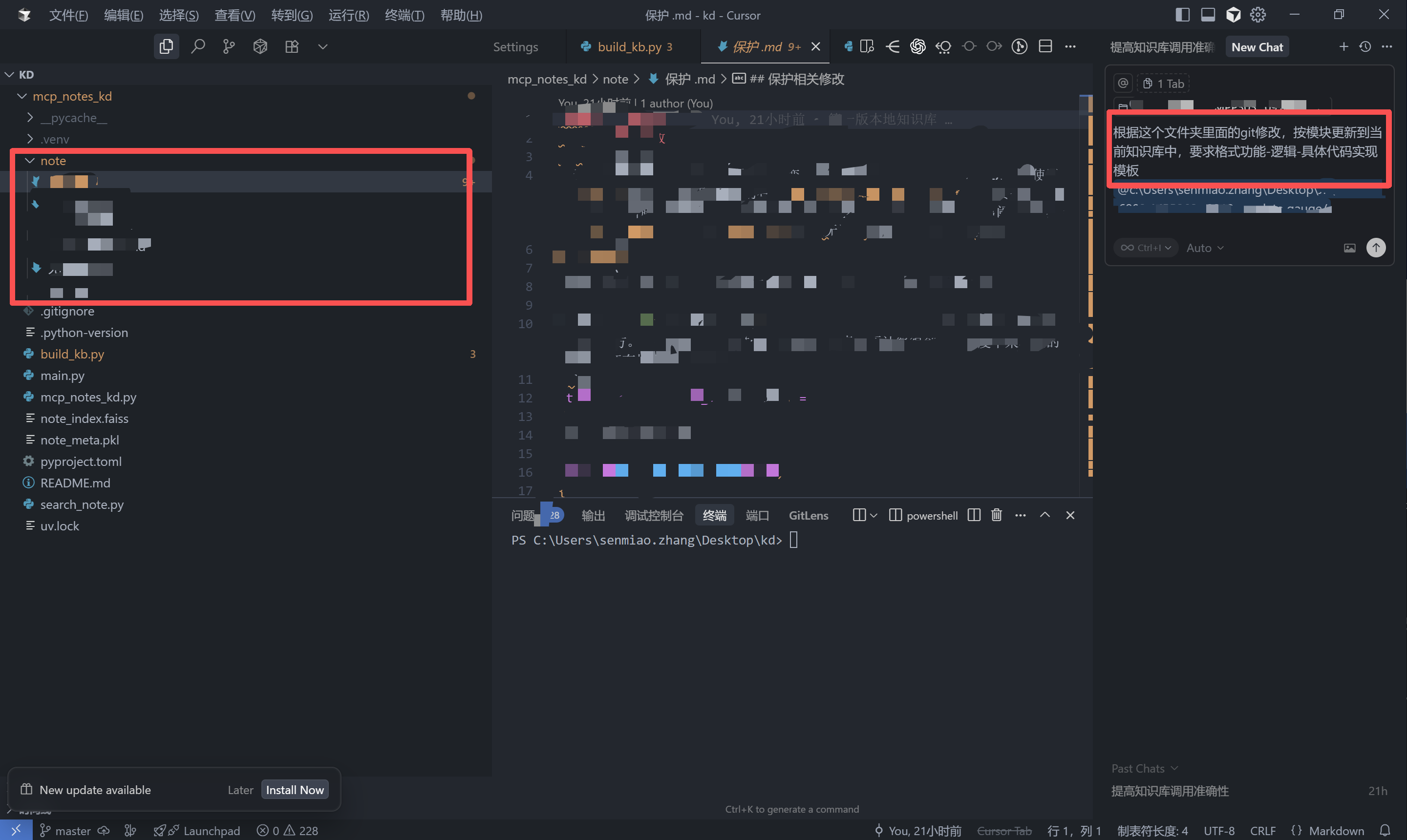
这样我们就可以搭建我们本地的知识库了,理论上来说,我们可以直接调用cursor读取知识库总结出修改方案等等,但是对于cursor来说还是有点困难,cursor大概一次可以使用200k token进行使用,大致读取1w5行代码。
对此我决定采用一个MCP工具,可以使用一个前置模型对知识库进行裁剪等,根据需求调取相关度高的部分。
MCP工具设计
由于Cursor的MCP tool识别有时间限制,如果把所有功能(特别是还要调用模型的代码)丢在一个代码中,cursor很容易会识别不到工具,对此这里采用预编译与懒加载的设计。
预编译
在文件夹中新建一个build_kd.py文件,该文件会调用模型对知识库进行切分。
# preprocess_notes.py
import os
import pickle
import faiss
import numpy as np
from sentence_transformers import SentenceTransformer
CACHE_INDEX = "note_index.faiss"
CACHE_META = "note_meta.pkl"
# 1. 加载模型
print("加载 embedding 模型中...")
