
大数据分析方法(1)基础概念
本文主要介绍了大数据分析的基本概念及相关技术,包括大数据的4V特征(体量大、价值密度低、多样性、速度快)、处理流程和关键技术(人工智能、互联网、云计算)。同时阐述了数据挖掘的分类(有监督/无监督学习)和预处理步骤(清理、整合、转换、规约)。重点讲解了统计学习的核心要素(模型、策略、算法)以及评估方法(正确率、召回率、精准率等),并介绍了P-R曲线和F1度量等评估指标。文章强调理解这些基础概念和流程
1.大数据分析方法参考书目
本文参考书目为《大数据分析:方法与应用》王星,清华大学出版社有限公司,2013年,按照讲授课内内容与教师所给PPT编写,可能与考试大纲不完全相符,具体内容以参考书目与实际招考情况为准!(注:PPT中仍推荐了机器学习 周志华著 数据挖掘:概念与技术(原书第3版) Jiawei Han Micheline Kamber Jian Pei著)
2.大数据
2.1大数据概念
大数据是一个新概念,英文中至少有三种名称:大数据(big data),大尺度数据(large scale data)和大规模数据(massive data),尚未形成统一定义,维基百科、数据科学家、研究机构和IT业界都曾经使用过大数据的概念。一般而言数据量PB级别以上才可称为大数据
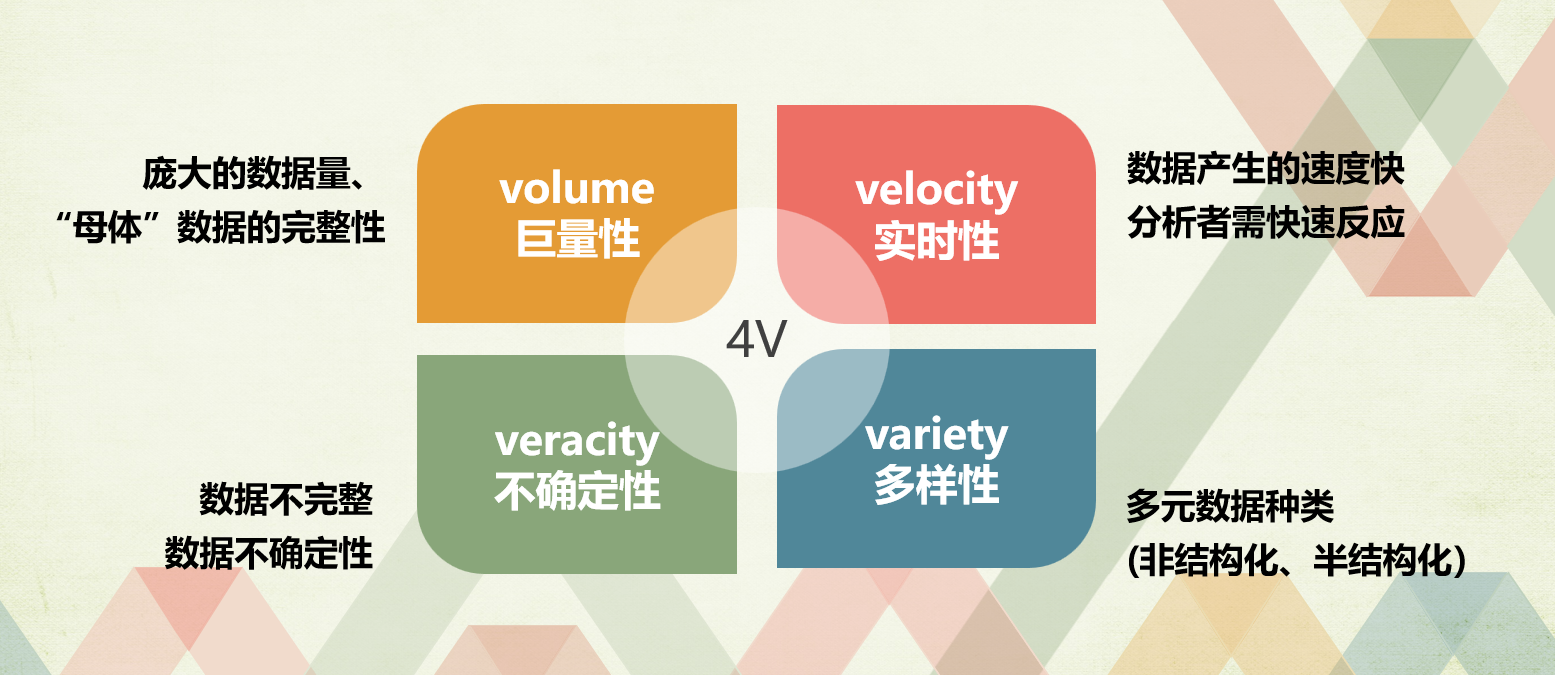
2.2大数据4V
Volume(体量大)、Value(价值密度低)、Variety(多样性)、Velocity(速度快)。
当然现在有部分文献中指出确实有不同的定义例如5V,即多一个Veracity(不确定性)这样的概念,具体内容参照参考书目!
