
手工调reward成历史!SEEA-R1作为通用大脑登NeurIPS,推动人形机器人规模化发展
自我进化能力,即智能体自主优化其推理与行为的能力,对于解决长时序、真实世界场景下的具身智能任务至关重要。尽管现有的强化微调(Reinforcement Fine-tuning, RFT)技术在提升大语言模型的推理能力上表现出色,但其在多模态交互的具身智能领域,尤其是在赋能自我进化方面的潜力仍未被充分挖掘。稀疏奖励问题:在多步骤的复杂任务中,缺乏中间步骤的有效奖励信号,导致信用分配困难,RFT 难以

项目主页: https://seea-r1.online/
论文链接: https://arxiv.org/abs/2506.21669
摘要
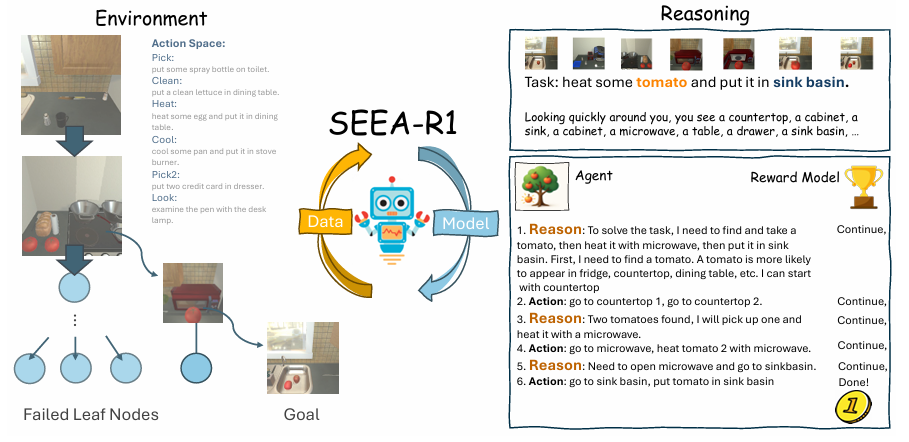
自我进化能力,即智能体自主优化其推理与行为的能力,对于解决长时序、真实世界场景下的具身智能任务至关重要。尽管现有的强化微调(Reinforcement Fine-tuning, RFT)技术在提升大语言模型的推理能力上表现出色,但其在多模态交互的具身智能领域,尤其是在赋能自我进化方面的潜力仍未被充分挖掘。
具身场景下的强化微调面临两大核心挑战:
- 稀疏奖励问题:在多步骤的复杂任务中,缺乏中间步骤的有效奖励信号,导致信用分配困难,RFT 难以有效指导策略学习。
- 泛化能力局限:依赖人工设计的、与特定任务或环境绑定的奖励函数,限制了智能体在新任务和新环境中的泛化与自我提升能力。
为应对上述挑战,我们提出了 SEEA-R1 (Self-Evolving Embodied Agents-R1),这是首个专为具身智能体自我进化而设计的强化微调框架。其核心创新包括:
- 树状分组相对策略优化 (Tree-GRPO):该算法将蒙特卡洛树搜索(MCTS)融入分组相对策略优化(GRPO)中。通过 MCTS 的探索与模拟,将任务最终的稀疏奖励信号(成功/失败)转化为稠密的、步进式的过程奖励(Q值),从而优化多步推理中的信用分配。
- 多模态生成式奖励模型 (MGRM):为了摆脱对人工奖励的依赖,我们引入了一个可学习的奖励模型。MGRM 能够理解多模态输入(文本与视觉),并以生成“思考-回答”对的方式,提供与具体任务无关的、具有可解释性的奖励评估,支持智能体跨任务、跨场景的自主适应。