model = SentenceTransformer("BAAI/bge-base-zh-v1.5")
# 2. 读取笔记
def load_notes(note_dir="./note"):
notes = []
file_map = []
for root, _, files in os.walk(note_dir):
for f in files:
if f.endswith(".txt") or f.endswith(".md"):
path = os.path.join(root, f)
with open(path, "r", encoding="utf-8", errors="ignore") as fp:
content = fp.read()
notes.append(content)
file_map.append(path)
return notes, file_map
# 3. Markdown 段落切分
def chunk_markdown(text):
chunks = []
current = []
for line in text.splitlines():
if line.strip().startswith("#"): # 遇到标题,切一个新块
if current:
chunks.append("\n".join(current).strip())
current = []
current.append(line)
if current:
chunks.append("\n".join(current).strip())
return chunks
# 4. 构建索引
def build_index(note_dir="./note"):
notes, file_map = load_notes(note_dir)
chunks = []
chunk_map = {}
for file_id, note in enumerate(notes):
sub_chunks = chunk_markdown(note)
for i, c in enumerate(sub_chunks):
if c.strip():
chunks.append(c)
chunk_map[len(chunks) - 1] = (os.path.abspath(file_map[file_id]), c)
print(f"总共生成 {len(chunks)} 个段落 chunk ✅")
embeddings = model.encode(chunks, normalize_embeddings=True)
embeddings = np.array(embeddings).astype("float32")
dim = embeddings.shape[1]
index = faiss.IndexFlatIP(dim)
index.add(embeddings)
faiss.write_index(index, CACHE_INDEX)
with open(CACHE_META, "wb") as f:
pickle.dump(chunk_map, f)
print("索引构建完成 ✅ 已保存到磁盘")
if __name__ == "__main__":
build_index("./note")
这里采用BAAI/bge-base-zh-v1.5模型,如果没有依赖需要先进行依赖下载。
pip install faiss-cpu sentence-transformers