2.3大数据处理流程和六个基本方面
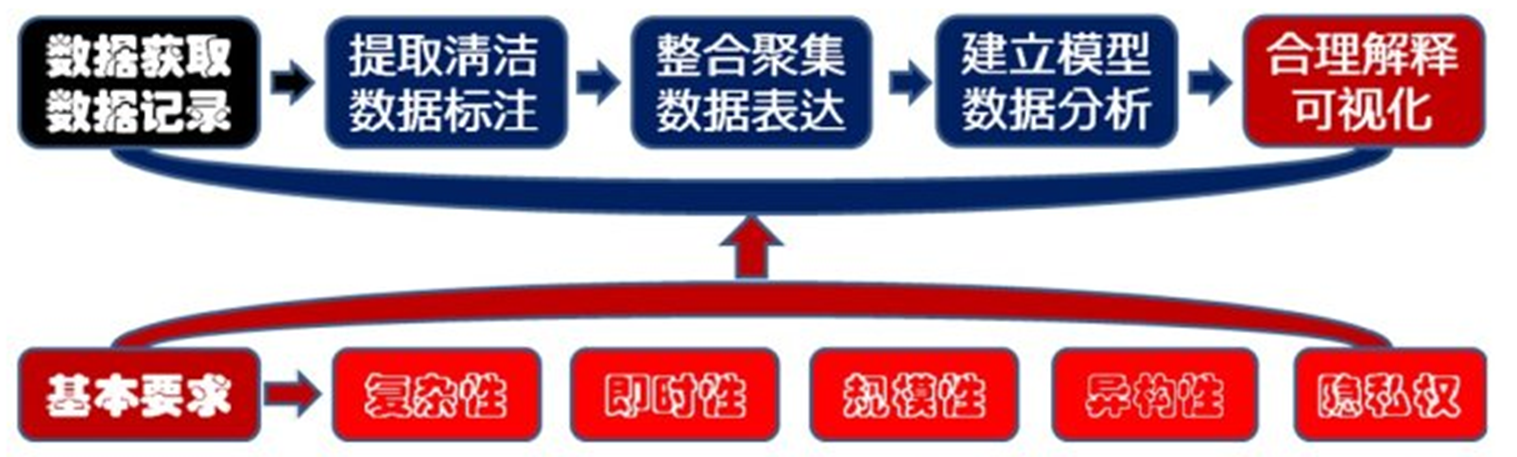
可视化分析、数据挖掘算法、预测分析、语义引擎、数据质量管理、数据仓库
2.4大数据相关技术
人工智能:是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。它是计算机科学的一个分支,企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器,该领域的研究包括机器人、语言识别、图像识别、自然语言处理和专家系统等。(现在比较火,一般这些任务是基于各类结构的神经网络的)
互联网:即广域网、局域网及单机按照一定的通讯协议组成的国际计算机网络。互联网是指将两台计算机或者是两台以上的计算机终端、客户端、服务端通过计算机信息技术的手段互相联系起来的结果,人们可以与远在千里之外的朋友相互发送邮件、共同完成一项工作、共同娱乐。
云计算:是一种按使用量付费的模式,这种模式提供可用的、便捷的、按需的网络访问, 进入可配置的计算资源共享池(资源包括网络,服务器,存储,应用软件,服务),这些资源能够被快速提供,只需投入很少的管理工作,或与服务供应商进行很少的交互。(其实就是计算资源外包,让别人提供计算设备,只需要发号施令就行)
3.数据挖掘
3.1数据挖掘概念
自动或半自动化地从大量数据中发现有效的、有意义的、潜在有用的、易于理解的数据模式的复杂过程。
3.2数据挖掘分类
有监督学习:是对分析者预定义的概念,通过数据探索和建立模型实现由观察变量对目标概念解释的效果。主要任务有分类和回归(数据是有标签的,或者说有真实值需要去学习的)
无监督学习:没有一个明确的标示变量用于表达目标概念,主要任务是提炼数据中潜在的模式,探索数据之间的联系和内在结构。主要任务有关联规则挖掘、聚类和可视化(数据只是一堆特征,无标签,需要从这些特征出发完成一些工作)
3.3数据预处理
数据清理:包含遗漏值的处理、平滑杂乱数据、找出离群值,并纠正数据的不一致性
数据整合:将多个数据源中的数据结合存放在一致的数据库中。也可以使用相关分析检测出冗余。
数据转换:将数据转化成适合挖掘的形式(标准化、归一化等)
数据规约:将高维度的数据集简化以降低数据维度,但同时应尽可能地保留数据的完整性,以权衡信息的保存与处理效率
下一章重点讲,这里背过预处理步骤是啥就行了......