通过数据进化(Data Evolution)与模型进化(Model Evolution)的双循环,SEEA-R1 实现了智能体能力的持续迭代优化。
我们在权威的 ALFWorld 基准上对 SEEA-R1 进行了全面评估。实验结果表明,SEEA-R1 在纯文本任务和多模态任务上分别取得了 85.07% 和 36.19% 的成功率,超越了包括 GPT-4o 在内的当前最优模型,达到了新的 SOTA 水平。这些成果验证了 SEEA-R1 作为一个可扩展的自我进化具身智能体框架的有效性与巨大潜力。
1. 整体框架与自我进化循环 (Overall Framework)
SEEA-R1 的核心是一个通过“数据进化”与“模型进化”双重循环驱动的闭环学习系统。智能体通过主动与环境交互来收集高质量的决策经验,并利用这些经验迭代优化自身的策略模型与奖励模型。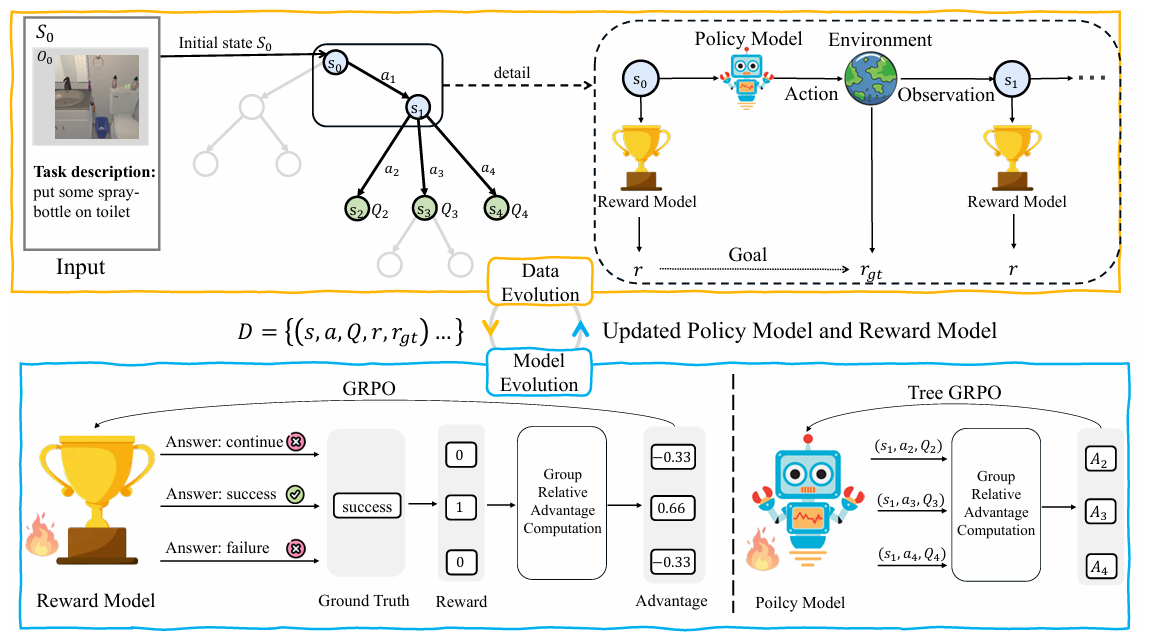
工作流程详解:
-
数据进化 (Data Evolution): 经验生成与过程奖励转化
- 目标: 探索环境,收集包含密集过程奖励的经验数据。
- 方法: 策略模型 (Policy Model) 利用蒙特卡洛树搜索 (MCTS) 与环境进行交互。MCTS 通过在内部模拟多条未来轨迹,将环境提供的稀疏最终奖励(如任务成功得1分)转化为对每一步动作的优劣评估,即 Q值。这个 Q 值就充当了稠密的“过程奖励”。
- 产出: 一个经验数据集
D。其中每条数据包含状态s、候选动作a、该动作的 Q 值Q、环境真实奖励r以及奖励模型评估的奖励r_rm。
-
模型进化 (Model Evolution): 策略与奖励的协同优化
- 目标: 利用收集到的高质量数据,同时提升策略模型和奖励模型。
- 方法:
- 策略模型更新: 使用 Tree-GRPO 算法,根据 MCTS 提供的高质量 Q 值(过程奖励)来更新策略模型,使其更倾向于选择高回报的动作。
- 奖励模型更新: 使用 GRPO 算法,利用收集到的轨迹和环境的最终奖励,训练多模态生成式奖励模型 (MGRM),使其能更准确地判断任务进度(成功/失败/继续)。
- 产出: 新一代、能力更强的策略模型和奖励模型。