然后在终端调用该函数,会切分知识库然后生成索引。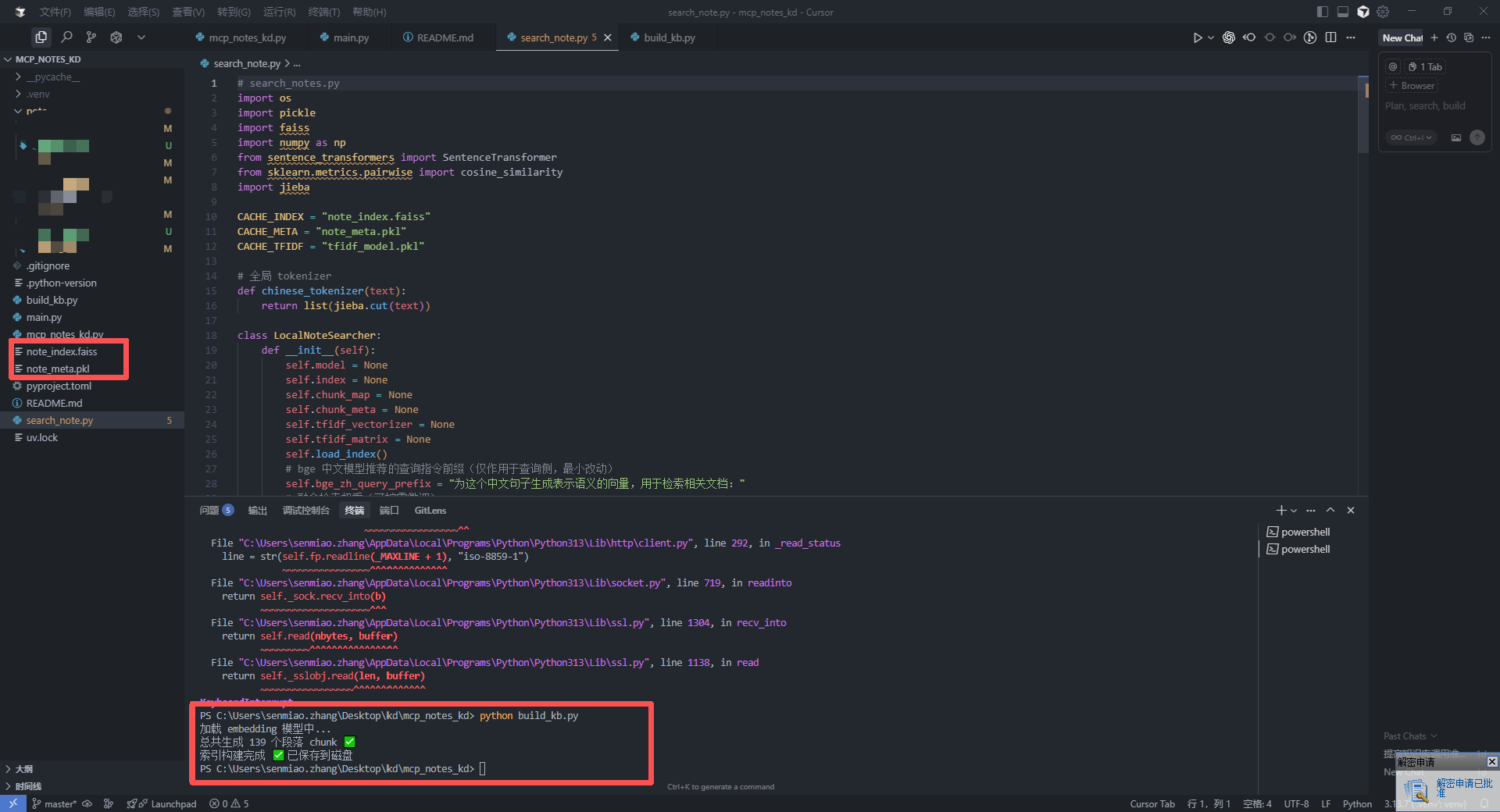
然后我们通过编写MCP工具文件mcp_notes_kd.py,就可以实现cursor调用MCP对知识库进行读取。
# mcp_notes_kd.py
import os
import sys
import json
import pickle
import faiss
import numpy as np
from sentence_transformers import SentenceTransformer
from mcp.server.fastmcp import FastMCP
# ---------------------------
# 绝对路径设置
# ---------------------------
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
CACHE_INDEX = os.path.join(BASE_DIR, "note_index.faiss")
CACHE_META = os.path.join(BASE_DIR, "note_meta.pkl")
print("启动 MCP Note Search 工具...", file=sys.stderr, flush=True)
mcp = FastMCP("note-search")
# ---------------------------
# 懒加载模型和索引
# ---------------------------
_model = None
_index = None
_chunk_map = None
# bge 中文模型推荐的查询指令前缀(仅作用于查询侧,最小改动)
_BGE_ZH_QUERY_PREFIX = "为这个中文句子生成表示语义的向量,用于检索相关文档:"
# 可开关同义词扩展(默认开启,仅查询侧,不改索引)
_ENABLE_SYNONYMS = True
_SYNONYMS = {
/*同义词*/
}
def _expand_query(query: str) -> str:
if not _ENABLE_SYNONYMS:
return query
tokens = {str(query)}
for k, vs in _SYNONYMS.items():
if k in query:
for v in vs:
tokens.add(v)
return " ".join(tokens)
def load_resources():
global _model, _index, _chunk_map
if _model is None:
print("加载模型...", file=sys.stderr, flush=True)
_model = SentenceTransformer("BAAI/bge-base-zh-v1.5")
if _index is None or _chunk_map is None:
if not os.path.exists(CACHE_INDEX) or not os.path.exists(CACHE_META):
print(f"❌ 找不到索引文件或元数据:{CACHE_INDEX}, {CACHE_META}", file=sys.stderr, flush=True)
raise FileNotFoundError("请先运行 preprocess_notes.py 构建索引")