4.统计学习
是关于计算机基于数据构建概率统计模型并运用模型对数据进行预测与分析的一门学科,统计学习也称为统计机器学习。
4.1统计学习的特点
统计学习以计算机及网络为平台,是建立在计算机及网络之上的;
统计学习以数据为研究对象,是数据驱动的学科;
统计学习的目的是对数据进行预测与分析;
统计学习以方法为中心,统计学习方法构建模型并应用模型进行预测与分析;
统计学习是概率、统计学、信息论、计算理论、最优化理论及计算机科学等多个领域的交叉学科,并且在发展中逐步形成独自的理论体系与方法论。
4.2统计学习的步骤
得到一个有限的训练数据集合;
确定包含所有可能的模型的假设空间,即学习模型的集合;
确定模型选择的准则,即学习的策略;(损失函数、风险函数)
实现求解最优模型的算法,即学习的算法;
通过学习方法选择最优模型;
利用学习的最优模型对新数据进行预测或分析。
至此我们得到了一个非常重要也十分好记的式子
统计学习 = 模型 + 策略 + 算法
4.3统计学习--模型
统计学习里首先要考虑使用什么模型是重要的,有监督学习中模型一般分为两种类型,一种是概率模型一种是非概率模型(决策模型)
非概率模型的假设空间可以定义为决策函数的集合:
概率模型则输出的是条件概率:
4.4统计学习--策略
一般而言存在两种不同的方法度量统计学习好坏,损失函数是基于一次预测好坏的度量,风险函数是度量平均意义上的好坏:

一般来讲平方损失和交叉熵损失是常用的,因为他们普遍是可微的,其他损失知道即可(该课程期末考过0-1损失)

风险函数的思想是我要算出在整个X所在空间的损失的一个期望,但是数据往往是离散的,所以我们用经验风险估计风险函数,但是由于经验风险是基于数据的,难免有偏,因而采用结构化风险更稳妥:

结构化风险的思路就是对模型参数进行惩罚使得它不要“过好地拟合当前数据”,也就是正则化。
4.5统计学习--算法
顾名思义,这里的算法就是使得模型学习到最优结果的办法。统计学习基于训练数据集,根据学习策略从假设空间中选择最优模型,最后需要考虑用什么样的计算方法求解最优模型。此时,统计学习问题归结为最优化问题,统计学习的算法成为求解最优化问题的算法。