这两个循环交替进行,形成了一个正向飞轮:更优的模型能够探索和生成更高质量的数据,而高质量的数据又能训练出更强大的模型,最终实现智能体能力的持续自我进化。
2. 关键技术解析
2.1 Tree-GRPO:融合树搜索的策略优化
为了解决长时序任务中的信用分配难题,SEEA-R1 提出了 Tree-GRPO,它将 MCTS 的规划能力与 GRPO 的优化稳定性深度结合。
a) 蒙特卡洛树搜索 (MCTS) 作为“过程奖励”生成器
MCTS 允许智能体在做出决策前进行“深思熟虑”的沙盘推演。其核心四步骤在 SEEA-R1 中具体实现如下 (对应论文 Figure 3):
-
选择 (Selection): 从根节点(当前状态)出发,根据 UCT (Upper Confidence Bound for Trees) 公式选择路径。UCT 在“利用”已知高价值的动作和“探索”尝试次数较少的动作之间取得平衡。
-
UCT 公式:
at=argmaxat,i[Q(st,at,i)+clnN(st−1,at−1)1+N(st,at,i)] a_t = \arg\max_{a_{t,i}} \left[ Q(s_t, a_{t,i}) + c \sqrt{\frac{\ln N(s_{t-1}, a_{t-1})}{1 + N(s_t, a_{t,i})}} \right] at=argat,imax[Q(st,at,i)+c1+N(st,at,i)lnN(st−1,at−1)]
其中
Q是动作价值,N是访问次数,c是探索常数。
-
-
扩展 (Expansion): 到达叶子节点后,执行选定动作,获得环境的新观测,并由策略模型生成一组候选动作作为新的子节点。
-
模拟 (Simulation): 从新节点开始,使用当前策略快速“前推”(rollout) 直至任务结束,并记录此过程的累积奖励。
-
回溯 (Backup): 将模拟得到的奖励结果反向传播,更新路径上所有节点的
Q值和访问次数N。-
Q值更新公式:
Q(st,at)=Eat∼πθold(A∣st)[R(st,at)]=∑j=1N(st,at)R(j)(st,at)N(st,at) Q(s_t, a_t) = \mathbb{E}_{a_t \sim \pi_{\theta_{\text{old}}}(A|s_t)} \left[ R(s_t, a_t) \right] = \frac{\sum_{j=1}^{N(s_t, a_t)} R^{(j)}(s_t, a_t)}{N(s_t, a_t)} Q(st,at)=Eat∼πθold(A∣st)[R(st,at)]=N(st,at)∑j=1N(st,at)R(j)(st,at)
经过多轮 MCTS 探索后,每个动作的
Q值成为了其在该状态下的优良性度量,即稠密的过程奖励。
-
b) GRPO:稳定高效的策略更新
获得过程奖励后,Tree-GRPO 使用分组相对策略优化 (GRPO) 算法来更新策略。GRPO 的核心思想是,在同一状态下比较一组候选动作的相对优劣,而不是依赖其绝对奖励值,这使得学习信号更稳定。
-
优势函数 (Advantage Function):
A^t,i,k=prt,i−mean({prt,i}i=1G)std({prt,i}i=1G) \hat{A}_{t,i,k} = \frac{\text{pr}_{t,i} - \text{mean}(\{\text{pr}_{t,i}\}_{i=1}^G)}{\text{std}(\{\text{pr}_{t,i}\}_{i=1}^G)} A^t,i,k=std({prt,i}i=1G)prt,i−mean({prt,i}i=1G)
其中pr是 MCTS 提供的过程奖励 (Q值)。该函数衡量了一个动作相对于同组其他动作的优势。 -
Tree-GRPO 损失函数:
J(θ)=E[… ]−βDKL[πθ(⋅∣st)∥πref(⋅∣st)] J(\theta) = \mathbb{E}[\dots] - \beta D_{KL}[\pi_\theta(\cdot|s_t) \| \pi_{\text{ref}}(\cdot|s_t)] J(θ)=E[…]−βDKL[πθ(⋅∣st)∥πref(⋅∣st)]
此损失函数包含两部分:- 策略提升项: 鼓励模型生成具有更高优势的动作。
- KL 散度惩罚项: 防止新策略偏离初始参考模型太远,确保训练的稳定性。
2.2 MGRM:自主学习的“任务完成度检测器”
为了实现真正的自我进化并摆脱对人工奖励的依赖,SEEA-R1 引入了多模态生成式奖励模型 (MGRM)。
-
设计理念:
- 多模态: 能够同时处理视觉(图像)与文本(历史交互)输入。