print("加载索引与元数据...", file=sys.stderr, flush=True)
_index = faiss.read_index(CACHE_INDEX)
with open(CACHE_META, "rb") as f:
_chunk_map = pickle.load(f)
print("索引加载完成 ✅", file=sys.stderr, flush=True)
# ---------------------------
# 检索函数
# ---------------------------
@mcp.tool()
async def search_notes(query: str, top_k: int = 3):
"""
查询知识库
Args:
query: 查询文本
top_k: 返回前 K 条结果
Returns:
JSON 列表,每条包含 file, content, score
"""
load_resources()
# 同义词扩展 + bge 中文查询前缀(不改动索引/文档向量)
expanded = _expand_query(str(query))
q_with_prefix = _BGE_ZH_QUERY_PREFIX + expanded
qvec = _model.encode([q_with_prefix], normalize_embeddings=True).astype("float32")
scores, ids = _index.search(qvec, top_k)
results = []
for score, idx in zip(scores[0], ids[0]):
file_path, chunk_text = _chunk_map[idx]
results.append({
"file": file_path,
"content": chunk_text,
"score": float(score)
})
return results
# ---------------------------
# 运行 MCP Server
# ---------------------------
if __name__ == "__main__":
print("MCP Note Search Server 启动中...", file=sys.stderr, flush=True)
mcp.run(transport="stdio")
然后打开cursor编写MCPtool节点。
{
"mcpServers": {
"mcp-notes-kd": {
"type": "stdio",
"command": "python",
"args": ["C:/Users/senmiao.zhang/Desktop/kd/mcp_notes_kd/mcp_notes_kd.py"],
"cwd": "C:/Users/senmiao.zhang/Desktop/kd/mcp_notes_kd"
}
}
}
这样就可以调用MCP工具了
效果
在Cursor中选择Auto模式,然后可以让他进行回环测试。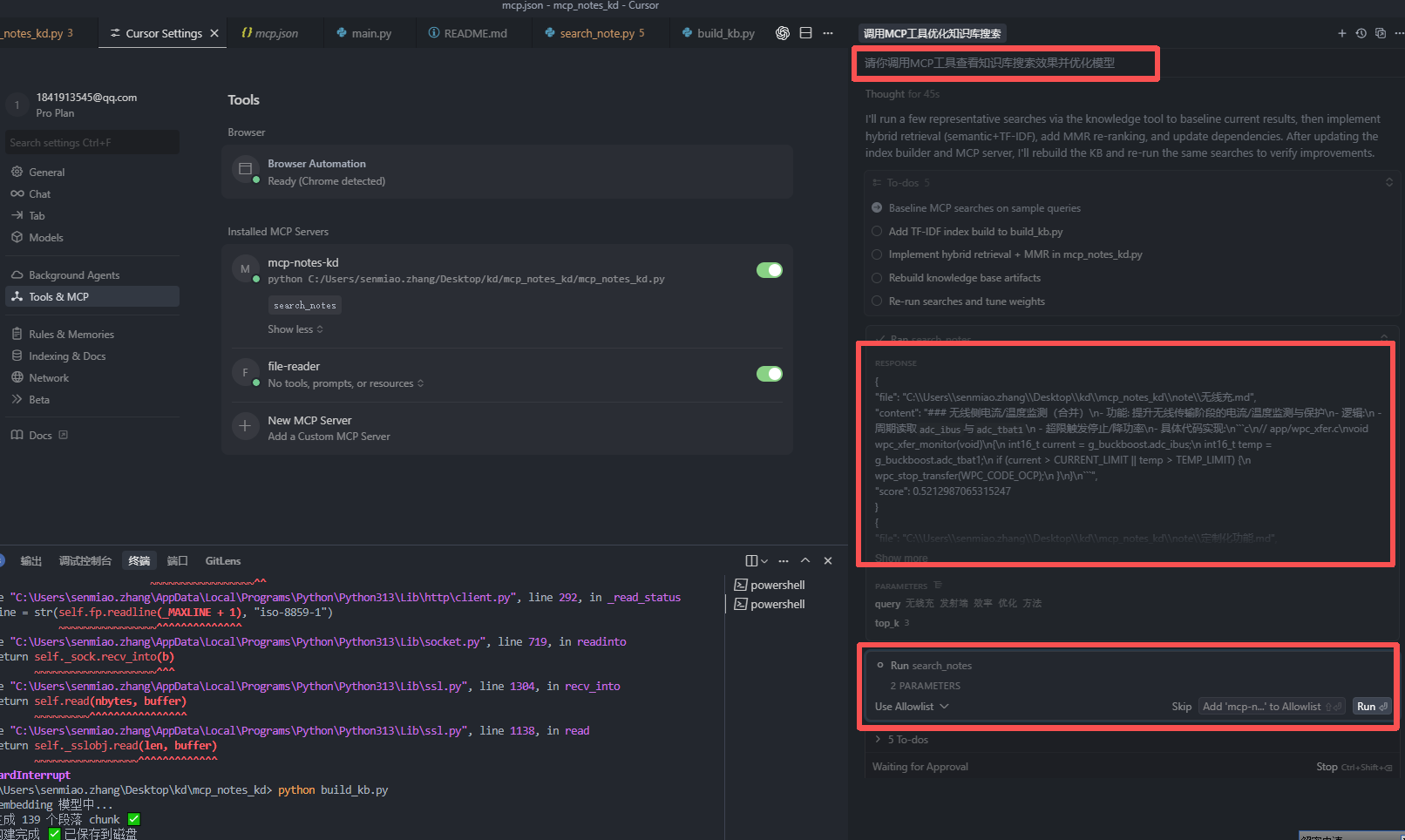
可以看到成功调用工具并放回关键词与内容相关性。
小结:相信这个不仅仅对知识库搭建可以给大家带来启发,在多模型多模态的应用以及项目管理上也希望大家可以有所收获。MCP的出现真的给AI带来一个很大的变化。
更多推荐
 12
12 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)