最后选择模型时我们通常选择泛化能力强的模型,也就是说在验证集上表现较好的模型,只有这样才能对未来的数据得到更好的结果。为了检验这个模型的泛化能力,我们通常还要设计一些验证算法,例如Bootstrap(自助法)、K折交叉验证等这两个方法的伪算法详见参考书P178页,思想比较简单,这里不过多赘述(该课程期末考过自助法)
5.几种评估方法
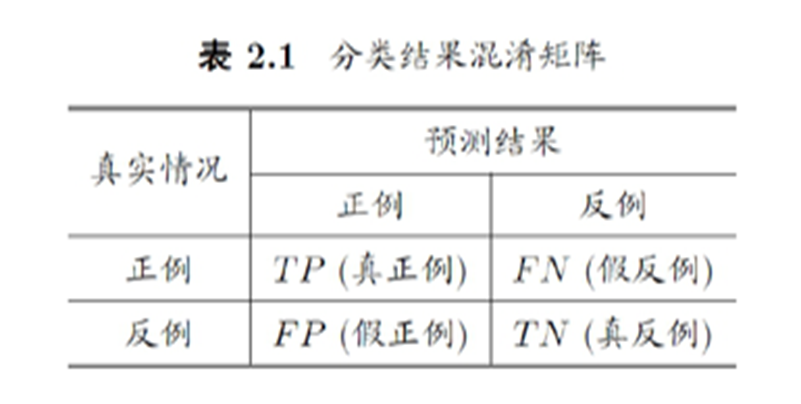
首先来看这张图,模型是二分类模型,其中横轴代表模型的预测结果,纵轴代表真实样本标签,交叉点即为真实情况为某类下模型预测为某类的样本数。
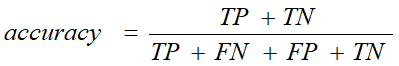
正确率:反映出是总共判断对了多少,相反的就是错误率。
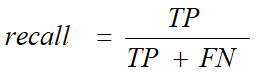
召回率(查全率):反映出有多少个真正的正例被真实的预测出来了。
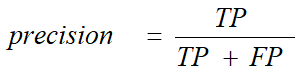
精准率(查准率):反映出被预测为正例的数据中对了的比例。
根据P-R可以绘制P-R曲线,这个曲线反映了二分类模型的能力:
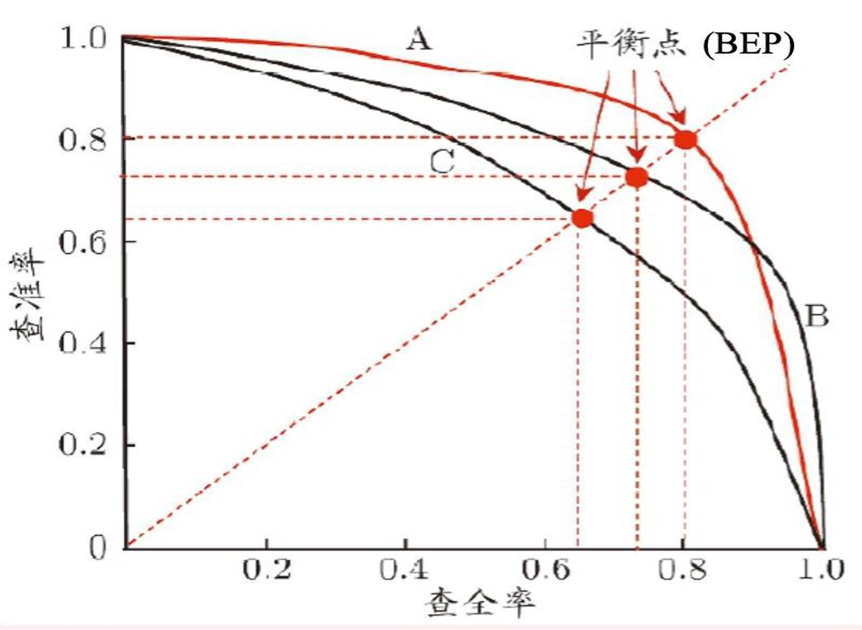
其中,曲线下面积越大越好,因为P与R是一对”对家“,他俩通常是唱反调的,当他俩都很大时证明这个模型效果是很好的,也就是说查得准也查的全!其次当曲线比较光滑时也认为其没有太过拟合(实际上绘制出的P-R曲线不会这么光滑,而且有很多”阶梯“),当面积差不多时一版平衡点更靠近左上方则更好。
当然,平衡点太过简单,导致信服度不高,这时我们便又有了一些新的定义,例如我们定义F-度量:
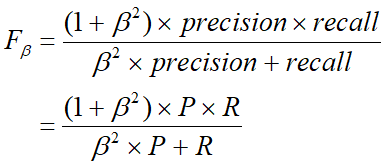
当β = 1时,便有了F1度量(该课程期末考过F1度量):
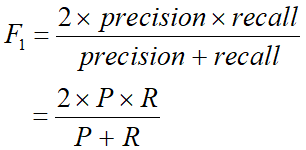
另外的,当其进行多次训练或验证时我们还有一些宏/微F度量的概念,这些概念也只不过是将F度量在不同层面上平均化罢了:

至此,基本概念阶段完结,下一章节将会讨论一些预处理的问题。基本概念阶段知识琐碎需要定期复盘并记忆,但公式或是统计学习流程等内容若将其理解应当也不算太难记忆。
更多推荐



 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)