- 生成式与可解释: MGRM 不仅仅输出一个分数,而是生成结构化的文本,模仿人类“先推理,后判断”的思考模式。
这种设计极大地增强了奖励信号的可解释性。<think> 用户的目标是找到并加热一个番茄。当前智能体已拿到番茄,正在走向微波炉。任务虽未完成,但进展顺利,没有犯错。 </think> <answer>Continue</answer>
-
训练与作用:
MGRM 被训练为一个三分类(Success, Continue, Failure)的序列生成任务。在自我进化循环中,它与策略模型协同进化:更强的策略模型探索出更优质的轨迹,为 MGRM 提供更好的训练数据;反过来,更精准的 MGRM 又能为策略模型提供更可靠的奖励信号,使其在没有环境真实奖励的情况下也能判断行为的正确性。
3. 实验与性能分析
3.1 实验环境与基准
- ALFWorld: 一个模拟家庭环境的交互式基准,包含拾取、清洁、加热、冷却等六类长时序、稀疏奖励任务。我们重点关注其 test-unseen 子集,以评估模型的泛化能力。
- EmbodiedEval: 一个更具挑战性的全新 OOD (Out-of-Distribution) 多模态评估基准,包含属性问答、空间问答、导航和物体交互等任务,用于测试模型在未知 3D 场景中的泛化推理能力。
3.2 主要实验结果
a) ALFWorld 性能对比:全面超越 SOTA
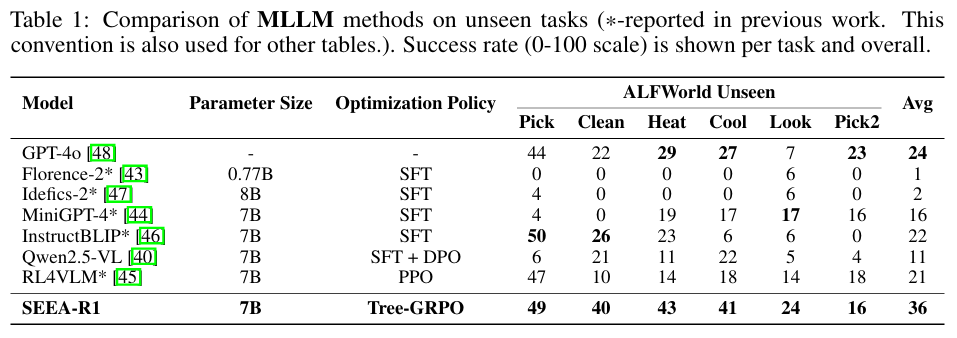
结果解读:
- SEEA-R1 (7B) 的平均成功率 (36%) 显著高于 GPT-4o (24%),证明了其算法框架在长时序规划上的优越性。
- 在需要复杂状态操作的清洁、加热、冷却等任务上,SEEA-R1 的优势尤为明显。
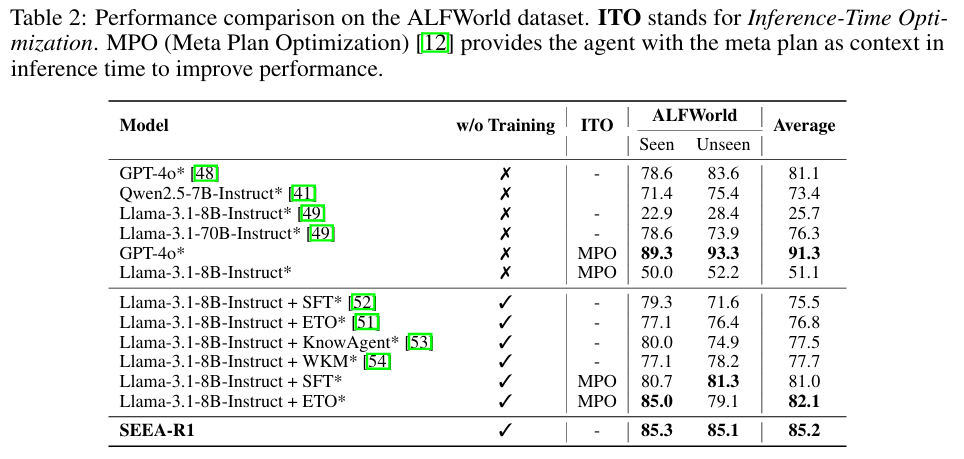
结果解读:
- 在纯文本任务中,SEEA-R1 同样达到了 SOTA 水平,证明了 Tree-GRPO 框架的普适性。
b) 自我进化能力验证:无外部奖励下的学习
实验模拟了没有环境真实奖励(GT Reward)的场景,智能体完全依赖 MGRM 进行学习。
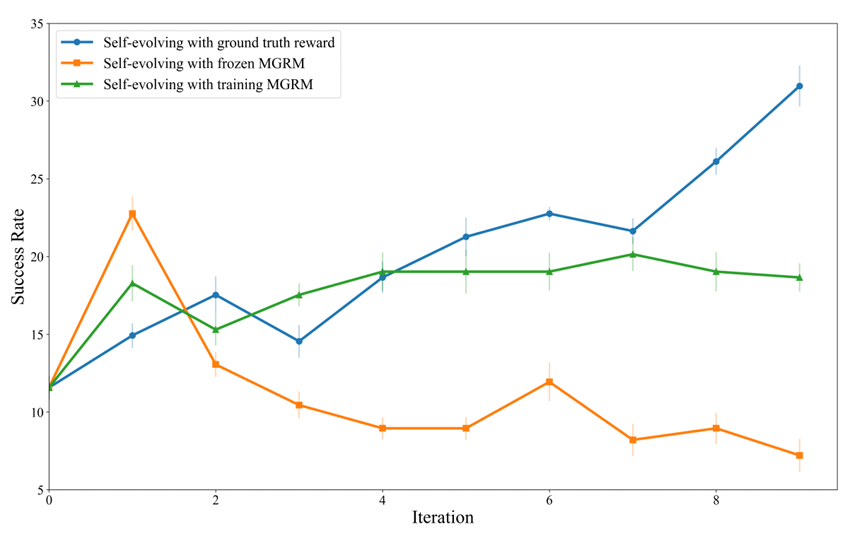
结果解读 (对应论文 Figure 5):
- 绿线 (SEEA-R1 w/ training MGRM): 使用在自我进化中共同训练的 MGRM 作为奖励信号,智能体性能持续并显著提升,接近使用真实奖励的理论上限(蓝线)。
- 橙线 (SEEA-R1 w/ frozen MGRM): 使用未经训练的 MGRM,性能在后期出现下降,表明一个不准确且固定的奖励模型会误导学习。
该实验有力地证明了 MGRM 能够提供可靠的内部奖励信号,赋能智能体在无外部监督的情况下实现真正的自我进化。
3.3 消融实验与泛化能力测试
-
训练算法对比 (对应论文 Figure 4 & 9):
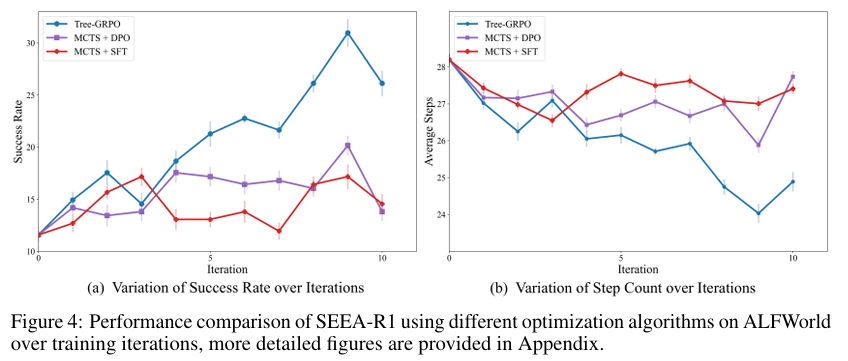
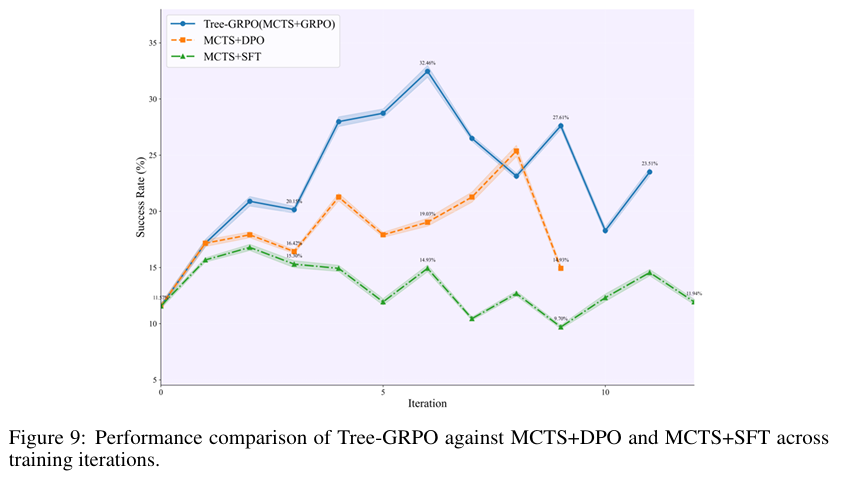
在相同的 MCTS 设置下,Tree-GRPO 的收敛速度和最终性能均显著优于 MCTS+DPO 和 MCTS+SFT。这得益于其 on-policy 的特性,使得策略优化与数据收集过程保持一致,学习信号更稳定。 -
EmbodiedEval 泛化能力测试 (对应论文 Table 3):
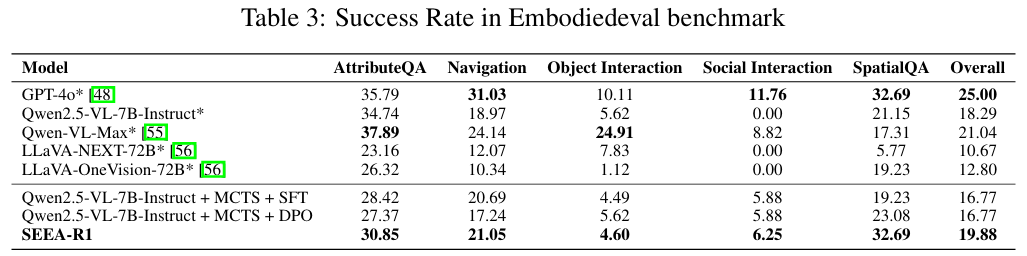
在 OOD 基准 EmbodiedEval 上,经过 Tree-GRPO 训练的 SEEA-R1 整体性能优于使用 SFT 或 DPO 训练的同基座模型。尤其在空间问答 (SpatialQA) 任务上,性能追平了 GPT-4o,体现了其 MCTS 探索带来的强大空间推理能力的可迁移性。
4. 结论
SEEA-R1 首次将强化微调(RFT)成功应用于训练能够自我进化的具身智能体。通过创新的 Tree-GRPO 算法,它有效解决了具身任务中普遍存在的稀疏奖励和长时序信用分配难题;通过 MGRM 模型,它摆脱了对人工奖励的依赖,实现了跨任务的自主学习。
在 ALFWorld 等基准上取得的 SOTA 性能,以及在无外部奖励和 OOD 场景下的出色表现,充分证明了 SEEA-R1 是一个用于构建可扩展、自主学习的具身智能的强大框架。
更多推荐
 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)